O rastreador de consultas do Explorar e o painel Desempenho do Explorar fornecem dados de desempenho passo a passo para uma consulta do Explorar. Estes dados podem ajudar a identificar os principais pontos de entrada para a resolução de problemas e a resolver problemas de desempenho com consultas, bem como fornecer recomendações de melhorias.
Explore o rastreador de consultas
O rastreador de consultas do Explore apresenta o progresso de uma consulta do Explore através das três fases da consulta enquanto a consulta está em execução.
![]()
Se uma consulta demorar muito tempo a ser executada, o rastreador de consultas pode indicar que fase da consulta está a causar o problema de desempenho. Isto é útil para identificar onde podem ocorrer problemas de desempenho e onde os esforços de otimização podem ser mais eficazes.
O rastreador de consultas é apresentado quando um Explorar está em execução, desde que o painel Visualização do Explorar ou o painel Dados do Explorar esteja aberto.
Explore o painel Desempenho
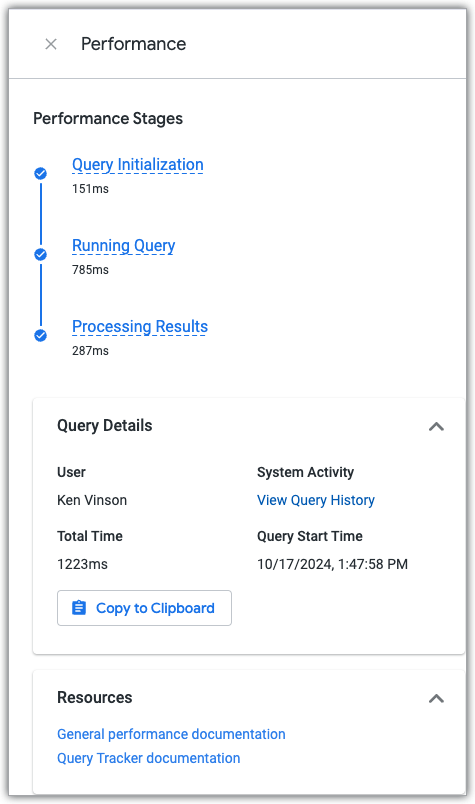
Para ver o painel Desempenho do Explorar, clique no link Ver detalhes de desempenho, que está disponível em qualquer consulta do Explorar que tenha sido executada.

O painel Desempenho mostra o tempo que a consulta passou em cada uma das três fases da consulta e inclui links para a documentação de desempenho e o painel de controlo do histórico de consultas da atividade do sistema, que mostra os dados de desempenho atuais e do histórico da consulta e da exploração usados para criar a consulta.
Fases da consulta
Quando um Explorar do Looker executa uma consulta de base de dados, a consulta é executada em três fases, da seguinte forma:
- A fase de inicialização da consulta
- A fase de execução da consulta
- A fase de resultados do processamento
Fase de inicialização da consulta
Durante a fase de inicialização da consulta, o Looker executa todas as tarefas necessárias antes de a consulta ser enviada para a sua base de dados. A fase de inicialização da consulta inclui as seguintes tarefas:
- Compilar o modelo LookML
- A verificar se é necessário criar tabelas derivadas persistentes (PDTs)
- Gerar o SQL da consulta
- Adquirir a ligação à base de dados
A página de documentação Compreender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas na Atividade do sistema para ver discriminações detalhadas de uma consulta. A fase de inicialização da consulta do rastreador de consultas inclui os eventos descritos na fase do trabalhador assíncrono, na fase de inicialização e na fase de processamento de ligações da análise detalhada Métricas de desempenho das consultas.
Fase de execução da consulta
A fase Running Query é quando o Looker contacta e consulta a sua base de dados e devolve os resultados da consulta. Os problemas de desempenho durante esta fase podem indicar um problema com a base de dados externa, como PDTs que demoram muito tempo a serem reconstruídos e podem ter de ser otimizados, ou tabelas de bases de dados externas que podem ter de ser otimizadas. A fase Executar consulta inclui as seguintes tarefas:
- Criar todas as PDTs na base de dados necessárias para a consulta da funcionalidade Explorar
- Executar a consulta pedida na base de dados
A página de documentação Compreender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas na Atividade do sistema para ver discriminações detalhadas de uma consulta. A fase Execução da consulta do rastreador de consultas inclui os eventos descritos na fase de consultas principais da exploração Métricas de desempenho das consultas.
Seguem-se possíveis passos a dar se tiver problemas de desempenho durante esta fase:
- Crie explorações com junções
many_to_onesempre que possível. A união de visualizações do nível mais detalhado ao nível de detalhe mais elevado (many_to_one) oferece normalmente o melhor desempenho das consultas. - Maximize o armazenamento em cache para sincronizar com as suas políticas de ETL sempre que possível, de modo a reduzir o tráfego de consultas da base de dados. Por predefinição, o Looker armazena consultas em cache durante uma hora. Pode controlar a política de colocação em cache e sincronizar as atualizações de dados do Looker com o seu processo de ETL aplicando grupos de dados
nas explorações através do parâmetro
persist_with. A maximização do armazenamento em cache permite que o Looker se integre mais estreitamente com o pipeline de dados de back-end, para que a utilização da cache possa ser maximizada sem o risco de analisar dados desatualizados. As políticas de colocação em cache com nome podem ser aplicadas a um modelo completo ou a Explores individuais e tabelas derivadas persistentes (PDTs). - Use a funcionalidade de consciência agregada do Looker para criar tabelas de resumo ou roll-ups que o Looker possa usar para consultas sempre que possível, especialmente para consultas comuns de grandes bases de dados. Também pode usar a agregação de notoriedade para melhorar drasticamente o desempenho de painéis de controlo completos. Consulte o tutorial de agregação de dados de reconhecimento para ver informações adicionais.
- Use PDTs para consultas mais rápidas. Converta as análises detalhadas com muitas junções complexas ou com baixo desempenho, ou dimensões com subconsultas ou subseleções, em PDTs para que as visualizações de propriedade sejam pré-unidas e estejam prontas antes do tempo de execução.
- Se o seu dialeto da base de dados suportar PDTs incrementais, configure PDTs incrementais para reduzir o tempo que o Looker dedica à recompilação de tabelas de PDT.
- Evite juntar vistas em Explorar com chaves principais concatenadas definidas no Looker. Em alternativa, junte-se aos campos base que compõem a chave principal concatenada da vista. Em alternativa, recrie a vista como um PDT com a chave principal concatenada predefinida na definição SQL da tabela, em vez de no LookML de uma vista.
- Use a ferramenta Explicar em execução de SQL para testes de referência.
EXPLAINproduz uma vista geral do plano de execução de consultas da sua base de dados para uma determinada consulta SQL, o que lhe permite detetar componentes de consulta que podem ser otimizados. Saiba mais no artigo da comunidade Como otimizar o SQL com oEXPLAIN. - Declare os índices. Pode consultar os índices de cada tabela diretamente no Looker a partir do SQL Runner clicando no ícone de roda dentada numa tabela e, em seguida, selecionando Mostrar índices.
As colunas mais comuns que podem beneficiar de índices são datas importantes e chaves externas. A adição de índices a estas colunas aumenta o desempenho de quase todas as consultas. Isto também se aplica a PDTs. Os parâmetros do LookML, como
indexes,sort keysedistribution, podem ser aplicados adequadamente.
Fase de resultados do processamento
Durante a fase de Processamento de resultados, o Looker processa e renderiza os resultados da consulta. A fase Processamento de resultados inclui as seguintes tarefas:
- Streaming dos resultados da consulta para a cache
- A resolver cálculos da tabela
- Formatar os resultados da linguagem de modelos Liquid
- Unir consultas
- Calcular totais e subtotais
A página de documentação Compreender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas na Atividade do sistema para ver discriminações detalhadas de uma consulta. A fase Processamento de resultados do rastreador de consultas inclui os eventos descritos na fase pós-consulta da análise detalhada Métricas de desempenho de consultas.
Possíveis passos a tomar se tiver problemas de desempenho durante esta fase:
- Use funcionalidades como unir resultados, campos personalizados e cálculos de tabelas com moderação. Estas funcionalidades destinam-se a ser usadas como provas de conceito para ajudar a conceber o seu modelo. É uma prática recomendada codificar permanentemente todos os cálculos e funções usados com frequência no LookML, o que gera SQL a ser processado na sua base de dados. Os cálculos excessivos podem competir pela memória Java na instância do Looker, o que faz com que a instância do Looker responda mais lentamente.
- Limite o número de visualizações que inclui num modelo quando estiver presente um grande número de ficheiros de visualização. A inclusão de todas as visualizações num único modelo pode diminuir o desempenho. Quando um projeto tiver um grande número de vistas, considere incluir apenas os ficheiros de vistas necessários em cada modelo. Considere usar convenções de nomenclatura estratégicas para os nomes dos ficheiros de visualização, de modo a permitir a inclusão de grupos de visualizações num modelo. Pode encontrar um exemplo na documentação do parâmetro
includes. - Evite devolver um grande número de pontos de dados por predefinição nos mosaicos do painel de controlo e nos Looks. As consultas que devolvem milhares de pontos de dados consomem mais memória. Certifique-se de que os dados são limitados sempre que possível aplicando
filtros de front-end a painéis de controlo, Looks e Explores, e ao nível do LookML com os parâmetros
required filters,conditionally_filteresql_always_where. - Transfira ou envie consultas usando a opção Todos os resultados com moderação, uma vez que algumas consultas podem ser muito grandes e sobrecarregar o servidor do Looker quando são processadas.