O rastreador de consultas do recurso "Analisar detalhadamente" e o painel Performance do recurso "Analisar detalhadamente" fornecem dados de desempenho detalhados para uma consulta de análise detalhada. Esses dados podem ajudar a identificar os principais pontos de entrada para resolver problemas de desempenho com consultas e fornecer recomendações de melhorias.
Analisar o rastreador de consultas
O rastreador de consultas do recurso Detalhar mostra o progresso de uma consulta do recurso nas três fases da consulta enquanto ela está em execução.
![]()
Se uma consulta estiver demorando muito para ser executada, o rastreador de consultas poderá indicar qual fase está causando o problema de desempenho. Isso é útil para identificar onde podem ocorrer problemas de desempenho e onde os esforços de otimização podem ser mais eficazes.
O rastreador de consultas é exibido quando uma análise detalhada está em execução, desde que o painel Visualização da análise detalhada ou o painel Dados da análise detalhada esteja aberto.
Conheça o painel Performance
Para acessar o painel Performance do recurso Detalhar, clique no link Ver detalhes de performance, disponível em qualquer consulta do recurso Detalhar que foi executada.

O painel Performance mostra o tempo que a consulta passou em cada uma das três fases de consulta e inclui links para a documentação de desempenho e o painel de atividades do sistema Histórico de consultas, que mostra dados de desempenho atuais e históricos da consulta e da análise detalhada usada para criar a consulta.
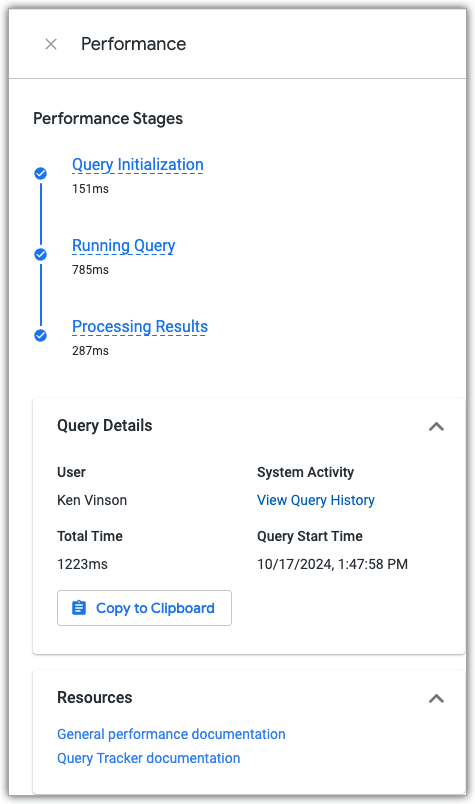
Fases da consulta
Quando uma Análise do Looker executa uma consulta de banco de dados, ela é executada em três fases:
- A fase de inicialização da consulta
- A fase de execução da consulta
- A fase de resultados do processamento
Fase de inicialização da consulta
Durante a fase de inicialização da consulta, o Looker executa todas as tarefas necessárias antes do envio da consulta ao seu banco de dados. A fase de inicialização da consulta inclui as seguintes tarefas:
- Compilar o modelo do LookML
- Verificar se alguma tabela derivada persistente (PDT) precisa ser criada
- Gerar o SQL de consulta
- Adquirir a conexão de banco de dados
A página de documentação Entender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas em Atividade do sistema para ver detalhamentos de uma consulta. A fase de Inicialização da consulta do rastreador de consultas inclui os eventos descritos nas fases de Trabalhador assíncrono, Inicialização e Processamento de conexão da análise detalhada Métricas de performance de consulta.
Fase de execução da consulta
Na fase Execução da consulta, o Looker entra em contato com o banco de dados, faz consultas e retorna os resultados. Problemas de desempenho durante essa fase podem indicar um problema com o banco de dados externo, como PDTs que levam muito tempo para serem reconstruídas e podem precisar de otimização, ou tabelas de banco de dados externo que podem precisar de otimização. A fase Consulta em execução inclui as seguintes tarefas:
- Criar todas as PDTs no banco de dados necessárias para a consulta do Explorar
- Executar a consulta solicitada no banco de dados
A página de documentação Entender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas em Atividade do sistema para ver detalhamentos de uma consulta. A fase Consulta em execução do rastreador de consultas inclui os eventos descritos na fase de consultas principais da análise detalhada Métricas de performance de consultas.
As possíveis etapas a serem seguidas se você tiver problemas de desempenho durante essa fase incluem:
- Crie análises detalhadas usando junções
many_to_onesempre que possível. Unir visualizações do nível mais granular ao mais alto de detalhes (many_to_one) geralmente oferece a melhor performance de consulta. - Maximize o armazenamento em cache para sincronizar com suas políticas de ETL sempre que possível e reduzir o tráfego de consultas do banco de dados. Por padrão, o Looker armazena consultas em cache por uma hora. É possível controlar a política de cache e sincronizar as atualizações de dados do Looker com seu processo de ETL aplicando grupos de dados nas análises detalhadas usando o parâmetro
persist_with. Ao maximizar o armazenamento em cache, o Looker se integra melhor ao pipeline de dados de back-end. Assim, o uso do cache pode ser maximizado sem o risco de analisar dados desatualizados. As políticas de cache nomeadas podem ser aplicadas a um modelo inteiro ou a análises detalhadas e tabelas derivadas permanentes (PDTs) individuais. - Use o recurso reconhecimento de agregação do Looker para criar tabelas de resumo ou consolidadas que o Looker possa usar para consultas sempre que possível, especialmente para consultas comuns de bancos de dados grandes. Também é possível usar o reconhecimento de agregação para melhorar drasticamente o desempenho de painéis inteiros. Consulte o tutorial sobre agregação de reconhecimento para mais informações.
- Use PDTs para consultas mais rápidas. Converta as análises detalhadas com muitas junções complexas ou de baixo desempenho ou dimensões com subconsultas ou subseleções em PDTs para que as visualizações sejam pré-combinadas e fiquem prontas antes da execução.
- Se o dialeto do banco de dados for compatível com PDTs incrementais, configure PDTs incrementais para reduzir o tempo que o Looker leva para recriar tabelas de PDTs.
- Evite mesclar visualizações em análises detalhadas com chaves primárias concatenadas definidas no Looker. Em vez disso, faça a junção nos campos básicos que compõem a chave primária concatenada da visualização. Como alternativa, recrie a visualização como uma PDT com a chave primária concatenada predefinida na definição SQL da tabela, em vez de em uma LookML de visualização.
- Use a ferramenta "Explicar no SQL Runner" para fazer comparativos de mercado.
EXPLAINproduz uma visão geral do plano de execução de consultas do seu banco de dados para uma determinada consulta SQL, permitindo detectar componentes de consulta que podem ser otimizados. Saiba mais na postagem da Comunidade Como otimizar o SQL comEXPLAIN. - Declare os índices. Para conferir os índices de cada tabela diretamente no Looker pelo SQL Runner, clique no ícone de engrenagem em uma tabela e selecione Mostrar índices.
As colunas mais comuns que podem se beneficiar de índices são datas importantes e chaves estrangeiras. Adicionar índices a essas colunas vai aumentar o desempenho de quase todas as consultas. Isso também se aplica às PDTs. Os parâmetros do LookML, como
indexes,sort keysedistribution, podem ser aplicados adequadamente.
Fase de processamento de resultados
Durante a fase de Processamento de resultados, o Looker processa e renderiza os resultados da consulta. A fase de Resultados do processamento inclui as seguintes tarefas:
- Streaming de resultados de consulta para o cache
- Como resolver cálculos de tabela
- Como formatar os resultados da linguagem de modelo Liquid
- Como mesclar consultas
- Cálculo de totais e subtotais
A página de documentação Entender as métricas de desempenho de consultas descreve como usar a análise detalhada Métricas de desempenho de consultas em Atividade do sistema para ver detalhamentos de uma consulta. A fase Processando resultados do rastreador de consultas inclui os eventos descritos na Fase pós-consulta da análise detalhada Métricas de performance de consulta.
Possíveis etapas a serem seguidas se você tiver problemas de desempenho durante essa fase:
- Use recursos como mesclar resultados, campos personalizados e cálculos de tabela com moderação. Esses recursos devem ser usados como provas de conceito para ajudar a projetar seu modelo. A prática recomendada é codificar cálculos e funções usados com frequência em LookML, o que vai gerar SQL para ser processado no seu banco de dados. Cálculos excessivos podem competir pela memória Java na instância do Looker, fazendo com que ela responda mais lentamente.
- Limite o número de visualizações incluídas em um modelo quando houver muitos arquivos de visualização. Incluir todas as visualizações em um único modelo pode prejudicar o desempenho. Quando um grande número de visualizações está presente em um projeto, considere incluir apenas os arquivos de visualização necessários em cada modelo. Use convenções de nomenclatura estratégicas para os nomes dos arquivos de visualização e inclua grupos de visualizações em um modelo. Um exemplo é descrito na documentação do parâmetro
includes. - Evite retornar um grande número de pontos de dados por padrão nos blocos do painel e nas análises. Consultas que retornam milhares de pontos de dados consomem mais memória. Sempre que possível, limite os dados aplicando
filtros de front-end a painéis, Looks e Análises, além de parâmetros
required filters,conditionally_filteresql_always_whereno nível da LookML. - Baixe ou entregue consultas usando a opção Todos os resultados com moderação, já que algumas consultas podem ser muito grandes e sobrecarregar o servidor do Looker quando são processadas.