探索查詢追蹤工具和「探索」效能面板會提供探索查詢的逐步效能資料。這項資料有助於找出疑難排解的主要切入點,並解決查詢效能問題,以及提供改善建議。
探索查詢追蹤器
查詢執行時,Explore 查詢追蹤工具會顯示查詢的進度,包括查詢的三個階段。
![]()
如果查詢執行時間過長,查詢追蹤器可以指出查詢的哪個階段導致效能問題。這有助於找出可能發生效能問題的地方,以及最能有效提升效能的方面。
只要開啟「探索」視覺化面板或「探索」資料面板,執行探索時就會顯示查詢追蹤器。
探索「效能」面板
如要查看「探索」成效面板,請按一下「查看成效詳情」連結,這個連結會顯示在所有已執行的「探索」查詢中。

「效能」面板會顯示查詢在三個查詢階段中花費的時間,並提供效能說明文件和「查詢記錄」系統活動資訊主頁的連結,其中會顯示查詢和用於建立查詢的探索的目前和歷來效能資料。
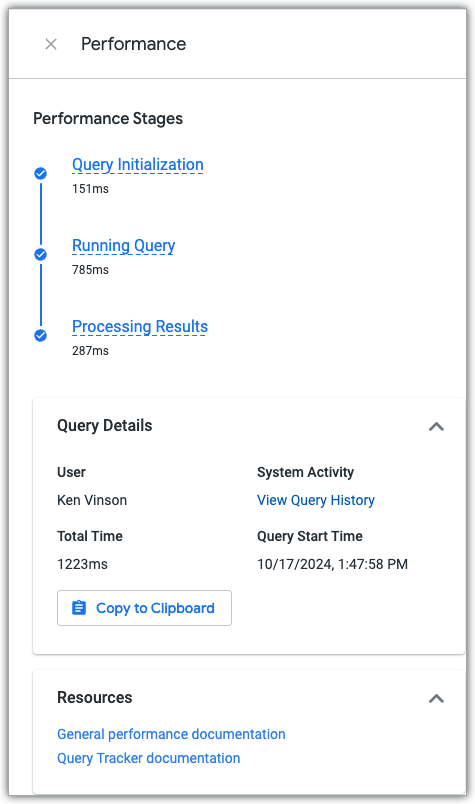
查詢階段
當 Looker 探索執行資料庫查詢時,查詢會依序經過下列三個階段:
查詢初始化階段
在「查詢初始化」階段,Looker 會先執行所有必要工作,再將查詢傳送至資料庫。「查詢初始化」階段包含下列工作:
- 編譯 LookML 模型
- 檢查是否需要建構任何持續衍生資料表 (PDT)
- 生成查詢 SQL
- 取得資料庫連線
「瞭解查詢效能指標」說明文件頁面說明如何使用「查詢效能指標」探索功能,在「系統活動」中查看查詢的詳細細目。查詢追蹤器的「查詢初始化」階段包含「查詢效能指標」探索中的「非同步工作階段」、「初始化階段」和「連線處理階段」所述事件。
執行查詢階段
在「執行查詢」階段,Looker 會連線至資料庫並進行查詢,然後傳回查詢結果。如果這個階段發生效能問題,可能表示外部資料庫有問題,例如 PDT 重建時間過長,可能需要最佳化,或是外部資料庫表格可能需要最佳化。「執行查詢」階段包含下列工作:
- 在資料庫中建構探索查詢所需的任何 PDT
- 在資料庫上執行要求的查詢
「瞭解查詢效能指標」說明文件頁面說明如何使用「查詢效能指標」探索功能,在「系統活動」中查看查詢的詳細細目。查詢追蹤器的「執行查詢」階段包含「查詢成效指標」探索中「主要查詢」階段所述的事件。
如果在這個階段遇到效能問題,可以採取下列步驟:
- 盡可能使用
many_to_one聯結來建構探索。從最細微的層級到最高詳細程度 (many_to_one) 聯結檢視畫面,通常可提供最佳查詢效能。 - 盡可能將快取功能發揮到極致,與 ETL 政策同步,減少資料庫查詢流量。根據預設,Looker 會將查詢結果快取一小時。您可以在「探索」中套用 datagroup,並使用
persist_with參數,控管快取政策及將 Looker 資料重新整理作業與 ETL 程序同步。盡量使用快取可讓 Looker 更緊密地整合後端資料管道,因此可盡量使用快取,不必擔心分析過時資料。具名快取政策可套用至整個模型,或個別的探索和持續衍生資料表 (PDT)。 - 盡可能使用 Looker 的匯總認知功能建立匯總或摘要表格,供 Looker 查詢使用,特別是大型資料庫的常見查詢。您也可以使用匯總認知度,大幅提升整個資訊主頁的成效。詳情請參閱匯總意識教學課程。
- 使用 PDT 加快查詢速度。將含有許多複雜或效能不佳的聯結,或是含有子查詢或子選取的維度,轉換為 PDT,以便在執行階段前預先聯結並準備好檢視。
- 如果資料庫方言支援增量 PDT,請設定增量 PDT,縮短 Looker 重建 PDT 資料表的時間。
- 請避免將檢視區塊彙整至 Looker 中定義的串連主鍵。請改為在構成檢視區塊中串連主鍵的基礎欄位上進行聯結。或者,您也可以將檢視區塊重新建立為 PDT,並在資料表的 SQL 定義中預先定義串連的主鍵,而不是在檢視區塊的 LookML 中定義。
- 使用「在 SQL Runner 中說明」工具進行基準化。
EXPLAIN會針對指定的 SQL 查詢,產生資料庫查詢執行計畫的總覽,方便您偵測可最佳化的查詢元件。詳情請參閱「如何使用EXPLAIN最佳化 SQL」社群貼文。 - 宣告索引。如要直接在 Looker 中查看每個資料表的索引,請前往 SQL Runner,按一下資料表中的齒輪圖示,然後選取「Show Indexes」。
索引最常使用的資料欄是重要日期和外鍵。為這些資料欄新增索引,幾乎所有查詢的效能都會提升。這也適用於 PDT。您可以適當套用 LookML 參數,例如
indexes、sort keys和distribution。
處理結果階段
在「處理結果」階段,Looker 會處理及呈現查詢結果。「處理結果」階段包含下列工作:
- 將查詢結果串流至快取
- 解決資料表計算問題
- 設定 Liquid 範本語言的結果格式
- 合併查詢
- 計算總計和小計
「瞭解查詢效能指標」說明文件頁面說明如何使用「查詢效能指標」探索功能,在「系統活動」中查看查詢的詳細細目。查詢追蹤器的「處理結果」階段包含「查詢成效指標」探索中的「查詢後階段」所述事件。
如果在這個階段遇到效能問題,可以採取下列步驟:
- 請盡量少用合併結果、自訂欄位和資料表計算等功能。這些功能僅供概念驗證,協助您設計模型。 最佳做法是在 LookML 中硬式編碼任何常用計算和函式,這會產生要在資料庫中處理的 SQL。過多的計算可能會與 Looker 執行個體上的 Java 記憶體競爭,導致 Looker 執行個體的回應速度變慢。
- 如果檢視區塊檔案數量龐大,請限制模型中包含的檢視區塊數量。在單一模型中納入所有檢視畫面可能會導致效能變慢。如果專案中存在大量檢視區塊,請考慮只在每個模型中加入所需的檢視區塊檔案。建議為檢視畫面檔案名稱採用策略性命名慣例,以便在模型中納入檢視畫面群組。如需範例,請參閱
includes參數說明文件。 - 請避免在資訊主頁動態磚和 Look 中,預設傳回大量資料點。傳回數千個資料點的查詢會耗用更多記憶體。盡可能在前端對資訊主頁、Look 和 Explore 套用
篩選器,並在 LookML 層級使用
required filters、conditionally_filter和sql_always_where參數,確保資料受到限制。 - 請盡量不要使用「所有結果」選項下載或傳送查詢,因為部分查詢可能非常龐大,處理時會對 Looker 伺服器造成負擔。