Dopo aver protetto e configurato il database, puoi connetterlo a Looker.
Puoi creare una connessione al database in Looker nella pagina Connetti il tuo database a Looker. Esistono due opzioni per aprire la pagina Connetti il tuo database a Looker:
- Seleziona Connessioni nella sezione Database del riquadro Amministrazione. Nella pagina Connessioni, fai clic sul pulsante Aggiungi connessione.
- Fai clic sul pulsante Crea nel pannello di navigazione a sinistra e poi seleziona la voce di menu Connessione.
Per ulteriori informazioni sull'applicazione degli attributi utente alle impostazioni di connessione, consulta la sezione Connessioni della pagina della documentazione relativa agli attributi utente.
Questa pagina descrive i campi comuni visualizzati da Looker nella pagina Connetti il tuo database a Looker. I campi esatti visualizzati nella pagina dipendono dall'impostazione del dialetto.
Fai clic qui per visualizzare i link alle istruzioni specifiche per il dialetto nella documentazione di Looker.
- Actian Avalanche
- AlloyDB per PostgreSQL
- Amazon Aurora PostgreSQL
- Amazon Athena
- Amazon Aurora MySQL
- Amazon RDS per MySQL
- Amazon RDS per PostgreSQL
- Amazon Redshift
- Apache Druid
- Apache Hive 2.3 e versioni successive e 3.1.2 e versioni successive
- Apache Spark 3+
- ClickHouse
- Cloudera Impala 3.1+
- Databricks
- DataVirtuality
- Denodo
- Dremio
- Exasol
- Firebolt
- SQL precedente di Google BigQuery
- SQL standard di Google BigQuery
- Google Cloud SQL per MySQL
- Google Cloud SQL per PostgreSQL
- Google Spanner
- Greenplum
- IBM DB2 su AS400
- IBM DB2 su LUW
- MariaDB
- Microsoft Azure Synapse Analytics
- Database SQL di Microsoft Azure
- Microsoft Azure PostgreSQL
- Microsoft SQL Server (MSSQL)
- Connettore MongoDB per la BI
- MySQL
- Oracle
- Oracle ADWC
- PostgreSQL
- PrestoDB
- SAP HANA
- SingleStore (in precedenza MemSQL)
- Snowflake
- Teradata
- Trino
- Vector
- Vertica
Dopo aver inserito le impostazioni di connessione al database, puoi selezionare il pulsante Testa nella pagina Connetti il database a Looker per testare la connessione e assicurarti che sia configurata correttamente. Fai clic su Test per verificare che la connessione sia riuscita. Per informazioni sulla risoluzione dei problemi, consulta la pagina della documentazione Testare la connettività del database. Se Looker mostra Può essere collegata, premi Connetti per creare la connessione. La connessione al database viene aggiunta all'elenco nella pagina di amministrazione Connessioni di Looker.
Impostazioni generali
Nome
Il nome che vuoi utilizzare per fare riferimento alla connessione. Devi utilizzare questo nome di connessione al database nel parametro connection del tuo modello LookML. Il nome della connessione al database è anche il modo in cui la connessione viene identificata nella pagina Amministrazione Connessioni di Looker. Non utilizzare il nome di alcuna cartella per questa impostazione. Questo valore non deve corrispondere necessariamente ai contenuti del database, Name è un'etichetta che identifica questa connessione all'interno dell'interfaccia utente di Looker.
Ambito della connessione
Seleziona se la connessione deve essere utilizzabile con tutti i progetti o solo con un progetto:
- Tutti i progetti: tutti i progetti LookML nell'istanza possono avere accesso alla connessione, pertanto il nome della connessione può essere specificato nel parametro
connectiondei file modello del progetto. - Progetto selezionato: solo un progetto LookML nell'istanza può avere accesso alla connessione. Quando selezioni questa opzione, nella schermata Connessione viene visualizzato un menu a discesa dei progetti nell'istanza. Seleziona il progetto che può avere accesso a questa connessione.
Utilizza questa opzione insieme alle seguenti autorizzazioni per delegare la gestione delle connessioni e la configurazione del modello:
Dialetto
Il dialetto SQL corrispondente alla tua connessione. È importante scegliere il valore corretto, in modo da visualizzare le opzioni di connessione appropriate e consentire a Looker di convertire correttamente il codice LookML in codice SQL.
ID progetto di fatturazione
Solo per i collegamenti a Google BigQuery, l'ID progetto di fatturazione è l'ID progetto Google Cloud.
Host
Il nome host del tuo database che deve essere utilizzato da Looker per la connessione all'host del tuo database.
Se hai collaborato con un analista Looker per configurare un tunnel SSH al tuo database, inserisci "localhost" nel campo Host.
Porta
La porta del database che deve essere utilizzata da Looker per la connessione all'host del tuo database.
Se hai collaborato con un analista Looker per configurare un tunnel SSH al tuo database, inserisci nel campo Porta il numero di porta che reindirizza al tuo database, che l'analista Looker dovrebbe averti fornito.
Database
Il nome del database sul tuo host. Ad esempio, potresti avere un host con nome my-instance.us-east-1.redshift.amazonaws.com su cui è presente un database con nome sales_info. In questo campo devi inserire sales_info. Se sono presenti più database sullo stesso host, potrebbe essere necessario creare più connessioni per utilizzarli (tranne che per MySQL, in cui il termine database assume un significato lievemente diverso da quello attribuito nella maggior parte dei dialetti SQL).
Schema
Lo schema predefinito utilizzato da Looker quando non è specificato alcuno schema. Viene applicato quando si utilizza SQL Runner, durante la creazione di un progetto LookML e durante l'esecuzione di query sulle tabelle.
Autenticazione
Per le connessioni a Google BigQuery, Snowflake, Trino e Databricks, seleziona il tipo di autenticazione che vuoi che Looker utilizzi per accedere al tuo database:
- Per le connessioni a Google BigQuery, puoi scegliere di configurare OAuth o un account di servizio da utilizzare da parte di Looker per autenticarsi nel tuo database.
- Per le connessioni a Snowflake, Trino e Databricks, puoi scegliere di configurare OAuth o un account database da utilizzare da parte di Looker per autenticarsi nel tuo database.
Quando utilizzi OAuth, gli utenti devono accedere al tuo database per eseguire query da Looker. Per ulteriori informazioni sulla configurazione di OAuth in una connessione a Looker, consulta le procedure di connessione a Google BigQuery, Snowflake, Trino o Databricks.
Nome utente
Il nome utente di un account utente del tuo database che Looker può utilizzare per connettersi al tuo database.
Password
La password di un account utente del tuo database che Looker può utilizzare per connettersi al tuo database.
Impostazioni facoltative
Server SSH
L'opzione Server SSH è disponibile solo se è stato eseguito il deployment dell'istanza nell'infrastruttura Kubernetes e solo se è stata concessa la possibilità di aggiungere informazioni di configurazione del server SSH alla tua istanza di Looker. Se questa opzione non è abilitata per la tua istanza di Looker e vuoi abilitarla, contatta un esperto del team di vendita Google Cloud o apri una richiesta di assistenza.
Il server SSH sceglie automaticamente la porta localhost per te e non è possibile specificarla. Se devi creare una connessione SSH che richiede di specificare una porta localhost, apri una richiesta di assistenza.
Per connetterti al tuo database utilizzando un tunnel SSH, sposta il pulsante di attivazione su ON e seleziona una configurazione del server SSH dall'elenco a discesa.
Porta locale
Per impostazione predefinita, Looker seleziona automaticamente una porta locale disponibile per il tunnel SSH. Per scegliere manualmente una porta locale, seleziona Inserimento manuale e inserisci un numero di porta nel campo Porta locale personalizzata. Assicurati che la porta locale sia disponibile sull'istanza.
Tabelle derivate permanenti (PDT)
Abilita PDT
Attiva l'opzione di attivazione/disattivazione Abilita PDT per attivare le tabelle derivate permanenti. Quando i PDT sono abilitati, la finestra Connessione mostra ulteriori campi PDT e la sezione Sostituzioni PDT. Looker mostra l'opzione di attivazione/disattivazione Attiva PDT solo se il dialetto del database supporta l'utilizzo delle PDT.
Tieni presente quanto segue sulle PDT:
- Le PDT non sono supportate per le connessioni a Snowflake che utilizzano OAuth.
- La disattivazione delle PDT su una connessione non implica la disattivazione dei gruppi di dati associati alle tue PDT. Anche se disattivi le PDT, i gruppi di dati esistenti continueranno a eseguire le proprie query
sql_triggersul database. Se vuoi impedire a un gruppo di dati di eseguire la querysql_triggersul tuo database, devi eliminare o commentare il parametrodatagroupdal progetto LookML oppure puoi aggiornare l'impostazione Pianificazione manutenzione PDT e gruppi di dati per la connessione in modo che Looker controlli le PDT e i gruppi di dati molto di rado o mai. - Per le connessioni Snowflake, Looker imposta il valore del parametro
AUTOCOMMITsuTRUE(valore predefinito di Snowflake).AUTOCOMMITè obbligatorio per i comandi SQL eseguiti da Looker per gestire il proprio sistema di registrazione delle PDT.
Database temporaneo
Anche se l'etichetta è Database temporaneo, devi inserire il nome del database o dello schema, in base al tuo dialetto SQL, che deve essere utilizzato da Looker per creare le tabelle derivate permanenti. Il database o lo schema deve essere configurato preventivamente, con le autorizzazioni di scrittura adeguate. Nella pagina della documentazione con le istruzioni per la configurazione del database, seleziona il dialetto del tuo database per visualizzare le istruzioni corrispondenti.
È necessario specificare un database temporaneo o uno schema per ogni connessione, poiché non possono essere condivisi tra più connessioni.
Numero massimo di connessioni del generatore di PDT
L'impostazione Numero massimo di connessioni del generatore di PDT consente di specificare il numero di operazioni di creazione di tabelle che possono essere avviate contemporaneamente dal rigeneratore Looker sulla connessione al tuo database. L'impostazione Numero massimo di connessioni del generatore di PDT si applica solo ai tipi di tabelle per cui il rigeneratore Looker avvia la ricostruzione:
- Tabelle rese permanenti da trigger (tabelle derivate permanenti e tabelle aggregate che utilizzano la strategia di permanenza
datagroup_triggerosql_trigger_value). - Tabelle permanenti che utilizzano la strategia
persist_for, ma solo quando la tabellapersist_forfa parte di una cascata di tabelle derivate da cui dipende una tabella che utilizza la strategia di persistenzadatagroup_triggerosql_trigger_value. In questo caso, il rigeneratore Looker ricostruisce una tabellapersist_for, poiché è necessaria per la ricostruzione di un'altra tabella nella cascata. In caso contrario, il rigeneratore non avvia alcuna operazione di creazione per le tabellepersist_for.
Il valore predefinito dell'impostazione Numero massimo di connessioni del generatore di PDT è 1, ma è possibile impostare un valore fino a 10. Tuttavia, questo valore non può superare quello impostato nel campo Numero massimo di connessioni per nodo o in per-user-query-limit impostato nelle opzioni di avvio di Looker.
Imposta questo valore con attenzione. Un valore troppo elevato può sovraccaricare il database. Se il valore è troppo basso, le PDT a esecuzione prolungata o le tabelle aggregate possono ritardare la creazione di altre tabelle permanenti o rallentare le altre query sulla connessione. I database che supportano la multitenancy, come BigQuery, Snowflake e Redshift, possono gestire più efficacemente la generazione delle query parallele.
Se vuoi aumentare il valore dell'impostazione Numero massimo di connessioni del builder di PDT, come regola generale è consigliabile procedere per incrementi di 1. Se si verifica un comportamento imprevisto, ripristina il valore predefinito 1. Se invece le prestazioni delle query non ne risentono, puoi continuare ad aumentare il valore di 1 e a verificare le prestazioni dopo ogni incremento, prima di aumentare ulteriormente l'impostazione.
Tieni presente quanto segue per l'impostazione Numero massimo di connessioni del generatore di PDT:
- L'impostazione Numero massimo di connessioni del generatore di PDT si applica solo alle connessioni necessarie per la ricostruzione delle tabelle, non alle connessioni necessarie per i controlli degli attivatori. Un controllo trigger è una query che verifica se la strategia di permanenza della tabella è stata attivata. Poiché queste query vengono sempre eseguite in sequenza, l'impostazione Numero massimo di connessioni a generatore PDT non viene applicata.
- In un'istanza di Looker in cluster, il rigeneratore viene eseguito solo sul nodo principale. L'impostazione Numero massimo di connessioni del builder di PDT viene applicata solo al nodo principale e, pertanto, imposta il limite per l'intero cluster.
- L'impostazione Numero massimo di connessioni del builder di PDT non si applica ai tipi di tabelle seguenti. Questi tipi di tabelle vengono creati in sequenza:
- Le tabelle rese permanenti tramite il parametro
persist_for(a meno che dalla tabella non dipendano altre tabelle che utilizzano le strategiedatagroup_triggerosql_trigger_value). - Tabelle in modalità di sviluppo.
- Tabelle ricostruite con l'opzione Ricostruisci tabelle derivate ed esegui.
- Tabelle che dipendono l'una dall'altra in uno schema di dipendenza a cascata. Non è possibile creare una tabella contemporaneamente alla tabella da cui dipende. Ad esempio, se
table_Bdipende datable_A, la ricostruzione ditable_Adeve essere completata prima che possa iniziare quella ditable_B.
- Le tabelle rese permanenti tramite il parametro
Pianificazione della manutenzione di PDT e gruppi di dati
Il rigeneratore Looker controlla i gruppi di dati e le tabelle rese permanenti (sia le tabelle aggregate sia le tabelle derivate permanenti) che si basano su sql_trigger_value. In base a questi controlli, il rigeneratore Looker ricostruisce o elimina le tabelle permanenti dallo schema da zero del database.
Il valore Datagroup and PDT Maintenance Schedule (Pianificazione manutenzione PDT e gruppi di dati) imposta l'intervallo cron per il rigeneratore Looker. Il rigeneratore Looker avvia un ciclo di rigenerazione per controllare i gruppi di dati e le tabelle permanenti nell'intervallo cron. Se un ciclo di rigenerazione di Looker è ancora in corso nell'intervallo cron successivo, il rigeneratore di Looker completerà il ciclo in corso e poi attenderà l'intervallo cron successivo per iniziare il ciclo successivo.
L'impostazione Pianificazione della manutenzione di PDT e gruppi di dati accetta un'espressione cron. Il valore predefinito è */5 * * * *, il che significa che il ciclo del rigeneratore di Looker avvierà un ciclo con intervallo di cinque minuti, se il ciclo precedente del rigeneratore è stato completato. Se il ciclo del rigeneratore precedente non è stato completato, il rigeneratore di Looker verrà avviato nel successivo intervallo di cinque minuti dopo il completamento del ciclo.
Il valore predefinito di cinque minuti è anche l'intervallo più frequente supportato per la Pianificazione della manutenzione di PDT e gruppi di dati. Looker non applica un intervallo massimo per la Pianificazione manutenzione gruppi di dati e PDT, il che significa che puoi estendere l'intervallo tra i cicli del rigeneratore Looker per il tempo specificato da un'espressione cron. Tieni presente che cicli di rigenerazione di Looker più lunghi possono influire negativamente sull'aggiornamento dei dati nella cache e nelle tabelle permanenti.
Una volta completati tutti i controlli e le ricostruzioni delle PDT in un ciclo, il rigeneratore Looker attenderà il successivo intervallo cron per avviare il ciclo successivo. Se hai ricostruzioni PDT di lunga durata, potrebbero verificarsi periodi lunghi tra i cicli del rigeneratore di Looker. Altri fattori possono influire sul tempo necessario per ricostruire le tabelle, come descritto nella sezione Considerazioni importanti per l'implementazione delle tabelle permanenti della pagina Tabelle derivate in Looker.
Se il tuo database non è in funzione 24 ore su 24, 7 giorni su 7, puoi limitare i controlli ai soli orari in cui è attivo. Di seguito sono riportate alcune espressioni cron aggiuntive:
espressione cron |
Definizione |
|---|---|
*/5 8-17 * * MON-FRI |
Controlla i gruppi di dati e le PDT ogni 5 minuti, dal lunedì al venerdì durante l'orario lavorativo |
*/5 8-17 * * * |
Controlla i gruppi di dati e le PDT ogni 5 minuti, tutti i giorni durante l'orario lavorativo |
0 8-17 * * MON-FRI |
Controlla i gruppi di dati e le PDT ogni ora, dal lunedì al venerdì durante l'orario lavorativo |
1 3 * * * |
Controlla i gruppi di dati e le PDT ogni giorno alle 03:01 |
Ecco alcune cose da tenere presente quando crei un'espressione cron:
- Looker utilizza parse-cron v0.1.3, che non supporta
?nelle espressionicron. - L'espressione
cronutilizza il fuso orario dell'applicazione di Looker per determinare quando eseguire i controlli. - Se le PDT non vengono ricostruite, reimposta il valore predefinito della stringa cron, ovvero
*/5 * * * *.
Di seguito sono riportate alcune risorse utili per la creazione delle stringhe cron:
- https://crontab.guru: contiene informazioni sulla modifica e il test delle stringhe
cron. - http://www.crontab-generator.org: seleziona le impostazioni di orario e il generatore crea la stringa
croncorrispondente.
Riprova le operazioni di creazione di PDT non riuscite
Il pulsante di attivazione/disattivazione Riprova le operazioni di creazione di PDT non riuscite configura il modo in cui il rigeneratore Looker tenta di ricostruire le tabelle rese permanenti da trigger che non sono riuscite durante il ciclo precedente del rigeneratore. Il rigeneratore Looker è il processo che ricostruisce le tabelle rese permanenti da trigger (PDT e tabelle aggregate) in base all'intervallo configurato nell'impostazione di connessione Datagroup and PDT Maintenance Schedule (Pianificazione manutenzione PDT e gruppi di dati). Quando l'opzione di attivazione/disattivazione Riprova le operazioni di creazione di PDT non riuscite è attivata, il rigeneratore Looker tenta di ricostruire una PDT non riuscita nel ciclo precedente del rigeneratore, anche se la relativa condizione trigger non è soddisfatta. Quando questa impostazione è disabilitata, il rigeneratore Looker tenta di ricostruire le PDT non riuscite nel ciclo precedente solo se la relativa condizione trigger è soddisfatta. L'impostazione Retry Failed PDT Builds (Riprova le operazioni di creazione di PDT non riuscite) è disabilitata per impostazione predefinita.
Per ulteriori informazioni sul rigeneratore Looker, consulta la pagina della documentazione dedicata alle tabelle derivate in Looker.
Controllo dell'API PDT
L'opzione di attivazione/disattivazione Controllo dell'API PDT determina se è possibile utilizzare le chiamate API start_pdt_build, check_pdt_build e stop_pdt_build per questa connessione. Quando l'opzione di attivazione/disattivazione Controllo dell'API PDT è disattivata, queste chiamate all'API non andranno a buon fine quando fanno riferimento ai PDT su questa connessione. L'opzione di attivazione/disattivazione Controllo dell'API PDT è disabilitata per impostazione predefinita.
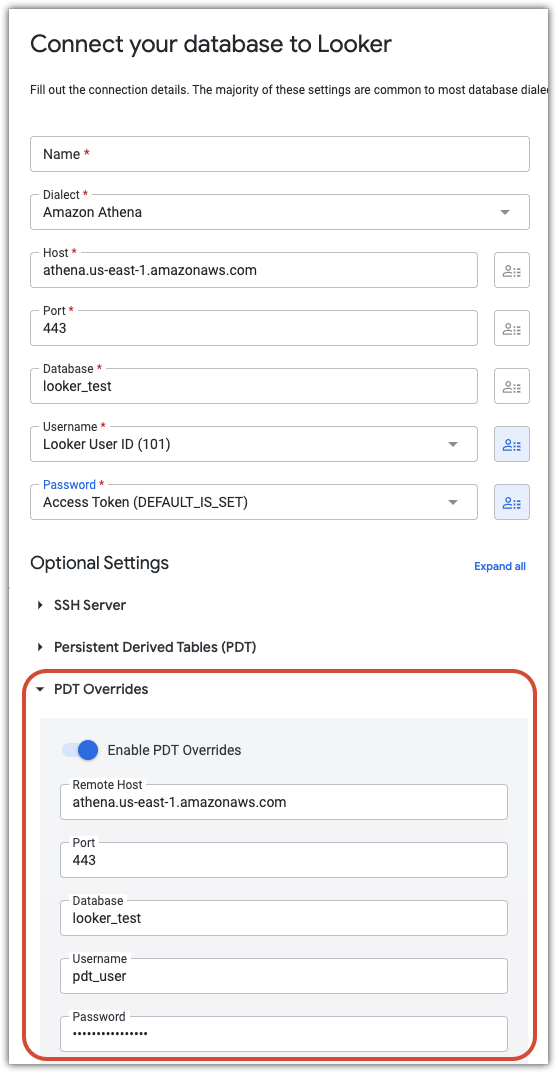
Override PDT
Se il tuo database supporta le tabelle derivate permanenti e hai attivato l'opzione di attivazione/disattivazione Attiva PDT nelle impostazioni di connessione, Looker mostra la sezione Sostituzioni PDT. Nella sezione Sostituzioni PDT puoi inserire parametri JDBC separati (host, porta, database, nome utente, password, schema, parametri aggiuntivi e istruzioni after connect) specifici per i processi PDT. Questo può essere utile per vari motivi:
- Creando un utente del database dedicato per i processi PDT, puoi utilizzare le PDT nel tuo progetto Looker anche se assegni attributi utente alle credenziali di accesso al database o utilizzi OAuth per la connessione al database.
- I processi PDT possono autenticarsi mediante un utente dedicato del database, dotato di una priorità superiore. In questo modo, il database può dare la priorità ai job PDT rispetto alle query utente meno critiche.
- L'accesso in scrittura può essere revocato per la connessione standard al database di Looker e concesso esclusivamente a un utente speciale, che verrà utilizzato dai processi PDT per l'autenticazione. Si tratta di una strategia di sicurezza più efficace per la maggior parte delle organizzazioni.
- Per database come Snowflake, i processi PDT possono essere instradati verso componenti hardware più potenti, che non vengono condivisi con gli altri utenti di Looker. In questo modo, le PDT vengono create più rapidamente, senza dover sostenere i costi dell'esecuzione a tempo pieno di risorse hardware più costose.
Ad esempio, la configurazione che segue utilizza una connessione in cui i campi Username (Nome utente) e Password vengono impostati su attributi utente. In questo modo, ogni utente può accedere al database utilizzando le proprie credenziali individuali. La sezione PDT Overrides (Override PDT) crea un utente separato (pdt_user) con la propria password. L'account pdt_user viene utilizzato per tutti i processi PDT, con livelli di accesso adeguati alla creazione e all'aggiornamento delle PDT.
Fuso orario
Fuso orario database
Il fuso orario in cui il database archivia le informazioni basate sul tempo. Looker utilizza queste impostazioni al fine di convertire i valori di data/ora per gli utenti, semplificando la comprensione e l'utilizzo dei dati basati sul tempo. Per ulteriori informazioni, consulta la pagina della documentazione dedicata all'utilizzo delle impostazioni relative al fuso orario.
Fuso orario query
L'opzione Fuso orario query è visibile solo se hai disattivato Fusi orari specifici degli utenti.
Quando i Fusi orari specifici degli utenti sono disabilitati, il Fuso orario query è quello che viene mostrato agli utenti quando eseguono una query per dati basati sul tempo e il fuso orario in cui Looker converte i dati basati sul tempo rispetto al Fuso orario del database.
Per ulteriori informazioni, consulta la pagina della documentazione dedicata all'utilizzo delle impostazioni relative al fuso orario.
Impostazioni aggiuntive
Parametri JDBC aggiuntivi
Se necessario, qui puoi aggiungere ulteriori parametri JDBC (Java Database Connectivity) per le tue query.
Per fare riferimento a un attributo utente in un parametro JDBC, utilizza la sintassi del linguaggio Liquid per la creazione dei modelli: _user_attributes['name_of_attribute']. Ad esempio:
my_jdbc_param={{ _user_attributes['name_of_attribute'] }}
Numero massimo di connessioni per nodo
Consente di specificare il numero massimo di connessioni con il tuo database instaurabili da Looker. Nella maggior parte dei casi, si tratta del numero di query simultanee eseguibili da Looker sul database in questione. Looker riserva inoltre fino a un massimo di tre connessioni per l'interruzione delle query. Se il pool di connessioni è molto limitato, Looker riserva un numero di connessioni inferiore.
Imposta questo valore con attenzione. Se il valore è troppo alto, potresti sovraccaricare il database. Se il valore è troppo basso, le query devono condividere un numero limitato di connessioni. Di conseguenza, molte query possono apparire lente agli utenti perché devono attendere la fine di quelle precedenti.
Il valore predefinito (che varia a seconda del dialetto SQL) è solitamente un punto di partenza ragionevole. La maggior parte dei database prevede anche una propria impostazione per il numero massimo di connessioni accettate. Se la configurazione del tuo database impone un limite alle connessioni, assicurati che il valore Numero massimo di connessioni per nodo sia minore o uguale al limite del database.
Timeout del pool di connessioni
Se gli utenti richiedono un numero di connessioni superiore al valore dell'impostazione Numero massimo di connessioni per nodo, le richieste in eccesso possono essere eseguite solo quando terminano quelle precedenti. Questa impostazione specifica il tempo massimo di attesa delle richieste. L'impostazione predefinita è 120 secondi.
Questo valore deve essere impostato con attenzione. Se è troppo basso, le query di alcuni utenti rischiano di essere annullate perché il tempo disponibile non è sufficiente per completare le query di altri utenti. Se è troppo elevato, le numerose query rischiano di accumularsi costringendo gli utenti ad attendere molto tempo. Il valore predefinito è solitamente un punto di partenza ragionevole.
SSL
Scegli se utilizzare o meno la crittografia SSL per proteggere i dati scambiati fra Looker e il tuo database. SSL è solo una delle opzioni disponibili per proteggere i tuoi dati. Le altre opzioni di sicurezza sono illustrate nella pagina della documentazione che illustra come abilitare l'accesso sicuro ai database.
Verifica SSL
Scegli se rendere obbligatoria la verifica del certificato SSL utilizzato dalla connessione. Se richiedi la verifica, l'autorità di certificazione (CA) SSL che ha firmato il certificato SSL deve essere inclusa nell'elenco delle origini attendibili del client. Se la CA non è un'origine attendibile, la connessione al database non viene stabilita.
Se questa casella non è selezionata, la crittografia SSL viene comunque utilizzata per la connessione, ma non viene richiesta la verifica della connessione SSL, che può quindi essere stabilita anche se la CA non è inclusa nell'elenco delle origini attendibili del client.
Pre-memorizzazione nella cache di SQL Runner
In SQL Runner, tutte le informazioni relative alle tabelle vengono precaricate appena selezioni una connessione e uno schema. Questo permette a SQL Runner di visualizzare rapidamente le colonne di una tabella appena fai clic sul suo nome. Tuttavia, per le connessioni e gli schemi associati a tabelle numerose o molto grandi non è consigliabile precaricare tutte le informazioni richieste da SQL Runner.
Se preferisci che SQL Runner carichi le informazioni sulle singole tabelle solo quando vengono selezionate, puoi deselezionare l'opzione Pre-cache SQL Runner per disabilitare il precaricamento per la connessione.
Recupera schema informazioni per scrittura SQL
Per alcune funzionalità di scrittura SQL, come la consapevolezza aggregata, Looker utilizza lo schema di informazioni del database per ottimizzare la scrittura del codice. Se lo schema di informazioni non viene memorizzato nella cache, di tanto in tanto Looker potrebbe avere l'esigenza di bloccare la scrittura del codice SQL nel database al fine di recuperare lo schema di informazioni. Per i dialetti che utilizzano Hadoop Distributed File System (HDFS), il recupero dello schema di informazioni potrebbe richiedere un tempo sufficientemente lungo da influire in modo significativo sulle prestazioni delle query di Looker. Se sai che il tuo schema di informazioni è lento, puoi disabilitare l'opzione Recupero schema informazioni per scrittura SQL per la tua connessione. Poiché la disattivazione di questa funzionalità impedisce in parte l'ottimizzazione SQL di Looker per determinate caratteristiche, è consigliabile abilitare l'opzione Recupera schema informazioni per scrittura SQL, a meno che lo schema di informazioni della tua connessione non sia particolarmente lento.
Stima dei costi
L'opzione di attivazione/disattivazione Stima costi si applica solo alle seguenti connessioni al database:
- Snowflake
- Amazon Redshift
- Amazon Aurora
- PostgreSQL, Google Cloud SQL per PostgreSQL e Microsoft Azure PostgreSQL
Il pulsante di attivazione/disattivazione Stima dei costi attiva le seguenti funzionalità nella connessione:
- Stime dei costi per le query di esplorazione
- Stime dei costi per le query di SQL Runner
- Stime dei risparmi di calcolo per le query sul riconoscimento aggregato
Per ulteriori informazioni, consulta la pagina della documentazione Esplorazione dei dati in Looker.
Pool di connessioni al database
Per i dialetti che supportano il pooling delle connessioni al database, questa funzionalità consente a Looker di utilizzare pool di connessioni tramite il driver JDBC. Il pooling delle connessioni al database consente prestazioni di query più rapide; una nuova query non deve creare una nuova connessione al database, ma può utilizzare una connessione esistente dal pool di connessioni. La funzionalità di pooling delle connessioni garantisce che una connessione venga ripulita dopo l'esecuzione di una query e sia disponibile per il riutilizzo al termine dell'esecuzione della query. Per ulteriori informazioni, consulta la pagina della documentazione relativa al pooling delle connessioni al database.
Test delle impostazioni di connessione
Puoi testare le impostazioni di connessione in due punti dell'interfaccia utente di Looker:
- Seleziona il pulsante Test in fondo alla pagina Impostazioni connessioni.
- Seleziona il pulsante Test accanto alla voce della connessione nella pagina di amministrazione Connessioni, come descritto nella pagina della documentazione Connessioni.
Dopo aver inserito le impostazioni di connessione, fai clic su Test per verificare che le informazioni siano corrette e che sia possibile stabilire la connessione al database.
Se la connessione non supera uno o più test, ecco alcune opzioni per la risoluzione dei problemi:
- Prova alcuni dei passaggi per la risoluzione dei problemi illustrati nella pagina della documentazione dedicata ai test di connettività del database.
- Se utilizzi Mongo versione 3.6 o precedente su Atlas e ricevi un errore del collegamento di comunicazione, consulta la pagina della documentazione dedicata al Connettore Mongo.
- Per ricevere un messaggio di connessione riuscita per le PDT e lo schema temp, devi abilitare questa funzionalità durante la configurazione del database Looker. Per sapere come eseguire questa operazione, consulta la pagina della documentazione con le istruzioni per la configurazione del database.
Se i problemi persistono, apri una richiesta di assistenza.
Esegui il test come utente
Se hai impostato uno o più valori del parametro di connessione su un attributo utente, viene visualizzata l'opzione Testa come utente. Seleziona un utente e poi fai clic su Test per verificare che il database possa connettersi ed eseguire query come questo utente.
Passaggi successivi
Dopo aver collegato il database a Looker, puoi configurare le opzioni di accesso per gli utenti.