変更データ キャプチャを使用してテーブル更新をストリーミングする
BigQuery 変更データ キャプチャ(CDC)は、ストリーミングされた変更を処理して既存のデータに適用することで、BigQuery テーブルを更新します。この同期は、BigQuery Storage Write API によってリアルタイムでストリーミングされる行の upsert オペレーションと削除オペレーションを介して行われます。作業を進める前にこれをよく理解しておく必要があります。
始める前に
このドキュメントの各タスクの実行に必要な権限をユーザーに与える、Identity and Access Management(IAM)ロールを付与します。また、ワークフローがそれぞれの前提条件を満たしていることを確認します。
必要な権限
Storage Write API の使用に必要な権限を取得するには、BigQuery データ編集者(roles/bigquery.dataEditor)IAM ロールを付与するよう管理者に依頼してください。ロールの付与については、プロジェクト、フォルダ、組織に対するアクセス権の管理をご覧ください。
この事前定義ロールには、Storage Write API を使用するのに必要な bigquery.tables.updateData 権限が含まれています。
カスタムロールや他の事前定義ロールを使用して、この権限を取得することもできます。
BigQuery における IAM ロールと権限の詳細については、IAM の概要をご覧ください。
前提条件
BigQuery CDC を使用するには、ワークフローが次の条件を満たしている必要があります。
- デフォルト ストリームで Storage Write API を使用する必要があります。
- 取り込み形式として protobuf 形式を使用する必要があります。Apache Arrow 形式はサポートされていません。
- BigQuery 内の宛先テーブルの主キーを宣言する必要があります。最大 16 列を含む複合主キーがサポートされています。
- CDC の行オペレーションを実行するには、十分な BigQuery コンピューティング リソースを利用できる必要があります。CDC の行変更オペレーションが失敗した場合、削除されるはずだったデータが意図せずに保持される場合があることにご注意ください。詳細については、削除されるデータに関する考慮事項をご覧ください。
既存のレコードに対する変更を指定する
BigQuery CDC における疑似列 _CHANGE_TYPE は、各行で処理される変更の種類を示します。CDC を使用するには、Storage Write API を使用して行の変更をストリーミングする際に _CHANGE_TYPE を設定します。疑似列 _CHANGE_TYPE は、値 UPSERT と DELETE のみを受け入れます。Storage Write API がこの方法で行の変更をテーブルにストリーミングしている間は、このテーブルは CDC 対応とみなされます。
UPSERT と DELETE の値の例
BigQuery の次のテーブルについて考えます。
| ID | 名前 | 給与 |
|---|---|---|
| 100 | Charlie | 2000 |
| 101 | Tal | 3000 |
| 102 | Lee | 5000 |
次の行変更が Storage Write API によってストリーミングされます。
| ID | 名前 | 給与 | _CHANGE_TYPE |
|---|---|---|---|
| 100 | DELETE | ||
| 101 | Tal | 8000 | UPSERT |
| 105 | Izumi | 6000 | UPSERT |
ここで、更新されたテーブルは次のようになります。
| ID | 名前 | 給与 |
|---|---|---|
| 101 | Tal | 8000 |
| 102 | Lee | 5000 |
| 105 | Izumi | 6000 |
テーブルの未更新を管理する
デフォルトでは、クエリを実行するたびに BigQuery は最新の結果を返します。CDC が有効になっているテーブルのクエリ時に最新の結果を提供するには、クエリ開始時間までにストリーミングされたそれぞれの行変更を BigQuery が適用する必要があります。これにより、テーブルの最新バージョンに対してクエリが実行されるようになります。クエリの実行時にこれらの行変更を適用すると、クエリのレイテンシと費用が増加します。一方、完全に最新な状態のクエリ結果を必要としない場合は、テーブルに max_staleness オプションを設定することでクエリの費用とレイテンシを削減できます。このオプションを設定すると、BigQuery は max_staleness 値で定義された間隔内に行変更を少なくとも 1 回適用します。したがって更新が適用されるのを待つ必要がなくなる反面、一部のデータは未更新のままになります。
この動作は、データの「新鮮さ」が必須ではないダッシュボードとレポートで特に役立ちます。また、BigQuery で行変更を適用する頻度をより細かく管理できるので、費用管理にも役立ちます。
max_staleness オプションを設定してテーブルにクエリを実行する
max_staleness オプションを設定してテーブルをクエリすると、BigQuery は max_staleness の値および(テーブルの upsert_stream_apply_watermark タイムスタンプで表される)最後の適用ジョブ発生時刻に基づいて結果を返します。
次の例では、テーブルの max_staleness オプションが 10 分に設定されていて、最新の適用ジョブが時刻 T20 で発生しました。
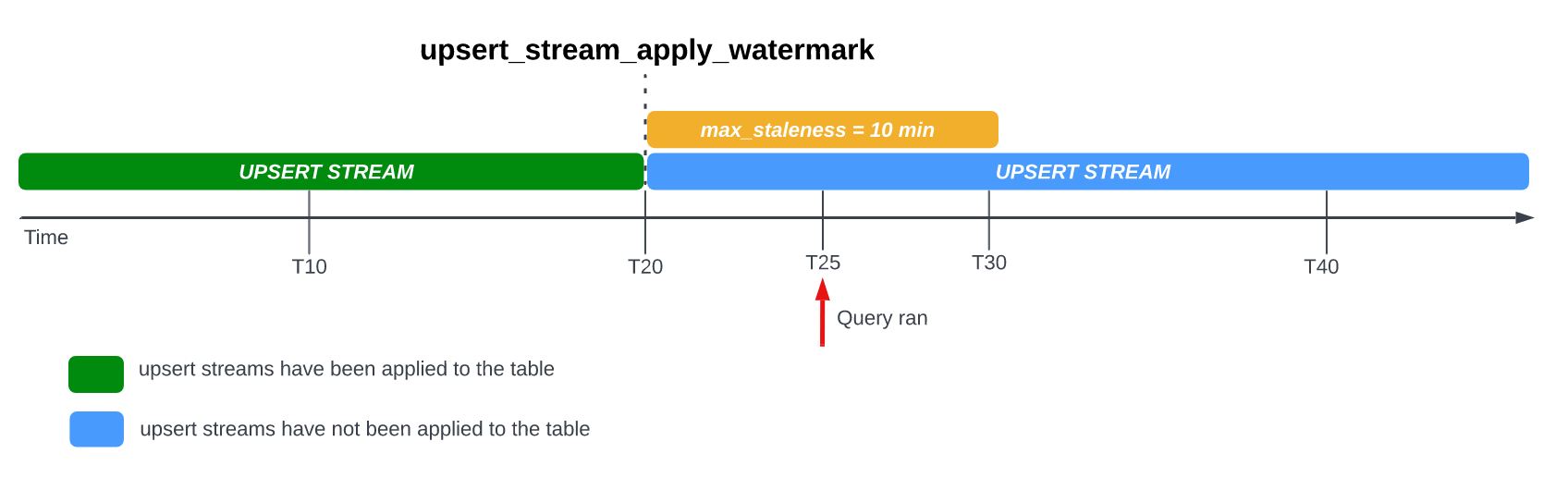
時刻 T25 にテーブルをクエリした場合、現在のバージョンのテーブルは 5 分間にわたり未更新状態で、これは max_staleness 間隔(10 分)未満です。この場合、BigQuery は T20 時点のテーブルのバージョンを返します。つまり、返されるデータも 5 分間にわたり未更新状態です。
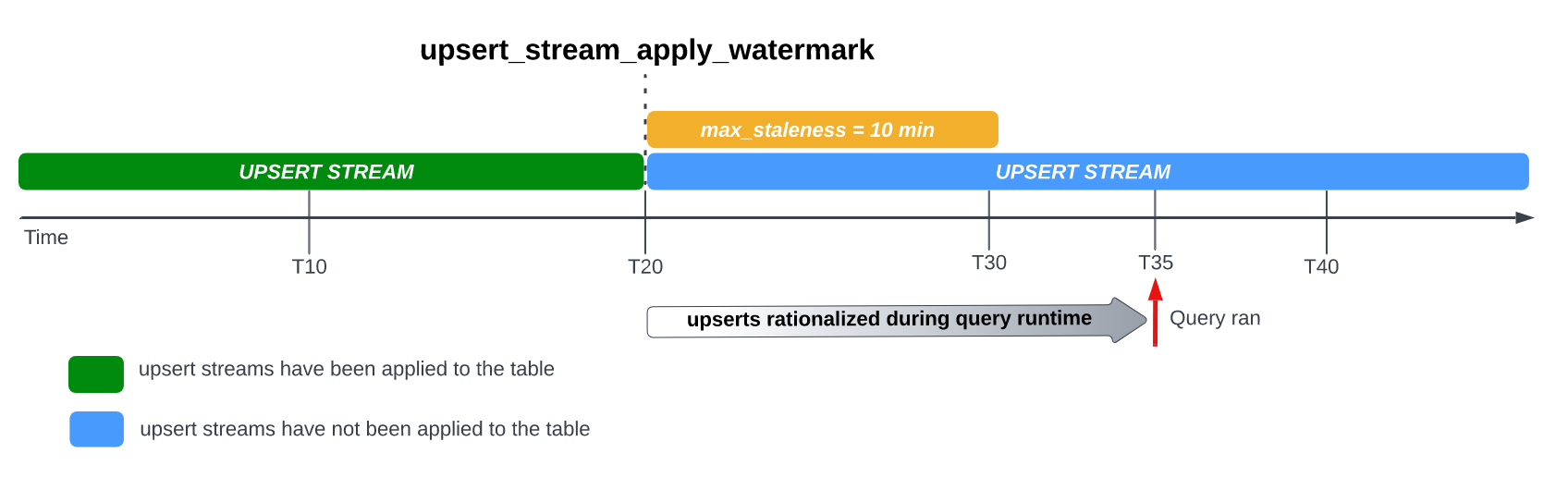
テーブルの max_staleness オプションを設定すると、BigQuery は max_staleness 間隔の中で少なくとも 1 回、保留中の行変更を適用します。ただし BigQuery では、これらの保留中の行変更を適用するプロセスがこの間隔内に完了しない可能性があります。
たとえば、T35 でテーブルをクエリした場合、保留中の行変更を適用するプロセスがまだ未完了であれば、テーブルの現在のバージョンは 15 分間にわたって未更新状態で、max_staleness 間隔(10 分間)より大きくなります。この場合、クエリの実行時に BigQuery は T20 と T35 の間にあるすべての行変更を現在のクエリに適用します。これにより、クエリされたデータが最新の状態になりますが、追加のクエリ レイテンシが発生します。これはランタイム マージジョブとみなされます。
テーブルで推奨される max_staleness 値
通常、テーブルの max_staleness 値は、次の 2 つの値のうち大きい方です。
- ワークフローでデータ未更新状態が許容される最大時間。
- upsert された変更をテーブルに適用するのにかかる最大時間を 2 倍して、多少のバッファを加えた時間。
upsert された変更を既存のテーブルに適用するのにかかる時間を計算するには、次の SQL クエリを使用して、バックグラウンド適用ジョブの 95 パーセンタイル時間を求めます。これに、書き込み最適化された BigQuery ストレージ(ストリーミング バッファ)のコンバージョン用として 7 分のバッファを加えます。
SELECT project_id, destination_table.dataset_id, destination_table.table_id, APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)] AS p95_background_apply_duration_in_seconds, CEILING(APPROX_QUANTILES((TIMESTAMP_DIFF(end_time, creation_time,MILLISECOND)/1000), 100)[OFFSET(95)]*2/60)+7 AS recommended_max_staleness_with_buffer_in_minutes FROM `region-REGION`.INFORMATION_SCHEMA.JOBS AS job WHERE project_id = 'PROJECT_ID' AND DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE "%cdc_background%" GROUP BY 1,2,3;
次のように置き換えます。
REGION: プロジェクトが配置されているリージョン名(例:us)。PROJECT_ID: BigQuery CDC によって変更される BigQuery テーブルを含むプロジェクトの ID。
バックグラウンド適用ジョブの期間は、データ未更新間隔内に発行される CDC オペレーションの数と複雑さ、テーブルサイズ、BigQuery リソースの可用性など、いくつかの要因に影響されます。リソースの可用性の詳細については、BACKGROUND 予約のサイズとモニタリングをご覧ください。
max_staleness オプションを使用してテーブルを作成する
max_staleness オプションを使用してテーブルを作成するには、CREATE TABLE ステートメントを使用します。次の例では、max_staleness 上限が 10 分に設定されたテーブル employees を作成します。
CREATE TABLE employees ( id INT64 PRIMARY KEY NOT ENFORCED, name STRING) CLUSTER BY id OPTIONS ( max_staleness = INTERVAL 10 MINUTE);
既存のテーブルの max_staleness オプションを変更する
既存のテーブルで max_staleness の上限を追加または変更するには、ALTER TABLE ステートメントを使用します。次の例では、employees テーブルの max_staleness 上限を 15 分に変更します。
ALTER TABLE employees SET OPTIONS ( max_staleness = INTERVAL 15 MINUTE);
テーブルの現在の max_staleness 値を特定する
テーブルの現在の max_staleness 値を判別するには、INFORMATION_SCHEMA.TABLE_OPTIONS ビューに対してクエリを実行します。次の例では、テーブル mytable の現在の max_staleness 値を確認します。
SELECT option_name, option_value FROM DATASET_NAME.INFORMATION_SCHEMA.TABLE_OPTIONS WHERE option_name = 'max_staleness' AND table_name = 'TABLE_NAME';
次のように置き換えます。
DATASET_NAME: CDC が有効になったテーブルが存在するデータセットの名前。TABLE_NAME: CDC が有効になったテーブルの名前。
結果から、max_staleness の値は 10 分であることがわかります。
+---------------------+--------------+ | Row | option_name | option_value | +---------------------+--------------+ | 1 | max_staleness | 0-0 0 0:10:0 | +---------------------+--------------+
テーブルの upsert オペレーションの進行状況をモニタリングする
テーブルの状態をモニタリングし、行変更が最後に適用されたのがいつかを確認するには、INFORMATION_SCHEMA.TABLES ビューに対してクエリを実行して upsert_stream_apply_watermark タイムスタンプを取得します。
次の例では、テーブル mytable の upsert_stream_apply_watermark 値を確認します。
SELECT upsert_stream_apply_watermark FROM DATASET_NAME.INFORMATION_SCHEMA.TABLES WHERE table_name = 'TABLE_NAME';
次のように置き換えます。
DATASET_NAME: CDC が有効になったテーブルが存在するデータセットの名前。TABLE_NAME: CDC が有効になったテーブルの名前。
次のような結果になります。
[{
"upsert_stream_apply_watermark": "2022-09-15T04:17:19.909Z"
}]
upsert オペレーションは bigquery-adminbot@system.gserviceaccount.com サービス アカウントで実行され、CDC 対応テーブルを含むプロジェクトのジョブ履歴に表示されます。
カスタム順序指定を管理する
BigQuery に upsert をストリーミングする場合、同じ主キーを持つレコードを並べ替えるデフォルトの動作は、レコードが BigQuery に取り込まれた BigQuery のシステム時間によって決まります。つまり、最新のタイムスタンプで取り込まれたレコードは、以前のタイムスタンプで取り込まれたレコードよりも優先されます。ただし、短時間に同じプライマリキーに対する upsert が頻繁に発生したり、upsert の順序が保証されていない場合など、この方法では十分でないユースケースもあります。このようなシナリオでは、ユーザー指定の順序キーが必要になる場合があります。
ユーザー指定の順序指定キーを構成するには、疑似列 _CHANGE_SEQUENCE_NUMBER を使用して、BigQuery がレコードに適用する順序を指定します。同じプライマリキーを持つ 2 つの一致するレコードのうち、_CHANGE_SEQUENCE_NUMBER の大きいほうが優先されます。疑似列 _CHANGE_SEQUENCE_NUMBER は省略可能な列であり、固定形式 STRING 型の値のみを受け入れます。
_CHANGE_SEQUENCE_NUMBER 形式
疑似列 _CHANGE_SEQUENCE_NUMBER は、固定形式で記述された STRING 型の値のみを受け入れます。この固定形式では、16 進数で記述された STRING 型の値を使用し、スラッシュ / でセクションを区切ります。各セクションは最大 16 個の 16 進数文字で表すことができ、_CHANGE_SEQUENCE_NUMBER ごとに最大 4 つのセクションを使用できます。_CHANGE_SEQUENCE_NUMBER の許容範囲は、0/0/0/0~FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF/FFFFFFFFFFFFFFFF の値です。_CHANGE_SEQUENCE_NUMBER 値は、大文字と小文字の両方に対応しています。
基本的な順序指定キーは、単一のセクションで表現できます。たとえば、アプリケーション サーバーからのレコードの処理タイムスタンプのみを基準にキーを並べ替えるには、1 つのセクション('2024-04-30 11:19:44 UTC')を使用します。この場合、タイムスタンプをエポック(この場合は '18F2EBB6480')からミリ秒に変換して 16 進数で表します。データを 16 進数に変換するロジックは、Storage Write API を使用して BigQuery への書き込みを行うクライアント側で処理します。
複数のセクションをサポートすることで、複数の処理ロジック値を 1 つのキーにまとめ、より複雑なユースケースに対応できます。たとえば、アプリケーション サーバーからのレコードの処理タイムスタンプ、ログのシーケンス番号、レコードのステータスに基づいてキーを並べ替えるには、3 つのセクション '2024-04-30 11:19:44 UTC' / '123' / 'complete' を使用します。各セクションは 16 進数で表します。セクションの順序は、処理ロジックのランク付けで重要な考慮事項となります。BigQuery は、最初のセクションを比較して _CHANGE_SEQUENCE_NUMBER 値を比較し、前のセクションが等しい場合にのみ次のセクションを比較します。
BigQuery は _CHANGE_SEQUENCE_NUMBER を使用して、2 つ以上の _CHANGE_SEQUENCE_NUMBER フィールドを符号なし数値として比較し、並べ替えを行います。
次の _CHANGE_SEQUENCE_NUMBER を比較した例とその優先度の結果について考えてみましょう。
例 1:
- レコード #1:
_CHANGE_SEQUENCE_NUMBER= '77' - レコード #2:
_CHANGE_SEQUENCE_NUMBER= '7B'
結果: 7B > 77(123 > 119)であるため、レコード 2 が最新のレコードと見なされます。
- レコード #1:
例 2:
- レコード #1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/B' - レコード 2:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC'
結果: FFF/ABC' > 'FFF/B'('4095/2748' > '4095/11')であるため、レコード #2 が最新のレコードと見なされます。
- レコード #1:
例 3:
- レコード #1:
_CHANGE_SEQUENCE_NUMBER= 'BA/FFFFFFFF' - レコード #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
結果: 'ABC' > 'BA/FFFFFFFF'('2748' > '186/4294967295')であるため、レコード #2 が最新のレコードと見なされます。
- レコード #1:
例 4:
- レコード 1:
_CHANGE_SEQUENCE_NUMBER= 'FFF/ABC' - レコード #2:
_CHANGE_SEQUENCE_NUMBER= 'ABC'
結果: 'FFF/ABC' > 'ABC'('4095/2748' > '2748')であるため、レコード #1 が最新のレコードと見なされます。
- レコード 1:
2 つの _CHANGE_SEQUENCE_NUMBER 値が同じ場合、BigQuery システムの最新の取り込み時刻を持つレコードが、以前に取り込んだレコードよりも優先されます。
テーブルにカスタム順序指定を使用する場合は、常に _CHANGE_SEQUENCE_NUMBER 値を指定する必要があります。_CHANGE_SEQUENCE_NUMBER 値を指定しない書き込みリクエストは、_CHANGE_SEQUENCE_NUMBER 値のある行とない行が混在することになり、順序が予測できなくなります。
CDC で使用する BigQuery 予約を設定する
BigQuery 予約を使用すると、CDC 行変更オペレーション専用の BigQuery コンピューティング リソースを割り当てることができます。予約では、これらのオペレーション実行の費用に上限を設定できます。この手法は、大規模なテーブルに対して頻繁に CDC オペレーションを行うワークフローで特に役立ちます。この方法を用いない場合、各オペレーションの実行時に処理されるバイト数が多くなり、オンデマンド費用が多くなります。
max_staleness 間隔内で保留中の行変更を適用する BigQuery CDC ジョブは、バックグラウンド ジョブと見なされ、QUERY 割り当てタイプではなく BACKGROUND 割り当てタイプを使用します。一方、max_staleness 間隔外のクエリのうち、クエリ実行時に行変更を適用する必要があるものは、QUERY 割り当てタイプを使用します。max_staleness が設定されていないテーブルや、max_staleness が 0 に設定されているテーブルでも、QUERY 割り当てタイプが使用されます。BACKGROUND 割り当てなしで実行される BigQuery CDC バックグラウンド ジョブには、オンデマンド料金が適用されます。この考慮事項は、BigQuery CDC のワークロード管理戦略を設計する際に重要です。
CDC で使用する BigQuery 予約を構成するには、まず BigQuery テーブルが配置されているリージョンで予約を設定します。予約のサイズに関するガイダンスについては、BACKGROUND 予約のサイズ設定とモニタリングをご覧ください。予約を作成したら、予約に BigQuery プロジェクトを割り当て、次の CREATE ASSIGNMENT ステートメントを実行して job_type オプションを BACKGROUND に設定します。
CREATE ASSIGNMENT `ADMIN_PROJECT_ID.region-REGION.RESERVATION_NAME.ASSIGNMENT_ID` OPTIONS ( assignee = 'projects/PROJECT_ID', job_type = 'BACKGROUND');
次のように置き換えます。
ADMIN_PROJECT_ID: 予約を所有する管理プロジェクトの ID。REGION: プロジェクトが配置されているリージョン名(例:us)。RESERVATION_NAME: 予約の名前。ASSIGNMENT_ID: 割り当ての ID。ID はプロジェクトとロケーションごとに一意でなければならず、先頭と末尾を英小文字または数字にする必要があり、英小文字、数字、ダッシュのみを使用できます。PROJECT_ID: BigQuery CDC によって変更される BigQuery テーブルを含むプロジェクトの ID。このプロジェクトは予約に割り当てられます。
BACKGROUND 予約のサイズ設定とモニタリング
予約によって、BigQuery のコンピューティング オペレーションの実行に使用できるコンピューティング リソースの量が決まります。予約のサイズが小さすぎると、CDC の行変更オペレーションの処理時間が長くなることがあります。予約のサイズを正確に設定するには、INFORMATION_SCHEMA.JOBS_TIMELINE ビューに対するクエリを実行することで、CDC オペレーションを実行するプロジェクトの過去のスロット消費量をモニタリングします。
SELECT period_start, SUM(period_slot_ms) / (1000 * 60) AS slots_used FROM region-REGION.INFORMATION_SCHEMA.JOBS_TIMELINE_BY_PROJECT WHERE DATE(job_creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY) AND CURRENT_DATE() AND job_id LIKE '%cdc_background%' GROUP BY period_start ORDER BY period_start DESC;
REGION は、プロジェクトが存在するリージョン名に置き換えます。例: us。
削除されるデータに関する考慮事項
- BigQuery CDC オペレーションでは、BigQuery のコンピューティング リソースを使用します。オンデマンド課金を使用するように CDC オペレーションが構成されている場合、CDC オペレーションは内部 BigQuery リソースを使用して定期的に実行されます。一方、
BACKGROUND予約を使って CDC オペレーションが構成されている場合、CDC オペレーションは構成済みの予約のリソース可用性に影響されます。構成した予約の中に十分なリソースがない場合、削除を含む CDC オペレーションの処理に予想よりも時間がかかることがあります。 - CDC
DELETEオペレーションが適用済みと見なされるのは、upsert_stream_apply_watermarkタイムスタンプが、Storage Write API によるオペレーション ストリーミング時のタイムスタンプを過ぎた場合だけです。upsert_stream_apply_watermarkタイムスタンプの詳細については、テーブル upsert オペレーションの進行状況をモニタリングするをご覧ください。 - 順不同で届く CDC
DELETEを適用するため、BigQuery では 2 日間の削除保持期間を設定しています。標準の Google Cloud データ削除プロセスが開始されるまでは、この期間中、テーブルDELETEオペレーションが保持されます。削除保持期間内のDELETEオペレーションには、標準の BigQuery ストレージの料金が適用されます。
制限事項
- BigQuery CDC ではキーの適用が行われませんから、主キーを一意にすることは重要です。
- 主キーは 16 列を超えてはなりません。
- CDC 対応テーブルでは、テーブルのスキーマで定義された最上位列を 2,000 個を超えて指定できません。
- CDC 対応テーブルは、次のものをサポートしていません。
DELETE、UPDATE、MERGEなどのデータ操作言語(DML)ステートメントの変更- ワイルドカード テーブルのクエリ
- 検索インデックス
- ランタイム マージジョブを実行する CDC 対応テーブルでは、テーブルの
max_staleness値が小さすぎるため、以下をサポートできません。 - CDC 対応テーブルに対する BigQuery エクスポート オペレーションでは、(バックグラウンド ジョブでまだ適用されていない)最近ストリーミングされた行変更がエクスポートされません。テーブル全体をエクスポートするには、
EXPORT DATAステートメントを使用します。 - パーティション分割テーブルに対するランタイム マージがクエリによってトリガーする場合、クエリが一部のパーティションに限定されているかどうかにかかわらず、テーブル全体がスキャンされます。
- Standard Edition を使用している場合は、
BACKGROUND予約が利用可能でないため、保留中の行変更を適用するとオンデマンド料金モデルが使用されます。ただし、どのエディションでも CDC 対応テーブルに対してクエリを実行できます。 - テーブル読み取りの実行時に、疑似列
_CHANGE_TYPEと_CHANGE_SEQUENCE_NUMBERはクエリ可能な列ではありません。 _CHANGE_TYPEにUPSERTまたはDELETEの値を持つ行と、_CHANGE_TYPEにINSERTまたは未指定の値を持つ行を同じ接続で混在させることはできません。混在すると、The given value is not a valid CHANGE_TYPEという検証エラーが発生します。
BigQuery CDC の料金
BigQuery CDC は、データの取り込みに Storage Write API、データ ストレージに BigQuery ストレージ、行変更オペレーションに BigQuery コンピューティングを使用し、これらのすべてに費用が発生します。料金については、BigQuery の料金をご覧ください。
BigQuery CDC の費用を見積もる
大量のデータ、低い max_staleness 構成、頻繁に変更されるデータを含むワークフローでは、BigQuery の費用見積もりに関する一般的なベスト プラクティスに加えて、BigQuery CDC の費用を見積もることが重要です。
BigQuery データの取り込みの料金と BigQuery ストレージの料金は、取り込んで保存するデータの量(疑似列を含む)で直接計算されます。ただし、BigQuery コンピューティングの料金は BigQuery CDC ジョブの実行に使用されるコンピューティング リソースの消費量に関連するため、この料金の見積もりが難しくなる場合があります。
BigQuery CDC ジョブは次の 3 つのカテゴリに分類されます。
- バックグラウンド適用ジョブ: テーブルの
max_staleness値により定義される一定の間隔でバックグラウンドで実行されるジョブ。これらのジョブは、最近ストリーミングされた行変更を CDC 対応テーブルに適用します。 - クエリジョブ:
max_stalenessウィンドウ内で実行され、CDC ベースライン テーブルからのみ読み取りを行う GoogleSQL クエリ。 - ランタイム マージジョブ:
max_stalenessウィンドウ外で実行されるアドホック GoogleSQL クエリによってトリガーされるジョブ。ランタイム マージジョブは、クエリ実行時に、CDC ベースライン テーブルと最近ストリーミングされた行変更のオンザフライ マージを実行する必要があります。
BigQuery のパーティショニングを利用するのはクエリジョブのみです。バックグラウンド適用ジョブとランタイム マージジョブはパーティショニングを使用できません。これは、最近ストリーミングされた行変更を適用するときに、最近ストリーミングされた upsert がどのテーブル パーティションに適用されるかが保証されないためです。つまり、バックグラウンド適用ジョブとランタイム マージジョブではベースライン テーブル全体が読み取られます。同じ理由で、BigQuery クラスタリング列のフィルタを利用できるのはクエリジョブのみです。CDC オペレーションを実行するために読み取られるデータの量を把握しておくと、合計費用を見積もる際に役立ちます。
テーブル ベースラインから読み取られるデータの量が多い場合は、処理されたデータの量に基づかない BigQuery の容量料金モデルの使用を検討してください。
BigQuery CDC の費用に関するベスト プラクティス
BigQuery の費用に関する一般的なベスト プラクティスに加えて、次の手法を使用して BigQuery CDC オペレーションの費用を最適化します。
- 必要な場合を除き、テーブルの
max_stalenessオプションを極端に低い値で構成しないでください。max_staleness値を使用すると、発生するバックグラウンド適用ジョブとランタイム マージジョブが増加する可能性があります。これらのジョブは、クエリジョブよりも費用が高く低速です。詳細なガイダンスについては、テーブルで推奨されるmax_staleness値をご覧ください。 - CDC テーブルで使用する BigQuery 予約を構成することを検討してください。この予約を構成しない場合、バックグラウンド適用ジョブとランタイム マージジョブはオンデマンド料金を使用しますが、データ処理量が増えるため、費用が高くなる可能性があります。詳細については、BigQuery の予約について確認し、BigQuery CDC で使用する
BACKGROUND予約のサイズ設定とモニタリングのガイダンスに沿って作業しください。
次のステップ
- Storage Write API のデフォルト ストリームを実装する方法ついて学習します。
- Storage Write API のベスト プラクティスについて学習します。
- BigQuery CDC で Datastream を使用してトランザクション データベースを BigQuery にレプリケートする方法について学習します。