No Looker, as tabelas derivadas persistentes (PDTs) são escritas no esquema temporário da sua base de dados. O Looker persiste e recompila um PDT com base na respetiva estratégia de persistência. Quando uma PDT é acionada para recompilação, por predefinição, o Looker recompila toda a tabela.
Um PDT incremental é um PDT que o Looker cria anexando dados atualizados à tabela em vez de reconstruir a tabela na íntegra:
Se o seu dialeto suportar PDTs incrementais, pode transformar os seguintes tipos de PDTs em PDTs incrementais:
Na primeira vez que executa uma consulta num PDT incremental, o Looker cria o PDT completo para obter os dados iniciais. Se a tabela for grande, a criação inicial pode demorar bastante tempo, tal como a criação de qualquer tabela grande. Depois de criar a tabela inicial, as criações subsequentes são incrementais e demoram menos tempo, se o PDT incremental estiver configurado estrategicamente.
Tenha em atenção o seguinte para PDTs incrementais:
- As PDTs incrementais só são suportadas para PDTs que usam uma estratégia de persistência baseada em acionadores (
datagroup_trigger,sql_trigger_valueouinterval_trigger). As PDTs incrementais não são suportadas para PDTs que usam a estratégia de persistênciapersist_for. - Para PDTs baseados em SQL, a consulta de tabela tem de ser definida através do parâmetro
sqlpara ser usada como um PDT incremental. As PDTs baseadas em SQL definidas com o parâmetrosql_createou o parâmetrocreate_processnão podem ser criadas incrementalmente. Como pode ver no Exemplo 1 nesta página, o Looker usa um comando INSERT ou MERGE para criar os incrementos para um PDT incremental. Não é possível definir a tabela derivada com declarações de linguagem de definição de dados (DDL) personalizadas, uma vez que o Looker não conseguiria determinar que declarações DDL seriam necessárias para criar um incremento preciso. - A tabela de origem dos PDTs incrementais tem de ser otimizada para consultas baseadas no tempo. Especificamente, a coluna baseada no tempo usada para a chave de incremento tem de ter uma estratégia de otimização, como partição, chaves de ordenação, índices ou qualquer estratégia de otimização suportada para o seu dialeto. A otimização da tabela de origem é fortemente recomendada porque, sempre que a tabela incremental é atualizada, o Looker consulta a tabela de origem para determinar os valores mais recentes da coluna baseada no tempo que é usada para a chave de incremento. Se a tabela de origem não estiver otimizada para estas consultas, a consulta do Looker para os valores mais recentes pode ser lenta e dispendiosa.
Definir uma PDT incremental
Pode usar os seguintes parâmetros para transformar um PDT num PDT incremental:
increment_key(obrigatório para tornar o PDT um PDT incremental): define o período durante o qual devem ser consultados novos registos.{% incrementcondition %}Filtro Liquid (obrigatório para tornar uma PDT baseada em SQL uma PDT incremental; não aplicável a PDTs baseadas em LookML): associa a chave de incremento à coluna de tempo da base de dados na qual a chave de incremento se baseia. Consulte a página de documentaçãoincrement_keypara mais informações.increment_offset(opcional): um número inteiro que define o número de períodos anteriores (na granularidade da chave de incremento) que são reconstruídos para cada compilação incremental. O parâmetroincrement_offseté útil no caso de dados recebidos tardiamente, em que os períodos anteriores podem ter novos dados que não foram incluídos quando o incremento correspondente foi originalmente criado e anexado à PDT.
Consulte a página de documentação do parâmetro increment_key para ver exemplos que mostram como criar PDTs incrementais a partir de tabelas derivadas nativas persistentes, tabelas derivadas persistentes baseadas em SQL e tabelas de agregação.
Segue-se um exemplo simples de um ficheiro de visualização que define um PDT incremental baseado em LookML:
view: flights_lookml_incremental_pdt {
derived_table: {
indexes: ["id"]
increment_key: "departure_date"
increment_offset: 3
datagroup_trigger: flights_default_datagroup
distribution_style: all
explore_source: flights {
column: id {}
column: carrier {}
column: departure_date {}
}
}
dimension: id {
type: number
}
dimension: carrier {
type: string
}
dimension: departure_date {
type: date
}
}
Esta tabela é criada na íntegra na primeira vez que é executada uma consulta na mesma. Depois disso, o PDT é reconstruído em incrementos de um dia (increment_key: departure_date), retrocedendo três dias (increment_offset: 3).
A chave de incremento baseia-se na dimensão departure_date, que é, na verdade, o date intervalo do grupo de dimensões departure. (Consulte a página de documentação do parâmetro dimension_group para ver uma vista geral do funcionamento dos grupos de dimensões.) O grupo de dimensões e o período são definidos na vista flights, que é o explore_source para este PDT. Veja como o grupo de dimensões departure é definido no ficheiro de visualização flights:
...
dimension_group: departure {
type: time
timeframes: [
raw,
date,
week,
month,
year
]
sql: ${TABLE}.dep_time ;;
}
...
Interação dos parâmetros de incremento e da estratégia de persistência
As definições increment_key e increment_offset de uma PDT são independentes da estratégia de persistência da PDT:
- A estratégia de persistência do PDT incremental determina apenas quando o PDT é incrementado. O criador de PDTs não modifica o PDT incremental, a menos que a estratégia de persistência da tabela seja acionada ou que o PDT seja acionado manualmente com a opção Reconstruir tabelas derivadas e executar num Explore.
- Quando o PDT aumenta, o criador de PDT determina quando os dados mais recentes foram adicionados anteriormente à tabela, em termos do incremento de tempo mais atual (o período definido pelo parâmetro
increment_key). Com base nisso, o criador de PDTs trunca os dados até ao início do incremento de tempo mais recente na tabela e, em seguida, cria o incremento mais recente a partir daí. - Se o PDT tiver um parâmetro
increment_offset, o criador de PDTs também recompila o número de períodos anteriores especificados no parâmetroincrement_offset. Os períodos anteriores recuam a partir do início do incremento de tempo mais atual (o período definido pelo parâmetroincrement_key).
Os cenários de exemplo seguintes ilustram como os PDTs incrementais são atualizados, mostrando a interação de increment_key, increment_offset e a estratégia de persistência.
Exemplo 1
Este exemplo usa um PDT com as seguintes propriedades:
- Chave de incremento: data
- Increment offset: 3
- Estratégia de persistência: acionada uma vez por mês no primeiro dia do mês
Veja como esta tabela vai ser atualizada:
- Uma estratégia de persistência mensal significa que a tabela é criada automaticamente uma vez por mês. Isto significa que, a 1 de junho, por exemplo, a última linha na tabela foi adicionada a 1 de maio.
- Uma vez que este PDT tem uma chave de incremento baseada na data, o criador de PDTs vai truncar 1 de maio até ao início do dia e reconstruir os dados de 1 de maio até ao dia atual, 1 de junho.
- Além disso, este PDT tem um desvio de incremento de
3. Assim, o criador de PDTs também recompila os dados dos três períodos (dias) anteriores a 1 de maio. O resultado é que os dados são reconstruídos para os dias 28, 29 e 30 de abril, e até ao dia 1 de junho.
Em termos de SQL, este é o comando que o criador de PDT vai executar a 1 de junho para determinar as linhas do PDT existente que devem ser recriadas:
## Example SQL for BigQuery:
SELECT FORMAT_TIMESTAMP('%F %T',TIMESTAMP_ADD(MAX(pdt_name),INTERVAL -3 DAY))
## Example SQL for other dialects:
SELECT CAST(DATE_ADD(MAX(pdt_name),INTERVAL -3 DAY) AS CHAR)
Segue-se o comando SQL que o criador de PDT vai executar a 1 de junho para criar o incremento mais recente:
## Example SQL for BigQuery:
MERGE INTO [pdt_name] USING (SELECT [columns]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM'))
AS tmp_name ON FALSE
WHEN NOT MATCHED BY SOURCE AND created_date >= TIMESTAMP('4/28/21 12:00:00 AM')
THEN DELETE
WHEN NOT MATCHED THEN INSERT [columns]
## Example SQL for other dialects:
START TRANSACTION;
DELETE FROM [pdt_name]
WHERE created_date >= TIMESTAMP('4/28/21 12:00:00 AM');
INSERT INTO [pdt_name]
SELECT [columns]
FROM [source_table]
WHERE created_at >= TIMESTAMP('4/28/21 12:00:00 AM');
COMMIT;
Exemplo 2
Este exemplo usa um PDT com as seguintes propriedades:
- Estratégia de persistência: acionada uma vez por dia
- Chave de incremento: mês
- Incrementar desvio: 0
Veja como esta tabela vai ser atualizada a 1 de junho:
- A estratégia de persistência diária significa que a tabela é criada automaticamente uma vez por dia. A 1 de junho, a última linha da tabela terá sido adicionada a 31 de maio.
- Uma vez que a chave de incremento se baseia no mês, o criador de PDT vai truncar os dados de 31 de maio até ao início do mês e reconstruir os dados de todo o mês de maio e até ao dia atual, incluindo 1 de junho.
- Uma vez que esta PDT não tem um desvio de incremento, não são recriados períodos anteriores.
Veja como esta tabela vai ser atualizada a 2 de junho:
- A 2 de junho, a última linha da tabela terá sido adicionada a 1 de junho.
- Uma vez que o criador de PDTs vai truncar os dados até ao início do mês de junho e, em seguida, reconstruir os dados a partir de 1 de junho até ao dia atual, os dados são reconstruídos apenas para 1 e 2 de junho.
- Uma vez que esta PDT não tem um desvio de incremento, não são recriados períodos anteriores.
Exemplo 3
Este exemplo usa um PDT com as seguintes propriedades:
- Chave de incremento: mês
- Increment offset: 3
- Estratégia de persistência: acionada uma vez por dia
Este cenário ilustra uma configuração inadequada para uma PDT incremental, uma vez que é uma PDT de acionamento diário com um desvio de três meses. Isto significa que, todos os dias, são recriados, pelo menos, três meses de dados, o que seria uma utilização muito ineficiente de uma PDT incremental. No entanto, é um cenário interessante para analisar como forma de compreender o funcionamento dos PDTs incrementais.
Veja como esta tabela vai ser atualizada a 1 de junho:
- A estratégia de persistência diária significa que a tabela é criada automaticamente uma vez por dia. Por exemplo, a 1 de junho, a última linha da tabela foi adicionada a 31 de maio.
- Uma vez que a chave de incremento se baseia no mês, o criador de PDT vai truncar os dados de 31 de maio até ao início do mês e reconstruir os dados de todo o mês de maio e até ao dia atual, incluindo 1 de junho.
- Além disso, este PDT tem um desvio de incremento de
3. Isto significa que o criador de PDT também recompila os dados dos três períodos (meses) anteriores a maio. O resultado é que os dados são recompilados a partir de fevereiro, março, abril e até ao dia atual, 1 de junho.
Veja como esta tabela vai ser atualizada a 2 de junho:
- A 2 de junho, a última linha da tabela terá sido adicionada a 1 de junho.
- O criador de PDT trunca o mês até 1 de junho e recompila os dados para o mês de junho, incluindo 2 de junho.
- Além disso, devido à compensação do incremento, o criador do PDT vai reconstruir os dados dos três meses anteriores a junho. O resultado é que os dados são reconstruídos a partir de março, abril, maio e até ao dia atual, 2 de junho.
Testar uma PDT incremental no modo de programação
Antes de implementar um novo PDT incremental no seu ambiente de produção, pode testar o PDT para se certificar de que é criado e incrementado. Para testar uma PDT incremental no modo de programação:
Crie uma exploração para o PDT:
- Num ficheiro de modelo associado, use o parâmetro
includepara incluir o ficheiro de visualização do PDT no ficheiro de modelo. - No mesmo ficheiro de modelo, use o parâmetro
explorepara criar uma análise detalhada da vista do PDT incremental.
include: "/views/e_faa_pdt.view" explore: e_faa_pdt {}- Num ficheiro de modelo associado, use o parâmetro
Abra a página Explorar para o PDT. Para tal, selecione o botão Ver ações de ficheiros e, de seguida, selecione um nome do Explorar.
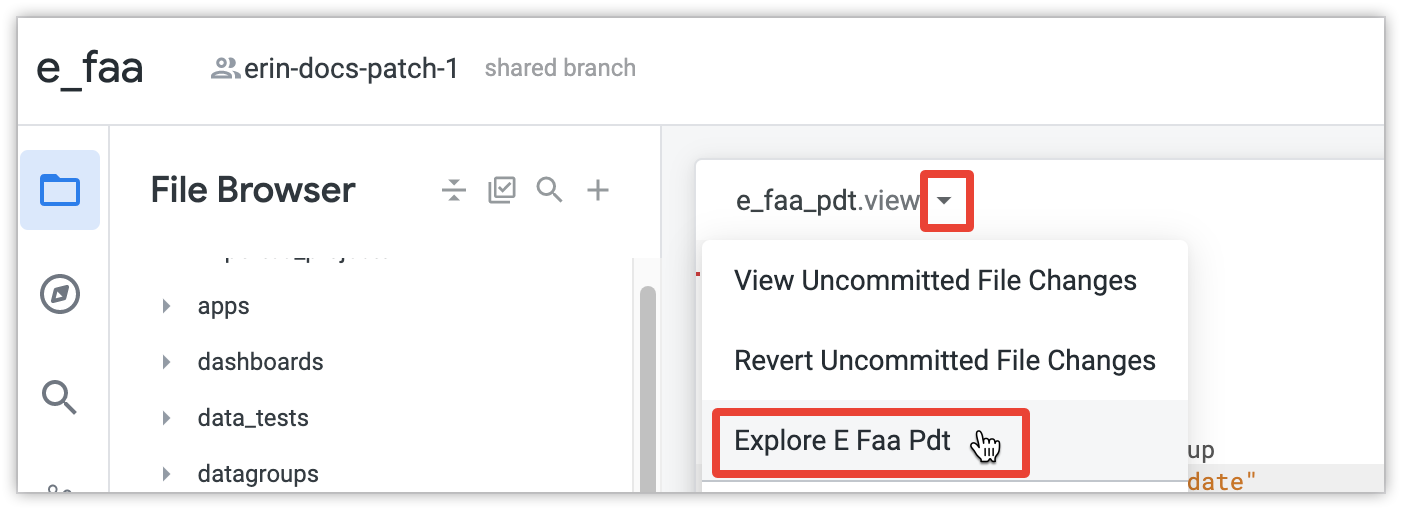
Na opção Explorar, selecione algumas dimensões ou medidas e clique em Executar. Em seguida, o Looker cria a PDT completa. Se esta for a primeira consulta que executou no PDT incremental, o criador de PDT cria o PDT completo para obter os dados iniciais. Se a tabela for grande, a criação inicial pode demorar bastante tempo, tal como a criação de qualquer tabela grande.
Pode verificar se o PDT inicial foi criado das seguintes formas:
- Se tiver a autorização
see_logs, pode verificar se a tabela foi criada consultando o registo de eventos do PDT. Se não vir os eventos de criação da PDT no registo de eventos da PDT, verifique as informações de estado na parte superior da análise detalhada do registo de eventos da PDT. Se for apresentado "da cache", pode selecionar Limpar cache e atualizar para obter informações mais recentes. - Caso contrário, pode consultar os comentários no separador SQL da barra Dados do Explorar. O separador SQL mostra a consulta e as ações que vão ser realizadas quando executar a consulta na funcionalidade Explorar. Por exemplo, se os comentários no separador SQL indicarem
-- generate derived table e_incremental_pdt,
- Se tiver a autorização
Depois de criar a compilação inicial do PDT, solicite uma compilação incremental do PDT através da opção Recompilar tabelas derivadas e executar no Explore.
Pode usar os mesmos métodos que anteriormente para verificar se o PDT é criado de forma incremental:
- Se tiver a autorização
see_logs, pode usar o registo de eventos do PDT para ver os eventoscreate increment completedo PDT incremental. Se não vir este evento no registo de eventos do PDT e o estado da consulta indicar "da cache", selecione Limpar cache e atualizar para obter informações mais recentes. - Consulte os comentários no separador SQL da barra Dados do Explore. Neste caso, os comentários indicam que o PDT foi incrementado. Por exemplo:
-- increment persistent derived table e_incremental_pdt to generation 2
- Se tiver a autorização
Depois de verificar que o PDT está criado e a ser incrementado corretamente, se não quiser manter a análise detalhada dedicada para o PDT, pode remover ou comentar os parâmetros
exploreeincludedo PDT no ficheiro de modelo.
Depois de o PDT ser criado no modo de programação, a mesma tabela é usada para produção assim que implementar as alterações, a menos que faça mais alterações à definição da tabela. Consulte a secção Tabelas persistentes no modo de desenvolvimento da página de documentação Tabelas derivadas no Looker para mais informações.
Resolução de problemas de PDTs incrementais
Esta secção descreve alguns problemas comuns que pode encontrar ao usar PDTs incrementais, bem como passos para resolver esses problemas.
A PDT incremental não é criada após a alteração do esquema
Se o PDT incremental for uma tabela derivada baseada em SQL e o parâmetro sql incluir um caráter universal, como SELECT *, as alterações ao esquema da base de dados subjacente (como a adição, a remoção ou a alteração do tipo de dados de colunas) podem fazer com que o PDT falhe com o seguinte erro:
SQL Error in incremental PDT: Query execution failed
Para resolver este problema, edite a declaração SELECT no parâmetro sql para selecionar colunas individuais. Por exemplo, se a cláusula SELECT for SELECT *, altere-a para SELECT column1, column2, ....
Se o seu esquema mudar e quiser reconstruir o PDT incremental de raiz, use a chamada API start_pdt_build e inclua o parâmetro full_force_incremental.
Dialetos de base de dados suportados para PDTs incrementais
Para que o Looker suporte PDTs incrementais no seu projeto do Looker, o dialeto da base de dados tem de suportar comandos de linguagem de definição de dados (DDL) que permitam eliminar e inserir linhas.
A tabela seguinte mostra que dialetos suportam PDTs incrementais na versão mais recente do Looker (para o Databricks, as PDTs incrementais só são suportadas na versão 12.1 e posteriores do Databricks):
| Dialeto | Suportado? |
|---|---|
| Actian Avalanche | Não |
| Amazon Athena | Não |
| Amazon Aurora MySQL | Não |
| Amazon Redshift | Sim |
| Amazon Redshift 2.1+ | Sim |
| Amazon Redshift Serverless 2.1+ | Sim |
| Apache Druid | Não |
| Apache Druid 0.13+ | Não |
| Apache Druid 0.18+ | Não |
| Apache Hive 2.3+ | Não |
| Apache Hive 3.1.2+ | Não |
| Apache Spark 3+ | Não |
| ClickHouse | Não |
| Cloudera Impala 3.1+ | Não |
| Cloudera Impala 3.1+ with Native Driver | Não |
| Cloudera Impala with Native Driver | Não |
| DataVirtuality | Não |
| Databricks | Sim |
| Denodo 7 | Não |
| Denodo 8 & 9 | Não |
| Dremio | Não |
| Dremio 11+ | Não |
| Exasol | Não |
| Google BigQuery Legacy SQL | Não |
| Google BigQuery Standard SQL | Sim |
| Google Cloud PostgreSQL | Sim |
| Google Cloud SQL | Não |
| Google Spanner | Não |
| Greenplum | Sim |
| HyperSQL | Não |
| IBM Netezza | Não |
| MariaDB | Não |
| Microsoft Azure PostgreSQL | Sim |
| Microsoft Azure SQL Database | Não |
| Microsoft Azure Synapse Analytics | Sim |
| Microsoft SQL Server 2008+ | Não |
| Microsoft SQL Server 2012+ | Não |
| Microsoft SQL Server 2016 | Não |
| Microsoft SQL Server 2017+ | Não |
| MongoBI | Não |
| MySQL | Sim |
| MySQL 8.0.12+ | Sim |
| Oracle | Não |
| Oracle ADWC | Não |
| PostgreSQL 9.5+ | Sim |
| PostgreSQL pre-9.5 | Sim |
| PrestoDB | Não |
| PrestoSQL | Não |
| SAP HANA | Não |
| SAP HANA 2+ | Não |
| SingleStore | Não |
| SingleStore 7+ | Não |
| Snowflake | Sim |
| Teradata | Não |
| Trino | Não |
| Vector | Não |
| Vertica | Sim |