En Looker, las tablas derivadas persistentes (PDT) se escriben en el esquema inicial de tu base de datos. Looker persiste y vuelve a compilar una PDT según su estrategia de persistencia. Cuando se activa una PDT para que se vuelva a compilar, Looker vuelve a compilar toda la tabla de forma predeterminada.
Una PDT incremental es una PDT que Looker compila agregando datos recientes a la tabla en lugar de recompilar la tabla en su totalidad:
Si tu dialecto admite PDT incrementales, puedes convertir los siguientes tipos de PDT en PDT incrementales:
La primera vez que ejecutas una consulta en una PDT incremental, Looker compila toda la PDT para obtener los datos iniciales. Si la tabla es grande, la compilación inicial puede tardar bastante, como sucedería con cualquier tabla grande. Una vez que se crea la tabla inicial, las compilaciones posteriores serán incrementales y tardarán menos tiempo si el PDT incremental se configura de forma estratégica.
Ten en cuenta lo siguiente para los PDT incrementales:
- Las PDT incrementales solo se admiten para las PDT que utilizan una estrategia de persistencia basada en activadores (
datagroup_trigger,sql_trigger_valueointerval_trigger). Las PDT incrementales no se admiten para las PDT que utilizan la estrategia de persistenciapersist_for. - En el caso de las PDT basadas en SQL, la consulta de la tabla se debe definir con el parámetro
sqlpara que se use como una PDT incremental. Los PDT basados en SQL que se definen con el parámetrosql_createo el parámetrocreate_processno se pueden compilar de forma incremental. Como puedes ver en el Ejemplo 1 de esta página, Looker usa un comando INSERT o MERGE para crear los incrementos de una PDT incremental. La tabla derivada no se puede definir con declaraciones personalizadas del lenguaje de definición de datos (DDL), ya que Looker no podría determinar qué declaraciones DDL se requerirían para crear un incremento preciso. - La tabla de origen del PDT incremental debe estar optimizada para las consultas basadas en el tiempo. Específicamente, la columna basada en el tiempo que se usa para la clave de incremento debe tener una estrategia de optimización, como particionamiento, sortkeys, índices o cualquier otra estrategia de optimización que se admita para tu dialecto. Se recomienda optimizar la tabla de origen, ya que, cada vez que se actualiza la tabla incremental, Looker consulta la tabla de origen para determinar los valores más recientes de la columna basada en el tiempo que se usa para la clave de incremento. Si la tabla de origen no está optimizada para estas consultas, la consulta de Looker para los valores más recientes puede ser lenta y costosa.
Cómo definir un PDT incremental
Puedes usar los siguientes parámetros para convertir una PDT en una PDT incremental:
increment_key(obligatorio para que el PDT sea incremental): Define el período para el que se deben consultar los registros nuevos.{% incrementcondition %}Filtro de Liquid (obligatorio para convertir un PDT basado en SQL en un PDT incremental; no se aplica a los PDT basados en LookML): Conecta la clave de incremento a la columna de tiempo de la base de datos en la que se basa la clave de incremento. Consulta la página de documentación sobreincrement_keypara obtener más información.increment_offset(opcional): Es un número entero que define la cantidad de períodos anteriores (en la granularidad de la clave de incremento) que se vuelven a compilar para cada compilación incremental. El parámetroincrement_offsetes útil en el caso de datos que llegan tarde, en el que los períodos anteriores pueden tener datos nuevos que no se incluyeron cuando se creó y agregó originalmente el incremento al PDT.
Consulta la página de documentación del parámetro increment_key para ver ejemplos que muestran cómo crear PDT incrementales a partir de tablas derivadas nativas persistentes, tablas derivadas persistentes basadas en SQL y tablas de agregación.
A continuación, se muestra un ejemplo simple de un archivo de vista que define una PDT incremental basada en LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Esta tabla se compilará en su totalidad la primera vez que se ejecute una consulta en ella. Después de eso, el PDT se volverá a compilar en incrementos de un día (increment_key: departure_date) y se retrocederá tres días (increment_offset: 3).
La clave de incremento se basa en la dimensión departure_date, que en realidad es el período de la dimensión date del grupo de dimensiones departure. (Consulta la página de documentación del parámetro dimension_group para obtener una descripción general de cómo funcionan los grupos de dimensiones). El grupo de dimensiones y el período se definen en la vista flights, que es el explore_source para este PDT. Así se define el grupo de dimensiones departure en el archivo de vista flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interacción de los parámetros de incremento y la estrategia de persistencia
Los parámetros de configuración increment_key y increment_offset de una PDT son independientes de la estrategia de persistencia de la PDT:
- La estrategia de persistencia del PDT incremental determina solo cuándo se incrementa el PDT. El compilador de PDT no modifica el PDT incremental, a menos que se active la estrategia de persistencia de la tabla o que el PDT se active manualmente con la opción Rebuild Derived Tables & Run en un Explorar.
- Cuando el PDT se incrementa, el compilador de PDT determinará cuándo se agregaron los datos más recientes a la tabla, en términos del incremento de tiempo más actual (el período definido por el parámetro
increment_key). Según eso, el compilador de PDT truncará los datos hasta el comienzo del incremento de tiempo más reciente de la tabla y, luego, compilará el incremento más reciente a partir de ahí. - Si el PDT tiene un parámetro
increment_offset, el compilador de PDT también volverá a compilar la cantidad de períodos anteriores especificados en el parámetroincrement_offset. Los períodos anteriores se remontan al comienzo del incremento de tiempo más actual (el período definido por el parámetroincrement_key).
En los siguientes ejemplos, se ilustra cómo se actualizan las PDT incrementales mostrando la interacción de increment_key, increment_offset y la estrategia de persistencia.
Ejemplo 1
En este ejemplo, se usa un PDT con las siguientes propiedades:
- Increment key: Fecha
- Increment offset: 3
- Estrategia de persistencia: Se activa una vez al mes, el primer día del mes.
Así se actualizará esta tabla:
- Una estrategia de persistencia mensual significa que la tabla se compila automáticamente una vez al mes. Esto significa que, por ejemplo, el 1 de junio, la última fila de la tabla se habrá agregado el 1 de mayo.
- Como este PDT tiene una clave de incremento basada en la fecha, el compilador de PDT truncará el 1 de mayo hasta el comienzo del día y volverá a compilar los datos del 1 de mayo hasta el día actual, el 1 de junio.
- Además, este PDT tiene un desplazamiento de incremento de
3. Por lo tanto, el compilador de PDT también recompila los datos de los tres períodos anteriores (días) al 1 de mayo. El resultado es que los datos se vuelven a generar para el 28, el 29 y el 30 de abril, y hasta el día de hoy, 1 de junio.
En términos de SQL, este es el comando que el compilador de PDT ejecutará el 1 de junio para determinar las filas de la PDT existente que se deben volver a compilar:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Y aquí está el comando SQL que el compilador de PDT ejecutará el 1 de junio para compilar el incremento más reciente:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Ejemplo 2
En este ejemplo, se usa un PDT con las siguientes propiedades:
- Estrategia de persistencia: Se activa una vez al día
- Increment key: mes
- Increment offset: 0
Así se actualizará esta tabla el 1 de junio:
- La estrategia de persistencia diaria significa que la tabla se compila automáticamente una vez al día. El 1 de junio, la última fila de la tabla se habrá agregado el 31 de mayo.
- Dado que la clave de incremento se basa en el mes, el compilador de PDT truncará los datos desde el 31 de mayo hasta el comienzo del mes y volverá a compilar los datos de todo mayo y hasta el día actual, incluido el 1 de junio.
- Como esta PDT no tiene un desplazamiento de incremento, no se vuelven a compilar los períodos anteriores.
Así se actualizará esta tabla el 2 de junio:
- El 2 de junio, la última fila de la tabla se habrá agregado el 1 de junio.
- Dado que el compilador de PDT truncará los datos hasta el comienzo del mes de junio y, luego, volverá a compilar los datos a partir del 1 de junio y hasta el día actual, los datos se volverán a compilar solo para el 1 y el 2 de junio.
- Como esta PDT no tiene un desplazamiento de incremento, no se vuelven a compilar los períodos anteriores.
Ejemplo 3
En este ejemplo, se usa un PDT con las siguientes propiedades:
- Increment key: mes
- Increment offset: 3
- Estrategia de persistencia: Se activa una vez al día
Este caso ilustra una configuración deficiente para una PDT incremental, ya que es una PDT que se activa diariamente con un desfase de tres meses. Esto significa que, cada día, se volverán a compilar al menos tres meses de datos, lo que sería un uso muy ineficiente de un PDT incremental. Sin embargo, es un escenario interesante para examinar como una forma de comprender cómo funcionan los PDT incrementales.
Así se actualizará esta tabla el 1 de junio:
- La estrategia de persistencia diaria significa que la tabla se compila automáticamente una vez al día. Por ejemplo, el 1 de junio, la última fila de la tabla se habrá agregado el 31 de mayo.
- Dado que la clave de incremento se basa en el mes, el compilador de PDT truncará los datos desde el 31 de mayo hasta el comienzo del mes y volverá a compilar los datos de todo mayo y hasta el día actual, incluido el 1 de junio.
- Además, este PDT tiene un desplazamiento de incremento de
3. Esto significa que el compilador de PDT también recompila los datos de los tres períodos anteriores (meses) a mayo. El resultado es que los datos se recompilan desde febrero, marzo y abril, y hasta el día actual, el 1 de junio.
Así se actualizará esta tabla el 2 de junio:
- El 2 de junio, la última fila de la tabla se habrá agregado el 1 de junio.
- El compilador de PDT truncará el mes hasta el 1 de junio y volverá a compilar los datos del mes de junio, incluido el 2 de junio.
- Además, debido al desplazamiento del incremento, el compilador de PDT volverá a compilar los datos de los tres meses anteriores a junio. El resultado es que los datos se reconstruyen desde marzo, abril, mayo y hasta el día actual, 2 de junio.
Cómo probar un PDT incremental en el modo de desarrollo
Antes de implementar un nuevo PDT incremental en tu entorno de producción, puedes probarlo para asegurarte de que se compile y se incremente. Para probar un PDT incremental en el modo de desarrollo, sigue estos pasos:
Crea una exploración para el PDT:
- En un archivo de modelo asociado, usa el parámetro
includepara incluir el archivo de vista del PDT en el archivo de modelo. - En el mismo archivo del modelo, usa el parámetro
explorepara crear un Explore para la vista del PDT incremental.
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- En un archivo de modelo asociado, usa el parámetro
Abre la función Explorar para el PDT. Para ello, selecciona el botón Ver acciones del archivo y, luego, elige un nombre de Explorar.
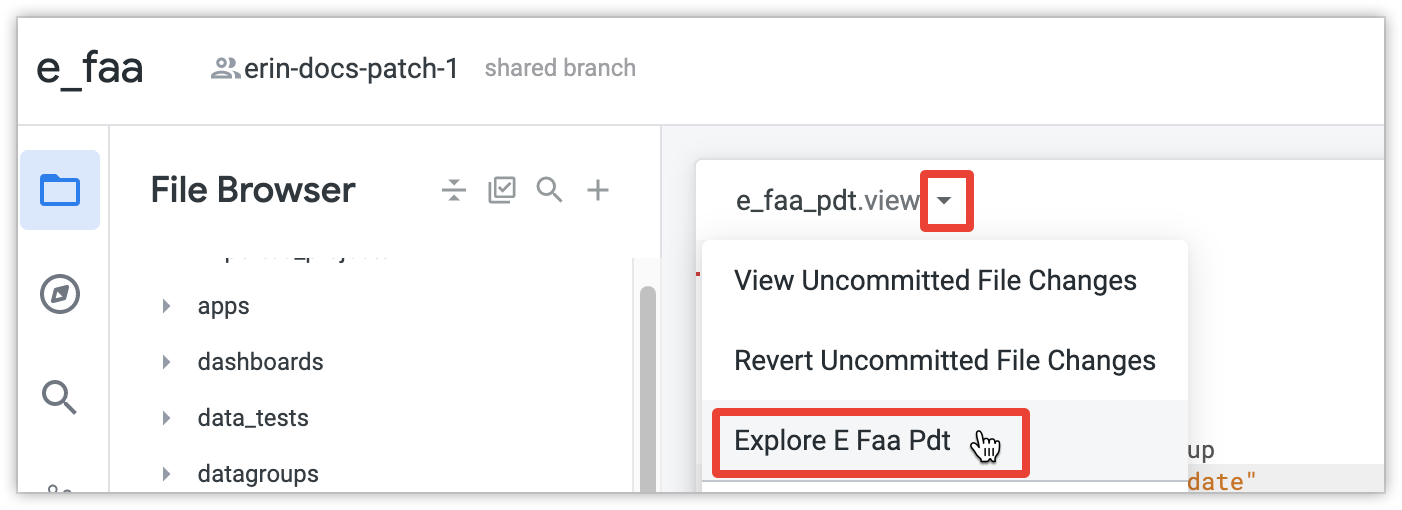
En Explorar, selecciona algunas dimensiones o mediciones y haz clic en Ejecutar. Luego, Looker compilará todo el PDT. Si esta es la primera consulta que ejecutas en el PDT incremental, el compilador de PDT compilará todo el PDT para obtener los datos iniciales. Si la tabla es grande, la compilación inicial puede tardar bastante, como sucedería con cualquier tabla grande.
Puedes verificar que se haya compilado el PDT inicial de las siguientes maneras:
- Si tienes el permiso
see_logs, puedes verificar que la tabla se haya compilado en el Registro de eventos de PDT. Si no ves los eventos de creación de PDT en el registro de eventos de PDT, verifica la información de estado en la parte superior del Explorador del registro de eventos de PDT. Si dice "de la caché", puedes seleccionar Borrar caché y actualizar para obtener información más reciente. - De lo contrario, puedes consultar los comentarios en la pestaña SQL de la barra Datos de la función Explorar. En la pestaña SQL, se muestran la consulta y las acciones que se realizarán cuando la ejecutes en Explorar. Por ejemplo, si los comentarios en la pestaña SQL dicen
-- generate derived table e_incremental_pdt,
- Si tienes el permiso
Una vez que crees la compilación inicial de la PDT, solicita una compilación incremental de la PDT con la opción Volver a compilar tablas derivadas y ejecutar de la Exploración.
Puedes usar los mismos métodos que antes para verificar que la PDT se compile de forma incremental:
- Si tienes el permiso
see_logs, puedes usar el Registro de eventos de PDT para ver los eventos decreate increment completedel PDT incremental. Si no ves este evento en el registro de eventos de PDT y el estado de la consulta indica "desde la caché", selecciona Borrar caché y actualizar para obtener información más reciente. - Consulta los comentarios en la pestaña SQL de la barra Datos de la Exploración. En este caso, los comentarios indicarán que se incrementó el PDT. Por ejemplo:
-- increment persistent derived table e_incremental_pdt to generation 2
- Si tienes el permiso
Una vez que hayas verificado que la PDT se compila y se incrementa correctamente, si no quieres conservar la función Explorar dedicada para la PDT, puedes quitar los parámetros
exploreyincludede la PDT de tu archivo de modelo o comentarlos.
Después de que se compila la PDT en el modo de desarrollo, se usará la misma tabla para la producción una vez que implementes los cambios, a menos que realices más cambios en la definición de la tabla. Consulta la sección Tablas persistentes en el modo de desarrollo de la página de documentación Tablas derivadas en Looker para obtener más información.
Soluciona problemas relacionados con los PDT incrementales
En esta sección, se describen algunos problemas comunes que puedes encontrar cuando usas PDT incrementales, así como los pasos para solucionar esos problemas.
No se puede compilar el PDT incremental después de un cambio de esquema
Si tu PDT incremental es una tabla derivada basada en SQL y el parámetro sql incluye un comodín como SELECT *, los cambios en el esquema de la base de datos subyacente (como la adición o eliminación de columnas, o el cambio del tipo de datos de las columnas) pueden hacer que el PDT falle con el siguiente error:
SQL Error in incremental PDT: Query execution failed
Para resolver este problema, edita la instrucción SELECT en el parámetro sql para seleccionar columnas individuales. Por ejemplo, si tu cláusula SELECT es SELECT *, cámbiala a SELECT column1, column2, ....
Si tu esquema cambia y deseas volver a compilar tu PDT incremental desde cero, usa la llamada a la API start_pdt_build y, luego, incluye el parámetro full_force_incremental.
Dialectos de bases de datos admitidos para los PDT incrementales
Para que Looker admita PDT incrementales en tu proyecto de Looker, el dialecto de la base de datos debe admitir comandos del lenguaje de definición de datos (DDL) que permitan borrar e insertar filas.
En la siguiente tabla, se muestran los dialectos que admiten PDT incrementales en la versión más reciente de Looker (en el caso de Databricks, las PDT incrementales solo se admiten en la versión 12.1 y posteriores de Databricks):
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Sí |
| Amazon Redshift 2.1+ | Sí |
| Amazon Redshift Serverless 2.1+ | Sí |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Sí |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Sí |
| Google Cloud PostgreSQL | Sí |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sí |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Sí |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Sí |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Sí |
| MySQL 8.0.12+ | Sí |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Sí |
| PostgreSQL pre-9.5 | Sí |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Sí |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Sí |