Cette page définit les termes et concepts de base suivants, que vous rencontrerez probablement souvent lors du développement LookML :
- Projets LookML
- Principales structures LookML (comme les modèles, les vues et les explorations)
- Tables dérivées
- Connexions à la base de données
- Sensibilité à la casse
Les Looks et les tableaux de bord définis par l'utilisateur ne sont pas décrits sur cette page, car les utilisateurs les créent sans utiliser LookML. En revanche, leurs requêtes reposent sur les éléments LookML sous-jacents abordés sur cette page.
Pour consulter la liste complète des termes et de leurs définitions utilisés dans Looker, consultez le glossaire Looker. Pour obtenir un aperçu complet des paramètres LookML que vous pouvez utiliser dans un projet LookML, consultez la page Référence rapide de LookML.
Pour en savoir plus sur les différences entre les termes et concepts similaires dans Looker et Looker Studio, consultez la page de documentation Termes et concepts communs à Looker et Looker Studio.
projet LookML
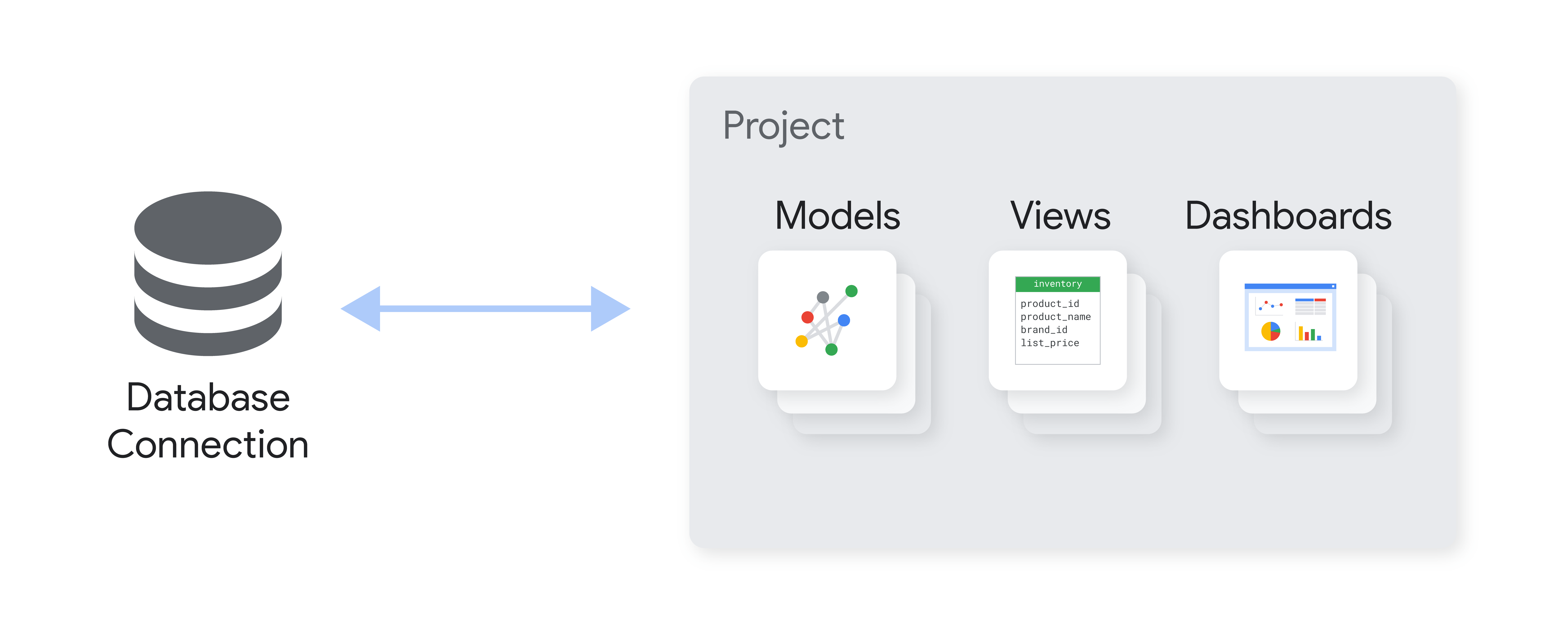
Dans Looker, un projet est un ensemble de fichiers qui décrivent les objets, les connexions de base de données et les éléments d'interface utilisateur qui seront utilisés pour exécuter des requêtes SQL. Au niveau le plus élémentaire, ces fichiers décrivent les relations entre les tables de votre base de données et indiquent comment Looker doit les interpréter. Les fichiers peuvent également inclure des paramètres LookML qui définissent ou modifient les options présentées dans l'UI de Looker. Chaque projet LookML se trouve dans son propre dépôt Git pour le contrôle des versions.
Une fois que vous avez connecté Looker à votre base de données, vous pouvez spécifier la connexion à utiliser pour votre projet Looker.
Vous pouvez accéder à vos projets depuis le menu Développer de Looker (pour en savoir plus et découvrir d'autres options, consultez Accéder aux fichiers de projet).

Pour savoir comment créer un projet, consultez la page de documentation Générer un modèle. Pour savoir comment accéder à des projets LookML existants et les modifier, consultez la page de documentation Accéder aux informations sur un projet et les modifier.
Composantes d'un projet
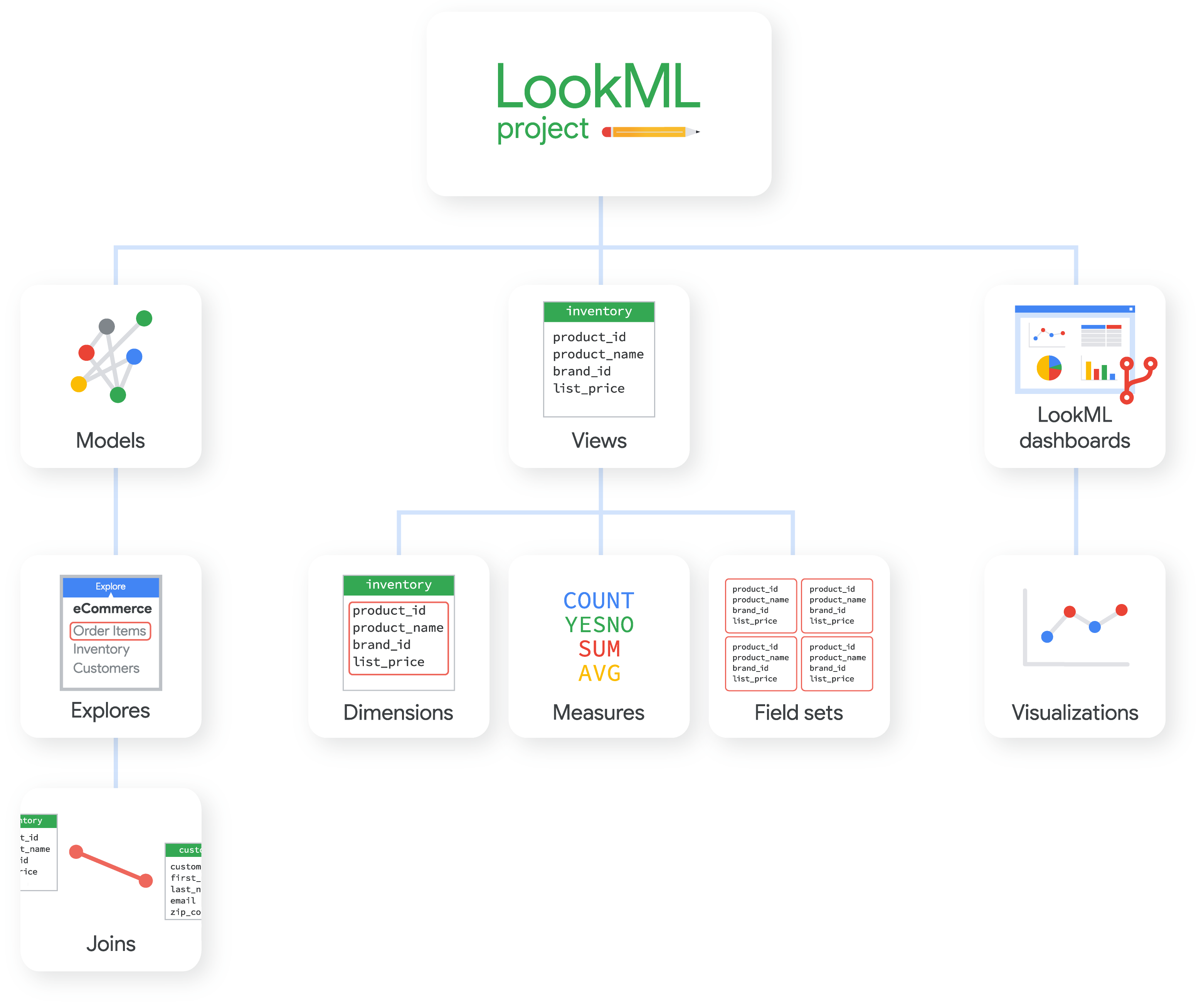
Comme le montre le schéma, voici quelques-uns des types de fichiers les plus courants dans un projet LookML :
- Un modèle contient des informations sur les tables à utiliser et la manière de les joindre. En principe, c'est à ce niveau que vous définissez le modèle, ses explorations et ses jointures.
- Une vue contient des informations sur la façon d'accéder aux données de chaque table (ou de plusieurs tables jointes) ou de les calculer. C'est généralement à ce niveau que vous définissez la vue, ses dimensions, ses mesures et ses ensembles de champs.
- Une exploration est souvent définie dans un fichier de modèle, mais vous avez parfois besoin d'un fichier d'exploration distinct pour une table dérivée ou pour étendre ou affiner une exploration dans plusieurs modèles.
- Un fichier manifeste peut contenir des instructions pour utiliser les fichiers importés d'un autre projet ou pour les paramètres de localisation de votre projet.
En plus des fichiers de modèle, de vue, Explore et manifeste, un projet peut comporter d'autres types de fichiers liés, par exemple, aux tableaux de bord intégrés, à la documentation, à la localisation, etc. Pour en savoir plus sur ces types de fichiers et sur les autres types de fichiers que vous pouvez inclure dans votre projet LookML, consultez la page de documentation sur les fichiers de projets LookML.
Ces fichiers constituent un projet. Si vous utilisez Git pour le contrôle des versions, chaque projet est généralement sauvegardé par son propre dépôt Git.
Origine des projets et fichiers LookML
La méthode la plus courante pour créer des fichiers LookML consiste à générer un projet LookML à partir de votre base de données. Vous pouvez également créer un projet vide et créer manuellement ses fichiers LookML.
Lorsque vous créez un nouveau projet depuis votre base de données, Looker crée un jeu de fichiers de référence que vous pouvez utiliser comme modèle pour composer le projet :
- Plusieurs fichiers view, à raison d'un fichier par table de la base de données.
- Un fichier modèle. Ce fichier déclare une exploration par vue. Chaque déclaration d'exploration comporte une logique
joinpour joindre une vue que Looker peut identifier comme étant liée à l'exploration.
À ce stade, vous pouvez personnaliser le projet en retirant les vues et explorations inutiles et en ajoutant des dimensions et mesures personnalisées.
Principales structures LookML
Comme illustré dans le diagramme des composants d'un projet, un projet se compose généralement d'un ou de plusieurs fichiers de modèle, qui contiennent des paramètres définissant un modèle, ses explorations et ses jointures. En outre, les projets comportent généralement un ou plusieurs fichiers de vue, contenant chacun des paramètres qui définissent la vue, ses champs (y compris les dimensions et les mesures) et des jeux de champs. Il peut également comporter un fichier manifeste de projet, qui vous permet de configurer les paramètres au niveau du projet. Cette section décrit ces principales structures.
Modèle
Un modèle est un portail personnalisé à l'intérieur de la base de données, conçu pour permettre une exploration intuitive des données par des utilisateurs métier spécifiques. Une même connexion de base de données d'un projet LookML peut comporter plusieurs modèles, chacun d'eux pouvant présenter des données différentes d'un utilisateur à l'autre. Par exemple, les commerciaux n'ont pas besoin des mêmes données que les dirigeants de l'entreprise, et vous devrez probablement développer deux modèles pour présenter des vues de la base de données adaptées à chaque utilisateur.
Un modèle spécifie une connexion à une seule base de données. Un développeur définit également les explorations d'un modèle dans le fichier de modèle. Par défaut, les explorations sont organisées sous le nom du modèle dans lequel elles sont définies. Vos utilisateurs voient les modèles répertoriés dans le menu Explorer.
Pour en savoir plus sur les fichiers de modèle, y compris sur leur structure et leur syntaxe générale, consultez la page de documentation Types de fichiers dans un projet LookML.
Consultez la page de documentation Paramètres du modèle pour en savoir plus sur les paramètres LookML qui peuvent être utilisés dans un fichier de modèle.
Afficher
Une déclaration de vue définit une liste de champs (dimensions ou mesures) et leur liaison avec une table sous-jacente ou dérivée. Dans LookML, les vues renvoient généralement à une table de base de données sous-jacente, mais peuvent aussi représenter une table dérivée.
Une vue peut être jointe à d'autres vues. La relation entre les vues est habituellement définie dans le cadre d'une déclaration d'exploration, dans un fichier de modèle.
Par défaut, les noms des vues sont affichés devant ceux des dimensions et des mesures de la table de données Explorer. ce qui permet de voir immédiatement à quelle vue un champ appartient : Dans l'exemple suivant, les noms de vues Orders et Users sont listés avant les noms des champs dans le tableau de données :
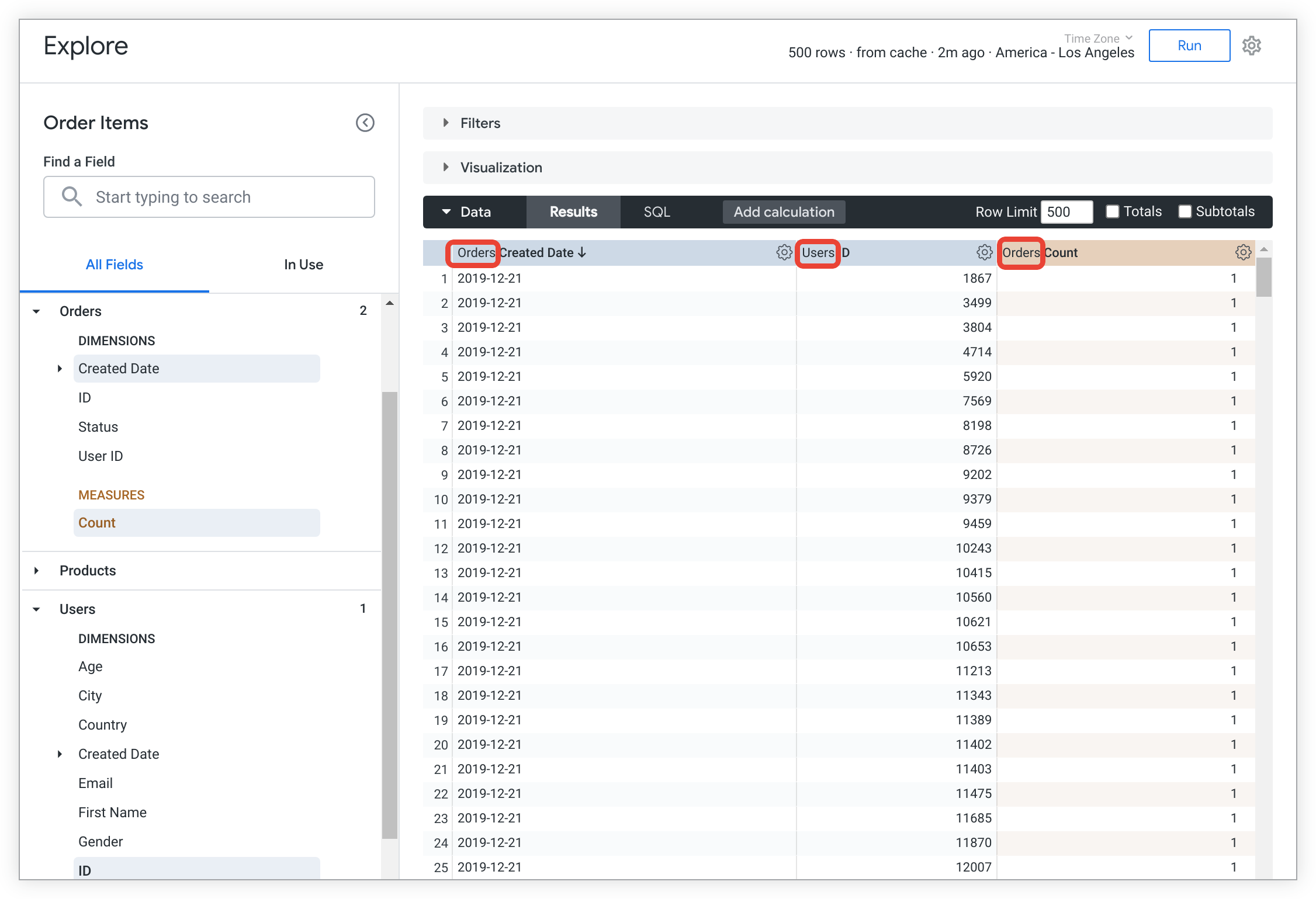
Pour en savoir plus sur les fichiers de vue, y compris sur leur structure et leur syntaxe générale, consultez la documentation Types de fichiers dans un projet LookML.
Pour en savoir plus sur les paramètres LookML pouvant être utilisés dans un fichier de vue, consultez la page de documentation Paramètres de vue.
Explorer
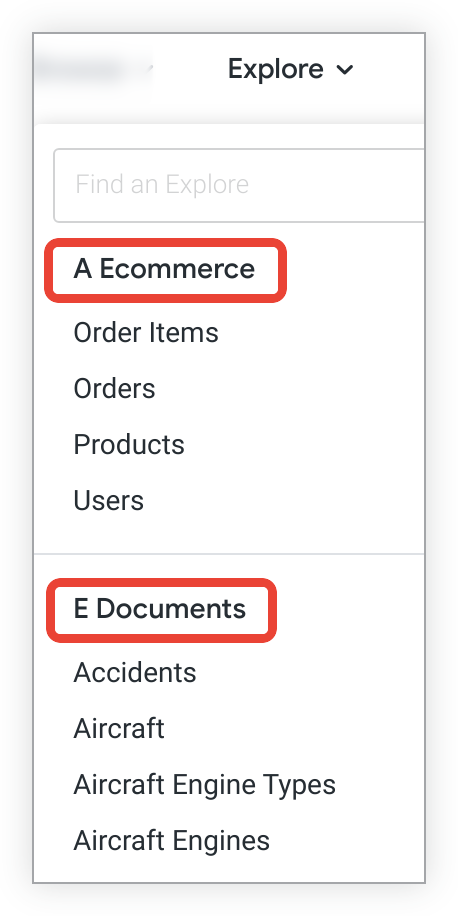
Une exploration est une vue sur laquelle les utilisateurs peuvent lancer une requête. Elle peut être considérée comme le point de départ d'une requête ou, en termes SQL, comme la clause FROM d'une instruction SQL. Toutes les vues ne sont pas des explorations, car elles ne décrivent pas toutes une entité présentant un intérêt. Par exemple, une vue États qui correspond à une table de recherche des noms d'États n'impose pas nécessairement une exploration, car les utilisateurs métier n'ont jamais besoin de l'interroger directement. À l'inverse, ils souhaiteront probablement interroger une vue Commandes, et il est donc pertinent de définir une exploration pour les commandes. Consultez la page de documentation Afficher les explorations et interagir avec elles dans Looker pour savoir comment les utilisateurs interagissent avec les explorations afin d'interroger vos données.
Dans Looker, les explorations sont présentées aux utilisateurs dans le menu Explorer. Les explorations sont listées sous le nom des modèles auxquels elles appartiennent.
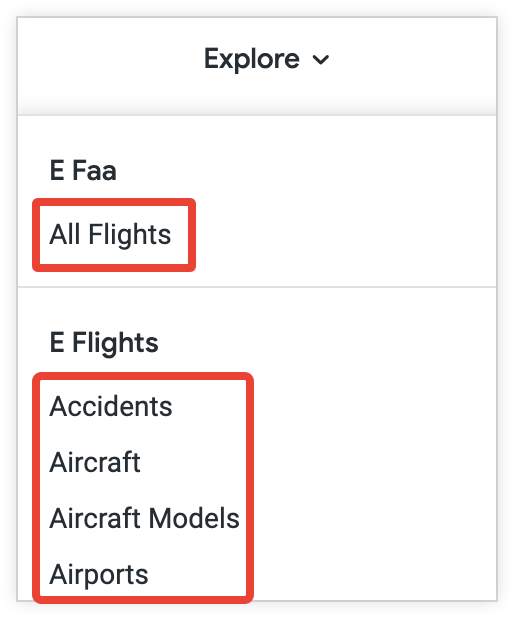
Par convention, les explorations sont déclarées dans le fichier de modèle avec le paramètre explore. Dans l'exemple suivant de fichier de modèle, l'exploration orders pour une base de données d'e-commerce est définie dans le fichier de modèle. Les vues orders et customers référencées dans la déclaration explore sont définies ailleurs, dans leurs fichiers de vue respectifs.
connection: order_database
include: "filename_pattern"
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
Dans cet exemple, le paramètre connection est utilisé pour spécifier la connexion à la base de données pour le modèle, et le paramètre include est utilisé pour spécifier les fichiers auxquels le modèle pourra faire référence.
Dans cet exemple, la déclaration explore spécifie également les relations de jointure entre les vues. Pour en savoir plus sur les déclarations join, consultez la section sur les jointures sur cette page. Consultez la page de documentation sur les paramètres de jointure pour en savoir plus sur les paramètres LookML qui peuvent être utilisés avec le paramètre join.
Champs de dimension et de mesure
Les vues contiennent des champs, essentiellement des dimensions et des mesures, qui sont les composantes fondamentales des requêtes Looker.
Dans Looker, une dimension est un champ pouvant faire partie d'un groupe et utilisable pour filtrer les résultats d'une requête. Il peut s'agir de l'un des éléments suivants :
- d'un attribut, directement associé à une colonne d'une table sous-jacente ;
- d'une valeur factuelle ou numérique ;
- d'une valeur dérivée, calculée à partir des valeurs d'autres champs sur une ligne unique.
Dans Looker, les dimensions apparaissent toujours dans la clause GROUP BY du code SQL généré par Looker.
Par exemple, les dimensions d'une vue Produits pourraient être le nom, le modèle, la couleur, le prix, la date de création et la date de fin de vie de chaque produit.
Une mesure est un champ qui utilise une fonction d'agrégation SQL, telle que COUNT, SUM, AVG, MIN ou MAX. Un champ calculé à partir d'autres valeurs de mesure est également une mesure. Les mesures permettent de filtrer des valeurs groupées. Par exemple, les mesures d'une vue Ventes pourraient être le nombre total d'articles vendus (un nombre), le prix de vente total (une somme) et le prix de vente moyen (une moyenne).
Le comportement et les valeurs attendues d'un champ varient en fonction de son type déclaré, comme string, number ou time. Pour les mesures, les types incluent des fonctions d'agrégation telles que sum et percent_of_previous. Pour en savoir plus, consultez les types de dimensions et les types de mesures.
Dans Looker, les champs sont listés sur la page Explorer, dans le sélecteur de champ à gauche de la page. Vous pouvez développer une vue dans le sélecteur de champs pour afficher la liste des champs disponibles pour les requêtes à partir de cette vue.
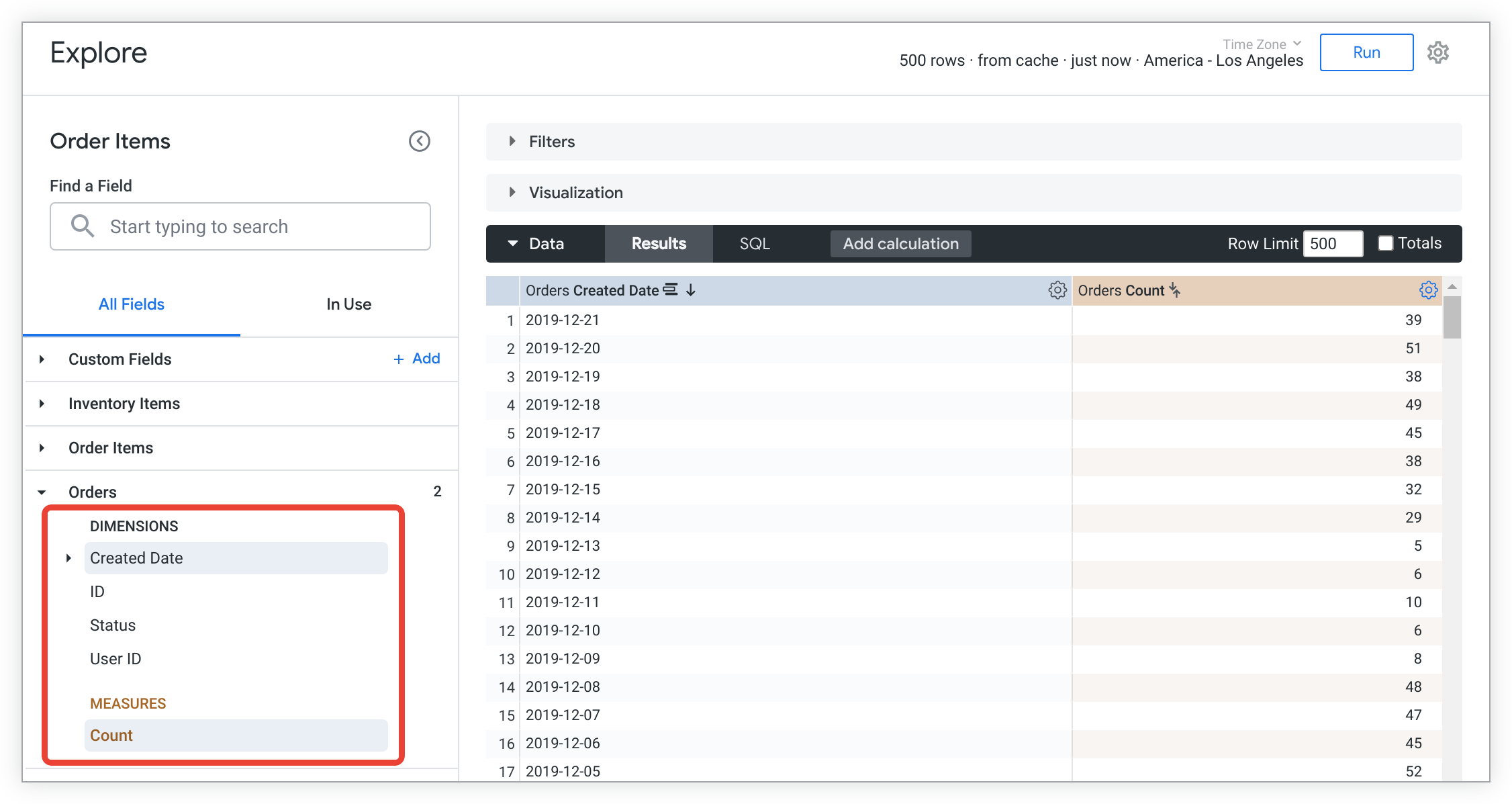
Par convention, les champs sont déclarés dans la vue dont ils font partie, enregistrée dans un fichier de vue. L'exemple suivant illustre plusieurs déclarations de dimension et de mesure. Notez l'utilisation de l'opérateur de substitution ($) pour référencer des champs sans utiliser de nom de colonne SQL entièrement défini.
Voici quelques exemples de déclarations de dimensions et de mesures :
view: orders {
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: customer_id {
sql: ${TABLE}.customer_id ;;
}
dimension: amount {
type: number
value_format: "0.00"
sql: ${TABLE}.amount ;;
}
dimension_group: created {
type: time
timeframes: [date, week]
sql: ${TABLE}.created_at ;;
}
measure: count {
type: count # creates sql COUNT(orders.id)
sql: ${id} ;;
}
measure: total_amount {
type: sum # creates sql SUM(orders.amount)
sql: ${amount} ;;
}
}
Vous pouvez également définir un dimension_group, qui crée plusieurs dimensions liées au temps à la fois, et des champs filter, qui offrent divers cas d'utilisation avancés tels que les filtres basés sur des modèles.
Pour plus de détails sur la déclaration de champs et les différents paramètres pouvant leur être appliqués, consultez la page de documentation Paramètres de champ.
Jointures
Dans une déclaration explore, chaque déclaration join désigne une vue pouvant être jointe à l'exploration. Lorsqu'un utilisateur crée une requête incluant des champs de plusieurs vues, Looker génère automatiquement une logique de jointure SQL pour présenter correctement la totalité de ces champs.
Voici un exemple de jointure dans une déclaration explore :
# file: ecommercestore.model.lookml
connection: order_database
include: "filename_pattern" # include all the views
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
Pour en savoir plus, consultez la page de documentation Utiliser des jointures dans LookML.
Fichiers manifestes d'un projet
Votre projet peut contenir un fichier manifeste de projet, qui est utilisé pour les paramètres au niveau du projet, comme ceux permettant de spécifier d'autres projets à importer dans le projet actuel, de définir des constantes LookML, de spécifier des paramètres de localisation de modèle et d'ajouter des extensions et des visualisations personnalisées à votre projet.
Chaque projet peut contenir un seul fichier manifeste. Il doit être nommé manifest.lkml et être situé à la racine de votre dépôt Git. Lorsque vous utilisez des dossiers dans l'IDE, assurez-vous que le fichier manifest.lkml est conservé au niveau racine de la structure de répertoires de votre projet.
Pour importer des fichiers LookML d'un autre projet, utilisez le fichier manifeste de celui-ci pour nommer votre projet actuel et indiquer l'emplacement des projets externes, qui peuvent être stockés en local ou à distance. Exemple :
# This project
project_name: "my_project"
# The project to import
local_dependency: {
project: "my_other_project"
}
remote_dependency: ga_360_block {
url: "https://github.com/llooker/google_ga360"
ref: "4be130a28f3776c2bf67a9acc637e65c11231bcc"
}
Après avoir défini les projets externes dans le fichier manifeste du projet, vous pouvez utiliser le paramètre include dans votre fichier de modèle pour ajouter des fichiers de ces projets externes à votre projet actuel. Exemple :
include: "//my_other_project/imported_view.view"
include: "//ga_360_block/*.view"
Pour en savoir plus, consultez la page de documentation Importer des fichiers depuis d'autres projets.
Pour ajouter des éléments de localisation à votre modèle, utilisez le fichier manifeste du projet pour définir des paramètres de localisation par défaut. Exemple :
localization_settings: {
default_locale: en
localization_level: permissive
}
La définition de paramètres de localisation par défaut est l'une des étapes de la localisation d'un modèle. Pour en savoir plus, consultez la page de documentation Localisation de votre modèle LookML.
Sets
Dans Looker, un ensemble est une liste définissant un groupe de champs utilisés ensemble. Les ensembles sont généralement utilisés pour spécifier les champs à afficher lorsqu'un utilisateur détaille des données. Dans ce cas, les jeux sont spécifiés par champ, de sorte que vous maîtrisez totalement les données qui s'affichent lorsqu'un utilisateur clique sur une valeur dans une table ou un tableau de bord. Les ensembles peuvent également faire office de fonction de sécurité, pour définir des groupes de champs visibles par certains utilisateurs.
L'exemple qui suit présente une déclaration de jeu dans une vue order_items, qui définit des champs contenant des détails intéressants sur un article acheté. Notez que les jeux font référence à des champs d'autres vues en définissant une portée.
set: order_items_stats_set {
fields: [
id, # scope defaults to order_items view
orders.created_date, # scope is "orders" view
orders.id,
users.name,
users.history, # show all products this user has purchased
products.item_name,
products.brand,
products.category,
total_sale_price
]
}
Pour en savoir plus sur leur utilisation, consultez la page de documentation du paramètre set.
Drill down
Dans Looker, vous pouvez configurer un champ pour que les utilisateurs puissent explorer plus en détail les données. Cette fonction est à la fois compatible avec les tables de résultats de requête et les tableaux de bord. La fonction de détail lance une nouvelle requête, limitée par la valeur sur laquelle vous cliquez.
Le comportement de cette fonction est différent pour les dimensions et les mesures :
- Lorsque vous détaillez une dimension, la nouvelle requête filtre sur la valeur détaillée. Par exemple, si vous cliquez sur une date donnée dans une requête de commandes client par date, la nouvelle requête affiche uniquement les commandes passées à cette date.
- Lorsque l'utilisateur détaille une mesure, la nouvelle requête présente le jeu de données ayant contribué à la mesure. Par exemple, lorsqu'il détaille un nombre, la nouvelle requête présente les lignes utilisées pour calculer ce nombre. Si la mesure détaillée est une valeur maximale, minimale ou moyenne, toutes les lignes ayant contribué à la mesure apparaissent. Par exemple, cela signifie que si une mesure maximale est détaillée, toutes les lignes utilisées pour calculer la valeur maximale sont affichées, et pas simplement la ligne contenant cette valeur.
Les champs à afficher pour la nouvelle requête d'analyse peuvent être définis par un ensemble ou par le paramètre drill_fields (pour les champs) ou le paramètre drill_fields (pour les vues).
Tables dérivées
Une table dérivée est une requête dont les résultats sont utilisés comme s'il s'agissait d'une table réelle de la base de données. Les tables dérivées sont créées à l'aide du paramètre derived_table dans une déclaration view. Looker accède aux tables dérivées comme s'il s'agissait de tables physiques avec leurs propres colonnes. Elle est présentée dans une vue spécifique dont les dimensions et mesures sont définies de la même manière que celles des autres vues. Comme n'importe quelle autre vue, celle d'une table dérivée peut faire l'objet de requêtes et être jointe à d'autres vues.
Les tables dérivées peuvent également être définies comme des tables dérivées persistantes (PDT). Il s'agit de tables dérivées écrites dans un schéma entièrement nouveau de la base de données et régénérées automatiquement selon la fréquence que vous définissez avec une stratégie de persistance.
Pour en savoir plus, consultez la page de documentation Tables dérivées dans Looker.
Connexion à une base de données
La connexion de base de données que Looker utilise pour exécuter les requêtes constitue un autre aspect important des projets LookML. Un administrateur Looker utilise la page "Connexions" pour configurer les connexions de base de données, et les développeurs LookML utilisent le paramètre connection dans un fichier de modèle pour spécifier la connexion à utiliser pour le modèle. Si vous générez un projet LookML à partir de votre base de données, Looker renseigne automatiquement le paramètre connection dans le fichier de modèle.
Sensibilité à la casse
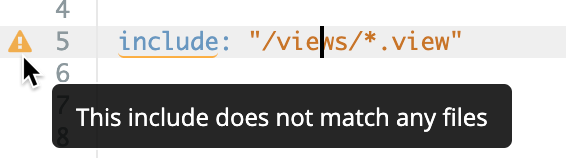
LookML est sensible à la casse, vérifiez donc la casse lorsque vous mentionnez des éléments LookML. Looker vous avertit si vous avez mentionné un élément qui n'existe pas.
Par exemple, supposons que vous ayez une exploration appelée e_flights_pdt et qu'un développeur LookML utilise une casse incorrecte (e_FLIGHTS_pdt) pour faire référence à cette exploration. Dans cet exemple, l'IDE Looker affiche un avertissement indiquant que l'exploration e_FLIGHTS_pdt n'existe pas. En outre, l'IDE suggère le nom d'une exploration existante, e_flights_pdt :

Cependant, si votre projet contenait à la fois e_FLIGHTS_pdt et e_flights_pdt, l'environnement IDE de Looker ne pourrait pas vous corriger, vous devriez donc être certain de la version que vous souhaitiez utiliser. Nous recommandons généralement d'utiliser des minuscules pour nommer des objets LookML.
Les noms des dossiers IDE sont également sensibles à la casse. Vous devez vérifier la casse du nom des fichiers dès que vous spécifiez des chemins de fichier. Par exemple, si vous avez un dossier nommé Views, vous devez utiliser la même casse dans le paramètre include. Une fois de plus, l'IDE Looker indique une erreur si la casse ne correspond pas au dossier existant de votre projet :