Was ist BI Engine?
BigQuery BI Engine ist ein schneller In-Memory-Analysedienst, der viele SQL-Abfragen in BigQuery beschleunigt. Dazu werden die am häufigsten verwendeten Daten auf intelligente Weise im Cache gespeichert. BI Engine kann SQL-Abfragen von jeder Quelle beschleunigen, einschließlich solcher, die von Datenvisualisierungstools geschrieben wurden, und kann im Cache gespeicherte Tabellen für eine kontinuierliche Optimierung verwalten. So können Sie die Abfrageleistung ohne manuelle Feinabstimmung oder Data Tiering verbessern. Mithilfe von Clustering und Partitionierung können Sie die Leistung großer Tabellen mit BI Engine weiter optimieren.
Wenn Ihr Dashboard beispielsweise nur die Daten des letzten Quartals anzeigt, sollten Sie Ihre Tabellen nach Zeit partitionieren, sodass nur die neuesten Partitionen in den Speicher geladen werden. Sie können auch die Vorteile von materialisierten Ansichten und BI Engine kombinieren. Dies funktioniert besonders gut, wenn die materialisierten Ansichten verwendet werden, um Daten zu verknüpfen und zu vereinfachen, um ihre Struktur für BI Engine zu optimieren.
BI Engine bietet folgende Vorteile:
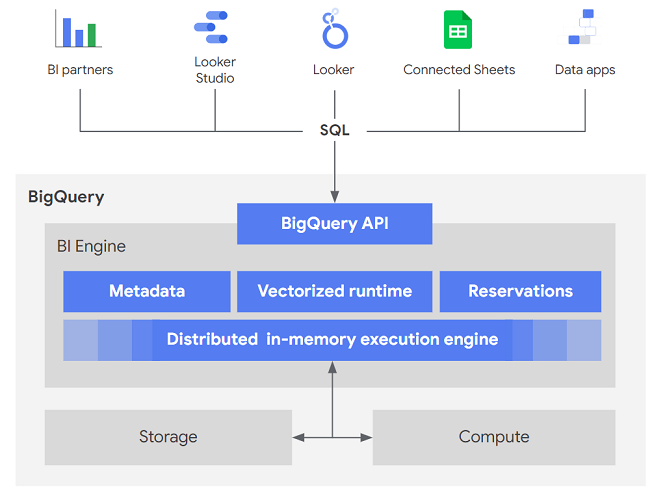
- BigQuery API: BI Engine ist direkt in die BigQuery API eingebunden. Jede BI-Lösung oder benutzerdefinierte Anwendung, die über Standardmechanismen wie REST oder JDBC- und ODBC-Treiber mit der BigQuery API arbeitet, kann BI Engine ohne Änderungen verwenden.
- Vektorisierte Laufzeit: Mit der BI Engine SQL-Schnittstelle führt BI Engine eine modernere Technik namens vektorisierte Verarbeitung ein. Die Verwendung der vektorisierten Verarbeitung in einer Ausführungs-Engine ermöglicht eine effizientere Nutzung der modernen CPU-Architektur, da immer mehrere Datenbatches ausgeführt werden. BI Engine verwendet auch erweiterte Datencodierungen, insbesondere die Ausführungslänge des Wörterbuchs, um die in der speicherinternen Ebene gespeicherten Daten weiter zu komprimieren.
- Nahtlose Integration: BI Engine funktioniert mit BigQuery-Features und -Metadaten, einschließlich autorisierter Ansichten, Spaltensicherheit sowie Datenmaskierung.
- Reservierungen: BI Engine-Reservierungen verwalten die Speicherzuweisung auf Projektebene. BI Engine speichert bestimmte Spalten oder Partitionen im Cache, die abgefragt werden, wobei diejenigen in Tabellen priorisiert werden, die als bevorzugt markiert werden.
Informationen zur SQL-Schnittstelle in BI Engine
Die BI Engine SQL-Schnittstelle erweitert die BI Engine zur Einbindung in andere Business Intelligence-Tools (BI) wie Looker, Tableau, Power BI und benutzerdefinierte Anwendungen, um die Datenexploration und -analyse zu beschleunigen. Diese Seite bietet einen Überblick über die BI Engine SQL-Schnittstelle und die erweiterten Möglichkeiten, die sie der BI Engine bietet.
BI Engine-Anwendungsfälle
BI Engine kann viele SQL-Abfragen erheblich beschleunigen, einschließlich solcher, die für BI-Dashboards verwendet werden. Beschleunigen ist am effektivsten, wenn Sie die Tabellen ermitteln, die für Ihre Abfragen wichtig sind, und diese dann als bevorzugte Tabellen markieren. Erstellen Sie zur Verwendung von BI Engine eine Reservierung, die die für BI Engine vorgesehene Speicherkapazität definiert. Sie können BigQuery anhand der Nutzungsmuster des Projekts festlegen lassen, welche Tabellen im Cache gespeichert werden, oder bestimmte Tabellen markieren, um zu verhindern, dass anderer Traffic die Beschleunigung stört.
BI Engine ist in folgenden Anwendungsfällen nützlich:
- Verwenden Sie BI-Tools zum Analysieren Ihrer Daten: Die BI Engine SQL-Schnittstelle kann BigQuery-Abfragen beschleunigen, unabhängig davon, ob sie in der BigQuery-Konsole, der Clientbibliothek oder über eine API oder einen ODBC- oder JDBC-Connector ausgeführt werden. Dies kann die Leistung von Dashboards, die über eine integrierte Verbindung (API) oder Connectors verbunden sind, erheblich verbessern.
- Sie haben bestimmte Tabellen, die am häufigsten abgefragt werden: Mit BI Engine können Sie bestimmte bevorzugte Tabellen beschleunigen. Dies ist hilfreich, wenn Sie eine Teilmenge von Tabellen haben, die häufiger abgefragt oder für Dashboards mit hoher Sichtbarkeit verwendet werden.
BI Engine erfüllt in den folgenden Fällen möglicherweise nicht Ihre Anforderungen:
Sie verwenden in Ihren Abfragen Platzhalter: Abfragen, die auf Platzhaltertabellen verweisen, werden von BI Engine nicht unterstützt und profitieren nicht von einer Beschleunigung.
Sie verlassen sich stark auf BigQuery-Features, die von BI Engine nicht unterstützt werden. BI Engine unterstützt die meistenSQL-Funktionen und Operatoren wenn Sie BI-Tools (Business Intelligence) mit BigQuery verbinden, es gibtnicht unterstützte Features, einschließlich externer Tabellen und benutzerdefinierter Nicht-SQL-Funktionen.
Überlegungen zu BI Engine
Berücksichtigen Sie bei der Konfiguration von BI Engine Folgendes:
Für bestimmte Abfragen beschleunigen
Sie können dafür sorgen, dass ein bestimmter Satz von Abfragen immer beschleunigt wird, indem Sie ein separates Projekt mit einer BI Engine-Reservierung erstellen. Dazu müssen Sie dafür sorgen, dass die BI Engine-Reservierung in diesem Projekt groß genug ist, um die Größe aller in diesen Abfragen verwendeten Tabellen zu erfüllen, und diese Tabellen als bevorzugte Tabellen für BI Engine festlegen. In diesem Projekt sollten nur die Abfragen ausgeführt werden, die beschleunigt werden müssen.
Joins minimieren
BI Engine funktioniert am besten mit vorab verknüpften oder vorab aggregierten Daten und mit Daten in einer kleinen Anzahl von Joins. Dies gilt insbesondere, wenn eine Seite des Join groß ist und die anderen wesentlich kleiner sind, z. B. wenn Sie eine große Faktentabelle abfragen, die mit einer kleinen Dimensionstabelle verknüpft ist. Sie können BI Engine mit materialisierten Ansichten kombinieren, die Joins ausführen, um eine einzelne große, flache Tabelle zu erzeugen. Auf diese Weise müssen nicht für jede Abfrage dieselben Joins ausgeführt werden.
Auswirkungen von BI Engine verstehen
Informationen zur Nutzung von BI Engine finden Sie unter BI Engine mit Cloud Monitoring überwachen oder durch Abfragen der Ansichten INFORMATION_SCHEMA.BI_CAPACITIES und INFORMATION_SCHEMA.BI_CAPACITY_CHANGES. Deaktivieren Sie die Option Im Cache gespeicherte Ergebnisse verwenden in BigQuery, um einen möglichst genauen Vergleich zu erhalten. Weitere Informationen finden Sie unter Im Cache gespeicherte Abfrageergebnisse verwenden.
Bevorzugte Tabellen
Mit bevorzugten BI Engine-Tabellen können Sie die BI Engine-Beschleunigung auf eine bestimmte Gruppe von Tabellen beschränken. Abfragen von allen anderen Tabellen verwenden reguläre BigQuery-Slots. Mit bevorzugten Tabellen können Sie beispielsweise nur die Tabellen und Dashboards beschleunigen, die Sie für Ihr Unternehmen als wichtig eingestuft haben.
Wenn im Projekt nicht genügend RAM vorhanden ist, um alle bevorzugten Tabellen zu speichern, lagert BI Engine Partitionen und Spalten aus, auf die in letzter Zeit nicht zugegriffen wurde. Durch diesen Prozess wird Arbeits-Speicher für neue Abfragen freigegeben, die beschleunigt werden müssen.
Einschränkungen für bevorzugte Tabellen
Für bevorzugte BI Engine-Tabellen gelten folgende Einschränkungen:
- Sie können keine Ansichten in der Liste der bevorzugten Tabellenreservierung hinzufügen. Bevorzugte BI Engine-Tabellen unterstützen nur Tabellen.
- Abfragen von materialisierte Ansichten werden nur beschleunigt, wenn sich sowohl die materialisierten Ansichten als auch ihre Basistabellen in der Liste der bevorzugten Tabellen befinden.
- Die Angabe von Partitionen oder Spalten zur Beschleunigung wird nicht unterstützt.
- Spalten vom Typ
JSONwerden nicht unterstützt und von BI Engine nicht beschleunigt. - Abfragen, die auf mehrere Tabellen zugreifen, werden nur beschleunigt, wenn alle Tabellen bevorzugte Tabellen sind. Beispielsweise müssen sich alle Tabellen in einer Abfrage mit einer
JOINin der Liste der bevorzugten Tabellen befinden, damit sie beschleunigt werden. Wenn nur eine Tabelle nicht in der bevorzugten Liste enthalten ist, kann die Abfrage nicht BI Engine verwenden. - Öffentliche Datasets werden in der Google Cloud Console nicht unterstützt. Verwenden Sie die API oder die DDL, um eine öffentliche Tabelle als bevorzugte Tabelle hinzuzufügen.
Kontingente und Limits
Informationen zu Kontingenten und Limits für BI Engine finden Sie unter BigQuery-Kontingente und -Limits.
Preise
Informationen zur BI Engine-Preisgestaltung finden Sie auf der Seite BigQuery Preisgestaltung.
Nächste Schritte
- Informationen zum Erstellen Ihrer BI Engine-Reservierung finden Sie unter BI Engine-Kapazität reservieren.
- Informationen zum Festlegen bevorzugter Tabellen finden Sie unter Bevorzugte BI Engine-Tabellen.
- Informationen zur Nutzung von BI Engine finden Sie unter BI Engine mit Cloud Monitoring überwachen.
- Informationen zu BI Engine-optimierten Funktionen
- Erfahren Sie, wie Sie BI Engine mit Folgendem verwenden: