These instructions show you how to set up a solution for replicating data from SAP applications, such as SAP S/4HANA or SAP Business Suite, to BigQuery by using SAP Landscape Transformation (LT) Replication Server and SAP Data Services (DS).
You can use data replication to backup your SAP data in near real time or to consolidate the data from your SAP systems with consumer data from other systems in BigQuery to draw insights from machine learning and for petabyte-scale data analytics.
The instructions are intended for SAP system administrators who have basic experience with the configuration of SAP Basis, SAP LT Replication Server, SAP DS and Google Cloud.
Architecture

SAP LT Replication Server can act as a data provider for the SAP NetWeaver Operational Data Provisioning Framework (ODP). SAP LT Replication Server receives data from connected SAP systems and stores it in the ODP framework in an Operational Delta Queue (ODQ) of the SAP LT Replication Server system. Thus, SAP LT Replication Server itself also acts as the target of the SAP LT Replication Server configurations. The ODP framework makes the data available as ODP objects that correspond to the source system tables.
The ODP framework supports extraction and replication scenarios for various target SAP applications, known as subscribers. The subscribers retrieve the data from the delta queue for further processing.
Data gets replicated as soon as a subscriber requests the data from a data source through an ODP context. Several subscribers can use the same ODQ as source.
SAP LT Replication Server leverages the changed-data capture (CDC) support of SAP Data Services 4.2 SP1 or later, which includes real-time data provisioning and delta capabilities for all source tables.
The following diagram explains the flow of data through the systems:
- SAP applications update data in the source system.
- SAP SAP LT Replication Server replicates the data changes and stores the data in the Operational Delta Queue.
- SAP DS is a subscriber of the Operational Delta Queue and periodically polls the queue for data changes.
- SAP DS retrieves the data from the delta queue, transforms the data to be compatible with BigQuery format, and initiates the load job that moves the data to BigQuery.
- The data is available in BigQuery for analysis.
In this scenario, the SAP source system, SAP LT Replication Server, and SAP Data Services can be running either on or off of Google Cloud. For more information from SAP, see Operational Data Provisioning in Real-time with SAP Landscape Transformation Replication Server.

Core solution components
The following components are required to replicate data from SAP applications to BigQuery by using SAP Landscape Transformation Replication Server and SAP Data Services:
| Component | Required versions | Notes |
|---|---|---|
| SAP application server stack | Any ABAP-based SAP System starting with R/3 4.6C SAP_Basis (min requirement):
|
In this guide, the application server and database server are
collectively
referred to as the source system, even if they are running on
different machines. Define RFC user with appropriate authorization Optional: define separate table space for logging tables |
| Database (DB) system | Any DB version that is listed as supported in the SAP Product Availability Matrix (PAM), subject to any restrictions of the SAP NetWeaver stack that are listed in the PAM. See service.sap.com/pam. | |
| Operating system (OS) | Any OS version that is listed as supported in the SAP PAM, subject to any restrictions of the SAP NetWeaver stack that are listed in the PAM. See service.sap.com/pam. | |
| SAP Data Migration Server (DMIS) | DMIS:
|
|
| SAP Landscape Transformation Replication Server | SAP LT Replication Server 2.0 or later | Requires an RFC connection to source system. Sizing of the SAP LT Replication Server system depends very much on the amount of data which is stored in ODQ and the planned retention periods. |
| SAP Data Services | SAP Data Services 4.2 SP1 or higher | |
| BigQuery | N/A |
Costs
BigQuery is a billable Google Cloud component.
Use the Pricing Calculator to generate a cost estimate based on your projected usage.
Prerequisites
These instructions assume that the SAP application server, database server, SAP LT Replication Server, and SAP Data Services are already installed and configured for normal operation.
Before you can use BigQuery, you need a Google Cloud project.
Set up a Google Cloud project in Google Cloud
You need to enable the BigQuery API, and if you haven't already created a Google Cloud project, you need to do that, too.
Create Google Cloud project
Go to the Google Cloud console and sign up, walking through the setup wizard.
Next to the Google Cloud logo in the upper left-hand corner, click the dropdown and select Create Project.
Give your project a name and click Create.
After the project is created (a notification is displayed in the upper right), refresh the page.
Enable APIs
Enable the BigQuery API:
Enable private access to the Google Cloud APIs
For SAP workloads running outside Google Cloud, after you establish a network connection to Google Cloud, you need to enable private access to the Google Cloud APIs.
For more information, see Private Google Access options for services.
Create a service account
The service account (specifically its key file) is used to authenticate SAP DS to BigQuery. You use the key file later when you create the target datastore.
In the Google Cloud console, go to the Service accounts page.
Select your Google Cloud project.
Click Create Service Account.
Enter a Service account name.
Click Create and Continue.
In the Select a role list, choose BigQuery > BigQuery Data Editor.
Click Add Another Role.
In the Select a role list, choose BigQuery > BigQuery Job User.
Click Continue.
As appropriate, grant other users access to the service account.
Click Done.
On the Service accounts page in the Google Cloud console, click the email address of the service account that you just created.
Under the service account name, click the Keys tab.
Click the Add Key drop-down menu, and then select Create new key.
Make sure the JSON key type is specified.
Click Create.
Save the automatically downloaded key file to a secure location.
Configuring replication between SAP applications and BigQuery
Configuring this solution includes the following high-level steps:
- Configuring SAP LT Replication Server
- Configuring SAP Data Services
- Creating the data flow between SAP Data Services and BigQuery
SAP Landscape Transformation Replication Server Configuration
The following steps configure SAP LT Replication Server to act as a provider within the operational data provisioning framework and create an Operational Delta Queue. In this configuration, SAP LT Replication Server uses trigger-based replication to copy the data from the source SAP system into tables in the delta queue. SAP Data Services, acting as a subscriber in the ODP framework, retrieves the data from the delta queue, transforms it, and loads into BigQuery.
Configure the Operational Delta Queue (ODQ)
- In SAP LT Replication Server, use transaction
SM59to create an RFC destination for the SAP application system that is the data source. - In SAP LT Replication Server, use transaction
LTRCto create a configuration. In the configuration, define the source and target of the SAP LT Replication Server. The target for data transfer using ODP is the SAP LT Replication Server itself.- To specify the source, enter the RFC destination for the SAP application system to be used as the data source.
- To specify the target:
- Enter NONE as the RFC connection.
- Choose ODQ Replication Scenario for RFC communication. Using this scenario, specify that data is transferred by using the operational data provisioning infrastructure with operational delta queues.
- Assign a queue alias.
The queue alias is used in SAP Data Services for datasource ODP context setting.
SAP Data Services Configuration
Create a data services project
- Open the SAP Data Services Designer application.
- Go to File > New > Project.
- Specify a name in the Project name field.
- In Data Services Repository, select your data services repository.
- Click Finish. Your project appears in the Project Explorer on the left.
SAP Data Services connects to the source systems to collect metadata and then to the SAP Replication Server agent to retrieve the configuration and change data.
Create a source datastore
The following steps create a connection to SAP LT Replication Server and add the data tables to the applicable datastore node in the Designer object library.
To use SAP LT Replication Server with SAP Data Services, you must connect SAP DataServices to the correct operational delta queue in ODP by connecting a datastore to the ODP infrastructure.
- Open the SAP Data Services Designer application.
- Right-click on your SAP Data Services project name in Project Explorer.
- Select New > Datastore.
- Fill in Datastore Name. For example, DS_SLT.
- In the Datastore type field, select SAP Applications.
- In the Application server name field, provide the instance name of the SAP LT Replication Server.
- Specify the SAP LT Replication Server access credentials.
- Open the Advanced tab.
- In ODP Context, enter SLT~ALIAS, where ALIAS is the queue alias that you specified in Configure the Operational Delta Queue (ODQ).
- Click OK.
The new datastore appears in the Datastore tab in the local object library in Designer.
Create the target datastore
These steps create a BigQuery datastore that uses the service account that you created previously in the Create a service account section. The service account enables SAP Data Services to securely access BigQuery.
For more information, see Obtain your Google service account email and Obtain a Google service account private key file in the SAP Data Services documentation.
- Open the SAP Data Services Designer application.
- Right-click on your SAP Data Services project name in Project Explorer.
- Select New > Datastore.
- Fill in the Name field. For example, BQ_DS.
- Click Next.
- In the Datastore type field, select Google BigQuery.
- The Web Service URL option appears. The software automatically completes the option with the default BigQuery web service URL.
- Select Advanced.
- Complete the Advanced options based on the Datastore option descriptions for BigQuery in the SAP Data Services documentation.
- Click OK.
The new datastore appears in the Datastore tab in the Designer local object library.
Import the source ODP object(s) for replication
These steps import ODP objects from the source datastore for the initial and delta loads and make them available in SAP Data Services.
- Open the SAP Data Services Designer application.
- Expand the source datastore for replication load in the Project Explorer.
- Select the External Metadata option in the upper portion of the right panel. The list of nodes with available tables and ODP objects appears.
- Click on the ODP objects node to retrieve the list of available ODP objects. The list might take a long time to display.
- Click on the Search button.
- In the dialog, select External data in the Look in menu and ODP object in the Object type menu.
- In the Search dialog, select the search criteria to filter the list of source ODP object(s).
- Select the ODP object to import from the list.
- Right-click and select the Import option.
- Fill in the Name of Consumer.
- Fill in the Name of project.
- Select Changed-data capture (CDC) option in Extraction mode.
- Click Import. This starts the import of the ODP object into Data Services. The ODP object is now available in the object library under the DS_SLT node.
For more information, see Importing ODP source metadata in the SAP Data Services documentation.
Create a schema file
These steps create a data flow in SAP Data Services to generate a schema file that reflects the structure of the source tables. Later, you use the schema file to create a BigQuery table.
The schema ensures that the BigQuery loader data flow populates the new BigQuery table successfully.
Create a data flow
- Open the SAP Data Services Designer application.
- Right-click on your SAP Data Services project name in Project Explorer.
- Select Project > New > Data flow.
- Fill in the Name field. For example, DF_BQ.
- Click on Finish.
Refresh the object library
- Right-click on the source datastore for initial load in Project Explorer and select the Refresh Object Library option. This updates the list of datasource database tables that you can use in your data flow.
Build your data flow
- Build your data flow by dragging and dropping the source tables onto the data flow workspace and choosing Import as Source when prompted.
- In the Transforms tab of the object library, drag an XML_Map transform from the Platform node i onto the data flow and choose Batch Load option when prompted.
- Connect all of the source tables in the workspace to the XML Map transform.
- Open the XML Map transform and complete the input and output schema sections based on the data you are including in the BigQuery table.
- Right-click the XML_Map node in the Schema Out column and select Generate Google BigQuery Schema from the dropdown menu.
- Enter a name and location for the schema.
- Click Save.
- Right-click on the data flow in Project Explorer and select Remove.
SAP Data Services generates a schema file with the .json file extension.
Create the BigQuery tables
You need to create tables in your BigQuery dataset on Google Cloud for both the initial load and the delta loads. You use the schemas you created in SAP Data Services to create the tables.
The table for initial load is used for the initial replication of the entire source dataset. The table for delta loads is used for the replication of the changes in the source dataset that occur after the initial load. The tables are based on the schema that you generated in the previous step. The table for the delta loads includes an additional timestamp field that identifies the time of each delta load.
Create a BigQuery table for the initial load
These steps create a table for the initial load in your BigQuery dataset.
- Access your Google Cloud project in the Google Cloud console.
- Select BigQuery.
- Click on the applicable dataset.
- Click on Create table.
- Enter a Table name. For example, BQ_INIT_LOAD.
- Under Schema, toggle the setting to enable the Edit as text mode.
- Set the schema of the new table in BigQuery by copying and pasting the contents of the schema file that you created in Create a schema file.
- Click Create table.
Create a BigQuery table for the delta loads
These steps create a table for the delta loads of your BigQuery dataset.
- Access your Google Cloud project in the Google Cloud console.
- Select BigQuery.
- Click on the applicable dataset.
- Click on Create table.
- Enter Table name. For example, BQ_DELTA_LOAD.
- Under Schema, toggle the setting to enable Edit as text mode.
- Set the schema of the new table in BigQuery by copying and pasting the contents of the schema file that you created in Create a schema file.
In the JSON list in the schema file, right before the field definition of the DI_SEQUENCE_NUMBER field, add the following DL_TIMESTAMP field definition. This field stores the timestamp of each delta load execution):
{ "name": "DL_TIMESTAMP", "type": "TIMESTAMP", "mode": "REQUIRED", "description": "Delta load timestamp" },Click Create table.
Set up the data flow between SAP Data Services and BigQuery
To set up the data flow, you need to import the BigQuery tables into SAP Data Services as external metadata and create the replication job and the BigQuery loader data flow.
Import the BigQuery tables
These steps import the BigQuery tables that you created in the previous step and make them available in SAP Data Services.
- In the SAP Data Services Designer object library, open the BigQuery datastore that you created previously.
- In the upper part of the right panel, select External Metadata. The BigQuery tables that you created appear.
- Right-click the applicable BigQuery table name and select Import.
- The import of the selected table into SAP Data Services starts. The table is now available in the object library under the target datastore node.
Create a replication job and the BigQuery loader data flow
These steps create a replication job and the data flow in SAP Data Services that is used to load the data from SAP LT Replication Server to the BigQuery table.
The data flow consists of two parts. The first executes the initial load of data from the source ODP object(s) to the BigQuery table and the second enables the subsequent delta loads.
Create a global variable
So that the replication job can determine whether to execute an initial load or a delta load, you need to create a global variable to track the load type in the data flow logic.
- In the SAP Data Services Designer application menu, go to Tools > Variables.
- Right-click on Global Variables and select Insert.
- Right-click on variable Name and select Properties.
- Enter $INITLOAD in variable Name.
- In Data Type, select Int.
- Enter 0 in the Value field.
- Click OK.
Create the replication job
- Right-click on your project name in Project Explorer.
- Select New > Batch Job
- Fill in the Name field. For example, JOB_SRS_DS_BQ_REPLICATION.
- Click Finish.
Create data flow logic for the initial load
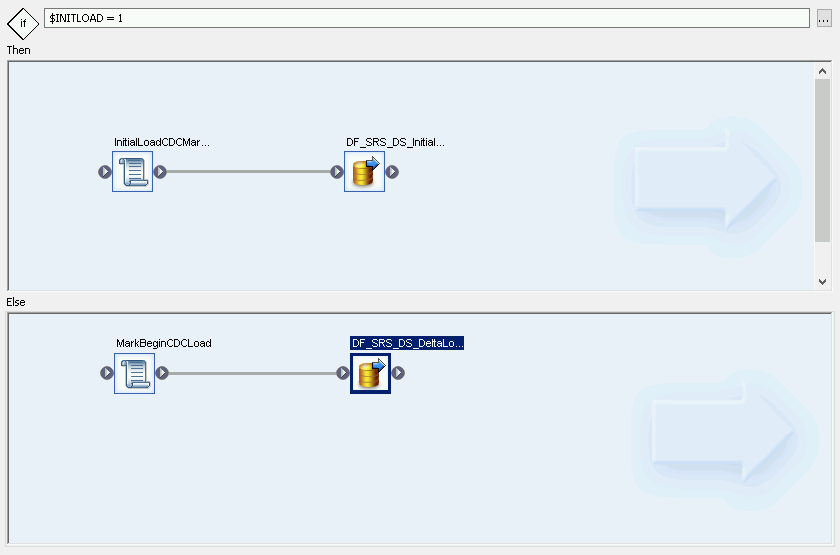
Create a conditional
- Right-click on Job Name and select option Add New > Conditional.
- Right-click on the conditional icon and select Rename.
Change the name to InitialOrDelta.

Open the Conditional Editor by double-clicking on the conditional icon.
In the If statement field, enter $INITLOAD = 1, which sets the condition to execute the initial load.
Right-click in the Then pane and select Add New > Script.
Right-click on the Script icon and select Rename.
Change the name. For example, these instructions use InitialLoadCDCMarker.
Double-click on the Script icon to open the Function editor.
Enter
print('Beginning Initial Load');Enter
begin_initial_load();
Click on the Back icon in the application toolbar to exit the Function Editor.
Create a data flow for the initial load
- Right-click in the Then pane and select Add New > Data Flow.
- Rename the data flow. For example, DF_SRS_DS_InitialLoad.
- Connect InitialLoadCDCMarker with DF_SRS_DS_InitialLoad by clicking on the connection output icon of InitialLoadCDCMarker and then dragging the connection line to the input icon of DF_SRS_DS_InitialLoad.
- Double-click on DF_SRS_DS_InitialLoad data flow.
Import and connect the data flow with the source datastore objects
- From the datastore, drag and drop the source ODP object(s) onto the data flow workspace. In these instructions, the datastore is named DS_SLT. The name of your datastore might be different.
- Drag Query transform from the Platform node in the Transforms tab of the object library onto the data flow.
Double-click on the ODP object(s) and in Source tab set Initial Load option to Yes.
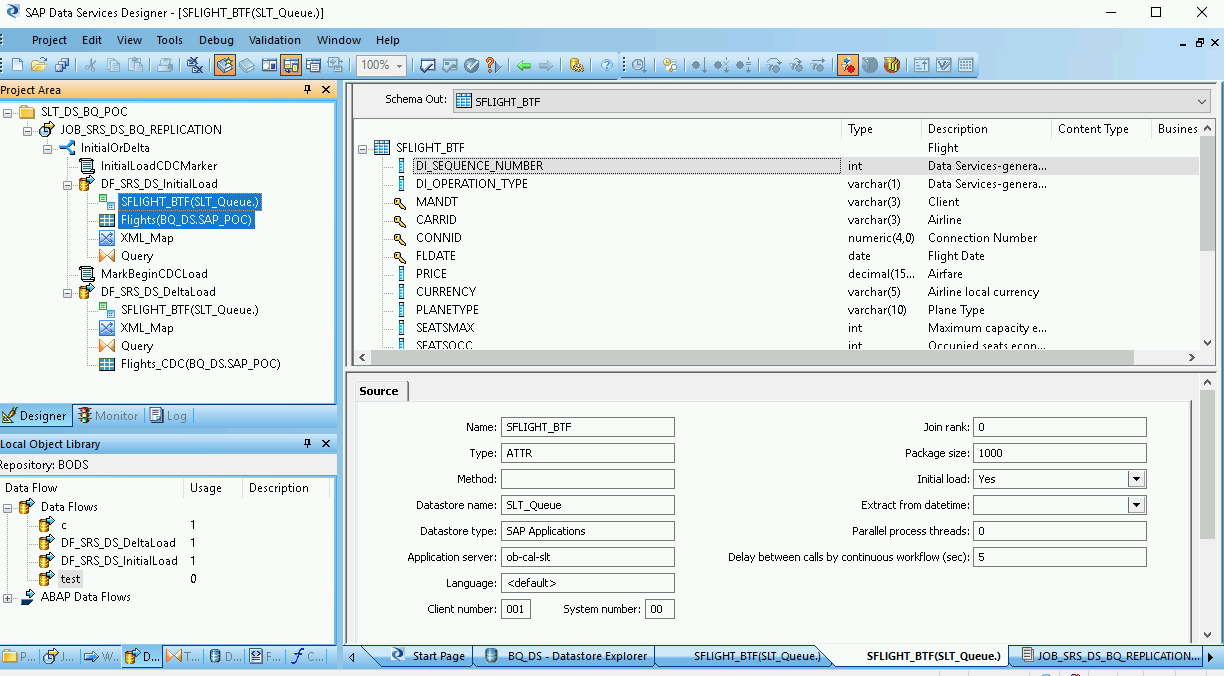
Connect all of the source ODP object(s) in the workspace to the Query transform.
Double-click on Query transform.
Select all of the table fields under Schema In on the left and drag them to Schema Out on the right.
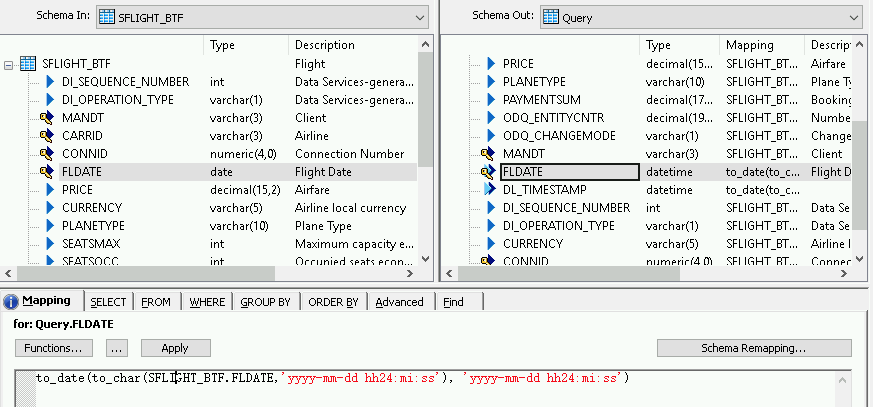
To add a conversion function for a datetime field:
- Select the datetime field in the Schema Out list on the right.
- Select the Mapping tab below the schema lists.
Replace the field name with the following function:
to_date(to_char(FIELDNAME,'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')Where FIELDNAME is the name of the field you selected.
Click on the Back icon in application toolbar to get back to the data flow.
Import and connect the data flow with the target datastore objects
- From the datastore in the object library, drag the imported BigQuery table for the initial load onto the data flow. The name of the datastore in these instructions is BQ_DS. Your datastore name might be different.
- From the Platform node in the Transforms tab of the object library, drag an XML_Map transform onto the data flow.
- Select Batch mode in the dialog.
- Connect the Query transform to the XML_Map transform.
Connect the XML_Map transform to the imported BigQuery table.
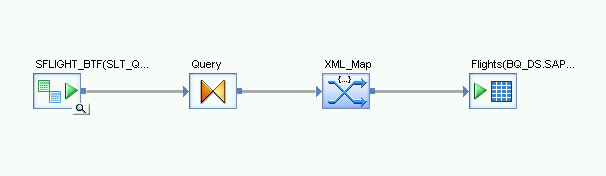
Open the XML_Map transform and complete the input and output schema sections based on the data you are including in the BigQuery table.
Double-click the BigQuery table in the workspace to open it and complete the options in the Target tab as indicated in the following table:
| Option | Description |
|---|---|
| Make Port | Specify No, which is the default. Specifying Yes makes a source or target file an embedded data flow port. |
| Mode | Specify Truncate for the initial load, which replaces any existing records in the BigQuery table with the data loaded by SAP Data Services. Truncate is the default. |
| Number of loaders | Specify a positive integer to set the number of loaders (threads)
to use for processing. The default is 4.
Each loader starts one resumable load job in BigQuery. You can specify any number of loaders. For help determining an appropriate number of loaders, see the SAP documentation, including: |
| Maximum failed records per loader | Specify 0 or a positive integer to set the maximum number of records that can fail per load job before BigQuery stops loading records. The default is zero (0). |
- Click on Validate icon in the top toolbar.
- Click on the Back icon in application toolbar to return to the Conditional Editor.
Create a data flow for the delta load
You need to create a data flow to replicate the changed-data capture records that accumulate after the initial load.
Create a conditional delta flow:
- Double-click on the InitialOrDelta conditional.
- Right-click in the Else section and select Add New > Script.
- Rename the script. For example, MarkBeginCDCLoad.
- Double-click on the Script icon to open the Function editor.
Enter print('Beginning Delta Load');

Click on the Back icon in the application toolbar to return to the Conditional Editor.
Create the data flow for the delta load
- In the Conditional Editor, right-click and select Add New > Data Flow.
- Rename data flow. For example, DF_SRS_DS_DeltaLoad.
- Connect MarkBeginCDCLoad with DF_SRS_DS_DeltaLoad, as shown in following the diagram.
Double-click on the DF_SRS_DS_DeltaLoad data flow.
Import and connect the data flow with the source datastore objects
- Drag and drop the source ODP object(s) from the datastore onto the data flow workspace. The datastore in these instructions uses the name DS_SLT. The name of your datastore might be different.
- From the Platform node in the Transforms tab of the object library, drag the Query transform onto the data flow.
- Double-click on the ODP object(s) and in the Source tab, set the Initial Load option to No.
- Connect all of the source ODP object(s) in the workspace to the Query transform.
- Double-click on Query transform.
- Select all of the table fields in the Schema In list on the left and drag them to the Schema Out list on the right
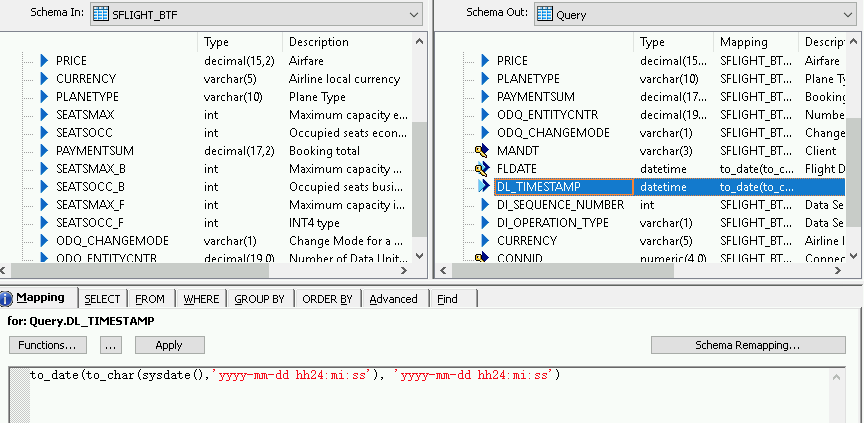
Enable the timestamp for the delta loads
The following steps enable SAP Data Services to automatically record the timestamp of each delta load execution in a field in the delta load table.
- Right-click on the Query node in the Schema Out pane on the right.
- Select New Output Column.
- Enter DL_TIMESTAMP in Name.
- Select datetime in Data type.
- Click OK.
- Click on newly created DL_TIMESTAMP field.
- Go to Mapping tab below
Enter the following function:
- to_date(to_char(sysdate(),'yyyy-mm-dd hh24:mi:ss'), 'yyyy-mm-dd hh24:mi:ss')
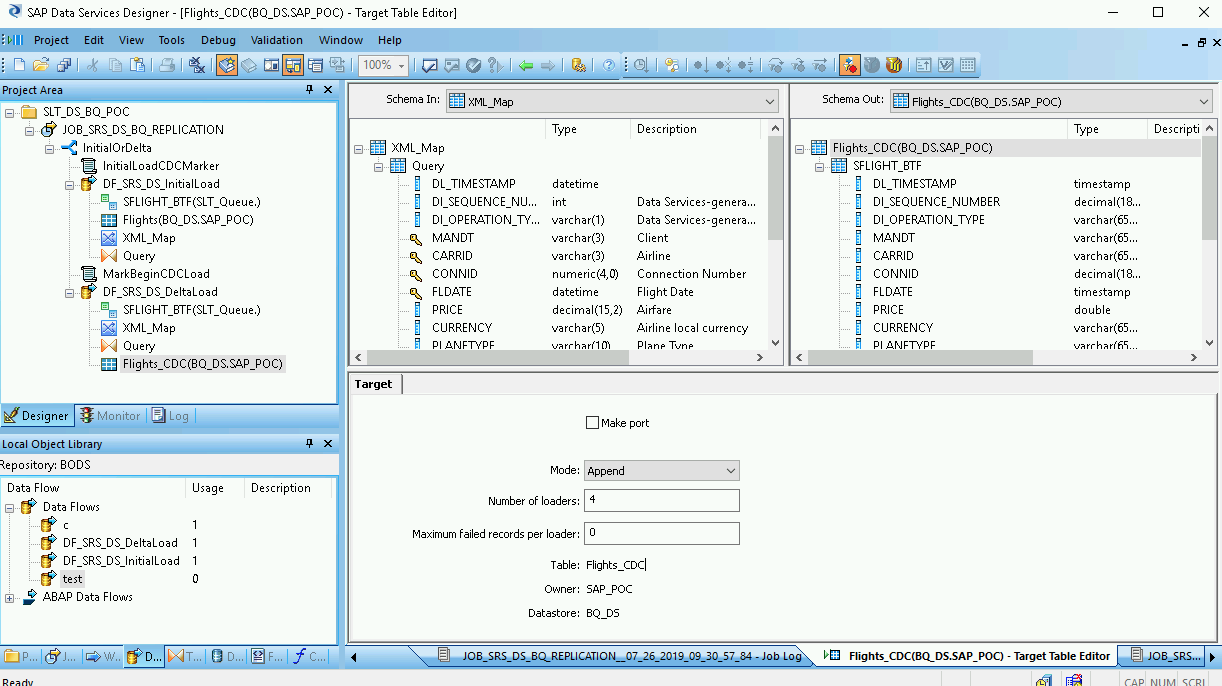
Import and connect the data flow to the target datastore objects
- From the datastore in the object library, drag the imported BigQuery table for the delta load onto the data flow workspace after the XML_Map transform. These instructions use the example datastore name BQ_DS. Your datastore name might be different.
- From the Platform node in the Transforms tab of the object library, drag an XML_Map transform onto the data flow.
- Connect Query transform to the XML_Map transform.
Connect the XML_Map transform to the imported BigQuery table.

Open the XML_Map transform and complete the input and output schema sections based on the data you are including in the BigQuery table.

Double-click the BigQuery table in the workspace to open it and complete the options in the Target tab based on the following descriptions:
| Option | Description |
|---|---|
| Make Port | Specify No, which is the default. Specifying Yes makes a source or target file an embedded data flow port. |
| Mode | Specify Append for the delta loads, which preserves the existing records in the BigQuery table when new records are loaded from SAP Data Services. |
| Number of loaders | Specify a positive integer to set the number of loaders (threads)
to use for processing.
Each loader starts one resumable load job in BigQuery. You can specify any number of loaders. Generally, delta loads need fewer loaders than the initial load. For help determining an appropriate number of loaders, see the SAP documentation, including: |
| Maximum failed records per loader | Specify 0 or a positive integer to set the maximum number of records that can fail per load job before BigQuery stops loading records. The default is zero (0). |
- Click on Validate icon in the top toolbar.
- Click on the Back icon in the application toolbar to return to the Conditional editor.
Loading the data into BigQuery
The steps for an initial load and a delta load are similar. For each, you start the replication job and execute the data flow in SAP Data Services to load the data from SAP LT Replication Server to BigQuery. An important difference between the two load procedures is the value of the $INITLOAD global variable. For an initial load, $INITLOAD must be set to 1. For a delta load, $INITLOAD must be 0.
Execute an initial load
When you execute an initial load, all of the data in the source dataset is replicated to the target BigQuery table that is connected to the initial load data flow. Any data in the target table is overwritten.
- In the SAP Data Services Designer, open Project Explorer.
- Right-click on the replication job name and select Execute. A dialog displays.
- In the dialog, go to the Global Variable tab and change the value of
$INITLOADto 1, so that the initial load runs first. - Click OK. The loading process starts and debug messages start appearing in the SAP Data Services log. The data is loaded into the table that you created in BigQuery for initial loads. The name of the initial load table in these instructions is BQ_INIT_LOAD. The name of your table might be different.
- To see if loading is complete, go to the Google Cloud console and open the BigQuery dataset that contains the table. If the data is still loading, "Loading" appears next to the table name.
After loading, the data is ready for processing in BigQuery.
From this point on, all changes in the source table are recorded in the SAP LT Replication Server delta queue. To load the data from the delta queue to BigQuery, execute a delta load job.
Execute a delta load
When you execute a delta load, only the changes that occurred in source dataset since the last load are replicated to the target BigQuery table that is connected to the delta load data flow.
- Right-click on the job name and select Execute.
- Click OK. The loading process starts and debug messages begin to appear in the SAP Data Services log. The data is loaded into the table that you created in BigQuery for the delta loads. In these instructions, the name of the delta load table is BQ_DELTA_LOAD. The name of your table might be different.
- To see if loading is complete, go to the Google Cloud console and open the BigQuery dataset that contains the table. If the data is still loading, "Loading" appears next to the table name.
- After loading, the data is ready for processing in BigQuery.
To keep track of the changes to the source data, SAP LT Replication Server records the order of changed-data operations in the DI_SEQUENCE_NUMBER column and the type of changed-data operation in the DI_OPERATION_TYPE column (D=delete, U=update, I=insert). SAP LT Replication Server stores the data in the columns in the delta queue tables, from which it is replicated to BigQuery.
Scheduling delta loads
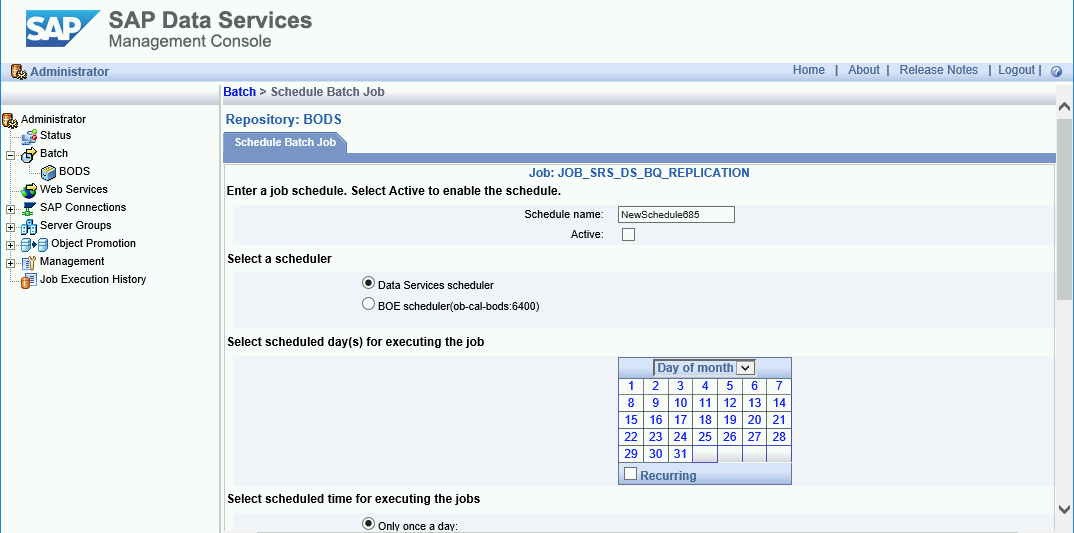
You can schedule a delta load job to run on at regular intervals by using the SAP Data Services Management Console.
- Open the SAP Data Services Management Console application.
- Click on Administrator.
- Expand the Batch node in the menu tree on the left side.
- Click on the name of your SAP Data Services repository.
- Click on the Batch Job Configuration tab.
- Click on Add Schedule.
- Fill in Schedule name.
- Check Active.
- In the Select scheduled time for executing the jobs section, specify
the frequency for your delta load execution.
- Important: Google Cloud limits the number of BigQuery load jobs that you can run in a day. Make sure that your schedule does not exceed the limit, which cannot be raised. For more information about the limit for BigQuery load jobs, see Quotas & limits in the BigQuery documentation.
- Expand Global Variables and check whether $INITLOAD is set to 0.
- Click on Apply.
What's next
Query and analyze replicated data in BigQuery.
For more information about querying, see:
- Overview of querying BigQuery data in the BigQuery documentation.
For some ideas about how to consolidate initial and delta load data in BigQuery at scale, see:
- Performing large-scale mutations in BigQuery solution available in Google Cloud blog.
- Data Manipulation Language in the BigQuery documentation.
Explore reference architectures, diagrams, and best practices about Google Cloud. Take a look at our Cloud Architecture Center.