El Explorador de consultas de Exploración y el panel Rendimiento de Exploración proporcionan datos de rendimiento paso a paso para una consulta de Exploración. Estos datos pueden ayudar a identificar los puntos de entrada clave para solucionar problemas de rendimiento con las consultas y proporcionar recomendaciones para mejorar el rendimiento.
Explorar el rastreador de consultas
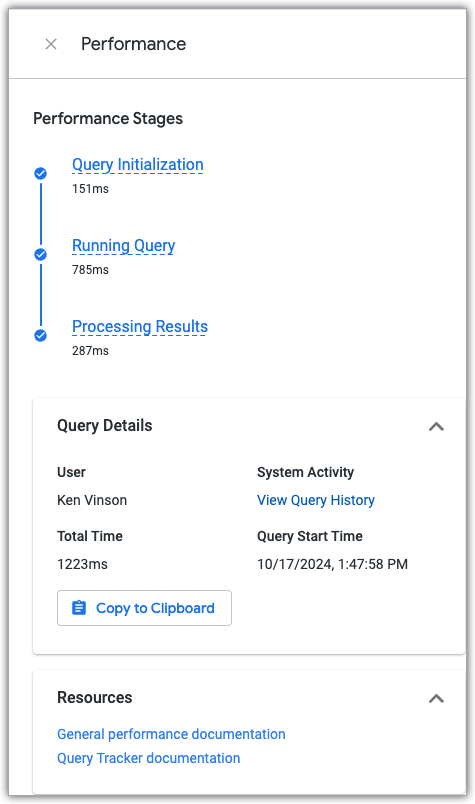
El rastreador de consultas de Explorar muestra el progreso de una consulta de Explorar a través de las tres fases de la consulta mientras se ejecuta.
![]()
Si una consulta tarda mucho en ejecutarse, el rastreador de consultas puede indicar qué fase de la consulta está causando el problema de rendimiento. Esto es útil para identificar dónde pueden ocurrir problemas de rendimiento y dónde los esfuerzos de optimización pueden ser más eficaces.
El seguimiento de consultas se muestra cuando se ejecuta un Explorar, siempre y cuando esté abierto el panel Visualización de Explorar o el panel Datos de Explorar.
Explora el panel Rendimiento
Para ver el panel Rendimiento de Explorar, haz clic en el vínculo Ver detalles del rendimiento, que está disponible en cualquier consulta de Explorar que se haya ejecutado.

El panel Rendimiento muestra el tiempo que la consulta dedicó a cada una de las tres fases de la consulta y contiene vínculos a la documentación sobre el rendimiento y al panel de actividad del sistema Historial de consultas, que muestra datos de rendimiento actuales e históricos de la consulta y del Explorar que se usó para crearla.
Fases de la búsqueda
Cuando un Explorar de Looker ejecuta una consulta de base de datos, la consulta se ejecuta en tres fases, como se indica a continuación:
- La fase de inicialización de la búsqueda
- La fase de ejecución de la consulta
- La fase de resultados del procesamiento
Fase de inicialización de la consulta
Durante la fase de inicialización de la consulta, Looker realiza todas las tareas necesarias antes de que se envíe la consulta a tu base de datos. La fase de Inicialización de la búsqueda incluye las siguientes tareas:
- Compila el modelo de LookML
- Verifica si se deberán compilar tablas derivadas persistentes (PDT).
- Genera el código SQL de la consulta
- Cómo adquirir la conexión de la base de datos
En la página de documentación Cómo comprender las métricas de rendimiento de las consultas, se describe cómo usar el Explorar Métricas de rendimiento de las consultas en Actividad del sistema para ver desgloses detallados de una consulta. La fase de inicialización de la consulta del rastreador de consultas incluye los eventos que se describen en las fases de trabajador asíncrono, inicialización y control de conexión del Explorador de Métricas de rendimiento de las consultas.
Fase de ejecución de la consulta
En la fase Ejecución de la consulta, Looker se comunica con tu base de datos, le envía consultas y muestra los resultados. Los problemas de rendimiento durante esta fase podrían indicar un problema con la base de datos externa, como PDT que tardan mucho en volver a compilarse y que podrían necesitar optimización, o tablas de bases de datos externas que podrían necesitar optimización. La fase Ejecución de la consulta incluye las siguientes tareas:
- Compila las PDT necesarias en la base de datos para la consulta de Explorar.
- Ejecutar la consulta solicitada en la base de datos
En la página de documentación Cómo comprender las métricas de rendimiento de las consultas, se describe cómo usar el Explorar Métricas de rendimiento de las consultas en Actividad del sistema para ver desgloses detallados de una consulta. La fase Ejecución de la consulta del monitor de consultas incluye los eventos que se describen en la fase de consultas principales del Explorador de Métricas de rendimiento de las consultas.
Estos son algunos pasos que puedes seguir si tienes problemas de rendimiento durante esta fase:
- Crea Explores con combinaciones
many_to_onesiempre que sea posible. Unir vistas desde el nivel más detallado hasta el nivel más alto de detalle (many_to_one) suele proporcionar el mejor rendimiento de la consulta. - Maximiza el almacenamiento en caché para sincronizarlo con tus políticas de ETL siempre que sea posible y, así, reducir el tráfico de consultas de la base de datos. De forma predeterminada, Looker almacena en caché las consultas durante una hora. Puedes controlar la política de almacenamiento en caché y sincronizar las actualizaciones de datos de Looker con tu proceso de ETL aplicando grupos de datos en Explorar con el parámetro
persist_with. Maximizar el almacenamiento en caché permite que Looker se integre más estrechamente con la canalización de datos de backend, de modo que se pueda maximizar el uso de la caché sin el riesgo de analizar datos obsoletos. Las políticas de almacenamiento en caché con nombre se pueden aplicar a un modelo completo o a Explorar y a tablas derivadas persistentes (PDT) individuales. - Usa la función de reconocimiento de agregaciones de Looker para crear tablas de resumen o de totales que Looker pueda usar para las consultas siempre que sea posible, en especial para las consultas comunes de bases de datos grandes. También puedes usar el conocimiento agregado para mejorar drásticamente el rendimiento de los paneles completos. Consulta el instructivo sobre la conciencia agregada para obtener más información.
- Usa PDT para acelerar las consultas. Convierte los Explorar con muchas uniones complejas o de bajo rendimiento, o dimensiones con subconsultas o subselecciones, en PDT para que las vistas se unan previamente y estén listas antes del tiempo de ejecución.
- Si tu dialecto de base de datos admite PDT incrementales, configura PDT incrementales para reducir el tiempo que Looker dedica a volver a compilar las tablas de PDT.
- Evita unir vistas en Explores en claves primarias concatenadas que se definen en Looker. En su lugar, une los campos base que componen la clave primaria concatenada de la vista. Como alternativa, puedes volver a crear la vista como un PDT con la clave primaria concatenada predefinida en la definición de SQL de la tabla, en lugar de en el LookML de una vista.
- Usa la herramienta Explicar en el Ejecutor de SQL para la comparativa.
EXPLAINproduce un resumen del plan de ejecución de consultas de tu base de datos para una consulta en SQL determinada, lo que te permite detectar los componentes de la consulta que se pueden optimizar. Obtén más información en la publicación de Comunidad Cómo optimizar SQL conEXPLAIN. - Declarar índices Puedes consultar los índices de cada tabla directamente en Looker desde SQL Runner. Para ello, haz clic en el ícono de ajustes de una tabla y, luego, selecciona Mostrar índices.
Las columnas más comunes que pueden beneficiarse de los índices son las fechas importantes y las claves externas. Agregar índices a estas columnas aumentará el rendimiento de casi todas las consultas. Esto también se aplica a los PDT. Los parámetros de LookML, como
indexes,sort keysydistribution, se pueden aplicar de forma adecuada.
Fase de procesamiento de resultados
Durante la fase de Procesamiento de resultados, Looker procesa y renderiza los resultados de la consulta. La fase de Procesamiento de resultados incluye las siguientes tareas:
- Transmite los resultados de la consulta a la caché
- Cómo resolver cálculos basados en tablas
- Cómo dar formato a los resultados del lenguaje de plantillas Liquid
- Cómo combinar consultas
- Cómo calcular totales y subtotales
En la página de documentación Cómo comprender las métricas de rendimiento de las consultas, se describe cómo usar el Explorar Métricas de rendimiento de las consultas en Actividad del sistema para ver desgloses detallados de una consulta. La fase Procesamiento de resultados del seguimiento de consultas incluye los eventos que se describen en la Fase posterior a la consulta del Explorador de Métricas de rendimiento de las consultas.
Estos son algunos pasos que puedes seguir si tienes problemas de rendimiento durante esta fase:
- Usa funciones como combinar resultados, campos personalizados y cálculos basados en tablas con moderación. Estas funciones están diseñadas para usarse como pruebas de concepto que te ayuden a diseñar tu modelo. La práctica recomendada es codificar de forma rígida cualquier cálculo y función que se usen con frecuencia en LookML, lo que generará SQL para que se procese en tu base de datos. Los cálculos excesivos pueden competir por la memoria de Java en la instancia de Looker, lo que hace que la instancia de Looker responda más lentamente.
- Limita la cantidad de vistas que incluyes en un modelo cuando hay una gran cantidad de archivos de vistas. Incluir todas las vistas en un solo modelo puede ralentizar el rendimiento. Cuando haya una gran cantidad de vistas en un proyecto, considera incluir solo los archivos de vista que se necesiten en cada modelo. Considera usar convenciones de nomenclatura estratégicas para los nombres de los archivos de vista para permitir la inclusión de grupos de vistas dentro de un modelo. Se describe un ejemplo en la documentación del parámetro
includes. - Evita mostrar una gran cantidad de puntos de datos de forma predeterminada en los paneles y las Looks. Las consultas que devuelven miles de datos consumirán más memoria. Asegúrate de que los datos se limiten siempre que sea posible aplicando
filtros de frontend a los paneles, las Looks y las Exploraciones, y a nivel de LookML con los parámetros
required filters,conditionally_filterysql_always_where. - Descarga o entrega consultas con la opción Todos los resultados con moderación, ya que algunas consultas pueden ser muy grandes y sobrecargar el servidor de Looker cuando se procesan.