このチュートリアルでは、クロスリージョン リードレプリカを使用した Cloud SQL for MySQL での完全な障害復旧(DR)フェイルオーバーとフォールバック プロセスについて説明します。
このチュートリアルでは、DR の高可用性(HA)Cloud SQL for MySQL インスタンスを設定し、サービスの停止をシミュレートします。その後、停止が解決したら DR プロセスに入って初期デプロイメントを復元します。
このチュートリアルは、データベース アーキテクト、管理者、エンジニアを対象としています。
SQL の障害復旧の仕組みの概要については、Cloud SQL の障害復旧についてをご覧ください。
目標
- HA Cloud SQL for MySQL インスタンスを作成します。
- Cloud SQL for MySQL を使用して、 Google Cloud にクロスリージョン リードレプリカをデプロイします。
- Cloud SQL for MySQL で障害とフェイルオーバーをシミュレートします。
- Cloud SQL for MySQL でフォールバックを使用して初期デプロイメントを復元する手順を理解します。
このドキュメントでは、クロスリージョン DR のフェイルオーバー プロセスとフォールバック プロセスのみに焦点を当てています。単一リージョンの HA フェイルオーバー プロセスの詳細については、高可用性構成の概要をご覧ください。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
フェーズ 1: DR 用 HA データベース インスタンスの設定
次のフェーズ(1~3)では、完全なフェイルオーバーとフォールバックのプロセスについて詳しく説明します。Cloud Shell で
gcloudコマンドを使用して、すべてのコマンドを実行します。このプロセスを簡略化するため、チュートリアルでは可能な限りデフォルトの設定(デフォルトの Cloud SQL バージョンなど)を使用します。本番環境では他の構成が追加される場合があります。環境変数を設定する
このセクションでは、このチュートリアルで実行するコマンドに必要なさまざまな名前とリージョンを定義する環境変数の例を示します。これらのサンプル変数は、必要に応じて調整できます。
次の表に、このチュートリアルの DR とフォールバック プロセスの各フェーズにおけるインスタンス名、ロール、デプロイ リージョンを示します。独自の名前とリージョンを指定することもできます。
初期フェーズ インスタンス名 ロール リージョン instance-1プライマリ us-west1instance-2スタンバイ us-west1instance-3リージョン間リードレプリカ us-west2障害発生フェーズ インスタンス名 ロール リージョン instance-3プライマリ us-west2instance-4スタンバイ us-west2instance-5リージョン間リードレプリカ us-west3instance-6リージョン間リードレプリカ us-west1フォールバック(最終)フェーズ インスタンス名 ロール リージョン instance-6プライマリ us-west1instance-7スタンバイ us-west1instance-8リージョン間リードレプリカ us-west2上表のインスタンス名にはロールを示す語句が含まれていません。DR により、インスタンスの機能が変更される可能性があります。たとえば、レプリカがプライマリに変わることがあります。新しいプライマリの名前に
replicaのような文字が含まれていると、混乱や競合が発生する可能性があります。このため、インスタンス名にはその機能やロールを示す語句を入れないようにすることをおすすめします。上表はスタンバイ インスタンスの名前を示しています。このチュートリアルでは HA フェイルオーバーを行うことはありませんが、すべてを網羅するためにスタンバイ インスタンス名は使用しています。
フォールバック フェーズでは、初期フェーズの元のデプロイを同じ元のリージョンで再作成します。ただしフォールバックでは、元のインスタンスが削除されても直ちには元の名前を使用できないため、インスタンスの名前を変更する必要があります。フォールバック フェーズでインスタンスをすばやく作成するには、初期フェーズで使用した名前とは同一でないインスタンス名を使用する必要があります。
Cloud Shell で、上表の仕様に基づく環境変数を設定します。
export primary_name=instance-1 export primary_tier=db-n1-standard-2 export primary_region=us-west1 export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-3 export cross_region_replica_region=us-west2プライマリ インスタンスに別の階層を使用する場合は、使用可能な階層を確認してから primary_tier に別の値を割り当てます。
gcloud sql tiers listCloud SQL をデプロイできるリージョンの一覧については、インスタンスの設定をご覧ください。
プライマリ データベース インスタンスを作成する
Cloud Shell で、Cloud SQL の単一のインスタンスを作成します。
gcloud sql instances create $primary_name \ --tier=$primary_tier \ --region=$primary_regiongcloudコマンドは、インスタンスを作成するまで一時停止します。root のパスワードを設定します。
gcloud sql users set-password root \ --host=% \ --instance $primary_name \ --password $primary_root_password
プライマリ データベースを作成する
Cloud Shell で MySQL シェルにログインし、プロンプトが表示されたら root パスワードを入力します。
gcloud sql connect $primary_name --user=rootMySQL プロンプトで、データベースを作成し、テストデータをアップロードします。
CREATE DATABASE guestbook; USE guestbook; CREATE TABLE entries (guestName VARCHAR(255), content VARCHAR(255), entryID INT NOT NULL AUTO_INCREMENT, PRIMARY KEY(entryID)); INSERT INTO entries (guestName, content) values ("first guest", "I got here!"); INSERT INTO entries (guestName, content) values ("second guest", "Me too!");データが正常に commit されたことを確認します。
SELECT * FROM entries;2 行のデータが返されていることを確認します。
MySQL シェルを終了します。
exit;
この時点で、テーブルといくつかのテストデータを含む 1 つのデータベースが存在します。
プライマリ インスタンスを HA データベース インスタンスに変更する
Cloud SQL は、クロスリージョン システムではなく、リージョンの HA システムとしてのみ構成できます(クロスリージョン リードレプリカの設定は、Cloud SQL をクロスリージョン システムとして構成する場合とは異なります)。詳細については、インスタンスでの高可用性の有効化と無効化をご覧ください。
Cloud Shell で、HA 対応 Cloud SQL インスタンスを作成します。
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$primary_backup_start_time
自動更新で DR のクロスリージョン リードレプリカを追加する
このチュートリアルでは、次の手順でクロスリージョン リードレプリカを作成します。
Cloud Shell で、クロスリージョン リードレプリカを設定します。
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region(省略可)データベースがレプリケートされたことを確認するには、Google Cloud コンソールで Cloud SQL の [インスタンス] ページに移動します。
![[インスタンス] ページに、HA 対応のプライマリ レプリカとリードレプリカが表示されます。](https://cloud.google.com/static/solutions/images/cloud-sql-mysql-disaster-recovery-complete-failover-fallback-instances-page-1.png?authuser=00&hl=ja)
Google Cloud コンソールに、プライマリ インスタンス(
instance-1)が HA で有効であることと、クロスリージョン リードレプリカ(instance-3)が存在することが表示されます。プライマリと同じ root パスワードを使用して、クロスリージョン リードレプリカにログインします。
gcloud sql connect $cross_region_replica_name --user=rootMySQL プロンプトで、データを選択して、レプリケーションが機能していることを確認します。
USE guestbook; SELECT * FROM entries;MySQL シェルを終了します。
exit;
完全なクロスリージョン リードレプリカの設定方法の詳細については、Cloud SQL のドキュメントをご覧ください。
本番環境で大規模なデータベースを使用する場合は、プライマリ データベースをバックアップし、バックアップからクロスリージョン リードレプリカを作成することをおすすめします。この手順を使用すると、リードレプリカがプライマリ データベースと同期する際に必要となる時間を短縮できます。このプロセスについては、次のセクションで説明します。ただし、この手順をスキップしてフェーズ 2 に進むこともできます。
ダンプファイルに基づいてクロスリージョン リードレプリカを追加する
クロスリージョン リードレプリカの作成を最適化する方法の 1 つは、新しいプライマリにアクセスする時点で同期するのではなく、それ以前の整合性のとれたプライマリ データベース状態でレプリカを同期することです。この最適化では、レプリカの出発点となる状態として使用するダンプファイルを作成する必要があります。
ダンプファイルに基づいてレプリカを作成する手順については、外部サーバーから Cloud SQL へのレプリケーション(v1.1)をご覧ください。このアプローチは、大規模な本番環境データベースに対して有用であることが考えられます。ただし、このチュートリアルでは、テスト データセットは小規模であり、完全なレプリケーションを実施できるため、この手順をスキップします。
フェーズ 2: 障害のシミュレーション(リージョンの停止)
このフェーズでは、プライマリ データベースを使用不可にし、本番環境設定でのプライマリ リージョンの停止をシミュレーションします。
クロスリージョン リードレプリカの遅延を確認する
次の手順で、クロスリージョン リードレプリカのレプリケーションの遅延を判断します。
Google Cloud コンソールで、Cloud SQL の [インスタンス] ページに移動します。
リードレプリカ(instance-3)をクリックします。
[指標] プルダウン リストで [レプリケーション ラグ] をクリックします。
![[指標] プルダウン リストには、レプリケーションの遅延など、いくつかのオプションが表示されています。](https://cloud.google.com/static/solutions/images/cloud-sql-mysql-disaster-recovery-complete-failover-fallback-replication-lag.png?authuser=00&hl=ja)
指標が [レプリケーション ラグ] に変わります。グラフに遅延は表示されていません。
![[レプリケーション ラグ] グラフには、1 時間から 30 日間までの表示オプションがあります。](https://cloud.google.com/static/solutions/images/cloud-sql-mysql-disaster-recovery-complete-failover-fallback-replication-no-lag.png?authuser=00&hl=ja)
プライマリ リージョンが停止した場合、レプリケーション ラグはゼロになるため、遅延ゼロですべてのトランザクションがレプリケートされていることが保証されます。ゼロでない場合、一部のトランザクションがレプリケートされない可能性があります。この場合、クロスリージョン リードレプリカには、プライマリで commit されたトランザクションのすべてが含まれるわけではありません。
プライマリ インスタンスを使用不可にする
次の手順では、プライマリを停止して障害をシミュレーションします。クロスリージョン リードレプリカがプライマリに接続されている場合、最初にレプリカの接続解除を行う必要があります。接続を解除しなければ、Cloud SQL インスタンスを停止できません。
Cloud Shell で、プライマリからクロスリージョン リードレプリカを削除します。
gcloud sql instances patch $cross_region_replica_name \ --no-enable-database-replicationプロンプトが表示されたら、そのオプションを受け入れて続行します。
プライマリ データベース インスタンスを停止します。
gcloud sql instances patch $primary_name --activation-policy NEVER
DR の実装
Cloud Shell で、クロスリージョン リードレプリカをスタンドアロン インスタンスに昇格します。
gcloud sql instances promote-replica $cross_region_replica_nameプロンプトが表示されたら、そのオプションを受け入れて続行します。Cloud SQL の [インスタンス] ページには、元のクロスリージョン リードレプリカ(
instance-3)が新しいプライマリとして表示され、元のプライマリ(instance-1)は停止済みとして表示されます。![[インスタンス] ページには、元のプライマリと新しいプライマリの 2 つのインスタンスの状態が表示されます。](https://cloud.google.com/static/solutions/images/cloud-sql-mysql-disaster-recovery-complete-failover-fallback-instances-page-2.png?authuser=00&hl=ja)
クロスリージョン リードレプリカを新しいプライマリに昇格させてから、HA に対して有効にします。環境変数を適切な名前に更新することをおすすめします。
環境変数を更新します。
export former_primary_name=$primary_name export primary_name=$cross_region_replica_name export primary_tier=db-n1-standard-2 export primary_region=$cross_region_replica_region export primary_root_password=my-root-password export primary_backup_start_time=22:00 export cross_region_replica_name=instance-5 export cross_region_replica_region=us-west3新しいプライマリを起動します。
gcloud sql instances patch $primary_name --activation-policy ALWAYS新しいプライマリを HA リージョン インスタンスとして有効にします。
gcloud sql instances patch $primary_name \ --availability-type REGIONAL \ --enable-bin-log \ --backup-start-time=$backup_start_time3 番目のリージョンでクロスリージョン リードレプリカを作成します。
gcloud sql instances create $cross_region_replica_name \ --master-instance-name=$primary_name \ --region=$cross_region_replica_region前の手順で、
cross_region_replica_region環境変数をus-west3に設定します。フェイルオーバーが完了すると、 Google Cloud コンソールの Cloud SQL [インスタンス] ページに、新しいプライマリ(
instance-3)が HA として有効であることと、クロスリージョン リードレプリカ(instance-5)が存在することが表示されます。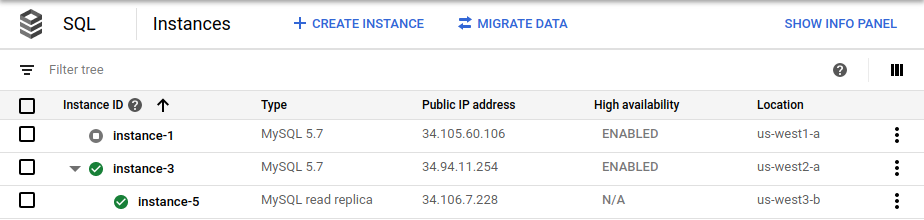
(省略可)定期バックアップがある場合は、前述のプロセスに沿って、新しいプライマリを最新のバックアップ バージョンと同期させます。
(省略可)Cloud SQL プロキシを使用している場合は、アプリケーション処理を再開するために新しいプライマリを使用するようにプロキシを構成します。
短時間のリージョンの停止を処理する
フェイルオーバーをトリガーするサービスの停止が、フェイルオーバーが完了する前に解消する場合があります。その場合、フェイルオーバー プロセスをキャンセルし、停止が発生したリージョンで元のプライマリ Cloud SQL インスタンスを引き続き使用することをおすすめします。
フェイルオーバー プロセスの個別の状態によっては、クロスリージョン リードレプリカがすでに昇格している可能性があります。この場合、そのクロスリージョン リードレプリカを削除し、クロスリージョン リードレプリカを再作成する必要があります。
スプリットブレイン状態を回避するため、元のプライマリを削除する
スプリットブレイン状態を回避するには、元のプライマリを削除する(またはデータベース クライアントからアクセス不可にする)必要があります。
フェイルオーバー後に、クライアントが元のプライマリ データベースと新しいプライマリ データベースに同時に書き込みを行うと、スプリットブレイン状態が発生する可能性があります。この場合、2 つのデータベースのコンテンツには一貫性がありません。フェイルオーバー後には、元のプライマリ データベースは最新の状態ではないため、読み取りトラフィックまたは書き込みトラフィックを受信しないようにする必要があります。
Cloud Shell で、元のプライマリを削除します。
gcloud sql instances delete $former_primary_nameプロンプトが表示されたら、そのオプションを受け入れて続行します。
Google Cloud コンソールの Cloud SQL の [インスタンス] ページには、デプロイの一環として元のプライマリ インスタンス(
instance-1)は表示されなくなります。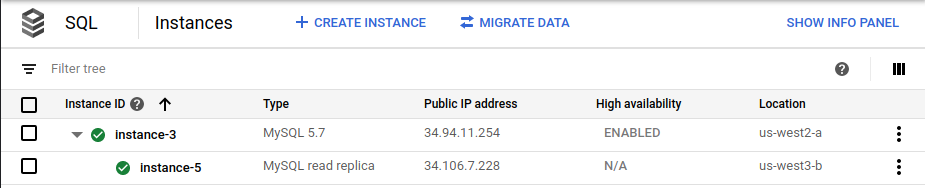
フェーズ 3: フォールバックの実装
使用が開始された元のリージョン(R1)にフォールバックするには、フェーズ 2 で説明したのと同一のプロセスに沿って進めます。このプロセスの概要は次のとおりです。
元のリージョン(R1)に 2 番目のクロスリージョン リードレプリカを作成します。この時点で、プライマリには 2 つのクロスリージョン リードレプリカ(リージョン R3 に 1 つ、リージョン R1 に 1 つ)が存在します。
R1 のクロスリージョン リードレプリカを最終的なプライマリとして昇格させます。
最終的なプライマリに対して HA を有効にします。
us-west2で、最終的なプライマリのクロスリージョン リードレプリカを作成します。スプリットブレイン状態を回避するため、不要になったインスタンス(元のプライマリと R3 のクロスリージョン リードレプリカ)をすべて削除します。
前述したように、新しいプライマリ データベースで定義された出発点の状態が含まれる初期バックアップを作成することをおすすめします。
最終的なデプロイには、HA プライマリ(
instance-6という名前)とクロスリージョン リードレプリカ(instance-8という名前)が存在します。手動 DR と自動 DR のメリット、デメリットの比較
次の表は、手動と自動で DR プロセスを実施する際のメリットとデメリットをまとめたものです。目的は、アプローチが正しいか、間違っているかを判断することではなく、ニーズに最適なアプローチを判断できるようにする基準を提供することです。
手動実行 自動実行 メリット: - すべてのステップを厳格に管理できます。
- このプロセスであらゆる問題をすばやく確認して対処し、文書化することが可能です。
- フェイルオーバー中は、すべてのプロセス ステップを表示して確認できます。
メリット: - フェイルオーバー プロセスを実装してテストできます。
- 自動化により、実装にかかる時間を最短にし、遅延を最小限に抑えることができます。
- 人間のオペレーターやオペレーターの知識、稼働状況には関係なく実施できます。
デメリット - 手動で処理手順を実施すると、処理が遅くなります。
- 人間の入力ミスによって問題が発生することがあります。
- このプロセスをテストする場合、通常はさまざまな役割と時間が必要となります。そのため、正規のテストを控えることもあります。
デメリット - 予期しないエラーが発生すると、本番環境のフェイルオーバーでデバッグを行う必要があります。
- 処理中にエラーが発生した場合は、処理が中断したところから再開する(復元)スクリプトが必要になります。
- スクリプトの動作(特にエラーの発生時)を把握するには、スクリプトとその実装についての十分な知識が必要です。
ベスト プラクティスとして、手動での実装から始めることをおすすめします。その後、自発的にこの実装を定期的に実行して(本番環境では推奨されます)、手動プロセスが機能していることを確認し、すべてのチームメンバーが各自の役割と責任を把握できるようにします。手動プロセスは、段階的なプロセスのドキュメントで定義することをおすすめします。実施するたびに、このプロセスのドキュメントの確認や改良を行う必要があります。
プロセスを微調整し、そのプロセスが信頼できることを確信したら、そのプロセスを自動化するかどうかを判断します。プロセスの自動化を選択して実装する場合は、本番環境で定期的にプロセスをテストして、確実に実施できることを確認する必要があります。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、このチュートリアルで作成した Google Cloud プロジェクトを削除します。
プロジェクトを削除する
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
次のステップ
- Cloud SQL の障害復旧について確認する。
- Compute Engine での MySQL の障害復旧について確認する。
- クラウド インフラストラクチャの停止に関する障害復旧アーキテクチャについて確認する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。