概要
Looker では、集約テーブルの自動認識ロジックを使用して、データベース内で最も小規模で効率的なテーブルを検出し、精度を維持しながらクエリを実行します。
Looker デベロッパーは、データベース内の非常に大きなテーブルに対して、さまざまな属性の組み合わせによってグループ化されたデータのより小さな集約テーブルを作成できます。 集約テーブルは、元の大きなテーブルの代わりに、Looker が可能であれば常にクエリに使用できるロールアップまたはサマリー テーブルとして機能します。 集約テーブルの自動認識を効果的に実装すれば、平均的なクエリを大幅に高速化できます。
たとえば、ウェブサイトで発生した注文ごとに 1 行にした 1 ペタバイト規模のデータテーブルがあるとします。このデータベースから、日次売上合計を含む集約テーブルを作成できます。ウェブサイトの注文件数が毎日 1,000 件だった場合、日次集約テーブルは毎日の行数を表し、元のテーブルより 999 行少なくなります。月ごとの販売合計が含まれる別の集約テーブルを作成すると、さらに効率的になります。これで、ユーザーが日次売上または週次売上の料金クエリを実行する場合、Looker は日次売上合計テーブルを使用するようになります。ユーザーが年間売上高に関するクエリを実行していて、年次集約テーブルがない場合、Looker は次善の手段を使用します。この例では、月間売上高集約テーブルです。
Looker は、小規模な集約テーブルで可能な限りユーザーの質問に回答します。次に例を示します。
- 月間総売上高に関するクエリの場合、Looker は月間売上高(
sales_monthly_aggregate_table)に基づく集約テーブルを使用します。 - 1 日の売上ごとの合計に関するクエリでは、その粒度の集約テーブルがないため、Looker は元のデータベース テーブル(
orders_database)からクエリ結果を取得します。(ただし、ユーザーがこのタイプのクエリを頻繁に実行する場合には、集約テーブルを作成できます)。 - 週次売上高のクエリには週次集約テーブルがないため、Looker は次善の方法として、日次売上に基づく集約テーブル(
sales_daily_aggregate_table)を使用します。
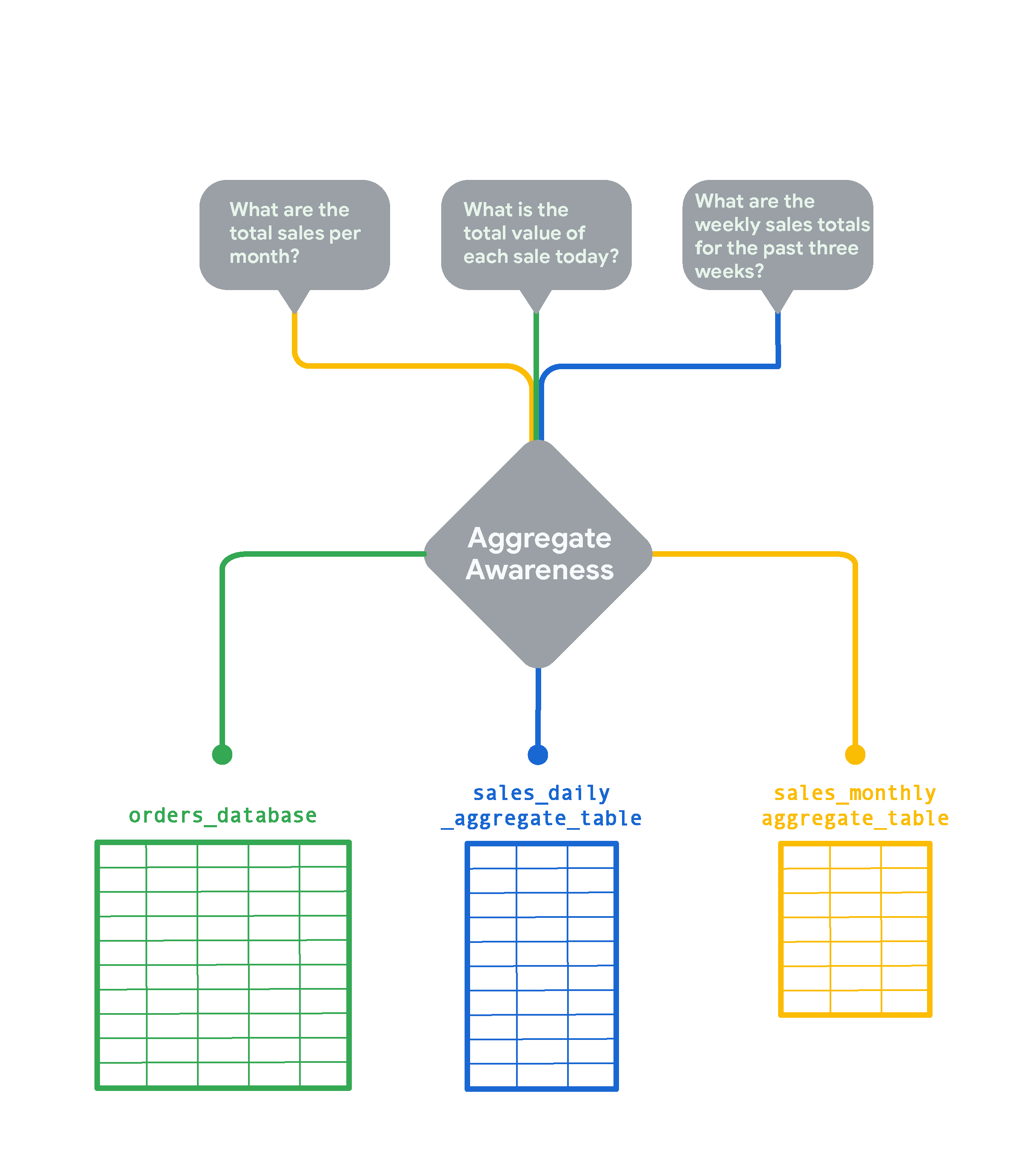
集約テーブルの自動認識ロジックを使用して、Looker はユーザーの質問に答えるために可能な限り小さい集約テーブルに対してクエリを実行します。元のテーブルは、集約テーブルが提供するよりも細かい粒度を必要とするクエリにのみ使用されます。
集約テーブルは、別の Explore に結合、追加する必要はありません。その代わり、Looker では Explore クエリの FROM 句を動的に調整し、クエリに最適な集約テーブルにアクセスします。 これは、ドリルが維持され、Explore を統合できることを意味します。集約テーブルの自動認識により、1 つの Explore で自動的に集約テーブルを利用できるうえ、必要に応じて詳細なデータの詳細な分析が可能になります。
また、大量のテーブルに対してクエリを実行するタイルの場合には、集約テーブルを利用してダッシュボードのパフォーマンスを大幅に向上させることもできます。詳しくは、aggregate_table パラメータのドキュメント ページのダッシュボードからの集計テーブルの LookML の取得をご覧ください。
プロジェクトに集計テーブルを追加する
Looker のデベロッパーは、データベース内の大きなテーブルに必要なクエリの数を最小限に抑える、戦略的な集約テーブルを作成できます。集約テーブルはデータベースに保持して、集約テーブルの自動認識でアクセスできるようにする必要があります。したがって、集約テーブルは一種の永続的な派生テーブル(PDT)の一種です。
集約テーブルは、LookML プロジェクトの explore パラメータの下にある aggregate_table パラメータを使用して定義されます。
LookML に集約テーブルがある explore の例を次に示します。
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
集約テーブルを作成するには、LookML をゼロから作成するか、Explore またはダッシュボードから集約テーブルの LookML を入手します。aggregate_table パラメータとそのサブパラメータの詳細については、aggregate_table パラメータのドキュメント ページをご覧ください。
集約テーブルの設計
Explore クエリで集約テーブルを使用するには、集約テーブルが Explore クエリに正確なデータを提供できる必要があります。 次のすべてに該当する場合、Looker で Explore クエリの集約テーブルを使用できます。
- Explore クエリのフィールドは、集約テーブルのフィールドのサブセットである(このページのフィールドの要因のセクションを参照)。または、期間の場合、Explore クエリの期間を集約テーブル内の期間から取得できる(このページの期間の要因のセクションをご参照)。
- Explore クエリには、集約テーブルの自動認識でサポートされるメジャータイプが含まれている(このページのメジャータイプの要因のセクションを参照)、または、Explore クエリに、完全一致がある集約テーブルがある(このベージのExplore クエリと完全に一致する集約テーブルを作成するのセクションを参照)。
- Explore クエリのタイムゾーンは、集約テーブルで使用されるタイムゾーンと一致する(このページのタイムゾーンの要因のセクションを参照)。
- Explore クエリのフィルタは、集約テーブルのディメンションとして使用できるフィールドを参照する、または、各 Explore クエリのフィルタが、集計テーブルのフィルタと一致する(このページのフィルタの要因のセクションを参照)。
集約テーブルで Explore クエリに正確なデータを提供する方法の 1 つとして、Explore クエリと完全に一致する集約テーブルを作成するという方法があります。詳細については、このページのExplore クエリと完全に一致する集約テーブルを作成するのセクションをご覧ください。
フィールドの要因
Explore のクエリで使用するには、集約テーブルに、その Explore クエリのフィルタに必要なすべてのディメンションとメジャーを含める必要があります。Explore のクエリにディメンションまたはメジャーが含まれており、そのテーブルが集約テーブルに含まれていない場合、Looker は集約テーブルを使用できないため、代わりにベーステーブルを使用します。
たとえば、クエリがディメンション A と B によってグループ化され、メジャー C によって集計されて、ディメンション D でフィルタされる場合、集約テーブルには、ディメンションとして A、B、D、メジャーとして C が最低限設定されている必要があります。
集約テーブルに他のフィールドを含めることもできますが、最適化を可能にするには、少なくとも Explore クエリ フィールドが必要です。例外は期間ディメンションです。より荒い粒度の期間は、より細かい粒度の期間から導出できます。
このようにフィールドを考慮することにより、集約テーブルは、それを定義する Explore に固有なものになります。ある Explore で定義された集約テーブルは、別の Explore のクエリには使用されません。
期間の要因
Looker の集約テーブルの自動認識ロジックでは、ある期間から別の期間を導き出すことができます。集約テーブルの期間が Explore クエリよりも細かく(またはそれと同等に)設定されていれば、集約テーブルをクエリに使用できます。たとえば、日次データに基づく集約テーブルは、日次、月次、年次データ、さらには、月の特定の日、年の特定の日、年の特定の週のデータなど、他の期間を呼び出す Explore のクエリに使用できます。ただし、集約テーブルのデータは Explore クエリに対して十分に細かくないため、年次集約テーブルは 1 時間ごとのデータを呼び出す Explore クエリには使用できません。
期間のサブセットについても同様です。たとえば、過去 3 か月間にフィルタされた集約テーブルがあり、ユーザーが過去 2 か月間のフィルタでデータをクエリした場合、Looker はそのクエリに集約テーブルを使用できます。
また、期間フィルタを含むクエリにも同じロジックが適用されます。集約テーブルの期間が Explore クエリよりも細かく(またはそれと同等に)設定されていれば、期間フィルタを使用するクエリに集約テーブルを使用できます。例えば、日次のタイムフレームディメンションがある集約テーブルを、日、週または月でフィルタリングする Explore クエリで使用できます。
メジャータイプの要因
Explore クエリで集約テーブルを使用するには、集約テーブルのメジャーが Explore クエリに正確なデータを提供できる必要があります。
このため、以下のセクションで説明するように、特定のタイプのメジャーのみがサポートされています。
Explore のクエリで他の種類のメジャーが使用されている場合、Looker では、集約テーブルではなく元のテーブルを使用して結果が返されます。唯一の例外は、Explore クエリと完全に一致する集約テーブルを作成するに説明されているように、Explore クエリが集約テーブルクエリの完全一致である場合です。
それ以外の場合、Looker は集約テーブルではなく元のテーブルを使用して結果を返します。
サポートされているメジャータイプを含むメジャー
集約テーブルの自動認識は、以下のメジャータイプを含むメジャーを使用する Explore クエリに使用できます。
Explore クエリで集約テーブルを使用するには、Looker が、集約テーブルのメジャーに対して Explore クエリに正確なデータを提供するように動作させる必要があります。たとえば、type: sum を含むメジャーは、複数の合計を合計できるため、集約テーブルの自動認識に使用できます。週次合計の集約テーブルは、正確な月次合計を得るために合算するこができます。同様に、日次の最大値の集約テーブルを使用して、正確な週次の最大値を見つけることができるため、type: max を含むメジャーを使用できます。
type: average を含むメジャーの場合、Looker が合計値とカウントデータを使用して、集約テーブルから平均値を正確に導き出すため、集約テーブルの自動認識がサポートされます。
SQL 式で定義された measure
集計テーブルの自動認識は、sql パラメータの式で定義されたメジャーでも使用できます。SQL 式で定義する場合、次のメジャータイプもサポートされます。
集約テーブルの自動認識は、次の例のような、他のメジャーの組み合わせとして定義されているメジャーでサポートされています。
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
集約テーブルの自動認識は、次のメジャーのような、sql パラメータで計算が定義されているメジャーでもサポートされます。
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
また、集約テーブルの自動認識は、次のメジャーのような、sql パラメータで MIN、MAX、COUNT 演算が定義されているメジャーでサポートされます。
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
LookML フィールドを参照する measure
メジャーで sql 式を使用する場合、集約テーブルの自動認識は次のタイプのフィールド参照をサポートします。
- 他のビューのフィールドを示す、
${view_name.field_name}形式を使用した参照 - 同じビューのフィールドを示す、
${field_name}形式を使用した参照
集約テーブルの自動認識は、テーブル内の列を示す ${TABLE}.column_name 形式を使用して定義されたメジャーではサポートされていません。(LookML で参照を使用する方法の概要については、SQL の組み込みと LookML オブジェクトへの参照のドキュメント ページをご覧ください)。
たとえば、この sql パラメータで定義したメジャーは、${TABLE}.column_name 形式を使用するため、集約テーブルではサポートされません。
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
集約テーブルにこのメジャーを含める場合は、代わりに ${TABLE}.column_name 形式で定義されたディメンションを作成し、次のように、ディメンションを参照するメジャーを作成します。
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
これで、集約テーブルで wholesale_value メジャーを使用できるようになりました。
個別のカウントを概算するメジャー
一般に、個別のカウントを集計しようとすると、正確なデータが得られないため、集約テーブルの自動認識では個別のカウントはサポートされていません。ウェブサイト上で個別のユーザー数をカウントしている場合、たとえば、3 週間空けて 2 回ウェブサイトにアクセスしたユーザーがいる場合があります。週次集約テーブルを適用して、ウェブサイト上の個別ユーザーの月次カウントを取得しようとした場合、そのユーザーは、月次個別カウントのクエリで 2 回カウントされるため、データは不正確になります。
回避策の 1 つは、このページの Explore クエリと完全に一致する集計テーブルを作成するのセクションで説明されるように、Explore クエリと完全に一致する集約テーブルを作成することです。Explore のクエリと集約テーブルのクエリが同じである場合、個別カウントメジャーが正確なデータを提供するため、集約テーブルの自動認識に使用できます。
もう 1 つの方法は、個別のカウントに概算を使用することです。HyperLogLog スケッチをサポートする言語の場合、Looker では HyperLogLog アルゴリズムを利用して、集約テーブルの個別カウントを概算できます。
HyperLogLog アルゴリズムには、約 2% のエラーがあることがわかっています。allow_approximate_optimization: yes パラメータでは、メジャーが集約テーブルから概算で計算できるように、メジャーに対して概算データを使用しても構わないということをデベロッパーが認識する必要があります。
詳しくは、allow_approximate_optimization パラメータのドキュメント ページ、および、HyperLogLog を使用した個別カウントをサポートする言語のリストをご覧ください。
タイムゾーンの要因
多くの場合、データベース管理者はデータベースのタイムゾーンとして UTC を使用します。ただし、多くのユーザーがその UTC タイムゾーンにはいない可能性があります。Looker では、ユーザーが各自のタイムゾーンでクエリ結果を取得できるように、タイムゾーンを変換するオプションが複数用意されています。
- クエリのタイムゾーン。データベース接続上のすべてのクエリに適用される設定です。すべてのユーザーが同じタイムゾーンにある場合、単一のクエリのタイムゾーンを設定して、すべてのクエリが、データベースのタイムゾーンからクエリのタイムゾーンに変換されます。
- ユーザー固有のタイムゾーン。ユーザーが個別に割り当てられ、タイムゾーンを選択できます。この場合、クエリはデータベースのタイムゾーンから個々のユーザーのタイムゾーンに変換されます。
これらのオプションの詳細については、タイムゾーンの設定の使用のドキュメント ページをご覧ください。
これらのコンセプトは、集約テーブルの自動認識を理解する上で重要です。その理由は、日付ディメンションまたは日付フィルタを使用したクエリに集約テーブルを使用するには、集約テーブルのタイムゾーンが元のクエリに使用されたタイムゾーン設定と一致必要があるためです。
timezone 値が指定されていない場合、集約テーブルではデータベースのタイムゾーンが使用されます。次のいずれかに該当する場合、データベース接続にもデータベースのタイムゾーンが使用されます。
- データベースがタイムゾーンをサポートしていない。
- データベース接続のクエリのタイムゾーンが、データベースのタイムゾーンとして同じタイムゾーンに設定されている。
- データベース接続に指定されたクエリのタイムゾーンもユーザー固有のタイムゾーンもない。この場合は、データベース接続にデータベースのタイムゾーンが使用されます。
いずれかが当てはまる場合は、集約テーブルの timezone パラメータを省略できます。
それ以外の場合は、集約テーブルが使用される可能性が高くなるように、集約テーブルのタイムゾーンをクエリと一致するように定義する必要があります。
- データベース接続が単一のクエリのタイムゾーンを使用している場合は、集約テーブルの
timezone値をクエリのタイムゾーンの値と一致させる必要があります。 - データベース接続でユーザー固有のタイムゾーンを使用している場合は、ユーザーのタイムゾーンと一致する異なる
timezone値を持つ、同一の集約テーブルを作成する必要があります。
フィルタの要因
集約テーブルにフィルタを含める場合は注意が必要です。集約テーブルでフィルタを使用すると、集約テーブルが使用不能な位置に結果を絞り込むことができます。たとえば、日次注文数の集約テーブルを作成し、集約テーブルでオーストラリアからのサングラスの注文のみをフィルタリングするとします。ユーザーが全世界のサングラスの日次注文数について Explore クエリを実行した場合、集約テーブルにはオーストラリアのデータしか含まれないため、Looker はこの集約テーブルを Explore クエリに使用できません。集約テーブルでは、Explore クエリで使用することができないほど狭いデータのフィルタリングが行われます。
また、Looker デベロッパーが Explore に組み込んでいる次のようなフィルタについても確認します。
access_filters: ユーザー固有のデータ制限を適用します。always_filter: Explore クエリには、特定のフィルタセットを含める必要があります。ユーザーはクエリのデフォルトのフィルタ値を変更できますが、フィルタを完全に削除することはできません。conditionally_filter: Explore でも定義されている 2 番目のリストから 1 つ以上のフィルタを適用する場合にユーザーがオーバーライドできるデフォルトのフィルタセットを定義します。
これらのフィルタタイプは特定のフィールドに基づいています。Explore にこれらのフィルタがある場合は、そのフィールドを aggregate_table の dimensions パラメータに含める必要があります。
たとえば、orders.region フィールドに基づくアクセス フィルタがある Explore は次のようになります。
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
この Explore に使用する集約テーブルを作成するには、集約テーブルに、アクセス フィルタの基になるフィールドを含める必要があります。次の例では、アクセス フィルタはフィールド orders.region に基づいており、同じフィールドが集約テーブルのディメンションとして含まれています。
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
集約テーブルのクエリには orders.region ディメンションが含まれているため、Looker は集約テーブルのデータを Explore クエリのフィルタに合わせて動的にフィルタリングできます。したがって、Looker にはアクセス フィルタがあっても、Explore のクエリに集約テーブルを使用できます。
これは、bind_filters で構成されたネイティブ派生テーブルを使用する Explore クエリにも適用されます。bind_filters パラメータは、指定されたフィルタを Explore クエリからネイティブ派生テーブルのサブクエリに渡します。集約テーブルの自動認識の場合、Explore クエリで bind_filters を使用するネイティブ派生テーブルが必要な場合は、ネイティブ派生テーブルの bind_filters パラメータで使用されているすべてのフィールドに、集約テーブルと同じ Explore クエリ内のフィルタ値がある場合にのみ、Explore クエリは集約テーブルを使用できます。
Explore クエリと完全に一致する集約テーブルを作成する
集約テーブルを Explore クエリに使用できることを確認する方法の 1 つは、Explore クエリと完全に一致する集約テーブルを作成することです。Explore のクエリと集約テーブルの両方が同じメジャー、ディメンション、フィルタ、タイムゾーン、その他のパラメータを使用している場合、定義上、集約テーブルの結果が Explore クエリに適用されます。集約テーブルが Explore クエリと完全に一致する場合、Looker はあらゆるタイプのメジャーを含む集約テーブルを使用できます。
Explore の集約テーブルを作成するには、Explore の歯車メニューから [LookML を取得] オプションを使用します。また、ダッシュボードの歯車メニューから [LookML を取得] オプションを使用して、ダッシュボード内のすべてのタイルと完全一致を作成することもできます。
クエリに使用される集約テーブルを決定する
see_sql 権限を持つユーザーは、Explore の [SQL] タブのコメントを使用して、クエリに使用される集約テーブルを確認できます。[SQL] タブのコメントも [Development Mode] に表示されるので、デベロッパーは新しい集約テーブルをテストして、本番環境に新しいテーブルを push する前に Looker でそれらがどのように使用されているか確認できます。
たとえば、前述の月次集約テーブルの例に基づいて、Explore に移動して年間売上合計のクエリを実行できます。次に [SQL] タブをクリックすると、Looker が作成したクエリの詳細が表示されます。Development Mode の場合は、クエリに使用した集約テーブルを示すコメントが Looker に表示されます。
[SQL] タブの次のコメントから、Looker がこのクエリに sales_monthly 集約テーブルを使用していること、および他の集約テーブルがクエリで使用されなかった理由を確認できます。
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
[SQL] タブに表示される可能性のあるコメントと、その解決方法に関する推奨事項については、このページのトラブルシューティングのセクションをご覧ください。
集約テーブルの自動認識向けのコスト削減予測の計算
データベース接続がコスト見積もりをサポートしており、クエリに集約テーブルを使用できる場合は、データベースに直接クエリを実行するのではなく、集約テーブルを使用することによるコスト削減額が Explore ウィンドウに表示されます。クエリの実行前に、Explore の [実行] ボタンの横には、集約テーブルの自動認識による削減額が表示されます。
クエリを実行する前にどの集約テーブルを使用するかを確認するには、このドキュメント ページのクエリに使用される集約テーブルを決定するのセクションで説明されるように、[SQL] タブをクリックします。
クエリを実行すると、Explore ウィンドウに、[実行] ボタンの横にクエリの集計に使用されたテーブルが表示されます。
コストの見積もりが有効になっているデータベース接続について、集約テーブルの自動認識による削減額が表示されます。詳細については、Looker でのデータ探索のドキュメント ページをご覧ください。
Looker による新しいデータの集約テーブルへの結合
時間フィルタを使用した集計テーブルの場合、Looker は集約テーブルに新しいデータを結合できます。過去 3 日間のデータを含む集約テーブルがありますが、昨日その集約テーブルが作成された場合が考えられます。集約テーブルには今日の情報がないため、最新の 1 日の情報を調べる Explore クエリには使用することが想定されません。
ただし、Looker は最新のデータに対してクエリを実行し、その結果を集約テーブルの結果に結合するため、Looker は引き続きその集約テーブルのデータをクエリに使用できます。
Looker は、次の状況で、集約テーブルのデータと新しいデータを結合できます。
- 集約テーブルに時間フィルタがある。
- 集約テーブルには、時間フィルタと同じ時間フィールドに基づくディメンションが含まれる。
たとえば、次の集約テーブルには、orders.created_date フィールドに基づくディメンションと、同じフィールドに基づく時間フィルタ("3 days")があります。
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
この集約テーブルが昨日作成された場合、Looker は集約テーブルにまだ含まれていない最新データを取得し、新しい結果を集約テーブルの結果と結合します。つまり、ユーザーは集約テーブルの自動認識を使用してパフォーマンスを最適化しながら、最新のデータを取得できます。
Development Mode の場合は、Explore の [SQL] タブをクリックすると、Looker がクエリに使用した集約テーブルと、集約テーブルに含まれていなかったより新しいデータを取り込むために Looker が使用した UNION ステートメントを表示できます。
集約テーブルは永続化する必要がある
集約テーブルの自動認識にアクセスするには、集約テーブルがデータベースに保持されている必要があります。永続性戦略は、集計テーブルの materialization パラメータで指定します。集約テーブルは一種の永続的な派生テーブル(PDT)であるため、集約テーブルには PDT と同じ要件があります。詳しくは、Looker の派生テーブルのドキュメント ページをご覧ください。
言語がサポートしている場合は、プロジェクトで増分 PDT を作成できます。Looker では、テーブル全体を再構築するのではなく、テーブルに新しいデータを追加して増分 PDT を作成します。集約テーブル自体も PDT の一種であるため、増分集約テーブルも作成できます。増分 PDT の詳細については、増分 PDT のドキュメント ページをご覧ください。増分集約テーブルの例については、increment_key パラメータのドキュメント ページをご覧ください。
develop 権限を持つユーザーは、永続性設定をオーバーライドして、クエリのすべての集約テーブルを再構築して最新のデータを取得できます。クエリのテーブルを再ビルドするには、Explore アクションの歯車メニューから [派生テーブルの再ビルドと実行] オプションを選択します。
このオプションを使用するには、Exploreクエリの読み込みを待つ必要があります。
[派生テーブルを再構築して実行する] オプションは、クエリで参照されるすべての派生テーブルと、クエリ内のテーブルに依存する派生テーブルを再構築します。これには、それ自体が永続的な派生テーブルの一種である集約テーブルも含まれます。
[派生テーブルを再構築して実行する] オプションを開始したユーザーの場合、クエリは、テーブルが再構築されるのを待ってから結果を読み込みます。他のユーザーのクエリには、引き続き既存のテーブルが使用されます。永続的なテーブルが再構築された後、すべてのユーザーは再構築されたテーブルを使用します。
[派生テーブルを再構築して実行する] オプションの詳細については、Looker の派生テーブルのドキュメント ページをご覧ください。
トラブルシューティング
クエリに使用される集計テーブルを決定するのセクションで説明されているように、Development Mode の場合は、Explore でクエリを実行し、[SQL] タブをクリックして、クエリに使用された集約テーブルに関するコメントを表示できます(存在する場合)。
[SQL] タブには、集約テーブルがクエリで使用されなかった理由(該当する場合)に関するコメントも表示されます。使用されていない集約テーブルの場合、コメントの先頭は次のようになります。
Did not use [explore name]::[aggregate table name];
たとえば、order_items Explore で定義された sales_daily 集約テーブルがクエリで使用されなかった理由について、コメントがあります。
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
この場合、クエリのフィルタによって、集約テーブルの使用が妨げられました。
次の表に、集約テーブルが使用できないその他の理由と、集約テーブルの使いやすさを向上させるための手順を示します。
| 集約テーブルを使用しない理由 | 説明と考えられる手順 |
|---|---|
| Explore にそのようなフィールドがありません。 | LookML 検証タイプのエラーがあります。集約テーブルが正しく定義されていないか、集約テーブルの LookML に入力ミスがあったことが最も可能性のある理由です。フィールド名などが間違っている可能性が最も高いです。この問題を解決するには、集約テーブルのディメンションとメジャーが Explore のフィールド名と一致することを確認します。集約テーブルの定義方法について詳しくは、aggregate_table パラメータのドキュメント ページをご覧ください。 |
| 集約テーブルには、クエリに次のフィールドが含まれていません。 | Explore のクエリで使用するには、集約テーブルに、その Explore クエリのフィルタに必要なすべてのディメンションとメジャーを含める必要があります。Explore のクエリにディメンションまたはメジャーが含まれており、そのテーブルが集約テーブルに含まれていない場合、Looker は集約テーブルを使用できないため、代わりにベーステーブルを使用します。詳しくは、このページのフィールドの要因をご覧ください。例外は期間ディメンションです。より荒い粒度の期間は、より細かい粒度の期間から導出できます。この問題を解決するには、Explore クエリのフィールドが集約テーブル定義に含まれていることを確認します。 |
| このクエリには、フィールドとして含まれていないか、集約テーブルのフィルタと完全には一致しなかった次のフィルタが含まれていました。 | クエリのフィルタによって、Lookder での集約テーブルの使用が妨げられました。これを解決するには、次のいずれかを行います。
|
| クエリに、ロールアップできない次のメジャーが含まれています。 | クエリに、個別カウント、中央値、パーセンタイルなど、集計テーブルによる自動認識でサポートされていないメジャータイプが 1 つ以上含まれています。この問題を解決するには、クエリの各メジャーのタイプが、サポートされているメジャーのタイプのいずれかであることを確認します。また、Explore に結合がある場合は、ファンアウト結合によってメジャーが個別のメジャー(対称集計)に変換されていないことを確認します。説明については、このページの結合を使用した Explore の対称集計をご覧ください。 |
| 別の集約テーブルが最適化に適していました。 | クエリには使用可能な複数の集約テーブルがあり、Looker では、代わりに使用できる最適な集約テーブルが見つかりました。この場合、何もする必要はありません。 |
primary_key または cancel_grouping_fields パラメータが原因で、Looker がグループ化しなかったため、クエリをロールアップできません。 |
クエリでは、GROUP BY 句がないディメンションを参照しているため、Looker はクエリに集約テーブルを使用できません。この問題を解決するには、ビューの primary_key パラメータと Explore の cancel_grouping_fields パラメータが正しく設定されていることを確認します。 |
| 集約テーブルにクエリにないフィルタが含まれていました。 | 集約テーブルには、クエリにない非時間フィルタがあります。この問題を解決するには、集約テーブルからフィルタを削除します。詳しくは、このページのフィルタの要因のセクションをご覧ください。 |
フィールドは、Explore クエリでフィルタ専用フィールドとして定義されていますが、集約テーブルの dimensions パラメータにリストされています。 |
集約テーブルの dimensions パラメータには、Explore クエリの filter フィールドとしてのみ定義されているフィールドが表示されます。この問題を解決するには、集約テーブルの dimensions リストからフィールドを削除します。集約テーブルにこのフィールドが必要な場合は、集約テーブルのクエリの filters リストに追加します。 |
| オプティマイザーでは、集約テーブルが使用されなかった理由を特定できません。 | このコメントはコーナーケース用に予約されています。頻繁に使用される Explore クエリにこのエラーが表示される場合は、Explore クエリと完全に一致する集約テーブルを作成できます。aggregate_table パラメータ ページで説明されているように、Explore から集約テーブルの LookML を簡単に取得できます。 |
注意点
結合を使用した Explore の対称集計
重要な注意点の 1 つは、複数のデータベース テーブルを結合する Explore では、Looker が、タイプ SUM、COUNT、AVERAGE のメジャーを、SUM DISTINCT、COUNT DISTINCT、AVERAGE DISTINCT としてそれぞれレンダリングできることです。Looker では、ファンアウトの誤計算を避けるためにこれを行います。たとえば、count メジャーは、count_distinct メジャータイプとしてレンダリングされます。これは、JOIN によるファンアウトの誤計算を避けるためであり、Looker の対称集計機能の一部です。Looker のこの機能の説明については、対称集計に関するベスト プラクティス ページをご覧ください。
対称集計機能は、誤計算を防ぐだけでなく、特定の状況で集約テーブルが使用されないようにすることもできます。そのため、理解しておくことが重要です。
集約テーブルの自動認識でサポートされているメジャータイプの場合、これは sum、count、average に適用されます。次の場合、Looker はこれらのメジャーのタイプを DISTINCT としてレンダリングします。
これらの結合のタイプの詳細については、relationship パラメータのドキュメント ページをご覧ください。
この理由で集約テーブルが使用されていない場合は、結合を使用する Explore でこれらのメジャータイプを使用するために、Explore のクエリと完全に一致する集約テーブルを作成します。詳細については、このページのExplore クエリと完全に一致する集約テーブルを作成するのセクションをご覧ください。
また、HyperLogLog スケッチをサポートする SQL 言語がある場合は、メジャーに allow_approximate_optimization: yes パラメータを追加できます。allow_approximate_optimization: yes でカウントのメジャーが定義されている場合、このメジャーが個別のカウントとしてレンダリングされる場合でも、Looker では、集約テーブルの自動認識にこのメジャーを使用できます。
詳しくは、allow_approximate_optimization パラメータのドキュメント ページ、および、HyperLogLog を使用した個別カウントをサポートする言語のリストをご覧ください。
集計テーブルの自動認識向けの言語サポート
集計認識を使用できるかどうかは、Looker 接続で使用されているデータベース言語によって異なります。Looker の最新リリースでは、次の言語が集約テーブルの自動認識をサポートしています。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | ○ |
| Amazon Aurora MySQL | ○ |
| Amazon Redshift | ○ |
| Apache Druid | × |
| Apache Druid 0.13+ | × |
| Apache Druid 0.18+ | × |
| Apache Hive 2.3+ | ○ |
| Apache Hive 3.1.2+ | ○ |
| Apache Spark 3 以降 | ○ |
| ClickHouse | × |
| Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala | ○ |
| DataVirtuality | × |
| Databricks | ○ |
| Denodo 7 | × |
| Denodo 8 | × |
| Dremio | × |
| Dremio 11+ | × |
| Exasol | ○ |
| Firebolt | × |
| Google BigQuery Legacy SQL | ○ |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | ○ |
| Google Cloud SQL | × |
| Google Spanner | × |
| Greenplum | ○ |
| HyperSQL | × |
| IBM Netezza | ○ |
| MariaDB | ○ |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | ○ |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | ○ |
| Microsoft SQL Server 2012+ | ○ |
| Microsoft SQL Server 2016 | ○ |
| Microsoft SQL Server 2017+ | ○ |
| MongoBI | × |
| MySQL | ○ |
| MySQL 8.0.12+ | ○ |
| Oracle | ○ |
| Oracle ADWC | ○ |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL 9.5 より前 | ○ |
| PrestoDB | ○ |
| PrestoSQL | ○ |
| SAP HANA 2+ | ○ |
| SingleStore | ○ |
| SingleStore 7+ | ○ |
| Snowflake | ○ |
| Teradata | ○ |
| Trino | ○ |
| Vector | ○ |
| Vertica | ○ |
集約テーブルの増分構築向けの言語サポート
Looker で Looker プロジェクトの増分集約テーブルをサポートするには、データベース言語でもこれらをサポートしている必要があります。次の表は、Looker の最新リリースで PDT の増分ビルドをサポートする方言を示しています。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | × |
| Amazon Athena | × |
| Amazon Aurora MySQL | × |
| Amazon Redshift | ○ |
| Apache Druid | × |
| Apache Druid 0.13+ | × |
| Apache Druid 0.18+ | × |
| Apache Hive 2.3+ | × |
| Apache Hive 3.1.2+ | × |
| Apache Spark 3 以降 | × |
| ClickHouse | × |
| Cloudera Impala 3.1+ | × |
| ネイティブ ドライバを使用した Cloudera Impala 3.1+ | × |
| ネイティブ ドライバを使用した Cloudera Impala | × |
| DataVirtuality | × |
| Databricks | ○ |
| Denodo 7 | × |
| Denodo 8 | × |
| Dremio | × |
| Dremio 11+ | × |
| Exasol | × |
| Firebolt | × |
| Google BigQuery Legacy SQL | × |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | ○ |
| Google Cloud SQL | × |
| Google Spanner | × |
| Greenplum | ○ |
| HyperSQL | × |
| IBM Netezza | × |
| MariaDB | × |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | × |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | × |
| Microsoft SQL Server 2012+ | × |
| Microsoft SQL Server 2016 | × |
| Microsoft SQL Server 2017+ | × |
| MongoBI | × |
| MySQL | ○ |
| MySQL 8.0.12+ | ○ |
| Oracle | × |
| Oracle ADWC | × |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL 9.5 より前 | ○ |
| PrestoDB | × |
| PrestoSQL | × |
| SAP HANA 2+ | × |
| SingleStore | × |
| SingleStore 7+ | × |
| Snowflake | ○ |
| Teradata | × |
| Trino | × |
| Vector | × |
| Vertica | ○ |