衍生表格可帶來無盡的進階分析可能,但要著手、實作及排解問題可能令人望而生畏。這本食譜收錄了 Looker 中最常見的衍生資料表用途。
這個頁面包含下列範例:
- 每天凌晨 3 點建立資料表
- 將新資料附加至大型資料表
- 使用 SQL 視窗函式
- 建立衍生資料欄來計算值
- 最佳化策略
- 使用 PDT 測試最佳化
UNION兩個資料表- 計算總和的總和 (將指標維度化)
- 匯總表格,並匯總品牌認知度
衍生資料表資源
這些食譜假設您對 LookML 和衍生資料表有初步瞭解。您必須熟悉如何建立檢視畫面及編輯模型檔案。如要複習這些主題,請參閱下列資源:
每天凌晨 3 點建構資料表
在本範例中,資料會在每天凌晨 2 點傳入。無論是在凌晨 3 點或晚上 9 點執行查詢,這項資料的查詢結果都會相同。因此,建議您每天建構一次資料表,並讓使用者從快取中提取結果。
在模型檔案中加入資料群組,即可重複用於多個表格和探索。這個資料群組包含 sql_trigger_value 參數,可告知資料群組何時觸發及重建衍生資料表。
如需觸發運算式的更多範例,請參閱 sql_trigger_value 說明文件。
## in the model file
datagroup: standard_data_load {
sql_trigger_value: SELECT FLOOR(((TIMESTAMP_DIFF(CURRENT_TIMESTAMP(),'1970-01-01 00:00:00',SECOND)) - 60*60*3)/(60*60*24)) ;;
max_cache_age: "24 hours"
}
explore: orders {
…
在檢視檔案的 derived_table 定義中新增 datagroup_trigger 參數,並指定要使用的資料群組名稱。在本例中,資料群組為 standard_data_load。
view: orders {
derived_table: {
indexes: ["id"]
datagroup_trigger: standard_data_load
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
…
}
將新資料附加至大型資料表
累加 PDT 是指 Looker 將新資料附加至資料表,而非重建整個資料表,藉此建立的持續衍生資料表。
下一個範例以 orders 資料表範例為基礎,說明如何逐步建構資料表。每天都會有新的訂單資料,只要新增 increment_key 參數和 increment_offset 參數,即可將這些資料附加到現有資料表。
view: orders {
derived_table: {
indexes: ["id"]
increment_key: "created_at"
increment_offset: 3
datagroup_trigger: standard_data_load
distribution_style: all
sql:
SELECT
user_id,
id,
created_at,
status
FROM
demo_db.orders
GROUP BY
user_id ;;
}
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;; }
…
}
increment_key 值設為 created_at,也就是應查詢新資料並附加至 PDT 的時間增量。
increment_offset 值設為 3,可指定要重建多少個先前的時間週期 (以遞增鍵的精細度為準),以納入延遲抵達的資料。
使用 SQL 視窗函式
部分資料庫方言支援視窗函式,特別是建立序號、主鍵、執行和累計總和,以及其他實用的多列計算。主要查詢執行完畢後,系統會在另一個階段執行所有 derived_column 宣告。
如果資料庫方言支援窗型函式,您可以在原生衍生資料表中使用這些函式。建立含有視窗函式的 sql 參數,並將其做為 derived_column 參數。如要參照值,請使用原生衍生資料表中定義的資料欄名稱。
下列範例說明如何建立包含 user_id、order_id 和 created_time 資料欄的原生衍生資料表。接著,您可以使用 SQL ROW_NUMBER() 視窗函式搭配衍生資料欄,計算包含顧客訂單序號的資料欄。
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
建立衍生資料欄來計算值
您可以新增 derived_column 參數,指定 explore_source 參數的「探索」中不存在的資料欄。每個 derived_column 參數都有 sql 參數,用於指定值的建構方式。
sql 計算可使用您透過 column 參數指定的任何資料欄。衍生資料欄無法包含匯總函式,但可以包含可在資料表單一資料列執行的計算。
這個範例會建立 average_customer_order 資料欄,該資料欄是根據原生衍生資料表中的 lifetime_customer_value 和 lifetime_number_of_orders 資料欄計算而來。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: users.id
}
column: lifetime_number_of_orders {
field: order_items.count
}
column: lifetime_customer_value {
field: order_items.total_profit
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
最佳化策略
由於 PDT 儲存在資料庫中,因此您應使用下列策略 (方言支援的策略) 最佳化 PDT:
舉例來說,如要新增持續性,您可以設定在資料群組 orders_datagroup 觸發時重建 PDT,然後在 customer_id 和 first_order 上新增索引,如下所示:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
如果未新增索引 (或方言的對等項目),Looker 會發出警告,建議您新增索引來提升查詢效能。
使用 PDT 測試最佳化設定
您可以使用 PDT 測試不同的索引、發布和其他最佳化選項,不必尋求 DBA 或 ETL 開發人員的大量支援。
假設您有一個資料表,但想測試不同的索引。檢視區塊的初始 LookML 可能如下所示:
view: customer {
sql_table_name: warehouse.customer ;;
}
如要測試最佳化策略,可以使用 indexes 參數將索引新增至 LookML,如下所示:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
查詢檢視區塊一次,即可產生 PDT。接著執行測試查詢並比較結果。如果結果良好,您可以請 DBA 或 ETL 團隊將索引新增至原始資料表。
UNION 兩個資料表
如果 SQL 方言支援,您可以在兩個衍生資料表中執行 SQL UNION 或 UNION ALL 運算子。UNION 和 UNION ALL 運算子會合併兩個查詢的結果集。
以下範例顯示以 SQL 為基礎的衍生資料表,其中包含 UNION:
view: first_and_second_quarter_sales {
derived_table: {
sql:
SELECT * AS sales_records
FROM sales_records_first_quarter
UNION
SELECT * AS sales_records
FROM sales_records_second_quarter ;;
}
}
sql 參數中的 UNION 陳述式會產生衍生資料表,合併兩個查詢的結果。
UNION 和 UNION ALL 的差異在於,UNION ALL 不會移除重複的資料列。使用 UNION 與 UNION ALL 時,請留意效能考量,因為資料庫伺服器必須執行額外工作才能移除重複的資料列。
計算總和的總和 (將指標維度化)
根據 SQL 的一般規則 (以及 Looker 的延伸規則),您無法依據匯總函式的結果 (在 Looker 中以測量表示) 將查詢分組。您只能依未匯總的欄位 (在 Looker 中以維度表示) 分組。
如要依匯總分組 (例如計算總和的總和),您需要「維度化」指標。其中一種做法是使用衍生資料表,有效建立匯總的子查詢。
從「探索」開始,Looker 就能為所有或大部分的衍生資料表產生 LookML。只要建立探索,然後選取要納入衍生資料表的所有欄位,接著,如要產生原生 (或以 SQL 為基礎) 衍生資料表的 LookML,請按照下列步驟操作:
按一下「探索」的齒輪選單,然後選取「取得 LookML」。
如要查看建立該探索原生衍生資料表的 LookML,請按一下「衍生資料表」分頁標籤。
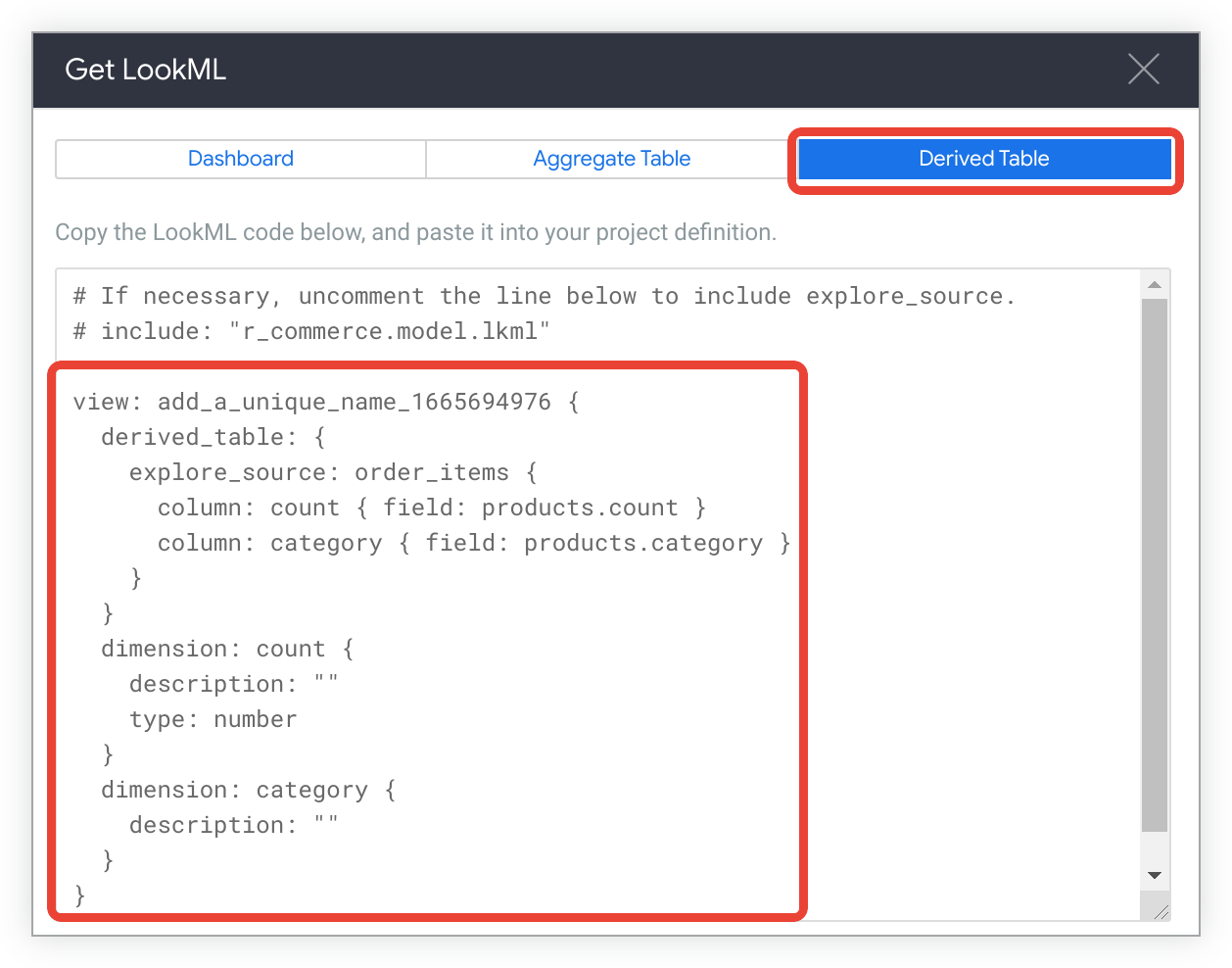
複製 LookML。
複製產生的 LookML 後,請按照下列步驟貼到檢視區塊檔案中:
在 Looker IDE 中,按一下專案檔案清單頂端的「+」,然後選取「建立檢視區塊」。如要在資料夾中建立檔案,請按一下資料夾選單,然後選取「建立檢視畫面」。
將檢視名稱設為有意義的名稱。
視需要變更資料欄名稱、指定衍生資料欄及新增篩選器。
匯總表格,瞭解整體曝光度
在 Looker 中,您可能會經常遇到非常大的資料集或資料表,為了確保效能,需要匯總資料表或匯總。
透過 Looker 的匯總感知功能,您可以預先建構各種精細程度、維度和匯總的匯總資料表,並告知 Looker 如何在現有探索中運用這些資料表。然後,在 Looker 認為適當的情況下,查詢會使用這些匯總資料表,不需要任何使用者輸入。這樣做可縮減查詢大小、減少等待時間,並提升使用者體驗。
以下是 Looker 模型中的簡易實作方式,可示範輕量型匯總感知功能。假設資料庫中有一個虛擬航班資料表,其中包含美國聯邦航空總署記錄的每趟航班,您可以在 Looker 中建立這個資料表的模型,並使用專屬的檢視區塊和探索。以下是可為「探索」定義的匯總資料表 LookML:
explore: flights {
aggregate_table: flights_by_week_and_carrier {
query: {
dimensions: [carrier, depart_week]
measures: [cancelled_count, count]
}
materialization: {
sql_trigger_value: SELECT CURRENT-DATE;;
}
}
}
有了這個匯總資料表,使用者就能查詢「探索」,而 Looker 會自動使用匯總資料表來回答查詢。flights如要詳細瞭解匯總認知度,請參閱匯總認知度教學課程。