Di Looker, tabel turunan adalah kueri yang hasilnya digunakan seolah-olah kueri tersebut adalah tabel sebenarnya dalam database.
Misalnya, Anda mungkin memiliki tabel database bernama orders yang memiliki banyak kolom. Anda ingin menghitung beberapa metrik gabungan tingkat pelanggan, seperti jumlah pesanan yang dilakukan setiap pelanggan atau kapan setiap pelanggan melakukan pesanan pertama mereka. Dengan menggunakan tabel turunan native atau tabel turunan berbasis SQL, Anda dapat membuat tabel database baru bernama customer_order_summary yang mencakup metrik ini.
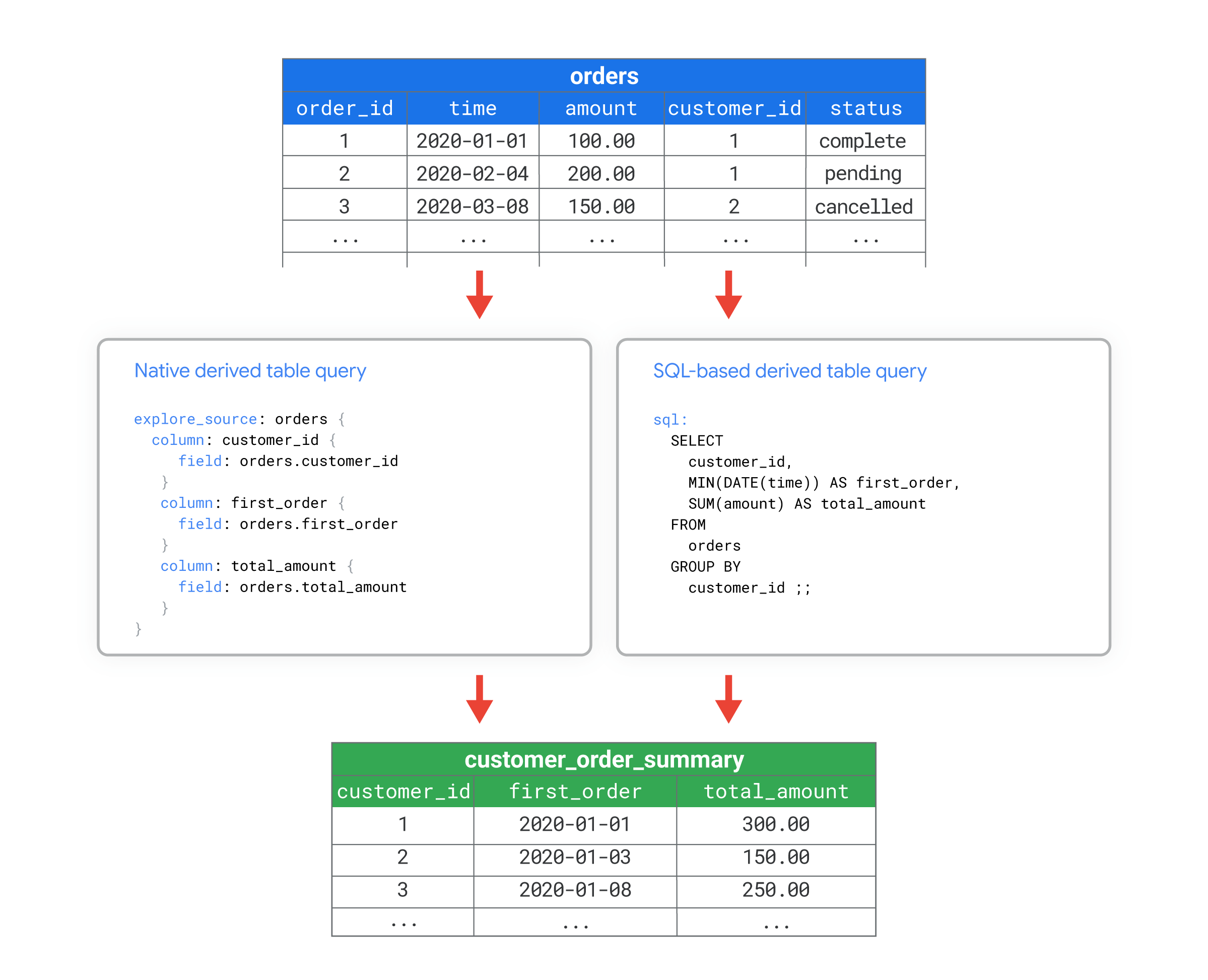
Kemudian, Anda dapat menggunakan tabel turunan customer_order_summary seolah-olah tabel tersebut adalah tabel lain dalam database.
Untuk kasus penggunaan populer tabel turunan, buka Cookbook Looker: Mendapatkan hasil maksimal dari tabel turunan di Looker.
Tabel turunan native dan tabel turunan berbasis SQL
Untuk membuat tabel turunan dalam project Looker, gunakan parameter derived_table di bawah parameter view. Di dalam parameter derived_table, Anda dapat menentukan kueri untuk tabel turunan dengan salah satu dari dua cara:
- Untuk tabel turunan native, Anda menentukan tabel turunan dengan kueri berbasis LookML.
- Untuk tabel turunan berbasis SQL, Anda menentukan tabel turunan dengan kueri SQL.
Misalnya, file tampilan berikut menunjukkan cara menggunakan LookML untuk membuat tampilan dari tabel turunan customer_order_summary. Dua versi LookML ini menunjukkan cara Anda dapat membuat tabel turunan yang setara menggunakan LookML atau SQL untuk menentukan kueri tabel turunan:
- Tabel turunan native menentukan kueri dengan LookML dalam parameter
explore_source. Dalam contoh ini, kueri didasarkan pada tampilanordersyang ada, yang ditentukan dalam file terpisah yang tidak ditampilkan dalam contoh ini. Kueriexplore_sourcedalam tabel turunan native mengambil kolomcustomer_id,first_order, dantotal_amountdari file tampilanorders. - Tabel turunan berbasis SQL menentukan kueri menggunakan SQL dalam parameter
sql. Dalam contoh ini, kueri SQL adalah kueri langsung dari tabelordersdalam database.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
Kedua versi membuat tampilan bernama customer_order_summary yang didasarkan pada tabel orders, dengan kolom customer_id, first_order,, dan total_amount.
Selain parameter derived_table dan subparameternya, tampilan customer_order_summary ini berfungsi seperti file tampilan lainnya. Baik Anda menentukan kueri tabel turunan dengan LookML atau dengan SQL, Anda dapat membuat ukuran dan dimensi LookML yang didasarkan pada kolom tabel turunan.
Setelah menentukan tabel turunan, Anda dapat menggunakannya seperti tabel lainnya dalam database.
Tabel turunan native
Tabel turunan native didasarkan pada kueri yang Anda tentukan menggunakan istilah LookML. Untuk membuat tabel turunan native, Anda menggunakan parameter explore_source di dalam parameter derived_table dari parameter view. Anda membuat kolom tabel turunan native dengan merujuk ke dimensi atau ukuran LookML dalam model Anda. Lihat file tampilan tabel turunan native dalam contoh sebelumnya.
Dibandingkan dengan tabel turunan berbasis SQL, tabel turunan native jauh lebih mudah dibaca dan dipahami saat Anda memodelkan data.
Lihat halaman dokumentasi Membuat tabel turunan native untuk mengetahui detail tentang cara membuat tabel turunan native.
Tabel turunan berbasis SQL
Untuk membuat tabel turunan berbasis SQL, Anda menentukan kueri dalam istilah SQL, membuat kolom dalam tabel menggunakan kueri SQL. Anda tidak dapat merujuk ke dimensi dan ukuran LookML dalam tabel turunan berbasis SQL. Lihat file tampilan tabel turunan berbasis SQL dalam contoh sebelumnya.
Biasanya, Anda menentukan kueri SQL menggunakan parameter sql di dalam parameter derived_table dari parameter view.
Cara pintas yang berguna untuk membuat kueri berbasis SQL di Looker adalah dengan menggunakan SQL Runner untuk membuat kueri SQL dan mengubahnya menjadi definisi tabel turunan.
Kasus ekstrem tertentu tidak akan mengizinkan penggunaan parameter sql. Dalam kasus tersebut, Looker mendukung parameter berikut untuk menentukan kueri SQL untuk tabel turunan persisten (PDT):
create_process: Saat Anda menggunakan parametersqluntuk PDT, di latar belakang Looker akan membungkus pernyataan Bahasa Definisi Data (DDL)CREATE TABLEdialek di sekitar kueri Anda untuk membuat PDT dari kueri SQL Anda. Beberapa dialek tidak mendukung pernyataan SQLCREATE TABLEdalam satu langkah. Untuk dialek ini, Anda tidak dapat membuat PDT dengan parametersql. Sebagai gantinya, Anda dapat menggunakan parametercreate_processuntuk membuat PDT dalam beberapa langkah. Lihat halaman dokumentasi parametercreate_processuntuk mengetahui informasi dan contohnya.sql_create: Jika kasus penggunaan Anda memerlukan perintah DDL kustom dan dialek Anda mendukung DDL (misalnya, BigQuery ML prediktif Google), Anda dapat menggunakan parametersql_createuntuk membuat PDT, bukan menggunakan parametersql. Lihat halaman dokumentasisql_createuntuk mengetahui informasi dan contohnya.
Baik Anda menggunakan parameter sql, create_process, atau sql_create, dalam semua kasus ini, Anda menentukan tabel turunan dengan kueri SQL, sehingga semuanya dianggap sebagai tabel turunan berbasis SQL.
Saat Anda menentukan tabel turunan berbasis SQL, pastikan untuk memberikan alias yang jelas pada setiap kolom menggunakan AS. Hal ini karena Anda harus mereferensikan nama kolom set hasil dalam dimensi, seperti ${TABLE}.first_order. Itulah sebabnya contoh sebelumnya menggunakan MIN(DATE(time)) AS first_order, bukan hanya MIN(DATE(time)).
Tabel turunan sementara dan persisten
Selain perbedaan antara tabel turunan bawaan dan tabel turunan berbasis SQL, ada juga perbedaan antara tabel turunan sementara — yang tidak ditulis ke database — dan tabel turunan persisten (PDT) — yang ditulis ke skema di database Anda.
Tabel turunan berbasis native dan tabel turunan berbasis SQL dapat bersifat sementara atau persisten.
Tabel turunan sementara
Tabel turunan yang ditampilkan sebelumnya adalah contoh tabel turunan sementara. Data ini bersifat sementara karena tidak ada strategi persistensi yang ditentukan dalam parameter derived_table.
Tabel turunan sementara tidak ditulis ke database. Saat pengguna menjalankan kueri Jelajah yang melibatkan satu atau beberapa tabel turunan, Looker membuat kueri SQL dengan menggunakan kombinasi SQL khusus dialek untuk tabel turunan ditambah kolom, gabungan, dan nilai filter yang diminta. Jika kombinasi telah dijalankan sebelumnya dan hasilnya masih valid dalam cache, Looker akan menggunakan hasil yang di-cache. Lihat halaman dokumentasi Meng-cache kueri untuk mengetahui informasi selengkapnya tentang penayangan cache kueri di Looker.
Jika tidak, jika Looker tidak dapat menggunakan hasil yang di-cache, Looker harus menjalankan kueri baru di database Anda setiap kali pengguna meminta data dari tabel turunan sementara. Oleh karena itu, Anda harus memastikan bahwa tabel turunan sementara Anda berperforma tinggi dan tidak akan membebani database Anda secara berlebihan. Jika kueri akan memerlukan waktu untuk dijalankan, PDT sering kali merupakan opsi yang lebih baik.
Dialek database yang didukung untuk tabel turunan sementara
Agar Looker mendukung tabel turunan dalam project Looker Anda, dialek database Anda juga harus mendukungnya. Tabel berikut menunjukkan dialek mana yang mendukung tabel turunan dalam rilis Looker terbaru:
Klik di sini untuk menampilkan tabel.
| Dialek | Didukung? |
|---|---|
| Actian Avalanche | Ya |
| Amazon Athena | Ya |
| Amazon Aurora MySQL | Ya |
| Amazon Redshift | Ya |
| Amazon Redshift 2.1+ | Ya |
| Amazon Redshift Serverless 2.1+ | Ya |
| Apache Druid | Ya |
| Apache Druid 0.13+ | Ya |
| Apache Druid 0.18+ | Ya |
| Apache Hive 2.3+ | Ya |
| Apache Hive 3.1.2+ | Ya |
| Apache Spark 3+ | Ya |
| ClickHouse | Ya |
| Cloudera Impala 3.1+ | Ya |
| Cloudera Impala 3.1+ with Native Driver | Ya |
| Cloudera Impala with Native Driver | Ya |
| DataVirtuality | Ya |
| Databricks | Ya |
| Denodo 7 | Ya |
| Denodo 8 & 9 | Ya |
| Dremio | Ya |
| Dremio 11+ | Ya |
| Exasol | Ya |
| Google BigQuery Legacy SQL | Ya |
| Google BigQuery Standard SQL | Ya |
| Google Cloud PostgreSQL | Ya |
| Google Cloud SQL | Ya |
| Google Spanner | Ya |
| Greenplum | Ya |
| HyperSQL | Ya |
| IBM Netezza | Ya |
| MariaDB | Ya |
| Microsoft Azure PostgreSQL | Ya |
| Microsoft Azure SQL Database | Ya |
| Microsoft Azure Synapse Analytics | Ya |
| Microsoft SQL Server 2008+ | Ya |
| Microsoft SQL Server 2012+ | Ya |
| Microsoft SQL Server 2016 | Ya |
| Microsoft SQL Server 2017+ | Ya |
| MongoBI | Ya |
| MySQL | Ya |
| MySQL 8.0.12+ | Ya |
| Oracle | Ya |
| Oracle ADWC | Ya |
| PostgreSQL 9.5+ | Ya |
| PostgreSQL pre-9.5 | Ya |
| PrestoDB | Ya |
| PrestoSQL | Ya |
| SAP HANA | Ya |
| SAP HANA 2+ | Ya |
| SingleStore | Ya |
| SingleStore 7+ | Ya |
| Snowflake | Ya |
| Teradata | Ya |
| Trino | Ya |
| Vector | Ya |
| Vertica | Ya |
Tabel turunan persisten
Tabel turunan persisten (PDT) adalah tabel turunan yang ditulis ke dalam skema sementara di database Anda dan dibuat ulang sesuai jadwal yang Anda tentukan dengan strategi persistensi.
PDT dapat berupa tabel turunan berbasis persisten atau tabel turunan berbasis SQL.
Persyaratan untuk PDT
Untuk menggunakan tabel turunan persisten (PDT) di project Looker, Anda memerlukan hal berikut:
- Dialek database yang mendukung PDT. Lihat bagian Dialek database yang didukung untuk PDT di halaman ini untuk mengetahui daftar dialek yang mendukung tabel turunan berbasis SQL persisten dan tabel turunan native persisten.
Skema sementara di database Anda. Ini dapat berupa skema apa pun di database Anda, tetapi sebaiknya buat skema baru yang hanya akan digunakan untuk tujuan ini. Administrator database Anda harus mengonfigurasi skema dengan izin tulis untuk pengguna database Looker.
Koneksi Looker yang dikonfigurasi dengan tombol Aktifkan PDT diaktifkan. Setelan Aktifkan PDT ini biasanya dikonfigurasi saat Anda pertama kali menyiapkan koneksi Looker (lihat halaman dokumentasi dialek Looker untuk mengetahui petunjuk dialek database Anda), tetapi Anda juga dapat mengaktifkan PDT untuk koneksi setelah penyiapan awal.
Dialek database yang didukung untuk PDT
Agar Looker mendukung PDT di project Looker Anda, dialek database Anda juga harus mendukungnya.
Untuk mendukung semua jenis PDT (berbasis LookML atau berbasis SQL), dialek harus mendukung penulisan ke database, di antara persyaratan lainnya. Ada beberapa konfigurasi database hanya baca yang tidak mengizinkan persistensi berfungsi (paling umum adalah database replika hot-swap Postgres). Dalam kasus ini, Anda dapat menggunakan tabel turunan sementara sebagai gantinya.
Tabel berikut menunjukkan dialek yang mendukung tabel turunan berbasis SQL persisten dalam rilis terbaru Looker:
Klik di sini untuk menampilkan tabel.
| Dialek | Didukung? |
|---|---|
| Actian Avalanche | Ya |
| Amazon Athena | Ya |
| Amazon Aurora MySQL | Ya |
| Amazon Redshift | Ya |
| Amazon Redshift 2.1+ | Ya |
| Amazon Redshift Serverless 2.1+ | Ya |
| Apache Druid | Tidak |
| Apache Druid 0.13+ | Tidak |
| Apache Druid 0.18+ | Tidak |
| Apache Hive 2.3+ | Ya |
| Apache Hive 3.1.2+ | Ya |
| Apache Spark 3+ | Ya |
| ClickHouse | Tidak |
| Cloudera Impala 3.1+ | Ya |
| Cloudera Impala 3.1+ with Native Driver | Ya |
| Cloudera Impala with Native Driver | Ya |
| DataVirtuality | Tidak |
| Databricks | Ya |
| Denodo 7 | Tidak |
| Denodo 8 & 9 | Tidak |
| Dremio | Tidak |
| Dremio 11+ | Tidak |
| Exasol | Ya |
| Google BigQuery Legacy SQL | Ya |
| Google BigQuery Standard SQL | Ya |
| Google Cloud PostgreSQL | Ya |
| Google Cloud SQL | Ya |
| Google Spanner | Tidak |
| Greenplum | Ya |
| HyperSQL | Tidak |
| IBM Netezza | Ya |
| MariaDB | Ya |
| Microsoft Azure PostgreSQL | Ya |
| Microsoft Azure SQL Database | Ya |
| Microsoft Azure Synapse Analytics | Ya |
| Microsoft SQL Server 2008+ | Ya |
| Microsoft SQL Server 2012+ | Ya |
| Microsoft SQL Server 2016 | Ya |
| Microsoft SQL Server 2017+ | Ya |
| MongoBI | Tidak |
| MySQL | Ya |
| MySQL 8.0.12+ | Ya |
| Oracle | Ya |
| Oracle ADWC | Ya |
| PostgreSQL 9.5+ | Ya |
| PostgreSQL pre-9.5 | Ya |
| PrestoDB | Ya |
| PrestoSQL | Ya |
| SAP HANA | Ya |
| SAP HANA 2+ | Ya |
| SingleStore | Ya |
| SingleStore 7+ | Ya |
| Snowflake | Ya |
| Teradata | Ya |
| Trino | Ya |
| Vector | Ya |
| Vertica | Ya |
Untuk mendukung tabel turunan native persisten (yang memiliki kueri berbasis LookML), dialek juga harus mendukung fungsi DDL CREATE TABLE. Berikut adalah daftar dialek yang mendukung tabel turunan berbasis native (LookML) persisten dalam rilis Looker terbaru:
Klik di sini untuk menampilkan tabel.
| Dialek | Didukung? |
|---|---|
| Actian Avalanche | Ya |
| Amazon Athena | Ya |
| Amazon Aurora MySQL | Ya |
| Amazon Redshift | Ya |
| Amazon Redshift 2.1+ | Ya |
| Amazon Redshift Serverless 2.1+ | Ya |
| Apache Druid | Tidak |
| Apache Druid 0.13+ | Tidak |
| Apache Druid 0.18+ | Tidak |
| Apache Hive 2.3+ | Ya |
| Apache Hive 3.1.2+ | Ya |
| Apache Spark 3+ | Ya |
| ClickHouse | Tidak |
| Cloudera Impala 3.1+ | Ya |
| Cloudera Impala 3.1+ with Native Driver | Ya |
| Cloudera Impala with Native Driver | Ya |
| DataVirtuality | Tidak |
| Databricks | Ya |
| Denodo 7 | Tidak |
| Denodo 8 & 9 | Tidak |
| Dremio | Tidak |
| Dremio 11+ | Tidak |
| Exasol | Ya |
| Google BigQuery Legacy SQL | Ya |
| Google BigQuery Standard SQL | Ya |
| Google Cloud PostgreSQL | Ya |
| Google Cloud SQL | Tidak |
| Google Spanner | Tidak |
| Greenplum | Ya |
| HyperSQL | Tidak |
| IBM Netezza | Ya |
| MariaDB | Ya |
| Microsoft Azure PostgreSQL | Ya |
| Microsoft Azure SQL Database | Ya |
| Microsoft Azure Synapse Analytics | Ya |
| Microsoft SQL Server 2008+ | Ya |
| Microsoft SQL Server 2012+ | Ya |
| Microsoft SQL Server 2016 | Ya |
| Microsoft SQL Server 2017+ | Ya |
| MongoBI | Tidak |
| MySQL | Ya |
| MySQL 8.0.12+ | Ya |
| Oracle | Ya |
| Oracle ADWC | Ya |
| PostgreSQL 9.5+ | Ya |
| PostgreSQL pre-9.5 | Ya |
| PrestoDB | Ya |
| PrestoSQL | Ya |
| SAP HANA | Ya |
| SAP HANA 2+ | Ya |
| SingleStore | Ya |
| SingleStore 7+ | Ya |
| Snowflake | Ya |
| Teradata | Ya |
| Trino | Ya |
| Vector | Ya |
| Vertica | Ya |
Membangun PDT secara inkremental
PDT inkremental adalah tabel turunan persisten yang dibuat Looker dengan menambahkan data baru ke tabel, bukan membangunnya kembali secara keseluruhan.
Jika dialek Anda mendukung PDT inkremental, dan PDT Anda menggunakan strategi persistensi berbasis pemicu (datagroup_trigger, sql_trigger_value, atau interval_trigger), Anda dapat menentukan PDT sebagai PDT inkremental.
Lihat halaman dokumentasi PDT Inkremental untuk mengetahui informasi selengkapnya.
Dialek database yang didukung untuk PDT inkremental
Agar Looker mendukung PDT inkremental di project Looker Anda, dialek database Anda juga harus mendukungnya. Tabel berikut menunjukkan dialek mana yang mendukung PDT inkremental dalam rilis Looker terbaru:
Klik di sini untuk menampilkan tabel.
| Dialek | Didukung? |
|---|---|
| Actian Avalanche | Tidak |
| Amazon Athena | Tidak |
| Amazon Aurora MySQL | Tidak |
| Amazon Redshift | Ya |
| Amazon Redshift 2.1+ | Ya |
| Amazon Redshift Serverless 2.1+ | Ya |
| Apache Druid | Tidak |
| Apache Druid 0.13+ | Tidak |
| Apache Druid 0.18+ | Tidak |
| Apache Hive 2.3+ | Tidak |
| Apache Hive 3.1.2+ | Tidak |
| Apache Spark 3+ | Tidak |
| ClickHouse | Tidak |
| Cloudera Impala 3.1+ | Tidak |
| Cloudera Impala 3.1+ with Native Driver | Tidak |
| Cloudera Impala with Native Driver | Tidak |
| DataVirtuality | Tidak |
| Databricks | Ya |
| Denodo 7 | Tidak |
| Denodo 8 & 9 | Tidak |
| Dremio | Tidak |
| Dremio 11+ | Tidak |
| Exasol | Tidak |
| Google BigQuery Legacy SQL | Tidak |
| Google BigQuery Standard SQL | Ya |
| Google Cloud PostgreSQL | Ya |
| Google Cloud SQL | Tidak |
| Google Spanner | Tidak |
| Greenplum | Ya |
| HyperSQL | Tidak |
| IBM Netezza | Tidak |
| MariaDB | Tidak |
| Microsoft Azure PostgreSQL | Ya |
| Microsoft Azure SQL Database | Tidak |
| Microsoft Azure Synapse Analytics | Ya |
| Microsoft SQL Server 2008+ | Tidak |
| Microsoft SQL Server 2012+ | Tidak |
| Microsoft SQL Server 2016 | Tidak |
| Microsoft SQL Server 2017+ | Tidak |
| MongoBI | Tidak |
| MySQL | Ya |
| MySQL 8.0.12+ | Ya |
| Oracle | Tidak |
| Oracle ADWC | Tidak |
| PostgreSQL 9.5+ | Ya |
| PostgreSQL pre-9.5 | Ya |
| PrestoDB | Tidak |
| PrestoSQL | Tidak |
| SAP HANA | Tidak |
| SAP HANA 2+ | Tidak |
| SingleStore | Tidak |
| SingleStore 7+ | Tidak |
| Snowflake | Ya |
| Teradata | Tidak |
| Trino | Tidak |
| Vector | Tidak |
| Vertica | Ya |
Membuat PDT
Untuk mengubah tabel turunan menjadi tabel turunan persisten (PDT), Anda menentukan strategi persistensi untuk tabel tersebut. Untuk mengoptimalkan performa, Anda juga harus menambahkan strategi pengoptimalan.
Strategi persistensi
Persistensi tabel turunan dapat dikelola oleh Looker atau, untuk dialek yang mendukung tampilan terwujud, oleh database Anda menggunakan tampilan terwujud.
Untuk membuat tabel turunan tetap ada, tambahkan salah satu parameter berikut ke definisi derived_table:
- Parameter persistensi yang dikelola Looker:
- Parameter persistensi yang dikelola database:
Dengan strategi persistensi berbasis pemicu (datagroup_trigger, sql_trigger_value, dan interval_trigger), Looker mempertahankan PDT di database hingga PDT dipicu untuk dibangun ulang. Saat PDT dipicu, Looker akan membangun ulang PDT untuk menggantikan versi sebelumnya. Artinya, dengan PDT berbasis pemicu, pengguna Anda tidak perlu menunggu PDT dibuat untuk mendapatkan jawaban atas kueri Jelajah dari PDT.
datagroup_trigger
Grup data adalah metode paling fleksibel untuk membuat persistensi. Jika telah menentukan datagroup dengan sql_trigger atau interval_trigger, Anda dapat menggunakan parameter datagroup_trigger untuk memulai pembangunan ulang tabel turunan persisten (PDT).
Looker mempertahankan PDT dalam database hingga grup datanya dipicu. Saat grup data dipicu, Looker akan membangun ulang PDT untuk menggantikan versi sebelumnya. Artinya, dalam sebagian besar kasus, pengguna Anda tidak perlu menunggu PDT dibuat. Jika pengguna meminta data dari PDT saat sedang dibuat dan hasil kueri tidak ada dalam cache, Looker akan menampilkan data dari PDT yang ada hingga PDT baru dibuat. Lihat Meng-cache kueri untuk mengetahui ringkasan grup data.
Lihat bagian tentang Regenerator Looker untuk mengetahui informasi selengkapnya tentang cara regenerator membangun PDT.
sql_trigger_value
Parameter sql_trigger_value memicu regenerasi tabel turunan persisten (PDT) yang didasarkan pada pernyataan SQL yang Anda berikan. Jika hasil pernyataan SQL berbeda dari nilai sebelumnya, PDT akan dibuat ulang. Jika tidak, PDT yang ada akan dipertahankan dalam database. Artinya, dalam sebagian besar kasus, pengguna Anda tidak perlu menunggu PDT dibuat. Jika pengguna meminta data dari PDT saat sedang dibuat, dan hasil kueri tidak ada dalam cache, Looker akan menampilkan data dari PDT yang ada hingga PDT baru dibuat.
Lihat bagian tentang Regenerator Looker untuk mengetahui informasi selengkapnya tentang cara regenerator membangun PDT.
interval_trigger
Parameter interval_trigger memicu regenerasi tabel turunan persisten (PDT) berdasarkan interval waktu yang Anda berikan, seperti "24 hours" atau "60 minutes". Mirip dengan parameter sql_trigger, ini berarti PDT biasanya akan dibuat sebelumnya saat pengguna Anda mengkuerinya. Jika pengguna meminta data dari PDT saat sedang dibuat, dan hasil kueri tidak ada dalam cache, Looker akan menampilkan data dari PDT yang ada hingga PDT baru dibuat.
persist_for
Opsi lainnya adalah menggunakan parameter persist_for untuk menetapkan jangka waktu tabel turunan harus disimpan sebelum ditandai sebagai habis masa berlaku, sehingga tidak lagi digunakan untuk kueri dan akan dihapus dari database.
Tabel turunan persisten (PDT) persist_for dibuat saat pengguna pertama kali menjalankan kueri di dalamnya. Kemudian, Looker mempertahankan PDT dalam database selama jangka waktu yang ditentukan dalam parameter persist_for PDT. Jika pengguna membuat kueri PDT dalam waktu persist_for, Looker akan menggunakan hasil yang di-cache jika memungkinkan atau menjalankan kueri pada PDT.
Setelah waktu persist_for, Looker akan menghapus PDT dari database Anda, dan PDT akan dibangun ulang saat pengguna berikutnya membuat kueri, yang berarti kueri harus menunggu pembangunan ulang.
PDT yang menggunakan persist_for tidak otomatis dibangun ulang oleh regenerator Looker, kecuali dalam kasus cascade dependensi PDT. Jika tabel persist_for adalah bagian dari rangkaian dependensi dengan PDT berbasis pemicu (PDT yang menggunakan strategi persistensi datagroup_trigger, interval_trigger, atau sql_trigger_value), regenerator akan memantau dan membangun ulang tabel persist_for untuk membangun ulang tabel lain dalam rangkaian. Lihat bagian Cara Looker membuat tabel turunan bertingkat di halaman ini.
materialized_view: yes
Tampilan terwujud memungkinkan Anda menggunakan fungsi database untuk mempertahankan tabel turunan dalam project Looker. Jika dialek database Anda mendukung tampilan terwujud dan koneksi Looker Anda dikonfigurasi dengan tombol Aktifkan PDT diaktifkan, Anda dapat membuat tampilan terwujud dengan menentukan materialized_view: yes untuk tabel turunan. Tampilan terwujud didukung untuk tabel turunan bawaan dan tabel turunan berbasis SQL.
Mirip dengan tabel turunan persisten (PDT), tampilan terwujud adalah hasil kueri yang disimpan sebagai tabel dalam skema sementara database Anda. Perbedaan utama antara PDT dan tampilan terwujud adalah cara tabel diperbarui:
- Untuk PDT, strategi persistensi ditentukan di Looker, dan persistensi dikelola oleh Looker.
- Untuk tampilan terwujud, database bertanggung jawab untuk mengelola dan memperbarui data dalam tabel.
Oleh karena itu, fungsi tampilan terwujud memerlukan pengetahuan lanjutan tentang dialek Anda dan fiturnya. Dalam sebagian besar kasus, database Anda akan memperbarui tampilan terwujud setiap kali database mendeteksi data baru dalam tabel yang dikueri oleh tampilan terwujud. Tampilan terwujud sangat optimal untuk skenario yang memerlukan data real-time.
Lihat halaman dokumentasi parameter materialized_view untuk mengetahui informasi tentang dukungan dialek, persyaratan, dan pertimbangan penting.
Strategi pengoptimalan
Karena tabel turunan persisten (PDT) disimpan di database, Anda harus mengoptimalkan PDT menggunakan strategi berikut, sebagaimana didukung oleh dialek Anda:
Misalnya, untuk menambahkan persistensi ke contoh tabel turunan, Anda dapat menyetelnya untuk dibangun ulang saat pemicu grup data orders_datagroup, dan menambahkan indeks pada customer_id dan first_order, seperti ini:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Jika Anda tidak menambahkan indeks (atau yang setara untuk dialek Anda), Looker akan memperingatkan Anda bahwa Anda harus melakukannya untuk meningkatkan performa kueri.
Kasus penggunaan untuk PDT
Tabel turunan persisten (PDT) berguna karena dapat meningkatkan performa kueri dengan mempertahankan hasil kueri dalam tabel.
Sebagai praktik terbaik umum, developer harus mencoba membuat model data tanpa menggunakan PDT kecuali jika benar-benar diperlukan.
Dalam beberapa kasus, data dapat dioptimalkan melalui cara lain. Misalnya, menambahkan indeks atau mengubah jenis data kolom dapat menyelesaikan masalah tanpa perlu membuat PDT. Pastikan untuk menganalisis rencana eksekusi kueri lambat menggunakan alat Explain dari SQL Runner.
Selain mengurangi waktu kueri dan beban database pada kueri yang sering dijalankan, ada beberapa kasus penggunaan lain untuk PDT, termasuk:
Anda juga dapat menggunakan PDT untuk menentukan kunci utama jika tidak ada cara yang wajar untuk mengidentifikasi baris unik dalam tabel sebagai kunci utama.
Menggunakan PDT untuk menguji pengoptimalan
Anda dapat menggunakan PDT untuk menguji berbagai opsi pengindeksan, distribusi, dan pengoptimalan lainnya tanpa memerlukan banyak dukungan dari DBA atau developer ETL.
Pertimbangkan kasus saat Anda memiliki tabel, tetapi ingin menguji indeks yang berbeda. LookML awal Anda untuk tampilan mungkin terlihat seperti berikut:
view: customer {
sql_table_name: warehouse.customer ;;
}
Untuk menguji strategi pengoptimalan, Anda dapat menggunakan parameter indexes untuk menambahkan indeks ke LookML seperti ini:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Buat kueri tampilan sekali untuk membuat PDT. Kemudian, jalankan kueri pengujian dan bandingkan hasilnya. Jika hasilnya menguntungkan, Anda dapat meminta tim DBA atau ETL untuk menambahkan indeks ke tabel asli.
Jangan lupa untuk mengubah kode tampilan Anda kembali untuk menghapus PDT.
Menggunakan PDT untuk menggabungkan atau mengagregasi data sebelumnya
Berguna untuk menggabungkan atau menggabungkan data sebelumnya guna menyesuaikan pengoptimalan kueri untuk volume tinggi atau beberapa jenis data.
Misalnya, Anda ingin membuat kueri untuk pelanggan menurut kelompok berdasarkan waktu mereka melakukan pesanan pertama. Kueri ini mungkin mahal untuk dijalankan beberapa kali setiap kali data diperlukan secara real time; namun, Anda dapat menghitung kueri hanya sekali, lalu menggunakan kembali hasilnya dengan PDT:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Mengelompokkan tabel turunan
Anda dapat mereferensikan satu tabel turunan dalam definisi tabel turunan lainnya, sehingga membuat rangkaian tabel turunan bertingkat, atau tabel turunan persisten (PDT) bertingkat, bergantung pada kasusnya. Contoh tabel turunan bertingkat adalah tabel, TABLE_D, yang bergantung pada tabel lain, TABLE_C, sementara TABLE_C bergantung pada TABLE_B, dan TABLE_B bergantung pada TABLE_A.
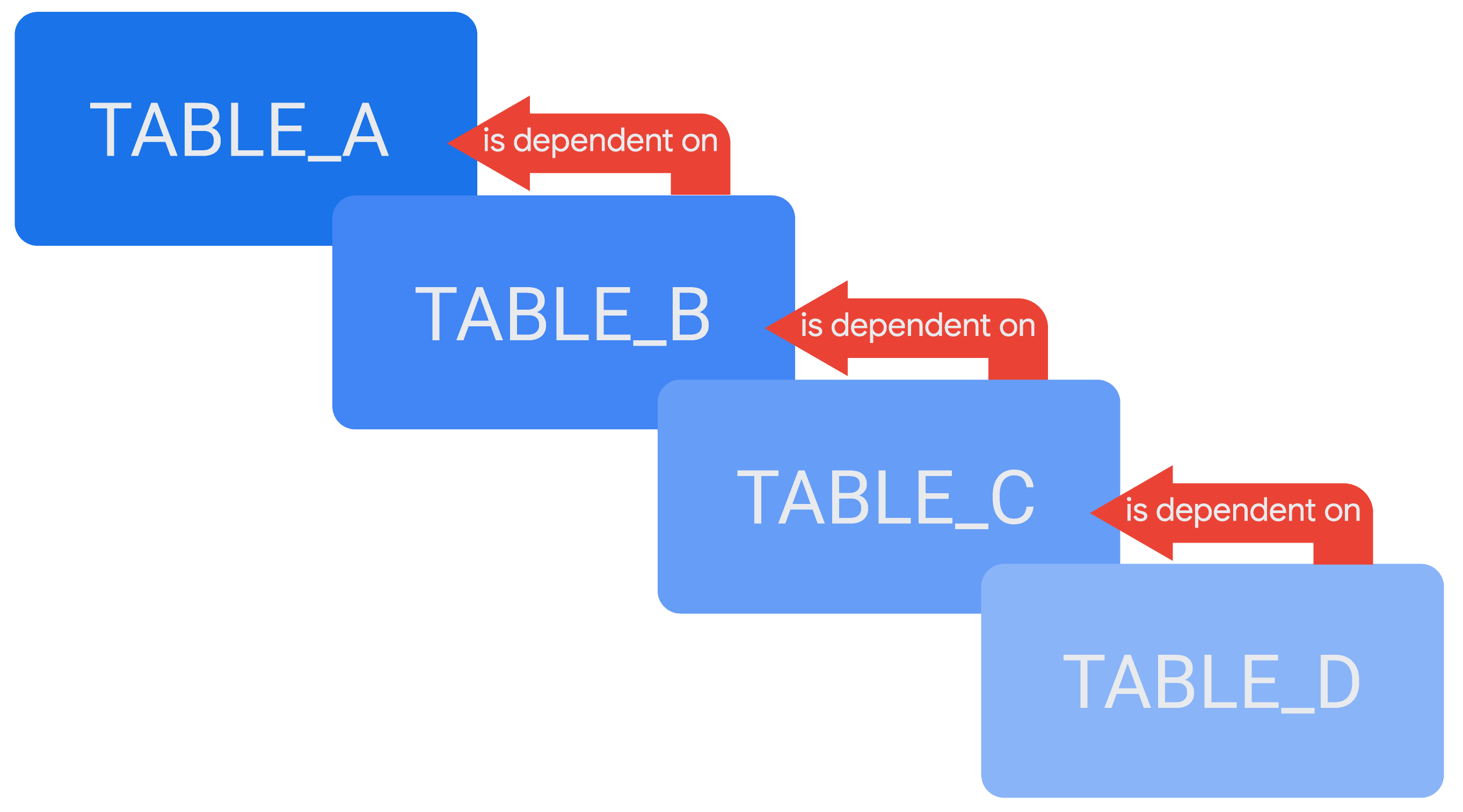
Sintaksis untuk merujuk tabel turunan
Untuk merujuk tabel turunan dalam tabel turunan lain, gunakan sintaksis ini:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
Dalam format ini, SQL_TABLE_NAME adalah string literal. Misalnya, Anda dapat mereferensikan tabel turunan clean_events dengan sintaksis ini:
`${clean_events.SQL_TABLE_NAME}`
Anda dapat menggunakan sintaksis yang sama ini untuk merujuk ke tampilan LookML. Sekali lagi, dalam kasus ini, SQL_TABLE_NAME adalah string literal.
Dalam contoh berikutnya, PDT clean_events dibuat dari tabel events dalam database. clean_events PDT menghilangkan baris yang tidak diinginkan dari tabel database events. Kemudian, PDT kedua ditampilkan; PDT event_summary adalah ringkasan PDT clean_events. Tabel event_summary dibuat ulang setiap kali baris baru ditambahkan ke clean_events.
event_summary PDT dan clean_events PDT adalah PDT bertingkat, dengan event_summary bergantung pada clean_events (karena event_summary ditentukan menggunakan clean_events PDT). Contoh khusus ini dapat dilakukan secara lebih efisien dalam satu PDT, tetapi berguna untuk mendemonstrasikan referensi tabel turunan.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Meskipun tidak selalu diperlukan, saat Anda merujuk ke tabel turunan dengan cara ini, sering kali berguna untuk membuat alias untuk tabel dengan menggunakan format ini:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
Contoh sebelumnya melakukan hal ini:
${clean_events.SQL_TABLE_NAME} AS clean_events
Sebaiknya gunakan alias karena, di balik layar, PDT diberi nama dengan kode panjang di database Anda. Dalam beberapa kasus (terutama dengan klausa ON), Anda mungkin lupa bahwa Anda perlu menggunakan sintaksis ${derived_table_or_view_name.SQL_TABLE_NAME} untuk mengambil nama yang panjang ini. Alias dapat membantu mencegah kesalahan jenis ini.
Cara Looker membuat tabel turunan bertingkat
Dalam kasus tabel turunan sementara bertingkat, jika hasil kueri pengguna tidak ada dalam cache, Looker akan membuat semua tabel turunan yang diperlukan untuk kueri. Jika Anda memiliki TABLE_D yang definisinya berisi referensi ke TABLE_C, maka TABLE_D bergantung pada TABLE_C. Artinya, jika Anda membuat kueri TABLE_D dan kueri tersebut tidak ada di cache Looker, Looker akan membangun ulang TABLE_D. Namun, TABLE_C harus dibangun ulang terlebih dahulu.
Pertimbangkan skenario dengan tabel turunan sementara bertingkat, di mana TABLE_D bergantung pada TABLE_C, yang bergantung pada TABLE_B, yang bergantung pada TABLE_A. Jika Looker tidak memiliki hasil yang valid untuk kueri di TABLE_C dalam cache, Looker akan membuat semua tabel yang diperlukan untuk kueri tersebut. Jadi, Looker akan membuat TABLE_A, lalu TABLE_B, lalu TABLE_C:
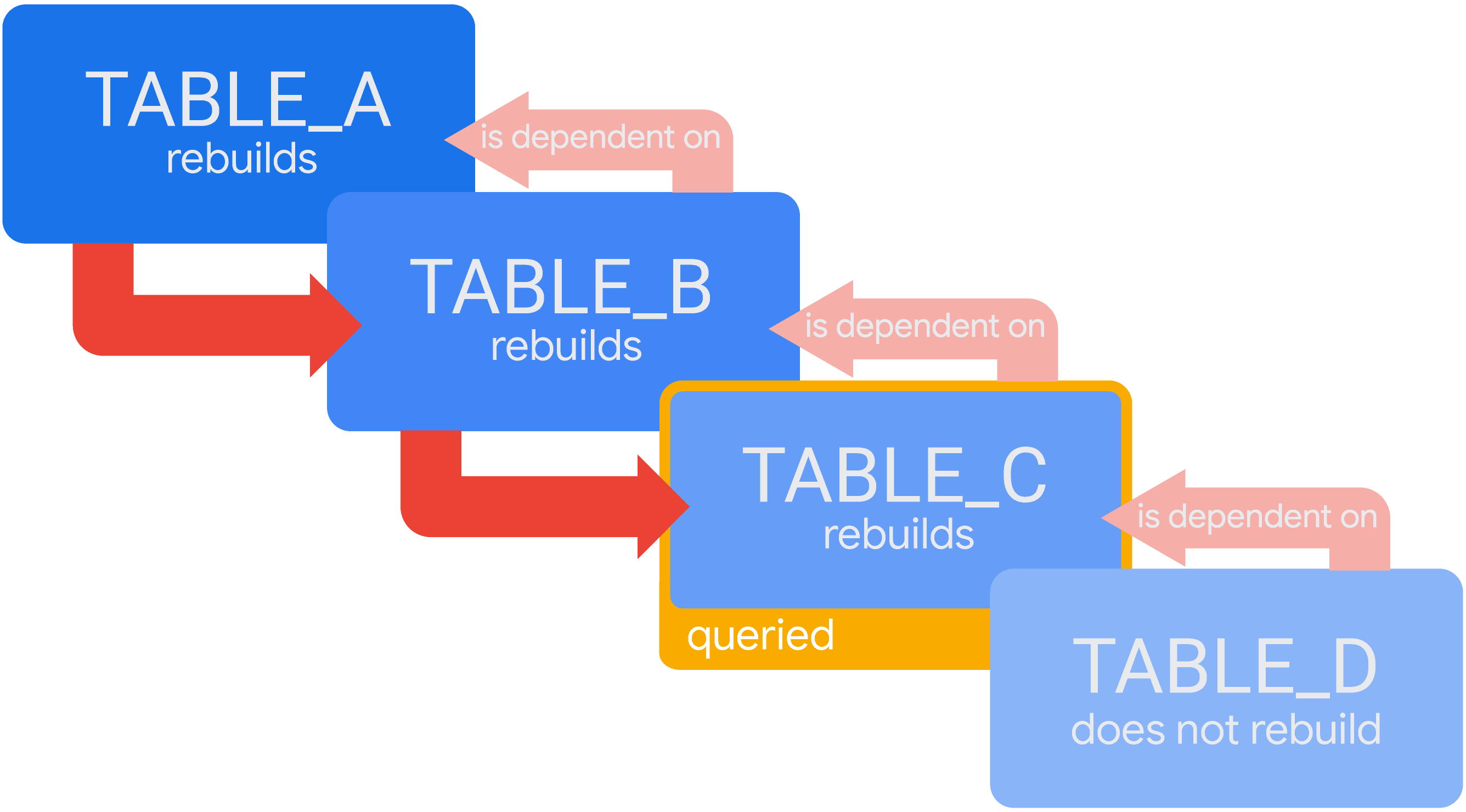
Dalam skenario ini, TABLE_A harus selesai dibuat sebelum Looker dapat mulai membuat TABLE_B, dan TABLE_B harus selesai dibuat sebelum Looker dapat mulai membuat TABLE_C. Setelah TABLE_C selesai, Looker akan memberikan hasil kueri. (Karena TABLE_D tidak diperlukan untuk menjawab kueri ini, Looker tidak akan membangun ulang TABLE_D saat ini.)
Lihat halaman dokumentasi parameter datagroup untuk contoh skenario PDT bertingkat yang menggunakan grup data yang sama.
Logika dasar yang sama berlaku untuk PDT: Looker akan membuat tabel apa pun yang diperlukan untuk menjawab kueri, hingga ke seluruh rantai dependensi. Namun, dengan PDT, sering kali tabel sudah ada dan tidak perlu dibangun ulang. Dengan kueri pengguna standar pada PDT bertingkat, Looker membangun ulang PDT dalam tingkatan hanya jika tidak ada versi PDT yang valid dalam database. Jika ingin memaksa pembangunan ulang untuk semua PDT dalam cascade, Anda dapat membangun ulang tabel secara manual untuk kueri melalui Eksplorasi.
Poin logis penting yang perlu dipahami adalah bahwa dalam kasus rangkaian PDT, PDT dependen pada dasarnya mengirimkan kueri ke PDT yang menjadi dependensinya. Hal ini sangat penting terutama untuk PDT yang menggunakan strategi persist_for. Biasanya, PDT persist_for dibuat saat pengguna membuat kueri, tetap berada di database hingga interval persist_for berakhir, lalu tidak dibuat ulang hingga kueri berikutnya dibuat oleh pengguna. Namun, jika persist_for PDT adalah bagian dari cascade dengan PDT berbasis pemicu (PDT yang menggunakan strategi persistensi datagroup_trigger, interval_trigger, atau sql_trigger_value), persist_for PDT pada dasarnya dikueri setiap kali PDT dependennya dibangun ulang. Jadi, dalam hal ini, persist_for PDT akan dibangun ulang sesuai jadwal PDT dependennya. Artinya, PDT persist_for dapat terpengaruh oleh strategi persistensi elemen dependennya.
Membangun ulang tabel persisten secara manual untuk kueri
Pengguna dapat memilih opsi Bangun Ulang Tabel Turunan & Jalankan dari menu Jelajah untuk mengganti setelan persistensi dan membangun ulang semua tabel turunan persisten (PDT) dan tabel gabungan yang diperlukan untuk kueri saat ini di Jelajah:
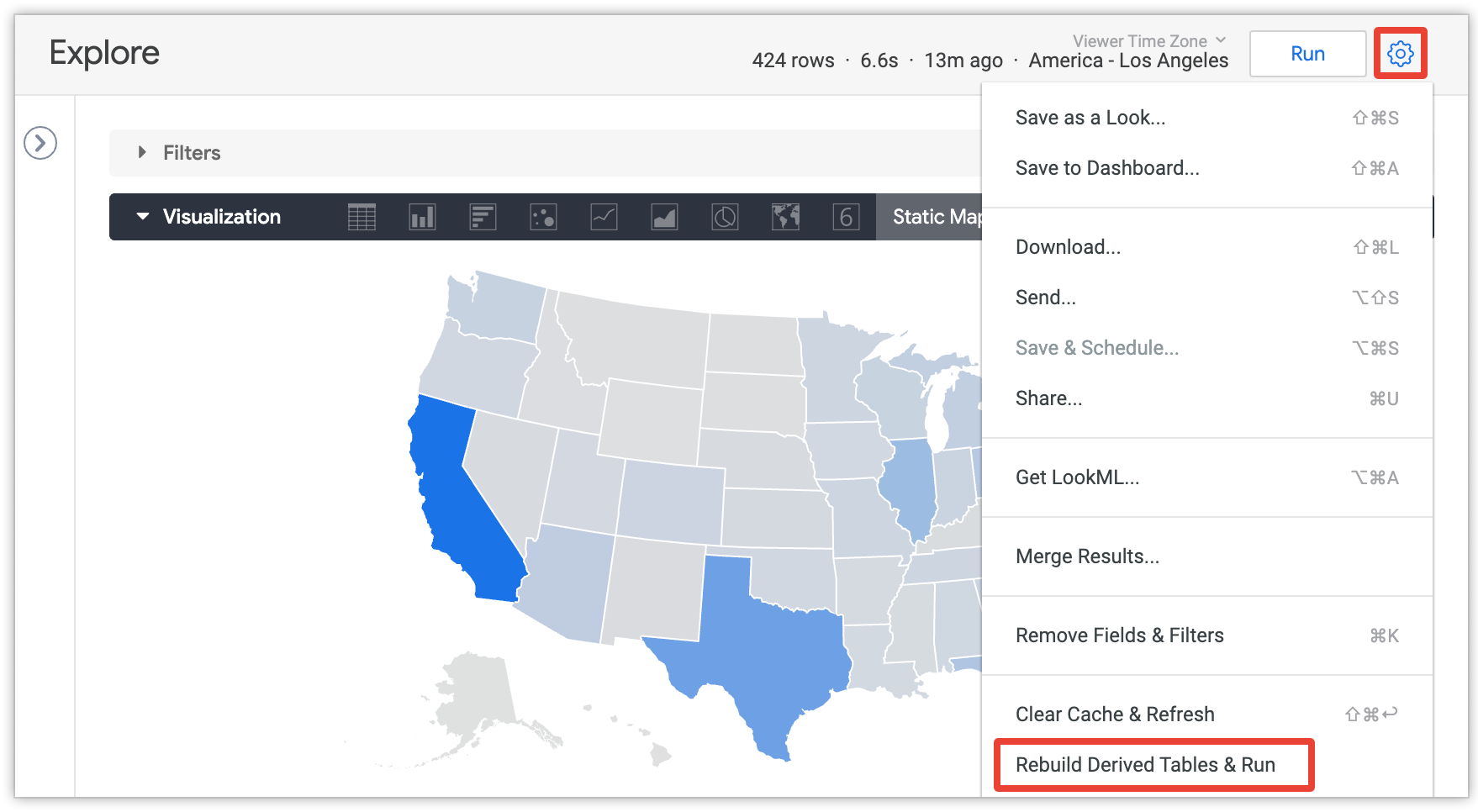
Opsi ini hanya terlihat oleh pengguna dengan izin develop, dan hanya setelah kueri Jelajah dimuat.
Opsi Bangun Ulang Tabel Turunan & Jalankan membangun ulang semua tabel persisten (semua PDT dan tabel gabungan) yang diperlukan untuk menjawab kueri, terlepas dari strategi persistennya. Hal ini mencakup semua tabel gabungan dan PDT dalam kueri saat ini, serta semua tabel gabungan dan PDT yang dirujuk oleh tabel gabungan dan PDT dalam kueri saat ini.
Dalam kasus PDT inkremental, opsi Bangun Ulang Tabel Turunan & Jalankan memicu pembangunan inkremen baru. Dengan PDT inkremental, inkremen mencakup jangka waktu yang ditentukan dalam parameter increment_key, dan juga jumlah jangka waktu sebelumnya yang ditentukan dalam parameter increment_offset, jika ada. Lihat halaman dokumentasi PDT Inkremental untuk beberapa contoh skenario yang menunjukkan cara pembuatan PDT inkremental, bergantung pada konfigurasinya.
Dalam kasus PDT bertingkat, ini berarti membangun ulang semua tabel turunan dalam tingkatan, dimulai dari atas. Perilaku ini sama seperti saat Anda membuat kueri tabel dalam deretan tabel turunan sementara:
Perhatikan hal-hal berikut terkait membangun ulang tabel turunan secara manual:
- Untuk pengguna yang memulai operasi Bangun Ulang & Jalankan Tabel Turunan, kueri akan menunggu hingga tabel dibangun ulang sebelum memuat hasil. Kueri pengguna lain akan tetap menggunakan tabel yang ada. Setelah tabel persisten dibangun ulang, semua pengguna akan menggunakan tabel yang dibangun ulang. Meskipun proses ini dirancang untuk menghindari gangguan pada kueri pengguna lain saat tabel dibuat ulang, pengguna tersebut masih dapat terpengaruh oleh beban tambahan pada database Anda. Jika Anda berada dalam situasi di mana pemicuan pembangunan ulang selama jam kerja dapat memberikan tekanan yang tidak dapat diterima pada database, Anda mungkin perlu memberi tahu pengguna bahwa mereka tidak boleh membangun ulang PDT atau tabel gabungan tertentu selama jam tersebut.
Jika pengguna berada dalam Mode Pengembangan dan Eksplorasi didasarkan pada tabel pengembangan, operasi Bangun Ulang Tabel Turunan & Jalankan akan membangun ulang tabel pengembangan, bukan tabel produksi, untuk Eksplorasi. Namun, jika Jelajahi dalam Mode Pengembangan menggunakan versi produksi tabel turunan, tabel produksi akan dibangun ulang. Lihat Tabel persisten dalam Mode Pengembangan untuk mengetahui informasi tentang tabel pengembangan dan tabel produksi.
Untuk instance yang dihosting Looker, jika tabel turunan memerlukan waktu lebih dari satu jam untuk dibangun ulang, tabel tidak akan berhasil dibangun ulang dan sesi browser akan berakhir. Lihat bagian Waktu tunggu dan antrean kueri di halaman dokumentasi Setelan admin - Kueri untuk mengetahui informasi selengkapnya tentang waktu tunggu yang dapat memengaruhi proses Looker.
Tabel yang dipertahankan dalam Mode Pengembangan
Looker memiliki beberapa perilaku khusus untuk mengelola tabel persisten dalam Mode Pengembangan.
Jika Anda membuat kueri tabel yang dipertahankan dalam Mode Pengembangan tanpa membuat perubahan apa pun pada definisinya, Looker akan membuat kueri versi produksi tabel tersebut. Jika Anda melakukan perubahan pada definisi tabel yang memengaruhi data dalam tabel atau cara kueri tabel, versi pengembangan baru tabel akan dibuat saat Anda membuat kueri tabel dalam Mode Pengembangan. Dengan memiliki tabel pengembangan seperti itu, Anda dapat menguji perubahan tanpa mengganggu pengguna.
Yang memicu Looker membuat tabel pengembangan
Jika memungkinkan, Looker menggunakan tabel produksi yang ada untuk menjawab kueri, baik Anda berada dalam Mode Pengembangan atau tidak. Namun, ada kasus tertentu saat Looker tidak dapat menggunakan tabel produksi untuk kueri dalam Mode Pengembangan:
- Jika tabel persisten Anda memiliki parameter yang mempersempit set datanya agar bekerja lebih cepat dalam Mode Pengembangan
- Jika Anda telah membuat perubahan pada definisi tabel persisten yang memengaruhi data dalam tabel
Looker akan membuat tabel pengembangan jika Anda berada dalam Mode Pengembangan dan Anda membuat kueri tabel turunan berbasis SQL yang ditentukan menggunakan klausa WHERE bersyarat dengan pernyataan if prod dan if dev.
Untuk tabel persisten yang tidak memiliki parameter untuk mempersempit set data dalam Mode Pengembangan, Looker menggunakan versi produksi tabel untuk menjawab kueri dalam Mode Pengembangan, kecuali jika Anda mengubah definisi tabel dan kemudian membuat kueri tabel dalam Mode Pengembangan. Hal ini berlaku untuk setiap perubahan pada tabel yang memengaruhi data dalam tabel atau cara kueri tabel.
Berikut beberapa contoh jenis perubahan yang akan memicu Looker membuat versi pengembangan tabel persisten (Looker akan membuat tabel hanya jika Anda selanjutnya membuat kueri tabel setelah melakukan perubahan ini):
- Mengubah kueri yang menjadi dasar tabel persisten, seperti mengubah parameter
explore_source,sql,query,sql_create, ataucreate_processdalam tabel persisten itu sendiri, atau dalam tabel yang diperlukan (dalam kasus tabel turunan bertingkat) - Mengubah strategi persistensi tabel, seperti mengubah parameter
datagroup_trigger,sql_trigger_value,interval_trigger, ataupersist_fortabel - Mengubah nama
viewtabel turunan - Mengubah
increment_keyatauincrement_offsetPDT inkremental - Mengubah
connectionyang digunakan oleh model terkait
Untuk perubahan yang tidak mengubah data tabel atau memengaruhi cara Looker membuat kueri tabel, Looker tidak akan membuat tabel pengembangan. Parameter publish_as_db_view adalah contoh yang baik: Dalam Mode Pengembangan, jika Anda hanya mengubah setelan publish_as_db_view untuk tabel turunan, Looker tidak perlu membangun kembali tabel turunan sehingga tidak akan membuat tabel pengembangan.
Durasi Looker mempertahankan tabel pengembangan
Terlepas dari strategi persistensi tabel yang sebenarnya, Looker memperlakukan tabel yang dipertahankan pengembangan seolah-olah memiliki strategi persistensi persist_for: "24 hours". Looker melakukan hal ini untuk memastikan bahwa tabel pengembangan tidak dipertahankan selama lebih dari satu hari, karena developer Looker dapat membuat kueri banyak iterasi tabel selama pengembangan, dan setiap kali tabel pengembangan baru dibuat. Untuk mencegah tabel pengembangan mengacaukan database, Looker menerapkan strategi persist_for: "24 hours" untuk memastikan bahwa tabel sering dibersihkan dari database.
Jika tidak, Looker akan membuat tabel turunan persisten (PDT) dan tabel gabungan dalam Mode Pengembangan dengan cara yang sama seperti saat membuat tabel persisten dalam Mode Produksi.
Jika tabel pengembangan dipertahankan di database saat Anda men-deploy perubahan ke PDT atau tabel gabungan, Looker sering kali dapat menggunakan tabel pengembangan sebagai tabel produksi sehingga pengguna tidak perlu menunggu tabel dibuat saat mereka membuat kueri tabel.
Perhatikan bahwa saat Anda men-deploy perubahan, tabel mungkin masih perlu dibangun ulang agar dapat dikueri dalam produksi, bergantung pada situasinya:
- Jika sudah lebih dari 24 jam sejak Anda membuat kueri tabel dalam Mode Pengembangan, versi pengembangan tabel akan ditandai sebagai sudah berakhir dan tidak akan digunakan untuk kueri. Anda dapat memeriksa PDT yang belum di-build dengan menggunakan IDE Looker atau dengan menggunakan tab Pengembangan di halaman Persistent Derived Tables. Jika memiliki PDT yang belum dibuat, Anda dapat membuat kueri di Mode Pengembangan tepat sebelum membuat perubahan sehingga tabel pengembangan dapat digunakan dalam produksi.
- Jika tabel persisten memiliki parameter
dev_filters(untuk tabel turunan native) atau klausaWHEREbersyarat yang menggunakan pernyataanif proddanif dev(untuk tabel turunan berbasis SQL), tabel pengembangan tidak dapat digunakan sebagai versi produksi, karena versi pengembangan memiliki set data yang disingkat. Jika demikian, setelah Anda selesai mengembangkan tabel dan sebelum men-deploy perubahan, Anda dapat mengomentari parameterdev_filtersatau klausaWHEREbersyarat, lalu membuat kueri tabel dalam Mode Pengembangan. Kemudian, Looker akan membuat versi lengkap tabel yang dapat digunakan untuk produksi saat Anda men-deploy perubahan.
Jika tidak, jika Anda men-deploy perubahan saat tidak ada tabel pengembangan yang valid yang dapat digunakan sebagai tabel produksi, Looker akan membangun ulang tabel pada saat tabel dikueri berikutnya dalam Mode Produksi (untuk tabel persisten yang menggunakan strategi persist_for), atau saat regenerator berjalan berikutnya (untuk tabel persisten yang menggunakan datagroup_trigger, interval_trigger, atau sql_trigger_value).
Memeriksa PDT yang belum dibuat dalam Mode Pengembangan
Jika tabel pengembangan dipertahankan di database saat Anda men-deploy perubahan ke tabel turunan persisten (PDT) atau tabel gabungan, Looker sering kali dapat menggunakan tabel pengembangan sebagai tabel produksi sehingga pengguna Anda tidak perlu menunggu tabel dibuat saat mereka membuat kueri tabel. Lihat bagian Berapa lama Looker mempertahankan tabel pengembangan dan Apa yang mendorong Looker membuat tabel pengembangan di halaman ini untuk mengetahui detail selengkapnya.
Oleh karena itu, sebaiknya semua PDT Anda dibuat saat Anda men-deploy ke produksi sehingga tabel dapat langsung digunakan sebagai versi produksi.
Anda dapat memeriksa project untuk PDT yang belum dibuat di panel Kesehatan Project. Klik ikon Project Health di Looker IDE untuk membuka panel Project Health. Kemudian, klik tombol Validasi Status PDT.
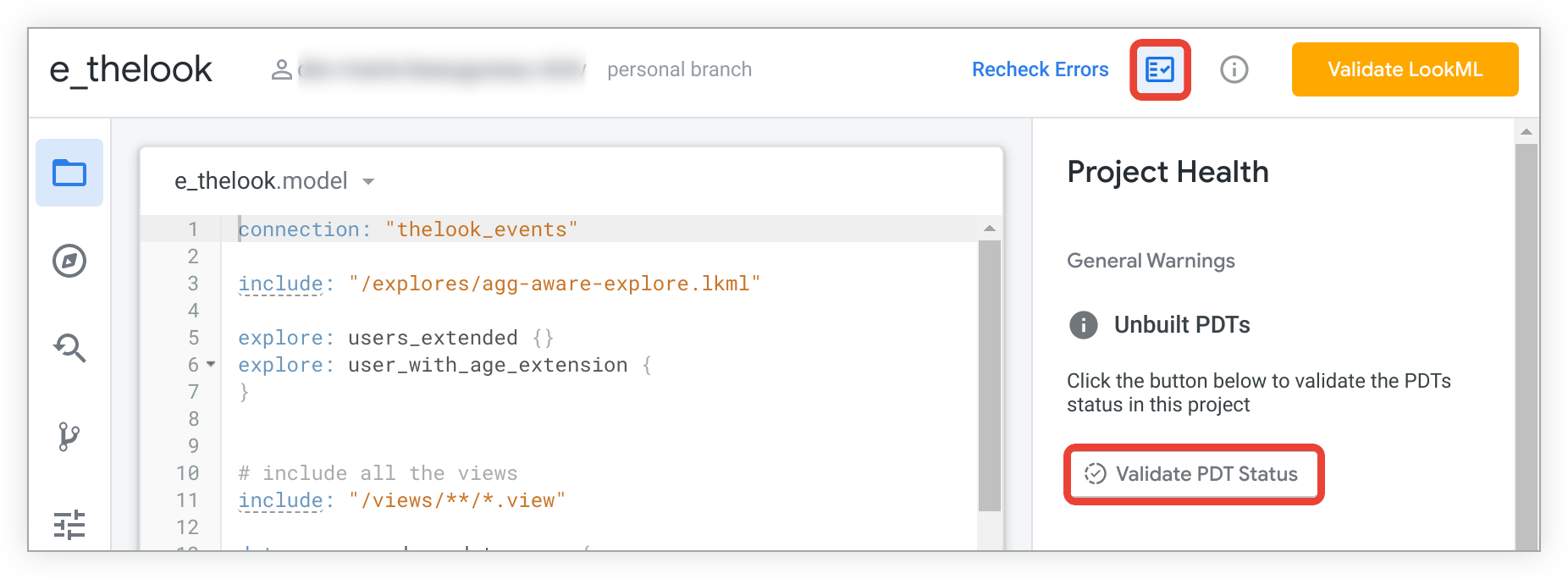
Jika ada PDT yang belum dibuat, panel Project Health akan mencantumkannya:
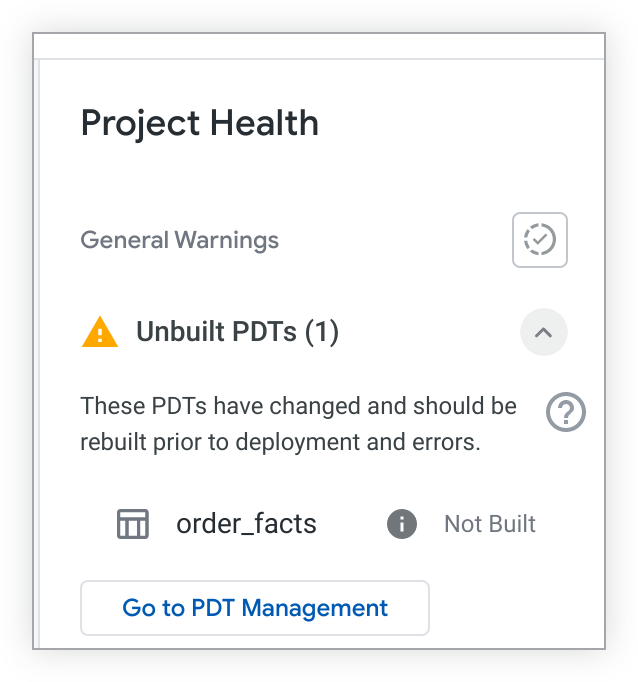
Jika memiliki izin see_pdts, Anda dapat mengklik tombol Buka Pengelolaan PDT. Looker akan membuka tab Pengembangan di halaman Tabel Turunan Persisten dan memfilter hasil ke project LookML spesifik Anda. Dari sana, Anda dapat melihat PDT pengembangan mana yang dibuat dan tidak dibuat, serta mengakses informasi pemecahan masalah lainnya. Lihat halaman dokumentasi Setelan admin - Tabel Turunan Persisten untuk mengetahui informasi selengkapnya.
Setelah mengidentifikasi PDT yang belum dibuat di project, Anda dapat membuat versi pengembangannya dengan membuka Eksplorasi yang mengkueri tabel, lalu menggunakan opsi Bangun Ulang Tabel Turunan & Jalankan dari menu Eksplorasi. Lihat bagian Membangun ulang tabel persisten secara manual untuk kueri di halaman ini.
Berbagi dan membersihkan tabel
Dalam instance Looker tertentu, Looker akan membagikan tabel yang dipertahankan antar-pengguna jika tabel memiliki definisi yang sama dan setelan metode persistensi yang sama. Selain itu, jika definisi tabel tidak ada lagi, Looker akan menandai tabel sebagai habis masa berlakunya.
Hal ini memiliki beberapa manfaat:
- Jika Anda belum membuat perubahan apa pun pada tabel dalam Mode Pengembangan, kueri Anda akan menggunakan tabel produksi yang ada. Hal ini berlaku kecuali jika tabel Anda adalah tabel turunan berbasis SQL yang ditentukan menggunakan klausa
WHEREkondisional dengan pernyataanif proddanif dev. Jika tabel ditentukan dengan klausaWHEREbersyarat, Looker akan membuat tabel pengembangan jika Anda membuat kueri tabel dalam Mode Pengembangan. (Untuk tabel turunan native dengan parameterdev_filters, Looker memiliki logika untuk menggunakan tabel produksi guna menjawab kueri dalam Mode Pengembangan, kecuali jika Anda mengubah definisi tabel, lalu membuat kueri tabel dalam Mode Pengembangan.) - Jika dua developer kebetulan membuat perubahan yang sama pada tabel saat dalam Mode Pengembangan, mereka akan berbagi tabel pengembangan yang sama.
- Setelah Anda menerapkan perubahan dari Mode Pengembangan ke Mode Produksi, definisi produksi lama tidak ada lagi, sehingga tabel produksi lama ditandai sebagai habis masa berlaku dan akan dihapus.
- Jika Anda memutuskan untuk menghapus perubahan Mode Pengembangan, definisi tabel tersebut tidak ada lagi, sehingga tabel pengembangan yang tidak diperlukan ditandai sebagai habis masa berlakunya dan akan dihapus.
Bekerja lebih cepat dalam Mode Pengembangan
Ada situasi saat tabel turunan persisten (PDT) yang Anda buat memerlukan waktu lama untuk dibuat, yang dapat memakan waktu jika Anda menguji banyak perubahan dalam Mode Pengembangan. Untuk kasus ini, Anda dapat meminta Looker membuat versi yang lebih kecil dari tabel turunan saat Anda berada dalam Mode Pengembangan.
Untuk tabel turunan native, Anda dapat menggunakan subparameter dev_filters dari explore_source untuk menentukan filter yang hanya diterapkan ke versi pengembangan tabel turunan:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Contoh ini mencakup parameter dev_filters yang memfilter data ke 90 hari terakhir dan parameter filters yang memfilter data ke 2 tahun terakhir dan ke Bandara Yucca Valley.
Parameter dev_filters bekerja bersama dengan parameter filters sehingga semua filter diterapkan ke versi pengembangan tabel. Jika dev_filters dan filters menentukan filter untuk kolom yang sama, dev_filters akan diprioritaskan untuk versi pengembangan tabel. Dalam contoh ini, versi pengembangan tabel akan memfilter data ke 90 hari terakhir untuk Bandara Yucca Valley.
Untuk tabel turunan berbasis SQL, Looker mendukung klausa WHERE bersyarat dengan opsi yang berbeda untuk versi produksi (if prod) dan pengembangan (if dev) tabel:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
Dalam contoh ini, kueri akan menyertakan semua data dari tahun 2000 dan seterusnya saat dalam Mode Produksi, tetapi hanya data dari tahun 2020 dan seterusnya saat dalam Mode Pengembangan. Menggunakan fitur ini secara strategis untuk membatasi kumpulan hasil dan meningkatkan kecepatan kueri dapat membuat perubahan Mode Pengembangan lebih mudah divalidasi.
Cara Looker membuat PDT
Setelah tabel turunan persisten (PDT) ditentukan dan dijalankan untuk pertama kalinya atau dipicu oleh regenerator untuk dibangun ulang sesuai dengan strategi persistennya, Looker akan melalui langkah-langkah berikut:
- Gunakan SQL tabel turunan untuk membuat pernyataan CREATE TABLE AS SELECT (atau CTAS) dan jalankan. Misalnya, untuk membangun kembali PDT yang disebut
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Keluarkan pernyataan untuk membuat indeks saat tabel dibuat
- Ganti nama tabel dari LC$.. ("Looker Create") menjadi LR$.. ("Looker Read"), untuk menunjukkan bahwa tabel siap digunakan
- Hapus versi tabel yang lebih lama yang tidak lagi digunakan
Ada beberapa implikasi penting:
- SQL yang membentuk tabel turunan harus valid dalam pernyataan CTAS.
- Alias kolom pada set hasil pernyataan SELECT harus berupa nama kolom yang valid.
- Nama yang digunakan saat menentukan distribusi, sortkey, dan indeks harus berupa nama kolom yang tercantum dalam definisi SQL tabel turunan, bukan nama kolom yang ditentukan dalam LookML.
Regenerator Looker
Regenerator Looker memeriksa status dan memulai build ulang untuk tabel yang dipertahankan pemicu. Tabel dengan pemicu persistensi adalah tabel turunan persisten (PDT) atau tabel gabungan yang menggunakan pemicu sebagai strategi persistensi:
- Untuk tabel yang menggunakan
sql_trigger_value, pemicunya adalah kueri yang ditentukan dalam parametersql_trigger_valuetabel. Regenerator Looker memicu pembangunan ulang tabel saat hasil pemeriksaan kueri pemicu terbaru berbeda dengan hasil pemeriksaan kueri pemicu sebelumnya. Misalnya, jika tabel turunan Anda dipertahankan dengan kueri SQLSELECT CURDATE(), regenerator Looker akan membangun ulang tabel pada saat regenerator memeriksa pemicu setelah tanggal berubah. - Untuk tabel yang menggunakan
interval_trigger, pemicunya adalah durasi waktu yang ditentukan dalam parameterinterval_triggertabel. Pembuat ulang Looker memicu pembangunan ulang tabel saat waktu yang ditentukan telah berlalu. - Untuk tabel yang menggunakan
datagroup_trigger, pemicunya dapat berupa kueri yang ditentukan dalam parametersql_triggerdatagroup terkait, atau pemicunya dapat berupa durasi waktu yang ditentukan dalam parameterinterval_triggerdatagroup.
Regenerator Looker juga memulai pembangunan ulang untuk tabel persisten yang menggunakan parameter persist_for, tetapi hanya jika tabel persist_for merupakan cascade dependensi dari tabel persisten pemicu. Dalam hal ini, regenerator Looker akan memulai pembangunan ulang untuk tabel persist_for, karena tabel tersebut diperlukan untuk membangun ulang tabel lain dalam cascade. Jika tidak, regenerator tidak memantau tabel persisten yang menggunakan strategi persist_for.
Siklus regenerasi Looker dimulai pada interval reguler yang dikonfigurasi oleh admin Looker Anda di setelan Jadwal Pemeliharaan pada koneksi database Anda (defaultnya adalah interval lima menit). Namun, regenerator Looker tidak memulai siklus baru hingga telah menyelesaikan semua pemeriksaan dan pembangunan ulang PDT dari siklus terakhir. Artinya, jika Anda memiliki build PDT yang berjalan lama, siklus regenerator Looker mungkin tidak berjalan sesering yang ditentukan dalam setelan Jadwal Pemeliharaan. Faktor lain dapat memengaruhi waktu yang diperlukan untuk membangun kembali tabel Anda, seperti yang dijelaskan di bagian Pertimbangan penting untuk menerapkan tabel persisten di halaman ini.
Jika PDT gagal dibuat, regenerator dapat mencoba membangun ulang tabel dalam siklus regenerator berikutnya:
- Jika setelan Coba Ulang Build PDT yang Gagal diaktifkan pada koneksi database Anda, regenerator Looker akan mencoba membangun ulang tabel selama siklus regenerator berikutnya, meskipun kondisi pemicu tabel tidak terpenuhi.
- Jika setelan Coba Ulang Build PDT yang Gagal dinonaktifkan, regenerator Looker tidak akan mencoba membangun ulang tabel hingga kondisi pemicu PDT terpenuhi.
Jika pengguna meminta data dari tabel yang dipertahankan saat sedang dibuat dan hasil kueri tidak ada dalam cache, Looker akan memeriksa apakah tabel yang ada masih valid. (Tabel sebelumnya mungkin tidak valid jika tidak kompatibel dengan versi baru tabel, yang dapat terjadi jika tabel baru memiliki definisi yang berbeda, tabel baru menggunakan koneksi database yang berbeda, atau tabel baru dibuat dengan versi Looker yang berbeda.) Jika tabel yang ada masih valid, Looker akan menampilkan data dari tabel yang ada hingga tabel baru dibuat. Jika tidak, jika tabel yang ada tidak valid, Looker akan memberikan hasil kueri setelah tabel baru dibangun ulang.
Pertimbangan penting untuk menerapkan tabel persisten
Mengingat kegunaan tabel persisten (PDT dan tabel agregat), Anda dapat mengumpulkan banyak tabel tersebut di instance Looker. Anda dapat membuat skenario saat regenerator Looker perlu membuat banyak tabel secara bersamaan. Terutama dengan tabel bertingkat, atau tabel yang berjalan lama, Anda dapat membuat skenario saat tabel mengalami penundaan yang lama sebelum dibangun ulang, atau saat pengguna mengalami penundaan dalam mendapatkan hasil kueri dari tabel saat database bekerja keras untuk membuat tabel.
Regenerator Looker memeriksa pemicu PDT untuk melihat apakah pemicu tersebut harus membangun kembali tabel yang dipertahankan pemicu. Siklus regenerasi ditetapkan pada interval reguler yang dikonfigurasi oleh admin Looker Anda dalam setelan Jadwal Pemeliharaan pada koneksi database Anda (defaultnya adalah interval lima menit).
Beberapa faktor dapat memengaruhi waktu yang diperlukan untuk membangun kembali tabel Anda:
- Admin Looker Anda mungkin telah mengubah interval pemeriksaan pemicu regenerator menggunakan setelan Jadwal Pemeliharaan pada koneksi database Anda.
- Regenerator Looker tidak memulai siklus baru hingga menyelesaikan semua pemeriksaan dan pembangunan ulang PDT dari siklus terakhir. Jadi, jika Anda memiliki build PDT yang berjalan lama, siklus regenerasi Looker mungkin tidak sesering setelan Jadwal Pemeliharaan.
- Secara default, regenerator dapat memulai pembangunan ulang satu PDT atau tabel gabungan dalam satu waktu melalui koneksi. Admin Looker dapat menyesuaikan jumlah pembangunan ulang serentak yang diizinkan oleh regenerator menggunakan kolom Jumlah maksimum koneksi pembuat PDT di setelan koneksi.
- Semua PDT dan tabel gabungan yang dipicu oleh
datagroupyang sama akan dibangun ulang selama proses regenerasi yang sama. Hal ini dapat menjadi beban berat jika Anda memiliki banyak tabel yang menggunakan grup data, baik secara langsung maupun sebagai akibat dari dependensi bertingkat.
Selain pertimbangan sebelumnya, ada juga beberapa situasi yang membuat Anda harus menghindari penambahan persistensi ke tabel turunan:
- Jika tabel turunan akan diperluas — Setiap perluasan PDT akan membuat salinan baru tabel di database Anda.
- Saat tabel turunan menggunakan filter template atau parameter Liquid — Persistensi tidak didukung untuk tabel turunan yang menggunakan filter template atau parameter Liquid.
- Saat tabel turunan native dibuat dari Eksplorasi yang menggunakan atribut pengguna dengan
access_filters, atau dengansql_always_where— Salinan tabel akan dibuat di database Anda untuk setiap kemungkinan nilai atribut pengguna yang ditentukan. - Jika data pokok sering berubah dan dialek database Anda tidak mendukung PDT inkremental.
- Jika biaya dan waktu yang diperlukan untuk membuat PDT terlalu tinggi.
Bergantung pada jumlah dan kompleksitas tabel persisten pada koneksi Looker Anda, antrean mungkin berisi banyak tabel persisten yang perlu diperiksa dan dibangun ulang pada setiap siklus, jadi penting untuk mengingat faktor-faktor ini saat menerapkan tabel turunan pada instance Looker Anda.
Mengelola PDT dalam skala besar menggunakan API
Memantau dan mengelola tabel turunan persisten (PDT) yang di-refresh dengan jadwal yang bervariasi menjadi semakin rumit saat Anda membuat lebih banyak PDT di instance. Sebaiknya gunakan integrasi Apache Airflow Looker untuk mengelola jadwal PDT bersama dengan proses ETL dan ELT lainnya.
Memantau dan memecahkan masalah PDT
Jika Anda menggunakan tabel turunan persisten (PDT), dan terutama PDT bertingkat, akan sangat membantu jika Anda dapat melihat status PDT. Anda dapat menggunakan halaman admin Persistent Derived Tables Looker untuk melihat status PDT Anda. Lihat halaman dokumentasi Setelan admin - Tabel Turunan Persisten untuk mengetahui informasinya.
Saat mencoba memecahkan masalah PDT:
- Perhatikan secara khusus perbedaan antara tabel pengembangan dan tabel produksi saat menyelidiki Log Peristiwa PDT.
- Pastikan setelan Temp Database di koneksi Looker Anda cocok dengan skema atau database sementara yang sebenarnya. Jika setelan Database Sementara pada koneksi tidak cocok dengan skema sementara di database Anda, perbarui setelan Database Sementara agar Looker dapat menyimpan tabel turunan persisten di database Anda.
- Tentukan apakah ada masalah dengan semua PDT atau hanya satu. Jika ada masalah dengan salah satunya, kemungkinan masalah disebabkan oleh error LookML atau SQL.
- Tentukan apakah masalah pada PDT sesuai dengan waktu saat PDT dijadwalkan untuk dibangun ulang.
- Pastikan semua kueri
sql_trigger_valueberhasil dievaluasi dan hanya menampilkan satu baris dan kolom. Untuk PDT berbasis SQL, Anda dapat melakukannya dengan menjalankannya di SQL Runner. (MenerapkanLIMITmelindungi dari kueri yang tidak terkendali.) Untuk mengetahui informasi selengkapnya tentang penggunaan SQL Runner untuk men-debug tabel turunan, lihat postingan Komunitas Menggunakan SQL Runner untuk menguji tabel turunan . - Untuk PDT berbasis SQL, gunakan SQL Runner untuk memverifikasi bahwa SQL PDT dijalankan tanpa error. (Pastikan untuk menerapkan
LIMITdi SQL Runner agar waktu kueri tetap wajar.) - Untuk tabel turunan berbasis SQL, hindari penggunaan ekspresi tabel umum (CTE). Penggunaan CTE dengan DT akan membuat pernyataan
WITHbertingkat yang dapat menyebabkan PDT gagal tanpa peringatan. Sebagai gantinya, gunakan SQL untuk CTE Anda guna membuat DT sekunder dan merujuk DT tersebut dari DT pertama Anda menggunakan sintaksis${derived_table_or_view_name.SQL_TABLE_NAME}. - Pastikan semua tabel yang menjadi dasar PDT masalah — baik tabel normal maupun PDT itu sendiri — ada dan dapat dikueri.
- Pastikan bahwa tabel yang menjadi dasar PDT masalah tidak memiliki kunci bersama atau eksklusif. Agar PDT berhasil dibuat, Looker harus mendapatkan kunci eksklusif pada tabel yang perlu diperbarui. Hal ini akan berkonflik dengan kunci eksklusif atau bersama lainnya yang ada di tabel. Looker tidak akan dapat memperbarui PDT hingga semua kunci lainnya dihapus. Hal yang sama berlaku untuk semua kunci eksklusif pada tabel yang digunakan Looker untuk membuat PDT; jika ada kunci eksklusif pada tabel, Looker tidak akan dapat memperoleh kunci bersama untuk menjalankan kueri hingga kunci eksklusif dihapus.
- Gunakan tombol Show Processes di SQL Runner. Jika ada banyak proses yang aktif, hal ini dapat memperlambat waktu kueri.
- Pantau komentar dalam kueri. Lihat bagian Komentar kueri untuk PDT di halaman ini.
Mengirim kueri komentar untuk PDT
Administrator database dapat membedakan kueri normal dari kueri yang menghasilkan tabel turunan persisten (PDT). Looker menambahkan komentar ke pernyataan CREATE TABLE ... AS SELECT ... yang mencakup model dan tampilan LookML PDT, serta ID unik (slug) untuk instance Looker. Jika PDT dibuat atas nama pengguna dalam Mode Pengembangan, komentar akan menunjukkan ID pengguna. Komentar pembuatan PDT mengikuti pola ini:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
Komentar pembuatan PDT akan muncul di tab SQL Jelajah jika Looker harus membuat PDT untuk kueri Jelajah. Komentar akan muncul di bagian atas pernyataan SQL.
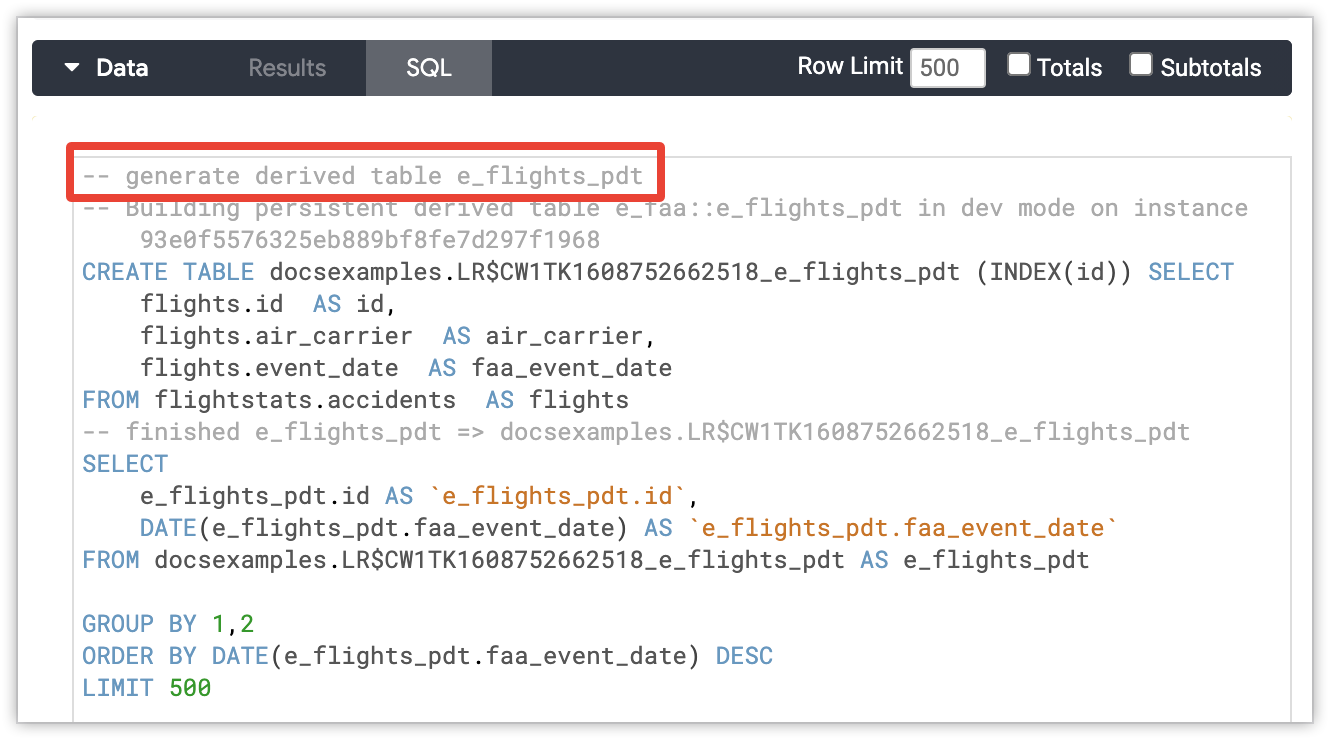
Terakhir, komentar pembuatan PDT muncul di kolom Pesan pada tab Info di pop-up Detail Kueri untuk setiap kueri di halaman admin Kueri.
Membangun ulang PDT setelah kegagalan
Jika tabel turunan persisten (PDT) mengalami kegagalan, berikut yang terjadi saat PDT tersebut dikueri:
- Looker akan menggunakan hasil dalam cache jika kueri yang sama telah dijalankan sebelumnya. (Lihat halaman dokumentasi Meng-cache kueri untuk mengetahui penjelasan tentang cara kerjanya.)
- Jika hasilnya tidak ada dalam cache, Looker akan menarik hasil dari PDT dalam database, jika ada PDT versi yang valid.
- Jika tidak ada PDT yang valid dalam database, Looker akan mencoba membangun ulang PDT.
- Jika PDT tidak dapat dibangun ulang, Looker akan menampilkan error untuk kueri. Regenerator Looker akan mencoba membangun ulang PDT pada saat PDT dikueri berikutnya atau saat strategi persistensi PDT memicu pembangunan ulang berikutnya.
Dengan PDT bertingkat, logika yang sama berlaku, kecuali bahwa dengan PDT bertingkat:
- Kegagalan membangun satu tabel mencegah pembangunan PDT di rantai dependensi.
- PDT dependen pada dasarnya mengkueri PDT yang menjadi dasarnya, sehingga strategi persistensi satu tabel dapat memicu pembangunan ulang PDT yang naik dalam rantai.
Membuka kembali contoh tabel bertingkat sebelumnya, dengan TABLE_D bergantung pada TABLE_C, yang bergantung pada TABLE_B, yang bergantung pada TABLE_A:
Jika TABLE_B mengalami kegagalan, semua perilaku standar (non-cascade) berlaku untuk TABLE_B:
- Jika
TABLE_Bdikueri, Looker akan mencoba menggunakan cache terlebih dahulu untuk menampilkan hasil. - Jika upaya ini gagal, Looker akan mencoba menggunakan versi tabel sebelumnya, jika memungkinkan.
- Jika upaya ini juga gagal, Looker akan mencoba membangun ulang tabel.
- Terakhir, jika
TABLE_Btidak dapat dibangun ulang, Looker akan menampilkan error.
Looker akan mencoba membangun ulang TABLE_B saat tabel dikueri berikutnya atau saat strategi persistensi tabel memicu pembangunan ulang berikutnya.
Hal yang sama juga berlaku untuk dependen TABLE_B. Jadi, jika TABLE_B tidak dapat dibuat, dan ada kueri di TABLE_C, urutan berikut akan terjadi:
- Looker akan mencoba menggunakan cache untuk kueri pada
TABLE_C. - Jika hasil tidak ada di cache, Looker akan mencoba menarik hasil dari
TABLE_Cdi database. - Jika tidak ada versi
TABLE_Cyang valid, Looker akan mencoba membangun ulangTABLE_C, yang membuat kueri diTABLE_B. - Kemudian, Looker akan mencoba membangun ulang
TABLE_B(yang akan gagal jikaTABLE_Bbelum diperbaiki). - Jika
TABLE_Btidak dapat dibangun ulang,TABLE_Cjuga tidak dapat dibangun ulang, sehingga Looker akan menampilkan error untuk kueri diTABLE_C. - Kemudian, Looker akan mencoba membangun ulang
TABLE_Csesuai dengan strategi persistennya yang biasa, atau saat PDT berikutnya dikueri (yang mencakup saatTABLE_Dmencoba membangun, karenaTABLE_Dbergantung padaTABLE_C).
Setelah Anda menyelesaikan masalah dengan TABLE_B, TABLE_B dan setiap tabel dependen akan mencoba membangun ulang sesuai dengan strategi persistennya, atau saat berikutnya tabel tersebut dikueri (termasuk saat PDT dependen mencoba membangun ulang). Atau, jika versi pengembangan PDT dalam cascade dibuat dalam Mode Pengembangan, versi pengembangan dapat digunakan sebagai PDT produksi baru. (Lihat bagian Tabel persisten dalam Mode Pengembangan di halaman ini untuk mengetahui cara kerjanya.) Atau, Anda dapat menggunakan Jelajah untuk menjalankan kueri di TABLE_D, lalu membangun ulang PDT untuk kueri secara manual, yang akan memaksa pembangunan ulang semua PDT yang naik ke kaskade dependensi.
Meningkatkan performa PDT
Saat Anda membuat tabel turunan persisten (PDT), performa dapat menjadi masalah. Terutama jika tabel sangat besar, membuat kueri tabel mungkin lambat, seperti halnya untuk tabel besar lainnya dalam database Anda.
Anda dapat meningkatkan performa dengan memfilter data atau dengan mengontrol cara data dalam PDT diurutkan dan diindeks.
Menambahkan filter untuk membatasi set data
Dengan set data yang sangat besar, memiliki banyak baris akan memperlambat kueri terhadap tabel turunan persisten (PDT). Jika biasanya Anda hanya membuat kueri data terbaru, pertimbangkan untuk menambahkan filter ke klausa WHERE PDT yang membatasi tabel hingga 90 hari atau kurang data. Dengan cara ini, hanya data yang relevan yang akan ditambahkan ke tabel setiap kali tabel dibangun ulang sehingga kueri yang dijalankan akan jauh lebih cepat. Kemudian, Anda dapat membuat PDT terpisah yang lebih besar untuk analisis historis agar kueri cepat untuk data terbaru dan kemampuan untuk membuat kueri data lama dapat dilakukan.
Menggunakan indexes atau sortkeys dan distribution
Saat Anda membuat tabel turunan persisten (PDT) berukuran besar, mengindeks tabel (untuk dialek seperti MySQL atau Postgres) atau menambahkan sortkey dan distribusi (untuk Redshift) dapat membantu performa.
Biasanya, sebaiknya tambahkan parameter indexes pada kolom ID atau tanggal.
Untuk Redshift, sebaiknya tambahkan parameter sortkeys pada kolom ID atau tanggal dan parameter distribution pada kolom yang digunakan untuk penggabungan.
Setelan yang direkomendasikan untuk meningkatkan performa
Setelan berikut mengontrol cara data dalam tabel turunan persisten (PDT) diurutkan dan diindeks. Setelan ini bersifat opsional, tetapi sangat direkomendasikan:
- Untuk Redshift dan Aster, gunakan parameter
distributionuntuk menentukan nama kolom yang nilainya digunakan untuk menyebarkan data di sekitar cluster. Jika dua tabel digabungkan berdasarkan kolom yang ditentukan dalam parameterdistribution, database dapat menemukan data gabungan di node yang sama, sehingga I/O antar-node diminimalkan. - Untuk Redshift, setel parameter
distribution_stylekealluntuk menginstruksikan database agar menyimpan salinan data yang lengkap di setiap node. Hal ini sering digunakan untuk meminimalkan I/O antar-node saat menggabungkan tabel yang relatif kecil. Tetapkan nilai ini keevenuntuk menginstruksikan database agar menyebarkan data secara merata melalui cluster tanpa menggunakan kolom distribusi. Nilai ini hanya dapat ditentukan jikadistributiontidak ditentukan. - Untuk Redshift, gunakan parameter
sortkeys. Nilai menentukan kolom PDT mana yang digunakan untuk mengurutkan data di disk agar penelusuran lebih mudah. Di Redshift, Anda dapat menggunakansortkeysatauindexes, tetapi tidak keduanya. - Di sebagian besar database, gunakan parameter
indexes. Nilai menentukan kolom PDT mana yang diindeks. (Di Redshift, indeks digunakan untuk membuat kunci pengurutan yang disisipkan.)