このチュートリアルでは、scikit-learn でトレーニングされた Open Neural Network Exchange(ONNX)モデルをインポートする方法について説明します。モデルを BigQuery データセットにインポートし、SQL クエリを使用して予測を行います。
ONNX は、機械学習(ML)フレームワークを統一された形式で表現するためのフォーマットです。ONNX に対する BigQuery ML サポートにより、次のことが可能になります。
- 使い慣れたフレームワークを使用してモデルをトレーニングします。
- モデルを ONNX 形式に変換します。
- ONNX モデルを BigQuery にインポートし、BigQuery ML を使用して予測を行う。
省略可: モデルをトレーニングして ONNX 形式に変換する
次のコードサンプルでは、scikit-learn で分類モデルをトレーニングする方法と、結果として得られるパイプラインを ONNX 形式に変換する方法を示します。このチュートリアルでは、gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnx に保存されている事前構築済みのサンプルモデルを使用します。サンプルモデルを使用する場合は、これらの手順を完了する必要はありません。
scikit-learn で分類モデルをトレーニングする
次のサンプルコードを使用して、Iris データセットで scikit-learn パイプラインを作成してトレーニングします。scikit-learn のインストールと使用については、scikit-learn インストール ガイドをご覧ください。
import numpy
from sklearn.datasets import load_iris
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
data = load_iris()
X = data.data[:, :4]
y = data.target
ind = numpy.arange(X.shape[0])
numpy.random.shuffle(ind)
X = X[ind, :].copy()
y = y[ind].copy()
pipe = Pipeline([('scaler', StandardScaler()),
('clr', RandomForestClassifier())])
pipe.fit(X, y)
パイプラインを ONNX モデルに変換する
sklearn-onnx で次のサンプルコードを使用して、scikit-learn パイプラインを pipeline_rf.onnx という名前の ONNX モデルに変換します。
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
# Disable zipmap as it is not supported in BigQuery ML.
options = {id(pipe): {'zipmap': False}}
# Define input features. scikit-learn does not store information about the
# training dataset. It is not always possible to retrieve the number of features
# or their types. That's why the function needs another argument called initial_types.
initial_types = [
('sepal_length', FloatTensorType([None, 1])),
('sepal_width', FloatTensorType([None, 1])),
('petal_length', FloatTensorType([None, 1])),
('petal_width', FloatTensorType([None, 1])),
]
# Convert the model.
model_onnx = convert_sklearn(
pipe, 'pipeline_rf', initial_types=initial_types, options=options
)
# And save.
with open('pipeline_rf.onnx', 'wb') as f:
f.write(model_onnx.SerializeToString())
ONNX モデルを Cloud Storage にアップロードする
モデルを保存したら、次の操作を行います。
- モデルを保存する Cloud Storage バケットを作成します。
- ONNX モデルを Cloud Storage バケットにアップロードします。
データセットを作成する
ML モデルを保存する BigQuery データセットを作成します。
コンソール
Google Cloud コンソールで、[BigQuery] ページに移動します。
[エクスプローラ] ペインで、プロジェクト名をクリックします。
[アクションを表示] > [データセットを作成] をクリックします。
[データセットを作成する] ページで、次の操作を行います。
[データセット ID] に「
bqml_tutorial」と入力します。[ロケーション タイプ] で [マルチリージョン] を選択してから、[US(米国の複数のリージョン)] を選択します。
残りのデフォルトの設定は変更せず、[データセットを作成] をクリックします。
bq
新しいデータセットを作成するには、--location フラグを指定した bq mk コマンドを使用します。使用可能なパラメータの一覧については、bq mk --dataset コマンドのリファレンスをご覧ください。
データの場所が
USに設定され、BigQuery ML tutorial datasetという説明の付いた、bqml_tutorialという名前のデータセットを作成します。bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
このコマンドでは、
--datasetフラグの代わりに-dショートカットを使用しています。-dと--datasetを省略した場合、このコマンドはデフォルトでデータセットを作成します。データセットが作成されたことを確認します。
bq ls
API
定義済みのデータセット リソースを使用して datasets.insert メソッドを呼び出します。
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
ONNX モデルを BigQuery にインポートする
次の手順では、CREATE MODEL ステートメントを使用して Cloud Storage からサンプル ONNX モデルをインポートする方法を示します。
ONNX モデルをデータセットにインポートするには、次のオプションのいずれかを選択します。
コンソール
Google Cloud コンソールで、[BigQuery Studio] ページに移動します。
クエリエディタで次の
CREATE MODELステートメントを入力します。CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')
BUCKET_PATHは、Cloud Storage にアップロードしたモデルのパスに置き換えます。サンプルモデルを使用する場合は、BUCKET_PATHを値gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnxに置き換えます。処理が完了すると、「
Successfully created model named imported_onnx_model」のようなメッセージが表示されます。新しいモデルが [リソース] パネルに表示されます。モデルにはモデルアイコン
![[リソース] パネルのモデルアイコン](https://cloud.google.com/static/bigquery/images/model-icon.png?hl=ja) がついています。[リソース] パネルで新しいモデルを選択すると、そのモデルに関する情報がクエリエディタの横に表示されます。
がついています。[リソース] パネルで新しいモデルを選択すると、そのモデルに関する情報がクエリエディタの横に表示されます。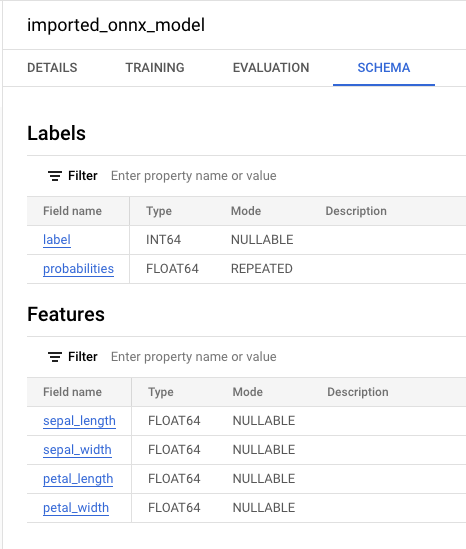
bq
次の
CREATE MODELステートメントを入力して Cloud Storage から ONNX モデルをインポートします。bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_onnx_model` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='BUCKET_PATH')"
BUCKET_PATHは、Cloud Storage にアップロードしたモデルのパスに置き換えます。サンプルモデルを使用する場合は、BUCKET_PATHを値gs://cloud-samples-data/bigquery/ml/onnx/pipeline_rf.onnxに置き換えます。処理が完了すると、「
Successfully created model named imported_onnx_model」のようなメッセージが表示されます。モデルをインポートしたら、モデルがデータセットに表示されていることを確認します。
bq ls -m bqml_tutorial
出力は次のようになります。
tableId Type --------------------- ------- imported_onnx_model MODEL
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
ONNXModel オブジェクトを使用してモデルをインポートします。
形式やストレージの要件など、BigQuery への ONNX モデルのインポートの詳細については、ONNX モデルをインポートする CREATE MODEL ステートメントをご覧ください。
インポートした ONNX モデルを使用して予測を行う
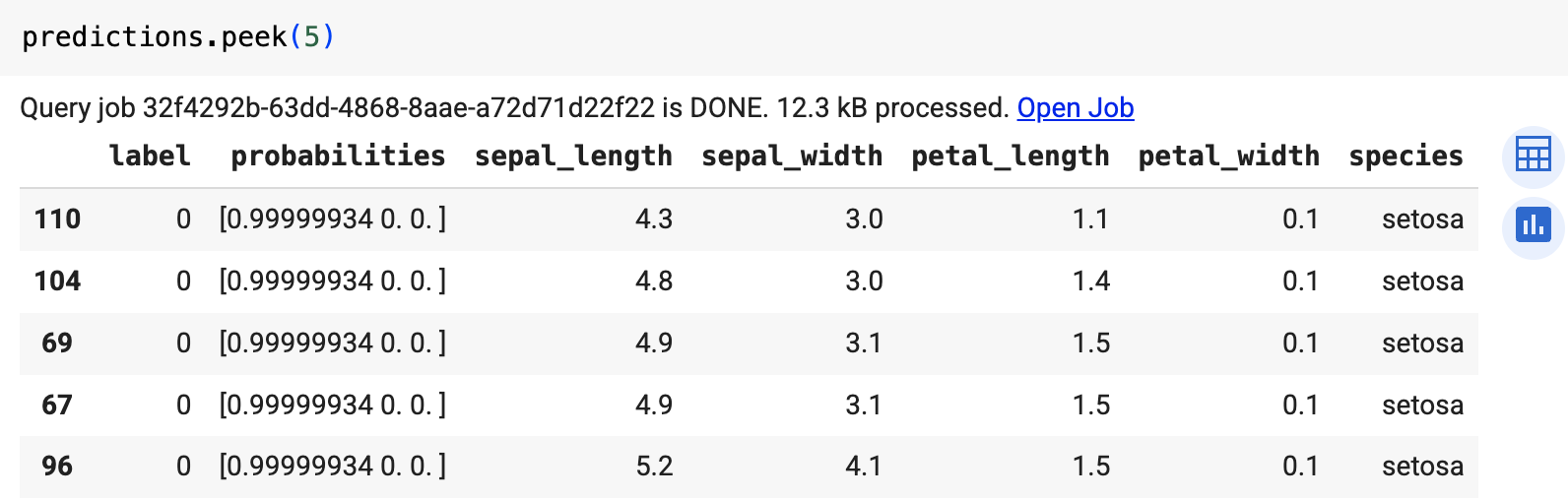
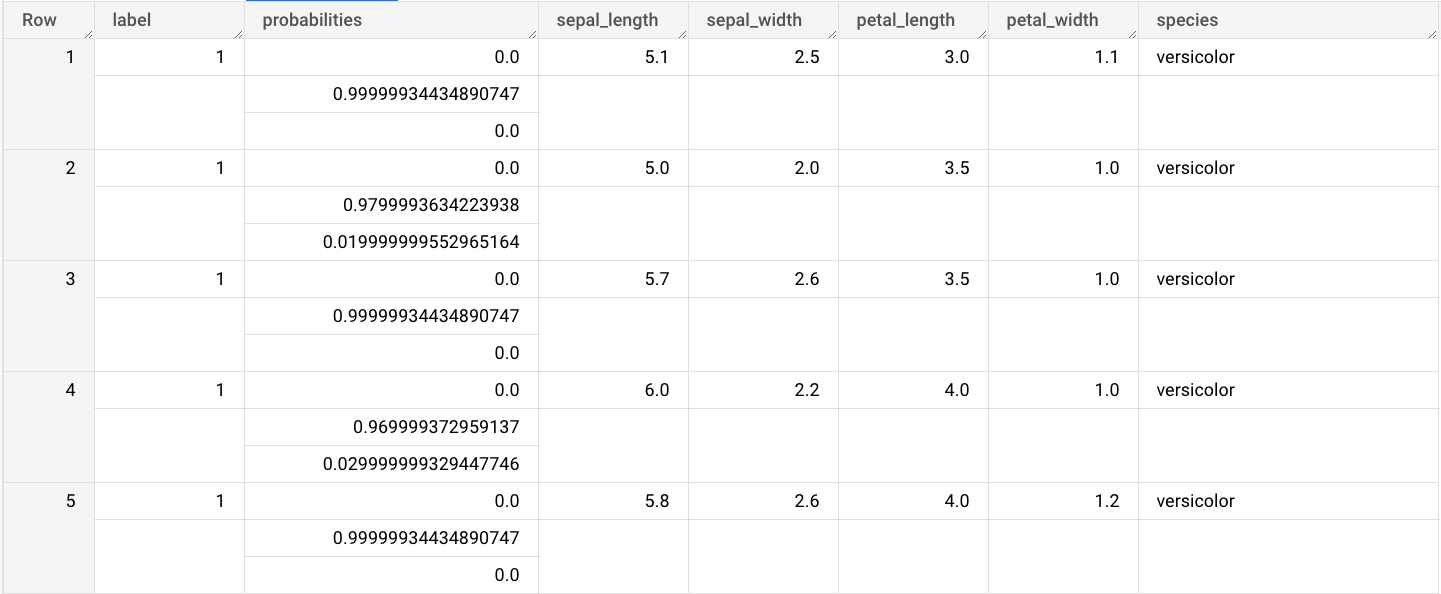
ONNX モデルをインポートしたら、ML.PREDICT 関数を使用してモデルで予測を行います。
次の手順のクエリでは、imported_onnx_model を使用して、ml_datasets 一般公開データセットの iris テーブルの入力データから予測を行います。ONNX モデルでは、4 つの FLOAT 値を入力として想定しています。
sepal_lengthsepal_widthpetal_lengthpetal_width
これらの入力は、モデルを ONNX 形式に変換したときに定義された initial_types と一致します。
出力には、label 列と probabilities 列、および入力テーブルの列が含まれます。label は予測されたクラスラベルを表します。probabilities は各クラスの確率を表す配列です。
インポートした ONNX モデルで予測を行うには、次のオプションのいずれかを選択します。
コンソール
[BigQuery Studio] ページに移動します。
クエリエディタで、
ML.PREDICT関数を使用する次のクエリを入力します。SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_onnx_model`, ( SELECT * FROM `bigquery-public-data.ml_datasets.iris` ) )
クエリ結果は次のようになります。
bq
ML.PREDICT を使用するクエリを実行します。
bq query --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `example_dataset.imported_onnx_model`, (SELECT * FROM `bigquery-public-data.ml_datasets.iris`))'
BigQuery DataFrames
このサンプルを試す前に、BigQuery DataFrames を使用した BigQuery クイックスタートの手順に沿って BigQuery DataFrames を設定してください。詳細については、BigQuery DataFrames のリファレンス ドキュメントをご覧ください。
BigQuery に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の ADC の設定をご覧ください。
predict 関数を使用して、ONNX モデルを実行します。
次のような結果になります。