Amazon S3 データを BigQuery に読み込む
BigQuery Data Transfer Service for Amazon S3 コネクタを使用して、Amazon S3 から BigQuery にデータを読み込むことができます。BigQuery Data Transfer Service を使用すると、Amazon S3 から BigQuery に最新のデータを追加する定期的な転送ジョブのスケジュールを設定できます。
始める前に
Amazon S3 データ転送を作成する前に:
- BigQuery Data Transfer Service を有効にするために必要なすべての操作が完了していることを確認します。
- データを保存する BigQuery データセットを作成します。
- データ転送用に宛先テーブルを作成し、スキーマ定義を指定します。宛先テーブルは、テーブルの命名規則に従う必要があります。宛先テーブル名でもパラメータがサポートされています。
- Amazon S3 の URI、アクセスキー ID、シークレット アクセスキーを取得します。アクセスキーの管理については、AWS のドキュメントをご覧ください。
- Pub/Sub の転送実行通知を設定する場合は、
pubsub.topics.setIamPolicy権限が必要です。メール通知を設定するだけの場合、Pub/Sub の権限は必要ありません。詳細については、BigQuery Data Transfer Service の実行通知をご覧ください。
制限事項
Amazon S3 データ転送には、次の制限があります。
- Amazon S3 URI のバケット部分はパラメータ化できません。
- Write disposition パラメータを
WRITE_TRUNCATEに設定した Amazon S3 からのデータ転送では、実行のたびに一致するすべてのファイルが Google Cloud に転送されます。これにより、Amazon S3 のアウトバウンド データ転送の追加費用が発生する場合があります。実行時に転送されるファイルの詳細については、接頭辞マッチングまたはワイルドカード マッチングの影響をご覧ください。 - AWS GovCloud(
us-gov)リージョンからのデータ転送はサポートされていません。 - BigQuery Omni のロケーションへのデータ転送はサポートされていません。
Amazon S3 のソースデータの形式によっては、追加の制限が適用される場合があります。詳細については、次のトピックをご覧ください。
定期的なデータ転送の最小間隔は 1 時間です。デフォルトの定期的なデータ転送間隔は 24 時間です。
必要な権限
次の権限が付与されていることを確認します。
必要な BigQuery のロール
BigQuery Data Transfer Service データ転送の作成に必要な権限を取得するには、プロジェクトに対する BigQuery 管理者 (roles/bigquery.admin)IAM ロールを付与するよう管理者に依頼します。ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
この事前定義ロールには、BigQuery Data Transfer Service のデータ転送の作成に必要な権限が含まれています。必要とされる正確な権限については、「必要な権限」セクションを開いてご確認ください。
必要な権限
BigQuery Data Transfer Service データ転送を作成するには、次の権限が必要です。
-
BigQuery Data Transfer Service の権限:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery の権限:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
カスタムロールや他の事前定義ロールを使用して、これらの権限を取得することもできます。
詳細については、bigquery.admin へのアクセス権を付与するをご覧ください。
必要な Amazon S3 のロール
データ転送を有効にするために必要な権限が構成されていることを確認するには、Amazon S3 のドキュメントをご覧ください。少なくとも、Amazon S3 ソースデータには AWS 管理ポリシー AmazonS3ReadOnlyAccess が適用されている必要があります。
Amazon S3 データ転送を設定する
Amazon S3 データ転送を作成するには:
コンソール
Google Cloud コンソールの [データ転送] ページに移動します。
[転送を作成] をクリックします。
[転送の作成] ページで、次の操作を行います。
[ソースタイプ] セクションの [ソース] で、[Amazon S3] を選択します。

[転送構成名] セクションの [表示名] に、転送名(例:
My Transfer)を入力します。転送名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。
[スケジュール オプション] セクションで:
[繰り返しの頻度] を選択します。[時間]、[日]、[週]、[月] を選択する場合は、頻度も指定する必要があります。[カスタム] を選択して、より具体的な繰り返し頻度を作成することもできます。[オンデマンド] を選択した場合、手動で転送をトリガーしたときにのみ、このデータ転送が実行されます。
必要に応じて、[すぐに開始] を選択するか、[設定した時刻に開始] を選択して開始日と実行時間を指定します。
[転送先の設定] セクションの [宛先データセット] で、データを保存するために作成したデータセット ID を選択します。

[データソースの詳細] セクションで、次の操作を行います。
- [宛先テーブル] に、BigQuery でデータを保存するために作成したテーブルの名前を入力します。宛先テーブルの名前では、パラメータがサポートされています。
- [Amazon S3 URI] に、
s3://mybucket/myfolder/...の形式で URI を入力します。URI でもパラメータがサポートされています。 - [アクセスキー ID] に、アクセスキー ID を入力します。
- [シークレット アクセスキー] に、シークレット アクセスキーを入力します。
- [ファイル形式] で、データ形式を選択します。JSON(改行区切り)、CSV、Avro、Parquet、ORC のいずれかを選択できます。
- [書き込み処理] で、次のいずれかを選択します。
WRITE_APPEND: 既存の宛先テーブルに新しいデータを段階的に追加します。WRITE_APPENDは、書き込み設定のデフォルト値です。WRITE_TRUNCATE: 各データ転送の実行時に宛先テーブル内のデータを上書きします。
BigQuery Data Transfer Service が
WRITE_APPENDまたはWRITE_TRUNCATEを使用してデータを取り込む方法の詳細については、Amazon S3 転送のデータ取り込みをご覧ください。writeDispositionフィールドの詳細については、JobConfigurationLoadをご覧ください。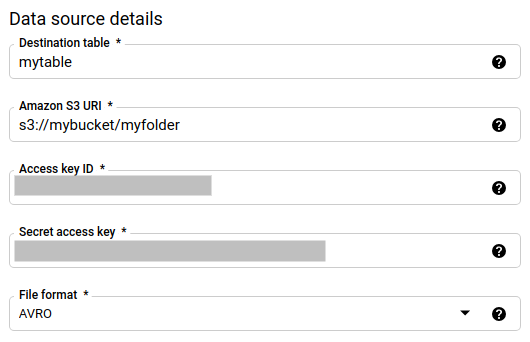
[Transfer Options] の [All Formats] セクションでは、以下のように設定します。
- [Number of errors allowed] に、無視できる不良レコードの最大数にあたる整数値を入力します。
- (省略可)[Decimal target types] に、ソースの 10 進数値を変換できる、有効な SQL データ型のカンマ区切りのリストを入力します。変換にどの SQL データ型を選択するかは、次の条件によって決まります。
- 変換に選択したデータ型は、ソースデータの精度とスケールをサポートする次のリスト内の最初のデータ型になります。順序は NUMERIC、BIGNUMERIC、STRING の順になります。
- リストされたデータ型が精度とスケールをサポートしていない場合は、指定されたリストの最も広い範囲をサポートするデータ型が選択されます。ソースデータの読み取り時に、値がサポートされている範囲を超えると、エラーがスローされます。
- データ型 STRING では、すべての精度とスケールの値がサポートされています。
- このフィールドが空の場合、ORC ではデータ型はデフォルトで「NUMERIC、STRING」、その他のファイル形式では「NUMERIC」になります。
- このフィールドに重複するデータ型を含めることはできません。
- このフィールドでリストするデータ型の順序は無視されます。

ファイル形式として CSV または JSON を選択した場合、スキーマに適合しない値を含んだ行を許容するには、[JSON, CSV] セクションで [Ignore unknown values] をオンにします。こうすると、不明な値は無視されるようになります。CSV ファイルでは、行の末尾の余分な値も無視されます。

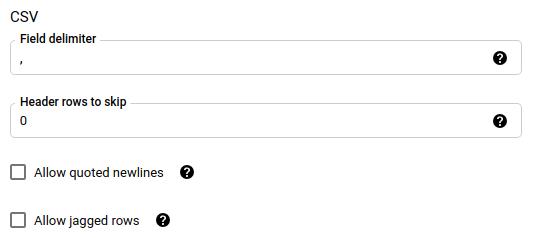
ファイル形式として CSV を選択した場合は、[CSV] セクションでデータを読み込むための追加の CSV オプションを入力します。
[サービス アカウント] メニューで、Google Cloud プロジェクトに関連付けられているサービス アカウントからサービス アカウントを選択します。ユーザー認証情報を使用する代わりに、サービス アカウントをデータ転送に関連付けることができます。データ転送でサービス アカウントを使用する方法の詳細については、サービス アカウントの使用をご覧ください。
- フェデレーション ID でログインした場合、データ転送を作成するにはサービス アカウントが必要です。Google アカウントでログインした場合、データ転送用のサービス アカウントは省略可能です。
- サービス アカウントには必要な権限が付与されている必要があります。
(省略可)[通知オプション] セクションで、次の操作を行います。
[保存] をクリックします。
bq
bq mk コマンドを入力して、転送作成フラグ --transfer_config を指定します。
bq mk \ --transfer_config \ --project_id=project_id \ --data_source=data_source \ --display_name=name \ --target_dataset=dataset \ --service_account_name=service_account \ --params='parameters'
ここで
- project_id: 省略可。 Google Cloud : 実際のプロジェクト ID。
--project_idで特定のプロジェクトを指定しない場合は、デフォルトのプロジェクトが使用されます。 - data_source: 必須。データソース
amazon_s3を指定します。 - display_name: 必須。データ転送構成の表示名を指定します。転送名には、後で修正が必要になった場合に識別できる任意の名前を使用できます。
- dataset: 必須。データ転送構成のターゲット データセットを指定します。
- service_account: データ転送の認証に使用されるサービス アカウント名を指定します。サービス アカウントは、データ転送の作成に使用した
project_idが所有している必要があります。また、必要な権限がすべて付与されている必要があります。 parameters: 必須。作成される転送構成のパラメータを JSON 形式で指定します。(例:
--params='{"param":"param_value"}')。Amazon S3 転送のパラメータは次のとおりです。- destination_table_name_template: 必須。宛先テーブルの名前を指定します。
data_path: 必須。次の形式で Amazon S3 URI を指定します。
s3://mybucket/myfolder/...URI でもパラメータがサポートされています。
access_key_id: 必須。アクセスキー ID を指定します。
secret_access_key: 必須。シークレット アクセスキーを指定します。
file_format: 省略可。転送するファイルの種類(
CSV、JSON、AVRO、PARQUET、ORC)を指定します。デフォルト値はCSVです。write_disposition: 省略可。
WRITE_APPENDは、前回の転送実行後に変更されたファイルのみを転送します。WRITE_TRUNCATEは、前回の実行時に転送されたファイルを含む、すべての一致ファイルを転送します。デフォルトはWRITE_APPENDです。max_bad_records: 省略可。許可する不良レコードの数を指定します。デフォルトは
0です。decimal_target_types: 省略可。ソースの 10 進数値を変換できる、有効な SQL データ型のカンマ区切りのリストを指定します。このフィールドが指定されていない場合、デフォルトのデータ型は ORC では「NUMERIC、STRING」、その他のファイル形式では「NUMERIC」になります。
ignore_unknown_values: 省略可。file_format が
JSONまたはCSVでない場合は無視されます。データ内の不明な値を無視するかどうかを指定します。field_delimiter: 省略可。
file_formatがCSVの場合にのみ適用されます。フィールドを区切る文字を指定します。デフォルト値はカンマ(,)です。skip_leading_rows: 省略可。file_format が
CSVの場合にのみ適用されます。インポートの対象外にするヘッダー行の数を指定します。デフォルト値は0です。allow_quoted_newlines: 省略可。file_format が
CSVの場合にのみ適用されます。引用符で囲まれたフィールド内で改行を許可するかどうかを指定します。allow_jagged_rows: 省略可。file_format が
CSVの場合にのみ適用されます。末尾のオプションの列が欠落している行を許可するかどうかを指定します。欠落した値には NULL が入力されます。
たとえば、次のコマンドは、data_path の値に s3://mybucket/myfile/*.csv を使用し、ターゲット データセットとして mydataset、file_format として CSV を指定した、My Transfer という名前の Amazon S3 データ転送を作成します。この例では、file_format の CSV 値に関連するオプションのパラメータとして、デフォルト以外の値を使用しています。
このデータ転送はデフォルトのプロジェクトで作成されます。
bq mk --transfer_config \
--target_dataset=mydataset \
--display_name='My Transfer' \
--params='{"data_path":"s3://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"write_disposition":"WRITE_APPEND",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false"}' \
--data_source=amazon_s3
コマンドを実行すると、次のようなメッセージが表示されます。
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
指示に従って、認証コードをコマンドラインに貼り付けます。
API
projects.locations.transferConfigs.create メソッドを使用して、TransferConfig リソースのインスタンスを指定します。
Java
このサンプルを試す前に、クライアント ライブラリを使用した BigQuery クイックスタートにある Java の設定手順を完了してください。詳細については、BigQuery Java API のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、クライアント ライブラリの認証情報を設定するをご覧ください。
プレフィックス マッチングまたはワイルドカード マッチングの影響
Amazon S3 API では、プレフィックス マッチングはサポートされていますが、ワイルドカード マッチングはサポートされていません。プレフィックスに一致するすべての Amazon S3 ファイルは Google Cloudに転送されます。ただし、実際に BigQuery に読み込まれるのは、転送構成の Amazon S3 URI に一致するファイルのみです。これにより、転送はされても BigQuery に読み込まれていないファイルにより、Amazon S3 アウトバウンド データ転送のコストが過剰になる可能性があります。
たとえば、次のデータパスを考えてみます。
s3://bucket/folder/*/subfolder/*.csv
ソースのロケーションには次のファイルがあります。
s3://bucket/folder/any/subfolder/file1.csv
s3://bucket/folder/file2.csv
この場合、プレフィックスが s3://bucket/folder/ のすべての Amazon S3 ファイルが Google Cloudに転送されます。この例では、file1.csv と file2.csv の両方が転送されます。
ただし、実際に BigQuery に読み込まれるのは、s3://bucket/folder/*/subfolder/*.csv に一致するファイルのみです。この例では、file1.csv だけが BigQuery に読み込まれます。
転送の設定に関するトラブルシューティング
データ転送の設定に問題がある場合は、Amazon S3 の転送に関する問題をご覧ください。
次のステップ
- Amazon S3 データ転送の概要については、Amazon S3 転送の概要をご覧ください。
- BigQuery Data Transfer Service の概要については、BigQuery Data Transfer Service の概要をご覧ください。
- 転送構成に関する情報の取得、転送構成の一覧表示、転送の実行履歴の表示など、データ転送の使用方法については、転送の操作をご覧ください。
- クロスクラウド オペレーションでデータを読み込む方法を学習する。