In Looker, una tabella derivata è una query i cui risultati vengono utilizzati come se la query fosse una tabella effettiva nel database.
Ad esempio, potresti avere una tabella di database chiamata orders con molte colonne. Vuoi calcolare alcune metriche aggregate a livello di cliente, ad esempio il numero di ordini effettuati da ciascun cliente o la data del primo ordine. Utilizzando una tabella derivata nativa o una tabella derivata basata su SQL, puoi creare una nuova tabella di database denominata customer_order_summary che include queste metriche.
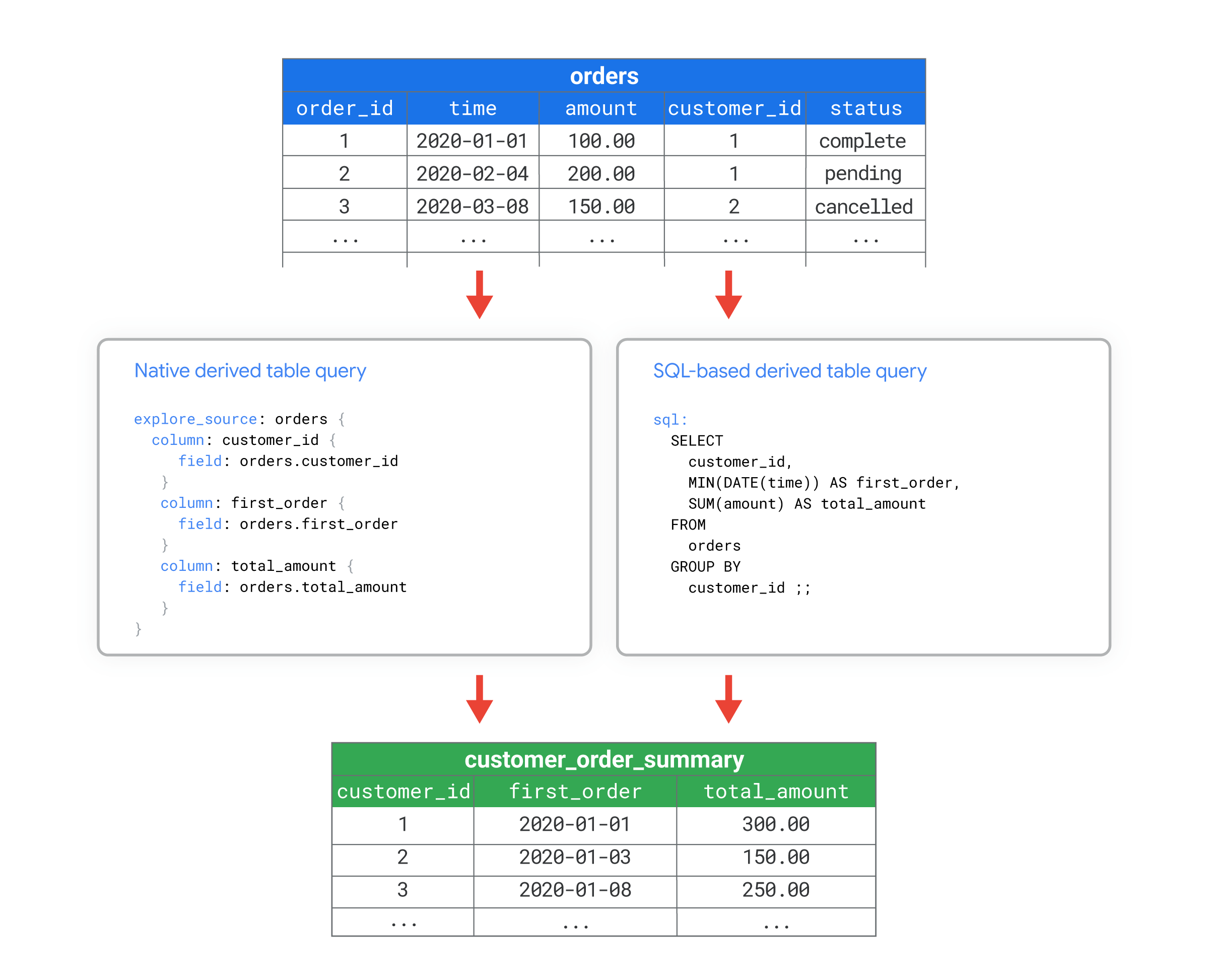
Puoi quindi utilizzare la tabella derivata customer_order_summary come qualsiasi altra tabella del database.
Per i casi d'uso più comuni delle tabelle derivate, visita la pagina Looker cookbooks: Getting the most out of derived tables in Looker.
Tabelle derivate native e tabelle derivate basate su SQL
Per creare una tabella derivata nel tuo progetto Looker, utilizza il parametro derived_table in un parametro view. All'interno del parametro derived_table, puoi definire la query per la tabella derivata in due modi:
- Per una tabella derivata nativa, definisci la tabella derivata con una query basata su LookML.
- Per una tabella derivata basata su SQL, definisci la tabella derivata con una query SQL.
Ad esempio, i seguenti file di visualizzazione mostrano come utilizzare LookML per creare una visualizzazione da una tabella derivata customer_order_summary. Le due versioni di LookML mostrano come creare tabelle derivate equivalenti utilizzando LookML o SQL per definire la query per la tabella derivata:
- La tabella derivata nativa definisce la query con LookML nel parametro
explore_source. In questo esempio, la query si basa su una visualizzazioneordersesistente, definita in un file separato che non viene mostrato in questo esempio. La queryexplore_sourcenella tabella derivata nativa importa i campicustomer_id,first_orderetotal_amountdal file della vistaorders. - La tabella derivata basata su SQL definisce la query utilizzando SQL nel parametro
sql. In questo esempio, la query SQL è una query diretta della tabellaordersnel database.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
Entrambe le versioni creano una vista denominata customer_order_summary basata sulla tabella orders, con le colonne customer_id, first_order, e total_amount.
A parte il parametro derived_table e i relativi parametri secondari, questa visualizzazione customer_order_summary funziona come qualsiasi altro file di visualizzazione. Indipendentemente dal fatto che tu definisca la query della tabella derivata con LookML o con SQL, puoi creare misure e dimensioni LookML basate sulle colonne della tabella derivata.
Una volta definita la tabella derivata, puoi utilizzarla come qualsiasi altra tabella del database.
Tabelle derivate native
Le tabelle derivate native si basano su query che definisci utilizzando i termini LookML. Per creare una tabella derivata nativa, utilizza il parametro explore_source all'interno del parametro derived_table di un parametro view. Crei le colonne della tabella derivata nativa facendo riferimento alle dimensioni o alle misure LookML nel modello. Consulta il file di visualizzazione della tabella derivata nativa nell'esempio precedente.
Rispetto alle tabelle derivate basate su SQL, le tabelle derivate native sono molto più facili da leggere e comprendere durante la modellazione dei dati.
Per informazioni dettagliate sulla creazione di tabelle derivate native, consulta la pagina della documentazione Creazione di tabelle derivate native.
Tabelle derivate basate su SQL
Per creare una tabella derivata basata su SQL, definisci una query in termini SQL, creando colonne nella tabella utilizzando una query SQL. Non puoi fare riferimento a dimensioni e misure LookML in una tabella derivata basata su SQL. Consulta il file di visualizzazione della tabella derivata basata su SQL nell'esempio precedente.
In genere, la query SQL viene definita utilizzando il parametro sql all'interno del parametro derived_table di un parametro view.
Una scorciatoia utile per creare query basate su SQL in Looker è utilizzare SQL Runner per creare la query SQL e trasformarla in una definizione di tabella derivata.
In alcuni casi limite non è consentito l'utilizzo del parametro sql. In questi casi, Looker supporta i seguenti parametri per definire una query SQL per le tabelle derivate persistenti (PDT):
create_process: quando utilizzi il parametrosqlper una PDT, in background Looker esegue il wrapping dell'CREATE TABLEistruzione DDL (Data Definition Language) del dialetto intorno alla query per creare la PDT dalla query SQL. Alcuni dialetti non supportano un'istruzione SQLCREATE TABLEin un unico passaggio. Per questi dialetti, non puoi creare una PDT con il parametrosql. Puoi invece utilizzare il parametrocreate_processper creare una PDT in più passaggi. Per informazioni ed esempi, consulta la pagina della documentazione del parametrocreate_process.sql_create: se il tuo caso d'uso richiede comandi DDL personalizzati e il tuo dialetto supporta DDL (ad esempio, BigQuery ML predittivo di Google), puoi utilizzare il parametrosql_createper creare un PDT anziché utilizzare il parametrosql. Per informazioni ed esempi, consulta la pagina della documentazione relativa asql_create.
Indipendentemente dal fatto che utilizzi il parametro sql, create_process o sql_create, in tutti questi casi stai definendo la tabella derivata con una query SQL, quindi tutte queste tabelle sono considerate tabelle derivate basate su SQL.
Quando definisci una tabella derivata basata su SQL, assicurati di assegnare a ogni colonna un alias pulito utilizzando AS. Questo perché dovrai fare riferimento ai nomi delle colonne del set di risultati nelle dimensioni, ad esempio ${TABLE}.first_order. Per questo motivo, l'esempio precedente utilizza MIN(DATE(time)) AS first_order anziché solo MIN(DATE(time)).
Tabelle derivate temporanee e permanenti
Oltre alla distinzione tra tabelle derivate native e tabelle derivate basate su SQL, esiste anche una distinzione tra una tabella derivata temporanea, che non viene scritta nel database, e una tabella derivata permanente (PDT), che viene scritta in uno schema del database.
Le tabelle derivate native e quelle basate su SQL possono essere temporanee o permanenti.
Tabelle derivate temporanee
Le tabelle derivate mostrate in precedenza sono esempi di tabelle derivate temporanee. Sono temporanei perché non è definita alcuna strategia di persistenza nel parametro derived_table.
Le tabelle derivate temporanee non vengono scritte nel database. Quando un utente esegue una query di esplorazione che coinvolge una o più tabelle derivate, Looker crea una query SQL utilizzando una combinazione specifica del dialetto dell'SQL per le tabelle derivate più i campi, le unioni e i valori di filtro richiesti. Se la combinazione è già stata eseguita e i risultati sono ancora validi nella cache, Looker utilizza i risultati memorizzati nella cache. Per ulteriori informazioni sulla memorizzazione nella cache delle query in Looker, consulta la pagina della documentazione Memorizzazione nella cache delle query.
In caso contrario, se Looker non può utilizzare i risultati memorizzati nella cache, deve eseguire una nuova query sul database ogni volta che un utente richiede dati da una tabella derivata temporanea. Per questo motivo, devi assicurarti che le tabelle derivate temporanee siano efficienti e non sovraccarichino eccessivamente il database. Nei casi in cui l'esecuzione della query richiede un po' di tempo, una PDT è spesso un'opzione migliore.
Dialetti di database supportati per le tabelle derivate temporanee
Affinché Looker supporti le tabelle derivate nel tuo progetto Looker, anche il dialetto del database deve supportarle. La tabella seguente mostra quali dialetti supportano le tabelle derivate nell'ultima release di Looker:
Fai clic qui per visualizzare la tabella.
| Dialetto | Supportato? |
|---|---|
| Actian Avalanche | Sì |
| Amazon Athena | Sì |
| Amazon Aurora MySQL | Sì |
| Amazon Redshift | Sì |
| Amazon Redshift 2.1+ | Sì |
| Amazon Redshift Serverless 2.1+ | Sì |
| Apache Druid | Sì |
| Apache Druid 0.13+ | Sì |
| Apache Druid 0.18+ | Sì |
| Apache Hive 2.3+ | Sì |
| Apache Hive 3.1.2+ | Sì |
| Apache Spark 3+ | Sì |
| ClickHouse | Sì |
| Cloudera Impala 3.1+ | Sì |
| Cloudera Impala 3.1+ with Native Driver | Sì |
| Cloudera Impala with Native Driver | Sì |
| DataVirtuality | Sì |
| Databricks | Sì |
| Denodo 7 | Sì |
| Denodo 8 & 9 | Sì |
| Dremio | Sì |
| Dremio 11+ | Sì |
| Exasol | Sì |
| Google BigQuery Legacy SQL | Sì |
| Google BigQuery Standard SQL | Sì |
| Google Cloud PostgreSQL | Sì |
| Google Cloud SQL | Sì |
| Google Spanner | Sì |
| Greenplum | Sì |
| HyperSQL | Sì |
| IBM Netezza | Sì |
| MariaDB | Sì |
| Microsoft Azure PostgreSQL | Sì |
| Microsoft Azure SQL Database | Sì |
| Microsoft Azure Synapse Analytics | Sì |
| Microsoft SQL Server 2008+ | Sì |
| Microsoft SQL Server 2012+ | Sì |
| Microsoft SQL Server 2016 | Sì |
| Microsoft SQL Server 2017+ | Sì |
| MongoBI | Sì |
| MySQL | Sì |
| MySQL 8.0.12+ | Sì |
| Oracle | Sì |
| Oracle ADWC | Sì |
| PostgreSQL 9.5+ | Sì |
| PostgreSQL pre-9.5 | Sì |
| PrestoDB | Sì |
| PrestoSQL | Sì |
| SAP HANA | Sì |
| SAP HANA 2+ | Sì |
| SingleStore | Sì |
| SingleStore 7+ | Sì |
| Snowflake | Sì |
| Teradata | Sì |
| Trino | Sì |
| Vector | Sì |
| Vertica | Sì |
Tabelle derivate permanenti
Una tabella derivata permanente (PDT) è una tabella derivata che viene scritta in uno schema temporaneo del database e rigenerata in base alla pianificazione specificata con una strategia di persistenza.
Una PDT può essere una tabella derivata nativa o una tabella derivata basata su SQL.
Requisiti per i PDT
Per utilizzare le tabelle derivate permanenti (PDT) nel tuo progetto Looker, devi disporre di quanto segue:
- Un dialetto del database che supporti le PDT. Consulta la sezione Dialetti di database supportati per le tabelle derivate permanenti più avanti in questa pagina per gli elenchi dei dialetti che supportano le tabelle derivate permanenti basate su SQL e le tabelle derivate permanenti native.
Uno schema temporaneo sul database. Può essere qualsiasi schema del tuo database, ma ti consigliamo di crearne uno nuovo da utilizzare solo a questo scopo. L'amministratore del database deve configurare lo schema con l'autorizzazione di scrittura per l'utente del database Looker.
Una connessione Looker configurata con l'opzione Attiva PDT attivata. Questa impostazione Abilita PDT viene in genere configurata durante la configurazione iniziale della connessione Looker (consulta la pagina di documentazione Dialetti Looker per istruzioni sul dialetto del tuo database), ma puoi anche abilitare le PDT per la connessione dopo la configurazione iniziale.
Dialetti del database supportati per le PDT
Affinché Looker supporti le PDT nel tuo progetto Looker, anche il dialetto del database deve supportarle.
Per supportare qualsiasi tipo di PDT (basate su LookML o SQL), il dialetto deve supportare le scritture nel database, tra gli altri requisiti. Esistono alcune configurazioni di database di sola lettura che non consentono il funzionamento della persistenza (più comunemente i database di replica hot-swap Postgres). In questi casi, puoi utilizzare le tabelle derivate temporanee.
La tabella seguente mostra i dialetti che supportano le tabelle derivate basate su SQL permanenti nell'ultima release di Looker:
Fai clic qui per visualizzare la tabella.
| Dialetto | Supportato? |
|---|---|
| Actian Avalanche | Sì |
| Amazon Athena | Sì |
| Amazon Aurora MySQL | Sì |
| Amazon Redshift | Sì |
| Amazon Redshift 2.1+ | Sì |
| Amazon Redshift Serverless 2.1+ | Sì |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Sì |
| Apache Hive 3.1.2+ | Sì |
| Apache Spark 3+ | Sì |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Sì |
| Cloudera Impala 3.1+ with Native Driver | Sì |
| Cloudera Impala with Native Driver | Sì |
| DataVirtuality | No |
| Databricks | Sì |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Sì |
| Google BigQuery Legacy SQL | Sì |
| Google BigQuery Standard SQL | Sì |
| Google Cloud PostgreSQL | Sì |
| Google Cloud SQL | Sì |
| Google Spanner | No |
| Greenplum | Sì |
| HyperSQL | No |
| IBM Netezza | Sì |
| MariaDB | Sì |
| Microsoft Azure PostgreSQL | Sì |
| Microsoft Azure SQL Database | Sì |
| Microsoft Azure Synapse Analytics | Sì |
| Microsoft SQL Server 2008+ | Sì |
| Microsoft SQL Server 2012+ | Sì |
| Microsoft SQL Server 2016 | Sì |
| Microsoft SQL Server 2017+ | Sì |
| MongoBI | No |
| MySQL | Sì |
| MySQL 8.0.12+ | Sì |
| Oracle | Sì |
| Oracle ADWC | Sì |
| PostgreSQL 9.5+ | Sì |
| PostgreSQL pre-9.5 | Sì |
| PrestoDB | Sì |
| PrestoSQL | Sì |
| SAP HANA | Sì |
| SAP HANA 2+ | Sì |
| SingleStore | Sì |
| SingleStore 7+ | Sì |
| Snowflake | Sì |
| Teradata | Sì |
| Trino | Sì |
| Vector | Sì |
| Vertica | Sì |
Per supportare le tabelle derivate native persistenti (che hanno query basate su LookML), il dialetto deve supportare anche una funzione DDL CREATE TABLE. Ecco un elenco dei dialetti che supportano le tabelle derivate native (basate su LookML) permanenti nell'ultima release di Looker:
Fai clic qui per visualizzare la tabella.
| Dialetto | Supportato? |
|---|---|
| Actian Avalanche | Sì |
| Amazon Athena | Sì |
| Amazon Aurora MySQL | Sì |
| Amazon Redshift | Sì |
| Amazon Redshift 2.1+ | Sì |
| Amazon Redshift Serverless 2.1+ | Sì |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Sì |
| Apache Hive 3.1.2+ | Sì |
| Apache Spark 3+ | Sì |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Sì |
| Cloudera Impala 3.1+ with Native Driver | Sì |
| Cloudera Impala with Native Driver | Sì |
| DataVirtuality | No |
| Databricks | Sì |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Sì |
| Google BigQuery Legacy SQL | Sì |
| Google BigQuery Standard SQL | Sì |
| Google Cloud PostgreSQL | Sì |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sì |
| HyperSQL | No |
| IBM Netezza | Sì |
| MariaDB | Sì |
| Microsoft Azure PostgreSQL | Sì |
| Microsoft Azure SQL Database | Sì |
| Microsoft Azure Synapse Analytics | Sì |
| Microsoft SQL Server 2008+ | Sì |
| Microsoft SQL Server 2012+ | Sì |
| Microsoft SQL Server 2016 | Sì |
| Microsoft SQL Server 2017+ | Sì |
| MongoBI | No |
| MySQL | Sì |
| MySQL 8.0.12+ | Sì |
| Oracle | Sì |
| Oracle ADWC | Sì |
| PostgreSQL 9.5+ | Sì |
| PostgreSQL pre-9.5 | Sì |
| PrestoDB | Sì |
| PrestoSQL | Sì |
| SAP HANA | Sì |
| SAP HANA 2+ | Sì |
| SingleStore | Sì |
| SingleStore 7+ | Sì |
| Snowflake | Sì |
| Teradata | Sì |
| Trino | Sì |
| Vector | Sì |
| Vertica | Sì |
Creazione incrementale di PDT
Una PDT incrementale è una tabella derivata persistente che Looker crea aggiungendo nuovi dati alla tabella anziché ricostruirla interamente.
Se il tuo dialetto supporta le PDT incrementali e la tua PDT utilizza una strategia di persistenza basata su trigger (datagroup_trigger, sql_trigger_value o interval_trigger), puoi definire la PDT come PDT incrementale.
Per ulteriori informazioni, consulta la pagina della documentazione relativa alle PDT incrementali.
Dialetti di database supportati per le PDT incrementali
Affinché Looker supporti le PDT incrementali nel tuo progetto Looker, anche il dialetto del database deve supportarle. La tabella seguente mostra quali dialetti supportano le PDT incrementali nell'ultima release di Looker:
Fai clic qui per visualizzare la tabella.
| Dialetto | Supportato? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Sì |
| Amazon Redshift 2.1+ | Sì |
| Amazon Redshift Serverless 2.1+ | Sì |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Sì |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Sì |
| Google Cloud PostgreSQL | Sì |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sì |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Sì |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Sì |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Sì |
| MySQL 8.0.12+ | Sì |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Sì |
| PostgreSQL pre-9.5 | Sì |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Sì |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Sì |
Creazione di PDT
Per trasformare una tabella derivata in una tabella derivata permanente (PDT), definisci una strategia di persistenza per la tabella. Per ottimizzare il rendimento, devi anche aggiungere una strategia di ottimizzazione.
Strategie di persistenza
La persistenza di una tabella derivata può essere gestita da Looker o, per i dialetti che supportano le viste materializzate, dal database utilizzando le viste materializzate.
Per rendere persistente una tabella derivata, aggiungi uno dei seguenti parametri alla definizione di derived_table:
- Parametri di persistenza gestiti da Looker:
- Parametri di persistenza gestiti dal database:
Con le strategie di persistenza basate su trigger (datagroup_trigger, sql_trigger_value e interval_trigger), Looker mantiene la PDT nel database finché non viene attivata per la ricreazione. Quando viene attivata, Looker ricrea la PDT per sostituire la versione precedente. Ciò significa che, con le PDT basate su trigger, gli utenti non dovranno attendere la creazione della PDT per ottenere risposte alle query di Esplora dalla PDT.
datagroup_trigger
I gruppi di dati sono il metodo più flessibile per creare la persistenza. Se hai definito un datagroup con sql_trigger o interval_trigger, puoi utilizzare il parametro datagroup_trigger per avviare la ricreazione delle tabelle derivate persistenti (PDT).
Looker mantiene la PDT nel database finché il relativo datagroup non viene attivato. Quando viene attivato il gruppo di dati, Looker ricostruisce la PDT per sostituire la versione precedente. Ciò significa che, nella maggior parte dei casi, gli utenti non dovranno attendere la creazione del PDT. Se un utente richiede dati dalla PDT durante la creazione e i risultati della query non sono nella cache, Looker restituirà i dati della PDT esistente finché non viene creata la nuova PDT. Per una panoramica dei gruppi di dati, consulta Memorizzazione nella cache delle query.
Per ulteriori informazioni su come il rigeneratore crea le PDT, consulta la sezione Il rigeneratore Looker.
sql_trigger_value
Il parametro sql_trigger_value attiva la rigenerazione di una tabella derivata permanente (PDT) basata su un'istruzione SQL che fornisci. Se il risultato dell'istruzione SQL è diverso dal valore precedente, la PDT viene rigenerata. In caso contrario, la PDT esistente viene mantenuta nel database. Ciò significa che, nella maggior parte dei casi, gli utenti non dovranno attendere la creazione del PDT. Se un utente richiede dati dalla PDT durante la creazione e i risultati della query non sono nella cache, Looker restituirà i dati della PDT esistente finché non viene creata la nuova PDT.
Per ulteriori informazioni su come il rigeneratore crea le PDT, consulta la sezione Il rigeneratore Looker.
interval_trigger
Il parametro interval_trigger attiva la rigenerazione di una tabella derivata permanente (PDT) in base a un intervallo di tempo che fornisci, ad esempio "24 hours" o "60 minutes". Analogamente al parametro sql_trigger, ciò significa che di solito il PDT viene precompilato quando gli utenti lo interrogano. Se un utente richiede dati dalla PDT durante la creazione e i risultati della query non sono nella cache, Looker restituirà i dati della PDT esistente finché non viene creata la nuova PDT.
persist_for
Un'altra opzione è utilizzare il parametro persist_for per impostare il periodo di tempo in cui la tabella derivata deve essere archiviata prima di essere contrassegnata come scaduta, in modo che non venga più utilizzata per le query e venga eliminata dal database.
Una persist_fortabella derivata persistente (PDT) viene creata quando un utente esegue per la prima volta una query. Looker mantiene quindi la PDT nel database per il periodo di tempo specificato nel parametro persist_for della PDT. Se un utente esegue una query sulla PDT entro il periodo di tempo persist_for, Looker utilizza i risultati memorizzati nella cache, se possibile, altrimenti esegue la query sulla PDT.
Dopo le ore persist_for, Looker cancella la PDT dal database e la ricostruisce la volta successiva che un utente esegue una query, il che significa che la query dovrà attendere la ricostruzione.
Le PDT che utilizzano persist_for non vengono ricostruite automaticamente dal rigeneratore di Looker, tranne nel caso di una cascata di PDT dipendenti. Quando una tabella persist_for fa parte di una cascata di dipendenze con PDT basate su trigger (PDT che utilizzano la strategia di persistenza datagroup_trigger, interval_trigger o sql_trigger_value), il rigeneratore monitora e ricostruisce la tabella persist_for per ricostruire altre tabelle nella cascata. Consulta la sezione Come Looker crea tabelle derivate a cascata in questa pagina.
materialized_view: yes
Le viste materializzate ti consentono di utilizzare la funzionalità del database per rendere persistenti le tabelle derivate nel progetto Looker. Se il dialetto del database supporta le viste materializzate e la tua connessione Looker è configurata con l'opzione Enable PDTs (Attiva PDT) attivata, puoi creare una vista materializzata specificando materialized_view: yes per una tabella derivata. Le viste materializzate sono supportate sia per le tabelle derivate native sia per le tabelle derivate basate su SQL.
Analogamente a una tabella derivata permanente (PDT), una vista materializzata è un risultato di query archiviato come tabella nello schema temporaneo del database. La differenza principale tra una PDT e una vista materializzata è il modo in cui vengono aggiornate le tabelle:
- Per le PDT, la strategia di persistenza è definita in Looker e la persistenza è gestita da Looker.
- Per le viste materializzate, il database è responsabile della manutenzione e dell'aggiornamento dei dati nella tabella.
Per questo motivo, la funzionalità di vista materializzata richiede una conoscenza avanzata del dialetto e delle sue funzionalità. Nella maggior parte dei casi, il database aggiorna la vista materializzata ogni volta che rileva nuovi dati nelle tabelle su cui viene eseguita una query dalla vista materializzata. Le viste materializzate sono ottimali per gli scenari che richiedono dati in tempo reale.
Consulta la pagina della documentazione relativa al parametro materialized_view per considerazioni importanti e informazioni sui requisiti e sul supporto del dialetto.
Strategie di ottimizzazione
Poiché le tabelle derivate permanenti (PDT) sono archiviate nel database, devi ottimizzarle utilizzando le seguenti strategie, in base al dialetto supportato:
Ad esempio, per aggiungere la persistenza all'esempio di tabella derivata, puoi impostarla in modo che venga ricreata quando vengono attivati i datagruppi orders_datagroup e aggiungere indici sia su customer_id sia su first_order, in questo modo:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Se non aggiungi un indice (o un equivalente per il tuo dialetto), Looker ti avviserà che devi farlo per migliorare le prestazioni delle query.
Casi d'uso dei PDT
Le tabelle derivate persistenti (PDT) sono utili perché possono migliorare le prestazioni di una query rendendo persistenti i risultati della query in una tabella.
Come best practice generale, gli sviluppatori devono provare a modellare i dati senza utilizzare PDT finché non è assolutamente necessario.
In alcuni casi, i dati possono essere ottimizzati in altri modi. Ad esempio, l'aggiunta di un indice o la modifica del tipo di dati di una colonna potrebbe risolvere un problema senza la necessità di creare una tabella PDT. Assicurati di analizzare i piani di esecuzione delle query lente utilizzando lo strumento Explain di SQL Runner.
Oltre a ridurre il tempo di esecuzione delle query e il carico del database per le query eseguite di frequente, esistono diversi altri casi d'uso per le PDT, tra cui:
Puoi anche utilizzare una PDT per definire una chiave primaria nei casi in cui non esiste un modo ragionevole per identificare una riga univoca in una tabella come chiave primaria.
Utilizzare i test PDT per testare le ottimizzazioni
Puoi utilizzare le PDT per testare diverse opzioni di indicizzazione, distribuzione e altre opzioni di ottimizzazione senza richiedere un grande supporto da parte degli sviluppatori DBA o ETL.
Considera un caso in cui hai una tabella, ma vuoi testare indici diversi. Il codice LookML iniziale per la vista potrebbe essere simile al seguente:
view: customer {
sql_table_name: warehouse.customer ;;
}
Per testare le strategie di ottimizzazione, puoi utilizzare il parametro indexes per aggiungere indici a LookML nel seguente modo:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Esegui una query sulla vista una volta per generare il PDT. Poi esegui le query di test e confronta i risultati. Se i risultati sono favorevoli, puoi chiedere al team DBA o ETL di aggiungere gli indici alla tabella originale.
Ricordati di modificare di nuovo il codice di visualizzazione per rimuovere l'ora legale.
Utilizzare le PDT per pre-unire o aggregare i dati
Può essere utile pre-unire o pre-aggregare i dati per modificare l'ottimizzazione delle query per volumi elevati o più tipi di dati.
Ad esempio, supponiamo che tu voglia creare una query per i clienti per coorte in base al momento in cui hanno effettuato il primo ordine. L'esecuzione ripetuta di questa query ogni volta che i dati sono necessari in tempo reale potrebbe essere costosa. Tuttavia, puoi calcolare la query una sola volta e riutilizzare i risultati con una tabella derivata permanente:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Tabelle derivate a cascata
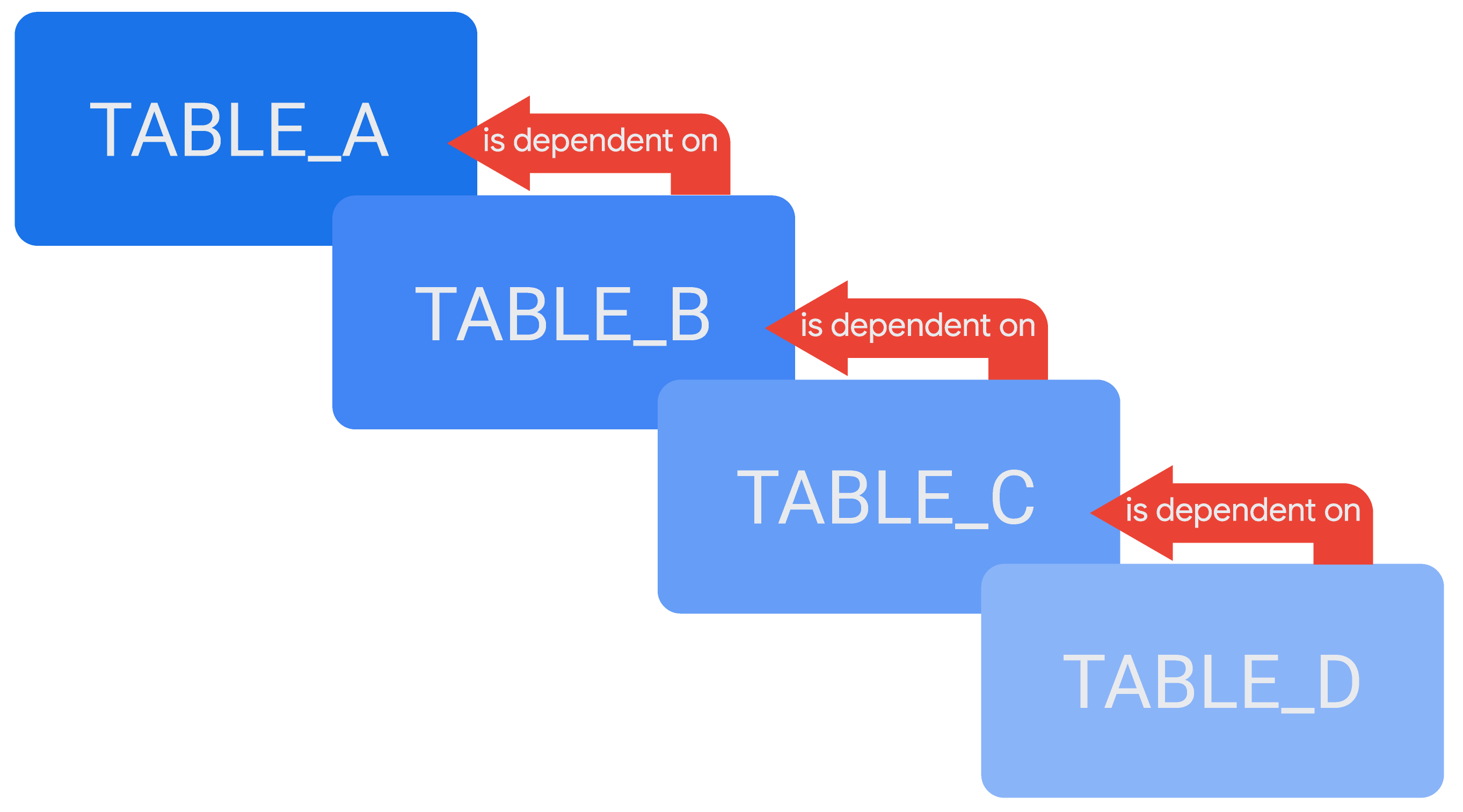
È possibile fare riferimento a una tabella derivata nella definizione di un'altra, creando una catena di tabelle derivate a cascata o tabelle derivate persistenti (PDT) a cascata, a seconda dei casi. Un esempio di tabelle derivate a cascata è una tabella, TABLE_D, che dipende da un'altra tabella, TABLE_C, mentre TABLE_C dipende da TABLE_B e TABLE_B dipende da TABLE_A.
Sintassi per fare riferimento a una tabella derivata
Per fare riferimento a una tabella derivata in un'altra tabella derivata, utilizza questa sintassi:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
In questo formato, SQL_TABLE_NAME è una stringa letterale. Ad esempio, puoi fare riferimento alla tabella derivata clean_events con questa sintassi:
`${clean_events.SQL_TABLE_NAME}`
Puoi utilizzare la stessa sintassi per fare riferimento a una vista LookML. Anche in questo caso, SQL_TABLE_NAME è una stringa letterale.
Nell'esempio successivo, il PDT clean_events viene creato dalla tabella events nel database. La tabella PDT clean_events esclude le righe indesiderate dalla tabella del database events. Viene quindi mostrata una seconda PDT: la PDT event_summary è un riepilogo della PDT clean_events. La tabella event_summary viene rigenerata ogni volta che vengono aggiunte nuove righe a clean_events.
La PDT event_summary e la PDT clean_events sono PDT a cascata, in cui event_summary dipende da clean_events (poiché event_summary è definita utilizzando la PDT clean_events). Questo esempio specifico potrebbe essere eseguito in modo più efficiente in una singola tabella derivata, ma è utile per dimostrare i riferimenti alle tabelle derivate.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Sebbene non sia sempre necessario, quando fai riferimento a una tabella derivata in questo modo, spesso è utile creare un alias per la tabella utilizzando questo formato:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
L'esempio precedente esegue le seguenti operazioni:
${clean_events.SQL_TABLE_NAME} AS clean_events
È utile utilizzare un alias perché, dietro le quinte, le PDT vengono denominate con codici lunghi nel database. In alcuni casi (soprattutto con le clausole ON) è possibile dimenticare che è necessario utilizzare la sintassi ${derived_table_or_view_name.SQL_TABLE_NAME} per recuperare questo nome lungo. Un alias può aiutarti a evitare questo tipo di errore.
Come Looker crea tabelle derivate a cascata
Nel caso di tabelle derivate temporanee a cascata, se i risultati della query di un utente non sono nella cache, Looker creerà tutte le tabelle derivate necessarie per la query. Se hai un TABLE_D la cui definizione contiene un riferimento a TABLE_C, allora TABLE_D è dipendente da TABLE_C. Ciò significa che se esegui una query su TABLE_D e la query non è nella cache di Looker, Looker ricompilerà TABLE_D. Ma prima deve ricostruire TABLE_C.
Considera uno scenario con tabelle derivate temporanee a cascata, in cui TABLE_D dipende da TABLE_C, che dipende da TABLE_B, che dipende da TABLE_A. Se Looker non dispone di risultati validi per una query su TABLE_C nella cache, creerà tutte le tabelle necessarie per la query. Quindi Looker creerà TABLE_A, poi TABLE_B e infine TABLE_C:
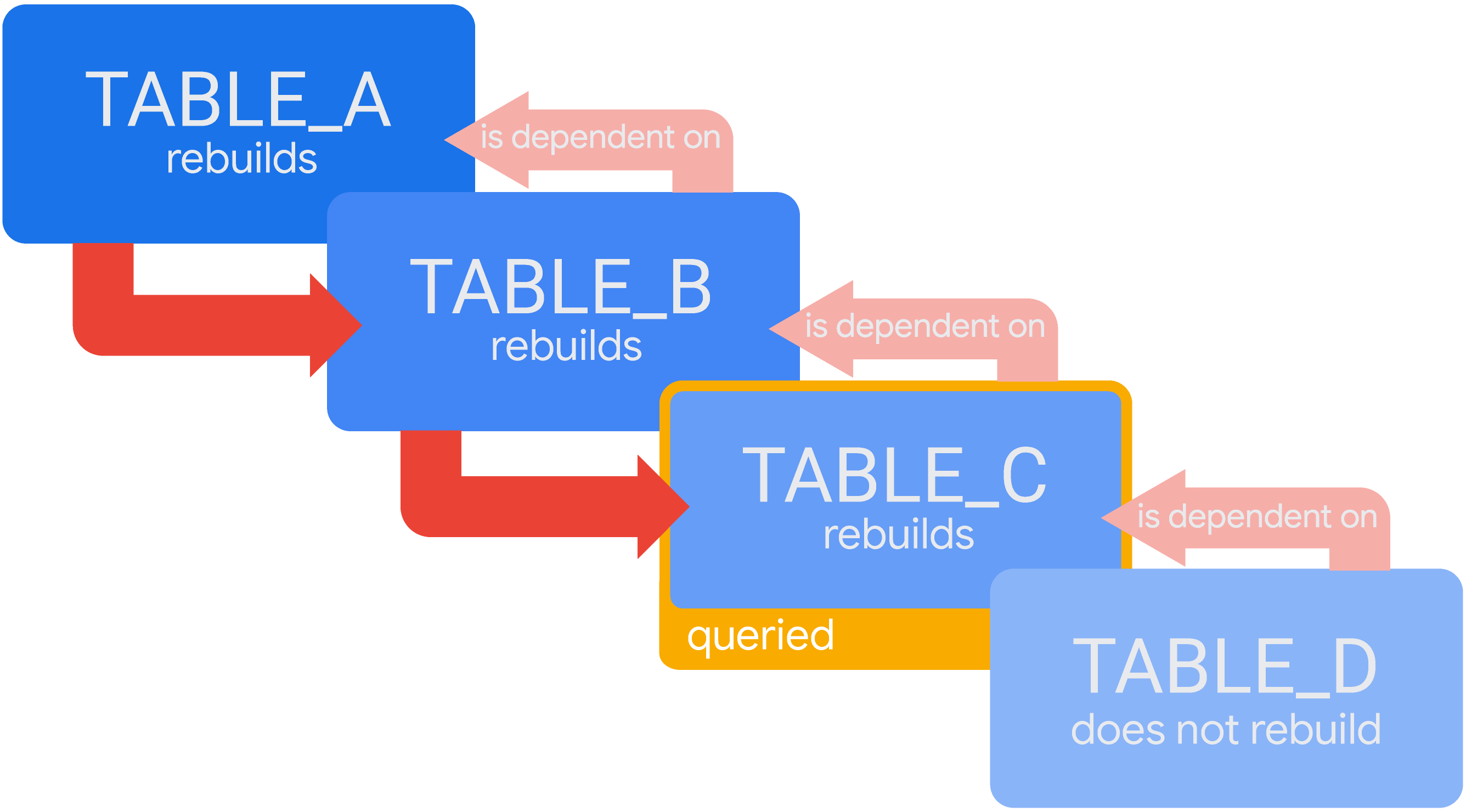
In questo scenario, TABLE_A deve terminare la generazione prima che Looker possa iniziare a generare TABLE_B e TABLE_B deve terminare la generazione prima che Looker possa iniziare a generare TABLE_C. Al termine di TABLE_C, Looker fornirà i risultati della query. Poiché TABLE_D non è necessario per rispondere a questa query, Looker non lo ricompilerà in questo momento.TABLE_D
Per un esempio di scenario di PDT a cascata che utilizzano lo stesso datagroup, consulta la pagina della documentazione relativa al parametro datagroup.
Per le PDT si applica la stessa logica di base: Looker creerà qualsiasi tabella necessaria per rispondere a una query, fino in fondo alla catena di dipendenze. Tuttavia, con le PDT, spesso le tabelle esistono già e non devono essere ricreate. Con le query utente standard sulle PDT a cascata, Looker ricrea le PDT nella cascata solo se non esiste una versione valida delle PDT nel database. Se vuoi forzare la ricreazione di tutte le PDT in una cascata, puoi ricreare manualmente le tabelle per una query tramite un'esplorazione.
Un punto logico importante da comprendere è che, nel caso di una cascata di PDT, una PDT dipendente interroga essenzialmente la PDT da cui dipende. Ciò è significativo soprattutto per i PDT che utilizzano la strategia persist_for. In genere, le persist_for PDT vengono create quando un utente le esegue, rimangono nel database fino al termine dell'intervallo persist_for e non vengono ricreate finché non vengono eseguite di nuovo da un utente. Tuttavia, se una PDT persist_for fa parte di una cascata con PDT basate su trigger (PDT che utilizzano la strategia di persistenza datagroup_trigger, interval_trigger o sql_trigger_value), la PDT persist_for viene interrogata ogni volta che le PDT dipendenti vengono ricreate. Pertanto, in questo caso, la PDT persist_for verrà ricostruita in base alla pianificazione delle PDT da cui dipende. Ciò significa che le PDT persist_for possono essere influenzate dalla strategia di persistenza delle relative dipendenze.
Ricreare manualmente le tabelle permanenti per una query
Gli utenti possono selezionare l'opzione Ricostruisci tabelle derivate ed esegui dal menu di un'esplorazione per ignorare le impostazioni di persistenza e ricostruire tutte le tabelle derivate permanenti (PDT) e le tabelle aggregate richieste per la query corrente nell'esplorazione:
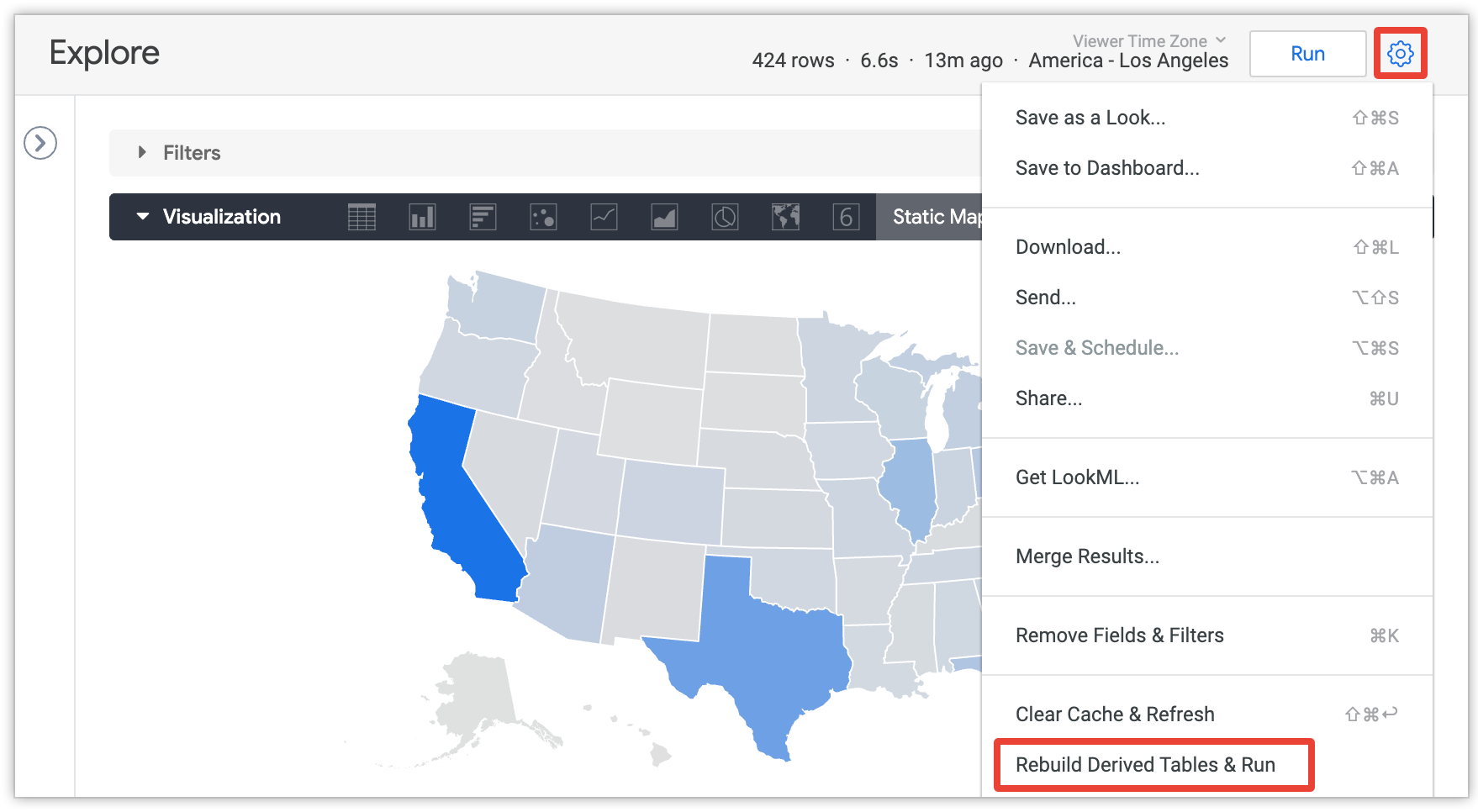
Questa opzione è visibile solo agli utenti con l'autorizzazione develop e solo dopo il caricamento della query Esplora.
L'opzione Ricostruisci tabelle derivate ed esegui ricostruisce tutte le tabelle persistenti (tutte le PDT e le tabelle aggregate) necessarie per rispondere alla query, indipendentemente dalla strategia di persistenza. Sono incluse tutte le tabelle aggregate e le PDT nella query corrente, nonché tutte le tabelle aggregate e le PDT a cui viene fatto riferimento dalle tabelle aggregate e dalle PDT nella query corrente.
Nel caso delle PDT incrementali, l'opzione Ricostruisci tabelle derivate ed esegui attiva la creazione di un nuovo incremento. Con i periodi di tempo incrementali, un incremento include il periodo di tempo specificato nel parametro increment_key, nonché il numero di periodi di tempo precedenti specificati nel parametro increment_offset, se presenti. Consulta la pagina di documentazione PDT incrementali per alcuni scenari di esempio che mostrano come vengono create le PDT incrementali, a seconda della loro configurazione.
Nel caso di PDT a cascata, ciò significa ricostruire tutte le tabelle derivate nella cascata, a partire dalla prima. Questo è lo stesso comportamento che si verifica quando esegui una query su una tabella in una cascata di tabelle derivate temporanee:
Tieni presente quanto segue in merito alla ricreazione manuale delle tabelle derivate:
- Per l'utente che avvia l'operazione Ricostruisci tabelle derivate ed esegui, la query attenderà la ricostruzione delle tabelle prima di caricare i risultati. Le query degli altri utenti continueranno a utilizzare le tabelle esistenti. Una volta ricreate le tabelle permanenti, tutti gli utenti le utilizzeranno. Sebbene questo processo sia progettato per evitare di interrompere le query di altri utenti durante la ricostruzione delle tabelle, questi utenti potrebbero comunque essere interessati dal carico aggiuntivo sul tuo database. Se ti trovi in una situazione in cui l'attivazione di una rigenerazione durante l'orario di lavoro potrebbe mettere a dura prova il tuo database, potresti dover comunicare ai tuoi utenti che non devono mai rigenerare determinate tabelle PDT o aggregate durante queste ore.
Se un utente si trova in modalità di sviluppo e l'esplorazione si basa su una tabella di sviluppo, l'operazione Ricostruisci tabelle derivate ed esegui ricostruirà la tabella di sviluppo, non la tabella di produzione, per l'esplorazione. Tuttavia, se l'esplorazione in modalità di sviluppo utilizza la versione di produzione di una tabella derivata, la tabella di produzione verrà ricreata. Per informazioni sulle tabelle di sviluppo e di produzione, consulta Tabelle persistenti in modalità di sviluppo.
Per le istanze ospitate da Looker, se la tabella derivata impiega più di un'ora per essere ricreata, la ricreazione non andrà a buon fine e la sessione del browser scadrà. Per ulteriori informazioni sui timeout che potrebbero influire sui processi di Looker, consulta la sezione Timeout e accodamento delle query nella pagina della documentazione Impostazioni di amministrazione - Query.
Tabelle persistenti in modalità di sviluppo
Looker ha alcuni comportamenti speciali per la gestione delle tabelle persistenti in modalità di sviluppo.
Se esegui una query su una tabella persistente in modalità di sviluppo senza apportare modifiche alla relativa definizione, Looker esegue una query sulla versione di produzione della tabella. Se apporti una modifica alla definizione della tabella che influisce sui dati della tabella o sul modo in cui viene eseguita la query sulla tabella, verrà creata una nuova versione di sviluppo della tabella la volta successiva che esegui una query sulla tabella in modalità Development (Sviluppo). Disporre di una tabella di sviluppo di questo tipo ti consente di testare le modifiche senza disturbare gli utenti.
Cosa spinge Looker a creare una tabella di sviluppo
Quando possibile, Looker utilizza la tabella di produzione esistente per rispondere alle query, indipendentemente dal fatto che tu sia in modalità di sviluppo. Tuttavia, in alcuni casi Looker non può utilizzare la tabella di produzione per le query in modalità di sviluppo:
- Se la tabella persistente ha un parametro che restringe il set di dati per funzionare più velocemente in modalità Development (Sviluppo)
- Se hai apportato modifiche alla definizione della tabella persistente che influiscono sui dati della tabella
Looker creerà una tabella di sviluppo se ti trovi in modalità di sviluppo ed esegui una query su una tabella derivata basata su SQL definita utilizzando una clausola condizionale WHERE con istruzioni if prod e if dev.
Per le tabelle persistenti che non hanno un parametro per restringere il set di dati in modalità di sviluppo, Looker utilizza la versione di produzione della tabella per rispondere alle query in modalità di sviluppo, a meno che tu non modifichi la definizione della tabella e poi esegui una query sulla tabella in modalità di sviluppo. Ciò vale per qualsiasi modifica alla tabella che influisce sui dati della tabella o sul modo in cui viene eseguita la query sulla tabella.
Di seguito sono riportati alcuni esempi dei tipi di modifiche che inducono Looker a creare una versione di sviluppo di una tabella persistente (Looker crea la tabella solo se in seguito esegui una query sulla tabella dopo aver apportato queste modifiche):
- Modificare la query su cui si basa la tabella permanente, ad esempio modificando il parametro
explore_source,sql,query,sql_createocreate_processnella tabella permanente stessa o in qualsiasi tabella richiesta (nel caso di tabelle derivate a cascata) - Modificare la strategia di persistenza della tabella, ad esempio modificando il parametro
datagroup_trigger,sql_trigger_value,interval_triggeropersist_fordella tabella - Modifica del nome di
viewdi una tabella derivata - Modifica di
increment_keyoincrement_offsetdi una PDT incrementale - Modifica del
connectionutilizzato dal modello associato
Per le modifiche che non modificano i dati della tabella o non influiscono sul modo in cui Looker esegue query sulla tabella, Looker non crea una tabella di sviluppo. Il parametro publish_as_db_view è un buon esempio: in modalità di sviluppo, se modifichi solo l'impostazione publish_as_db_view per una tabella derivata, Looker non deve ricompilare la tabella derivata, quindi non creerà una tabella di sviluppo.
Per quanto tempo Looker mantiene le tabelle di sviluppo
Indipendentemente dalla strategia di persistenza effettiva della tabella, Looker considera le tabelle persistenti di sviluppo come se avessero una strategia di persistenza di persist_for: "24 hours". Looker esegue questa operazione per garantire che le tabelle di sviluppo non vengano mantenute per più di un giorno, poiché uno sviluppatore Looker potrebbe eseguire query su molte iterazioni di una tabella durante lo sviluppo e ogni volta che viene creata una nuova tabella di sviluppo. Per evitare che le tabelle di sviluppo ingombrino il database, Looker applica la strategia persist_for: "24 hours" per assicurarsi che le tabelle vengano pulite frequentemente dal database.
In caso contrario, Looker crea tabelle derivate permanenti (PDT) e tabelle aggregate in modalità di sviluppo nello stesso modo in cui crea tabelle permanenti in modalità di produzione.
Se una tabella di sviluppo viene mantenuta nel database quando implementi le modifiche a una PDT o a una tabella aggregata, Looker può spesso utilizzare la tabella di sviluppo come tabella di produzione, in modo che gli utenti non debbano attendere la creazione della tabella quando la interrogano.
Tieni presente che, quando implementi le modifiche, potrebbe essere necessario ricostruire la tabella per poterla interrogare in produzione, a seconda della situazione:
- Se sono trascorse più di 24 ore da quando hai eseguito una query sulla tabella in modalità di sviluppo, la versione di sviluppo della tabella viene contrassegnata come scaduta e non verrà utilizzata per le query. Puoi verificare la presenza di PDT non create utilizzando l'IDE di Looker o la scheda Sviluppo della pagina Tabelle derivate persistenti. Se hai PDT non create, puoi eseguire query su di esse in modalità di sviluppo subito prima di apportare le modifiche, in modo che la tabella di sviluppo sia disponibile per l'utilizzo in produzione.
- Se una tabella persistente ha il parametro
dev_filters(per le tabelle derivate native) o la clausolaWHEREcondizionale che utilizza le istruzioniif prodeif dev(per le tabelle derivate basate su SQL), la tabella di sviluppo non può essere utilizzata come versione di produzione, poiché la versione di sviluppo ha un set di dati abbreviato. In questo caso, dopo aver terminato lo sviluppo della tabella e prima di eseguire il deployment delle modifiche, puoi impostare come commento il parametrodev_filterso la clausola condizionaleWHEREe poi eseguire una query sulla tabella in modalità di sviluppo. Looker creerà quindi una versione completa della tabella che potrà essere utilizzata per la produzione quando esegui il deployment delle modifiche.
In caso contrario, se implementi le modifiche quando non è presente una tabella di sviluppo valida che possa essere utilizzata come tabella di produzione, Looker ricompilerà la tabella la volta successiva che viene interrogata in modalità Produzione (per le tabelle permanenti che utilizzano la strategia persist_for) o la volta successiva che viene eseguito il rigeneratore (per le tabelle permanenti che utilizzano datagroup_trigger, interval_trigger o sql_trigger_value).
Controllo delle PDT non create in modalità di sviluppo
Se una tabella di sviluppo viene mantenuta nel database quando implementi le modifiche a una tabella derivata persistente (PDT) o a una tabella aggregata, Looker può spesso utilizzare la tabella di sviluppo come tabella di produzione in modo che gli utenti non debbano attendere la creazione della tabella quando la interrogano. Per ulteriori dettagli, consulta le sezioni Per quanto tempo Looker mantiene le tabelle di sviluppo e Cosa spinge Looker a creare una tabella di sviluppo in questa pagina.
Pertanto, è ottimale che tutte le PDT vengano create quando esegui il deployment nella produzione, in modo che le tabelle possano essere utilizzate immediatamente come versioni di produzione.
Puoi controllare il tuo progetto per individuare le PDT non create nel riquadro Stato del progetto. Fai clic sull'icona Stato del progetto nell'IDE di Looker per aprire il riquadro Stato del progetto. Quindi, fai clic sul pulsante Convalida stato PDT.

Se sono presenti PDT non create, il riquadro Stato del progetto le elencherà:
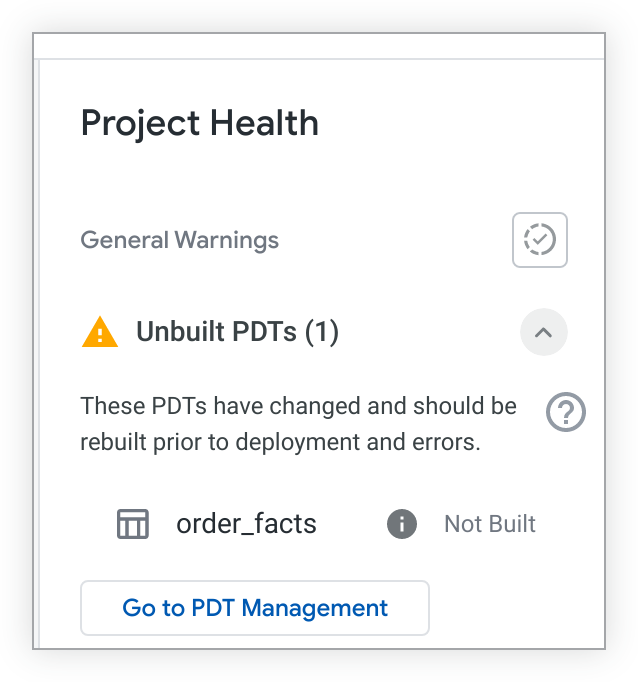
Se disponi dell'autorizzazione see_pdts, puoi fare clic sul pulsante Vai alla gestione delle PDT. Looker aprirà la scheda Sviluppo della pagina Tabelle derivate persistenti e filtrerà i risultati in base al tuo progetto LookML specifico. Da qui puoi vedere quali PDT di sviluppo sono stati creati e quali no, nonché accedere ad altre informazioni per la risoluzione dei problemi. Per ulteriori informazioni, consulta la pagina della documentazione Impostazioni di amministrazione - Tabelle derivate persistenti.
Una volta identificata una PDT non creata nel progetto, puoi crearne una versione di sviluppo aprendo un'esplorazione che esegue query sulla tabella, quindi utilizzando l'opzione Ricostruisci tabelle derivate ed esegui dal menu Esplora. Consulta la sezione Ricreare manualmente le tabelle permanenti per una query in questa pagina.
Condivisione e pulizia delle tabelle
All'interno di una determinata istanza di Looker, Looker condividerà le tabelle persistenti tra gli utenti se le tabelle hanno la stessa definizione e la stessa impostazione del metodo di persistenza. Inoltre, se la definizione di una tabella non esiste più, Looker la contrassegna come scaduta.
Questo approccio offre diversi vantaggi:
- Se non hai apportato modifiche a una tabella in modalità di sviluppo, le query utilizzeranno le tabelle di produzione esistenti. Questo è il caso a meno che la tabella non sia una tabella derivata basata su SQL definita utilizzando una clausola condizionale
WHEREcon istruzioniif prodeif dev. Se la tabella è definita con una clausolaWHEREcondizionale, Looker creerà una tabella di sviluppo se esegui una query sulla tabella in modalità di sviluppo. Per le tabelle derivate native con il parametrodev_filters, Looker ha la logica per utilizzare la tabella di produzione per rispondere alle query in modalità di sviluppo, a meno che tu non modifichi la definizione della tabella e poi esegui una query sulla tabella in modalità di sviluppo. - Se due sviluppatori apportano la stessa modifica a una tabella in modalità Development (Sviluppo), condivideranno la stessa tabella di sviluppo.
- Una volta trasferite le modifiche dalla modalità di sviluppo alla modalità di produzione, la vecchia definizione di produzione non esiste più, quindi la vecchia tabella di produzione viene contrassegnata come scaduta e verrà eliminata.
- Se decidi di eliminare le modifiche alla modalità di sviluppo, la definizione della tabella non esiste più, quindi le tabelle di sviluppo non necessarie vengono contrassegnate come scadute e verranno eliminate.
Lavorare più velocemente in modalità di sviluppo
In alcune situazioni, la tabella derivata persistente (PDT) che stai creando richiede molto tempo per essere generata, il che può richiedere molto tempo se stai testando molte modifiche in modalità di sviluppo. In questi casi, puoi chiedere a Looker di creare versioni più piccole di una tabella derivata quando ti trovi in modalità Development (Sviluppo).
Per le tabelle derivate native, puoi utilizzare il parametro secondario dev_filters di explore_source per specificare i filtri che vengono applicati solo alle versioni di sviluppo della tabella derivata:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Questo esempio include un parametro dev_filters che filtra i dati in base agli ultimi 90 giorni e un parametro filters che filtra i dati in base agli ultimi due anni e all'aeroporto di Yucca Valley.
Il parametro dev_filters agisce in combinazione con il parametro filters in modo che tutti i filtri vengano applicati alla versione di sviluppo della tabella. Se sia dev_filters che filters specificano filtri per la stessa colonna, dev_filters ha la precedenza per la versione di sviluppo della tabella. In questo esempio, la versione di sviluppo della tabella filtra i dati degli ultimi 90 giorni per l'aeroporto di Yucca Valley.
Per le tabelle derivate basate su SQL, Looker supporta una clausola WHERE condizionale con diverse opzioni per le versioni di produzione (if prod) e di sviluppo (if dev) della tabella:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
In questo esempio, la query includerà tutti i dati dal 2000 in poi in modalità Production (Produzione), ma solo i dati dal 2020 in poi in modalità Development (Sviluppo). L'utilizzo strategico di questa funzionalità per limitare il set di risultati e aumentare la velocità delle query può semplificare notevolmente la convalida delle modifiche alla modalità di sviluppo.
Come Looker crea le PDT
Dopo che una tabella derivata persistente (PDT) è stata definita e viene eseguita per la prima volta o attivata dal rigeneratore per la ricostruzione in base alla sua strategia di persistenza, Looker esegue i seguenti passaggi:
- Utilizza l'SQL della tabella derivata per creare un'istruzione CREATE TABLE AS SELECT (o CTAS) ed eseguirla. Ad esempio, per ricreare una PDT denominata
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Emettere le istruzioni per creare gli indici durante la creazione della tabella
- Rinomina la tabella da LC$.. ("Looker Create") a LR$.. ("Looker Read") per indicare che la tabella è pronta per l'uso
- Elimina le versioni precedenti della tabella che non devono più essere utilizzate
Ci sono alcune implicazioni importanti:
- L'SQL che forma la tabella derivata deve essere valido all'interno di un'istruzione CTAS.
- Gli alias delle colonne nel set di risultati dell'istruzione SELECT devono essere nomi di colonne validi.
- I nomi utilizzati per specificare la distribuzione, le chiavi di ordinamento e gli indici devono essere i nomi delle colonne elencati nella definizione SQL della tabella derivata, non i nomi dei campi definiti in LookML.
Il rigeneratore di Looker
Il rigeneratore Looker controlla lo stato e avvia le ricostruzioni per le tabelle persistenti attivate. Una tabella resa permanente da trigger è una tabella derivata permanente (PDT) o una tabella aggregata che utilizza un trigger come strategia di permanenza:
- Per le tabelle che utilizzano
sql_trigger_value, il trigger è una query specificata nel parametrosql_trigger_valuedella tabella. Il rigeneratore Looker attiva una ricostruzione della tabella quando il risultato dell'ultimo controllo della query del trigger è diverso dal risultato del controllo precedente della query del trigger. Ad esempio, se la tabella derivata viene mantenuta con la query SQLSELECT CURDATE(), il rigeneratore di Looker ricostruirà la tabella la volta successiva che controllerà il trigger dopo la modifica della data. - Per le tabelle che utilizzano
interval_trigger, l'attivatore è una durata specificata nel parametrointerval_triggerdella tabella. Il rigeneratore Looker attiva la ricostruzione della tabella quando è trascorso il tempo specificato. - Per le tabelle che utilizzano
datagroup_trigger, il trigger può essere una query specificata nel parametrosql_triggerdel datagroup associato oppure una durata specificata nel parametrointerval_triggerdel datagroup.
Il rigeneratore Looker avvia anche le ricostruzioni per le tabelle rese permanenti che utilizzano il parametro persist_for, ma solo quando la tabella persist_for è una cascata di dipendenze di una tabella resa permanente da trigger. In questo caso, il rigeneratore Looker avvierà le ricostruzioni per una tabella persist_for, poiché è necessaria per la ricostruzione delle altre tabelle nella cascata. In caso contrario, il rigeneratore non monitora le tabelle persistenti che utilizzano la strategia persist_for.
Il ciclo del rigeneratore Looker inizia a intervalli regolari configurati dall'amministratore di Looker nell'impostazione Pianificazione manutenzione della connessione al database (l'intervallo predefinito è di cinque minuti). Tuttavia, il rigeneratore Looker non avvia un nuovo ciclo finché non ha completato tutti i controlli e le ricostruzioni delle PDT dell'ultimo ciclo. Ciò significa che, se hai build PDT di lunga durata, il ciclo del rigeneratore Looker potrebbe non essere eseguito con la frequenza definita nell'impostazione Pianificazione della manutenzione. Altri fattori possono influire sul tempo necessario per ricompilare le tabelle, come descritto nella sezione Considerazioni importanti per l'implementazione delle tabelle persistenti di questa pagina.
Nei casi in cui una PDT non viene creata, il rigeneratore potrebbe tentare di ricostruire la tabella nel ciclo successivo del rigeneratore:
- Se l'impostazione Retry Failed PDT Builds (Ritenta le ricostruzioni PDT non riuscite) è abilitata nella connessione al database, il rigeneratore Looker tenta di ricostruire la tabella durante il ciclo successivo del rigeneratore, anche se la condizione trigger della tabella non è soddisfatta.
- Se l'impostazione Retry Failed PDT Builds (Ritenta le ricostruzioni PDT non riuscite) è disabilitata, il rigeneratore Looker non tenterà di ricostruire la tabella finché la condizione trigger della PDT non sarà soddisfatta.
Se un utente richiede dati dalla tabella persistente durante la creazione e i risultati della query non sono nella cache, Looker verifica se la tabella esistente è ancora valida. La tabella precedente potrebbe non essere valida se non è compatibile con la nuova versione, il che può accadere se la nuova tabella ha una definizione diversa, utilizza una connessione al database diversa o è stata creata con una versione diversa di Looker. Se la tabella esistente è ancora valida, Looker restituirà i dati della tabella esistente finché non viene creata la nuova tabella. Altrimenti, se la tabella esistente non è valida, Looker fornirà i risultati della query una volta ricostruita la nuova tabella.
Considerazioni importanti per l'implementazione di tabelle persistenti
Considerando l'utilità delle tabelle persistenti (PDT e tabelle aggregate), è possibile accumularne molte nell'istanza di Looker. È possibile creare uno scenario in cui il rigeneratore Looker deve creare molte tabelle contemporaneamente. Soprattutto con le tabelle a cascata o quelle a esecuzione prolungata, puoi creare uno scenario in cui le tabelle subiscono un lungo ritardo prima di essere ricostruite o in cui gli utenti riscontrano un ritardo nella ricezione dei risultati delle query da una tabella mentre il database è impegnato a generarla.
Il rigeneratore Looker controlla i trigger PDT per verificare se deve ricostruire le tabelle rese permanenti da trigger. Il ciclo del rigeneratore è impostato a un intervallo regolare configurato dall'amministratore di Looker nell'impostazione Pianificazione manutenzione della connessione al database (l'intervallo predefinito è di cinque minuti).
Diversi fattori possono influire sul tempo necessario per ricreare le tabelle:
- L'amministratore di Looker potrebbe aver modificato l'intervallo dei controlli del trigger del rigeneratore utilizzando l'impostazione Pianificazione della manutenzione nella connessione al database.
- Il rigeneratore Looker non avvia un nuovo ciclo finché non ha completato tutti i controlli e le ricostruzioni delle PDT dell'ultimo ciclo. Pertanto, se hai build PDT di lunga durata, il ciclo del rigeneratore Looker potrebbe non essere frequente come l'impostazione Pianificazione della manutenzione.
- Per impostazione predefinita, il rigeneratore può avviare la ricostruzione di una PDT o di una tabella aggregata alla volta su una connessione. Un amministratore di Looker può modificare il numero consentito di ricostruzioni simultanee del rigeneratore utilizzando il campo Numero massimo di connessioni del builder di PDT nelle impostazioni di una connessione.
- Tutte le PDT e le tabelle aggregate attivate dallo stesso
datagroupverranno ricostruite durante lo stesso processo di rigenerazione. Può trattarsi di un carico pesante se hai molte tabelle che utilizzano il datagruppo, direttamente o a causa di dipendenze a cascata.
Oltre alle considerazioni precedenti, ci sono anche alcune situazioni in cui è consigliabile evitare di aggiungere la persistenza a una tabella derivata:
- Quando le tabelle derivate verranno estese: ogni estensione di una PDT creerà una nuova copia della tabella nel database.
- Quando le tabelle derivate utilizzano filtri basati su modelli o parametri Liquid: la persistenza non è supportata per le tabelle derivate che utilizzano filtri basati su modelli o parametri Liquid.
- Quando le tabelle derivate native vengono create da esplorazioni che utilizzano attributi utente con
access_filterso consql_always_where, nel database vengono create copie della tabella per ogni valore possibile dell'attributo utente specificato. - Quando i dati sottostanti cambiano di frequente e il dialetto del database non supporta le PDT incrementali.
- Quando il costo e il tempo necessari per creare PDT sono troppo elevati.
A seconda del numero e della complessità delle tabelle persistenti nella connessione Looker, la coda potrebbe contenere molte tabelle persistenti che devono essere controllate e ricreate a ogni ciclo, pertanto è importante tenere a mente questi fattori quando implementi tabelle derivate nell'istanza Looker.
Gestione delle PDT su larga scala utilizzando l'API
Il monitoraggio e la gestione delle tabelle derivate persistenti (PDT) che vengono aggiornate in base a pianificazioni diverse diventano sempre più complessi man mano che crei più PDT nella tua istanza. Valuta la possibilità di utilizzare l'integrazione di Apache Airflow di Looker per gestire le pianificazioni delle PDT insieme agli altri processi ETL ed ELT.
Monitoraggio e risoluzione dei problemi relativi ai PDT
Se utilizzi tabelle derivate permanenti (PDT), in particolare PDT in cascata, è utile visualizzare lo stato delle PDT. Puoi utilizzare la pagina di amministrazione Tabelle derivate permanenti di Looker per visualizzare lo stato delle PDT. Per informazioni, consulta la pagina della documentazione Impostazioni di amministrazione - Tabelle derivate persistenti.
Quando tenti di risolvere i problemi relativi alle PDT:
- Presta particolare attenzione alla distinzione tra tabelle di sviluppo e tabelle di produzione quando esamini il log eventi PDT.
- Verifica che l'impostazione Database temporaneo nella connessione Looker corrisponda allo schema o al database temporaneo effettivo. Se l'impostazione Database temporaneo nella connessione non corrisponde allo schema temporaneo del database, aggiorna l'impostazione Database temporaneo in modo che Looker possa archiviare le tabelle derivate permanenti nel database.
- Determina se ci sono problemi con tutte le PDT o solo con una. Se si verifica un problema con uno, è probabile che sia causato da un errore LookML o SQL.
- Determina se i problemi relativi al PDT corrispondono agli orari in cui è pianificata la rigenerazione.
- Assicurati che tutte le query
sql_trigger_valuevengano valutate correttamente e che restituiscano una sola riga e colonna. Per le PDT basate su SQL, puoi farlo eseguendole in SQL Runner. L'applicazione di unLIMITprotegge dalle query incontrollate. Per ulteriori informazioni sull'utilizzo di SQL Runner per il debug delle tabelle derivate, consulta il post della Community Utilizzo di SQL Runner per testare le tabelle derivate . - Per le PDT basate su SQL, utilizza SQL Runner per verificare che l'SQL della PDT venga eseguito senza errori. Assicurati di applicare un
LIMITin SQL Runner per mantenere tempi di query ragionevoli. - Per le tabelle derivate basate su SQL, evita di utilizzare le espressioni di tabella comuni (CTE). L'utilizzo di CTE con DT crea istruzioni
WITHnidificate che possono causare l'errore delle PDT senza preavviso. Utilizza invece l'SQL per la tua CTE per creare una DT secondaria e fai riferimento a questa DT dalla prima DT utilizzando la sintassi${derived_table_or_view_name.SQL_TABLE_NAME}. - Verifica che tutte le tabelle da cui dipende la PDT problematica, siano esse tabelle normali o PDT, esistano e possano essere interrogate.
- Assicurati che le tabelle da cui dipende il PDT problematico non abbiano blocchi condivisi o esclusivi. Affinché Looker possa creare correttamente una tabella derivata permanente, deve acquisire un blocco esclusivo sulla tabella da aggiornare. Questa operazione è in conflitto con altri blocchi condivisi o esclusivi presenti nella tabella. Looker non potrà aggiornare la PDT finché non saranno stati rimossi tutti gli altri blocchi. Lo stesso vale per tutti i blocchi esclusivi sulla tabella da cui Looker sta creando una PDT: se è presente un blocco esclusivo su una tabella, Looker non potrà acquisire un blocco condiviso per eseguire query finché il blocco esclusivo non viene rimosso.
- Utilizza il pulsante Mostra processi in SQL Runner. Se è attivo un numero elevato di processi, i tempi di esecuzione delle query potrebbero rallentare.
- Monitora i commenti nella query. Consulta la sezione Commenti sulle query per le PDT in questa pagina.
Commenti alle query per le PDT
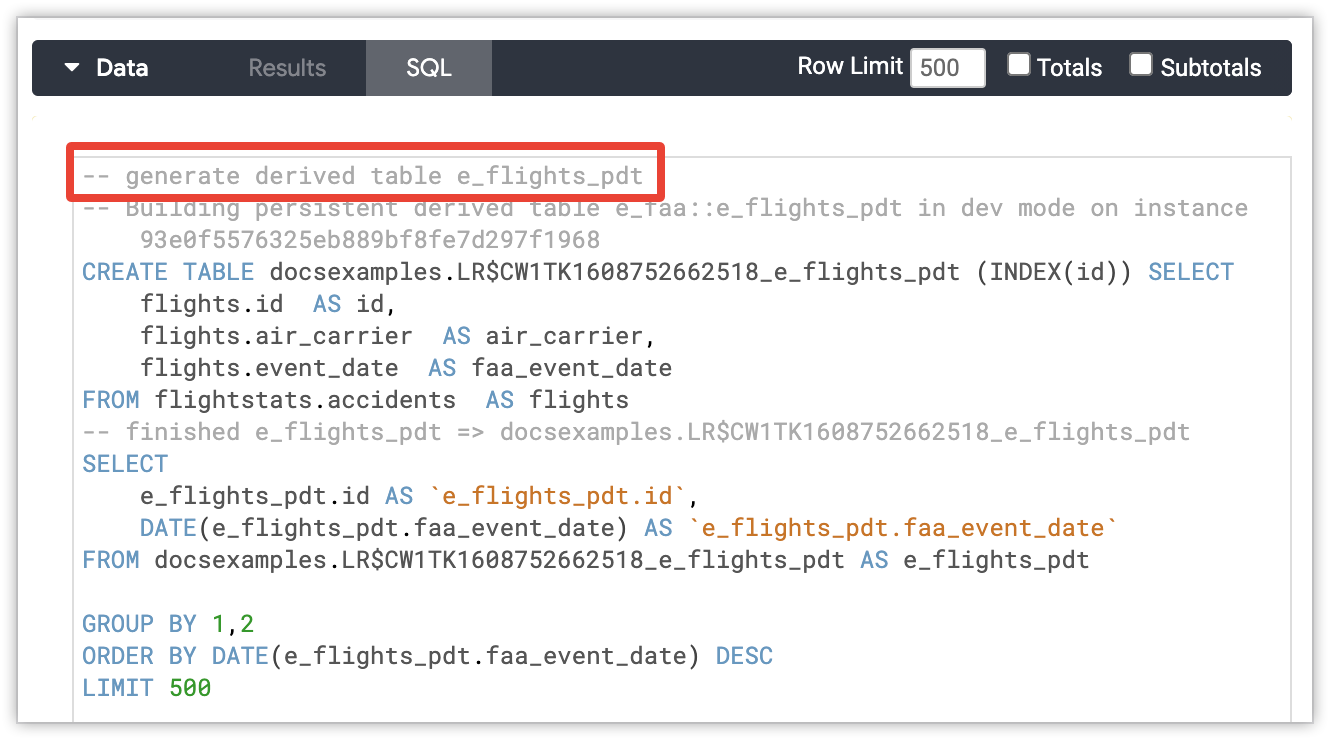
Gli amministratori di database possono distinguere le query normali da quelle che generano tabelle derivate persistenti (PDT). Looker aggiunge commenti all'istruzione CREATE TABLE ... AS SELECT ... che include il modello LookML e la vista del PDT, oltre a un identificatore univoco (slug) per l'istanza di Looker. Se il PDT viene generato per conto di un utente in modalità di sviluppo, i commenti indicheranno l'ID utente. I commenti sulla generazione di PDT seguono questo pattern:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
Il commento sulla generazione di PDT viene visualizzato nella scheda SQL di un'esplorazione se Looker ha dovuto generare una PDT per la query dell'esplorazione. Il commento verrà visualizzato nella parte superiore dell'istruzione SQL.
Infine, il commento sulla generazione di PDT viene visualizzato nel campo Messaggio della scheda Informazioni del popup Dettagli query per ogni query nella pagina di amministrazione Query.
Ricostruzione delle PDT dopo un errore
Quando una tabella derivata permanente (PDT) ha un errore, ecco cosa succede quando viene eseguita una query sulla PDT:
- Looker utilizzerà i risultati nella cache se la stessa query è stata eseguita in precedenza. Per una spiegazione del funzionamento, consulta la pagina di documentazione Memorizzazione nella cache delle query.
- Se i risultati non sono nella cache, Looker li estrae dalla PDT nel database, se esiste una versione valida della PDT.
- Se nel database non è presente una PDT valida, Looker tenta di ricostruirla.
- Se la PDT non può essere ricostruita, Looker restituirà un errore per una query. Il rigeneratore Looker tenterà di ricostruire la PDT la volta successiva che viene eseguita una query sulla PDT o la volta successiva che la strategia di persistenza della PDT attiva una ricostruzione.
Con le PDT a cascata, si applica la stessa logica, tranne che con le PDT a cascata:
- Se la creazione di una tabella non va a buon fine, non è possibile creare le PDT nella catena di dipendenze.
- Una PDT dipendente esegue essenzialmente una query sulla PDT da cui dipende, quindi la strategia di permanenza di una tabella può attivare le ricostruzioni delle PDT che si trovano più in alto nella catena.
Riprendendo l'esempio precedente delle tabelle a cascata, in cui TABLE_D dipende da TABLE_C, che dipende da TABLE_B, che dipende da TABLE_A:
Se TABLE_B ha un errore, per TABLE_B si applica tutto il comportamento standard (non a cascata):
- Se viene eseguita una query su
TABLE_B, Looker tenta innanzitutto di utilizzare la cache per restituire i risultati. - Se questo tentativo non va a buon fine, Looker prova a utilizzare una versione precedente della tabella, se possibile.
- Se anche questo tentativo non va a buon fine, Looker prova a ricostruire la tabella.
- Infine, se non è possibile ricompilare
TABLE_B, Looker restituirà un errore.
Looker proverà di nuovo a ricostruire TABLE_B quando la tabella verrà interrogata di nuovo o quando la strategia di persistenza della tabella attiverà di nuovo una ricostruzione.
Lo stesso vale anche per i familiari a carico di TABLE_B. Pertanto, se non è possibile creare TABLE_B e c'è una query su TABLE_C, si verifica la seguente sequenza:
- Looker tenterà di utilizzare la cache per la query su
TABLE_C. - Se i risultati non sono nella cache, Looker tenterà di estrarli da
TABLE_Cnel database. - Se non è presente una versione valida di
TABLE_C, Looker tenterà di ricompilarla, creando una query suTABLE_B.TABLE_C - Looker tenterà quindi di ricompilare
TABLE_B(operazione che non andrà a buon fine seTABLE_Bnon è stato corretto). - Se
TABLE_Bnon può essere ricreato, non può essere ricreato neancheTABLE_C, quindi Looker restituirà un errore per la query suTABLE_C. - Looker tenterà quindi di ricostruire
TABLE_Cin base alla sua consueta strategia di persistenza o la volta successiva che la PDT viene interrogata (inclusa la volta successiva cheTABLE_Dtenta di creare, poichéTABLE_Ddipende daTABLE_C).
Una volta risolto il problema con TABLE_B, TABLE_B e ciascuna delle tabelle dipendenti tenteranno di essere ricostruite in base alle rispettive strategie di persistenza o alla successiva esecuzione di query (inclusa la successiva ricostruzione di una PDT dipendente). In alternativa, se una versione di sviluppo delle PDT nella cascata è stata creata in modalità di sviluppo, le versioni di sviluppo possono essere utilizzate come nuove PDT di produzione. Per informazioni su come funziona, consulta la sezione Tabelle persistenti in modalità di sviluppo in questa pagina. In alternativa, puoi utilizzare un'esplorazione per eseguire una query su TABLE_D e poi ricreare manualmente le PDT per la query, il che forzerà la ricreazione di tutte le PDT nella cascata di dipendenze.
Migliorare il rendimento del PDT
Quando crei tabelle derivate permanenti (PDT), le prestazioni possono essere un problema. Soprattutto quando la tabella è molto grande, l'esecuzione di query sulla tabella potrebbe essere lenta, proprio come per qualsiasi tabella di grandi dimensioni nel database.
Puoi migliorare le prestazioni filtrando i dati o controllando il modo in cui i dati nella tabella derivata persistente vengono ordinati e indicizzati.
Aggiungere filtri per limitare il set di dati
Con set di dati particolarmente grandi, avere molte righe rallenterà le query su una tabella derivata permanente (PDT). Se di solito esegui query solo sui dati recenti, valuta la possibilità di aggiungere un filtro alla clausola WHERE del PDT che limiti la tabella a 90 giorni o meno di dati. In questo modo, alla tabella verranno aggiunti solo i dati pertinenti ogni volta che viene ricreata, in modo che l'esecuzione delle query sia molto più veloce. Poi, puoi creare un PDT separato e più grande per l'analisi storica, in modo da consentire sia query veloci per i dati recenti sia la possibilità di eseguire query sui dati meno recenti.
Utilizzo di indexes o sortkeys e distribution
Quando crei una PDT (Persistent Derived Table) di grandi dimensioni, l'indicizzazione della tabella (per dialetti come MySQL o Postgres) o l'aggiunta di chiavi di ordinamento e distribuzione (per Redshift) può migliorare le prestazioni.
In genere è meglio aggiungere il parametro indexes ai campi ID o data.
Per Redshift, in genere è meglio aggiungere il parametro sortkeys ai campi ID o data e il parametro distribution al campo utilizzato per l'unione.
Impostazioni consigliate per migliorare il rendimento
Le seguenti impostazioni controllano la modalità di ordinamento e indicizzazione dei dati nella tabella derivata permanente (PDT). Queste impostazioni sono facoltative, ma vivamente consigliate:
- Per Redshift e Aster, utilizza il parametro
distributionper specificare il nome della colonna il cui valore viene utilizzato per distribuire i dati in un cluster. Quando due tabelle vengono unite dalla colonna specificata nel parametrodistribution, il database può trovare i dati di unione nello stesso nodo, in modo da ridurre al minimo l'I/O tra i nodi. - Per Redshift, imposta il parametro
distribution_stylesuallper indicare al database di conservare una copia completa dei dati su ogni nodo. Viene spesso utilizzato per ridurre al minimo l'I/O tra i nodi quando vengono unite tabelle relativamente piccole. Imposta questo valore suevenper indicare al database di distribuire i dati in modo uniforme nel cluster senza utilizzare una colonna di distribuzione. Questo valore può essere specificato solo quandodistributionnon è specificato. - Per Redshift, utilizza il parametro
sortkeys. I valori specificano quali colonne della tabella derivata vengono utilizzate per ordinare i dati sul disco per semplificare la ricerca. Su Redshift, puoi utilizzaresortkeysoindexes, ma non entrambi. - Nella maggior parte dei database, utilizza il parametro
indexes. I valori specificano le colonne della tabella derivata che vengono indicizzate. In Redshift, gli indici vengono utilizzati per generare chiavi di ordinamento interleaved.