SQL のバックグラウンドから Looker を利用している場合、Looker で SQL がどのように生成されるのかに興味をお持ちではないでしょうか。基本的に、Looker は SQL クエリを生成してデータベース接続に対して送信するツールです。Looker は、データベースのテーブルと列の関係を記述する LookML プロジェクトに基づいて SQL クエリを作成します。Looker でクエリが生成される仕組みを理解することで、LookML コードが効率的な SQL クエリに変換される仕組みをより深く理解できます。
すべての LookML パラメータは、クエリの構造、コンテンツ、動作を変更することによって、Looker による SQL の生成方法のいくつかのアスペクトを制御します。このページでは、Looker が SQL を生成する方法の原則について説明しますが、すべての LookML 要素について詳しく説明しているわけではありません。LookML クイック リファレンスのドキュメント ページは、LookML パラメータに関する情報収集に着手するのに適しています。
クエリの表示
保存済み Look または Explore では、[SQL] パネルの [SQL] タブを使用して、Looker がデータ取得のためにデータベースに送信するクエリを確認できます。[SQL] タブの下部にある [SQL Runner で開く] と [SQL Runner で説明する] を使用すると、SQL Runner でクエリを表示できます。または、クエリに対するデータベースの説明プランを確認できます。
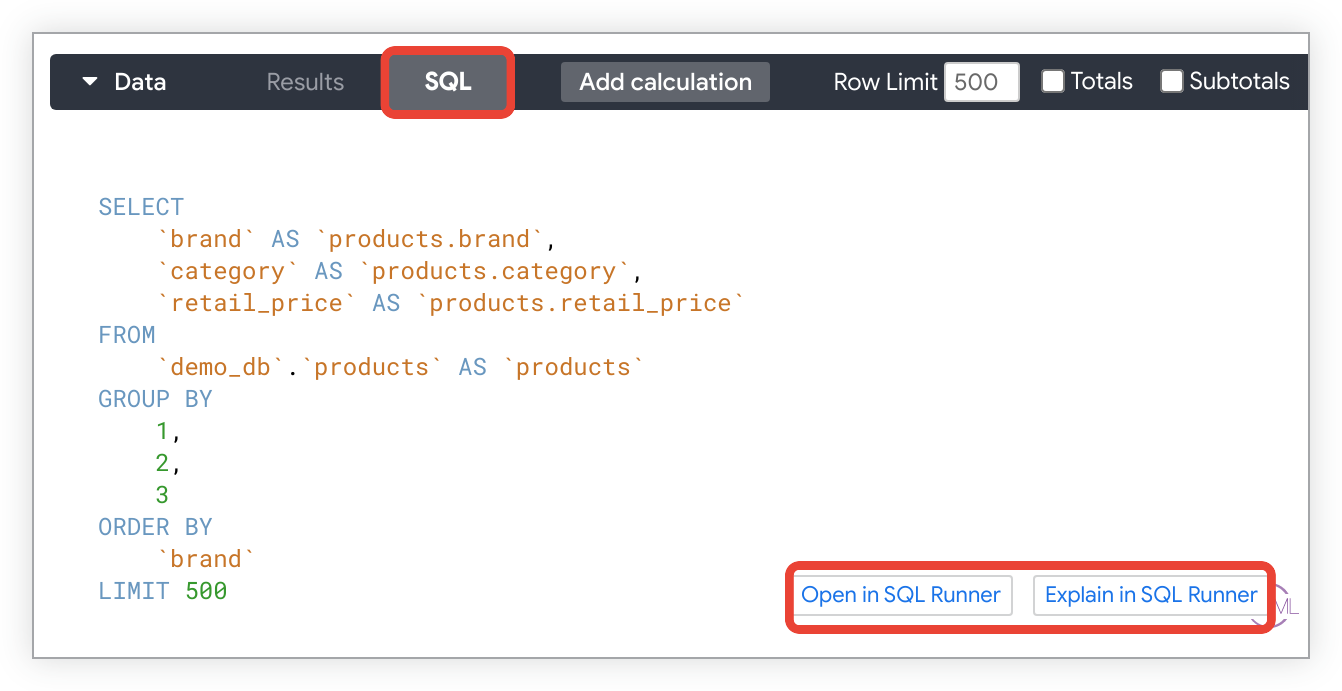
SQL Runner の詳細については、SQL Runner の基本のドキュメント ページをご覧ください。SQL Runner を使用したクエリの最適化の詳細については、EXPLAIN を使用して SQL を最適化する方法のコミュニティ投稿をご覧ください。
Looker クエリの正規形式
Looker の SQL クエリは常に次の形式になります。
SELECT
<dimension>, <dimension>, ...
<measure>, <measure>, ...
FROM <explore>
LEFT JOIN <view> ON ...
LEFT JOIN <view> ON ...
WHERE (<dimension_filter_expression>) AND (<dimension_filter_expression>) AND ...
GROUP BY <dimension>, <dimension>, <dimension>, ...
HAVING <measure_filter_expression> AND <measure_filter_expression> AND ...
ORDER BY <dimension> | <measure>
LIMIT <limit>
LookML プロジェクトは、SQL クエリで参照されるすべてのディメンション、メジャー、Explore、ビューを定義します。フィルタ式は Looker でユーザーが指定し、アドホック クエリを作成します。フィルタ式は、LookML で直接宣言して、すべてのクエリに適用することもできます。
Looker クエリの基本コンポーネント
すべての Looker クエリは、前の例クエリに示されているように、LookML プロジェクトに適用されるこれらの基本パラメータによって表されます。
Looker は、次のパラメータを使用して完全な SQL クエリを生成します。
model: ターゲットにする LookML モデルの名前。ターゲット データベースを指定します。explore: クエリを実行する Explore の名前。SQLFROM句が入力されます。- フィールド: クエリに含める
dimensionパラメータとmeasureパラメータ。SQL のSELECT句が入力されます。 filter: 0 個以上のフィールドに適用する Looker フィルタ式。SQL のWHERE句とHAVING句が入力されます。- 並べ替え順序: 並べ替えるフィールドと並べ替え順序。SQL の
ORDER BY句が入力されます。
これらのパラメータは、まさに Looker の Explore ページでクエリを作成する際にユーザーが指定する要素です。これら同じ要素は、生成された SQL、クエリを表す URL、Looker API など、Looker でクエリを実行するすべてのモードに表示されます。
LEFT JOIN 句で指定されたビューはどうでしょうか?JOIN 句は、ビューが Explore に結合される方法を指定する LookML モデルの構造に基づいて入力されます。SQL クエリを作成するとき、Looker は必要な場合にのみ JOIN 句を含めます。ユーザーが Looker でクエリを作成する場合、テーブルをまとめて結合する方法を指定する必要がありません。それは、この情報はモデルにエンコードされるためです。このことは、ビジネス ユーザーにとっての Looker の最も大きな利点の 1 つです。
クエリの例と生成される SQL
Looker でクエリを作成し、以前のパターンに従ってクエリがどのように生成されるかを見てみましょう。ユーザーと注文を追跡するために、orders と users という 2 つのテーブルを含むデータベースを持つ e コマースストアについて考えてみましょう。
orders |
|---|
id INT |
created_at DATETIME |
users_id INT |
status VARCHAR(255) |
traffic_source VARCHAR(15) |
users |
|---|
id INT |
email VARCHAR(255) |
first_name VARCHAR(255) |
last_name VARCHAR(255) |
created_at DATETIME |
zip INT |
country VARCHAR(255) |
state VARCHAR(255) |
city VARCHAR(255) |
age INT |
traffic_source VARCHAR(15) |
Looker Explorer で、状態(USERS State)別にグループ化され、注文の作成日(ORDERS Created Date)でフィルタされた注文数([ORDERS Count])を検索します。
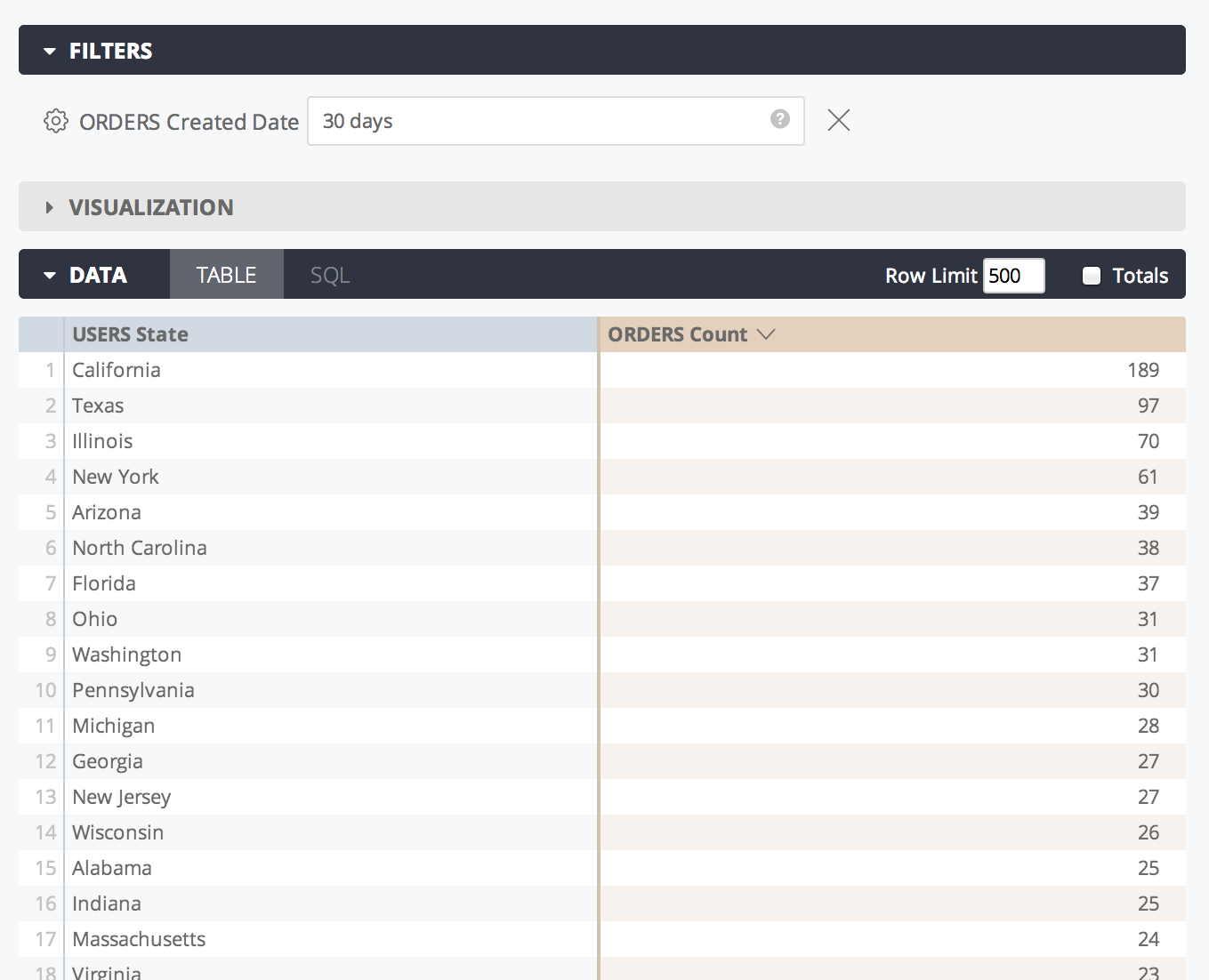
Looker によって生成および実行される SQL クエリを表示するには、[SQL] パネルの [SQL] タブをクリックします。
SELECT COALESCE(users.state, ' ') AS "_g1",
users.state AS 'users.state',
COUNT(DISTINCT orders.id) AS 'orders.count'
FROM orders
LEFT JOIN users ON orders.user_id = users.id
WHERE
orders.created_at BETWEEN (CONVERT_TZ(DATE_ADD(CURDATE(), INTERVAL -29 day), 'America/Los_Angeles', 'UTC',)) AND (CONVERT_TZ(DATE_ADD(DATE_ADD(DATE_ADD(CURDATE(), INTERVAL -29 day), INTERVAL 30 day), INTERVAL -1 second), 'America/Los_Angeles', 'UTC'))
GROUP BY 1
ORDER BY COUNT(DISTINCT orders.id) DESC
LIMIT 500
正規のクエリ式と類似しています。Looker SQL は、マシンで生成されたコード(たとえば、COALESCE(users.state,'') AS "_g1")のいくつかの特性を示しますが、常にその式に適合します。
Looker でより多くのクエリを試して、クエリ構造が常に同じであることを証明してください。
Looker の SQL Runner で未加工の SQL を実行する
Looker には SQL Runner という機能があり、Looker で設定したデータベース接続に対して任意の SQL を実行できます。
Looker によって生成されたすべてのクエリは、完全な機能する SQL コマンドとなるため、SQL Runner を使用してクエリを調査したり操作したりできます。
SQL Runner で実行される未加工の SQL クエリは、同じ結果セットを生成します。SQL にエラーが含まれている場合、SQL Runner は SQL コマンド内の最初のエラーの場所をハイライト表示し、エラー メッセージにそのエラーの位置を含めます。
拡張 URL 内のクエリ コンポーネントの調査
Looker でクエリを実行した後、拡張 URL を調べて、Looker クエリの基本コンポーネントを確認します。まず、Explore の歯車メニューから [共有] を選択して、[URL を共有] メニューを開きます。
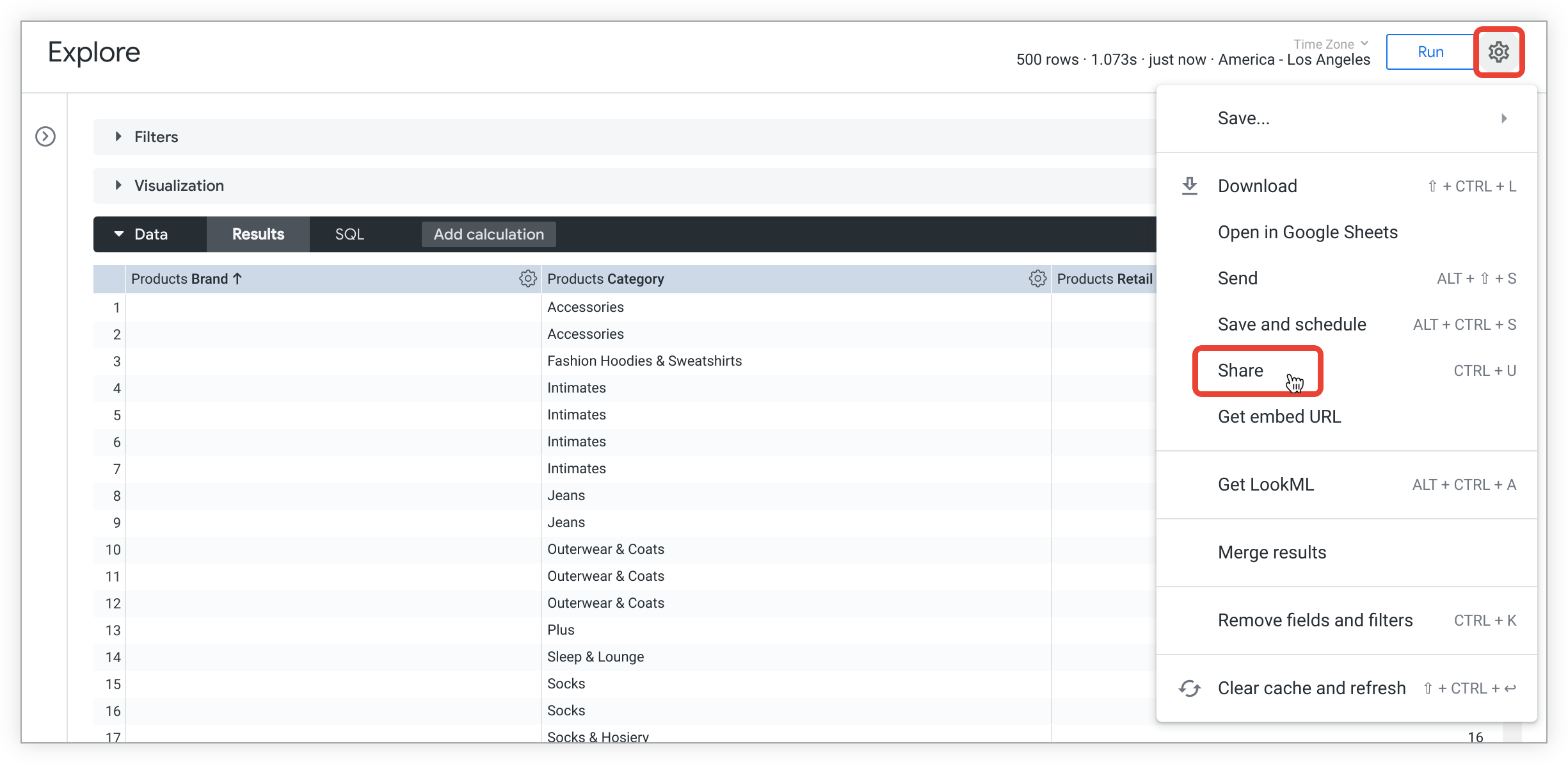
拡張 URL には、クエリを再作成するのに十分な情報が含まれています。たとえば、この拡張 URL の例では次の情報が提供されます。
https://<Looker instance URL>.cloud.looker.com/explore/e_thelook/events?fields=users.state,users.count
&f[users.created_year]=2020&sorts=users.count+desc&limit=500
| モデル | e_thelook |
| explore | events |
| クエリを実行して表示するフィールド | fields=users.state,users.count |
| 並べ替えフィールドと順序 | sorts=users.count+desc |
| フィールドと値をフィルタする | f[users.created_year]=2020 |
Looker による JOIN の構造
前述の例のクエリでは、メインの FROM 句に orders Explore が、LEFT JOIN 句に結合されたビューが表示されています。Looker の結合は多くの異なる方法で記述できます。詳細は LookML での結合の操作で説明されています。
SQL ブロックはカスタム SQL 句を指定
Looker クエリのすべての要素が自動生成されるわけではありません。ある時点で、データモデルは、Looker が基になるテーブルにアクセスして派生値を計算するための特定の詳細情報を提供する必要があります。LookML では、SQL ブロックはデータモデラーによって提供される SQL コードのスニペットです。Looker はこれを使用して完全な SQL 式を合成します。
最も一般的な SQL ブロック パラメータは sql で、ディメンションとメジャーの定義で使用されます。sql パラメータは、基になる列を参照する SQL 句や集計関数を実行する SQL 句を指定します。一般的に、sql_ で始まるすべての LookML パラメータは、特定の形式の SQL 式を想定しています。例えば、sql_always_where、sql_on、およびsql_table_name。各パラメータの詳細については、LookML リファレンスをご覧ください。
ディメンションやメジャー用のSQLブロックの例
以下のコードサンプルは、ディメンションとメジャー用の SQL ブロックの例です。LookML 置換演算子($)により、これらの sql 宣言が SQL と一見違って表示されます。しかし、置換を行った後のストリングは純粋なSQLとなります。Lookerはこれをクエリの SELECT 句に挿入します。
dimension: id {
primary_key: yes
sql: ${TABLE}.id ;; # Specify the primary key, id
}
measure: average_cost {
type: average
value_format: "0.00"
sql: ${cost} ;; # Specify the field that you want to average
# The field 'cost' is declared elsewhere
}
dimension: name {
sql: CONCAT(${first_name}, ' ', ${last_name}) ;;
}
dimension: days_in_inventory {
type: number
sql: DATEDIFF(${sold_date}, ${created_date}) ;;
}
この例のディメンションの最後の 2 つに示されているように、SQL ブロックは、基盤となるデータベースでサポートしている関数(この場合は MySQL 関数 CONCAT と DATEDIFF など)を使用できます。SQL ブロックで使用するコードは、データベースで使用される SQL ダイアレクトと一致する必要があります。
派生テーブルのためのSQLブロックの例
派生テーブルはSQLブロックも使って、テーブルを派生させるクエリを指定します。これは、SQL ベースの派生テーブルの例です。
view: user_order_facts {
derived_table: {
sql:
SELECT
user_id
, COUNT(*) as lifetime_orders
FROM orders
GROUP BY 1 ;;
}
# later, dimension declarations reference the derived column(s)…
dimension: lifetime_orders {
type: number
}
}
Explore をフィルタリングする SQL ブロックの例
sql_always_where と sql_always_having の LookML パラメータを使用すると、SQL の WHERE 句または HAVING 句に SQL ブロックを挿入することで、クエリで使用できるデータを制限できます。この例では、LookML 置換演算子 ${view_name.SQL_TABLE_NAME} を使用して派生テーブルを参照しています。
explore: trips {
view_label: "Long Trips"
# This will ensure that we only see trips that are longer than average!
sql_always_where: ${trips.trip_duration}>=(SELECT tripduration FROM ${average_trip_duration.SQL_TABLE_NAME});;
}