探索查询跟踪器和探索性能面板可提供探索查询的逐步性能数据。这些数据有助于确定用于排查和解决查询性能问题的关键入口点,并提供改进建议。
探索查询跟踪器
在探索查询运行时,探索查询跟踪器会显示探索查询在查询的三个阶段中的进度。
![]()
如果查询执行时间过长,查询跟踪器可以指示查询的哪个阶段导致了性能问题。这有助于确定可能出现性能问题的位置,以及优化工作可以发挥最大效用的位置。
只要“探索”可视化图表面板或“探索”数据面板处于打开状态,系统就会在探索运行时显示查询跟踪器。
探索效果面板
如需查看“探索”效果面板,请点击任意已运行的“探索”查询中的查看效果详情链接。

性能面板会显示查询在三个查询阶段中花费的时间,并包含指向性能文档和查询历史记录系统活动信息中心的链接,该信息中心会显示查询和用于创建查询的探索的当前和历史性能数据。
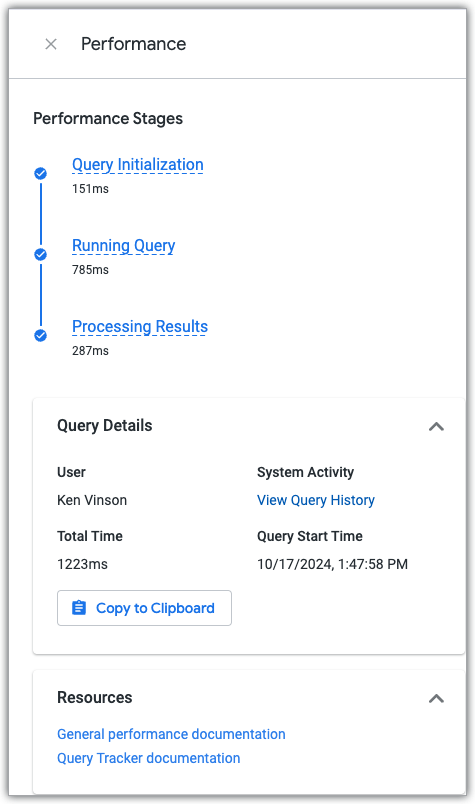
查询阶段
当 Looker 探索运行数据库查询时,该查询会分三个阶段执行,如下所示:
查询初始化阶段
在查询初始化阶段,Looker 会执行在将查询发送到数据库之前需要完成的所有任务。查询初始化阶段包括以下任务:
- 编译 LookML 模型
- 检查是否需要构建任何永久性派生表 (PDT)
- 生成查询 SQL
- 获取数据库连接
了解查询性能指标文档页面介绍了如何使用系统活动中的查询性能指标探索来查看查询的详细细分数据。查询跟踪器的查询初始化阶段包括查询性能指标探索中的异步工作器阶段、初始化阶段和连接处理阶段中所述的事件。
运行查询阶段
在运行查询阶段,Looker 会连接并查询您的数据库,以便返回查询结果。此阶段的性能问题可能表明外部数据库存在问题,例如 PDT 重建时间过长,可能需要优化;或者外部数据库表可能需要优化。运行查询阶段包括以下任务:
- 构建数据库中探索查询所需的任何 PDT
- 在数据库中运行所请求的查询
了解查询性能指标文档页面介绍了如何使用系统活动中的查询性能指标探索来查看查询的详细细分数据。查询跟踪器的正在运行的查询阶段包含查询效果指标探索中的主要查询阶段中所述的事件。
如果您在此阶段遇到性能问题,可以采取以下措施:
- 尽可能使用
many_to_one连接构建探索。将视图从最精细的级别联接到最高级别的详细程度 (many_to_one) 通常可提供最佳查询性能。 - 尽可能最大限度地利用缓存来与 ETL 政策同步,以减少数据库查询流量。默认情况下,Looker 会将查询缓存 1 小时。您可以使用
persist_with参数在探索中应用数据组,从而控制缓存政策并将 Looker 数据刷新与 ETL 流程同步。最大限度地利用缓存可让 Looker 与后端数据流水线更紧密地集成,从而最大限度地利用缓存,而不会有分析过时数据的风险。命名缓存政策可应用于整个模型,也可应用于单个 Explore 和持久派生表 (PDT)。 - 使用 Looker 的汇总感知功能创建汇总表或摘要表,以便 Looker 尽可能在查询中使用这些表,尤其是在查询大型数据库时。您还可以使用汇总感知功能来大幅提升整个信息中心的性能。如需了解详情,请参阅汇总感知教程。
- 使用 PDT 可加快查询速度。将包含许多复杂或低效联接的探索或包含子查询或子选择的维度转换为 PDT,以便在运行时之前预联接视图并使其处于就绪状态。
- 如果您的数据库方言支持增量 PDT,请配置增量 PDT,以缩短 Looker 重建 PDT 表的时间。
- 避免在 Looker 中定义的串联主键上将视图联接到探索中。而是基于视图中构成串联主键的基础字段进行联接。或者,将视图重新创建为 PDT,并在表的 SQL 定义中预定义串联的主键,而不是在视图的 LookML 中预定义。
- 使用 SQL Runner 中的“说明”工具进行基准比较。
EXPLAIN会针对给定的 SQL 查询生成数据库的查询执行计划概览,让您能够检测到可以优化的查询组件。如需了解详情,请参阅如何使用EXPLAIN优化 SQL 社区帖子。 - 声明索引。您可以在 Looker 中通过 SQL Runner 直接查看每个表的索引,方法是点击表中的齿轮图标,然后选择 Show Indexes。
最常受益于索引的列是重要日期和外键。为这些列添加索引几乎可以提高所有查询的性能。这也适用于 PDT。LookML 参数(例如
indexes、sort keys和distribution)可以得到适当应用。
“处理结果”阶段
在处理结果阶段,Looker 会处理和呈现查询结果。处理结果阶段包括以下任务:
- 将查询结果流式传输到缓存
- 解决表计算问题
- 设置 Liquid 模板语言的结果格式
- 合并查询
- 计算总计和小计
了解查询性能指标文档页面介绍了如何使用系统活动中的查询性能指标探索来查看查询的详细细分数据。查询跟踪器的处理结果阶段包括查询性能指标探索中的查询后阶段中所述的事件。
如果您在此阶段遇到性能问题,可以采取以下措施:
- 谨慎使用合并结果、自定义字段和表计算等功能。这些功能旨在用作概念验证,帮助您设计模型。 最佳实践是在 LookML 中对任何常用计算和函数进行硬编码,这样会生成要在数据库中处理的 SQL。过多的计算会争用 Looker 实例上的 Java 内存,导致 Looker 实例的响应速度变慢。
- 如果存在大量视图文件,请限制模型中包含的视图数量。在单个模型中包含所有视图可能会降低性能。如果项目中有大量视图,请考虑仅在每个模型中包含所需的视图文件。考虑为视图文件名使用战略性命名惯例,以便在模型中包含视图组。
includes参数文档中概述了一个示例。 - 避免在信息中心图块和 Look 中默认返回大量数据点。返回数千个数据点的查询会消耗更多内存。通过以下方式尽可能限制数据:在信息中心、Look 和探索中应用前端
过滤条件,并在 LookML 级别使用
required filters、conditionally_filter和sql_always_where参数。 - 请谨慎使用所有结果选项下载或传送查询,因为有些查询可能非常大,在处理时会使 Looker 服务器不堪重负。