Cette section du framework d'architecture explique que l'excellence opérationnelle se traduit par l'efficacité de l'exécution, de la gestion et de la surveillance des systèmes offrant une valeur commerciale.
Le framework comprend les articles suivants :
- Présentation
- Considérations liées à la conception du système Google Cloud
- Excellence opérationnelle (cet article)
- Sécurité, confidentialité et conformité
- Fiabilité
- Optimisation des performances et des coûts
L'excellence opérationnelle vous permet de poser les bases d'un autre principe essentiel : la fiabilité. (Consultez la section Fiabilité pour connaître les exigences techniques et procédurales associées concernant la conception et l'utilisation de services fiables sur Google Cloud.)
Stratégies
Utilisez les stratégies ci-dessous pour atteindre l'excellence opérationnelle.
Automatisez la création, le test et le déploiement. Utilisez les pipelines d'intégration continue ou de déploiement continu (CI/CD) pour intégrer des tests automatisés à vos versions. Effectuez un déploiement et des tests d'intégration automatisés.
Surveillez les métriques liées aux objectifs commerciaux. Définissez, évaluez et envoyez des alertes concernant les métriques commerciales pertinentes.
Effectuez des tests de reprise après sinistre. N'attendez pas qu'un sinistre se produise. À l'inverse, vérifiez régulièrement que vos procédures de reprise après sinistre fonctionnent et testez-les régulièrement.
Bonnes pratiques
Suivez les pratiques ci-dessous pour atteindre l'excellence opérationnelle.
- Accélérez le développement logiciel et le processus de lancement.
- Surveillez l'état du système et de l'entreprise.
- Planifiez et concevez des solutions en cas de défaillances.
Les sections suivantes décrivent ces bonnes pratiques en détail.
Accélérer le développement et le processus de lancement
Améliorez la rapidité à l'aide d'une approche CI/CD. Commencez par améliorer la productivité de votre équipe de développement de logiciels et automatisez les tests d'intégration dans le processus de compilation. Vous devez automatiser le déploiement lorsque votre build répond aux critères de test spécifiques que vous avez définis. Vos développeurs peuvent effectuer des modifications plus petites de manière plus fréquente. Les modifications sont testées minutieusement et le temps de déploiement est réduit.
Cette section décrit les éléments d'une approche CI/CD : ingénierie des versions, automatisation, dépôts de code central, pipelines de compilation, tests et déploiement.
Ingénierie des versions
L'ingénierie des versions est un poste qui supervise la création et la livraison des logiciels. L'ingénierie des versions est régie par les quatre pratiques suivantes :
- Mode libre-service. Permet de définir des consignes pour aider les ingénieurs logiciels à éviter les erreurs courantes. Appliqué par des processus automatisés.
- Versions fréquentes. Une rapidité améliorée facilite le dépannage et la résolution des problèmes. Les versions fréquentes reposent sur des tests unitaires automatisés.
- Builds hermétiques. Permettent d'assurer la cohérence avec vos outils de compilation. Mettez à jour les compilateurs de build qui vous permettent de créer des builds aujourd'hui par rapport à ceux que vous utilisiez il y a un mois.
- Application des règles. Toutes les modifications nécessitent une vérification du code, idéalement sous la forme d'un ensemble de consignes et de règles destinées à la sécurité. Cela permet d'améliorer la vérification du code, le dépannage et les tests d'une nouvelle version.
Automatisation
Automatisez votre pipeline de compilation et de publication pour analyser les problèmes connus et effectuer des tests rapides. L'automatisation peut également vous permettre d'éliminer les tâches répétitives.
Dépôts de code central
Stockez votre code dans un dépôt central, versionné et étiqueté (par exemple, test, dev, prod) selon vos besoins. En suivant ces étapes, vous vous assurez que votre pipeline de compilation fournit des résultats cohérents. Dans Google Cloud, vous pouvez stocker votre code dans la version Cloud Source Repositories et l'intégrer à divers produits.
Pipelines de compilation
Mettez à jour votre configuration de compilation pour vous assurer que toutes vos builds sont cohérents et que vous pouvez effectuer un rollback vers la dernière configuration la plus connue si nécessaire. Dans Google Cloud, Cloud Build vous aide à définir des dépendances et des versions pour créer un package d'application. Vous pouvez vous servir de Cloud Functions pour déclencher un processus de compilation de manière régulière ou déclencher des builds sur des événements spécifiques lorsque du nouveau code est enregistré. À l'aide de Cloud Functions, vous pouvez également déclencher des tests et automatiser l'ensemble du pipeline.
Tests
Les tests constituent un élément essentiel d'un lancement réussi. Exemples de tests :
- Tests unitaires. Les tests unitaires sont rapides et vous permettent d'effectuer des déploiements rapides.
- Tests d'intégration. Ces tests peuvent devenir complexes lorsque vous testez l'intégration avec des services interconnectés.
- Tests du système. Les tests du système sont longs et complexes. Toutefois, ils vous aident à identifier les cas spéciaux et à résoudre les problèmes avant le déploiement.
Vous pouvez effectuer d'autres tests, y compris des tests statiques, des tests de charge ou encore des tests de sécurité avant de déployer votre application en production. Après avoir automatisé les tests, vous pouvez mettre à jour et ajouter des tests afin d'améliorer et de maintenir l'état opérationnel de votre déploiement.
Déploiement
Vous pouvez choisir le mode de déploiement de votre application. Il est recommandé d'effectuer des tests en version Canary et de rechercher d'éventuelles erreurs dans votre système, ce qui s'avère plus facile lorsque vous disposez d'un système de surveillance et d'alerte performant. Dans Google Cloud, les groupes d'instances gérés peuvent vous servir à mener des tests A/B ou des tests en version Canary, ainsi qu'à effectuer un déploiement lent ou un rollback si nécessaire.
Questions concernant la conception
- Comment votre équipe de développement gère-t-elle la compilation et le déploiement ?
- Quels tests d'intégration et de sécurité votre équipe de développement utilise-t-elle ?
- Comment effectuer un rollback ?
Recommandations
- Faites en sorte que le pipeline CI/CD soit le seul moyen de déployer en production.
- Isolez et sécurisez votre environnement CI/CD.
- Effectuez la compilation une seule fois et faites la promotion du résultat via le pipeline.
- Assurez la rapidité de vos pipelines CI/CD.
- Réduisez les branches dans votre système de contrôle des versions.
Principaux services
Cloud Source Repositories est un service de dépôt Git privé et complet, hébergé sur Google Cloud. Vous pouvez utiliser Cloud Source Repositories pour faciliter le développement collaboratif des applications ou des services.
Avec Container Registry, votre équipe dispose d'un outil centralisé qui lui permet de gérer les images Docker, d'analyser les failles et de définir avec une grande précision les droits d'accès de chaque utilisateur. Les intégrations CI/CD existantes vous offrent la possibilité de configurer des pipelines Docker entièrement automatisés afin de recevoir rapidement des retours.
Cloud Build est un service qui exécute vos builds sur l'infrastructure Google Cloud. Cloud Build peut importer un code source depuis GitHub, Bitbucket, Cloud Storage ou Cloud Source Repositories, exécuter une compilation selon vos spécifications et produire des artefacts, tels que des conteneurs Docker ou des archives Java.
Surveiller l'état du système et de l'entreprise
Le projet DORA (DevOps Resource and Analysis) définit la surveillance comme suit :
La surveillance consiste à collecter, analyser et utiliser des informations pour suivre les applications et l'infrastructure afin d'orienter les décisions commerciales. Fonction essentielle, la surveillance vous donne un aperçu de vos systèmes et de vos tâches.
La surveillance vous permet de prendre des décisions concernant l'impact des modifications apportées à votre service, d'appliquer la méthode scientifique à la gestion des incidents et d'évaluer la conformité de votre service par rapport à vos objectifs commerciaux. Une fois la surveillance activée, vous pouvez effectuer les opérations suivantes :
- Analyser les tendances à long terme.
- Comparer vos tests au fil du temps.
- Définir des alertes sur les métriques essentielles.
- Créer des tableaux de bord en temps réel pertinents.
- Effectuer des analyses rétrospectives.
Surveillez les métriques propres à l'entreprise et les métriques d'état du système. Les métriques propres à l'entreprise vous aident à comprendre dans quelle mesure vos systèmes répondent aux besoins de votre activité. Par exemple, vous pouvez surveiller le coût de diffusion d'un utilisateur dans une application, la variation du volume de trafic sur votre site à la suite d'une modification de la conception, ou le temps nécessaire à un client pour acheter un produit sur votre site. Les métriques d'état du système vous aident à déterminer si vos systèmes fonctionnent correctement et à des niveaux de performances acceptables.
Suivez les quatre signaux clés suivants pour surveiller votre système :
- Latence. Le temps nécessaire au traitement d'une requête.
- Trafic. La quantité de demandes sur votre système.
- Erreurs. Le taux de requêtes ayant échoué. Les requêtes peuvent échouer explicitement (par exemple, avec l'erreur HTTP 500s), implicitement (par exemple, avec la réponse positive HTTP 200 mais avec un contenu incorrect) ou en raison du non-respect de règles (par exemple, si vous vous engagez à fournir des temps de réponse d'une seconde, toute requête dont le temps de réponse est supérieur à une seconde sera considérée comme une erreur).
- Saturation. Le niveau d'occupation de votre service. Permet d'évaluer vos ressources les plus limitées. (Autrement dit, dans un système à mémoire limitée, c'est la mémoire qui s'affiche alors que dans un système à opérations E/S limitées, ce sont les opérations E/S qui s'affichent.)
Logging
Les services de journalisation sont essentiels à la surveillance de vos systèmes. Bien que les métriques constituent la base des éléments spécifiques à surveiller, les journaux contiennent des informations précieuses nécessaires au débogage, à l'analyse de la sécurité et aux exigences de conformité. Google Cloud inclut Cloud Logging, qui est un service de journalisation intégré permettant de stocker, interroger, analyser et surveiller les données et les événements de journalisation de Google Cloud, et d'envoyer des alertes si nécessaire. Cloud Logging collecte automatiquement les journaux des services Google Cloud. Ces journaux peuvent vous servir à créer des métriques pour la surveillance ainsi que des exportations de journaux vers des services externes, tels que Cloud Storage, BigQuery et Pub/Sub.
Métriques
Définissez des métriques pour évaluer le comportement de votre déploiement. Assurez-vous que vos définitions de métriques correspondent toujours aux besoins de l'entreprise, et envisagez de promouvoir ou de combiner certaines métriques pour former des indicateurs de niveau de service. Pour en savoir plus, consultez la section Fiabilité.
Tous les niveaux de votre service génèrent des métriques, depuis l'infrastructure et la mise en réseau jusqu'à la logique métier. Voici quelques exemples :
- Requêtes par seconde, telles qu'évaluées par l'équilibreur de charge.
- Nombre total de blocs de disques lus, par disque.
- Paquets envoyés via une interface réseau donnée.
- Taille du tas de mémoire pour un processus donné.
- Distribution des latences de réponse.
- Nombre de requêtes non valides rejetées par une instance de base de données.
Monitoring
Surveiller une application complexe est une opération d'ingénierie importante en soi. Cloud Monitoring est un service géré qui fait partie de la suite Google Cloud Operations. Cloud Monitoring vous offre la possibilité de surveiller les métriques personnalisées et les services Google Cloud. Il fournit également une API permettant l'intégration avec des outils de surveillance tiers.
Cloud Monitoring rassemble les métriques, journaux et événements de l'infrastructure, offrant ainsi aux développeurs et opérateurs un riche ensemble de signaux observables qui vous permettent de découvrir plus rapidement l'origine des problèmes et raccourcissent les délais moyens de résolution. Vous pouvez définir des alertes et des métriques personnalisées qui répondent à vos objectifs commerciaux et vous permettent d'agréger, de visualiser et de surveiller l'état de votre système.
Cloud Monitoring fournit des tableaux de bord configurés par défaut pour vos services applicatifs Open Source et cloud. Le modèle de métriques vous permet de définir des tableaux de bord personnalisés grâce à des outils de visualisation performants et de configurer des graphiques dans l'explorateur de métriques.
Tableaux de bord
Une fois la surveillance activée, créez des tableaux de bord pertinents pour prendre les mesures appropriées. Simplifiez la lecture de vos tableaux de bord. Vous devez effectuer des analyses à court terme (ou en temps réel) et à long terme, puis les visualiser. Pour en savoir plus, consultez la section Fiabilité.
Alertes
Assurez-vous que votre système d'alerte correspond directement aux quatre signaux clés de la surveillance de votre système, afin de pouvoir comparer les performances au fil du temps et déterminer la vitesse d'exécution ou effectuer un rollback des modifications.
Rendez les alertes exploitables. Lorsque vous envoyez des alertes, incluez une description et fournissez toutes les informations nécessaires pour que la personne chargée de résoudre le problème puisse agir immédiatement. Le traitement des alertes doit se faire rapidement, sans demander trop de clics, ni de recherches.
Essayez d'éliminer les tâches laborieuses, par exemple en supprimant ou en corrigeant les erreurs que vous rencontrez fréquemment. Cela permet à la personne chargée de résoudre le problème de se concentrer sur la fiabilité des composants opérationnels. Pour en savoir plus, consultez la section Fiabilité.
Processus de signalement
Un processus de signalement bien défini est essentiel pour réduire les efforts que vous consacrez à obtenir de l'aide pour les produits Google Cloud. Ce processus inclut la compréhension du fonctionnement de l'équipe d'assistance Google, la recherche de documents d'architecture adaptés aux ingénieurs de l'assistance, la définition du mode de communication en cas de panne, ainsi que la configuration de la surveillance et de la journalisation pour le diagnostic des problèmes.
Vous pouvez commencer à définir un processus de signalement en vous assurant que les administrateurs système, réseau et de sécurité sont correctement configurés pour recevoir les e-mails et les alertes importants de la part de Google Cloud. Cela permet aux administrateurs de prendre des décisions avisées et de résoudre les problèmes le plus rapidement possible. De même, assurez-vous que les propriétaires du projet disposent de noms d'utilisateur routables pour qu'ils puissent recevoir les e-mails importants.
Recommandations
- Choisissez des métriques pertinentes qui correspondent aux besoins de votre entreprise.
- Utilisez Cloud Monitoring et déployez des agents de surveillance pour les métriques personnalisées si nécessaire.
- Assurez-vous que Cloud Logging est configuré pour toutes vos entrées de journal.
- Créez des alertes bien définies, par exemple sous la forme d'un pourcentage d'opérations réussies ou échouées.
- Incluez des informations permettant de résoudre le problème dans vos alertes.
- Pensez à acheter une formule d'assistance Role-based ou Enterprise.
- Définissez un processus de signalement et fournissez des indicateurs utiles tels que l'heure, le produit et l'emplacement lorsque vous travaillez avec l'assistance Cloud.
Principaux services
Cloud Monitoring permet de collecter et de rassembler des métriques, ainsi que de consulter des tableaux de bord les concernant. Il fournit également un framework d'alerte et des vérifications de points de terminaison aux applications Web et à d'autres services accessibles sur Internet.
Cloud Logging vous permet de filtrer, interroger, afficher et exporter vers des journaux BigQuery, Cloud Storage ou Pub/Sub à partir de vos services applicatifs Open Source et cloud. Vous pouvez définir des métriques basées sur le contenu des journaux et les intégrer à vos tableaux de bord et alertes.
Cloud Debugger fait le lien entre les données de production de votre application et votre code source en inspectant l'état de votre application, quel que soit l'emplacement du code en production, sans interrompre ni ralentir l'exécution de vos requêtes d'application.
Error Reporting rassemble et analyse les erreurs produites par les applications cloud. Vous recevez des notifications lorsque de nouveaux problèmes sont décelés.
Cloud Trace fournit des échantillons de latence et des rapports à App Engine, y compris des statistiques concernant les URL et la répartition de la latence.
Cloud Profiler fournit un profilage continu de la consommation des ressources au sein de vos applications de production pour vous aider à identifier et éliminer tout problème de performances.
Ressources
Modèles de conception des exportations de journaux
Concevoir pour la reprise après sinistre
La conception de votre système en anticipant et en prévoyant la gestion des scénarios de défaillance permet de minimiser l'impact en cas de sinistre. Pour anticiper les défaillances, assurez-vous de disposer d'un plan de reprise après sinistre bien défini et faisant l'objet de tests réguliers afin de pouvoir sauvegarder et restaurer vos services et données.
Des événements d'interruption de service peuvent survenir à tout moment. Vous pouvez subir une panne de réseau, votre dernier déploiement d'application peut entraîner un bug critique ou vous pouvez être victime d'une catastrophe naturelle. En cas de problème, il est important de disposer d'un plan de reprise après sinistre solide, ciblé et bien testé.
Planifier
La reprise après sinistre est un sous-ensemble du plan de continuité d'activité. Elle commence par une analyse de l'impact métier qui définit deux métriques clés :
Un objectif de temps de récupération (RTO), qui correspond à la durée maximale acceptable pendant laquelle votre application peut être indisponible. Cette valeur est généralement définie dans le cadre d'un contrat de niveau de service plus vaste.
Un objectif de point de récupération (RPO), qui correspond à la durée maximale acceptable pendant laquelle votre application peut perdre des données en raison d'un incident majeur. Cette métrique varie en fonction de la manière dont les données sont utilisées. Par exemple, des données utilisateur régulièrement modifiées peuvent avoir un RPO de quelques minutes seulement. En revanche, des données moins critiques et rarement modifiées peuvent avoir un RPO de plusieurs heures. Cette métrique ne décrit que la durée, elle ne traite pas de la quantité, ni de la qualité des données perdues.
En règle générale, plus les valeurs de RTO et de RPO sont faibles (c'est-à-dire, plus votre application doit récupérer rapidement d'une interruption), plus les coûts d'exécution de votre application sont élevés. Le graphique suivant décrit le ratio entre les coûts et les valeurs RTO/RPO :
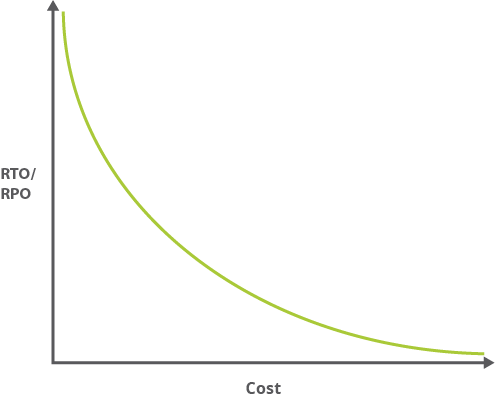
Comme des valeurs RTO et RPO plus faibles impliquent souvent davantage de complexité, les frais administratifs s'en voient également accrus. Par exemple, une application haute disponibilité peut nécessiter la gestion de la distribution entre deux centres de données séparés physiquement, la gestion de la réplication, etc.
Les valeurs RTO et RPO sont généralement regroupées dans une autre métrique : l'objectif de niveau de service (SLO), qui constitue un élément clé mesurable d'un contrat de niveau de service.
- Un contrat de niveau de service est un contrat intégral qui spécifie le service à fournir, la manière dont il est géré, ses heures, ses emplacements, ses coûts, ses performances, ses pénalités ainsi que les responsabilités des parties concernées.
- Les SLO sont quant à eux des caractéristiques spécifiques et mesurables du SLA, telles que la disponibilité, le débit, la fréquence, le temps de réponse ou la qualité.
Un même contrat de niveau de service peut contenir de nombreux SLO. Les RTO et les RPO sont mesurables et doivent être considérés comme des SLO.
Exigences en termes d'infrastructure
Dans les scénarios de reprise après sinistre, il est recommandé de tenir compte d'un certain nombre d'exigences, parmi lesquelles :
- Capacité : mobiliser suffisamment de ressources pour pouvoir s'adapter en fonction des besoins.
- Sécurité : assurer la sécurité physique pour protéger les ressources.
- Infrastructure réseau : intégrer des composants logiciels tels que des pare-feu et des équilibreurs de charge.
- Assistance : mettre à disposition des techniciens qualifiés pour la maintenance et la résolution des problèmes.
- Bande passante : prévoir une bande passante adaptée aux pics de charge.
- Installations : garantir une infrastructure physique, dont les équipements et l'énergie.
Reprise après sinistre sur Google Cloud
En comparaison avec une utilisation sur site, Google Cloud peut vous aider à réduire les coûts associés au respect des exigences RTO et RPO. Google Cloud vous aide à contourner la plupart ou la totalité des facteurs de complication liés au matériel physique, supprimant ainsi de nombreux coûts d'entreprise. En outre, l'accent mis par Google Cloud sur la simplicité administrative implique également une réduction des coûts de gestion liés aux applications complexes.
Google Cloud propose plusieurs fonctionnalités pertinentes pour la planification de la reprise après sinistre :
Réseau mondial. Nous possédons l'un des réseaux informatiques les plus étendus et les plus sophistiqués au monde. Le réseau backbone de Google fait appel à une technologie de mise en réseau avancée définie par logiciel et propose des services de mise en cache périphérique pour offrir des performances élevées, constantes et évolutives.
Redondance. La multiplicité de nos points de présence à travers le monde permet d'assurer une excellente redondance. Vos données sont automatiquement répliquées sur les appareils de stockage de plusieurs sites.
Évolutivité. Google Cloud est conçu pour évoluer comme d'autres produits Google, tels que la recherche et Gmail, même en cas de pic de trafic important. Les services gérés tels qu'App Engine, les autoscalers Compute Engine et Datastore vous offrent un scaling automatique qui permet à votre application d'augmenter ou de réduire sa capacité selon les besoins.
Sécurité : Notre modèle de sécurité est le fruit de plus de quinze ans d'expérience consacrés à protéger nos clients et nos applications telles que Gmail et Google Workspace. De plus, nos équipes d'ingénieurs chargés de la fiabilité des sites aident à garantir un niveau de haute disponibilité et à éviter toute utilisation abusive des ressources de la plate-forme.
Conformité. Google se soumet régulièrement à des audits tiers indépendants afin de vérifier que Google Cloud est conforme aux règles et bonnes pratiques liées à la sécurité, la confidentialité et la conformité. Google Cloud est conforme aux normes telles que ISO 27001, SOC 2/3 et PCI DSS 3.2.1.
Recommandations
- Définissez vos objectifs RTO et RPO.
- Concevez votre plan de reprise après sinistre en fonction des solutions dédiées aux données et aux applications.
- Testez votre plan de reprise après sinistre manuellement au moins une fois par an.
- Évaluez la mise en œuvre de l'injection de pannes contrôlée pour détecter les régressions de manière anticipée.
- Identifiez les zones à risque à l'aide de l'ingénierie du chaos.
Principaux services
L'instantané de disque persistant offre des sauvegardes ou des instantanés incrémentiels de machines virtuelles (VM) Compute Engine que vous pouvez copier dans différentes régions. Ils peuvent également vous servir à recréer des disques persistants en cas de sinistre.
La migration à chaud maintient vos instances de machine virtuelle en fonctionnement même lorsqu'un événement système hôte se produit tel qu'une mise à jour logicielle ou matérielle.
Cloud Storage est un magasin d'objets qui fournit des classes de stockage, telles que Nearline et Coldline, adaptées à des cas d'utilisation spécifiques, comme la sauvegarde.
Cloud DNS fournit un moyen automatisé de gérer vos entrées DNS dans le cadre d'un processus de reprise automatique. Cloud DNS utilise notre réseau mondial de serveurs de noms Anycast pour servir vos zones DNS depuis des lieux redondants partout dans le monde, afin d'offrir une haute disponibilité et une faible latence à vos utilisateurs.
Ressources
- Guide de planification de reprise après sinistre | Architectures
- Structure de la reprise après sinistre | Architectures
- Scénarios de reprise après sinistre pour les données | Architectures
- Scénarios de reprise après sinistre pour les applications | Architectures
- Conception de l'infrastructure pour la disponibilité et la résilience (PDF)