派生テーブルとは、クエリ結果をデータベース内の物理テーブルのように使用できるクエリのことです。ネイティブ派生テーブルは、LookML 用語を使用して定義したクエリに基づいています。これは、SQL 用語を使用して定義したクエリに基づく SQL ベースの派生テーブルとは異なります。SQLベースの派生テーブルと比較すると、ネイティブ派生テーブルでは、データをモデル化するときの読みやすさと理解しやすさが向上します。 詳しくは、Looker の派生テーブルのドキュメント ページにあるネイティブ派生テーブルと SQL ベースの派生テーブルセクションをご覧ください。
ネイティブ派生テーブルと SQL ベースの派生テーブルはどちらも、ビューレベルで derived_table パラメータを使用して LookML で定義されます。ただし、ネイティブ派生テーブルでは、SQL クエリを作成する必要がありません。 代わりに、explore_source パラメータを使用して、派生テーブルのベースとなる Explore、必要な列、その他の必要な特性を指定します。
SQL Runner を使用して派生テーブルを作成するドキュメント ページに説明されている方法で、Looker で SQL Runner クエリから派生テーブル LookML を作成することもできます。
Explore を使用したネイティブ派生テーブルの定義の開始
Looker の Explore を使うと、派生テーブルのすべてまたは大半に対して LookML を生成できます。 まずは Explore を作成し、派生テーブルに含めるすべてのフィールドを選択します。 その後、ネイティブ派生テーブル LookML を生成するには、次の手順に沿って操作します。
[Explore アクション] の歯車アイコンを選択し、[Get LookML] を選択します。
[派生テーブル] タブをクリックすると、Explore のネイティブ派生テーブルを作成するための LookML が表示されます。
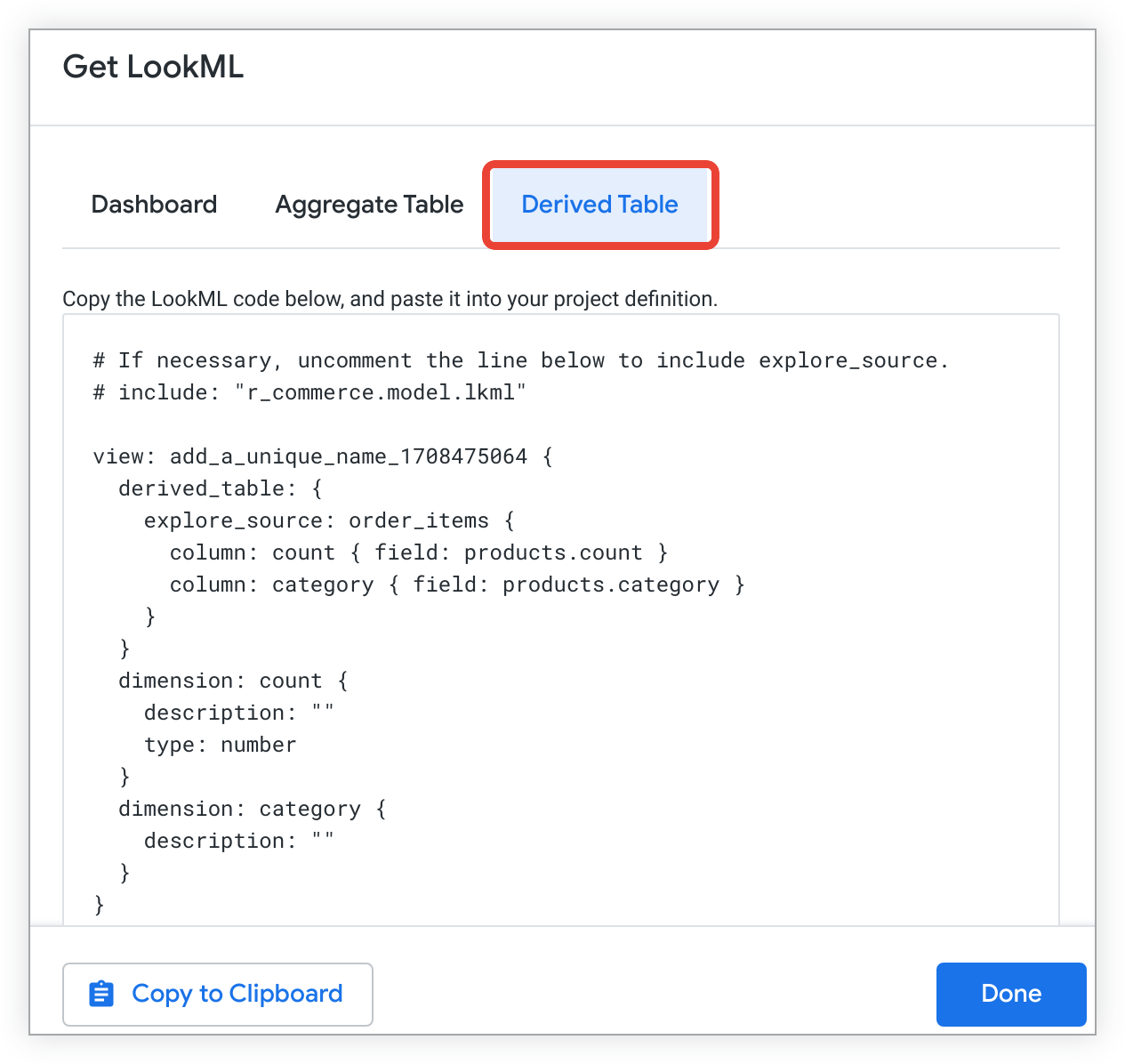
その LookML をコピーします。
生成された LookML をコピーしたら、ビューファイルにペーストします。
Development Mode で、プロジェクト ファイルに移動します。
Looker IDE のプロジェクトファイルリストの上部にある [+] をクリックし、[ビューを作成] を選択します。または、フォルダのメニューをクリックし、メニューから [ビューを作成] を選択して、フォルダ内にファイルを作成することもできます。
内容がわかりやすいビュー名を設定します。
必要に応じて、列名の変更、派生列の指定、フィルタの追加を行います。
Explore で
type: countの measure を使用する場合、可視化された値には、Count という単語ではなく、ビュー名でラベルが付けられます。混乱を避けるため、ビュー名を複数形にします。ビュー名を変更するには、ビジュアリゼーション設定の [シリーズ] で [完全なフィールド名を表示] を選択するか、ビュー名の複数形でview_labelパラメータを使用します。
LookML でのネイティブ派生テーブルの定義
SQL とネイティブ LookML のいずれの方法で宣言された派生テーブルを使用する場合でも、derived_table クエリの出力は一連の列を含むテーブルになります。派生テーブルが SQL で記述される場合、出力列名は SQL クエリによって暗黙的に示されます。 たとえば、次の SQL クエリの出力列は user_id、lifetime_number_of_orders、lifetime_customer_value になります。
SELECT
user_id
, COUNT(DISTINCT order_id) as lifetime_number_of_orders
, SUM(sale_price) as lifetime_customer_value
FROM order_items
GROUP BY 1
Looker では、クエリは Explore に基づき、メジャー フィールドとディメンション フィールドが含まれます。また、適用可能なフィルタも追加され、ソート順を指定することもできます。 ネイティブ派生テーブルには、これらすべての要素に加え、その列の出力名が含まれます。
次の簡単な例では、user_id、lifetime_customer_value、lifetime_number_of_orders の 3 つの列を含む派生テーブルを生成します。クエリを SQL で手動で記述する必要はありません。代わりに、Looker が指定の Explore order_items と Explore のフィールドの一部(order_items.user_id、order_items.total_revenue、order_items.order_count)を使用してクエリを作成します。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
}
include ステートメントを使用した参照フィールドの有効化
ネイティブ派生テーブルのビューファイルで、explore_source パラメータを使用して Explore を指し、ネイティブ派生テーブルの列やその他の特性を定義します。
ネイティブ派生テーブルのビューファイルでは、Explore の定義を含むファイルを指すのに include パラメータを使用する必要はありません。include ステートメントがない場合、Looker IDE はネイティブ派生テーブルの作成時にフィールド名をautosuggestしたり、フィールド参照を検証したりしません。代わりに、LookML バリデータを使用して、ネイティブ派生テーブルで参照しているフィールドを検証できます。
ただし、Looker IDE で自動候補と即時フィールド検証を有効にする場合や、名前が同じか循環参照の可能性がある複数の Explore を含む複雑な LookML プロジェクトがある場合は、include パラメータを使用して Explore の定義の場所を指します。
Explore はモデルファイル内で定義されることが多いですが、ネイティブ派生テーブルの場合は、Explore 用に別のファイルを作成する方が明確になります。LookML Explore ファイルのファイル拡張子は .explore.lkml です。詳しくは、Explore ファイルの作成のドキュメントをご覧ください。この方法によって、ネイティブ派生テーブルのビューファイル内に、モデルファイル全体ではなく、単一の Explore ファイルを含めることができます。
別の Explore ファイルを作成し、include パラメータを使用してネイティブ派生テーブルのビューファイルで Explore ファイルを指す場合は、LookML ファイルが次の要件を満たしていることを確認してください。
- ネイティブ派生テーブルのビューファイルには次のように Explore のファイルを含める必要があります。例:
include: "/explores/order_items.explore.lkml"
- Explore のファイルには次のように必要なビューファイルを含める必要があります。例:
include: "/views/order_items.view.lkml"include: "/views/users.view.lkml"
- モデルには次のように Explore のファイルを含める必要があります。例:
include: "/explores/order_items.explore.lkml"
ネイティブ派生テーブルの列の定義
前の例に示すように、column を使用して派生テーブルの出力列を指定します。
列名の指定
user_id 列については、列名は元の Explore 内の指定されたフィールド名に一致します。
元のExploreのフィールド名ではなく、出力テーブルの別の列名を使用したい場合もよくあることでしょう。 上記の例では、order_items Explore を使用してユーザー別のライフタイム バリューの計算を生成しています。出力テーブルでは、total_revenue は実際には顧客の lifetime_customer_value です。
column 宣言では、入力フィールドとは異なる出力名の宣言に対応しています。たとえば、次のコードは、「フィールド order_items.total_revenue から lifetime_value という名前の出力列を作成します」ということを Looker に指示しています。
column: lifetime_value {
field: order_items.total_revenue
}
暗黙的な列名
列の宣言で field パラメータを省略した場合、その列は <explore_name>.<field_name> と解釈されます。たとえば、explore_source: order_items を指定した場合は、
column: user_id {
field: order_items.user_id
}
上記は次と等しくなります。
column: user_id {}
計算値の派生列の作成
derived_column パラメータを追加すると、explore_source パラメータの Explore に存在しない列を指定できます。各 derived_column パラメータには、値の構築方法を指定する sql パラメータがあります。
sql 計算では、column パラメータで指定した任意の列を使用できます。派生列に集計関数を含めることはできませんが、テーブルの単一行に対して実行される計算を含めることができます。
次の例では、前の例と同じ派生テーブルを生成します。ただし、計算された average_customer_order 列が追加されます。この列は、ネイティブ派生テーブルの lifetime_customer_value 列と lifetime_number_of_orders 列から計算されています。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
SQLウィンドウ関数の使用
一部のデータベース言語はウィンドウ関数をサポートしており、特にシーケンス番号、主キー、実行中の累積合計、その他の便利な複数行の計算を行うことができます。プライマリ クエリが実行された後、derived_column 宣言が個別に実行されます。
データベース ダイアレクトがウィンドウ関数に対応している場合には、ネイティブ派生テーブルでこれを使用できます。 目的のウィンドウ関数を含む sql パラメータで derived_column パラメータを作成します。値を参照する際には、ネイティブ派生テーブルで定義された列名を使用する必要があります。
次の例では、user_id、order_id、created_time の各列を含むネイティブ派生テーブルを作成します。その後、SQL ROW_NUMBER() ウィンドウ関数を含む派生列を使用して、お客様の注文のシーケンス番号を含む列を計算します。
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
ネイティブ派生テーブルへのフィルタの追加
過去 90 日間のお客様の値の派生テーブルを作成するとします。前の例と同じ計算を行いますが、過去 90 日間の購入のみを含めます。
過去 90 日間のトランザクションをフィルタするフィルタを derived_table に追加するだけです。派生テーブルの filters パラメータは、フィルタされた measure の作成に使用するものと同じ構文を使用します。
view: user_90_day_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: number_of_orders_90_day {
field: order_items.order_count
}
column: customer_value_90_day {
field: order_items.total_revenue
}
filters: [order_items.created_date: "90 days"]
}
}
# Add define view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: number_of_orders_90_day {
type: number
}
dimension: customer_value_90_day {
type: number
}
}
Looker が派生テーブルの SQL を書き込むと、フィルタが WHERE 句に追加されます。
また、explore_source の dev_filters サブパラメータを、ネイティブ派生テーブルとともに使用できます。dev_filters パラメータを使用すると、Looker が派生テーブルの開発バージョンにのみ適用するフィルタを指定できます。こうすることで、フィルタによって絞り込まれた、より小さなテーブルを作成して繰り返しやテストを行えるため、変更のたびにテーブル全体が作成されるのを待たなくてすむようになります。
dev_filters パラメータは filters パラメータと連動して動作し、すべてのフィルタがテーブルの開発バージョンに適用されるようになります。dev_filters と filters の両方が同じ列のフィルタを指定した場合、テーブルの開発バージョンには dev_filters が優先されます。
詳しくは、Development Mode での作業の高速化をご覧ください。
テンプレート フィルタの使用
bind_filters を使用して、テンプレート フィルタを含めることができます。
bind_filters: {
to_field: users.created_date
from_field: filtered_lookml_dt.filter_date
}
これは基本的に sql ブロックで次のコードを使用する場合と同じです。
{% condition filtered_lookml_dt.filter_date %} users.created_date {% endcondition %}
to_field は、フィルタの適用先のフィールドです。to_field は、基盤となる explore_source のフィールドである必要があります。
実行時にフィルタが存在する場合、from_field はフィルタの取得先のフィールドを指定します。
上記の bind_filters の例では、Looker は、filtered_lookml_dt.filter_date フィールドに適用されたフィルタを取得して users.created_date フィールドに適用します。
また、explore_source の bind_all_filters サブパラメータを使用して、すべてのランタイム フィルタを Explore からネイティブ派生テーブルのサブクエリに渡すこともできます。詳しくは、explore_source パラメータのドキュメント ページをご覧ください。
ネイティブ派生テーブルのソートおよび制限
sorts: [order_items.count: desc]
limit: 10
Explore では基礎となるソートと異なる順で行が表示される場合があるので注意してください。
ネイティブ派生テーブルの異なるタイムゾーンへの変換
timezone サブパラメータを使用して、ネイティブ派生テーブルのタイムゾーンを指定できます。
timezone: "America/Los_Angeles"
timezone サブパラメータを使用すると、ネイティブ派生テーブルのすべての時間ベースのデータが指定したタイムゾーンに変換されます。サポートされているタイムゾーンのリストについては、timezone 値のドキュメント ページをご覧ください。
ネイティブ派生テーブルの定義でタイムゾーンを指定しない場合、ネイティブ派生テーブルは時間ベースのデータに対してタイムゾーン変換を行いません。代わりに、時間ベースのデータがデータベースのタイムゾーンのデフォルトとなります。
ネイティブ派生テーブルが永続的ではない場合、タイムゾーン値を "query_timezone" に設定して、現在実行中のクエリのタイムゾーンを自動的に使用できます。