In Looker, le tabelle derivate permanenti (PDT) vengono scritte nello schema temporaneo del database. Looker rende permanente e ricostruisce una PDT in base alla sua strategia di persistenza. Quando viene attivata la rigenerazione di una PDT, per impostazione predefinita Looker rigenera l'intera tabella.
Una PDT incrementale è una PDT che Looker crea aggiungendo nuovi dati alla tabella anziché ricostruirla interamente:
Se il tuo dialetto supporta le PDT incrementali, puoi trasformare i seguenti tipi di PDT in PDT incrementali:
- Tabelle aggregate
- PDT basate su LookML (native)
- PDT basate su SQL
La prima volta che esegui una query su una PDT incrementale, Looker crea l'intera PDT per ottenere i dati iniziali. Se la tabella è di grandi dimensioni, la creazione iniziale potrebbe richiedere molto tempo, come per qualsiasi tabella di grandi dimensioni. Una volta creata la tabella iniziale, le build successive saranno incrementali e richiederanno meno tempo, se la PDT incrementale è configurata in modo strategico.
Tieni presente quanto segue per le PDT incrementali:
- Le PDT incrementali sono supportate solo per le PDT che utilizzano una strategia di persistenza basata su trigger (
datagroup_trigger,sql_trigger_valueointerval_trigger). Le PDT incrementali non sono supportate per le PDT che utilizzano la strategia di persistenzapersist_for. - Per le PDT basate su SQL, la query della tabella deve essere definita utilizzando il parametro
sqlda utilizzare come PDT incrementale. Le PDT basate su SQL definite con il parametrosql_createocreate_processnon possono essere create in modo incrementale. Come puoi vedere nell'esempio 1 di questa pagina, Looker utilizza un comando INSERT o MERGE per creare gli incrementi per una PDT incrementale. La tabella derivata non può essere definita utilizzando istruzioni DDL (Data Definition Language) personalizzate, poiché Looker non sarebbe in grado di determinare quali istruzioni DDL sarebbero necessarie per creare un incremento accurato. - La tabella di origine del PDT incrementale deve essere ottimizzata per le query basate sul tempo. Nello specifico, la colonna basata sul tempo utilizzata per la chiave di incremento deve avere una strategia di ottimizzazione, ad esempio partizionamento, chiavi di ordinamento, indici o qualsiasi strategia di ottimizzazione supportata per il tuo dialetto. L'ottimizzazione della tabella di origine è vivamente consigliata perché ogni volta che la tabella incrementale viene aggiornata, Looker esegue query sulla tabella di origine per determinare i valori più recenti della colonna basata sul tempo utilizzata per la chiave di incremento. Se la tabella di origine non è ottimizzata per queste query, la query di Looker per i valori più recenti potrebbe essere lenta e costosa.
Definizione di un PDT incrementale
Puoi utilizzare i seguenti parametri per trasformare una PDT in una PDT incrementale:
increment_key(obbligatorio per rendere la PDT incrementale): definisce il periodo di tempo per cui devono essere eseguite query sui nuovi record.{% incrementcondition %}Filtro Liquid (obbligatorio per trasformare una PDT basata su SQL in una PDT incrementale; non applicabile alle PDT basate su LookML): collega la chiave di incremento alla colonna temporale del database su cui si basa la chiave di incremento. Per ulteriori informazioni, consulta la pagina della documentazione relativa aincrement_key.increment_offset(facoltativo): un numero intero che definisce il numero di periodi di tempo precedenti (alla granularità della chiave di incremento) che vengono ricreati per ogni build incrementale. Il parametroincrement_offsetè utile in caso di dati in arrivo in ritardo, in cui i periodi di tempo precedenti potrebbero avere nuovi dati che non erano inclusi quando l'incremento corrispondente è stato originariamente creato e aggiunto alla PDT.
Consulta la pagina della documentazione del parametro increment_key per esempi che mostrano come creare PDT incrementali da tabelle derivate native permanenti, tabelle derivate permanenti basate su SQL e tabelle aggregate.
Ecco un semplice esempio di un file di visualizzazione che definisce una PDT incrementale basata su LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Questa tabella verrà creata per intero la prima volta che viene eseguita una query. Dopodiché, il PDT verrà ricreato con incrementi di un giorno (increment_key: departure_date), tornando indietro di tre giorni (increment_offset: 3).
La chiave di incremento si basa sulla dimensione departure_date, che in realtà è l'date intervallo di tempo del gruppo di dimensioni departure. Per una panoramica del funzionamento dei gruppi di dimensioni, consulta la pagina della documentazione del parametro dimension_group. Il gruppo di dimensioni e l'intervallo di tempo sono entrambi definiti nella visualizzazione flights, che è explore_source per questa PDT. Ecco come è definito il gruppo di dimensioni departure nel file di visualizzazione flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interazione tra i parametri di incremento e la strategia di persistenza
Le impostazioni increment_key e increment_offset di una PDT sono indipendenti dalla strategia di persistenza della PDT:
- La strategia di persistenza della PDT incrementale determina solo quando la PDT viene incrementata. Il generatore di PDT non modifica la PDT incrementale a meno che non venga attivata la strategia di persistenza della tabella o a meno che la PDT non venga attivata manualmente con l'opzione Ricostruisci tabelle derivate ed esegui in un'esplorazione.
- Quando la PDT viene incrementata, il builder PDT determina quando sono stati aggiunti in precedenza i dati più recenti alla tabella, in termini di incremento di tempo più recente (il periodo di tempo definito dal parametro
increment_key). In base a questo, il generatore di PDT troncherà i dati all'inizio dell'incremento di tempo più recente nella tabella, quindi creerà l'ultimo incremento da lì. - Se la PDT ha un parametro
increment_offset, il builder PDT ricostruirà anche il numero di periodi di tempo precedenti specificati nel parametroincrement_offset. I periodi di tempo precedenti iniziano dall'inizio dell'incremento di tempo più recente (il periodo di tempo definito dal parametroincrement_key).
Gli scenari di esempio seguenti illustrano come vengono aggiornate le PDT incrementali, mostrando l'interazione di increment_key, increment_offset e della strategia di persistenza.
Esempio 1
Questo esempio utilizza un PDT con le seguenti proprietà:
- Incrementa chiave: data
- Incrementa offset: 3
- Strategia di persistenza: attivata una volta al mese il primo giorno del mese
Ecco come verrà aggiornata questa tabella:
- Una strategia di persistenza mensile significa che la tabella viene creata automaticamente una volta al mese. Ciò significa che il 1° giugno, ad esempio, l'ultima riga della tabella sarà stata aggiunta il 1° maggio.
- Poiché questa tabella derivata ha una chiave incrementale basata sulla data, il generatore di tabelle derivate troncherà il 1° maggio riportandolo all'inizio della giornata e ricostruirà i dati per il 1° maggio e fino al giorno corrente, il 1° giugno.
- Inoltre, questo PDT ha un offset di incremento pari a
3. Pertanto, il generatore di PDT ricompila anche i dati dei tre periodi di tempo (giorni) precedenti il 1° maggio. Il risultato è che i dati vengono ricostruiti per il 28, 29 e 30 aprile e fino al 1° giugno.
In termini SQL, ecco il comando che il generatore di PDT eseguirà il 1° giugno per determinare le righe del PDT esistente che devono essere ricreate:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Ecco il comando SQL che il generatore PDT eseguirà il 1° giugno per creare l'ultimo incremento:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Esempio 2
Questo esempio utilizza un PDT con le seguenti proprietà:
- Strategia di persistenza: attivata una volta al giorno
- Incrementa chiave: mese
- Incrementa offset: 0
Ecco come verrà aggiornata questa tabella il 1° giugno:
- La strategia di persistenza giornaliera prevede che la tabella venga creata automaticamente una volta al giorno. Il 1° giugno, l'ultima riga della tabella sarà stata aggiunta il 31 maggio.
- Poiché la chiave di incremento si basa sul mese, il generatore di PDT troncherà i dati dal 31 maggio all'inizio del mese e li ricostruirà per tutto il mese di maggio e fino al giorno corrente, incluso il 1° giugno.
- Poiché questa PDT non ha un offset di incremento, non vengono ricreati periodi di tempo precedenti.
Ecco come verrà aggiornata questa tabella il 2 giugno:
- Il 2 giugno, l'ultima riga della tabella sarà stata aggiunta il 1° giugno.
- Poiché il generatore di PDT troncherà i dati fino all'inizio del mese di giugno, per poi ricostruirli a partire dal 1° giugno fino al giorno corrente, i dati vengono ricostruiti solo per il 1° e il 2 giugno.
- Poiché questa PDT non ha un offset di incremento, non vengono ricreati periodi di tempo precedenti.
Esempio 3
Questo esempio utilizza un PDT con le seguenti proprietà:
- Incrementa chiave: mese
- Incrementa offset: 3
- Strategia di persistenza: attivata una volta al giorno
Questo scenario illustra una configurazione errata per una PDT incrementale, in quanto si tratta di una PDT con attivazione giornaliera e un offset di tre mesi. Ciò significa che ogni giorno verranno ricostruiti almeno tre mesi di dati, il che rappresenterebbe un utilizzo molto inefficiente di un PDT incrementale. Tuttavia, è uno scenario interessante da esaminare per capire come funzionano i PDT incrementali.
Ecco come verrà aggiornata questa tabella il 1° giugno:
- La strategia di persistenza giornaliera prevede che la tabella venga creata automaticamente una volta al giorno. Ad esempio, il 1° giugno l'ultima riga della tabella sarà stata aggiunta il 31 maggio.
- Poiché la chiave di incremento si basa sul mese, il generatore di PDT troncherà i dati dal 31 maggio all'inizio del mese e li ricostruirà per tutto il mese di maggio e fino al giorno corrente, incluso il 1° giugno.
- Inoltre, questo PDT ha un offset di incremento pari a
3. Ciò significa che il generatore di PDT ricostruisce anche i dati dei tre periodi di tempo (mesi) precedenti a maggio. Il risultato è che i dati vengono ricostruiti a partire da febbraio, marzo, aprile e fino al giorno corrente, il 1° giugno.
Ecco come verrà aggiornata questa tabella il 2 giugno:
- Il 2 giugno, l'ultima riga della tabella sarà stata aggiunta il 1° giugno.
- Il generatore di PDT troncherà il mese fino al 1° giugno e ricostruirà i dati per il mese di giugno, incluso il 2 giugno.
- Inoltre, a causa dell'offset dell'incremento, il generatore di PDT ricostruirà i dati dei tre mesi precedenti a giugno. Il risultato è che i dati vengono ricostruiti a partire da marzo, aprile, maggio e fino al giorno corrente, il 2 giugno.
Test di un PDT incrementale in modalità di sviluppo
Prima di eseguire il deployment di una nuova PDT incrementale nell'ambiente di produzione, puoi testarla per assicurarti che venga creata e incrementata. Per testare una PDT incrementale in modalità di sviluppo:
Crea un Explore per il PDT:
- In un file modello associato, utilizza il parametro
includeper includere il file di visualizzazione del PDT nel file modello. - Nello stesso file del modello, utilizza il parametro
exploreper creare un'esplorazione per la visualizzazione della PDT incrementale.
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- In un file modello associato, utilizza il parametro
Apri Esplora per il PDT. Per farlo, seleziona il pulsante Visualizza azioni file e poi seleziona un nome di esplorazione.
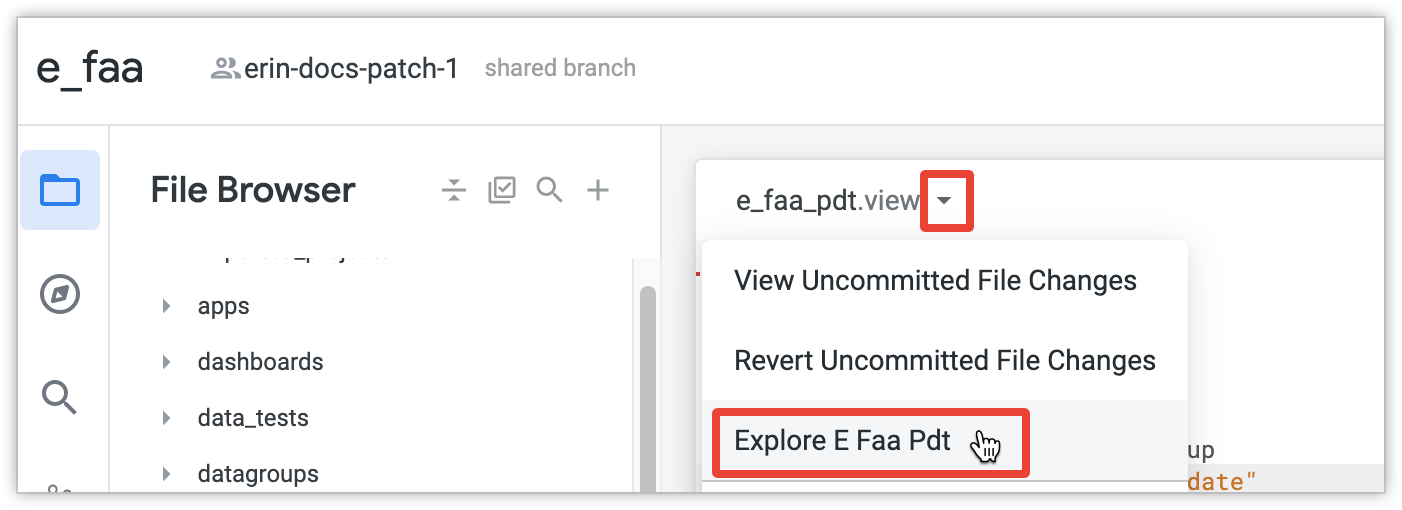
In Esplora, seleziona alcune dimensioni o misure e fai clic su Esegui. Looker creerà quindi l'intera PDT. Se è la prima query eseguita sulla PDT incrementale, il builder PDT creerà l'intera PDT per ottenere i dati iniziali. Se la tabella è di grandi dimensioni, la creazione iniziale potrebbe richiedere molto tempo, come per qualsiasi tabella di grandi dimensioni.
Puoi verificare che il PDT iniziale sia stato creato nei seguenti modi:
- Se disponi dell'autorizzazione
see_logs, puoi verificare che la tabella sia stata creata esaminando il log eventi PDT. Se non vedi gli eventi di PDT creati nel log eventi PDT, controlla le informazioni sullo stato nella parte superiore dell'esplorazione del log eventi PDT. Se viene visualizzato il messaggio "dalla cache", puoi selezionare Svuota cache e aggiorna per ottenere informazioni più recenti. - In alternativa, puoi esaminare i commenti nella scheda SQL della barra Dati di Esplora. La scheda SQL mostra la query e le azioni che verranno eseguite quando la esegui in Esplora. Ad esempio, se i commenti nella scheda SQL indicano
-- generate derived table e_incremental_pdt
- Se disponi dell'autorizzazione
Dopo aver creato la build iniziale della PDT, richiedi una build incrementale della PDT utilizzando l'opzione Ricostruisci tabelle derivate ed esegui dall'esplorazione.
Puoi utilizzare gli stessi metodi di prima per verificare che la PDT venga creata in modo incrementale:
- Se disponi dell'autorizzazione
see_logs, puoi utilizzare il log eventi PDT per visualizzare gli eventicreate increment completeper la PDT incrementale. Se non vedi questo evento nel log eventi PDT e lo stato della query indica "dalla cache", seleziona Svuota cache e aggiorna per ottenere informazioni più recenti. - Esamina i commenti nella scheda SQL della barra Dati di Esplora. In questo caso, i commenti indicheranno che il PDT è stato incrementato. Ad esempio:
-- increment persistent derived table e_incremental_pdt to generation 2
- Se disponi dell'autorizzazione
Una volta verificato che la tabella derivata è creata e incrementata correttamente, se non vuoi conservare l'esplorazione dedicata per la tabella derivata, puoi rimuovere o commentare i parametri
exploreeincludedella tabella derivata dal file del modello.
Dopo la creazione della PDT in modalità di sviluppo, la stessa tabella verrà utilizzata per la produzione una volta eseguito il deployment delle modifiche, a meno che non apporti ulteriori modifiche alla definizione della tabella. Per ulteriori informazioni, consulta la sezione Tabelle persistenti in modalità Development (Sviluppo) della pagina della documentazione Tabelle derivate in Looker.
Risoluzione dei problemi relativi alle PDT incrementali
Questa sezione descrive alcuni problemi comuni che potresti riscontrare durante l'utilizzo delle PDT incrementali, nonché i passaggi per risolvere questi problemi.
La creazione di PDT incrementali non riesce dopo la modifica dello schema
Se la PDT incrementale è una tabella derivata basata su SQL e il parametro sql include un carattere jolly come SELECT *, le modifiche allo schema del database sottostante (ad esempio l'aggiunta, la rimozione o la modifica del tipo di dati di una colonna) potrebbero causare l'errore della PDT:
SQL Error in incremental PDT: Query execution failed
Per risolvere il problema, modifica l'istruzione SELECT nel parametro sql per selezionare invece singole colonne. Ad esempio, se la clausola SELECT è SELECT *, modificala in SELECT column1, column2, ....
Se lo schema cambia e vuoi ricreare la PDT incrementale da zero, utilizza la chiamata API start_pdt_build e includi il parametro full_force_incremental.
Dialetti di database supportati per le PDT incrementali
Affinché Looker supporti le PDT incrementali nel tuo progetto Looker, il dialetto del database deve supportare i comandi Data Definition Language (DDL) che consentono l'eliminazione e l'inserimento di righe.
La tabella seguente mostra quali dialetti supportano le PDT incrementali nell'ultima release di Looker (per Databricks, le PDT incrementali sono supportate solo su Databricks versione 12.1 e successive):
| Dialetto | Supportato? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Sì |
| Amazon Redshift 2.1+ | Sì |
| Amazon Redshift Serverless 2.1+ | Sì |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Sì |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Sì |
| Google Cloud PostgreSQL | Sì |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sì |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Sì |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Sì |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Sì |
| MySQL 8.0.12+ | Sì |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Sì |
| PostgreSQL pre-9.5 | Sì |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Sì |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Sì |