Com as junções, é possível conectar diferentes visualizações para analisar dados de mais de uma visualização ao mesmo tempo e entender como as diferentes partes dos dados se relacionam.
Por exemplo, seu banco de dados pode incluir as tabelas order_items, orders e users. Você pode usar junções para analisar dados de todas as tabelas ao mesmo tempo. Esta página explica as junções em LookML, incluindo parâmetros e padrões específicos.
As junções começam com uma análise detalhada
As junções são definidas no arquivo de modelo para estabelecer a relação entre uma Análise e uma visualização. As junções conectam uma ou mais visualizações a uma única Análise, diretamente ou por outra visualização unida.
Considere duas tabelas de banco de dados: order_items e orders. Depois de gerar visualizações para as duas tabelas, declare uma ou mais delas no parâmetro explore no arquivo de modelo:
explore: order_items { ... }
Quando você executa uma consulta na análise detalhada order_items, order_items aparece na cláusula FROM do SQL gerado:
SELECT ...
FROM order_items
Você pode adicionar mais informações à análise detalhada order_items. Por exemplo, é possível usar o seguinte exemplo de LookML para unir a visualização orders à análise detalhada order_items:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
}
}
A LookML mostrada anteriormente realiza duas coisas. Primeiro, você pode ver campos de orders e order_items no Seletor de campos de análise detalhada:
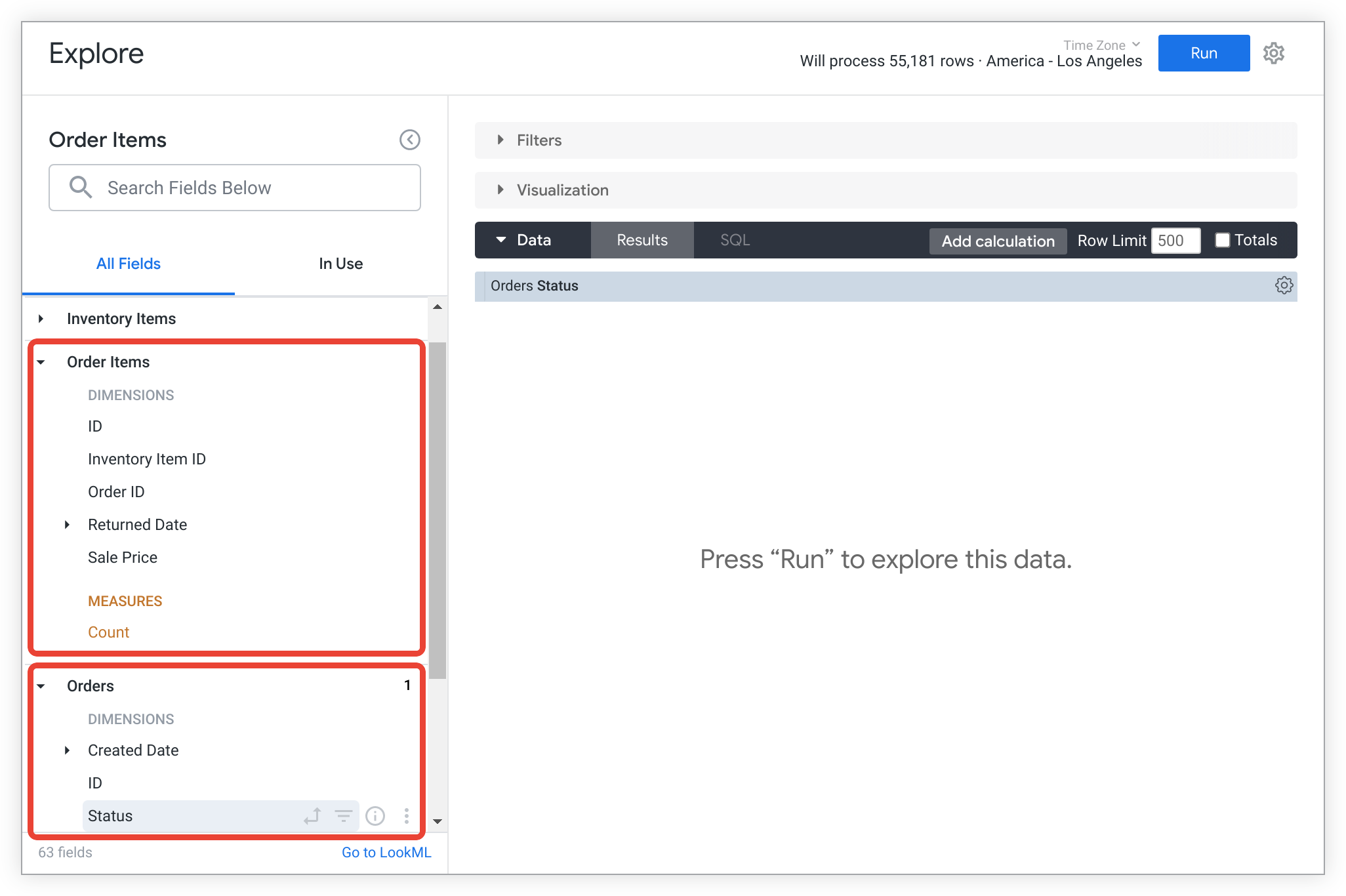
Em segundo lugar, a LookML descreve como unir orders e order_items. Essa LookML seria convertida no seguinte SQL:
SELECT ...
FROM order_items
LEFT JOIN orders
ON order_items.order_id = orders.id
Esses parâmetros da LookML são descritos em mais detalhes nas seções a seguir.
Parâmetros de junção
Quatro parâmetros principais são usados para junção: join, type, relationship e sql_on.
Etapa 1: iniciar a análise detalhada
Primeiro, crie a análise detalhada order_items:
explore: order_items { ... }
Etapa 2: join
Para fazer isso, primeiro declare a tabela em uma visualização. Neste exemplo, suponha que orders seja uma visualização existente no seu modelo.
Em seguida, use o parâmetro join para declarar que você quer unir a visualização orders à análise detalhada order_items:
explore: order_items {
join: orders { ... }
}
Etapa 3: type
Considere qual tipo de junção realizar. O Looker é compatível com LEFT JOIN, INNER JOIN, FULL OUTER JOIN e CROSS JOIN. Eles correspondem aos valores de parâmetro type de left_outer, inner, full_outer e cross.
explore: order_items {
join: orders {
type: left_outer
}
}
O valor padrão de type é left_outer.
Etapa 4: relationship
Defina uma relação de junção entre a análise detalhada order_items e a visualização orders. Declarar corretamente a relação de uma junção é importante para que o Looker calcule medidas precisas. A relação é definida da análise order_items para a visualização orders. As opções possíveis são one_to_one, many_to_one, one_to_many e many_to_many.
Neste exemplo, pode haver muitos itens para um único pedido. A relação da Análise order_items com a visualização orders é many_to_one:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
}
}
Se você não incluir um parâmetro relationship na junção, o Looker vai usar many_to_one por padrão.
Para mais dicas sobre como definir o parâmetro relationship corretamente para uma junção, consulte Como definir o parâmetro relationship corretamente.
Etapa 5: sql_on
Declare como unir as tabelas order_items e orders com o parâmetro sql_on ou foreign_key.
sql_on
O parâmetro sql_on é equivalente à cláusula ON no SQL gerado para uma consulta. Com esse parâmetro, é possível declarar quais campos devem ser correspondidos para realizar a junção:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
}
}
Você também pode escrever junções mais complexas. Por exemplo, talvez você queira unir apenas pedidos com id maior que 1.000:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} AND ${orders.id} > 1000 ;;
}
}
Consulte a documentação sobre operadores de substituição para saber mais sobre a sintaxe ${ ... } nesses exemplos.
Etapa 6: teste
Teste se essa junção está funcionando conforme o esperado acessando a análise detalhada Itens do pedido. Você vai ver campos de order_items e orders.
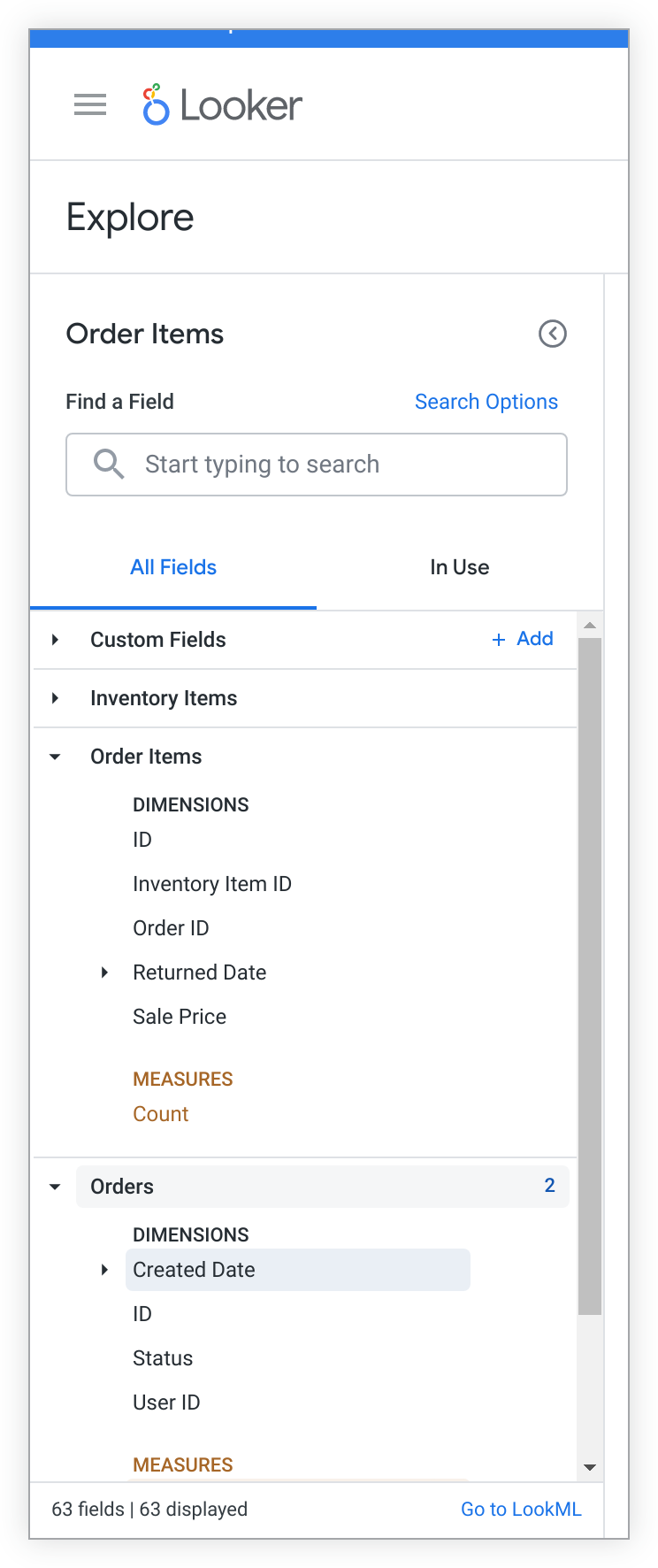
Consulte Testar os campos na análise detalhada para saber mais sobre como testar mudanças no LookML em uma análise detalhada.
Participar por outra visualização
É possível unir uma visualização a uma análise detalhada usando outra visualização. No exemplo de parâmetros de junção, você uniu orders a order_items usando o campo order_id. Também podemos querer unir os dados de uma visualização chamada users à análise detalhada order_items, mesmo que elas não compartilhem um campo comum. Isso pode ser feito unindo a visualização orders.
Use o parâmetro sql_on ou foreign_key para unir as visualizações users e orders, em vez de usar o recurso Detalhar order_items. Para isso, defina corretamente o escopo do campo de orders como orders.user_id.
Confira um exemplo usando o parâmetro sql_on:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
}
join: users {
type: left_outer
relationship: many_to_one
sql_on: ${orders.user_id} = ${users.id} ;;
}
}
Entrar em uma visualização mais de uma vez
Uma visualização users contém dados de compradores e vendedores. Para unir os dados dessa visualização ao order_items, mas separadamente para compradores e vendedores, é possível unir users duas vezes, com nomes diferentes, usando o parâmetro from.
O parâmetro from permite especificar qual visualização usar em uma junção, além de dar a ela um nome exclusivo. Exemplo:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
}
join: buyers {
from: users
type: left_outer
relationship: many_to_one
sql_on: ${orders.buyer_id} = ${buyers.id} ;;
}
join: sellers {
from: users
type: left_outer
relationship: many_to_one
sql_on: ${orders.seller_id} = ${sellers.id} ;;
}
}
Nesse caso, apenas os dados do comprador são unidos como buyers, enquanto apenas os dados do vendedor são unidos como sellers.
Observação: agora, a visualização users precisa ser referenciada pelos nomes de alias buyers e sellers na junção.
Como limitar campos de uma junção
O parâmetro fields permite especificar quais campos são extraídos de uma junção para uma Análise. Por padrão, todos os campos de uma visualização são incluídos quando unidos. No entanto, talvez você queira trazer apenas um subconjunto de campos.
Por exemplo, quando orders é combinado com order_items, talvez você queira trazer apenas os campos shipping e tax pela junção:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
fields: [shipping, tax]
}
}
Também é possível referenciar um conjunto de campos, como [set_a*]. Cada conjunto é definido em uma visualização usando o parâmetro set. Suponha que você tenha o seguinte conjunto definido na visualização orders:
set: orders_set {
fields: [created_date, shipping, tax]
}
Você pode escolher trazer apenas estes três campos ao unir orders e order_items:
explore: order_items {
join: orders {
type: left_outer
relationship: many_to_one
sql_on: ${order_items.order_id} = ${orders.id} ;;
fields: [orders_set*]
}
}
Agregações simétricas
O Looker usa um recurso chamado "agregações simétricas" para calcular agregações (como somas e médias) corretamente, mesmo quando as junções resultam em um fanout. Os agregados simétricos são descritos em mais detalhes em Noções básicas sobre agregados simétricos. O problema de fanout que os agregados simétricos resolvem é explicado na postagem da comunidade O problema de fanouts do SQL.
Chaves primárias obrigatórias
Para que as medidas (agregações) sejam incluídas nas junções, é necessário definir chaves primárias em todas as visualizações envolvidas na junção.
Para fazer isso, adicione o parâmetro primary_key à definição do campo de chave primária em cada visualização:
dimension: id {
type: number
primary_key: yes
}
Dialetos SQL compatíveis
Para que o Looker ofereça suporte a agregações simétricas no seu projeto, o dialeto do banco de dados também precisa oferecer. A tabela a seguir mostra quais dialetos são compatíveis com agregações simétricas na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | Sim |
| Amazon Athena | Sim |
| Amazon Aurora MySQL | Sim |
| Amazon Redshift | Sim |
| Amazon Redshift 2.1+ | Sim |
| Amazon Redshift Serverless 2.1+ | Sim |
| Apache Druid | Não |
| Apache Druid 0.13+ | Não |
| Apache Druid 0.18+ | Não |
| Apache Hive 2.3+ | Não |
| Apache Hive 3.1.2+ | Não |
| Apache Spark 3+ | Sim |
| ClickHouse | Não |
| Cloudera Impala 3.1+ | Sim |
| Cloudera Impala 3.1+ with Native Driver | Sim |
| Cloudera Impala with Native Driver | Não |
| DataVirtuality | Sim |
| Databricks | Sim |
| Denodo 7 | Sim |
| Denodo 8 & 9 | Sim |
| Dremio | Não |
| Dremio 11+ | Sim |
| Exasol | Sim |
| Google BigQuery Legacy SQL | Sim |
| Google BigQuery Standard SQL | Sim |
| Google Cloud PostgreSQL | Sim |
| Google Cloud SQL | Sim |
| Google Spanner | Sim |
| Greenplum | Sim |
| HyperSQL | Não |
| IBM Netezza | Sim |
| MariaDB | Sim |
| Microsoft Azure PostgreSQL | Sim |
| Microsoft Azure SQL Database | Sim |
| Microsoft Azure Synapse Analytics | Sim |
| Microsoft SQL Server 2008+ | Sim |
| Microsoft SQL Server 2012+ | Sim |
| Microsoft SQL Server 2016 | Sim |
| Microsoft SQL Server 2017+ | Sim |
| MongoBI | Não |
| MySQL | Sim |
| MySQL 8.0.12+ | Sim |
| Oracle | Sim |
| Oracle ADWC | Sim |
| PostgreSQL 9.5+ | Sim |
| PostgreSQL pre-9.5 | Sim |
| PrestoDB | Sim |
| PrestoSQL | Sim |
| SAP HANA | Sim |
| SAP HANA 2+ | Sim |
| SingleStore | Sim |
| SingleStore 7+ | Sim |
| Snowflake | Sim |
| Teradata | Sim |
| Trino | Sim |
| Vector | Sim |
| Vertica | Sim |
Se o dialeto não for compatível com agregações simétricas, tenha cuidado ao executar junções no Looker, já que alguns tipos podem resultar em agregações imprecisas (como somas e médias). Esse problema e as soluções alternativas são descritos em detalhes na postagem da comunidade O problema dos fanouts de SQL.
Saiba mais sobre junções
Para saber mais sobre os parâmetros de junção na LookML, consulte a documentação de referência de junção.