Présentation
Looker utilise une logique de reconnaissance des agrégats pour trouver la table la plus petite et la plus efficace disponible dans votre base de données afin d'exécuter une requête tout en conservant la précision.
Pour les très grandes tables de votre base de données, les développeurs Looker peuvent créer des tables de données agrégées plus petites, regroupées selon différentes combinaisons d'attributs. Les tables agrégées servent de tables récapitulatives ou de synthèse que Looker peut utiliser pour les requêtes chaque fois que possible, au lieu de la grande table d'origine. Lorsqu'elle est implémentée de manière stratégique, la fonction Aggregate Awareness peut accélérer la requête moyenne de plusieurs ordres de grandeur.
Par exemple, vous pouvez avoir une table de données à l'échelle du pétaoctet avec une ligne pour chaque commande passée sur votre site Web. À partir de cette base de données, vous pouvez créer un tableau agrégé avec le total de vos ventes quotidiennes. Si votre site Web reçoit 1 000 commandes par jour, votre tableau agrégé quotidien représentera chaque jour avec 999 lignes de moins que votre tableau d'origine. Vous pouvez créer une autre table agrégée avec les totaux des ventes mensuelles, qui sera encore plus efficace. Désormais, si un utilisateur exécute une requête sur les ventes quotidiennes ou hebdomadaires, Looker utilisera la table du total des ventes quotidiennes. Si un utilisateur exécute une requête sur les ventes annuelles et que vous ne disposez pas d'un tableau agrégé annuel, Looker utilisera la meilleure option suivante, à savoir le tableau agrégé des ventes mensuelles dans cet exemple.
Looker répond aux questions de vos utilisateurs avec les plus petites tables agrégées possible. Exemple :
- Pour une requête sur le total des ventes mensuelles, Looker utilise la table agrégée basée sur les ventes mensuelles (
sales_monthly_aggregate_table). - Pour une requête sur le total de chaque vente au cours d'une journée, il n'existe aucune table agrégée avec cette précision. Looker obtient donc les résultats de la requête à partir de la table de base de données d'origine (
orders_database). Toutefois, si vos utilisateurs exécutent souvent ce type de requête, vous pouvez créer une table agrégée pour celle-ci. - Pour une requête sur les ventes hebdomadaires, il n'existe pas de table agrégée hebdomadaire. Looker utilise donc la table agrégée basée sur les ventes quotidiennes (
sales_daily_aggregate_table), qui est la plus adaptée.
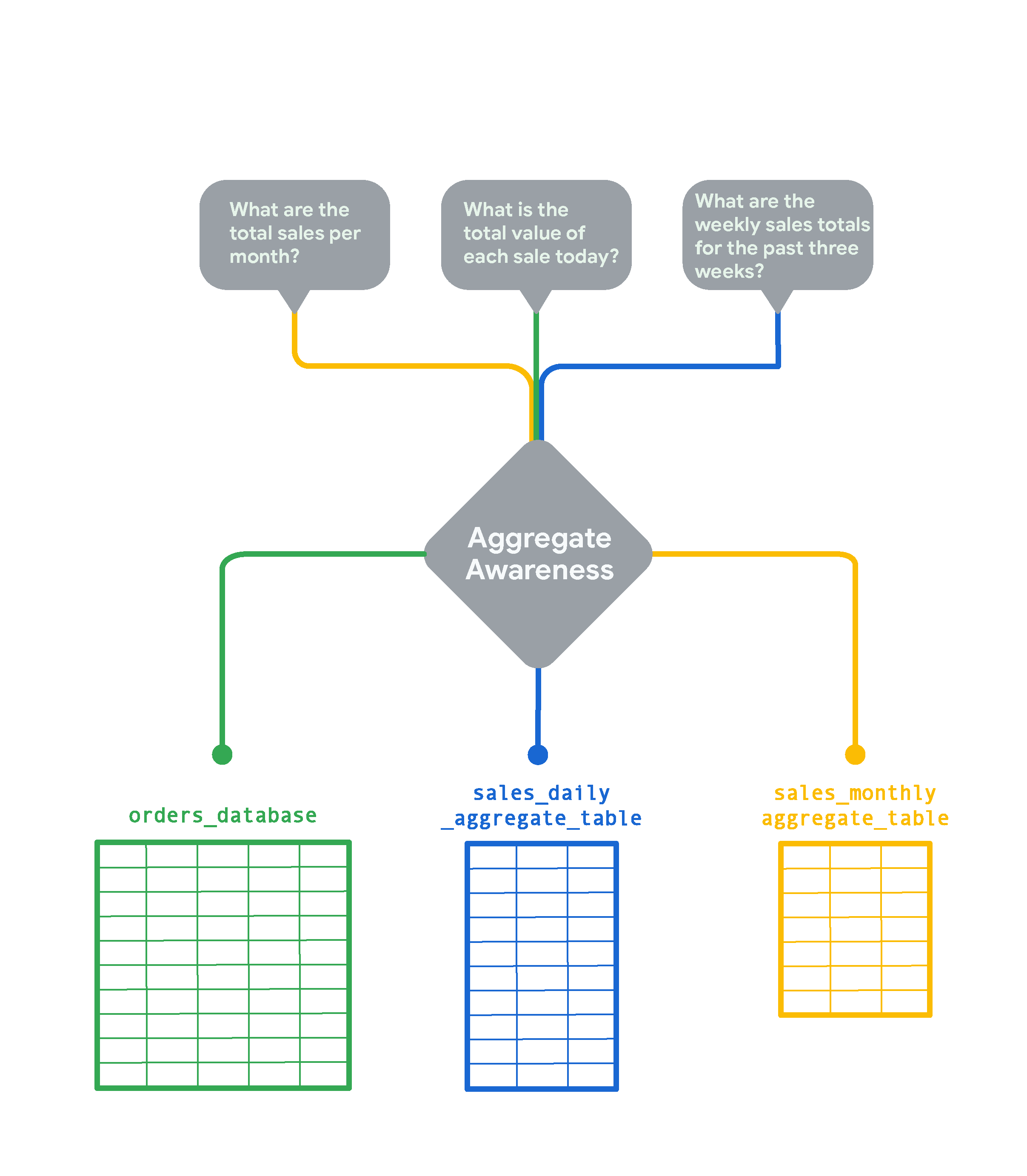
Grâce à la logique de reconnaissance des agrégats, Looker interroge le plus petit tableau agrégé possible pour répondre aux questions de vos utilisateurs. La table d'origine ne serait utilisée que pour les requêtes nécessitant une précision plus fine que celle que peuvent fournir les tables agrégées.
Il n'est pas nécessaire de joindre les tables agrégées ni de les ajouter à une exploration distincte. Au lieu de cela, Looker ajuste dynamiquement la clause FROM de la requête Explorer pour accéder à la table agrégée la plus adaptée à la requête. Cela signifie que vos analyses sont conservées et que les explorations peuvent être consolidées. Grâce à la reconnaissance des agrégats, une exploration peut exploiter automatiquement les tables agrégées, tout en permettant d'analyser en détail les données granulaires si nécessaire.
Vous pouvez également utiliser des tables agrégées pour améliorer considérablement les performances des tableaux de bord, en particulier pour les tuiles qui interrogent d'énormes ensembles de données. Pour en savoir plus, consultez la section Extraire le code LookML d'une table agrégée à partir d'un tableau de bord sur la page de documentation du paramètre aggregate_table.
Ajouter des tableaux agrégés à votre projet
Les développeurs Looker peuvent créer des tables agrégées stratégiques qui minimisent le nombre de requêtes requises sur les grandes tables d'une base de données. Les tables agrégées doivent être persistantes dans votre base de données pour être accessibles à la fonctionnalité de reconnaissance des agrégats. Les tables agrégées sont donc un type de table dérivée persistante (PDT).
Une table agrégée est définie à l'aide du paramètre aggregate_table sous un paramètre explore dans votre projet LookML.
Voici un exemple de fichier explore avec un tableau agrégé dans LookML :
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
Pour créer une table agrégée, vous pouvez écrire le code LookML à partir de zéro ou l'obtenir à partir d'une exploration ou d'un tableau de bord. Consultez la page de documentation sur le paramètre aggregate_table pour en savoir plus sur le paramètre aggregate_table et ses sous-paramètres.
Concevoir des tables agrégées
Pour qu'une requête Explorer puisse utiliser une table agrégée, celle-ci doit être en mesure de fournir des données précises pour la requête Explorer. Looker peut utiliser un tableau agrégé pour une requête Explore si toutes les conditions suivantes sont remplies :
- Les champs de la requête Explorer sont un sous-ensemble des champs du tableau agrégé (voir la section Facteurs de champ sur cette page). Pour les périodes, les périodes de la requête Explorer peuvent être dérivées de celles du tableau agrégé (voir la section Facteurs de période sur cette page).
- La requête Explorer contient des types de mesures compatibles avec la notoriété agrégée (consultez la section Facteurs liés au type de mesure sur cette page) ou une table agrégée qui correspond exactement à la requête Explorer (consultez la section Créer des tables agrégées qui correspondent exactement aux requêtes Explorer sur cette page).
- Le fuseau horaire de la requête "Explorer" correspond à celui utilisé par le tableau agrégé (voir la section Facteurs liés au fuseau horaire sur cette page).
- Les filtres de la requête Explorer font référence à des champs disponibles en tant que dimensions dans la table agrégée, ou chacun des filtres de la requête Explorer correspond à un filtre de la table agrégée (voir la section Facteurs de filtre sur cette page).
Pour vous assurer qu'une table agrégée peut fournir des données précises pour une requête Explore, vous pouvez créer une table agrégée qui correspond exactement à une requête Explore. Pour en savoir plus, consultez la section Créer des tables agrégées qui correspondent exactement aux requêtes Explore sur cette page.
Facteurs de champ
Pour être utilisée dans une requête d'exploration, une table agrégée doit comporter toutes les dimensions et mesures nécessaires à cette requête, y compris les champs utilisés pour les filtres. Si une requête Explorer contient une dimension ou une mesure qui ne figure pas dans une table agrégée, Looker ne peut pas utiliser la table agrégée et utilisera la table de base à la place.
Par exemple, si une requête regroupe les données par dimensions A et B, les agrège par mesure C et les filtre par dimension D, le tableau agrégé doit au minimum comporter les dimensions A, B et D, et la mesure C.
La table agrégée peut également contenir d'autres champs, mais elle doit au moins contenir les champs de la requête Explorer pour pouvoir être optimisée. La seule exception concerne les dimensions de période, car les périodes de précision plus faible peuvent être dérivées de celles de précision plus élevée.
En raison de ces considérations concernant les champs, une table agrégée est spécifique à l'exploration sous laquelle elle est définie. Une table agrégée définie sous une exploration ne sera pas utilisée pour les requêtes sur une autre exploration.
Facteurs de période
La logique de sensibilisation globale de Looker est capable de dériver une période d'une autre. Une table agrégée peut être utilisée pour une requête tant que la période de la table agrégée a une granularité plus fine (ou égale) que celle de la requête d'exploration. Par exemple, une table agrégée basée sur des données quotidiennes peut être utilisée pour une requête Explorer qui appelle d'autres périodes, telles que des requêtes pour des données quotidiennes, mensuelles et annuelles, ou même des données sur le jour du mois, le jour de l'année et la semaine de l'année. En revanche, une table agrégée annuelle ne peut pas être utilisée pour une requête Explorer qui nécessite des données horaires, car les données de la table agrégée ne sont pas assez précises pour la requête Explorer.
Il en va de même pour les sous-ensembles de plages de dates. Par exemple, si vous disposez d'une table agrégée filtrée pour les trois derniers mois et qu'un utilisateur interroge les données avec un filtre pour les deux derniers mois, Looker pourra utiliser la table agrégée pour cette requête.
De plus, la même logique s'applique aux requêtes avec des filtres de période : une table agrégée peut être utilisée pour une requête avec un filtre de période tant que la période de la table agrégée a une granularité plus fine (ou égale) que le filtre de période utilisé dans la requête d'exploration. Par exemple, une table agrégée avec une dimension de période quotidienne peut être utilisée pour une requête d'exploration avec un filtrage par jour, par semaine ou par mois.
Facteurs de type de mesure
Pour qu'une requête Explorer puisse utiliser une table agrégée, les mesures de la table agrégée doivent pouvoir fournir des données précises pour la requête Explorer.
C'est pourquoi seuls certains types de mesures sont acceptés, comme décrit dans les sections suivantes :
- Mesures avec des types de mesures compatibles
- Mesures définies par des expressions SQL
- Mesures non définies avec
${TABLE} - Mesures qui permettent d'approximer les nombres distincts
Si une requête Explore utilise un autre type de mesure, Looker utilisera la table d'origine, et non la table agrégée, pour renvoyer les résultats. La seule exception est si la requête d'exploration correspond exactement à une requête de table agrégée, comme décrit dans la section Créer des tables agrégées qui correspondent exactement aux requêtes d'exploration.
Sinon, Looker utilisera la table d'origine, et non la table agrégée, pour renvoyer les résultats.
Mesures avec des types de mesures acceptés
La sensibilisation agrégée peut être utilisée pour les requêtes Explore qui utilisent des mesures avec les types de mesures suivants :
Pour utiliser une table agrégée pour une requête d'exploration, Looker doit pouvoir opérer sur les mesures de la table agrégée afin de fournir des données précises dans la requête d'exploration. Par exemple, une mesure avec type: sum peut être utilisée pour l'agrégation de la notoriété, car vous pouvez additionner plusieurs sommes : une table agrégée de sommes hebdomadaires peut être additionnée pour obtenir une somme mensuelle précise. De même, une mesure avec type: max peut être utilisée, car une table agrégée des maximums quotidiens peut être utilisée pour trouver le maximum hebdomadaire précis.
Dans le cas des mesures avec type: average, la notoriété globale est prise en charge, car Looker utilise les données de somme et de nombre pour dériver précisément les valeurs moyennes des tableaux agrégés.
Mesures définies avec des expressions SQL
La notoriété globale peut également être utilisée avec des mesures définies avec des expressions dans le paramètre sql. Les types de mesures suivants sont également acceptés lorsqu'ils sont définis avec des expressions SQL :
La sensibilisation agrégée est acceptée pour les mesures définies comme des combinaisons d'autres mesures, comme dans l'exemple suivant :
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
La prise en compte de l'agrégation est également possible pour les mesures dont les calculs sont définis dans le paramètre sql, comme cette mesure :
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
La prise en compte des agrégats est compatible avec les mesures pour lesquelles les opérations MIN, MAX et COUNT sont définies dans le paramètre sql, comme cette mesure :
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
Mesures faisant référence à des champs LookML
Lorsque des expressions sql sont utilisées dans des mesures, la connaissance agrégée est compatible avec les types de références de champ suivants :
- Références au format
${view_name.field_name}, qui indique les champs dans d'autres vues - Références au format
${field_name}, qui indiquent les champs de la même vue
La fonction Aggregate Awareness n'est pas compatible avec les mesures définies au format ${TABLE}.column_name, qui indique une colonne dans un tableau. (Pour obtenir une présentation de l'utilisation des références dans LookML, consultez la page de documentation Intégrer des objets SQL et faire référence à des objets LookML.)
Par exemple, une mesure définie avec ce paramètre sql ne serait pas acceptée dans un tableau agrégé, car elle utilise le format ${TABLE}.column_name :
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
Si vous souhaitez inclure cette mesure dans un tableau agrégé, vous pouvez créer une dimension définie au format ${TABLE}.column_name, puis créer une mesure qui fait référence à la dimension, comme ceci :
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Vous pouvez maintenant utiliser la mesure wholesale_value dans votre tableau agrégé.
Mesures qui permettent d'approximer les nombres distincts
En général, les nombres distincts ne sont pas compatibles avec la notoriété agrégée, car vous ne pouvez pas obtenir de données précises si vous essayez d'agréger des nombres distincts. Par exemple, si vous comptez les utilisateurs distincts sur un site Web, il peut y avoir un utilisateur qui est venu sur le site Web deux fois, à trois semaines d'intervalle. Si vous avez essayé d'appliquer un tableau agrégé hebdomadaire pour obtenir un nombre mensuel d'utilisateurs uniques sur votre site Web, cet utilisateur aurait été comptabilisé deux fois dans votre requête mensuelle sur le nombre d'utilisateurs uniques, et les données auraient été incorrectes.
Pour contourner ce problème, vous pouvez créer une table agrégée qui correspond exactement à une requête Explorer, comme décrit dans la section Créer des tables agrégées qui correspondent exactement aux requêtes Explorer de cette page. Lorsque la requête d'exploration et la requête de table agrégée sont identiques, les mesures de nombre de valeurs distinctes fournissent des données précises. Elles peuvent donc être utilisées pour la prise de conscience des agrégats.
Une autre option consiste à utiliser des approximations pour les nombres distincts. Pour les dialectes compatibles avec les résumés HyperLogLog, Looker peut utiliser l'algorithme HyperLogLog pour estimer les nombres distincts pour les tableaux agrégés.
L'algorithme HyperLogLog est connu pour avoir une marge d'erreur d'environ 2 %. Le paramètre allow_approximate_optimization: yes exige que vos développeurs Looker reconnaissent qu'il est acceptable d'utiliser des données approximatives pour la mesure afin qu'elle puisse être calculée approximativement à partir de tableaux agrégés.
Pour en savoir plus et consulter la liste des dialectes compatibles avec le décompte distinct à l'aide de HyperLogLog, consultez la page de documentation sur le paramètre allow_approximate_optimization.
Facteurs liés au fuseau horaire
Dans de nombreux cas, les administrateurs de bases de données utilisent le fuseau horaire UTC pour les bases de données. Toutefois, de nombreux utilisateurs ne se trouvent pas dans le fuseau horaire UTC. Looker propose plusieurs options pour convertir les fuseaux horaires afin que vos utilisateurs obtiennent des résultats de requête dans leur propre fuseau horaire :
- Le fuseau horaire des requêtes, un paramètre qui s'applique à toutes les requêtes sur la connexion à la base de données. Si tous vos utilisateurs se trouvent dans le même fuseau horaire, vous pouvez définir un seul fuseau horaire pour les requêtes. Toutes les requêtes seront ainsi converties du fuseau horaire de la base de données vers le fuseau horaire des requêtes.
- Fuseaux horaires spécifiques aux utilisateurs : les utilisateurs peuvent se voir attribuer des fuseaux horaires et les sélectionner individuellement. Dans ce cas, les requêtes sont converties du fuseau horaire de la base de données vers le fuseau horaire de chaque utilisateur.
Pour en savoir plus sur ces options, consultez la page de documentation Utiliser les paramètres de fuseau horaire.
Il est important de comprendre ces concepts pour comprendre la prise en compte des tables agrégées. En effet, pour qu'une table agrégée puisse être utilisée pour une requête avec des dimensions ou des filtres de date, le fuseau horaire de la table agrégée doit correspondre au paramètre de fuseau horaire utilisé pour la requête d'origine.
Les tables agrégées utilisent le fuseau horaire de la base de données si aucune valeur timezone n'est spécifiée. Votre connexion à la base de données utilisera également le fuseau horaire de la base de données si l'une des conditions suivantes est remplie :
- Votre base de données n'accepte pas les fuseaux horaires.
- Le fuseau horaire des requêtes de votre connexion à la base de données est défini sur le même fuseau horaire que celui de la base de données.
- Votre connexion à la base de données ne comporte ni fuseau horaire de requête spécifié, ni fuseaux horaires spécifiques à l'utilisateur. Dans ce cas, votre connexion à la base de données utilisera le fuseau horaire de la base de données.
Si l'une de ces conditions est remplie, vous pouvez omettre le paramètre timezone pour vos tableaux agrégés.
Sinon, le fuseau horaire de la table agrégée doit être défini pour correspondre aux requêtes possibles afin que la table agrégée soit plus susceptible d'être utilisée :
- Si votre connexion à la base de données utilise un seul fuseau horaire pour les requêtes, vous devez faire correspondre la valeur
timezonede votre tableau agrégé à la valeur du fuseau horaire pour les requêtes. - Si votre connexion à la base de données utilise des fuseaux horaires spécifiques aux utilisateurs, vous devez créer des tables agrégées identiques, chacune avec une valeur
timezonedifférente pour correspondre aux fuseaux horaires possibles de vos utilisateurs.
Facteurs de filtrage
Soyez prudent lorsque vous incluez des filtres dans votre tableau agrégé. Les filtres appliqués à un tableau agrégé peuvent affiner les résultats au point de rendre le tableau inutilisable. Par exemple, imaginons que vous créez une table agrégée pour le nombre de commandes quotidiennes, et que cette table agrégée ne filtre que les commandes de lunettes de soleil provenant d'Australie. Si un utilisateur exécute une requête Explorer pour obtenir le nombre de commandes quotidiennes de lunettes de soleil dans le monde entier, Looker ne peut pas utiliser le tableau agrégé pour cette requête Explorer, car il ne contient que les données pour l'Australie. La table agrégée filtre les données de manière trop restrictive pour être utilisée par la requête d'exploration.
Faites également attention aux filtres que vos développeurs Looker ont peut-être intégrés à votre exploration, par exemple :
access_filters: applique des restrictions de données spécifiques à l'utilisateur.always_filter: oblige les utilisateurs à inclure un certain ensemble de filtres pour une requête Explore. Les utilisateurs peuvent modifier la valeur par défaut du filtre pour leur requête, mais ils ne peuvent pas le supprimer complètement.conditionally_filter: définit un ensemble de filtres par défaut que les utilisateurs peuvent remplacer s'ils appliquent au moins un filtre à partir d'une deuxième liste également définie dans Explorer.
Ces types de filtres sont basés sur des champs spécifiques. Si votre exploration comporte ces filtres, vous devez inclure leurs champs dans le paramètre dimensions de aggregate_table.
Par exemple, voici une exploration avec un filtre d'accès basé sur le champ orders.region :
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
Pour créer une table agrégée qui serait utilisée pour cette exploration, elle doit inclure le champ sur lequel repose le filtre d'accès. Dans l'exemple suivant, le filtre d'accès est basé sur le champ orders.region, et ce même champ est inclus en tant que dimension dans le tableau agrégé :
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Étant donné que la requête de table agrégée inclut la dimension orders.region, Looker peut filtrer dynamiquement les données de la table agrégée pour qu'elles correspondent au filtre de la requête d'exploration. Par conséquent, Looker peut toujours utiliser la table agrégée pour les requêtes de l'exploration, même si l'exploration comporte un filtre d'accès.
Cela s'applique également aux requêtes Explorer qui utilisent une table dérivée native configurée avec bind_filters. Le paramètre bind_filters transmet les filtres spécifiés d'une requête Explorer à la sous-requête de la table dérivée native. Dans le cas de l'agrégation, si votre requête d'exploration nécessite une table dérivée native qui utilise bind_filters, la requête d'exploration ne peut utiliser une table agrégée que si tous les champs utilisés dans le paramètre bind_filters de la table dérivée native ont exactement les mêmes valeurs de filtre dans la requête d'exploration que dans la table agrégée.
Créer des tables agrégées qui correspondent exactement aux requêtes Explorer
Pour vous assurer qu'une table agrégée peut être utilisée pour une requête d'exploration, vous pouvez créer une table agrégée qui correspond exactement à la requête d'exploration. Si la requête d'exploration et la table agrégée utilisent les mêmes mesures, dimensions, filtres, fuseaux horaires et autres paramètres, les résultats de la table agrégée s'appliqueront à la requête d'exploration. Si une table agrégée correspond exactement à une requête Explorer, Looker peut utiliser des tables agrégées incluant n'importe quel type de mesure.
Vous pouvez créer une table agrégée à partir d'une exploration à l'aide de l'option Obtenir le code LookML du menu en forme de roue dentée d'une exploration. Vous pouvez également créer des correspondances exactes pour toutes les vignettes d'un tableau de bord à l'aide de l'option Obtenir le LookML du menu en forme de roue dentée d'un tableau de bord.
Déterminer quelle table agrégée est utilisée pour une requête
Les utilisateurs disposant des autorisations see_sql peuvent utiliser les commentaires de l'onglet SQL d'une exploration pour voir quelle table agrégée sera utilisée pour une requête. Les commentaires de l'onglet SQL s'affichent également en mode Développement. Les développeurs peuvent ainsi tester de nouveaux tableaux agrégés pour voir comment Looker les utilise avant de les transférer en production.
Par exemple, en vous basant sur l'exemple de tableau agrégé mensuel présenté précédemment, vous pouvez accéder à Explorer et exécuter une requête pour obtenir le total des ventes annuelles. Vous pouvez ensuite cliquer sur l'onglet SQL pour afficher les détails de la requête créée par Looker. Si vous êtes en mode Développement, Looker affiche des commentaires pour indiquer le tableau agrégé qu'il a utilisé pour la requête.
Les commentaires suivants de l'onglet SQL indiquent que Looker utilise la table agrégée sales_monthly pour cette requête, ainsi que des informations expliquant pourquoi d'autres tables agrégées n'ont pas été utilisées pour la requête :
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
Consultez la section Dépannage de cette page pour connaître les commentaires que vous pouvez voir dans l'onglet SQL et obtenir des suggestions pour les résoudre.
Estimation des économies de calcul pour la notoriété globale
Si votre connexion à la base de données est compatible avec les estimations de coût et qu'un tableau agrégé peut être utilisé pour une requête, la fenêtre "Explorer" affichera les économies de calcul réalisées en utilisant le tableau agrégé au lieu d'interroger directement la base de données. Les économies globales de notoriété sont affichées à côté du bouton Exécuter dans une exploration avant l'exécution de la requête.
Avant d'exécuter la requête, si vous souhaitez voir quelle table agrégée sera utilisée, vous pouvez cliquer sur l'onglet SQL, comme décrit dans la section Déterminer quelle table agrégée est utilisée pour une requête de cette page de documentation.
Une fois la requête exécutée, la fenêtre "Explorer" indique la table agrégée utilisée pour répondre à la requête à côté du bouton Exécuter.
Les économies globales de notoriété sont affichées pour les connexions à la base de données pour lesquelles les estimations de coûts sont activées. Pour en savoir plus, consultez la page de documentation Explorer les données dans Looker .
Looker ajoute de nouvelles données à vos tableaux agrégés
Pour les tables agrégées avec des filtres temporels, Looker peut unir des données récentes à votre table agrégée. Vous pouvez disposer d'un tableau agrégé qui inclut les données des trois derniers jours, mais qui a été créé hier. Il manquerait les informations du jour dans le tableau agrégé. Vous ne vous attendriez donc pas à l'utiliser pour une requête Explorer sur les informations quotidiennes les plus récentes.
Toutefois, Looker peut toujours utiliser les données de ce tableau agrégé pour la requête, car il exécutera une requête sur les données les plus récentes, puis fusionnera ces résultats avec ceux du tableau agrégé.
Looker peut associer des données récentes à celles de votre tableau agrégé dans les cas suivants :
- La table agrégée comporte un filtre temporel.
- Le tableau agrégé inclut une dimension basée sur le même champ temporel que le filtre temporel.
Par exemple, le tableau agrégé suivant comporte une dimension basée sur le champ orders.created_date et un filtre temporel ("3 days") basé sur le même champ :
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
Si cette table agrégée a été créée hier, Looker récupère les données les plus récentes qui ne sont pas encore incluses dans la table agrégée, puis les fusionne avec les résultats de la table agrégée. Cela signifie que vos utilisateurs bénéficieront des données les plus récentes tout en optimisant les performances grâce à la notoriété globale.
Si vous êtes en mode Développement, vous pouvez cliquer sur l'onglet SQL d'une exploration pour afficher le tableau agrégé utilisé par Looker pour la requête, ainsi que l'instruction UNION utilisée par Looker pour importer des données plus récentes qui n'étaient pas incluses dans le tableau agrégé.
Les tables agrégées doivent être persistantes.
Pour que votre table agrégée soit accessible pour la couverture globale, elle doit être persistante dans votre base de données. La stratégie de persistance est spécifiée dans le paramètre materialization de la table agrégée. Les tables agrégées étant un type de table dérivée persistante (PDT), elles sont soumises aux mêmes exigences que les PDT. Pour en savoir plus, consultez la page de documentation Tables dérivées dans Looker.
Vous pouvez créer des tables PDT incrémentielles dans votre projet si votre dialecte les prend en charge. Looker crée des PDT incrémentielles en ajoutant de nouvelles données à la table, au lieu de régénérer la table entière. Étant donné que les tables agrégées sont elles-mêmes un type de PDT, vous pouvez également créer des tables agrégées incrémentielles. Pour en savoir plus sur les tests incrémentaux de temps et de délai avant achat, consultez la page de documentation Tests incrémentaux de temps et de délai avant achat. Pour obtenir un exemple de tableau agrégé incrémentiel, consultez la page de documentation sur le paramètre increment_key.
Un utilisateur disposant de l'autorisation develop peut remplacer les paramètres de persistance et reconstruire toutes les tables agrégées pour une requête afin d'obtenir les données les plus récentes. Pour recréer les tables d'une requête, sélectionnez l'option Recréer les tables dérivées et exécuter dans le menu en forme de roue dentée Actions d'exploration.
Vous devez attendre le chargement de la requête Explore avant que cette option soit disponible.
L'option Régénérer les tables dérivées et exécuter permet de régénérer toutes les tables dérivées référencées dans la requête, ainsi que toutes les tables dérivées dont dépendent les tables de la requête. Cela inclut les tables agrégées, qui sont elles-mêmes un type de table dérivée persistante.
Pour l'utilisateur qui sélectionne l'option Régénérer les tables dérivées et exécuter, la requête attend que les tables soient régénérées avant de charger des résultats. Les requêtes des autres utilisateurs continueront d'utiliser les tables existantes. Une fois les tables persistantes régénérées, tous les utilisateurs s'en servent.
Pour en savoir plus sur l'option Recréer les tables dérivées et exécuter, consultez la page de documentation Tables dérivées dans Looker.
Dépannage
Comme décrit dans la section Déterminer quelle table agrégée est utilisée pour une requête, si vous êtes en mode Développement, vous pouvez exécuter des requêtes sur l'exploration et cliquer sur l'onglet SQL pour afficher les commentaires sur la table agrégée utilisée pour la requête, le cas échéant.
L'onglet SQL inclut également des commentaires expliquant pourquoi les tables agrégées n'ont pas été utilisées pour une requête, le cas échéant. Pour les tables agrégées inutilisées, le commentaire commencera par :
Did not use [explore name]::[aggregate table name];
Par exemple, voici un commentaire expliquant pourquoi le tableau agrégé sales_daily défini dans l'exploration order_items n'a pas été utilisé pour une requête :
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
Dans ce cas, les filtres de la requête ont empêché l'utilisation de la table agrégée.
Le tableau suivant présente d'autres raisons possibles pour lesquelles une table agrégée ne peut pas être utilisée, ainsi que les étapes à suivre pour améliorer son utilité.
| Raison pour laquelle vous n'utilisez pas le tableau agrégé | Explication et étapes possibles |
|---|---|
| Ce champ n'existe pas dans l'exploration. | Une erreur de type de validation LookML s'est produite. Cela est probablement dû au fait que le tableau agrégé n'a pas été correctement défini ou qu'il y a une faute de frappe dans le LookML de votre tableau agrégé. Un nom de champ incorrect ou une erreur similaire est probablement à l'origine du problème.Pour résoudre ce problème, vérifiez que les dimensions et les mesures de la table agrégée correspondent aux noms de champs dans l'exploration. Pour en savoir plus sur la définition d'un tableau agrégé, consultez la page de documentation sur le paramètre aggregate_table. |
| Le tableau agrégé n'inclut pas les champs suivants dans la requête. | Pour être utilisée dans une requête d'exploration, une table agrégée doit comporter toutes les dimensions et mesures nécessaires à cette requête, y compris les champs utilisés pour les filtres. Si une requête Explorer contient une dimension ou une mesure qui ne figure pas dans une table agrégée, Looker ne peut pas utiliser la table agrégée et utilisera la table de base à la place. Pour en savoir plus, consultez la section Facteurs de champ sur cette page. La seule exception concerne les dimensions de période, car les périodes de précision plus faible peuvent être dérivées de celles de précision plus élevée. Pour résoudre ce problème, vérifiez que les champs de la requête Explorer sont inclus dans la définition de la table agrégée. |
| La requête contenait les filtres suivants, qui n'étaient pas inclus en tant que champs et ne correspondaient pas exactement aux filtres de la table agrégée. | Les filtres de la requête Explorer empêchent Looker d'utiliser la table agrégée. Pour résoudre ce problème, vous pouvez effectuer l'une des opérations suivantes :
|
| La requête contient les mesures suivantes qui ne peuvent pas être cumulées. | La requête contient un ou plusieurs types de mesures qui ne sont pas compatibles avec la reconnaissance des agrégats, comme Nombre de valeurs distinctes, Médiane ou Centile.Pour résoudre ce problème, vérifiez le type de chaque mesure dans la requête et assurez-vous qu'il s'agit de l'un des types de mesures acceptés. De plus, si votre exploration comporte des jointures, vérifiez que vos mesures ne sont pas converties en mesures distinctes (agrégats symétriques) par le biais de jointures en éventail. Pour en savoir plus, consultez la section Agrégations symétriques pour les explorations avec jointures sur cette page. |
| Une autre table agrégée était plus adaptée à l'optimisation. | Plusieurs tables agrégées viables étaient disponibles pour la requête, et Looker en a trouvé une plus optimale à utiliser à la place. Dans ce cas, aucune action de votre part n'est nécessaire. |
Looker n'a effectué aucun regroupement (en raison d'un paramètre primary_key ou cancel_grouping_fields). La requête ne peut donc pas être cumulée. |
La requête fait référence à une dimension qui l'empêche d'avoir une clause GROUP BY. Looker ne peut donc utiliser aucune table agrégée pour la requête.
Pour résoudre ce problème, vérifiez que le paramètre primary_key de la vue et le paramètre cancel_grouping_fields de l'exploration sont correctement configurés. |
| La table agrégée contenait des filtres qui ne figuraient pas dans la requête. | La table agrégée comporte un filtre non temporel qui ne figure pas dans la requête.Pour résoudre ce problème, vous pouvez supprimer le filtre du tableau agrégé. Pour en savoir plus, consultez la section Facteurs de filtrage de cette page. |
Un champ est défini comme champ de filtre uniquement dans la requête Explorer, mais il est listé dans le paramètre dimensions de la table agrégée. |
Le paramètre dimensions de la table agrégée liste un champ qui n'est défini que comme champ filter dans la requête Explorer.Pour résoudre ce problème, supprimez le champ de la liste dimensions de la table agrégée. Si ce champ est nécessaire pour la table agrégée, ajoutez-le à la liste filters dans la requête de la table agrégée. |
| L'optimiseur ne peut pas déterminer pourquoi la table agrégée n'a pas été utilisée. | Ce commentaire est réservé aux cas particuliers. Si ce message s'affiche pour une requête Explore souvent utilisée, vous pouvez créer une table agrégée qui correspond exactement à la requête Explore. Vous pouvez obtenir le code LookML d'une table agrégée à partir d'une exploration, comme décrit sur la page du paramètre aggregate_table. |
Éléments à prendre en compte
Agrégations symétriques pour les explorations avec jointures
Il est important de noter que dans une exploration qui joint plusieurs tables de base de données, Looker peut afficher les mesures de type SUM, COUNT et AVERAGE sous la forme SUM DISTINCT, COUNT DISTINCT et AVERAGE DISTINCT, respectivement. Looker procède ainsi pour éviter les erreurs de calcul de la distribution. Par exemple, une mesure count est affichée en tant que type de mesure count_distinct. Cela permet d'éviter les erreurs de calcul du fanout pour les jointures et fait partie de la fonctionnalité d'agrégations symétriques de Looker. Pour en savoir plus sur cette fonctionnalité de Looker, consultez la page Bonnes pratiques concernant les agrégations symétriques.
La fonctionnalité d'agrégats symétriques permet d'éviter les erreurs de calcul, mais elle peut également empêcher l'utilisation de vos tables agrégées dans certains cas. Il est donc important de la comprendre.
Pour les types de mesures compatibles avec la connaissance agrégée, cela s'applique à sum, count et average. Looker affichera ces types de mesures comme DISTINCT si :
- La mesure provient de la vue "un" d'une jointure plusieurs-à-un ou un-à-plusieurs.
- La mesure provient de l'une des vues d'une jointure plusieurs-à-plusieurs.
Pour en savoir plus sur ces types de jointures, consultez la page de documentation sur le paramètre relationship.
Si vous constatez que votre table agrégée n'est pas utilisée pour cette raison, vous pouvez créer une table agrégée qui correspond exactement à une requête Explorer afin d'utiliser ces types de mesures pour une exploration avec des jointures. Pour en savoir plus, consultez la section Créer des tables agrégées qui correspondent exactement aux requêtes Explore sur cette page.
De plus, si vous disposez d'un dialecte SQL compatible avec les croquis HyperLogLog, vous pouvez ajouter le paramètre allow_approximate_optimization: yes à la mesure. Lorsqu'une mesure de nombre est définie avec allow_approximate_optimization: yes, Looker peut l'utiliser pour la reconnaissance des agrégats, même si elle s'affiche sous forme de nombre distinct.
Pour en savoir plus, consultez la page de documentation sur le paramètre allow_approximate_optimization et la liste des dialectes SQL compatibles avec les croquis HyperLogLog.
Prise en charge des dialectes pour la notoriété globale
La possibilité d'utiliser la fonction Aggregate Awareness dépend du dialecte de base de données de votre connexion Looker. Dans la dernière version de Looker, les dialectes suivants sont compatibles avec la reconnaissance des agrégats :
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Oui |
| Amazon Athena | Oui |
| Amazon Aurora MySQL | Oui |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Non |
| Apache Druid 0.13+ | Non |
| Apache Druid 0.18+ | Non |
| Apache Hive 2.3+ | Oui |
| Apache Hive 3.1.2+ | Oui |
| Apache Spark 3+ | Oui |
| ClickHouse | Non |
| Cloudera Impala 3.1+ | Oui |
| Cloudera Impala 3.1+ with Native Driver | Oui |
| Cloudera Impala with Native Driver | Oui |
| DataVirtuality | Non |
| Databricks | Oui |
| Denodo 7 | Non |
| Denodo 8 & 9 | Non |
| Dremio | Non |
| Dremio 11+ | Non |
| Exasol | Oui |
| Google BigQuery Legacy SQL | Oui |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Non |
| Google Spanner | Non |
| Greenplum | Oui |
| HyperSQL | Non |
| IBM Netezza | Oui |
| MariaDB | Oui |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Oui |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Oui |
| Microsoft SQL Server 2012+ | Oui |
| Microsoft SQL Server 2016 | Oui |
| Microsoft SQL Server 2017+ | Oui |
| MongoBI | Non |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Oui |
| Oracle ADWC | Oui |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Oui |
| PrestoSQL | Oui |
| SAP HANA | Oui |
| SAP HANA 2+ | Oui |
| SingleStore | Oui |
| SingleStore 7+ | Oui |
| Snowflake | Oui |
| Teradata | Oui |
| Trino | Oui |
| Vector | Oui |
| Vertica | Oui |
Compatibilité des dialectes pour la création incrémentielle de tables agrégées
Pour que Looker prenne en charge les tables agrégées incrémentielles dans votre projet, votre dialecte de base de données doit également les prendre en charge. Le tableau suivant indique les dialectes qui permettent de créer des PDT de manière incrémentielle dans la dernière version de Looker :
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | Non |
| Amazon Athena | Non |
| Amazon Aurora MySQL | Non |
| Amazon Redshift | Oui |
| Amazon Redshift 2.1+ | Oui |
| Amazon Redshift Serverless 2.1+ | Oui |
| Apache Druid | Non |
| Apache Druid 0.13+ | Non |
| Apache Druid 0.18+ | Non |
| Apache Hive 2.3+ | Non |
| Apache Hive 3.1.2+ | Non |
| Apache Spark 3+ | Non |
| ClickHouse | Non |
| Cloudera Impala 3.1+ | Non |
| Cloudera Impala 3.1+ with Native Driver | Non |
| Cloudera Impala with Native Driver | Non |
| DataVirtuality | Non |
| Databricks | Oui |
| Denodo 7 | Non |
| Denodo 8 & 9 | Non |
| Dremio | Non |
| Dremio 11+ | Non |
| Exasol | Non |
| Google BigQuery Legacy SQL | Non |
| Google BigQuery Standard SQL | Oui |
| Google Cloud PostgreSQL | Oui |
| Google Cloud SQL | Non |
| Google Spanner | Non |
| Greenplum | Oui |
| HyperSQL | Non |
| IBM Netezza | Non |
| MariaDB | Non |
| Microsoft Azure PostgreSQL | Oui |
| Microsoft Azure SQL Database | Non |
| Microsoft Azure Synapse Analytics | Oui |
| Microsoft SQL Server 2008+ | Non |
| Microsoft SQL Server 2012+ | Non |
| Microsoft SQL Server 2016 | Non |
| Microsoft SQL Server 2017+ | Non |
| MongoBI | Non |
| MySQL | Oui |
| MySQL 8.0.12+ | Oui |
| Oracle | Non |
| Oracle ADWC | Non |
| PostgreSQL 9.5+ | Oui |
| PostgreSQL pre-9.5 | Oui |
| PrestoDB | Non |
| PrestoSQL | Non |
| SAP HANA | Non |
| SAP HANA 2+ | Non |
| SingleStore | Non |
| SingleStore 7+ | Non |
| Snowflake | Oui |
| Teradata | Non |
| Trino | Non |
| Vector | Non |
| Vertica | Oui |