Le validateur SQL d'intégration continue (CI) vérifie que les dimensions de vos explorations s'exécutent correctement par rapport à votre base de données. Pour ce faire, le validateur SQL exécute une série de requêtes sur les explorations de votre projet LookML.
Par défaut, le validateur SQL effectue les tâches suivantes :
- Pour chaque exploration de votre projet, le validateur SQL exécute une requête d'exploration qui inclut toutes les dimensions de l'exploration.
- Si Looker renvoie une erreur pour la requête d'exploration, le validateur SQL exécute ensuite une requête d'exploration distincte pour chaque dimension de l'exploration.
Si vous ne souhaitez pas que le validateur SQL teste chaque dimension dans chaque exploration, vous pouvez éventuellement effectuer une ou plusieurs des opérations suivantes :
- Configurez le validateur SQL pour n'interroger que certains Explorers.
- Configurez le validateur SQL pour exclure certaines explorations.
- Configurez le validateur SQL pour ignorer vos dimensions LookML définies avec
hidden: yes. - Ajoutez un commentaire ou un tag
ci: ignoreau LookML d'une dimension pour empêcher le validateur SQL d'inclure la dimension dans l'une de ses requêtes Explorer.
Pour en savoir plus sur les options que vous pouvez configurer lorsque vous créez ou modifiez une suite CI, consultez la section Options du validateur SQL de cette page. Pour savoir comment exécuter le validateur SQL, consultez la page de documentation Exécuter des suites d'intégration continue.
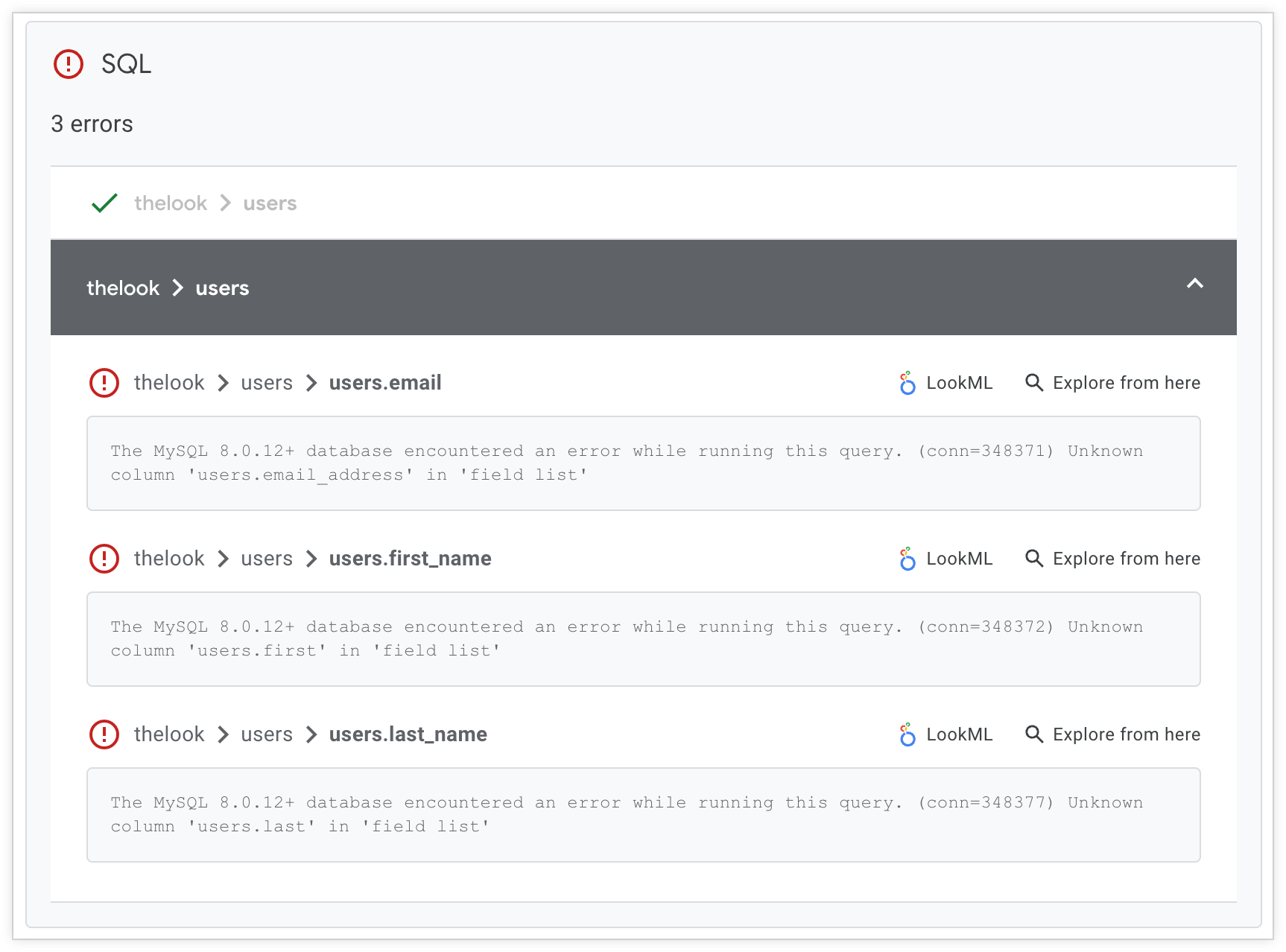
Sur la page des résultats de l'exécution, le validateur SQL affiche chaque erreur SQL, classée par dimension et par exploration, avec un lien vers le fichier LookML problématique et un lien "Explorer à partir d'ici" pour le débogage :
Consommation des ressources
Le validateur SQL est conçu pour consommer le moins de ressources possible dans Looker et dans votre entrepôt de données. Toutes les requêtes du validateur SQL incluent une clause LIMIT 0 et WHERE 1=2. Ces clauses indiquent effectivement au planificateur de requêtes de votre entrepôt de données de ne pas traiter les données, mais de vérifier la validité du code SQL.
Avec BigQuery, par exemple, ce type de requête est semblable à l'exécution d'une requête d'essai dans BigQuery. Pour BigQuery, les requêtes LIMIT 0 n'analysent pas les données. Vous ne devriez donc pas être facturé pour les requêtes exécutées par le validateur SQL.
Exclure des dimensions de la validation SQL
Vous pouvez exclure certaines dimensions de la validation SQL, comme celles qui dépendent d'un paramètre, car la valeur du paramètre sera nulle lors de la validation et entraînera toujours une erreur SQL.
Vous pouvez également exclure les dimensions qui ne comportent pas de paramètre sql, comme les dimensions type: distance, type: location ou type: duration.
Pour exclure une dimension de la validation SQL, vous pouvez modifier son LookML de deux manières :
Vous pouvez ajouter une instruction
ci: ignoredans le paramètretagsde la définition LookML de la dimension, comme indiqué dans l'exemple suivant :dimension: addresses { sql: ${TABLE}.addresses ;; tags: ["ci: ignore"] }Vous pouvez ajouter le commentaire
-- ci: ignoreau champsqldu fichier LookML de votre dimension, comme illustré dans l'exemple suivant :dimension: addresses { sql: -- ci: ignore ${TABLE}.addresses ;; }
Options du programme de validation SQL
Vous pouvez spécifier plusieurs options lorsque vous créez ou modifiez une suite d'intégration continue pour configurer la façon dont SQL Validator s'exécute. Les options sont décrites dans les sections suivantes de cette page :
- Explorations à interroger
- Explorations à exclure
- Échec rapide
- Ignorer les dimensions masquées
- Requêtes simultanées
- Validation incrémentielle
Explorations à interroger
Par défaut, le validateur SQL exécute la validation SQL sur tous les modèles et toutes les explorations de votre projet LookML.
Vous pouvez utiliser le champ Explorations à interroger pour spécifier les explorations et les modèles que vous souhaitez inclure dans la validation SQL.
Vous pouvez spécifier des Explorations au format suivant : model_name/explore_name
Veuillez noter les points suivants :
- Pour
model_name, utilisez le nom du fichier de modèle sans l'extension.model.lkml. Par exemple, pour spécifier le modèle défini dansthelook.model.lkml, vous devez saisirthelook. - Pour
explore_name, utilisezexplore_nameà partir du paramètre LookMLexplore. Par exemple, pour spécifier l'exploration définie commeexplore: usersdans votre projet LookML, vous devez saisirusers. - Vous pouvez créer une liste séparée par des virgules pour spécifier plusieurs explorations.
- Vous pouvez utiliser le caractère générique
*dansmodel_nameouexplore_name.
Voici quelques exemples :
Pour spécifier uniquement l'exploration Users définie avec
explore: usersdans le fichierthelook.model.lkml, saisissez ce qui suit :thelook/usersPour spécifier les explorations nommées
usersetordersdans le fichierthelook.model.lkml, vous devez saisir ce qui suit :thelook/users, thelook/ordersPour spécifier toutes les explorations dans
thelook.model.lkml, saisissez ce qui suit :thelook/*Pour spécifier chaque exploration nommée
usersdans tous les modèles de votre projet, saisissez ce qui suit :*/users
Explorations à exclure
Par défaut, le validateur SQL exécute la validation SQL sur tous les modèles et toutes les explorations de votre projet LookML.
Vous pouvez utiliser le champ Explorations à exclure pour spécifier les explorations et les modèles que vous souhaitez exclure de la validation SQL.
Vous pouvez spécifier des Explorations au format suivant : model_name/explore_name
Pour savoir comment spécifier des explorations pour le validateur SQL, consultez la section Explorations à interroger.
Les échecs rapides
Par défaut, le validateur SQL exécute une requête par exploration avec toutes les dimensions de la requête. Si cette requête Explore échoue, le validateur SQL exécutera ensuite une requête Explore pour chaque dimension de l'exploration individuellement.
Pour une validation plus rapide, vous pouvez activer l'option Échec rapide. Le validateur SQL n'exécutera alors que la requête initiale d'une exploration, c'est-à-dire celle qui contient toutes les dimensions à la fois. Si cette requête renvoie une erreur, le validateur SQL l'affichera dans les résultats de l'exécution de l'intégration continue et passera à la prochaine exploration à valider.
Si l'option Échec rapide est activée, la validation est généralement plus rapide. Toutefois, les résultats du validateur SQL n'affichent que la première erreur pour chaque exploration, même si plusieurs dimensions peuvent comporter des erreurs. Cela signifie qu'après avoir corrigé la première erreur, la prochaine exécution du validateur SQL peut afficher une erreur supplémentaire.
Ignorer les dimensions masquées
Activez le champ Ignorer les éléments masqués si vous souhaitez que le validateur SQL ignore les dimensions LookML que vos développeurs Looker ont définies avec hidden: yes. L'outil de validation SQL exclura ces dimensions de ses requêtes "Explorer" lors de la validation.
Simultanéité des requêtes
Par défaut, le validateur SQL n'exécute pas plus de 10 requêtes à la fois pour éviter de surcharger votre instance Looker. Vous pouvez utiliser le champ Nombre de requêtes simultanées pour spécifier un nombre maximal différent de requêtes que le validateur SQL peut exécuter simultanément.
La valeur maximale du champ Simultanéité des requêtes est limitée au paramètre Nombre maximal de requêtes simultanées pour cette connexion de votre connexion à la base de données.
Si vous constatez un ralentissement de votre instance Looker lors de la validation SQL, vous pouvez diminuer cette valeur.
Validation incrémentielle
La validation incrémentale est une méthode permettant de détecter les erreurs qui sont propres à une branche de développement spécifique et qui n'existent pas déjà dans celle de production. La validation incrémentielle aide les développeurs à trouver et à corriger les erreurs dont ils sont responsables sans être distraits par les erreurs existantes dans le projet. Elle peut également accélérer la validation, en particulier pour les projets LookML qui contiennent de nombreuses explorations.
Pour la validation incrémentielle, le validateur SQL n'exécute que les requêtes Explorer qui ont été modifiées entre une version de développement (la référence de base) et la version de production (la référence cible). Le validateur SQL ne renvoie que les erreurs propres à la version de développement, même si la version de production elle-même comporte des erreurs.
Dans les résultats du validateur, le validateur SQL indique chaque exploration qui a été ignorée, car son code SQL compilé n'a pas été modifié dans la branche ou le commit en cours de validation. Pour voir un exemple de résultats de validation incrémentielle, consultez Afficher les résultats de la validation incrémentielle.
Vous pouvez activer la validation incrémentielle pour le validateur SQL en cochant la case Erreurs incrémentielles uniquement dans la section Validateur SQL lorsque vous créez ou modifiez une suite d'intégration continue.
Notez les points suivants concernant la validation incrémentielle :
- Le paramètre de validation incrémentale n'est pas appliqué lorsque le programme de validation SQL valide la branche de production elle-même (par exemple, lorsque vous y effectuez manuellement des exécutions). Lors de la validation de la branche de production, le programme de validation SQL effectue une validation complète.
- Le mode Échec rapide n'est pas compatible avec les exécutions de validation incrémentale, car des requêtes de dimension individuelles sont nécessaires pour exposer les erreurs incrémentales spécifiques à une branche de développement du projet.