Looker では、データベースのスクラッチ スキーマに永続的な派生テーブル(PDT)が書き込まれます。Looker は永続性戦略に基づいて PDT の永続化と再構築を行います。PDTの再構築がトリガーされると、Lookerはデフォルトでテーブル全体を再構築します。
増分 PDT は、テーブル全体を再構築するのではなく、Looker が新しいデータをテーブルに追加して構築する PDT です。
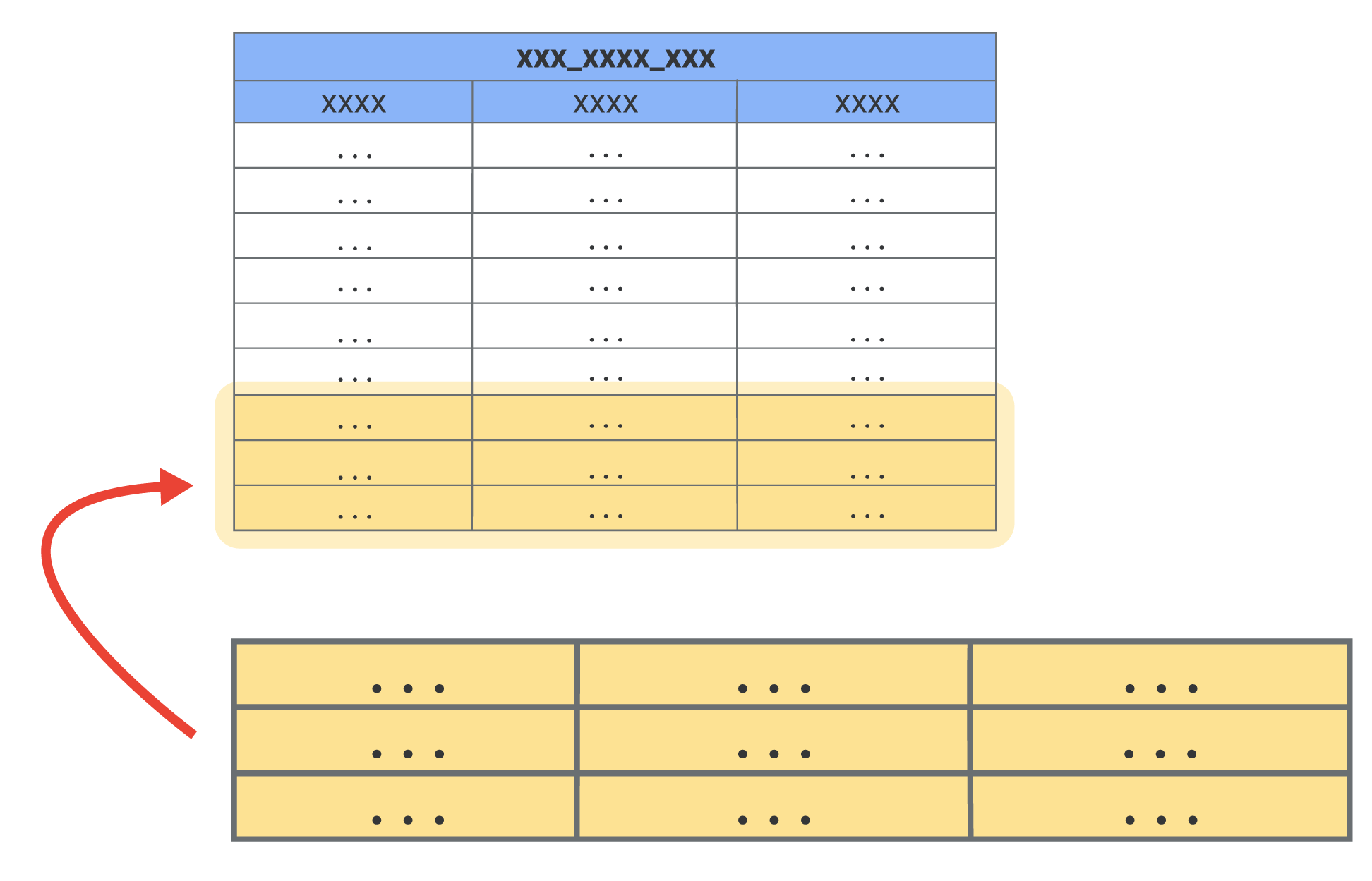
言語が増分 PDT をサポートしている場合、以下のタイプの PDT を増分 PDT にすることができます。
- 集計テーブル
- LookML ベース(ネイティブ)の PDT
- SQL ベースの PDT
増分PDTに対するクエリを初めて実行すると、Lookerは、初期データを取得するためにPDT全体を構築します。テーブルのサイズが大きい場合、初期構築には大規模なテーブル構築のためにかなり時間がかかる場合があります。初期テーブルが構築されると、戦略的に増分PDTが設定されているなら、それ以降の構築は増分になり必要な時間は短くなります。
増分 PDT について、次の点に注意してください。
- 増分 PDT は、トリガーベースの永続化戦略を使用する PDT にのみサポートされています(
datagroup_trigger、sql_trigger_value、interval_trigger)。増分 PDT は、persist_for永続性戦略を使用する PDT ではサポートされていません。 - SQL ベースの PDT の場合、テーブルクエリは増分 PDT として使用するため
sqlパラメータを使用して定義する必要があります。sql_createパラメータ、またはcreate_processパラメータで定義された SQL ベースの PDT は、段階的に構築することはできません。このページの例 1 で示されているように、Looker では、INSERT コマンドまたは MERGE コマンドを使用することにより、増分 PDT の増分を作成します。派生テーブルを、カスタムデータ定義言語(DDL)ステートメントを使用して定義することはできません。というのは、Looker は、正確な増分作成のためにどの DDL ステートメントが必要になるかを判別できないからです。 - 増分 PDT のソーステーブルは、時間ベースのクエリ用に最適化する必要があります。具体的には、増分キーに使用される時間ベースの列には、パーティショニング、並べ替えキー、インデックスなどの最適化戦略、または言語でサポートされているなんらかの最適化戦略が含まれている必要があります。ソーステーブル最適化は強く推奨されます。というのは、増分テーブルが更新されるたびに、Looker はソーステーブルに対してクエリを実行し、増分キーとして使用される時間ベースの列の最新値を調べるからです。それらのクエリ用にソーステーブルが最適化されていない場合、Looker が最新値をクエリする処理は遅くなってコストがかかる可能性があります。
増分PDTを定義する
次のパラメータを使用して、PDTを増分PDTにすることができます。
increment_key(PDT を増分 PDT にする場合に必須): 新しいレコードを照会する期間を定義します。{% incrementcondition %}Liquid フィルタ(SQL ベースの PDT を、LookML ベースの PDT には非適用の増分 PDT とする場合に必須): 増分 キーが基になっているデータベース時間列に接続します。詳しくは、increment_keyのドキュメント ページをご覧ください。increment_offset(任意): 増分構築ごとに再構築する、以前の期間(increment key の粒度で指定される)の数を定義する整数。increment_offsetパラメータは、遅れて到着したデータに便利です。この場合、対応する増分が最初に構築され、PDT に追加されたときに、以前の期間に含まれていない新しいデータが含まれていることがあります。
永続的なネイティブ派生テーブル、永続的な SQL ベースの派生テーブル、サマリー表から増分 PDT を作成する方法の例については、increment_key パラメータのドキュメント ページをご覧ください。
LookMLベースの増分PDTを定義するビューファイルの簡単な例を以下に示します。
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
このテーブルは、クエリの初回実行時に全体が構築されます。その後、PDT は 1 日分(increment_key: departure_date)単位で再構築され、3 日分(increment_offset: 3)に戻ります。
増分キーは departure_date ディメンションに基づいています。これは、実際には departure ディメンション グループの date 期間です。(ディメンション グループの仕組みの概要については、dimension_group パラメータのドキュメント ページをご覧ください)。ディメンション グループと期間はどちらも、この PDT の explore_source である flights ビューで定義されます。departure ディメンション グループは、flights ビューファイルで次のように定義されます。
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
増分パラメーターと永続性戦略の関係
PDT の increment_key と increment_offset の設定は、PDT の永続性戦略とは独立しています。
- 増分 PDT の永続性戦略で決まるのは、PDT の増分のタイミングのみです。PDT ビルダーは、テーブルの永続性戦略がトリガーされる場合や、Explore の [Rebuild Dtables & Run] オプションで PDT を手動でトリガーしない限り、増分 PDT を変更しません。
- PDT の増分を行う際、PDT ビルダーは直近の時間増分(
increment_keyパラメータによって定義される期間)を調べることにより、以前テーブルに最後のデータを追加したのがいつだったのかを判別します。それに基づき、PDTビルダーは、テーブルの中の最新の時間増分の開始時間までデータを切り捨てた後、そこから最新の増分を構築します。 - PDT に
increment_offsetパラメータがある場合、PDT ビルダーはincrement_offsetパラメータで指定される数の以前の期間のデータも再構築します。以前の期間は、直近の時間増分(increment_keyパラメータによって定義される期間)の開始時間からさかのぼります。
次のシナリオのサンプルは、increment_key、increment_offset、永続性戦略の関係を示し、増分 PDT がどのように更新されるかを示すものです。
例 1
この例で使用されるPDTのプロパティは次のとおりです:
- 増分キー: 日付
- 増分オフセット: 3
- 永続性戦略: 毎月 1 日にトリガーされます。
このテーブルがどう更新されるかを以下に示します:
- 永続性戦略が毎月であることは、テーブルが月に一度自動構築されることを意味します。つまり、例えば6月1日の時点で、テーブルに追加されていた最後の行は5月1日になります。
- このPDTの増分キーは日単位であるため、PDTビルダーは、5月1日をその日の初めまで切り捨て、5月1日と当日6月1日までのデータを再構築します。
- さらに、この PDT の増分オフセットは
3です。そのためPDTビルダーは、5月1日より前の3つの期間(日)のデータも再構築します。その結果、4月28、29、30日、および当日6月1日までのデータが再構築されます。
SQLで言えば、既存PDTのうち再構築する必要のある行を判別するためにPDTビルダーが6月1日に実行するコマンドは次のとおりです:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
また、最新の増分を構築するためにPDTビルダーが6月1日に実行するSQLコマンドは次のとおりです:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
例 2
この例で使用されるPDTのプロパティは次のとおりです:
- 永続性戦略: 1 日に 1 回トリガーされます。
- 増分キー: 月
- 増分オフセット: 0
このテーブルが6月1日にどう更新されるかを以下に示します:
- 永続性戦略が毎日であることは、テーブルが1日に一度自動構築されることを意味します。6月1日の時点で、テーブルに追加されていたの最後の行は5月31日になります。
- 増分キーは月単位であるため、PDTビルダーは、5月31日からその月の初めまで切り捨て、5月のすべておよび6月1日を含む当日までのデータを再構築します。
- このPDTには増分オフセットがないため、再構築される以前の期間はありません。
このテーブルが6月2日にどう更新されるかを以下に示します:
- 6月2日の時点で、テーブルに追加されていた最後の行は6月1日になります。
- PDTビルダーは6月の月初めまでさかのぼって切り捨て、6月1日以降当日までのデータを再構築するため、再構築されるデータは6月1日と6月2日だけです。
- このPDTには増分オフセットがないため、再構築される以前の期間はありません。
例 3
この例で使用されるPDTのプロパティは次のとおりです:
- 増分キー: 月
- 増分オフセット: 3
- 永続性戦略: 1 日に 1 回トリガーされます。
このシナリオは、増分 PDT のまずい設定例です。3か月オフセットで毎日トリガーされる PDT となっています。つまり、最低でも3か月分のデータが毎日再構築されるため、増分PDTが非常に非効率な方法で使用されることになります。しかし、これは増分PDTの動作について理解を深める上で興味深いシナリオです。
このテーブルが6月1日にどう更新されるかを以下に示します:
- 永続性戦略が毎日であることは、テーブルが1日に一度自動構築されることを意味します。例えば6月1日の時点で、テーブルに追加されていた最後の行は5月31日になります。
- 増分キーは月単位であるため、PDTビルダーは、5月31日からその月の初めまで切り捨て、5月のすべておよび6月1日を含む当日までのデータを再構築します。
- さらに、この PDT の増分オフセットは
3です。つまり、PDT ビルダーは 5 月より前の 3 つの期間(月)のデータも再構築します。2 月、3 月、4 月から6月1日を含む当日までのデータが再構築されます。
このテーブルが6月2日にどう更新されるかを以下に示します:
- 6月2日の時点で、テーブルに追加されていた最後の行は6月1日になります。
- PDTビルダーは、6月1日までさかのぼって月を切り捨て、6月2日を含む6月のデータを再構築します。
- さらに、増分オフセットがあるため、PDTビルダーは、6月より前の3か月分のデータを再構築することになります。その結果、3月、4月、5月、および当日6月2までのデータが再構築されます。
増分PDTを開発モードでテストする
新しい増分PDTを本番環境にデプロイする前に、PDTをテストして、その構築と増分を確認することができます。増分PDTを開発モードでテストするには:
PDT用のExploreを作成します:
- 関連するモデルファイルで、
includeパラメータを使用して、PDT のビューファイルをモデルファイルに含めます。 - 同じモデルファイルで、
exploreパラメータを使用して、増分 PDT のビューの Explore を作成します。
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- 関連するモデルファイルで、
PDT用のExploreを開きます。これを行うには、[See file actions] ボタンを選択して Explore の名前を選択します。
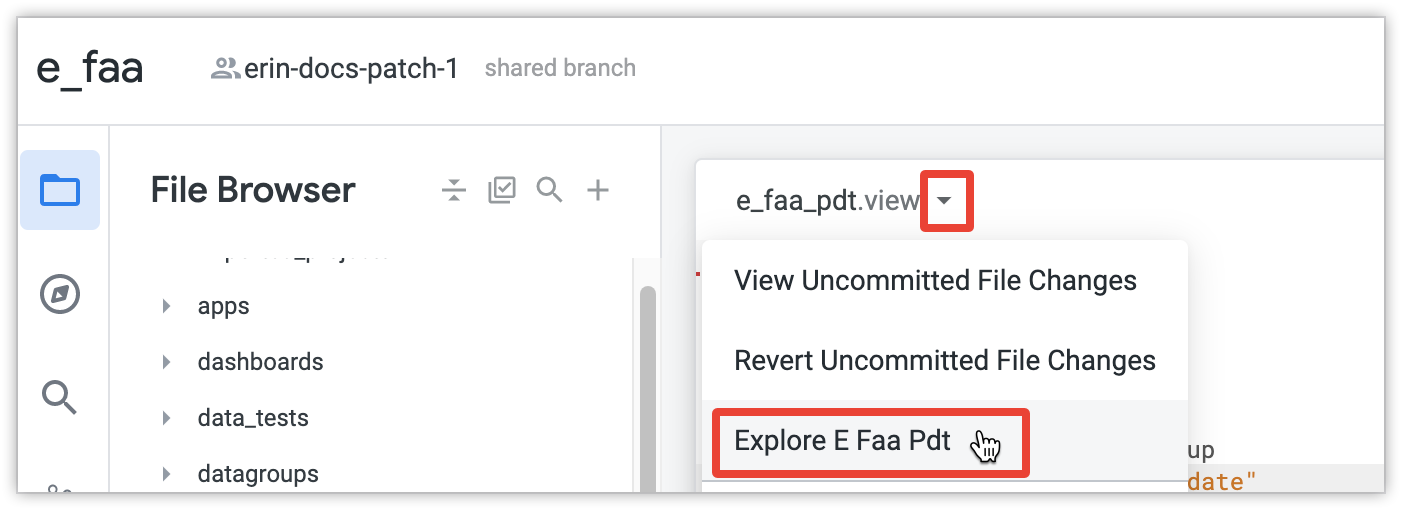
Explore の中で、ディメンションまたはメジャーを選択し、[Run] をクリックします。LookerによりPDT全体が構築されます。これが増分PDTに対して実行した最初のクエリである場合、PDTビルダーはPDT全体を構築し初期データを取得します。テーブルのサイズが大きい場合、初期構築には大規模なテーブル構築のためにかなり時間がかかる場合があります。
初期PDTが構築されたことは、次の方法で確認できます:
see_logs権限がある場合は、PDT イベントログでテーブルが構築されていることを確認できます。PDT イベントログの中に PDT の作成イベントが見当たらない場合、PDT イベントログ Explore の先頭のステータス情報を確認してください。それが「キャッシュから」となっている場合、[キャッシュをクリアして更新] を選択することにより、最新情報を得ることができます。- そうなっていない場合、Explore の [SQL] バーの [SQL] タブの中のコメントを調べることができます。[SQL] タブには、Explore の中でクエリを実行した場合に実行されるクエリとアクションが示されています。たとえば、[SQL] タブのコメントが
-- generate derived table e_incremental_pdt
PDT の最初の構築を作成したら、「Explore」の [Rebuild Derived Tables & Run] オプションを使用して、PDT の増分構築のプロンプトを表示します。
前と同じ方法を使用することによりPDTの増分構築を確認できます。
see_logs権限がある場合は、PDT イベントログを使用して、増分 PDT のcreate increment completeイベントを確認できます。PDT イベントログの中にこのイベントが見当たらず、クエリのステータスが「キャッシュから」となっている場合は、[キャッシュをクリアして更新] を選択して最新情報を得ます。- Explore の [SQL] バーの [SQL] タブでコメントを確認します。この場合、コメントにはPDTが増分されたことが示されています。例:
-- increment persistent derived table e_incremental_pdt to generation 2
PDT が構築されていて増分が適切であることを確認した後、PDT の専用 Explore をそのまま保持することが望ましくない場合は、PDT の
exploreパラメータとincludeパラメータをモデルファイルから削除するかコメントアウトします。
開発モードで PDT を構築した後、変更内容をデプロイしたら、テーブルの定義にそれ以上変更を加えるのでなければ、同じテーブルが本番用に使用されます。詳しくは、Looker の派生テーブル ドキュメントの Development Mode の永続テーブルをご覧ください。
増分PDT対応のデータベース言語
Looker プロジェクトで増分 PDT に対応するためには、データベース言語が、行の削除と挿入を有効にするデータ定義言語(DDL)のコマンドに対応している必要があります。
次の表は、Looker の最新リリースで増分 PDT をサポートする言語を示しています(Databricks の場合、増分 PDT は Databricks バージョン 12.1 以降でのみサポートされます)。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | × |
| Amazon Athena | × |
| Amazon Aurora MySQL | × |
| Amazon Redshift | ○ |
| Apache Druid | × |
| Apache Druid 0.13+ | × |
| Apache Druid 0.18+ | × |
| Apache Hive 2.3+ | × |
| Apache Hive 3.1.2+ | × |
| Apache Spark 3 以降 | × |
| ClickHouse | × |
| Cloudera Impala 3.1+ | × |
| ネイティブ ドライバを使用した Cloudera Impala 3.1+ | × |
| ネイティブ ドライバを使用した Cloudera Impala | × |
| DataVirtuality | × |
| Databricks | ○ |
| Denodo 7 | × |
| Denodo 8 | × |
| Dremio | × |
| Dremio 11+ | × |
| Exasol | × |
| Firebolt | × |
| Google BigQuery Legacy SQL | × |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | ○ |
| Google Cloud SQL | × |
| Google Spanner | × |
| Greenplum | ○ |
| HyperSQL | × |
| IBM Netezza | × |
| MariaDB | × |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | × |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | × |
| Microsoft SQL Server 2012+ | × |
| Microsoft SQL Server 2016 | × |
| Microsoft SQL Server 2017+ | × |
| MongoBI | × |
| MySQL | ○ |
| MySQL 8.0.12+ | ○ |
| Oracle | × |
| Oracle ADWC | × |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL 9.5 より前 | ○ |
| PrestoDB | × |
| PrestoSQL | × |
| SAP HANA 2+ | × |
| SingleStore | × |
| SingleStore 7+ | × |
| Snowflake | ○ |
| Teradata | × |
| Trino | × |
| Vector | × |
| Vertica | ○ |