En Looker, una tabla derivada es una consulta cuyos resultados se usan como si la consulta fuera una tabla real de la base de datos.
Por ejemplo, puede tener una tabla de base de datos llamada orders que tenga muchas columnas. Quieres calcular algunas métricas agregadas a nivel de cliente, como el número de pedidos que ha realizado cada cliente o cuándo hizo su primer pedido. Puedes crear una tabla de base de datos llamada customer_order_summary que incluya estas métricas mediante una tabla derivada nativa o una tabla derivada basada en SQL.

A continuación, puede trabajar con la tabla derivada customer_order_summary como si fuera cualquier otra tabla de la base de datos.
Para ver casos prácticos habituales de tablas derivadas, consulta el artículo Looker cookbooks: Getting the most out of derived tables in Looker (Recetas de Looker: sacar el máximo partido a las tablas derivadas en Looker).
Tablas derivadas nativas y tablas derivadas basadas en SQL
Para crear una tabla derivada en tu proyecto de Looker, usa el parámetro derived_table en un parámetro view. Dentro del parámetro derived_table, puedes definir la consulta de la tabla derivada de dos formas:
- En el caso de una tabla derivada nativa, se define con una consulta basada en LookML.
- En el caso de las tablas derivadas basadas en SQL, se definen con una consulta de SQL.
Por ejemplo, los siguientes archivos de vista muestran cómo puedes usar LookML para crear una vista a partir de una tabla derivada customer_order_summary. Las dos versiones de LookML muestran cómo puedes crear tablas derivadas equivalentes usando LookML o SQL para definir la consulta de la tabla derivada:
- La tabla derivada nativa define la consulta con LookML en el parámetro
explore_source. En este ejemplo, la consulta se basa en una vistaordersque se define en un archivo independiente que no se muestra en este ejemplo. La consultaexplore_sourcede la tabla derivada nativa incluye los camposcustomer_id,first_orderytotal_amountdel archivo de vistaorders. - La tabla derivada basada en SQL define la consulta mediante SQL en el parámetro
sql. En este ejemplo, la consulta de SQL es una consulta directa de la tablaordersde la base de datos.
view: customer_order_summary {
derived_table: {
explore_source: orders {
column: customer_id {
field: orders.customer_id
}
column: first_order {
field: orders.first_order
}
column: total_amount {
field: orders.total_amount
}
}
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
view: customer_order_summary {
derived_table: {
sql:
SELECT
customer_id,
MIN(DATE(time)) AS first_order,
SUM(amount) AS total_amount
FROM
orders
GROUP BY
customer_id ;;
}
dimension: customer_id {
type: number
primary_key: yes
sql: ${TABLE}.customer_id ;;
}
dimension_group: first_order {
type: time
timeframes: [date, week, month]
sql: ${TABLE}.first_order ;;
}
dimension: total_amount {
type: number
value_format: "0.00"
sql: ${TABLE}.total_amount ;;
}
}
Ambas versiones crean una vista llamada customer_order_summary basada en la tabla orders, con las columnas customer_id, first_order, y total_amount.
Aparte del parámetro derived_table y sus subparámetros, esta vista customer_order_summary funciona igual que cualquier otro archivo de vista. Tanto si defines la consulta de la tabla derivada con LookML como con SQL, puedes crear medidas y dimensiones de LookML basadas en las columnas de la tabla derivada.
Una vez que haya definido la tabla derivada, podrá usarla como cualquier otra tabla de su base de datos.
Tablas derivadas nativas
Las tablas derivadas nativas se basan en consultas que defines con términos de LookML. Para crear una tabla derivada nativa, usa el parámetro explore_source dentro del parámetro derived_table de un parámetro view. Para crear las columnas de tu tabla derivada nativa, debes hacer referencia a las dimensiones o medidas de LookML de tu modelo. Consulte el archivo de vista de tabla derivada nativa en el ejemplo anterior.
En comparación con las tablas derivadas basadas en SQL, las tablas derivadas nativas son mucho más fáciles de leer y entender al modelar los datos.
Consulta la página de documentación Crear tablas derivadas nativas para obtener más información sobre cómo crear tablas derivadas nativas.
Tablas derivadas basadas en SQL
Para crear una tabla derivada basada en SQL, define una consulta en términos de SQL, creando columnas en la tabla mediante una consulta SQL. No puedes hacer referencia a dimensiones ni medidas de LookML en una tabla derivada basada en SQL. Consulta el archivo de vista de la tabla derivada basada en SQL en el ejemplo anterior.
Lo más habitual es definir la consulta de SQL con el parámetro sql dentro del parámetro derived_table de un parámetro view.
Un atajo útil para crear consultas basadas en SQL en Looker es usar SQL Runner para crear la consulta de SQL y convertirla en una definición de tabla derivada.
En algunos casos extremos, no se podrá usar el parámetro sql. En estos casos, Looker admite los siguientes parámetros para definir una consulta de SQL para tablas derivadas persistentes (PDTs):
create_process: Cuando usas el parámetrosqlen una PDT, Looker envuelve en segundo plano laCREATE TABLEinstrucción del lenguaje de definición de datos (DDL) del dialecto en tu consulta para crear la PDT a partir de tu consulta SQL. Algunos dialectos no admiten una instrucciónCREATE TABLEde SQL en un solo paso. En estas variantes, no puedes crear un PDT con el parámetrosql. En su lugar, puede usar el parámetrocreate_processpara crear un PDT en varios pasos. Consulta la página de documentación del parámetrocreate_processpara obtener información y ejemplos.sql_create: Si tu caso práctico requiere comandos DDL personalizados y tu dialecto admite DDL (por ejemplo, el BigQuery ML predictivo de Google), puedes usar el parámetrosql_createpara crear un PDT en lugar del parámetrosql. Consulta la página de documentación desql_createpara obtener información y ejemplos.
Tanto si usas el parámetro sql, create_process o sql_create, en todos los casos defines la tabla derivada con una consulta SQL, por lo que se consideran tablas derivadas basadas en SQL.
Cuando definas una tabla derivada basada en SQL, asegúrate de asignar un alias claro a cada columna mediante AS. Esto se debe a que tendrás que hacer referencia a los nombres de las columnas del conjunto de resultados en tus dimensiones, como ${TABLE}.first_order. Por eso, en el ejemplo anterior se usa MIN(DATE(time)) AS first_order en lugar de MIN(DATE(time)).
Tablas derivadas temporales y persistentes
Además de la distinción entre las tablas derivadas nativas y las basadas en SQL, también hay una diferencia entre las tablas derivadas temporales, que no se escriben en la base de datos, y las tablas derivadas persistentes (PDTs), que se escriben en un esquema de la base de datos.
Las tablas derivadas nativas y las basadas en SQL pueden ser temporales o persistentes.
Tablas derivadas temporales
Las tablas derivadas que se han mostrado anteriormente son ejemplos de tablas derivadas temporales. Son temporales porque no se ha definido ninguna estrategia de persistencia en el parámetro derived_table.
Las tablas derivadas temporales no se escriben en la base de datos. Cuando un usuario ejecuta una consulta de Exploración que incluye una o varias tablas derivadas, Looker crea una consulta SQL mediante una combinación específica del dialecto del SQL de las tablas derivadas, además de los campos, las combinaciones y los valores de filtro solicitados. Si la combinación se ha ejecutado antes y los resultados siguen siendo válidos en la caché, Looker utiliza los resultados almacenados en caché. Consulta la página de documentación Almacenar en caché las consultas para obtener más información sobre el almacenamiento en caché de consultas en Looker.
De lo contrario, si Looker no puede usar los resultados almacenados en caché, deberá ejecutar una nueva consulta en tu base de datos cada vez que un usuario solicite datos de una tabla derivada temporal. Por este motivo, debes asegurarte de que tus tablas derivadas temporales tengan un buen rendimiento y no supongan una carga excesiva para tu base de datos. En los casos en los que la consulta tardará un tiempo en ejecutarse, suele ser mejor opción usar un PDT.
Dialectos de bases de datos compatibles con las tablas derivadas temporales
Para que Looker admita las tablas derivadas en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlas. En la siguiente tabla se muestra qué dialectos admiten tablas derivadas en la última versión de Looker:
Haz clic aquí para ver la tabla.
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | Sí |
| Amazon Athena | Sí |
| Amazon Aurora MySQL | Sí |
| Amazon Redshift | Sí |
| Amazon Redshift 2.1+ | Sí |
| Amazon Redshift Serverless 2.1+ | Sí |
| Apache Druid | Sí |
| Apache Druid 0.13+ | Sí |
| Apache Druid 0.18+ | Sí |
| Apache Hive 2.3+ | Sí |
| Apache Hive 3.1.2+ | Sí |
| Apache Spark 3+ | Sí |
| ClickHouse | Sí |
| Cloudera Impala 3.1+ | Sí |
| Cloudera Impala 3.1+ with Native Driver | Sí |
| Cloudera Impala with Native Driver | Sí |
| DataVirtuality | Sí |
| Databricks | Sí |
| Denodo 7 | Sí |
| Denodo 8 & 9 | Sí |
| Dremio | Sí |
| Dremio 11+ | Sí |
| Exasol | Sí |
| Google BigQuery Legacy SQL | Sí |
| Google BigQuery Standard SQL | Sí |
| Google Cloud PostgreSQL | Sí |
| Google Cloud SQL | Sí |
| Google Spanner | Sí |
| Greenplum | Sí |
| HyperSQL | Sí |
| IBM Netezza | Sí |
| MariaDB | Sí |
| Microsoft Azure PostgreSQL | Sí |
| Microsoft Azure SQL Database | Sí |
| Microsoft Azure Synapse Analytics | Sí |
| Microsoft SQL Server 2008+ | Sí |
| Microsoft SQL Server 2012+ | Sí |
| Microsoft SQL Server 2016 | Sí |
| Microsoft SQL Server 2017+ | Sí |
| MongoBI | Sí |
| MySQL | Sí |
| MySQL 8.0.12+ | Sí |
| Oracle | Sí |
| Oracle ADWC | Sí |
| PostgreSQL 9.5+ | Sí |
| PostgreSQL pre-9.5 | Sí |
| PrestoDB | Sí |
| PrestoSQL | Sí |
| SAP HANA | Sí |
| SAP HANA 2+ | Sí |
| SingleStore | Sí |
| SingleStore 7+ | Sí |
| Snowflake | Sí |
| Teradata | Sí |
| Trino | Sí |
| Vector | Sí |
| Vertica | Sí |
Tablas derivadas persistentes
Una tabla derivada persistente (PDT) es una tabla derivada que se escribe en un esquema Scratch de tu base de datos y se vuelve a generar según la programación que especifiques con una estrategia de persistencia.
Una PDT puede ser una tabla derivada nativa o una tabla derivada basada en SQL.
Requisitos de las PDTs
Para usar tablas derivadas persistentes (PDTs) en tu proyecto de Looker, necesitas lo siguiente:
- Un dialecto de base de datos que admita PDTs. Consulta las listas de dialectos que admiten tablas derivadas basadas en SQL persistentes y tablas derivadas nativas persistentes en la sección Dialectos de bases de datos admitidos para PDTs de esta página.
Un esquema provisional en tu base de datos. Puede ser cualquier esquema de tu base de datos, pero te recomendamos que crees uno nuevo que se use solo para este fin. El administrador de la base de datos debe configurar el esquema con permiso de escritura para el usuario de la base de datos de Looker.
Una conexión de Looker configurada con el interruptor Habilitar PDTs activado. Este ajuste Habilitar PDTs se suele configurar cuando se configura inicialmente la conexión de Looker (consulta la página de documentación sobre los dialectos de Looker para ver las instrucciones del dialecto de tu base de datos), pero también puedes habilitar los PDTs de tu conexión después de la configuración inicial.
Dialectos de bases de datos admitidos para PDTs
Para que Looker admita PDTs en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlos.
Para admitir cualquier tipo de PDT (basado en LookML o en SQL), el dialecto debe admitir escrituras en la base de datos, entre otros requisitos. Hay algunas configuraciones de bases de datos de solo lectura que no permiten que funcione la persistencia (las bases de datos de réplica de intercambio en caliente de Postgres son las más habituales). En estos casos, puede usar tablas derivadas temporales.
En la siguiente tabla se muestran los dialectos que admiten tablas derivadas basadas en SQL persistentes en la versión más reciente de Looker:
Haz clic aquí para ver la tabla.
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | Sí |
| Amazon Athena | Sí |
| Amazon Aurora MySQL | Sí |
| Amazon Redshift | Sí |
| Amazon Redshift 2.1+ | Sí |
| Amazon Redshift Serverless 2.1+ | Sí |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Sí |
| Apache Hive 3.1.2+ | Sí |
| Apache Spark 3+ | Sí |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Sí |
| Cloudera Impala 3.1+ with Native Driver | Sí |
| Cloudera Impala with Native Driver | Sí |
| DataVirtuality | No |
| Databricks | Sí |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Sí |
| Google BigQuery Legacy SQL | Sí |
| Google BigQuery Standard SQL | Sí |
| Google Cloud PostgreSQL | Sí |
| Google Cloud SQL | Sí |
| Google Spanner | No |
| Greenplum | Sí |
| HyperSQL | No |
| IBM Netezza | Sí |
| MariaDB | Sí |
| Microsoft Azure PostgreSQL | Sí |
| Microsoft Azure SQL Database | Sí |
| Microsoft Azure Synapse Analytics | Sí |
| Microsoft SQL Server 2008+ | Sí |
| Microsoft SQL Server 2012+ | Sí |
| Microsoft SQL Server 2016 | Sí |
| Microsoft SQL Server 2017+ | Sí |
| MongoBI | No |
| MySQL | Sí |
| MySQL 8.0.12+ | Sí |
| Oracle | Sí |
| Oracle ADWC | Sí |
| PostgreSQL 9.5+ | Sí |
| PostgreSQL pre-9.5 | Sí |
| PrestoDB | Sí |
| PrestoSQL | Sí |
| SAP HANA | Sí |
| SAP HANA 2+ | Sí |
| SingleStore | Sí |
| SingleStore 7+ | Sí |
| Snowflake | Sí |
| Teradata | Sí |
| Trino | Sí |
| Vector | Sí |
| Vertica | Sí |
Para admitir tablas derivadas nativas persistentes (que tienen consultas basadas en LookML), el dialecto también debe admitir una función CREATE TABLE DDL. A continuación, se muestra una lista de los dialectos que admiten tablas derivadas nativas (basadas en LookML) persistentes en la última versión de Looker:
Haz clic aquí para ver la tabla.
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | Sí |
| Amazon Athena | Sí |
| Amazon Aurora MySQL | Sí |
| Amazon Redshift | Sí |
| Amazon Redshift 2.1+ | Sí |
| Amazon Redshift Serverless 2.1+ | Sí |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | Sí |
| Apache Hive 3.1.2+ | Sí |
| Apache Spark 3+ | Sí |
| ClickHouse | No |
| Cloudera Impala 3.1+ | Sí |
| Cloudera Impala 3.1+ with Native Driver | Sí |
| Cloudera Impala with Native Driver | Sí |
| DataVirtuality | No |
| Databricks | Sí |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | Sí |
| Google BigQuery Legacy SQL | Sí |
| Google BigQuery Standard SQL | Sí |
| Google Cloud PostgreSQL | Sí |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sí |
| HyperSQL | No |
| IBM Netezza | Sí |
| MariaDB | Sí |
| Microsoft Azure PostgreSQL | Sí |
| Microsoft Azure SQL Database | Sí |
| Microsoft Azure Synapse Analytics | Sí |
| Microsoft SQL Server 2008+ | Sí |
| Microsoft SQL Server 2012+ | Sí |
| Microsoft SQL Server 2016 | Sí |
| Microsoft SQL Server 2017+ | Sí |
| MongoBI | No |
| MySQL | Sí |
| MySQL 8.0.12+ | Sí |
| Oracle | Sí |
| Oracle ADWC | Sí |
| PostgreSQL 9.5+ | Sí |
| PostgreSQL pre-9.5 | Sí |
| PrestoDB | Sí |
| PrestoSQL | Sí |
| SAP HANA | Sí |
| SAP HANA 2+ | Sí |
| SingleStore | Sí |
| SingleStore 7+ | Sí |
| Snowflake | Sí |
| Teradata | Sí |
| Trino | Sí |
| Vector | Sí |
| Vertica | Sí |
Crear PDTs de forma incremental
Una tabla derivada persistente incremental es una tabla derivada persistente que Looker crea añadiendo datos nuevos a la tabla en lugar de volver a crearla por completo.
Si tu dialecto admite PDTs incrementales y tu PDT usa una estrategia de persistencia basada en activadores (datagroup_trigger, sql_trigger_value o interval_trigger), puedes definir el PDT como incremental.
Para obtener más información, consulta la página de documentación sobre PDTs incrementales.
Dialectos de bases de datos compatibles con PDTs incrementales
Para que Looker admita PDTs incrementales en tu proyecto de Looker, el dialecto de tu base de datos también debe admitirlos. En la siguiente tabla se muestra qué dialectos admiten PDTs incrementales en la última versión de Looker:
Haz clic aquí para ver la tabla.
| Dialecto | ¿Es compatible? |
|---|---|
| Actian Avalanche | No |
| Amazon Athena | No |
| Amazon Aurora MySQL | No |
| Amazon Redshift | Sí |
| Amazon Redshift 2.1+ | Sí |
| Amazon Redshift Serverless 2.1+ | Sí |
| Apache Druid | No |
| Apache Druid 0.13+ | No |
| Apache Druid 0.18+ | No |
| Apache Hive 2.3+ | No |
| Apache Hive 3.1.2+ | No |
| Apache Spark 3+ | No |
| ClickHouse | No |
| Cloudera Impala 3.1+ | No |
| Cloudera Impala 3.1+ with Native Driver | No |
| Cloudera Impala with Native Driver | No |
| DataVirtuality | No |
| Databricks | Sí |
| Denodo 7 | No |
| Denodo 8 & 9 | No |
| Dremio | No |
| Dremio 11+ | No |
| Exasol | No |
| Google BigQuery Legacy SQL | No |
| Google BigQuery Standard SQL | Sí |
| Google Cloud PostgreSQL | Sí |
| Google Cloud SQL | No |
| Google Spanner | No |
| Greenplum | Sí |
| HyperSQL | No |
| IBM Netezza | No |
| MariaDB | No |
| Microsoft Azure PostgreSQL | Sí |
| Microsoft Azure SQL Database | No |
| Microsoft Azure Synapse Analytics | Sí |
| Microsoft SQL Server 2008+ | No |
| Microsoft SQL Server 2012+ | No |
| Microsoft SQL Server 2016 | No |
| Microsoft SQL Server 2017+ | No |
| MongoBI | No |
| MySQL | Sí |
| MySQL 8.0.12+ | Sí |
| Oracle | No |
| Oracle ADWC | No |
| PostgreSQL 9.5+ | Sí |
| PostgreSQL pre-9.5 | Sí |
| PrestoDB | No |
| PrestoSQL | No |
| SAP HANA | No |
| SAP HANA 2+ | No |
| SingleStore | No |
| SingleStore 7+ | No |
| Snowflake | Sí |
| Teradata | No |
| Trino | No |
| Vector | No |
| Vertica | Sí |
Crear PDTs
Para convertir una tabla derivada en una tabla derivada persistente (PDT), debes definir una estrategia de persistencia para la tabla. Para optimizar el rendimiento, también debes añadir una estrategia de optimización.
Estrategias de persistencia
Looker puede gestionar la persistencia de una tabla derivada o, en el caso de los dialectos que admiten vistas materializadas, tu base de datos puede hacerlo mediante vistas materializadas.
Para que una tabla derivada sea persistente, añade uno de los siguientes parámetros a la definición de derived_table:
- Parámetros de persistencia gestionados por Looker:
- Parámetros de persistencia gestionados por la base de datos:
Con las estrategias de persistencia basadas en activadores (datagroup_trigger, sql_trigger_value y interval_trigger), Looker mantiene la PDT en la base de datos hasta que se activa para volver a compilarse. Cuando se activa la PDT, Looker la vuelve a compilar para sustituir la versión anterior. Esto significa que, con las PDTs basadas en activadores, los usuarios no tendrán que esperar a que se cree la PDT para obtener respuestas a las consultas de Exploración de la PDT.
datagroup_trigger
Los grupos de datos son el método más flexible para crear persistencia. Si has definido un datagroup con sql_trigger o interval_trigger, puedes usar el parámetro datagroup_trigger para iniciar la recompilación de tus tablas derivadas persistentes (PDTs).
Looker mantiene el PDT en la base de datos hasta que se activa su grupo de datos. Cuando se activa el grupo de datos, Looker vuelve a compilar el PDT para sustituir la versión anterior. Esto significa que, en la mayoría de los casos, los usuarios no tendrán que esperar a que se cree el PDT. Si un usuario solicita datos del PDT mientras se está creando y los resultados de la consulta no están en la caché, Looker devolverá datos del PDT actual hasta que se cree el nuevo. Consulta Almacenar en caché las consultas para obtener una descripción general de los grupos de datos.
Consulta la sección El regenerador de Looker para obtener más información sobre cómo crea el regenerador las PDTs.
sql_trigger_value
El parámetro sql_trigger_value activa la regeneración de una tabla derivada persistente (PDT) basada en una instrucción SQL que proporciones. Si el resultado de la instrucción SQL es diferente del valor anterior, se vuelve a generar el PDT. De lo contrario, el PDT se mantendrá en la base de datos. Esto significa que, en la mayoría de los casos, los usuarios no tendrán que esperar a que se cree el PDT. Si un usuario solicita datos del PDT mientras se está creando y los resultados de la consulta no están en la caché, Looker devolverá datos del PDT actual hasta que se cree el nuevo PDT.
Consulta la sección El regenerador de Looker para obtener más información sobre cómo crea el regenerador las PDTs.
interval_trigger
El parámetro interval_trigger activa la regeneración de una tabla derivada persistente (PDT) en función de un intervalo de tiempo que proporciones, como "24 hours" o "60 minutes". Al igual que el parámetro sql_trigger, esto significa que, normalmente, el PDT se compilará previamente cuando los usuarios lo consulten. Si un usuario solicita datos del PDT mientras se está creando y los resultados de la consulta no están en la caché, Looker devolverá datos del PDT actual hasta que se cree el nuevo PDT.
persist_for
Otra opción es usar el parámetro persist_for para definir el tiempo que debe almacenarse la tabla derivada antes de que se marque como caducada, de modo que ya no se utilice en las consultas y se elimine de la base de datos.
Una persist_fortabla derivada persistente (PDT) se crea cuando un usuario ejecuta una consulta en ella por primera vez. A continuación, Looker mantiene el PDT en la base de datos durante el periodo especificado en el parámetro persist_for del PDT. Si un usuario consulta el PDT en el plazo de persist_for, Looker usa los resultados almacenados en caché, si es posible, o ejecuta la consulta en el PDT.
Transcurrido el persist_for, Looker borra el PDT de tu base de datos y lo vuelve a compilar la próxima vez que un usuario lo consulte, lo que significa que la consulta tendrá que esperar a que se vuelva a compilar.
El regenerador de Looker no vuelve a compilar automáticamente los PDTs que usan persist_for, excepto en el caso de una cascada de PDTs dependientes. Cuando una tabla persist_for forma parte de una cascada de dependencias con PDTs basados en activadores (PDTs que usan la estrategia de persistencia datagroup_trigger, interval_trigger o sql_trigger_value), el regenerador monitorizará y volverá a compilar la tabla persist_for para volver a compilar otras tablas de la cascada. Consulta la sección Cómo crea Looker tablas derivadas en cascada de esta página.
materialized_view: yes
Las vistas materializadas te permiten usar la funcionalidad de tu base de datos para conservar las tablas derivadas en tu proyecto de Looker. Si el dialecto de tu base de datos admite vistas materializadas y tu conexión de Looker tiene activado el interruptor Habilitar PDTs, puedes crear una vista materializada especificando materialized_view: yes en una tabla derivada. Las vistas materializadas se admiten tanto en tablas derivadas nativas como en tablas derivadas basadas en SQL.
Al igual que una tabla derivada persistente (PDT), una vista materializada es el resultado de una consulta que se almacena como una tabla en el esquema Scratch de tu base de datos. La diferencia clave entre un PDT y una vista materializada es la forma en que se actualizan las tablas:
- En el caso de los PDTs, la estrategia de persistencia se define en Looker y la persistencia la gestiona Looker.
- En el caso de las vistas materializadas, la base de datos se encarga de mantener y actualizar los datos de la tabla.
Por este motivo, la función de vista materializada requiere un conocimiento avanzado de tu dialecto y sus funciones. En la mayoría de los casos, la base de datos actualizará la vista materializada cada vez que detecte datos nuevos en las tablas que consulta la vista materializada. Las vistas materializadas son óptimas para situaciones que requieren datos en tiempo real.
Consulta la página de documentación del parámetro materialized_view para obtener información sobre los dialectos admitidos, los requisitos y las consideraciones importantes.
Estrategias de optimización
Como las tablas derivadas persistentes (PDTs) se almacenan en tu base de datos, debes optimizarlas con las siguientes estrategias, según lo admita tu dialecto:
Por ejemplo, para añadir persistencia al ejemplo de tabla derivada, puedes configurarla para que se vuelva a compilar cuando se active el grupo de datos orders_datagroup y añadir índices en customer_id y first_order, de la siguiente manera:
view: customer_order_summary {
derived_table: {
explore_source: orders {
...
}
datagroup_trigger: orders_datagroup
indexes: ["customer_id", "first_order"]
}
}
Si no añade un índice (o un equivalente para su dialecto), Looker le advertirá de que debe hacerlo para mejorar el rendimiento de las consultas.
Casos prácticos de PDTs
Las tablas derivadas persistentes (PDTs) son útiles porque pueden mejorar el rendimiento de una consulta al conservar los resultados de la consulta en una tabla.
Como práctica recomendada general, los desarrolladores deben intentar modelar los datos sin usar PDTs hasta que sea absolutamente necesario.
En algunos casos, los datos se pueden optimizar de otras formas. Por ejemplo, añadir un índice o cambiar el tipo de datos de una columna puede resolver un problema sin necesidad de crear un PDT. Analiza los planes de ejecución de las consultas lentas con la herramienta Explain de SQL Runner.
Además de reducir el tiempo de consulta y la carga de la base de datos en las consultas que se ejecutan con frecuencia, hay otros casos prácticos para los PDTs, como los siguientes:
También puede usar un PDT para definir una clave principal en los casos en los que no haya una forma razonable de identificar una fila única en una tabla como clave principal.
Usar PDTs para probar optimizaciones
Puedes usar PDTs para probar diferentes opciones de indexación, distribución y otras opciones de optimización sin necesidad de recibir mucha asistencia de tus administradores de bases de datos o desarrolladores de ETL.
Supongamos que tienes una tabla, pero quieres probar diferentes índices. El LookML inicial de la vista puede ser similar al siguiente:
view: customer {
sql_table_name: warehouse.customer ;;
}
Para probar estrategias de optimización, puedes usar el parámetro indexes para añadir índices al LookML de esta forma:
view: customer {
# sql_table_name: warehouse.customer
derived_table: {
sql: SELECT * FROM warehouse.customer ;;
persist_for: "8 hours"
indexes: [customer_id, customer_name, salesperson_id]
}
}
Consulta la vista una vez para generar el PDT. Después, ejecuta las consultas de prueba y compara los resultados. Si los resultados son favorables, puedes pedirle a tu administrador de bases de datos o al equipo de ETL que añadan los índices a la tabla original.
No olvides volver a cambiar el código de vista para quitar la prueba.
Usar PDTs para combinar o agregar datos previamente
Puede ser útil combinar o agregar datos previamente para ajustar la optimización de las consultas en el caso de volúmenes elevados o varios tipos de datos.
Por ejemplo, supongamos que quiere crear una consulta de clientes por cohorte en función de cuándo hicieron su primer pedido. Esta consulta puede ser costosa si se ejecuta varias veces cada vez que se necesiten los datos en tiempo real. Sin embargo, puedes calcular la consulta solo una vez y, después, reutilizar los resultados con un PDT:
view: customer_order_facts {
derived_table: {
sql: SELECT
c.customer_id,
MIN(o.order_date) OVER (PARTITION BY c.customer_id) AS first_order_date,
MAX(o.order_date) OVER (PARTITION BY c.customer_id) AS most_recent_order_date,
COUNT(o.order_id) OVER (PARTITION BY c.customer_id) AS lifetime_orders,
SUM(o.order_value) OVER (PARTITION BY c.customer_id) AS lifetime_value,
RANK() OVER (PARTITION BY c.customer_id ORDER BY o.order_date ASC) AS order_sequence,
o.order_id
FROM warehouse.customer c LEFT JOIN warehouse.order o ON c.customer_id = o.customer_id
;;
sql_trigger_value: SELECT CURRENT_DATE ;;
indexes: [customer_id, order_id, order_sequence, first_order_date]
}
}
Tablas derivadas en cascada
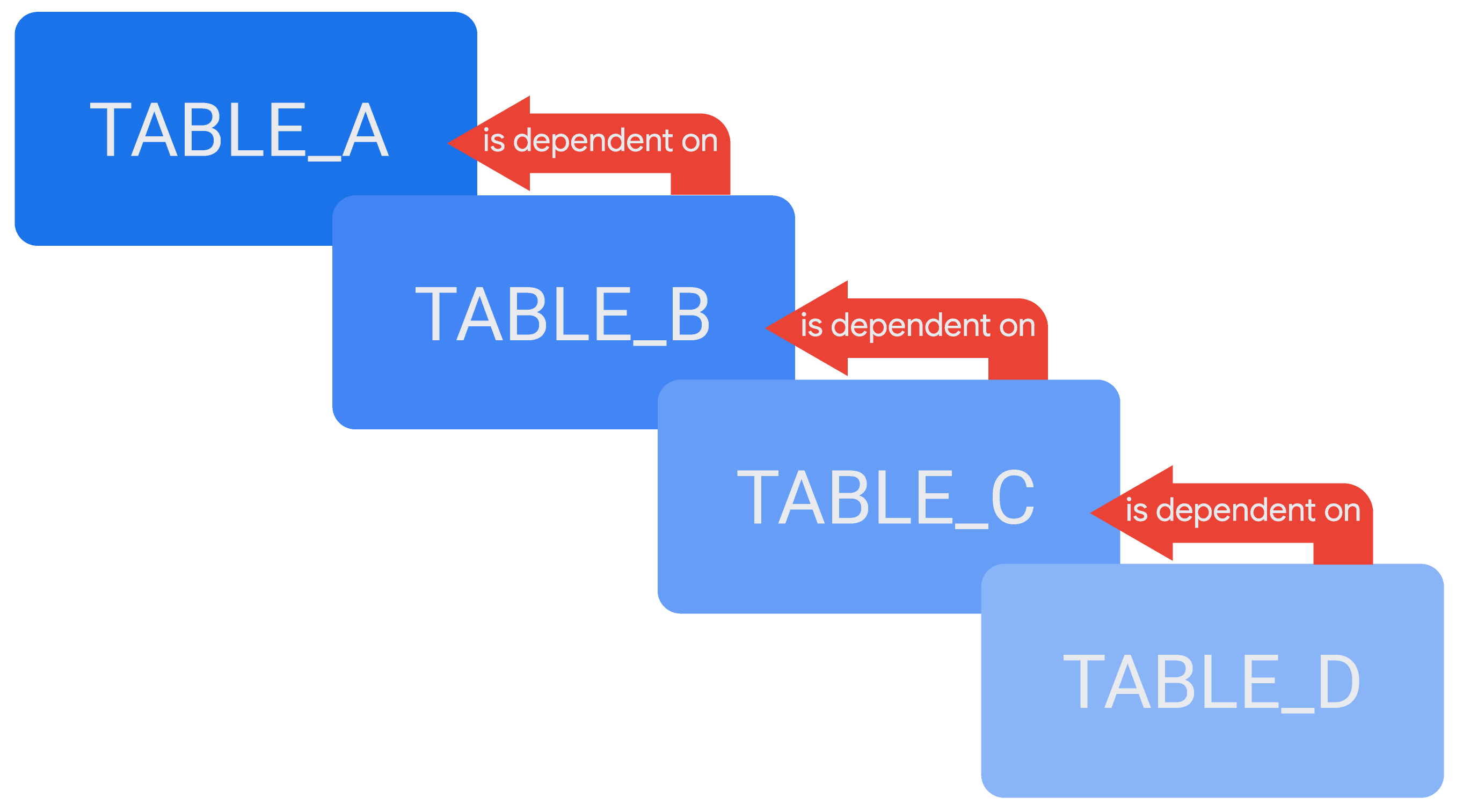
Es posible hacer referencia a una tabla derivada en la definición de otra, lo que crea una cadena de tablas derivadas en cascada o tablas derivadas persistentes (PDTs) en cascada, según corresponda. Un ejemplo de tablas derivadas en cascada sería una tabla, TABLE_D, que depende de otra tabla, TABLE_C, mientras que TABLE_C depende de TABLE_B y TABLE_B depende de TABLE_A.
Sintaxis para hacer referencia a una tabla derivada
Para hacer referencia a una tabla derivada en otra tabla derivada, usa esta sintaxis:
`${derived_table_or_view_name.SQL_TABLE_NAME}`
En este formato, SQL_TABLE_NAME es una cadena literal. Por ejemplo, puedes hacer referencia a la tabla derivada clean_events con esta sintaxis:
`${clean_events.SQL_TABLE_NAME}`
Puedes usar la misma sintaxis para hacer referencia a una vista de LookML. En este caso, SQL_TABLE_NAME es una cadena literal.
En el siguiente ejemplo, el clean_events PDT se crea a partir de la tabla events de la base de datos. El PDT clean_events omite las filas no deseadas de la tabla de la base de datos events. A continuación, se muestra una segunda PDT. La PDT event_summary es un resumen de la PDT clean_events. La tabla event_summary se regenera cada vez que se añaden filas a clean_events.
La event_summary PDT y la clean_events PDT son PDTs en cascada, donde event_summary depende de clean_events (ya que event_summary se define mediante la clean_events PDT). Este ejemplo concreto se podría hacer de forma más eficiente en una sola tabla derivada, pero es útil para mostrar las referencias de tablas derivadas.
view: clean_events {
derived_table: {
sql:
SELECT *
FROM events
WHERE type NOT IN ('test', 'staff') ;;
datagroup_trigger: events_datagroup
}
}
view: events_summary {
derived_table: {
sql:
SELECT
type,
date,
COUNT(*) AS num_events
FROM
${clean_events.SQL_TABLE_NAME} AS clean_events
GROUP BY
type,
date ;;
datagroup_trigger: events_datagroup
}
}
Aunque no siempre es necesario, cuando haces referencia a una tabla derivada de esta forma, suele ser útil crear un alias para la tabla con este formato:
${derived_table_or_view_name.SQL_TABLE_NAME} AS derived_table_or_view_name
En el ejemplo anterior se hace lo siguiente:
${clean_events.SQL_TABLE_NAME} AS clean_events
Es útil usar un alias porque, en segundo plano, las PDTs se denominan con códigos largos en tu base de datos. En algunos casos (especialmente con las cláusulas ON), es posible que se te olvide que debes usar la sintaxis ${derived_table_or_view_name.SQL_TABLE_NAME} para recuperar este nombre largo. Un alias puede ayudar a evitar este tipo de errores.
Cómo crea Looker tablas derivadas en cascada
En el caso de las tablas derivadas temporales en cascada, si los resultados de la consulta de un usuario no están en la caché, Looker creará todas las tablas derivadas que se necesiten para la consulta. Si tienes un TABLE_D cuya definición contiene una referencia a TABLE_C, entonces TABLE_D depende de TABLE_C. Esto significa que, si consultas TABLE_D y la consulta no está en la caché de Looker, Looker volverá a compilar TABLE_D. Pero primero debe reconstruir TABLE_C.
Imaginemos un caso en el que hay tablas derivadas temporales en cascada, donde TABLE_D depende de TABLE_C, que depende de TABLE_B, que depende de TABLE_A. Si Looker no tiene resultados válidos para una consulta en TABLE_C en la caché, Looker creará todas las tablas que necesite para la consulta. Por lo tanto, Looker creará TABLE_A, luego TABLE_B y, por último, TABLE_C:

En este caso, TABLE_A debe terminar de generarse para que Looker pueda empezar a generar TABLE_B, y TABLE_B debe terminar de generarse para que Looker pueda empezar a generar TABLE_C. Cuando TABLE_C termine, Looker proporcionará los resultados de la consulta. Como TABLE_D no es necesario para responder a esta consulta, Looker no volverá a compilar TABLE_D en este momento.
Consulta la página de documentación del parámetro datagroup para ver un ejemplo de una situación en la que se usan PDTs en cascada que utilizan el mismo grupo de datos.
La lógica básica es la misma para los PDTs: Looker creará cualquier tabla que se necesite para responder a una consulta, hasta llegar al final de la cadena de dependencias. Sin embargo, con las PDTs, a menudo las tablas ya existen y no es necesario volver a crearlas. Con las consultas de usuario estándar en PDTs en cascada, Looker vuelve a compilar los PDTs de la cascada solo si no hay ninguna versión válida de los PDTs en la base de datos. Si quieres forzar una recompilación de todas las PDTs de una cascada, puedes recompilar manualmente las tablas de una consulta a través de un Explorar.
Es importante tener en cuenta que, en el caso de una cascada de PDTs, un PDT dependiente consulta el PDT del que depende. Esto es especialmente importante en el caso de las PDTs que usan la estrategia persist_for. Normalmente, los persist_for PDTs se crean cuando un usuario los consulta, permanecen en la base de datos hasta que finaliza su intervalo de persist_for y, después, no se vuelven a crear hasta que un usuario los vuelva a consultar. Sin embargo, si un persist_for PDT forma parte de una cascada con PDTs basados en activadores (PDTs que usan la estrategia de persistencia datagroup_trigger, interval_trigger o sql_trigger_value), el persist_for PDT se consulta cada vez que se vuelven a compilar sus PDTs dependientes. Por lo tanto, en este caso, el persist_for PDT se volverá a compilar según la programación de sus PDTs dependientes. Esto significa que los persist_for PDTs pueden verse afectados por la estrategia de persistencia de sus elementos dependientes.
Reconstruir manualmente las tablas persistentes de una consulta
Los usuarios pueden seleccionar la opción Recompilar tablas derivadas y ejecutar en el menú de un Explore para anular la configuración de persistencia y recompilar todas las tablas derivadas persistentes (PDTs) y las tablas agregadas necesarias para la consulta actual del Explore:
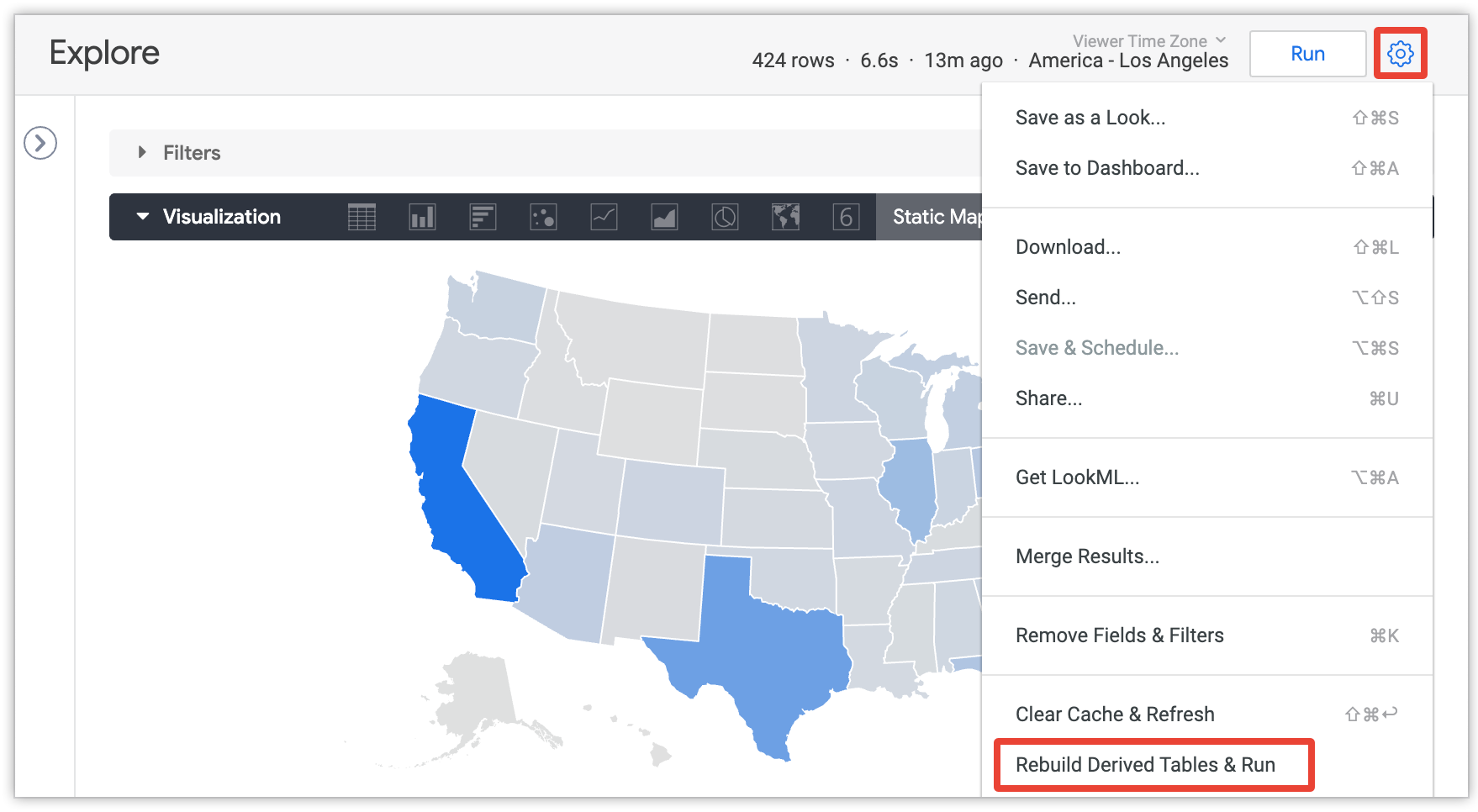
Esta opción solo la pueden ver los usuarios con el permiso develop y solo después de que se haya cargado la consulta Explorar.
La opción Reconstruir tablas derivadas y ejecutar reconstruye todas las tablas persistentes (todas las PDTs y las tablas agregadas) que se necesitan para responder a la consulta, independientemente de su estrategia de persistencia. Esto incluye las tablas agregadas y las PDTs de la consulta actual, así como las tablas agregadas y las PDTs a las que se hace referencia en las tablas agregadas y las PDTs de la consulta actual.
En el caso de las PDTs incrementales, la opción Recompilar tablas derivadas y ejecutar activa la compilación de un nuevo incremento. Con los PDTs incrementales, un incremento incluye el periodo especificado en el parámetro increment_key, así como el número de periodos anteriores especificados en el parámetro increment_offset, si los hay. Consulta la página de documentación sobre PDTs incrementales para ver algunos ejemplos de situaciones que muestran cómo se compilan los PDTs incrementales en función de su configuración.
En el caso de los PDTs en cascada, esto significa volver a generar todas las tablas derivadas de la cascada, empezando por la parte superior. Es lo mismo que cuando consultas una tabla en una cascada de tablas derivadas temporales:
Ten en cuenta lo siguiente sobre la recompilación manual de tablas derivadas:
- En el caso del usuario que inicia la operación Recompilar tablas derivadas y ejecutar, la consulta esperará a que se recompilen las tablas antes de cargar los resultados. Las consultas de otros usuarios seguirán usando las tablas actuales. Una vez que se hayan vuelto a crear las tablas persistentes, todos los usuarios utilizarán las tablas reconstruidas. Aunque este proceso se ha diseñado para evitar que se interrumpan las consultas de otros usuarios mientras se reconstruyen las tablas, estos usuarios podrían verse afectados por la carga adicional en tu base de datos. Si te encuentras en una situación en la que activar una recompilación durante el horario de trabajo podría suponer una carga inaceptable para tu base de datos, es posible que tengas que comunicar a tus usuarios que nunca deben recompilar determinados PDTs o tablas agregadas durante esas horas.
Si un usuario está en modo Desarrollo y la exploración se basa en una tabla de desarrollo, la operación Reconstruir tablas derivadas y ejecutar reconstruirá la tabla de desarrollo, no la de producción, de la exploración. Sin embargo, si la opción Explorar en modo de desarrollo usa la versión de producción de una tabla derivada, se volverá a compilar la tabla de producción. Consulta Tablas persistentes en el modo Desarrollo para obtener información sobre las tablas de desarrollo y las de producción.
En las instancias alojadas en Looker, si la tabla derivada tarda más de una hora en volver a generarse, no se volverá a generar correctamente y la sesión del navegador se agotará. Consulta la sección Tiempos de espera y colas de las consultas de la página de documentación Ajustes de administrador - Consultas para obtener más información sobre los tiempos de espera que pueden afectar a los procesos de Looker.
Tablas persistentes en el modo de desarrollo
Looker tiene algunos comportamientos especiales para gestionar las tablas persistentes en el modo Desarrollo.
Si consultas una tabla persistente en el modo Desarrollo sin hacer ningún cambio en su definición, Looker consultará la versión de producción de esa tabla. Si haces un cambio en la definición de la tabla que afecte a los datos de la tabla o a la forma en que se consulta, se creará una nueva versión de desarrollo de la tabla la próxima vez que la consultes en el modo Desarrollo. Tener una tabla de desarrollo de este tipo te permite probar los cambios sin molestar a los usuarios.
Qué lleva a Looker a crear una tabla de desarrollo
Cuando es posible, Looker usa la tabla de producción para responder a las consultas, independientemente de si estás en el modo Desarrollo o no. Sin embargo, hay ciertos casos en los que Looker no puede usar la tabla de producción para las consultas en el modo Desarrollo:
- Si tu tabla persistente tiene un parámetro que reduce su conjunto de datos para funcionar más rápido en el modo Desarrollo
- Si has hecho cambios en la definición de tu tabla persistente que afectan a los datos de la tabla
Looker creará una tabla de desarrollo si estás en modo Desarrollo y consultas una tabla derivada basada en SQL que se haya definido con una cláusula WHERE condicional con instrucciones if prod y if dev.
En el caso de las tablas persistentes que no tienen un parámetro para acotar el conjunto de datos en el modo Desarrollo, Looker usa la versión de producción de la tabla para responder a las consultas en el modo Desarrollo, a menos que cambies la definición de la tabla y después consultes la tabla en el modo Desarrollo. Esto se aplica a cualquier cambio en la tabla que afecte a los datos de la tabla o a la forma en que se consulta.
Estos son algunos ejemplos de los tipos de cambios que harán que Looker cree una versión de desarrollo de una tabla persistente (Looker creará la tabla solo si la consultas después de hacer estos cambios):
- Cambiar la consulta en la que se basa la tabla persistente, como modificar los parámetros
explore_source,sql,query,sql_createocreate_processen la propia tabla persistente o en cualquier tabla obligatoria (en el caso de las tablas derivadas en cascada) - Cambiar la estrategia de persistencia de la tabla, como modificar los parámetros
datagroup_trigger,sql_trigger_value,interval_triggeropersist_forde la tabla - Cambiar el nombre de un
viewde una tabla derivada - Cambiar el
increment_keyo elincrement_offsetde una PDT incremental - Cambiar el
connectionque usa el modelo asociado
En el caso de los cambios que no modifiquen los datos de la tabla ni afecten a la forma en que Looker consulta la tabla, Looker no creará una tabla de desarrollo. El parámetro publish_as_db_view es un buen ejemplo: en el modo Desarrollo, si solo cambia el ajuste publish_as_db_view de una tabla derivada, Looker no tiene que volver a compilar la tabla derivada, por lo que no creará una tabla de desarrollo.
Durante cuánto tiempo conserva Looker las tablas de desarrollo
Independientemente de la estrategia de persistencia real de la tabla, Looker trata las tablas persistentes de desarrollo como si tuvieran una estrategia de persistencia de persist_for: "24 hours". Looker lo hace para asegurarse de que las tablas de desarrollo no se conserven durante más de un día, ya que un desarrollador de Looker puede consultar muchas iteraciones de una tabla durante el desarrollo y cada vez que se crea una nueva tabla de desarrollo. Para evitar que las tablas de desarrollo desordenen la base de datos, Looker aplica la estrategia persist_for: "24 hours" para asegurarse de que las tablas se limpien con frecuencia de la base de datos.
De lo contrario, Looker creará tablas derivadas persistentes (PDTs) y tablas agregadas en el modo Desarrollo de la misma forma que crea tablas persistentes en el modo Producción.
Si una tabla de desarrollo se conserva en tu base de datos cuando implementas cambios en una tabla derivada persistente o en una tabla agregada, Looker puede usar a menudo la tabla de desarrollo como tabla de producción para que tus usuarios no tengan que esperar a que se cree la tabla cuando la consulten.
Ten en cuenta que, cuando implementes los cambios, es posible que la tabla deba volver a compilarse para poder consultarla en producción, en función de la situación:
- Si han pasado más de 24 horas desde que consultaste la tabla en el modo Desarrollo, la versión de desarrollo de la tabla se etiquetará como caducada y no se usará en las consultas. Puedes comprobar si hay PDTs sin compilar en el IDE de Looker o en la pestaña Desarrollo de la página Tablas derivadas persistentes. Si tienes PDTs sin compilar, puedes consultarlos en el modo Desarrollo justo antes de hacer los cambios para que la tabla de desarrollo esté disponible para usarse en producción.
- Si una tabla persistente tiene el parámetro
dev_filters(para tablas derivadas nativas) o la cláusula condicionalWHEREque usa las instruccionesif prodyif dev(para tablas derivadas basadas en SQL), la tabla de desarrollo no se puede usar como versión de producción, ya que la versión de desarrollo tiene un conjunto de datos abreviado. Si es así, después de desarrollar la tabla y antes de implementar los cambios, puede comentar el parámetrodev_filterso la cláusula condicionalWHEREy, a continuación, consultar la tabla en el modo Desarrollo. A continuación, Looker creará una versión completa de la tabla que se podrá usar en producción cuando implementes los cambios.
De lo contrario, si implementas los cambios cuando no hay ninguna tabla de desarrollo válida que se pueda usar como tabla de producción, Looker volverá a crear la tabla la próxima vez que se consulte en el modo de producción (en el caso de las tablas persistentes que usan la estrategia persist_for) o la próxima vez que se ejecute el regenerador (en el caso de las tablas persistentes que usan datagroup_trigger, interval_trigger o sql_trigger_value).
Comprobar si hay PDTs sin compilar en el modo Desarrollo
Si una tabla de desarrollo se conserva en tu base de datos cuando implementas cambios en una tabla derivada persistente (PDT) o en una tabla agregada, Looker puede usar a menudo la tabla de desarrollo como tabla de producción para que tus usuarios no tengan que esperar a que se cree la tabla cuando la consulten. Para obtener más información, consulta las secciones Cuánto tiempo conserva Looker las tablas de desarrollo y Qué hace que Looker cree una tabla de desarrollo de esta página.
Por lo tanto, lo ideal es que todas tus PDTs se creen cuando implementes en producción para que las tablas se puedan usar inmediatamente como versiones de producción.
Puedes comprobar si hay PDTs sin compilar en tu proyecto en el panel Estado del proyecto. En el IDE de Looker, haz clic en el icono Estado del proyecto para abrir el panel Estado del proyecto. A continuación, haz clic en el botón Validar estado de PDT.

Si hay PDTs sin compilar, el panel Estado del proyecto los mostrará:
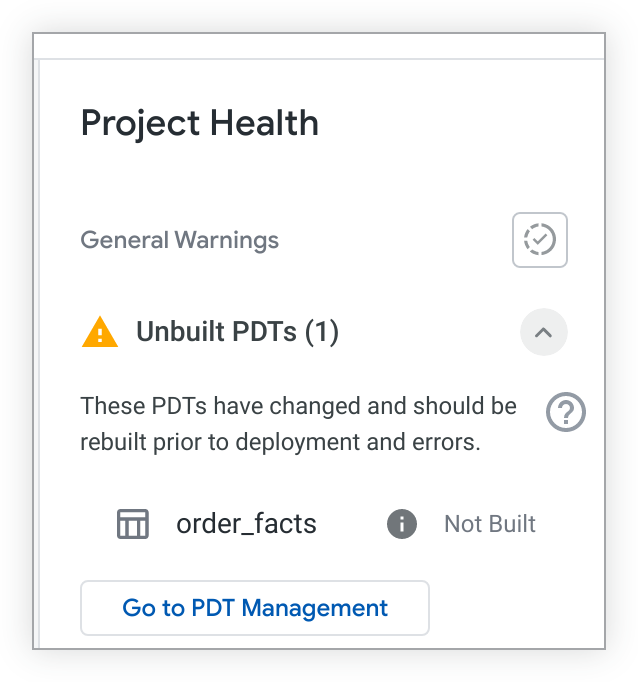
Si tienes permiso see_pdts, puedes hacer clic en el botón Ir a Gestión de TPD. Looker abrirá la pestaña Desarrollo de la página Tablas derivadas persistentes y filtrará los resultados para que solo se muestre tu proyecto de LookML. Desde ahí, puedes ver qué PDTs de desarrollo se han compilado y cuáles no, así como acceder a otra información para solucionar problemas. Para obtener más información, consulta la página de documentación Ajustes de administrador: tablas derivadas persistentes.
Una vez que hayas identificado un PDT sin compilar en tu proyecto, puedes compilar una versión de desarrollo abriendo un Explorar que consulte la tabla y, a continuación, usando la opción Recompilar tablas derivadas y ejecutar del menú Explorar. Consulta la sección Reconstruir manualmente las tablas persistentes de una consulta de esta página.
Compartir y limpiar tablas
En cualquier instancia de Looker, Looker compartirá las tablas persistentes entre los usuarios si las tablas tienen la misma definición y el mismo ajuste de método de persistencia. Además, si la definición de una tabla deja de existir, Looker la marca como caducada.
Esto tiene varias ventajas:
- Si no has hecho ningún cambio en una tabla en el modo Desarrollo, tus consultas usarán las tablas de producción. Esto ocurre a menos que la tabla sea una tabla derivada basada en SQL definida mediante una cláusula
WHEREcondicional con las instruccionesif prodyif dev. Si la tabla se define con una cláusulaWHEREcondicional, Looker creará una tabla de desarrollo si consultas la tabla en el modo Desarrollo. En el caso de las tablas derivadas nativas con el parámetrodev_filters, Looker tiene la lógica para usar la tabla de producción y responder a las consultas en el modo Desarrollo, a menos que cambie la definición de la tabla y, a continuación, consulte la tabla en el modo Desarrollo. - Si dos desarrolladores hacen el mismo cambio en una tabla mientras están en el modo Desarrollo, compartirán la misma tabla de desarrollo.
- Una vez que envíes los cambios del modo Desarrollo al modo Producción, la antigua definición de producción dejará de existir, por lo que la antigua tabla de producción se marcará como caducada y se eliminará.
- Si decides descartar los cambios del modo Desarrollo, esa definición de tabla ya no existirá, por lo que las tablas de desarrollo innecesarias se marcarán como caducadas y se eliminarán.
Trabajar más rápido en el modo Desarrollo
Hay situaciones en las que la tabla derivada persistente (PDT) que estás creando tarda mucho tiempo en generarse, lo que puede llevar mucho tiempo si estás probando muchos cambios en el modo Desarrollo. En estos casos, puedes pedirle a Looker que cree versiones más pequeñas de una tabla derivada cuando estés en el modo Desarrollo.
En las tablas derivadas nativas, puede usar el subparámetro dev_filters de explore_source para especificar filtros que solo se apliquen a las versiones de desarrollo de la tabla derivada:
view: e_faa_pdt {
derived_table: {
...
datagroup_trigger: e_faa_shared_datagroup
explore_source: flights {
dev_filters: [flights.event_date: "90 days"]
filters: [flights.event_date: "2 years", flights.airport_name: "Yucca Valley Airport"]
column: id {}
column: airport_name {}
column: event_date {}
}
}
...
}
Este ejemplo incluye un parámetro dev_filters que filtra los datos de los últimos 90 días y un parámetro filters que filtra los datos de los últimos dos años y del aeropuerto de Yucca Valley.
El parámetro dev_filters funciona junto con el parámetro filters para que todos los filtros se apliquen a la versión de desarrollo de la tabla. Si tanto dev_filters como filters especifican filtros para la misma columna, dev_filters tiene prioridad en la versión de desarrollo de la tabla. En este ejemplo, la versión de desarrollo de la tabla filtrará los datos de los últimos 90 días del aeropuerto de Yucca Valley.
En el caso de las tablas derivadas basadas en SQL, Looker admite una cláusula WHERE condicional con diferentes opciones para las versiones de producción (if prod) y de desarrollo (if dev) de la tabla:
view: my_view {
derived_table: {
sql:
SELECT
columns
FROM
my_table
WHERE
-- if prod -- date > '2000-01-01'
-- if dev -- date > '2020-01-01'
;;
}
}
En este ejemplo, la consulta incluirá todos los datos a partir del año 2000 cuando esté en el modo de producción, pero solo los datos a partir del 2020 cuando esté en el modo de desarrollo. Si usas esta función de forma estratégica para limitar el conjunto de resultados y aumentar la velocidad de las consultas, podrás validar los cambios del modo Desarrollo mucho más fácilmente.
Cómo crea Looker PDTs
Una vez que se ha definido una tabla derivada persistente (PDT) y se ejecuta por primera vez o el regenerador la activa para que se vuelva a compilar según su estrategia de persistencia, Looker seguirá estos pasos:
- Usa el SQL de la tabla derivada para crear una instrucción CREATE TABLE AS SELECT (o CTAS) y ejecútala. Por ejemplo, para volver a generar un PDT llamado
customer_orders_facts:CREATE TABLE tmp.customer_orders_facts AS SELECT ... FROM ... WHERE ... - Ejecuta las instrucciones para crear los índices cuando se cree la tabla.
- Cambia el nombre de la tabla de LC$.. ("Looker Create") a LR$.. ("Looker Read") para indicar que la tabla está lista para usarse.
- Elimina cualquier versión anterior de la tabla que ya no se deba usar.
Hay algunas implicaciones importantes:
- El SQL que forma la tabla derivada debe ser válido dentro de una instrucción CTAS.
- Los alias de columna del conjunto de resultados de la instrucción SELECT deben ser nombres de columna válidos.
- Los nombres que se usan al especificar la distribución, las claves de ordenación y los índices deben ser los nombres de las columnas que se indican en la definición SQL de la tabla derivada, no los nombres de los campos que se definen en LookML.
El regenerador de Looker
El regenerador de Looker comprueba el estado e inicia las recompilaciones de las tablas persistentes activadas. Una tabla con activador de persistencia es una tabla derivada persistente (PDT) o una tabla agregada que usa un activador como estrategia de persistencia:
- En las tablas que usan
sql_trigger_value, el activador es una consulta que se especifica en el parámetrosql_trigger_valuede la tabla. El regenerador de Looker activa una recompilación de la tabla cuando el resultado de la comprobación de la consulta de activación más reciente es diferente del resultado de la comprobación de la consulta de activación anterior. Por ejemplo, si tu tabla derivada se persiste con la consulta SQLSELECT CURDATE(), el regenerador de Looker volverá a compilar la tabla la próxima vez que compruebe el activador después de que cambie la fecha. - En las tablas que usan
interval_trigger, el activador es un periodo que se especifica en el parámetrointerval_triggerde la tabla. El regenerador de Looker activa una recompilación de la tabla cuando ha transcurrido el tiempo especificado. - En el caso de las tablas que usan
datagroup_trigger, el activador puede ser una consulta especificada en el parámetrosql_triggerdel grupo de datos asociado o una duración especificada en el parámetrointerval_triggerdel grupo de datos.
El regenerador de Looker también inicia recompilaciones de tablas persistentes que usan el parámetro persist_for, pero solo cuando la tabla persist_for es una cascada de dependencia de una tabla persistente activada. En este caso, el regenerador de Looker iniciará la recompilación de una tabla persist_for, ya que es necesaria para recompilar las demás tablas de la cascada. De lo contrario, el regenerador no monitoriza las tablas persistentes que usan la estrategia persist_for.
El ciclo de regeneración de Looker comienza a intervalos regulares que configura el administrador de Looker en el ajuste Programación de mantenimiento de la conexión de la base de datos (el valor predeterminado es un intervalo de cinco minutos). Sin embargo, el regenerador de Looker no inicia un nuevo ciclo hasta que haya completado todas las comprobaciones y las recompilaciones de PDT del último ciclo. Esto significa que, si tienes compilaciones de PDT de larga duración, es posible que el ciclo del regenerador de Looker no se ejecute con la frecuencia definida en el ajuste Programación de mantenimiento. Otros factores pueden afectar al tiempo necesario para volver a crear las tablas, tal como se describe en la sección Consideraciones importantes para implementar tablas persistentes de esta página.
En los casos en los que no se pueda compilar un PDT, el regenerador puede intentar volver a compilar la tabla en el siguiente ciclo del regenerador:
- Si el ajuste Reintentar compilaciones de PDT fallidas está habilitado en tu conexión de base de datos, el regenerador de Looker intentará volver a compilar la tabla durante el siguiente ciclo del regenerador, aunque no se cumpla la condición de activación de la tabla.
- Si el ajuste Reintentar compilaciones de PDT fallidas está inhabilitado, el regenerador de Looker no intentará volver a compilar la tabla hasta que se cumpla la condición de activación del PDT.
Si un usuario solicita datos de la tabla persistente mientras se está creando y los resultados de la consulta no están en la caché, Looker comprueba si la tabla sigue siendo válida. Es posible que la tabla anterior no sea válida si no es compatible con la nueva versión de la tabla. Esto puede ocurrir si la nueva tabla tiene una definición diferente, usa una conexión de base de datos distinta o se ha creado con una versión diferente de Looker. Si la tabla sigue siendo válida, Looker devolverá datos de la tabla hasta que se cree la nueva. De lo contrario, si la tabla no es válida, Looker proporcionará los resultados de la consulta una vez que se haya vuelto a crear la tabla.
Consideraciones importantes para implementar tablas persistentes
Teniendo en cuenta la utilidad de las tablas persistentes (PDTs y tablas agregadas), es posible acumular muchas de ellas en tu instancia de Looker. Es posible crear una situación en la que el regenerador de Looker necesite crear muchas tablas al mismo tiempo. Sobre todo en el caso de las tablas en cascada o las tablas de larga duración, puedes crear una situación en la que las tablas tarden mucho en volver a generarse o en la que los usuarios experimenten un retraso al obtener los resultados de las consultas de una tabla mientras la base de datos trabaja para generar la tabla.
El regenerador de Looker comprueba los activadores de PDT para ver si debe volver a compilar las tablas persistentes activadas. El ciclo de regeneración se establece a intervalos regulares que configura el administrador de Looker en el ajuste Programación de mantenimiento de la conexión de la base de datos (el valor predeterminado es un intervalo de cinco minutos).
Hay varios factores que pueden afectar al tiempo necesario para volver a crear las tablas:
- Es posible que el administrador de Looker haya cambiado el intervalo de las comprobaciones del activador del regenerador mediante el ajuste Mantenimiento programado de la conexión de tu base de datos.
- El regenerador de Looker no inicia un nuevo ciclo hasta que ha completado todas las comprobaciones y las recompilaciones de PDT del último ciclo. Por lo tanto, si tienes compilaciones de PDT de larga duración, es posible que el ciclo de regeneración de Looker no sea tan frecuente como el ajuste Programación de mantenimiento.
- De forma predeterminada, el regenerador puede iniciar la recompilación de una tabla agregada o PDT a la vez a través de una conexión. Un administrador de Looker puede ajustar el número permitido de recompilaciones simultáneas del regenerador mediante el campo Número máximo de conexiones de compilación de PDT en la configuración de una conexión.
- Todas las PDTs y las tablas agregadas activadas por el mismo
datagroupse volverán a compilar durante el mismo proceso de regeneración. Esto puede suponer una carga pesada si tienes muchas tablas que usan el grupo de datos, ya sea directamente o como resultado de dependencias en cascada.
Además de las consideraciones anteriores, hay algunas situaciones en las que no deberías añadir persistencia a una tabla derivada:
- Cuándo se ampliarán las tablas derivadas: cada ampliación de una tabla derivada persistente creará una copia de la tabla en tu base de datos.
- Cuando las tablas derivadas usan filtros con plantilla o parámetros de Liquid: no se admite la persistencia en las tablas derivadas que usan filtros con plantilla o parámetros de Liquid.
- Cuando se crean tablas derivadas nativas a partir de Exploraciones que usan atributos de usuario con
access_filterso consql_always_where, se crearán copias de la tabla en tu base de datos para cada valor de atributo de usuario posible que se haya especificado. - Cuando los datos subyacentes cambian con frecuencia y el dialecto de tu base de datos no admite PDTs incrementales.
- Cuando el coste y el tiempo necesarios para crear TPDs son demasiado altos.
En función del número y la complejidad de las tablas persistentes de tu conexión de Looker, la cola puede contener muchas tablas persistentes que deban comprobarse y recompilarse en cada ciclo, por lo que es importante tener en cuenta estos factores al implementar tablas derivadas en tu instancia de Looker.
Gestionar PDTs a gran escala mediante la API
Monitorizar y gestionar las tablas derivadas persistentes (PDTs) que se actualizan con diferentes programaciones se vuelve cada vez más complejo a medida que creas más PDTs en tu instancia. Puedes usar la integración de Apache Airflow de Looker para gestionar tus programaciones de PDT junto con otros procesos de ETL y ELT.
Monitorizar y solucionar problemas de PDTs
Si usas tablas derivadas persistentes (PDTs), sobre todo PDTs en cascada, es útil ver el estado de tus PDTs. Puedes usar la página de administrador Tablas derivadas persistentes de Looker para ver el estado de tus PDTs. Para obtener más información, consulta la página de documentación Ajustes de administrador: tablas derivadas persistentes.
Cuando intentes solucionar problemas de PDTs:
- Presta especial atención a la distinción entre las tablas de desarrollo y las tablas de producción al investigar el registro de eventos de PDT.
- Verifica que el ajuste Base de datos temporal de tu conexión de Looker coincida con tu esquema o base de datos temporal. Si el ajuste Base de datos temporal de la conexión no coincide con el esquema temporal de tu base de datos, actualiza el ajuste Base de datos temporal para que Looker pueda almacenar tablas derivadas persistentes en tu base de datos.
- Determina si hay problemas con todos los PDTs o solo con uno. Si hay un problema con uno de ellos, es probable que se deba a un error de LookML o SQL.
- Determina si los problemas con el PDT se corresponden con las horas en las que está programado para volver a compilarse.
- Asegúrese de que todas las consultas
sql_trigger_valuese evalúen correctamente y de que devuelvan solo una fila y una columna. En el caso de las PDTs basadas en SQL, puedes hacerlo ejecutándolas en SQL Runner. (Al aplicar unLIMIT, se protege frente a las consultas descontroladas). Para obtener más información sobre cómo usar SQL Runner para depurar tablas derivadas, consulta la publicación de la comunidad Usar SQL Runner para probar tablas derivadas . - En el caso de las PDTs basadas en SQL, usa SQL Runner para verificar que el SQL de la PDT se ejecuta sin errores. (Asegúrate de aplicar un
LIMITen SQL Runner para que los tiempos de consulta sean razonables). - En las tablas derivadas basadas en SQL, no uses expresiones de tabla comunes (CTEs). Si usas CTEs con DTs, se crean instrucciones
WITHanidadas que pueden provocar que los PDTs fallen sin previo aviso. En su lugar, usa el SQL de tu CTE para crear una tabla derivada secundaria y haz referencia a ella desde tu primera tabla derivada con la sintaxis${derived_table_or_view_name.SQL_TABLE_NAME}. - Comprueba que existan todas las tablas de las que depende el PDT problemático (ya sean tablas normales o PDTs) y que se puedan consultar.
- Asegúrate de que las tablas de las que depende el PDT problemático no tengan ningún bloqueo compartido o exclusivo. Para que Looker pueda compilar correctamente una tabla derivada persistente, debe obtener un bloqueo exclusivo en la tabla que se va a actualizar. Esto entrará en conflicto con otros bloqueos compartidos o exclusivos de la tabla. Looker no podrá actualizar la PDT hasta que se hayan quitado todos los demás bloqueos. Lo mismo ocurre con los bloqueos exclusivos de la tabla a partir de la que Looker está creando una PDT. Si hay un bloqueo exclusivo en una tabla, Looker no podrá obtener un bloqueo compartido para ejecutar consultas hasta que se elimine el bloqueo exclusivo.
- Usa el botón Mostrar procesos en SQL Runner. Si hay un gran número de procesos activos, esto podría ralentizar los tiempos de consulta.
- Monitoriza los comentarios de la consulta. Consulta la sección Consultar comentarios de PDTs de esta página.
Consultar comentarios de PDTs
Los administradores de bases de datos pueden diferenciar las consultas normales de las que generan tablas derivadas persistentes (PDTs). Looker añade comentarios a la instrucción CREATE TABLE ... AS SELECT ... que incluye el modelo y la vista de LookML de la PDT, así como un identificador único (slug) de la instancia de Looker. Si el PDT se genera en nombre de un usuario en el modo Desarrollo, los comentarios indicarán el ID del usuario. Los comentarios de generación de PDT siguen este patrón:
-- Building `<view_name>` in dev mode for user `<user_id>` on instance `<instance_slug>`
CREATE TABLE `<table_name>` SELECT ...
-- finished `<view_name>` => `<table_name>`
El comentario de generación de PDT aparecerá en la pestaña SQL de una Exploración si Looker ha tenido que generar un PDT para la consulta de la Exploración. El comentario aparecerá en la parte superior de la instrucción SQL.

Por último, el comentario de generación de PDT aparece en el campo Mensaje de la pestaña Información de la ventana emergente Detalles de la consulta de cada consulta de la página de administración Consultas.
Recompilar PDTs después de un fallo
Cuando se produce un error en una tabla derivada persistente (PDT), esto es lo que ocurre cuando se consulta esa PDT:
- Looker usará los resultados de la caché si se ha ejecutado la misma consulta anteriormente. Para obtener una explicación sobre cómo funciona, consulta la página de documentación Almacenar en caché las consultas.
- Si los resultados no están en la caché, Looker extraerá los resultados de la tabla derivada persistente de la base de datos, si existe una versión válida de la tabla derivada persistente.
- Si no hay ningún PDT válido en la base de datos, Looker intentará volver a compilarlo.
- Si no se puede volver a compilar la tabla derivada persistente, Looker devolverá un error en una consulta. El regenerador de Looker intentará volver a compilar el PDT la próxima vez que se consulte o la próxima vez que la estrategia de persistencia del PDT active una recompilación.
Con los PDTs en cascada, se aplica la misma lógica, pero con las siguientes diferencias:
- Si no se puede generar una tabla, no se podrán generar las PDTs de la cadena de dependencias.
- Una PDT dependiente consulta esencialmente la PDT de la que depende, por lo que la estrategia de persistencia de una tabla puede activar la recompilación de las PDTs que se encuentran más arriba en la cadena.
Volviendo al ejemplo anterior de tablas en cascada, donde TABLE_D depende de TABLE_C, que depende de TABLE_B, que depende de TABLE_A:
Si TABLE_B falla, se aplicará todo el comportamiento estándar (no en cascada) de TABLE_B:
- Si se consulta
TABLE_B, Looker primero intenta usar la caché para devolver resultados. - Si este intento falla, Looker intentará usar una versión anterior de la tabla, si es posible.
- Si este intento también falla, Looker intenta volver a compilar la tabla.
- Por último, si no se puede volver a compilar
TABLE_B, Looker devolverá un error.
Looker volverá a intentar compilar TABLE_B cuando se consulte la tabla o cuando la estrategia de persistencia de la tabla vuelva a activar una compilación.
Lo mismo se aplica a las personas dependientes de TABLE_B. Por lo tanto, si no se puede crear TABLE_B y hay una consulta en TABLE_C, se produce la siguiente secuencia:
- Looker intentará usar la caché de la consulta en
TABLE_C. - Si los resultados no están en la caché, Looker intentará obtenerlos de
TABLE_Cen la base de datos. - Si no hay ninguna versión válida de
TABLE_C, Looker intentará volver a compilarTABLE_C, lo que crea una consulta enTABLE_B. - A continuación, Looker intentará volver a compilar
TABLE_B(lo que no funcionará siTABLE_Bno se ha corregido). - Si no se puede volver a compilar
TABLE_B, tampoco se podrá volver a compilarTABLE_C, por lo que Looker devolverá un error en la consulta deTABLE_C. - A continuación, Looker intentará volver a compilar
TABLE_Csegún su estrategia de persistencia habitual o la próxima vez que se consulte la PDT (lo que incluye la próxima vez queTABLE_Dintente compilarse, ya queTABLE_Ddepende deTABLE_C).
Una vez que resuelvas el problema con TABLE_B, TABLE_B y cada una de las tablas dependientes intentarán volver a compilarse según sus estrategias de persistencia o la próxima vez que se consulten (lo que incluye la próxima vez que una PDT dependiente intente volver a compilarse). O bien, si se ha creado una versión de desarrollo de los PDTs en cascada en el modo Desarrollo, las versiones de desarrollo se pueden usar como los nuevos PDTs de producción. Para saber cómo funciona, consulta la sección Tablas persistentes en el modo Desarrollo de esta página. También puede usar una exploración para ejecutar una consulta en TABLE_D y, a continuación, volver a crear manualmente los PDTs de la consulta, lo que forzará la recompilación de todos los PDTs que suban por la cascada de dependencias.
Mejorar el rendimiento de las PDT
Cuando crea tablas derivadas persistentes (PDTs), el rendimiento puede ser un problema. Sobre todo si la tabla es muy grande, la consulta puede ser lenta, al igual que ocurre con cualquier tabla grande de tu base de datos.
Para mejorar el rendimiento, puede filtrar los datos o controlar cómo se ordenan e indexan los datos de la PDT.
Añadir filtros para limitar el conjunto de datos
En el caso de los conjuntos de datos especialmente grandes, tener muchas filas ralentizará las consultas en una tabla derivada persistente (PDT). Si normalmente solo consultas datos recientes, te recomendamos que añadas un filtro a la cláusula WHERE de tu PDT que limite la tabla a 90 días o menos de datos. De esta forma, solo se añadirán datos relevantes a la tabla cada vez que se reconstruya, por lo que las consultas se ejecutarán mucho más rápido. Después, puede crear un PDT independiente de mayor tamaño para el análisis histórico, de modo que pueda hacer consultas rápidas de datos recientes y consultar datos antiguos.
Usar indexes o sortkeys y distribution
Cuando creas una PDT grande, indexar la tabla (en dialectos como MySQL o Postgres) o añadir claves de ordenación y distribución (en Redshift) puede mejorar el rendimiento.
Normalmente, es mejor añadir el parámetro indexes en los campos de ID o de fecha.
En Redshift, suele ser mejor añadir el parámetro sortkeys en los campos de ID o de fecha, y el parámetro distribution en el campo que se usa para la unión.
Configuración recomendada para mejorar el rendimiento
Los siguientes ajustes controlan cómo se ordenan e indexan los datos de la tabla derivada persistente (PDT). Estos ajustes son opcionales, pero muy recomendables:
- En Redshift y Aster, use el parámetro
distributionpara especificar el nombre de la columna cuyo valor se utiliza para distribuir los datos en un clúster. Cuando se unen dos tablas por la columna especificada en el parámetrodistribution, la base de datos puede encontrar los datos de unión en el mismo nodo, por lo que se minimiza la E/S entre nodos. - En Redshift, asigna el valor
allal parámetrodistribution_stylepara indicar a la base de datos que mantenga una copia completa de los datos en cada nodo. Se suele usar para minimizar la E/S entre nodos cuando se combinan tablas relativamente pequeñas. Asigna el valorevena este campo para indicar a la base de datos que distribuya los datos de forma uniforme por todo el clúster sin usar una columna de distribución. Este valor solo se puede especificar cuando no se especificadistribution. - En Redshift, usa el parámetro
sortkeys. Los valores especifican qué columnas de la PDT se usan para ordenar los datos en el disco y facilitar las búsquedas. En Redshift, puedes usarsortkeysoindexes, pero no ambos. - En la mayoría de las bases de datos, usa el parámetro
indexes. Los valores especifican qué columnas de la PDT están indexadas. En Redshift, los índices se usan para generar claves de ordenación intercaladas.