在 Looker 中,衍生資料表是指查詢,其結果會當做資料庫中的實際資料表使用。
舉例來說,您可能有一個名為 orders 的資料庫資料表,其中包含許多資料欄。您想計算一些顧客層級的匯總指標,例如每位顧客的下單次數,或是每位顧客首次下單的時間。您可以使用原生衍生資料表或以 SQL 為基礎的衍生資料表,建立名為 customer_order_summary 的新資料庫資料表,其中包含這些指標。

接著,您就可以像使用資料庫中的任何其他資料表一樣,使用customer_order_summary衍生資料表。
如要瞭解衍生資料表的常見用途,請參閱 Looker 食譜:充分運用 Looker 中的衍生資料表。
原生衍生資料表和以 SQL 為基礎的衍生資料表
如要在 Looker 專案中建立衍生資料表,請使用 view 參數底下的 derived_table 參數。在 derived_table 參數中,您可以透過下列任一方式定義衍生資料表的查詢:
- 如果是原生衍生資料表,您可以使用以 LookML 為基礎的查詢定義衍生資料表。
- 如果是以 SQL 為基礎的衍生資料表,您可以使用 SQL 查詢定義衍生資料表。
舉例來說,下列檢視檔案說明如何使用 LookML 從 customer_order_summary 衍生資料表建立檢視區塊。這兩個版本的 LookML 說明如何使用 LookML 或 SQL 定義衍生資料表的查詢,藉此建立等效的衍生資料表:
- 原生衍生資料表會在
explore_source參數中,使用 LookML 定義查詢。在本範例中,查詢是以現有的orders檢視畫面為依據,該檢視畫面定義在另一個檔案中,本範例未顯示該檔案。原生衍生資料表中的explore_source查詢會從orders檢視區塊檔案帶入customer_id、first_order和total_amount欄位。 - 以 SQL 為基礎的衍生資料表會使用
sql參數中的 SQL 定義查詢。在本例中,SQL 查詢是直接查詢資料庫中的orders資料表。
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
這兩個版本都會根據 orders 資料表建立名為 customer_order_summary 的檢視區塊,並包含 customer_id、first_order, 和 total_amount 資料欄。
除了 derived_table 參數及其子參數外,這個 customer_order_summary 檢視畫面與其他檢視畫面檔案的運作方式相同。無論您是使用 LookML 或 SQL 定義衍生資料表的查詢,都可以根據衍生資料表的資料欄建立 LookML 測量值和維度。
定義衍生資料表後,您就可以像使用資料庫中的其他資料表一樣使用衍生資料表。
原生衍生資料表
原生衍生資料表是以您使用 LookML 字詞定義的查詢為基礎。如要建立原生衍生資料表,請在 檢視區塊參數的 derived_table 參數內使用 explore_source 參數。您可以參照模型中的 LookML 維度或測量指標,建立原生衍生資料表的資料欄。請參閱上一個範例中的原生衍生資料表檢視檔案。
相較於以 SQL 為基礎的衍生資料表,原生衍生資料表在您建立資料模型時,更容易閱讀及瞭解。
如要進一步瞭解如何建立原生衍生資料表,請參閱「建立原生衍生資料表」說明文件頁面。
以 SQL 為基礎的衍生資料表
如要建立以 SQL 為基礎的衍生資料表,請以 SQL 條件定義查詢,並使用 SQL 查詢在資料表中建立資料欄。您無法在以 SQL 為基礎的衍生資料表中參照 LookML 維度和測量指標。請參閱上一個範例中以 SQL 為基礎的衍生資料表檢視檔案。
最常見的做法是使用 view 參數的 derived_table 參數內的 sql 參數,定義 SQL 查詢。
在 Looker 中建立以 SQL 為基礎的查詢時,有個實用的捷徑:使用 SQL Runner 建立 SQL 查詢,並將其轉換為衍生資料表定義。
在某些極端情況下,系統不允許使用 sql 參數。在這種情況下,Looker 支援下列參數,用於定義永久衍生資料表 (PDT) 的 SQL 查詢:
create_process:當您為 PDT 使用sql參數時,Looker 會在背景中將方言的CREATE TABLE資料定義語言 (DDL) 陳述式包裝在查詢周圍,以便從 SQL 查詢建立 PDT。部分方言不支援單一步驟中的 SQLCREATE TABLE陳述式。對於這些方言,您無法使用sql參數建立 PDT。您可以改用create_process參數,分多個步驟建立 PDT。如需相關資訊和範例,請參閱create_process參數說明文件頁面。sql_create:如果您的用途需要自訂 DDL 指令,且方言支援 DDL (例如 Google 預測性 BigQuery ML),您可以使用sql_create參數建立 PDT,而不使用sql參數。如需相關資訊和範例,請參閱sql_create說明文件頁面。
無論您使用 sql、create_process 或 sql_create 參數,在所有這些情況下,您都是使用 SQL 查詢定義衍生資料表,因此這些都視為以 SQL 為基礎的衍生資料表。
定義以 SQL 為基礎的衍生資料表時,請務必使用 AS 為每個資料欄指定清楚的別名。這是因為您需要在維度中參照結果集的資料欄名稱,例如 ${TABLE}.first_order。因此,上一個範例使用 MIN(DATE(time)) AS first_order,而非僅使用 MIN(DATE(time))。
暫時性和永久性衍生資料表
除了原生衍生資料表和以 SQL 為基礎的衍生資料表之間的差異外,還有暫時性衍生資料表 (不會寫入資料庫) 和永久性衍生資料表 (PDT) (會寫入資料庫的結構定義) 之間的差異。
原生衍生資料表和以 SQL 為基礎的衍生資料表可以是暫時性或永久性。
暫時性衍生資料表
先前顯示的衍生資料表是暫時性衍生資料表的範例。由於 derived_table 參數中未定義持續性策略,因此這些值是暫時性的。
系統不會將臨時衍生資料表寫入資料庫。使用者執行包含一或多個衍生資料表的「探索」查詢時,Looker 會使用衍生資料表的 SQL,加上要求的欄位、聯結和篩選值,以特定方言組合建構 SQL 查詢。如果先前已執行過該組合,且結果在快取中仍有效,Looker 就會使用快取的結果。如要進一步瞭解 Looker 中的查詢快取,請參閱「快取查詢」說明文件頁面。
否則,如果 Looker 無法使用快取結果,使用者每次從臨時衍生資料表要求資料時,Looker 都必須對資料庫執行新的查詢。因此,請務必確保臨時衍生資料表效能良好,不會對資料庫造成過度負擔。如果查詢需要一段時間才能執行,通常會建議使用 PDT。
臨時衍生資料表支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的衍生資料表,資料庫方言也必須支援。下表列出 Looker 最新版本中支援衍生資料表的方言:
按這裡即可顯示表格。
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 是 |
| Apache Druid 0.13+ | 是 |
| Apache Druid 0.18+ | 是 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 是 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 是 |
| Databricks | 是 |
| Denodo 7 | 是 |
| Denodo 8 & 9 | 是 |
| Dremio | 是 |
| Dremio 11+ | 是 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 是 |
| Google Spanner | 是 |
| Greenplum | 是 |
| HyperSQL | 是 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 是 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
永久衍生資料表
持續衍生資料表 (PDT) 是寫入資料庫暫存結構定義的衍生資料表,並會按照您使用持續策略指定的排程重新產生。
PDT 可以是原生衍生資料表,也可以是以 SQL 為基礎的衍生資料表。
PDT 的規定
如要在 Looker 專案中使用永久衍生資料表 (PDT),您需要:
- 支援 PDT 的資料庫方言。如需支援以 SQL 為基礎的永久衍生資料表和永久原生衍生資料表的方言清單,請參閱本頁稍後的「支援 PDT 的資料庫方言」一節。
資料庫的暫存結構定義。這可以是資料庫中的任何結構定義,但建議您建立僅用於此用途的新結構定義。資料庫管理員必須為 Looker 資料庫使用者設定具有寫入權限的結構定義。
已啟用「啟用 PDT」切換鈕的Looker 連線。通常在首次設定 Looker 連線時,會設定「啟用 PDT」設定 (如需資料庫方言的操作說明,請參閱「Looker 方言」說明文件頁面),但您也可以在初始設定後,為連線啟用 PDT。
PDT 支援的資料庫方言
如要讓 Looker 支援 Looker 專案中的 PDT,資料庫方言也必須支援 PDT。
如要支援任何類型的 PDT (無論是 LookML 或 SQL 型),方言必須支援寫入資料庫,以及其他需求。部分唯讀資料庫設定不允許持續性作業 (最常見的是 Postgres 熱交換副本資料庫)。在這種情況下,您可以改用暫時衍生資料表。
下表列出 Looker 最新版本中支援以 SQL 為基礎的永久衍生資料表的方言:
按這裡即可顯示表格。
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 是 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
如要支援持續性原生衍生資料表 (具有 LookML 型查詢),方言也必須支援 CREATE TABLE DDL 函式。以下列出最新版 Looker 中支援永久原生 (以 LookML 為基礎) 衍生資料表的方言:
按這裡即可顯示表格。
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | 是 |
| Amazon Athena | 是 |
| Amazon Aurora MySQL | 是 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 是 |
| Apache Hive 3.1.2+ | 是 |
| Apache Spark 3+ | 是 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 是 |
| Cloudera Impala 3.1+ with Native Driver | 是 |
| Cloudera Impala with Native Driver | 是 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 是 |
| Google BigQuery Legacy SQL | 是 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 是 |
| MariaDB | 是 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 是 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 是 |
| Microsoft SQL Server 2012+ | 是 |
| Microsoft SQL Server 2016 | 是 |
| Microsoft SQL Server 2017+ | 是 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 是 |
| Oracle ADWC | 是 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 是 |
| PrestoSQL | 是 |
| SAP HANA | 是 |
| SAP HANA 2+ | 是 |
| SingleStore | 是 |
| SingleStore 7+ | 是 |
| Snowflake | 是 |
| Teradata | 是 |
| Trino | 是 |
| Vector | 是 |
| Vertica | 是 |
增量建構 PDT
增量 PDT 是 持續衍生資料表,Looker 會將新資料附加至資料表,而非重建整個資料表。
如果方言支援增量 PDT,且 PDT 使用以觸發條件為準的持續策略 (datagroup_trigger、sql_trigger_value 或 interval_trigger),您可以將 PDT 定義為增量 PDT。
詳情請參閱「累加 PDT」說明文件頁面。
增量 PDT 支援的資料庫方言
如要讓 Looker 專案支援累加 PDT,資料庫方言也必須支援。下表列出最新版 Looker 中支援遞增 PDT 的方言:
按這裡即可顯示表格。
| 方言 | 是否支援? |
|---|---|
| Actian Avalanche | 否 |
| Amazon Athena | 否 |
| Amazon Aurora MySQL | 否 |
| Amazon Redshift | 是 |
| Amazon Redshift 2.1+ | 是 |
| Amazon Redshift Serverless 2.1+ | 是 |
| Apache Druid | 否 |
| Apache Druid 0.13+ | 否 |
| Apache Druid 0.18+ | 否 |
| Apache Hive 2.3+ | 否 |
| Apache Hive 3.1.2+ | 否 |
| Apache Spark 3+ | 否 |
| ClickHouse | 否 |
| Cloudera Impala 3.1+ | 否 |
| Cloudera Impala 3.1+ with Native Driver | 否 |
| Cloudera Impala with Native Driver | 否 |
| DataVirtuality | 否 |
| Databricks | 是 |
| Denodo 7 | 否 |
| Denodo 8 & 9 | 否 |
| Dremio | 否 |
| Dremio 11+ | 否 |
| Exasol | 否 |
| Google BigQuery Legacy SQL | 否 |
| Google BigQuery Standard SQL | 是 |
| Google Cloud PostgreSQL | 是 |
| Google Cloud SQL | 否 |
| Google Spanner | 否 |
| Greenplum | 是 |
| HyperSQL | 否 |
| IBM Netezza | 否 |
| MariaDB | 否 |
| Microsoft Azure PostgreSQL | 是 |
| Microsoft Azure SQL Database | 否 |
| Microsoft Azure Synapse Analytics | 是 |
| Microsoft SQL Server 2008+ | 否 |
| Microsoft SQL Server 2012+ | 否 |
| Microsoft SQL Server 2016 | 否 |
| Microsoft SQL Server 2017+ | 否 |
| MongoBI | 否 |
| MySQL | 是 |
| MySQL 8.0.12+ | 是 |
| Oracle | 否 |
| Oracle ADWC | 否 |
| PostgreSQL 9.5+ | 是 |
| PostgreSQL pre-9.5 | 是 |
| PrestoDB | 否 |
| PrestoSQL | 否 |
| SAP HANA | 否 |
| SAP HANA 2+ | 否 |
| SingleStore | 否 |
| SingleStore 7+ | 否 |
| Snowflake | 是 |
| Teradata | 否 |
| Trino | 否 |
| Vector | 否 |
| Vertica | 是 |
建立 PDT
如要將衍生資料表設為永久衍生資料表 (PDT),請為該資料表定義持續策略。如要盡量提升成效,建議您也加入最佳化策略。
保留策略
衍生資料表的持續性可由 Looker 管理,或由資料庫使用具體化檢視區塊 (適用於支援具體化檢視區塊的方言)。
如要讓衍生資料表保持不變,請將下列其中一個參數新增至 derived_table 定義:
- Looker 管理的持續性參數:
- 資料庫管理的持續性參數:
採用觸發條件式持續策略 (datagroup_trigger、sql_trigger_value 和 interval_trigger) 時,Looker 會將 PDT 保留在資料庫中,直到 PDT 觸發重建為止。系統觸發 PDT 時,Looker 會重建 PDT,取代先前版本。也就是說,使用觸發式 PDT 時,使用者不必等待系統建構 PDT,就能從 PDT 取得探索查詢的答案。
datagroup_trigger
資料群組是建立持續性的最靈活方法。如果您已使用 sql_trigger 或 interval_trigger 定義 datagroup,則可以使用 datagroup_trigger 參數啟動永久衍生資料表 (PDT) 的重建作業。
Looker 會將 PDT 保留在資料庫中,直到觸發資料群組為止。資料群組觸發後,Looker 會重建 PDT,取代先前的版本。也就是說,在大多數情況下,使用者不必等待系統建構 PDT。如果使用者在 PDT 建構期間要求資料,且查詢結果不在快取中,Looker 會傳回現有 PDT 的資料,直到新的 PDT 建構完成為止。如要瞭解資料群組,請參閱「快取查詢」一文。
如要進一步瞭解再生器如何建構 PDT,請參閱「Looker 再生器」一節。
sql_trigger_value
sql_trigger_value 參數會根據您提供的 SQL 陳述式,觸發永久衍生資料表 (PDT) 的重新產生作業。如果 SQL 陳述式的結果與先前的值不同,系統會重新產生 PDT。否則,資料庫會保留現有的 PDT。也就是說,在大多數情況下,使用者不必等待系統建構 PDT。如果使用者在 PDT 建構期間要求資料,且查詢結果不在快取中,Looker 會傳回現有 PDT 的資料,直到新的 PDT 建構完成為止。
如要進一步瞭解再生器如何建構 PDT,請參閱「Looker 再生器」一節。
interval_trigger
interval_trigger 參數會根據您提供的时间間隔 (例如 "24 hours" 或 "60 minutes"),觸發永久衍生資料表 (PDT) 的重新產生作業。與 sql_trigger 參數類似,這表示使用者查詢 PDT 時,系統通常會預先建構 PDT。如果使用者在 PDT 建構期間要求資料,且查詢結果不在快取中,Looker 會傳回現有 PDT 的資料,直到新的 PDT 建構完成為止。
persist_for
您也可以使用 persist_for 參數設定衍生表格的儲存時間長度,之後系統會將該表格標示為過期,不再用於查詢,並從資料庫中捨棄。
使用者首次對persist_for持續衍生資料表 (PDT) 執行查詢時,系統會建構該資料表。接著,Looker 會在資料庫中保留 PDT,時間長度由 PDT 的 persist_for 參數指定。如果使用者在 persist_for 時間內查詢 PDT,Looker 會盡可能使用快取結果,否則會在 PDT 上執行查詢。
persist_for時間過後,Looker 會從資料庫清除 PDT,並在使用者下次查詢時重建 PDT,這表示查詢需要等待重建完成。
使用 persist_for 的 PDT 不會由 Looker 再生器自動重建,除非是 PDT 的依附元件層疊。如果 persist_for 資料表是依附元件連鎖的一部分,且包含以觸發條件為基礎的 PDT (使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 持續性策略的 PDT),重新產生器會監控並重建 persist_for 資料表,以便重建連鎖中的其他資料表。請參閱本頁面的「Looker 如何建構層疊衍生資料表」一節。
materialized_view: yes
透過具體化檢視區塊,您可以使用資料庫功能,在 Looker 專案中保留衍生資料表。如果資料庫方言支援具體化檢視區塊,且Looker 連線已啟用「啟用 PDT」切換鈕,您可以在衍生資料表指定 materialized_view: yes,建立具體化檢視區塊。具體化檢視表支援原生衍生資料表和以 SQL 為基礎的衍生資料表。
與永久衍生資料表 (PDT) 類似,具體化檢視區塊是查詢結果,會以資料表的形式儲存在資料庫的暫存結構定義中。PDT 和具體化檢視區別在於資料表重新整理的方式:
- 如果是 PDT,持久性策略會在 Looker 中定義,並由 Looker 管理。
- 如果是具體化檢視區塊,資料庫會負責維護及重新整理資料表中的資料。
因此,如要使用具體化檢視區塊功能,必須對方言及其功能有深入瞭解。在大多數情況下,只要資料庫偵測到具體化檢視查詢的資料表中有新資料,就會重新整理具體化檢視。具體化檢視表最適合需要即時資料的情境。
如要瞭解方言支援、需求和重要考量事項,請參閱 materialized_view 參數說明文件頁面。
最佳化策略
由於衍生永久資料表 (PDT) 儲存在資料庫中,因此您應使用方言支援的下列策略,盡可能提升 PDT 效能:
舉例來說,如要為衍生資料表範例新增持續性,可以將其設為在資料群組 orders_datagroup 觸發時重建,並在 customer_id 和 first_order 上新增索引,如下所示:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
如果未新增索引 (或方言的對等項目),Looker 會發出警告,建議您新增索引來提升查詢效能。
PDT 的用途
持續衍生資料表 (PDT) 的實用之處在於,可將查詢結果保留在資料表中,藉此提升查詢效能。
一般來說,開發人員應盡量在沒有絕對必要的情況下,嘗試建立資料模型,而不使用 PDT。
在某些情況下,資料可透過其他方式最佳化。舉例來說,新增索引或變更資料欄的資料類型,可能就能解決問題,不必建立 PDT。請務必使用 SQL Runner 工具的「說明」功能,分析執行緩慢的查詢的執行計畫。
除了縮短查詢時間,以及減少經常執行的查詢作業對資料庫造成的負擔,PDT 還有其他用途,包括:
如果無法合理地將資料表中的不重複資料列識別為主鍵,您也可以使用 PDT 定義主鍵。
使用 PDT 測試最佳化設定
您可以使用 PDT 測試不同的索引、發布和其他最佳化選項,不必尋求 DBA 或 ETL 開發人員的大量支援。
假設您有一個資料表,但想測試不同的索引。檢視區塊的初始 LookML 可能如下所示:
view: customer {
sql_table_name: warehouse.customer ;;
}
如要測試最佳化策略,可以使用 indexes 參數將索引新增至 LookML,如下所示:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
查詢檢視區塊一次,即可生成 PDT。接著執行測試查詢並比較結果。如果結果良好,您可以請 DBA 或 ETL 團隊將索引新增至原始資料表。
別忘了變更檢視區塊程式碼,移除 PDT。
使用 PDT 預先彙整或匯總資料
預先聯結或匯總資料,有助於調整查詢最佳化設定,以處理大量或多種資料。
舉例來說,假設您想根據顧客首次下單的時間,為同類群組建立顧客查詢。每當需要即時資料時,多次執行這項查詢可能會很耗費資源,但您可以只計算一次查詢,然後使用 PDT 重複使用結果:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
衍生資料表層疊
您可以在另一個衍生資料表的定義中參照一個衍生資料表,視情況建立層疊衍生資料表或層疊持續性衍生資料表 (PDT) 鏈結。舉例來說,假設資料表 TABLE_D 依附於另一個資料表 TABLE_C,而 TABLE_C 依附於 TABLE_B,TABLE_B 則依附於 TABLE_A,這就是層疊衍生資料表。
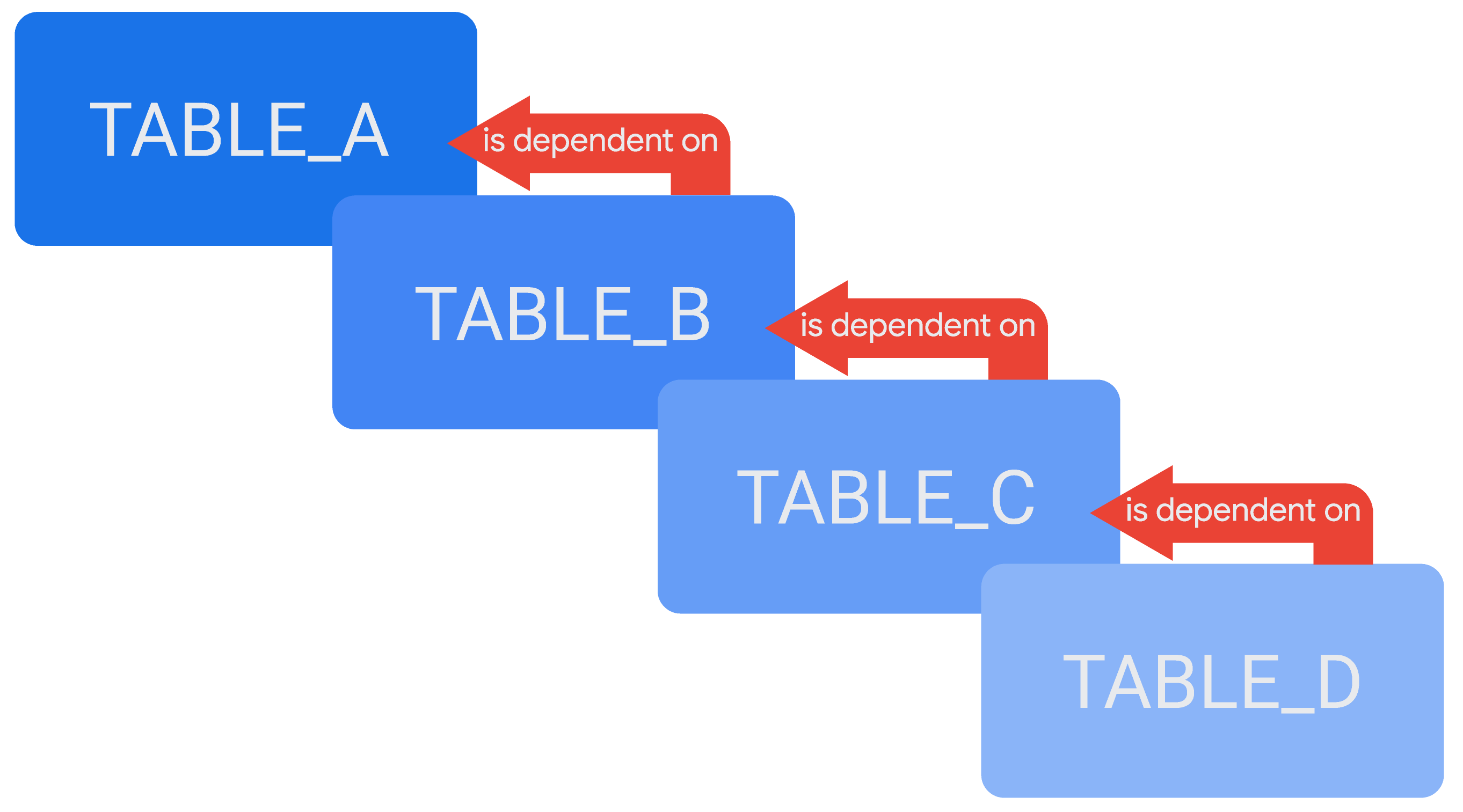
參照衍生資料表的語法
如要在另一個衍生資料表中參照衍生資料表,請使用下列語法:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
在這個格式中,SQL_TABLE_NAME 是字串常值。舉例來說,您可以使用下列語法參照 clean_events 衍生資料表:
`${clean_events.SQL_TABLE_NAME}`
您可以使用相同的語法參照 LookML 檢視區塊。同樣地,在這個情況下,SQL_TABLE_NAME 是字串常值。
在下一個範例中,系統會從資料庫中的 events 資料表建立 clean_events PDT。clean_events PDT 會從 events 資料庫資料表中排除不需要的資料列。接著會顯示第二個 PDT,即 clean_events PDT 的摘要。event_summary每當 clean_events 中新增資料列時,event_summary 資料表就會重新產生。
event_summary PDT 和 clean_events PDT 是層疊 PDT,其中 event_summary 依附於 clean_events (因為 event_summary 是使用 clean_events PDT 定義)。這個特定範例可以在單一 PDT 中更有效率地完成,但可用於示範衍生資料表參照。
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
雖然不一定需要,但以這種方式參照衍生資料表時,通常會使用以下格式為資料表建立別名:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
上一個範例會執行下列操作:
${clean_events.SQL_TABLE_NAME} AS clean_events
使用別名很有幫助,因為在幕後,PDT 在資料庫中是以冗長的程式碼命名。有時 (尤其是使用 ON 子句時),您可能會忘記需要使用 ${derived_table_or_view_name.SQL_TABLE_NAME} 語法來擷取這個長名稱。別名有助於避免這類錯誤。
Looker 如何建構層疊衍生資料表
如果是連鎖暫時性衍生資料表,如果使用者的查詢結果不在快取中,Looker 會建構查詢所需的所有衍生資料表。如果 TABLE_D 的定義包含對 TABLE_C 的參照,則 TABLE_D 會依附於 TABLE_C。也就是說,如果您查詢 TABLE_D,但查詢不在 Looker 的快取中,Looker 會重建 TABLE_D。但必須先重建 TABLE_C。
假設有連鎖的暫時衍生資料表,其中 TABLE_D 依附於 TABLE_C,而 TABLE_C 依附於 TABLE_B,TABLE_B 則依附於 TABLE_A。如果 Looker 在快取中找不到 TABLE_C 查詢的有效結果,就會建構查詢所需的所有資料表。因此 Looker 會先建構 TABLE_A,然後是 TABLE_B,最後是 TABLE_C:
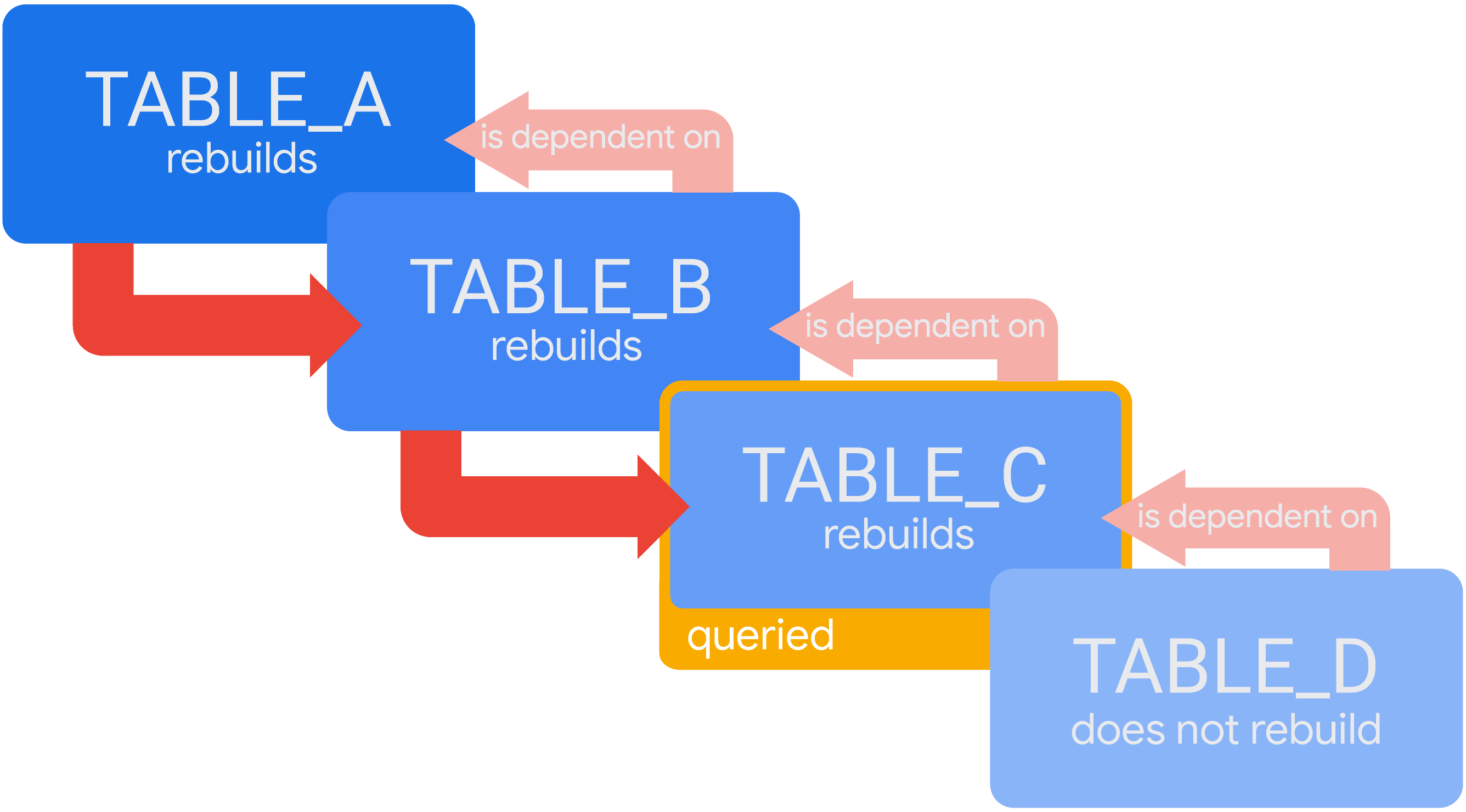
在這種情況下,Looker 必須先完成 TABLE_A 的生成作業,才能開始生成 TABLE_B,且必須先完成 TABLE_B 的生成作業,才能開始生成 TABLE_C。TABLE_C 完成後,Looker 會提供查詢結果。(由於回答這項查詢不需要 TABLE_D,Looker 目前不會重建 TABLE_D)。
如要查看使用相同資料群組的 PDT 級聯範例情境,請參閱 datagroup 參數說明文件頁面。
PDT 也適用相同的基本邏輯:Looker 會建構回答查詢所需的所有資料表,直到依附元件鏈結的頂端為止。但使用 PDT 時,表格通常已存在,不需要重建。如果使用標準使用者查詢,並採用層疊式 PDT,只有在資料庫中沒有有效的 PDT 版本時,Looker 才會重建層疊式 PDT。如要強制重新建立連鎖中的所有 PDT,可以透過「探索」手動重新建立查詢的資料表。
請務必瞭解,在 PDT 串聯的情況下,相依的 PDT 基本上是查詢所依附的 PDT。如果 PDT 使用 persist_for 策略,這項功能就特別重要。通常,persist_for PDT 會在使用者查詢時建構,並保留在資料庫中,直到 persist_for 間隔結束為止,之後除非使用者再次查詢,否則不會重建。不過,如果 persist_for PDT 是以觸發條件為基礎的 PDT (使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 持續性策略的 PDT) 串聯的一部分,系統會在重建其依附的 PDT 時,查詢 persist_for PDT。因此,在這種情況下,系統會依據相依 PDT 的時間表重建 persist_for PDT。也就是說,persist_for PDT 可能會受到其依附項目的持續性策略影響。
手動重建查詢的永久資料表
使用者可以從「探索」選單中選取「重新建立衍生資料表並執行」選項,覆寫持續性設定,並重新建立「探索」中目前查詢所需的所有永久衍生資料表 (PDT) 和匯總資料表:
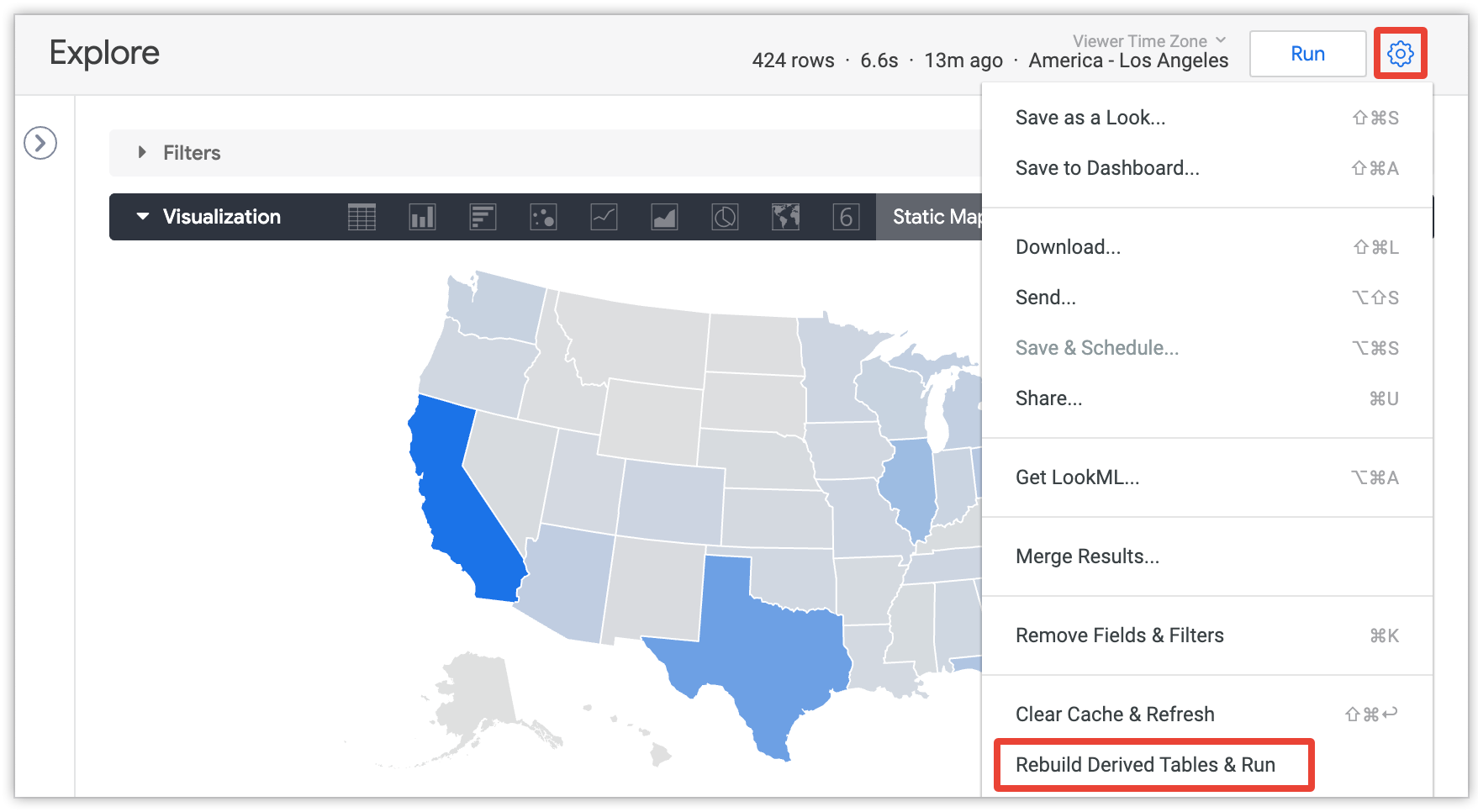
只有具備 develop 權限的使用者,才能看到這個選項,且必須在探索查詢載入後才會顯示。
「重建衍生資料表並執行」選項會重建回答查詢所需的所有持續性資料表 (所有 PDT 和匯總資料表),無論其持續性策略為何。包括目前查詢中的所有匯總資料表和 PDT,以及目前查詢中匯總資料表和 PDT 參照的任何匯總資料表和 PDT。
如果是增量 PDT,「重建衍生資料表並執行」選項會觸發新增量的建構作業。使用增量 PDT 時,增量會包含 increment_key 參數中指定的時間範圍,以及 increment_offset 參數中指定的先前時間範圍數量 (如有)。如要查看一些範例情境,瞭解遞增 PDT 如何根據設定建構,請參閱「遞增 PDT」說明文件頁面。
如果是層疊 PDT,這表示要從頂端開始,重建層疊中的所有衍生資料表。這與查詢一連串臨時衍生資料表中的資料表時的行為相同:
手動重建衍生資料表時,請注意下列事項:
- 如果使用者啟動「重建衍生資料表並執行」作業,查詢會等待資料表重建完成,再載入結果。其他使用者的查詢仍會使用現有資料表。重建永久資料表後,所有使用者都會使用重建的資料表。雖然這個程序旨在避免在重建資料表時中斷其他使用者的查詢,但資料庫的額外負載仍可能影響這些使用者。如果您在上班時間觸發重建作業,可能會對資料庫造成無法接受的負擔,因此您可能需要告知使用者,在這些時段內絕不能重建特定 PDT 或匯總資料表。
如果使用者處於開發模式,且「探索」是以開發資料表為基礎,則「重新建立衍生資料表並執行」作業會重新建立「探索」的開發資料表,而非正式環境資料表。但如果開發模式中的「探索」使用衍生資料表的正式版,系統就會重建正式版資料表。如要瞭解開發資料表和正式版資料表,請參閱「開發模式中的持續性資料表」。
如果是 Looker 代管的執行個體,如果衍生資料表重建時間超過一小時,資料表將無法順利重建,瀏覽器工作階段也會逾時。如要進一步瞭解可能影響 Looker 程序的逾時,請參閱「管理設定 - 查詢」說明文件頁面的「查詢逾時和排隊」一節。
開發模式下的永久性資料表
在開發模式中管理持續性資料表時,Looker 會有一些特殊行為。
如果您在開發模式中查詢持續性資料表,但未對其定義進行任何變更,Looker 會查詢該資料表的正式版本。如果變更資料表定義,導致資料表中的資料或查詢方式受到影響,下次在開發模式中查詢資料表時,系統會建立新的資料表開發版本。有了這類開發資料表,您就能測試變更,而不會干擾使用者。
Looker 建立開發資料表的觸發條件
無論您是否處於開發模式,Looker 都會盡可能使用現有的正式版資料表來回答查詢。不過,在某些情況下,Looker 無法在開發模式中使用正式版資料表進行查詢:
- 如果持續性資料表含有可將資料集縮小範圍的參數,在開發模式中就能加快工作速度
- 如果您對持續性資料表的定義進行變更,而這些變更會影響資料表中的資料
如果您處於開發模式,並查詢使用條件式 WHERE 子句 (含 if prod 和 if dev 陳述式) 定義的以 SQL 為基礎的衍生資料表,Looker 就會建立開發資料表。
如果持續性資料表沒有參數可在開發模式中縮小資料集範圍,Looker 會使用資料表的正式版來回答開發模式中的查詢,除非您變更資料表的定義,然後在開發模式中查詢資料表。凡是會影響資料表中的資料或查詢方式的變更,都適用這項規定。
以下列舉幾種變更類型,這些變更會促使 Looker 建立永久資料表的開發版本 (只有在您進行這些變更後查詢資料表時,Looker 才會建立資料表):
- 變更永久資料表所依據的查詢,例如修改永久資料表本身或任何必要資料表 (如果是層疊衍生資料表) 中的
explore_source、sql、query、sql_create或create_process參數 - 變更資料表的持續性策略,例如修改資料表的
datagroup_trigger、sql_trigger_value、interval_trigger或persist_for參數 - 變更衍生資料表的
view名稱 - 變更增量 PDT 的
increment_key或increment_offset - 變更相關聯模型使用的
connection
如果變更不會修改資料表資料,也不會影響 Looker 查詢資料表的方式,Looker 就不會建立開發資料表。publish_as_db_view 參數就是一個很好的例子:在開發模式中,如果您只變更衍生資料表的 publish_as_db_view 設定,Looker 就不需要重建衍生資料表,因此不會建立開發資料表。
Looker 會保留開發資料表多久時間
無論資料表的實際持續策略為何,Looker 都會將開發持續性資料表視為具有 persist_for: "24 hours" 的持續性策略。Looker 這麼做是為了確保開發資料表不會保留超過一天,因為 Looker 開發人員在開發期間可能會查詢多個資料表疊代,且每次都會建構新的開發資料表。為避免開發資料表造成資料庫雜亂,Looker 會套用 persist_for: "24 hours" 策略,確保資料表經常從資料庫中清除。
否則,Looker 會在開發模式中建構持續衍生資料表 (PDT) 和匯總資料表,方式與在正式環境模式中建構持續性資料表相同。
如果將變更部署至 PDT 或匯總資料表時,開發資料表會保留在資料庫中,Looker 通常會將開發資料表做為正式版資料表,這樣使用者查詢資料表時,就不必等待資料表建構完成。
請注意,視情況而定,部署變更後,資料表可能仍需重建,才能在正式環境中查詢:
- 如果您在開發模式中查詢資料表超過 24 小時,系統會將開發版本的資料表標示為已過期,且不會用於查詢。您可以使用 Looker IDE,或使用「Persistent Derived Tables」(持續性衍生資料表) 頁面的「Development」(開發) 分頁,檢查是否有未建構的 PDT。如果您有未建構的 PDT,可以在變更前以開發模式查詢,這樣開發資料表就能在正式環境中使用。
- 如果持續性資料表具有
dev_filters參數 (適用於原生衍生資料表),或使用if prod和if dev陳述式的條件式WHERE子句 (適用於以 SQL 為基礎的衍生資料表),則開發資料表無法做為正式版,因為開發版本具有縮寫資料集。如果是這種情況,在完成資料表開發並部署變更前,您可以註解掉dev_filters參數或條件式WHERE子句,然後在開發模式中查詢資料表。部署變更後,Looker 會建構完整版本的資料表,供實際工作環境使用。
否則,如果部署變更時沒有可做為正式版資料表的有效開發資料表,Looker 會在下次以正式版模式查詢資料表時 (適用於使用 persist_for 策略的持續性資料表),或下次執行 regenerator 時 (適用於使用 datagroup_trigger、interval_trigger 或 sql_trigger_value 的持續性資料表),重建資料表。
在開發模式下檢查未建構的 PDT
如果您將變更部署至永久衍生資料表 (PDT) 或匯總資料表,且開發資料表保留在資料庫中,Looker 通常會將開發資料表做為正式環境資料表,這樣使用者查詢資料表時,就不必等待資料表建構完成。詳情請參閱本頁的「Looker 會保留開發資料表多久」和「Looker 會在什麼情況下建立開發資料表」一節。
因此,建議您在部署至正式環境時建立所有 PDT,以便立即使用這些資料表做為正式環境版本。
您可以在「專案健康狀態」面板中,檢查專案是否有未建構的 PDT。在 Looker IDE 中按一下「專案健康狀態」圖示,開啟「專案健康狀態」面板。然後按一下「驗證 PDT 狀態」按鈕。

如有未建構的 PDT,專案健康狀態面板會列出這些 PDT:
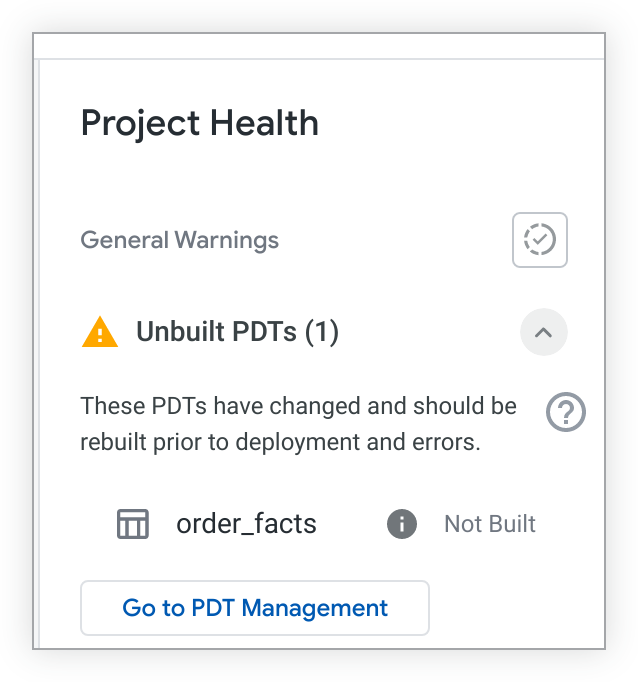
如果您有 see_pdts 權限,可以點選「前往 PDT 管理」按鈕。Looker 會開啟「永續衍生資料表」頁面的「開發」分頁,並將結果篩選為特定 LookML 專案。您可以在這裡查看已建構和未建構的開發 PDT,以及存取其他疑難排解資訊。詳情請參閱「管理設定 - 永久衍生資料表」說明文件頁面。
在專案中找出未建構的 PDT 後,開啟查詢該資料表的「探索」,然後使用「探索」選單中的「重新建立衍生資料表並執行」選項,即可建構開發版本。請參閱本頁面的「手動重建查詢的永久資料表」一節。
資料表共用和清除
在任何指定的 Looker 執行個體中,如果資料表具有相同的定義和相同的持續性方法設定,Looker 就會在使用者之間共用持續性資料表。此外,如果資料表的定義不再存在,Looker 會將資料表標示為已過期。
這麼做有幾個好處:
- 如果您尚未在開發模式中變更資料表,查詢會使用現有的正式版資料表。除非資料表是以 SQL 為基礎的衍生資料表,並使用含有
if prod和if dev陳述式的條件式WHERE子句定義,否則就會發生這種情況。如果資料表是以條件式WHERE子句定義,當您在開發模式中查詢資料表時,Looker 會建立開發資料表。(如果是使用dev_filters參數的原生衍生資料表,除非您變更資料表的定義,然後在開發模式中查詢資料表,否則 Looker 會使用正式環境資料表來回答開發模式中的查詢。) - 如果兩位開發人員在開發模式下對同一個表格進行相同變更,他們會共用同一個開發表格。
- 將變更從開發模式推送至實際工作環境模式後,舊的實際工作環境定義就不再存在,因此舊的實際工作環境資料表會標示為已過期並遭到捨棄。
- 如果您決定捨棄開發模式變更,該資料表定義就不會再存在,因此系統會將不需要的開發資料表標示為過期,並予以捨棄。
在開發模式下加快工作速度
有時您建立的永久衍生資料表 (PDT) 需要很長時間才能產生,如果您在開發模式中測試大量變更,這可能會很耗時。在這些情況下,您可以在開發模式中提示 Looker 建立衍生資料表的較小版本。
如果是原生衍生資料表,您可以使用 explore_source 的 dev_filters 子參數,指定僅套用至衍生資料表開發版本的篩選器:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
這個範例包含 dev_filters 參數,可將資料篩選為過去 90 天的資料;也包含 filters 參數,可將資料篩選為過去 2 年的資料,以及 Yucca Valley 機場的資料。
dev_filters 參數會與 filters 參數搭配運作,以便將所有篩選條件套用至資料表的開發版本。如果 dev_filters 和 filters 都為同一欄指定篩選器,則表格的開發版本會優先採用 dev_filters。在這個範例中,表格的開發版本會篩選出 Yucca Valley 機場過去 90 天的資料。
如果是以 SQL 為基礎的衍生資料表,Looker 支援條件式 WHERE 子句,並提供資料表正式版 (if prod) 和開發版 (if dev) 的不同選項:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
在本例中,查詢在「實際工作環境模式」下會包含 2000 年之後的所有資料,但在「開發模式」下只會包含 2020 年之後的資料。善用這項功能限制結果集並提高查詢速度,可大幅簡化開發模式變更的驗證作業。
Looker 如何建構 PDT
定義永久衍生資料表 (PDT) 後,如果這是第一次執行,或是 再生器根據持續性策略觸發重建作業,Looker 會執行下列步驟:
- 使用衍生資料表 SQL 建立 CREATE TABLE AS SELECT (或 CTAS) 陳述式,然後執行該陳述式。舉例來說,如要重建名為
customer_orders_facts的 PDT,請輸入:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - 在建構資料表時,發出陳述式來建立索引
- 將資料表從 LC$.. (「Looker Create」) 重新命名為 LR$.. (「Looker Read」),表示資料表已可供使用
- 捨棄不再使用的舊版表格
這會造成幾項重要影響:
- 構成衍生資料表的 SQL 必須在 CTAS 陳述式內有效。
- SELECT 陳述式結果集中的資料欄別名必須是有效的資料欄名稱。
- 指定分配、排序鍵和索引時使用的名稱,必須是衍生資料表的 SQL 定義中列出的資料欄名稱,而非 LookML 中定義的欄位名稱。
Looker 重新產生器
Looker 再生器會檢查狀態,並為觸發永久資料表啟動重建作業。採用觸發條件的永久資料表是永久衍生資料表 (PDT) 或匯總資料表,使用觸發條件做為持續策略:
- 如果資料表使用
sql_trigger_value,觸發條件就是資料表sql_trigger_value參數中指定的查詢。如果最新觸發查詢檢查的結果與先前觸發查詢檢查的結果不同,Looker 重新產生器就會觸發資料表重建作業。舉例來說,如果衍生資料表是透過 SQL 查詢SELECT CURDATE()持續存在,下次再生器在日期變更後檢查觸發條件時,就會重建資料表。 - 如果資料表使用
interval_trigger,觸發條件就是資料表interval_trigger參數中指定的時間長度。指定時間過後,Looker 再生器會觸發資料表重建作業。 - 如果資料表使用
datagroup_trigger,觸發條件可以是相關聯資料群組sql_trigger參數中指定的查詢,也可以是資料群組interval_trigger參數中指定的時間長度。
如果持續性資料表使用 persist_for 參數,Looker 再生器也會啟動重建作業,但前提是 persist_for 資料表是觸發持續性資料表的依附元件 cascade。在本例中,Looker 再生器會啟動 persist_for 資料表的重建作業,因為重建其他層疊資料表時需要用到這個資料表。否則,再生器不會監控使用 persist_for 策略的持續性資料表。
Looker 再生器週期會以固定間隔啟動,間隔由 Looker 管理員在資料庫連線的「維護排程」設定中設定 (預設間隔為五分鐘)。不過,Looker 重新產生器必須完成上一個週期的所有檢查和 PDT 重建作業,才會開始新的週期。也就是說,如果 PDT 建構作業耗時較長,Looker 再生器週期可能不會按照「維護時間表」設定的頻率執行。如本頁「實作持續性資料表的重要注意事項」一節所述,重建資料表所需的時間可能會受到其他因素影響。
如果 PDT 建構失敗,再生器可能會在下一個再生器週期嘗試重建資料表:
- 如果資料庫連線已啟用「重試失敗的 PDT 建構作業」設定,即使資料表的觸發條件未達成,Looker 再生器也會在下一個再生器週期嘗試重建資料表。
- 如果停用「Retry Failed PDT Builds」(重新執行失敗的 PDT 建構作業) 設定,Looker 重新產生器就不會嘗試重建資料表,直到符合 PDT 的觸發條件為止。
如果使用者在持續性資料表建構期間要求資料,且查詢結果不在快取中,Looker 會檢查現有資料表是否仍有效。(如果舊資料表與新版資料表不相容,可能就無效。如果新資料表有不同的定義、使用不同的資料庫連線,或是以不同版本的 Looker 建立,就可能發生這種情況)。如果現有資料表仍有效,Looker 會從現有資料表傳回資料,直到新資料表建構完成為止。否則,如果現有資料表無效,Looker 會在重建新資料表後提供查詢結果。
實作持續性資料表的重要注意事項
考量到持續性衍生資料表 (PDT 和匯總資料表) 的實用性,您的 Looker 執行個體可能會累積許多這類資料表。您可能會建立需要Looker 再生器同時建構多個資料表的案例。特別是串聯資料表或長時間執行的資料表,您可能會建立資料表重建作業延遲許久的情境,或是使用者在資料庫努力產生資料表時,查詢資料表結果會延遲。
Looker 再生器會檢查 PDT 觸發條件,判斷是否應重建觸發條件永久資料表。再生器週期會以固定間隔執行,由 Looker 管理員在資料庫連線的「維護排程」設定中設定 (預設間隔為五分鐘)。
重建資料表所需的時間會受到下列因素影響:
- Looker 管理員可能已使用資料庫連線的「維護時間表」設定,變更再生器觸發檢查的間隔。
- Looker 再生器必須完成上一個週期的所有檢查和 PDT 重建作業,才會開始新的週期。因此,如果 PDT 建構作業耗時較長,Looker 再生器週期可能不會像維護時間表設定一樣頻繁。
- 根據預設,再生器可透過連線一次啟動一個 PDT 或匯總資料表的重建作業。Looker 管理員可以在連線設定中,使用「PDT 建構工具連線數量上限」欄位,調整再生器允許的並行重建數量。
- 由相同
datagroup觸發的所有 PDT 和匯總資料表,都會在同一個重新產生程序中重建。如果有多個資料表直接或因連鎖依附元件而使用資料群組,這可能會造成大量負載。
除了上述考量事項,在某些情況下,您也應避免將持續性新增至衍生資料表:
- 衍生資料表將擴充時:每擴充一次 PDT,資料庫中就會建立一份新的資料表副本。
- 衍生資料表使用範本化篩選器或 Liquid 參數時:衍生資料表使用範本化篩選器或 Liquid 參數時,不支援持續性。
- 如果從使用 使用者屬性的探索建立原生衍生資料表,且這些屬性使用
access_filters或sql_always_where,系統就會在資料庫中為每個可能的使用者屬性值建立資料表副本。 - 基礎資料經常變更,且資料庫方言不支援累加 PDT。
- 建立 PDT 的成本和時間過高。
視 Looker 連線中持續性資料表的數量和複雜度而定,佇列可能包含許多需要在每個週期檢查和重建的持續性資料表,因此在 Looker 執行個體中實作衍生資料表時,請務必考量這些因素。
使用 API 大規模管理 PDT
在執行個體上建立的 PDT 越多,監控及管理以不同時間表重新整理的 PDT 就越複雜。建議使用 Looker Apache Airflow 整合,一併管理 PDT 排程和其他 ETL 和 ELT 程序。
監控及排解 PDT 的相關問題
如果您使用持續衍生資料表 (PDT),尤其是連鎖 PDT,查看 PDT 的狀態會很有幫助。您可以使用 Looker 的「永久衍生資料表」管理員頁面,查看 PDT 的狀態。您也可以查看 PDT 疑難排解樹狀結構,逐步進行偵錯。
嘗試排解 PDT 問題時:
- 調查 PDT 事件記錄時,請特別注意開發資料表和正式版資料表之間的差異。
- 確認 Looker 連線的「暫存資料庫」設定與實際的暫存結構定義或資料庫相符。如果連線的「暫存資料庫」設定與資料庫的暫存結構定義不符,請更新「暫存資料庫」設定,讓 Looker 可以在資料庫中儲存永久衍生資料表。
- 判斷是所有 PDT 都有問題,還是只有一個。如果其中一個有問題,則問題很可能是由 LookML 或 SQL 錯誤所致。
- 判斷 PDT 的問題是否與排定重建的時間相符。
- 請確認所有
sql_trigger_value查詢都評估成功,且只傳回一個資料列和資料欄。如果是以 SQL 為基礎的 PDT,您可以在 SQL Runner 中執行 PDT,(套用LIMIT可避免查詢失控。) 如要進一步瞭解如何使用 SQL Runner 偵錯衍生資料表,請參閱使用 SQL Runner 測試衍生資料表 社群貼文。 - 如果是以 SQL 為基礎的 PDT,請使用 SQL Runner 驗證 PDT 的 SQL 是否能順利執行。(請務必在 SQL Runner 中套用
LIMIT,確保查詢時間合理)。 - 如果是以 SQL 為基礎的衍生資料表,請避免使用一般資料表運算式 (CTE)。使用 CTE 搭配 DT 會建立巢狀
WITH陳述式,導致 PDT 失敗,且不會顯示警告。請改用 CTE 的 SQL 建立次要 DT,並使用${derived_table_or_view_name.SQL_TABLE_NAME}語法從第一個 DT 參照該 DT。 - 檢查問題 PDT 所依附的任何資料表 (無論是正常資料表或 PDT 本身) 是否存在,以及是否可查詢。
- 確認問題 PDT 所依附的任何資料表都沒有共用或專屬鎖定。如要讓 Looker 順利建構 PDT,必須取得需要更新的資料表專屬鎖定。這會與資料表上的其他共用或專屬鎖定發生衝突。所有其他鎖定清除後,Looker 才能更新 PDT。如果 Looker 要從資料表建構 PDT,該資料表就不能有任何專屬鎖定。如果資料表有專屬鎖定,Looker 就無法取得共用鎖定來執行查詢,直到專屬鎖定清除為止。
- 使用 SQL Runner 中的「顯示程序」按鈕。如果作用中的程序數量眾多,可能會導致查詢時間變慢。
- 監控查詢中的留言。請參閱本頁的「查詢 PDT 的註解」一節。
查詢 PDT 的註解
資料庫管理員可以區分一般查詢和產生永久衍生資料表 (PDT) 的查詢。Looker 會在 CREATE TABLE ... AS SELECT ... 陳述式中加入註解,其中包含 PDT 的 LookML 模型和檢視區塊,以及 Looker 執行個體的專屬 ID (slug)。如果 PDT 是以開發模式代表使用者產生,註解會指出使用者的 ID。PDT 生成註解遵循以下模式:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
如果 Looker 必須為「探索」的查詢生成 PDT,則 PDT 生成註解會顯示在「探索」的 SQL 分頁中。註解會顯示在 SQL 陳述式頂端。
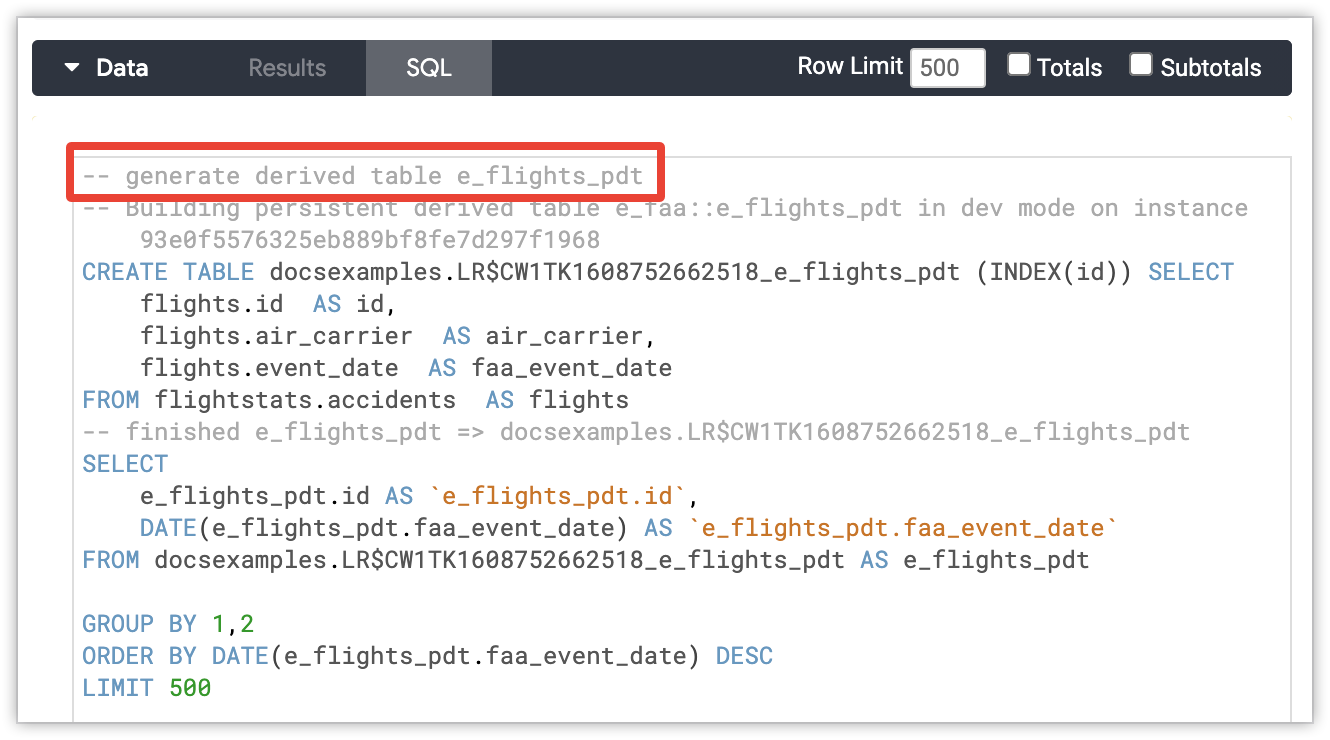
最後,在「查詢」管理頁面上,每個查詢的「查詢詳細資料」彈出式視窗的「資訊」分頁中,「訊息」欄位會顯示 PDT 生成註解。
在失敗後重建 PDT
如果永久衍生資料表 (PDT) 發生失敗,查詢該 PDT 時會發生下列情況:
- 如果先前執行過相同查詢,Looker 會使用快取中的結果。(如要瞭解運作方式,請參閱「快取查詢」說明文件頁面)。
- 如果快取中沒有結果,Looker 會從資料庫中的 PDT 提取結果 (如果 PDT 的有效版本存在)。
- 如果資料庫中沒有有效的 PDT,Looker 會嘗試重建 PDT。
- 如果無法重建 PDT,Looker 會針對查詢傳回錯誤。下次查詢 PDT 時,或下次 PDT 的持續策略觸發重建作業時,Looker 再生器會嘗試重建 PDT。
層疊 PDT 也是採用相同邏輯,但層疊 PDT 的不同之處在於:
- 如果無法為某個資料表建構 PDT,依附鏈中的 PDT 就無法建構。
- 從本質上來說,相依 PDT 會查詢所依附的 PDT,因此一個資料表的持續策略可能會觸發鏈結中上方 PDT 的重建作業。
回顧先前的層疊資料表範例,其中 TABLE_D 依附於 TABLE_C,而 TABLE_C 依附於 TABLE_B,TABLE_B 則依附於 TABLE_A:
如果 TABLE_B 發生失敗,所有標準 (非連鎖) 行為都會套用至 TABLE_B:
- 如果查詢
TABLE_B,Looker 會先嘗試使用快取傳回結果。 - 如果這次嘗試失敗,Looker 會盡可能使用舊版資料表。
- 如果這次嘗試也失敗,Looker 就會嘗試重建資料表。
- 最後,如果無法重建
TABLE_B,Looker 會傳回錯誤。
下次查詢資料表時,或資料表的持續性策略下次觸發重建作業時,Looker 會再次嘗試重建 TABLE_B。
TABLE_B 的依附元件也適用相同原則。因此,如果無法建構 TABLE_B,且 TABLE_C 上有查詢,就會發生下列情況:
- Looker 會嘗試使用
TABLE_C上的查詢快取。 - 如果快取中沒有結果,Looker 會嘗試從資料庫中的
TABLE_C擷取結果。 - 如果沒有有效的
TABLE_C版本,Looker 會嘗試重建TABLE_C,在TABLE_B上建立查詢。 - Looker 接著會嘗試重建
TABLE_B(如果TABLE_B尚未修正,就會失敗)。 - 如果無法重建
TABLE_B,TABLE_C就無法重建,因此 Looker 會針對TABLE_C上的查詢傳回錯誤。 - 接著,Looker 會嘗試根據一般持續性策略重建
TABLE_C,或在下次查詢 PDT 時重建 (包括下次TABLE_D嘗試建構時,因為TABLE_D依附於TABLE_C)。
解決 TABLE_B 的問題後,TABLE_B 和每個相依資料表都會嘗試根據其持續性策略重建,或在下次查詢時重建 (包括相依 PDT 下次嘗試重建時)。或者,如果以開發模式建構 PDT 級聯中的 PDT 開發版本,則開發版本可能會做為新的正式版 PDT。(如要瞭解運作方式,請參閱本頁的「開發模式中的持續性資料表」一節)。或者,您可以使用「探索」在 TABLE_D 上執行查詢,然後手動重新建立查詢的 PDT,這會強制重新建立依附元件層疊中的所有 PDT。
提升 PDT 效能
建立永久衍生資料表 (PDT) 時,效能可能會是個問題。特別是當資料表非常大時,查詢資料表的速度可能會很慢,就像查詢資料庫中任何大型資料表一樣。
您可以篩選資料,或控管 PDT 中資料的排序和索引方式,進而提升效能。
新增篩選器來限制資料集
如果資料集特別龐大,大量資料列會導致針對永久衍生資料表 (PDT) 執行的查詢變慢。如果您通常只查詢近期資料,請考慮在 PDT 的 WHERE 子句中新增篩選條件,將資料表限制為 90 天或更短時間內的資料。這樣一來,每次重建資料表時,系統只會加入相關資料,因此執行查詢的速度會快上許多。接著,您可以建立另一個較大的 PDT,用於歷史資料分析,這樣一來,您就能快速查詢近期資料,也能查詢舊資料。
使用 indexes 或 sortkeys 和 distribution
建立大型永久衍生資料表 (PDT) 時,為資料表建立索引 (適用於 MySQL 或 Postgres 等方言),或新增排序鍵和分配 (適用於 Redshift),有助於提升效能。
通常最好在 ID 或日期欄位中加入 indexes 參數。
如果是 Redshift,通常最好在 ID 或日期欄位中加入 sortkeys 參數,並在用於聯結的欄位中加入 distribution 參數。
有助於提升成效的建議設定
下列設定可控管永久衍生資料表 (PDT) 中的資料排序和建立索引方式。以下設定為選用項目,但強烈建議您進行設定:
- 如果是 Redshift 和 Aster,請使用
distribution參數指定資料欄名稱,系統會使用該資料欄的值將資料分散到叢集。當兩個資料表透過distribution參數中指定的資料欄彙整時,資料庫可以在同一個節點上找到彙整資料,因此節點間的 I/O 會降到最低。 - 如果是 Redshift,請將
distribution_style參數設為all,指示資料庫在每個節點上保留完整的資料副本。當相對較小的資料表聯結時,這通常用於盡量減少節點間的 I/O。將這個值設為even,即可指示資料庫在叢集中平均分配資料,而不使用分配資料欄。只有在未指定distribution時,才能指定這個值。 - 如果是 Redshift,請使用
sortkeys參數。這些值會指定 PDT 的哪些資料欄用於排序磁碟上的資料,方便搜尋。在 Redshift 上,你可以使用sortkeys或indexes,但不能同時使用兩者。 - 在大多數資料庫中,請使用
indexes參數。這些值會指定要為 PDT 的哪些資料欄建立索引。(在 Redshift 中,索引用於產生交錯排序鍵)。