このページでは、Looker からコンテンツ(可視化またはデータ)をダウンロードする方法について説明します。
コンテンツをダウンロードするには、Looker 管理者から download_with_limit または download_without_limit の権限を付与されている必要があります。
コンテンツのダウンロードおよびダウンロードしたコンテンツのフォーマットに関するプロセスおよびオプションは、Look または Explore、ダッシュボード、または結合結果クエリのいずれからダウンロードするかに応じて異なります。
Look または Explore からデータをダウンロードする
Look または Explore ページからデータをダウンロードするには、右上の歯車メニューを選択して [ダウンロード] を選択します。
Looker に [ダウンロード] ウィンドウが表示され、ダウンロードの名前と形式を設定できます。

以下のセクションでは、[ダウンロード] ウィンドウの各フィールドについて説明します。
形式
レンダラを使用する形式(PNG と PDF)へのダウンロードでは、本番環境モードの結果が使用されます。別の形式でダウンロードする場合は、使用している(開発モードまたは本番環境モード)モードの結果が表示されます。
Look と Explore から次のファイル形式でデータをダウンロードできます。
- TXT(タブ区切り値)
- Excel スプレッドシート(Excel 2007以降)
- CSV
- JSON
- HTML
- マークダウン
- PNG(表示画像)
ダウンロードするデータ形式を選択する際に、Look 用の HTML または PNG(表示画像)オプションが表示されない場合は、Looker 管理者に問い合わせて、Looker インスタンス用の Chromium レンダラの適切なバージョンをインストールする方法をご確認ください。
JSON 形式の場合、Looker は JSON 出力でレンダリングされた値としてフィールド ラベルを使用します。Looker で JSON 形式でフィールドがどのようにレンダリングされるかについては、JSON 形式の変更のコミュニティ投稿をご覧ください。
行 / 列の入れ替えられたテーブルでは、PNG ダウンロードでのみレンダリングされます。
Looker デベロッパーの場合、Development Mode では、ほとんどのファイル形式でのデータ ダウンロードは、Development Mode にあるものとしてモデルのクエリを実行します。PDF ファイル形式と PNG ファイル形式は例外です。これらのファイル形式でデータがダウンロードされる場合、常に本番環境モードにあるかのようにモデルがクエリされます。
ファイル名
ダウンロード用のファイル名を入力するか、フィールドに事前入力されたデフォルトのファイル名を使用できます。[形式] フィールドで選択した内容に基づいて、適切なファイル拡張子が自動的に追加されます。
結果
[結果] セクションで、可視化設定を TXT、Excel、CSV、JSON、HTML、マークダウンのデータのダウンロードに適用するかどうかを選択します。
[表示オプションの適用] を選択すると、表示設定の一部が適用されます。表示用に構成された [プロット]、[シリーズ]、[書式設定] メニューの次のいずれかの設定は、データのダウンロードに適用されます。
- 行番号を表示
- 合計を表示する
- 行の合計を表示する
- 表示する行を制限する。最大 500 行まで表示または非表示にします
- Show Full Field Name
- 各列のカスタムラベル(Looker では、JSON 出力でレンダリングされた値としてフィールドラベルを使用します。Looker で JSON 形式のフィールドがどのようにレンダリングされるかについては、Looker のコミュニティ投稿のJSON 形式の変更をご覧ください。
- Excel 形式で表示されたテーブルグラフをダウンロードするための条件付きフォーマット
スケーリング ルールを適用が適用されている場合にのみ、テーブルグラフが可視化された条件付き書式が Look と Explore の Excel デリバリーで表示されます。
一部の可視化設定は、ダウンロードした結果には適用されません。次に例を示します。
- カスタム ヘッダーのテキスト色と背景色は、PNG ファイルを除き、ダウンロードした結果には適用されません。
- ピボットと複数のメジャーを含む結果表では、各ピボット値は 1 つの結合列としてではなく、列全体にわたって繰り返されます。HTML と PNG のダウンロードは例外であるため、統合された列は保持されます。
- ダッシュボードからダウンロードする場合、ダウンロードした結果にダッシュボード タイルのタイトルは含まれません。
- [合計] と [行の合計] の値はダウンロードされた結果に含まれますが、それぞれの行と列にはラベルが付けられません。
- ストリーミングできないクエリの小計はダウンロードされません。
クエリに次のいずれかの要素が含まれている場合、手動で並べ替えられたテーブルグラフの列は、ダウンロードされた元の順序で表示されます。
- 可視化で意図的に非表示になっているフィールド
基盤となる SQL には存在するが、可視化には存在しないフィールド。次に例を示します。
- 可視化に存在していない別のフィールドを参照する
linkパラメータを含む、可視化に存在するディメンション。 caseパラメータを使用するフィールド。- 可視化に存在していない
{{ field_name._value }} Liquid variable syntaxを持つ別のフィールドを参照する、可視化に存在するディメンション。
- 可視化に存在していない別のフィールドを参照する
ディメンション フィルが有効になっている 1 つ以上のフィールド
3 つ以上のピボット フィールド
有効になっている行の合計
フィールド定義に
order_by_fieldLookML パラメータを含む 1 つ以上のフィールド
[データテーブルに表示] を選択すると、可視化オプションは適用されず、Look または Explore の [Data] セクションにデータテーブルが表示されます。
データ値
[データ値] セクションで、ダウンロードしたクエリ結果の表示方法を選択します。
- [Unformated] を選択した場合、Looker では、Looker デベロッパーが配置した長すぎる番号の丸めや特殊文字の追加など、特別な形式のクエリ結果を適用しません。これは多くの場合、処理のためにデータを他のツールにフィードするときに推奨されます。
- [書式設定済み] を選択すると、データの外観は Looker の [Explore] エクスペリエンスに似ていますが、一部のファイル形式(リンクなど)ではすべてのファイル形式でサポートされるわけではありません。たとえば、
htmlパラメータで適用された書式は、TXT、CSV、Excel、JSON のダウンロードには適用されません。
含める行と列の数
ダウンロードするデータの量は、次のように選択できます。
- 現在の結果テーブル: コンテンツの行数制限で指定された行数。
- すべての結果: クエリによって返されたすべての結果。このオプションを選択する前に、このページのすべての結果セクションをご覧ください。
- カスタム: 行のカスタム数。
download_with_limit権限を持つユーザーは、5,000 行までに制限されます。他のユーザーの上限は通常 100,000 です。
すべての検索結果
Look または Explore で [実行] を選択すると、Looker が権限をチェックし、クエリの複雑さとデータベース言語によってクエリ全体をダウンロードできるかどうかが判定されます。権限があり(設定した制限を超える結果の場合)、クエリ全体をダウンロードできると Looker が判断した場合、[ダウンロード] ウィンドウで [すべての結果] オプションを利用できます。
通常、[すべての結果] オプションは、次のいずれかを行うクエリに対して無効になります。
- 行の合計または表計算を含む
- [合計に対する割合]、[前の行に対する割合]、または累積の種類の measure を使用します。
- 結果をストリーミングできないデータベース言語からデータを取得する
- ピボットを計算できないデータベース言語からデータが取得されるため、Looker で計算されるピボット列を含める
[すべての結果] オプションが使用可能な場合でも、すべての結果をダウンロードする際は注意が必要です。クエリによっては、数千行または数百万行が含まれる非常に大きなクエリがあり、ほとんどのスプレッドシート プログラムや Looker インスタンスで処理しきれない場合があります。
[すべての結果] オプションを使用できない場合は、[カスタム] オプションを使用して、権限で許可されている行の最大数を指定できます。
クエリ結果をストリーミングする
ストリーミングとは、データを一度にすべてではなくチャンクとして処理するLookerの機能のことです。Lookerが結果セットをストリーミングできる場合、無制限の数のダウンロードが可能です。 [すべての結果] オプションは、Looker の結果ストリーミング機能に依存しています。結果のストリーミングが不可能な場合、[すべての結果] は使用できません。
書式設定制限に加え、ストリーミングが不可能な次の2つのケースがあります。
- 表計算: 表計算をストリーミングすることはできません。そのため、クエリ結果を無制限にダウンロードするには、クエリから表計算を削除することが必要です。
- データベースの制限: クエリにピボットが含まれている場合、一部のデータベースはストリーミングできません。そうしたデータベースの場合、結果を無制限にダウンロードするにはピボットを削除しなければなりません。いずれの結果もストリーミングできないデータベースもあります。その場合は、無制限のダウンロードも行えません。
ストリーミングをサポートしているデータベースは次のとおりです。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | ○ |
| Amazon Aurora MySQL | ○ |
| Amazon Redshift | ○ |
| Apache Druid | × |
| Apache Druid 0.13+ | × |
| Apache Druid 0.18+ | × |
| Apache Hive 2.3+ | ○ |
| Apache Hive 3.1.2+ | ○ |
| Apache Spark 3 以降 | ○ |
| ClickHouse | ○ |
| Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala | ○ |
| DataVirtuality | ○ |
| Databricks | ○ |
| Denodo 7 | ○ |
| Denodo 8 | ○ |
| Dremio | ○ |
| Dremio 11+ | ○ |
| Exasol | ○ |
| Firebolt | ○ |
| Google BigQuery Legacy SQL | ○ |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | ○ |
| Google Cloud SQL | ○ |
| Google Spanner | × |
| Greenplum | ○ |
| HyperSQL | × |
| IBM Netezza | × |
| MariaDB | ○ |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | ○ |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | ○ |
| Microsoft SQL Server 2012+ | ○ |
| Microsoft SQL Server 2016 | ○ |
| Microsoft SQL Server 2017+ | ○ |
| MongoBI | ○ |
| MySQL | ○ |
| MySQL 8.0.12+ | ○ |
| Oracle | ○ |
| Oracle ADWC | ○ |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL 9.5 より前 | ○ |
| PrestoDB | ○ |
| PrestoSQL | ○ |
| SAP HANA 2+ | × |
| SingleStore | ○ |
| SingleStore 7+ | ○ |
| Snowflake | ○ |
| Teradata | ○ |
| Trino | ○ |
| Vector | ○ |
| Vertica | ○ |
ピボットが適用されているストリーミングをサポートしているデータベースは次のとおりです。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | ○ |
| Amazon Athena | ○ |
| Amazon Aurora MySQL | × |
| Amazon Redshift | ○ |
| Apache Druid | × |
| Apache Druid 0.13+ | × |
| Apache Druid 0.18+ | × |
| Apache Hive 2.3+ | × |
| Apache Hive 3.1.2+ | × |
| Apache Spark 3 以降 | ○ |
| ClickHouse | × |
| Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala 3.1+ | ○ |
| ネイティブ ドライバを使用した Cloudera Impala | ○ |
| DataVirtuality | × |
| Databricks | ○ |
| Denodo 7 | × |
| Denodo 8 | × |
| Dremio | × |
| Dremio 11+ | × |
| Exasol | ○ |
| Firebolt | ○ |
| Google BigQuery Legacy SQL | ○ |
| Google BigQuery Standard SQL | ○ |
| Google Cloud PostgreSQL | ○ |
| Google Cloud SQL | × |
| Google Spanner | × |
| Greenplum | ○ |
| HyperSQL | × |
| IBM Netezza | ○ |
| MariaDB | × |
| Microsoft Azure PostgreSQL | ○ |
| Microsoft Azure SQL Database | ○ |
| Microsoft Azure Synapse Analytics | ○ |
| Microsoft SQL Server 2008+ | ○ |
| Microsoft SQL Server 2012+ | ○ |
| Microsoft SQL Server 2016 | ○ |
| Microsoft SQL Server 2017+ | ○ |
| MongoBI | × |
| MySQL | × |
| MySQL 8.0.12+ | × |
| Oracle | ○ |
| Oracle ADWC | ○ |
| PostgreSQL 9.5+ | ○ |
| PostgreSQL 9.5 より前 | ○ |
| PrestoDB | ○ |
| PrestoSQL | ○ |
| SAP HANA 2+ | × |
| SingleStore | ○ |
| SingleStore 7+ | ○ |
| Snowflake | ○ |
| Teradata | ○ |
| Trino | ○ |
| Vector | ○ |
| Vertica | ○ |
クエリからすべての並べ替えを削除
[すべての結果] を選択すると、[クエリからすべての並べ替えを削除] のオプションが表示されることもあります。このオプションを選択すると、結果をダウンロードする前にクエリを並べ替えることができなくなります。特定のデータベース タイプでは、クエリの並べ替えがパフォーマンスに影響する可能性があるため、このオプションを選択するとダウンロードが速くなることがあります。
[クエリからすべての並べ替えを削除] オプションは、ピボット結果ではサポートされていません。
大容量の結果の許可
データベース言語として Google BigQuery を使用して Looker で大規模な結果セットをダウンロードするときに [すべての結果] を選択すると、大規模な結果の許可 オプションが表示されます。これは、Google Cloud ドキュメントのトピックのクエリ結果の書き込みで説明されているように、Google BigQuery がクエリ結果の最大レスポンス サイズを持っているためです。BigQuery の最大レスポンス サイズを超える結果をダウンロードするには、Looker で別のプロセスを実行する必要があります。
[大容量の結果の許可] を選択した場合、ダウンロード プロセスは次のように影響を受けます。
- クエリの
allowLargeResultsBigQuery オプションはtrueに設定されます。 - クエリの
ORDER BY句が削除されます。 - クエリは PDT 一時スキーマに書き込まれます。このスキーマに書き込む権限が必要です。
- クエリの結果は、この一時的なスクラッチ スキーマにランダムなテーブル名で 1 時間保存されます。
ブラウザでダウンロードするか開く
オプションを選択したら、[ダウンロード] ボタンをクリックしてコンピュータにファイルをダウンロードするか、[ブラウザで開く] を選択してブラウザでファイルを表示します。
マージされた結果クエリからのデータのダウンロード
統合結果クエリをダウンロードするには、クエリをダッシュボードに保存してから、ダッシュボードを PDF または CSV ファイルのコレクションとしてダウンロードします。ただし、ダッシュボード全体をダウンロードする必要があります。統合された結果クエリに基づく単一のタイルのデータをダウンロードすることはできません。
ダッシュボードからのデータのダウンロード
ダッシュボード全体をダウンロードするには、ダッシュボードのその他メニューから [ダウンロード] を選択します。
これにより、ダウンロード形式として PDF または CSV を選択できるダイアログボックスが表示されます。
ダッシュボードを PDF としてダウンロードする
ダッシュボード全体を PDF としてダウンロードできます。この場合、ダッシュボードのタイトル、ダッシュボードフィルタ、一部またはすべてのダッシュボードタイル、ダッシュボードが実行されているタイムゾーンが含まれている PDF を取得することになります。PDF には、ダッシュボードのダウンロード時刻を示すタイムスタンプも含まれます。
PDF 形式でのダウンロードでは、Development Mode にあっても、常に本番環境モードのモデルからデータが返されます。
ダッシュボードをPDFとしてダウンロードするには、以下のステップを実行します。
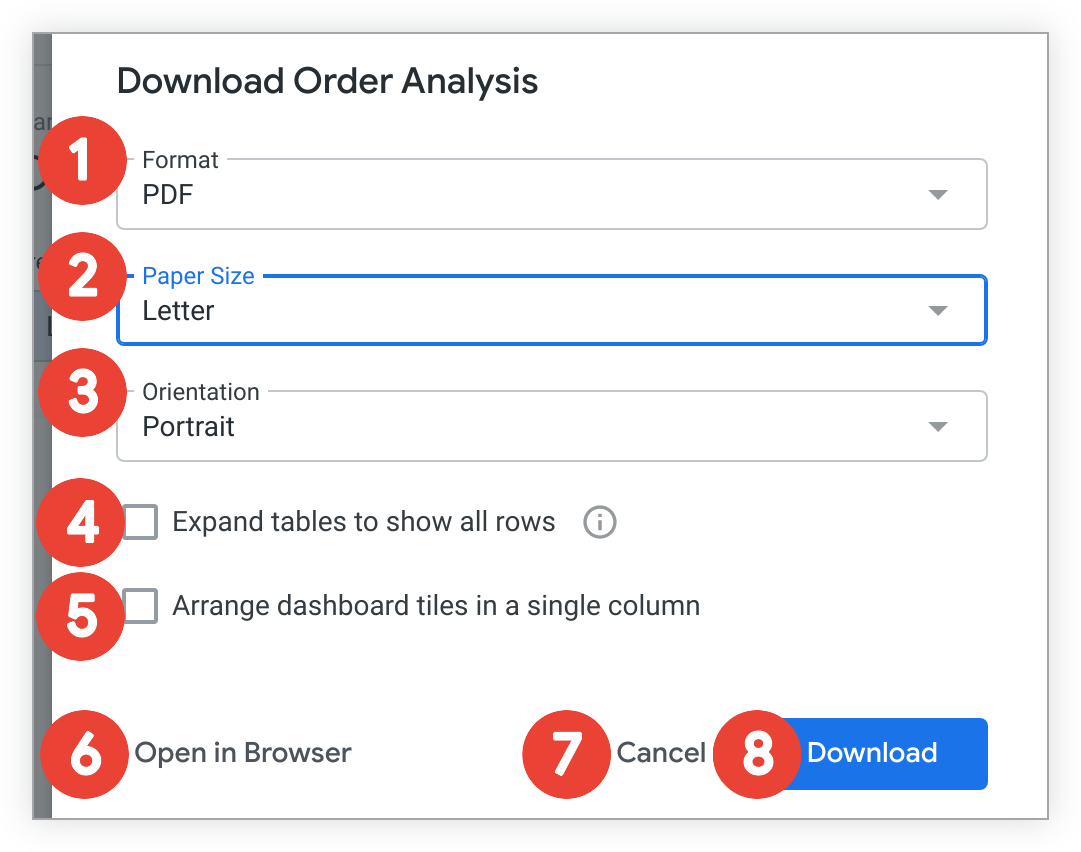
- [PDF] プルダウン メニューから [PDF] を選択します。
[用紙サイズ] プルダウン メニューからオプションを選択します。

デフォルトでは、[ページをダッシュボードに合わせる] オプションが選択されています。PDF は、ダッシュボードのデフォルトの幅(1260 px)に変更されます。その他の用紙サイズオプションでは、標準の用紙サイズに合わせて、ダッシュボード全体がその中に納まるように、PDF のサイズが設定されます。ダッシュボードのレイアウトと選択した用紙サイズによっては、PDF 出力の一部が、Looker 内で表示されるダッシュボードのレイアウトと異なる場合があります。たとえば、選択した用紙サイズがダッシュボードよりも狭い場合、間隔やその他の書式設定に問題が生じ、調整が必要になることがあります。
- 大きなビジュアリゼーションや重なっているタイルのグループの場合、PDF に合わせてサイズの変更が必要になる場合があります。
- テーブルを含むタイルでは、PDF にすべてのテーブル列が表示されない場合があります。
- タイル幅は、PDF に収まるように縮小される場合があります。同様に、Looker アプリでスクロールが必要なタイルでは、すべてのコンテンツが表示されるように拡大されない場合があります。
[用紙サイズ] オプションが表示されない場合は、Looker インスタンスに適した最新バージョンの Chromium レンダラのインストールについて Looker 管理者にお問い合わせください。
[用紙サイズ] プルダウンで [ページをダッシュボードに合わせる] 以外を選択すると、[画面の向き] オプションが表示されます。ダッシュボードの向きとして縦または横を選択できます。
[テーブルを開いてすべての行を表示] を選択または選択解除します。このオプションを選択すると、テーブル表示を使用するダッシュボード タイルの場合、PDF には、ダッシュボード タイルのサムネイルに表示される行だけでなく、テーブル表示で使用できるすべての行が表示されます。このオプションを選択しない場合は、スクロールせずにサムネイルに表示される行だけが PDF に表示されます。ダッシュボードとクエリフィルタは引き続き適用され、行の制限、列の制限などの表示の設定、および表示される行の上限 オプションによる設定も適用されます。
[表を展開してすべての行を表示する] オプションを選択すると、テーブルが可視化されているダッシュボード タイルは、Looker 内での表示とは若干異なる状態でダウンロードされた PDF に表示される場合があります。PDF には次のような違いが見られる場合があります。
- 列見出しと小計行から、背景色とフォントサイズのカスタマイズが削除されます。
- カスタムテーマが設定されていない場合、テーブルは白のテーマで表示されます。指定しない場合、カスタムテーマはダウンロード時に適用されます。
- [並べ替えオプション] アイコンは、手動で並べ替えていないピボット テーブルには表示されません。
- [列が収まるようにサイズを変更] が有効になっているテーブルは、タイルの全幅にストレッチされます。
また、セル数が 20,000 を超えるテーブルについては、PDF に次の違いが見られることがあります。
[テーブルを開いてすべての行を表示] オプションが表示されない場合は、Looker インスタンスに適した Chromium レンダラのバージョンのインストールについて Looker 管理者にご相談ください。
[ダッシュボード タイルを単一の列に配置する] を選択またはオフのままにします。このオプションを選択すると、PDFでダッシュボードタイルが単一の垂直列に表示されます。このオプションを選択しない場合、ダッシュボードタイルはダッシュボード上の配置どおりに表示されます。
[ブラウザで開く] を選択すると、ブラウザの新しいタブに PDF の画像が表示されます。ここからブラウザのコントロールを使って PDF をダウンロードできます。
ダッシュボードをダウンロードしない場合は、[キャンセル] を選択します。
[ダウンロード] を選択してダウンロードを開始します。ブラウザで新しいタブが開き、ダウンロードのステータスが表示されます。
ダッシュボードを CSV としてダウンロードする
ダッシュボードのすべてのクエリタイルは、zipされたCSVファイルのコレクションとしてダウンロードできます。このzipファイルにはテキストタイルは含まれません。ダッシュボードをCSVファイルのコレクションとしてダウンロードするには、以下の手順に従ってください。
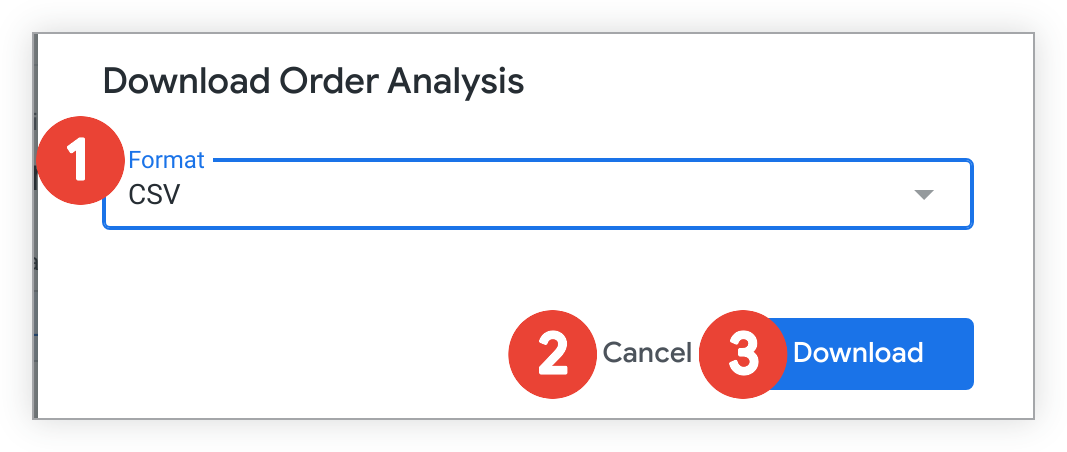
- [CSV] プルダウン メニューから [CSV] を選択します。
- ダッシュボードをダウンロードしない場合は、[キャンセル] を選択します。
- [ダウンロード] をクリックして、圧縮された CSV コレクションのダウンロードを開始します。
ダッシュボードを CSV ファイルとしてダウンロードすると、カスタム行制限の設定やすべての結果の選択などのダウンロードのフォーマット オプションは使用できません。ダウンロードしたファイルの行数の上限は、対応するタイルの行数の上限に対応しています。
LookerではUTF-8エンコードを使ってzipファイルを生成します。CSV ファイル名の文字が文字化けする場合、Looker の UTF-8 エンコードと、ご利用のマシンのオペレーティング システムまたはサードパーティ アプリケーションのデフォルト エンコードの競合が原因かもしれません。Looker では、UTF-8 を認識するファイル エクストラクタ(7-Zip など)を使用することと、サードパーティ アプリケーションが UTF-8 をサポートするように構成されていることを確認することをおすすめします。
ダッシュボードタイルからデータをダウンロードする
統合された結果のクエリに基づいて、ダッシュボード タイルからデータをダウンロードすることはできませんが、ダッシュボードを PDF としてダウンロードした場合、またはCSV ファイルのコレクションした場合、統合された結果のタイルのデータが含まれます。
ダッシュボード タイルからデータをダウンロードするには、タイルのその他アイコンを選択し、[データをダウンロード] を選択します。
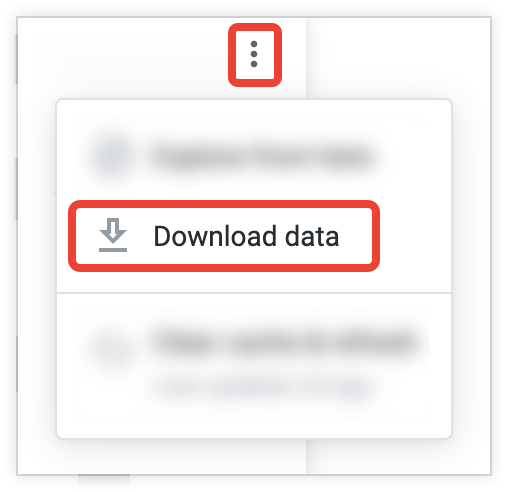
ダイアログ ボックスが開き、Look または Explore のオプションに似た複数のオプションが表示されます。[データの詳細オプション] メニューを開くと、ダウンロードに使用できるすべてのオプションが表示されます。
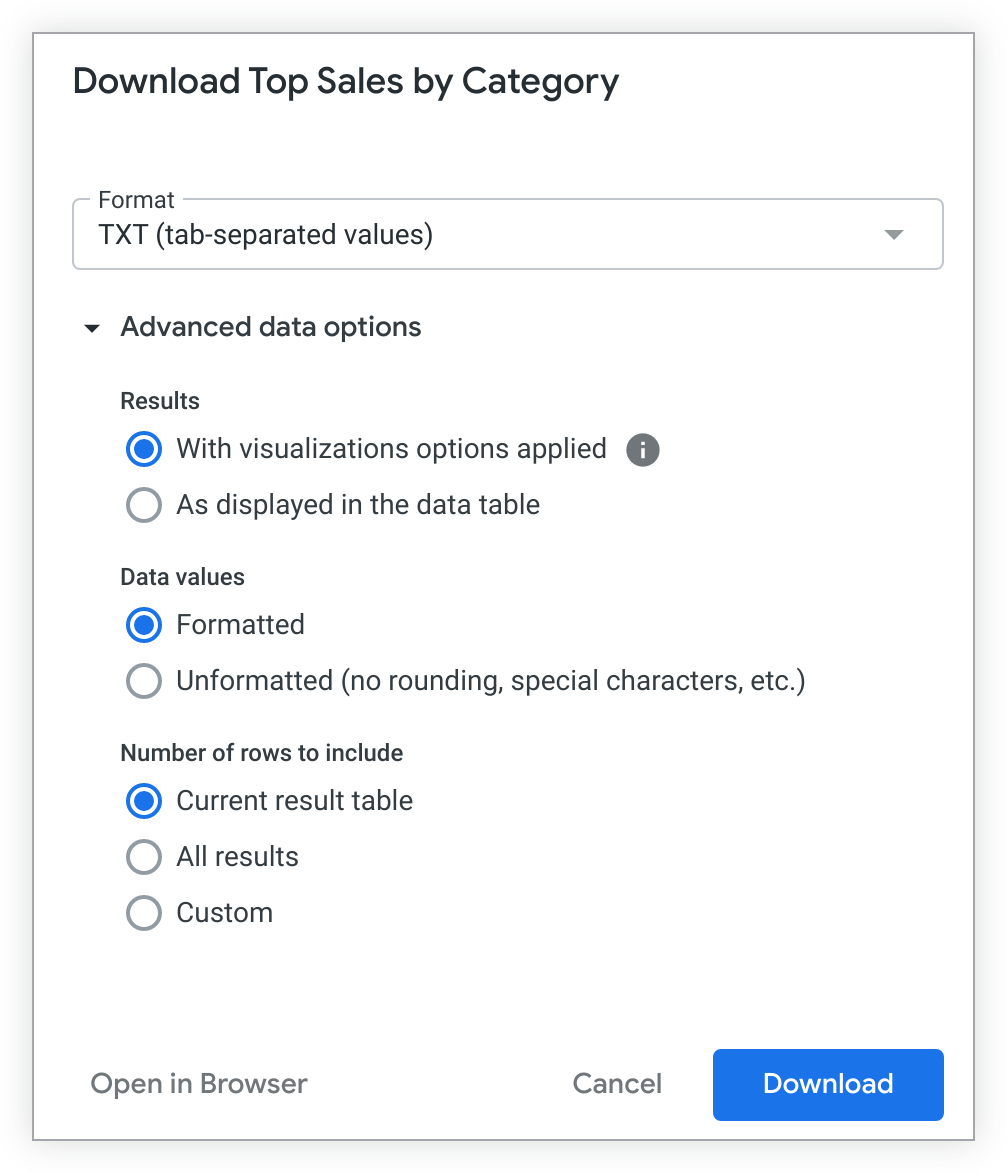
形式
ダッシュボード タイルから次の形式でデータをダウンロードできます。
- TXT(タブ区切り値)
- Excel スプレッドシート(Excel 2007以降)
- CSV
- JSON
- HTML
- マークダウン
- PNG(表示画像)
選択した形式によっては、[データの詳細オプション] メニューの一部が使用できない場合があります。
HTML または PNG(表示画像)オプションがない場合は、Looker 管理者に連絡して、Looker インスタンスに適切なバージョンの Chromium レンダラをインストールします。
JSON 形式の場合、Looker は JSON 出力でレンダリングされた値としてフィールド ラベルを使用します。Looker で JSON 形式でフィールドがどのようにレンダリングされるかについては、JSON 形式の変更のコミュニティ投稿をご覧ください。
行 / 列が入れ替えられたテーブルの可視化は、PDF および PNG ダウンロードでのみレンダリングされます。
PNG 形式でのダウンロードでは、Development Mode にあっても、常に本番環境モードのモデルからデータが返されます。
結果
[結果] セクションで、データのダウンロードに表示設定を適用するかどうかを選択します。
[表示オプションの適用] を選択すると、表示設定の一部が適用されます。表示用に構成された [プロット]、[シリーズ]、[書式設定] メニューの次のいずれかの設定は、データのダウンロードに適用されます。
- 行番号を表示
- 合計を非表示にする
- 行の合計を非表示にする
- 表示する行を制限する。最大 500 行まで表示または非表示にします
- Show Full Field Name
- 各列のカスタムラベル(Looker では、JSON 出力でレンダリングされた値としてフィールドラベルを使用します。{looker_name_short}} で JSON 形式のフィールドがどのようにレンダリングされるかについては、Looker のコミュニティ投稿のJSON 形式の変更をご覧ください。
- Excel 形式でテーブルグラフの可視化をダウンロードするための条件付きフォーマット。
スケーリングを適用が適用された場合にのみ、条件付き書式が Excel 形式でダウンロードされて、テーブルグラフが表示されます。
クエリに次のいずれかの要素が含まれている場合、手動で並べ替えられたテーブルグラフの列は、ダウンロードされた元の順序で表示されます。
- 1 つ以上の表計算
- 非表示の 1 つ以上のフィールド
- ディメンション フィルが有効になっている 1 つ以上のフィールド
- 3 つ以上のピボット フィールド
- 有効になっている行の合計
[データテーブルに表示] を選択すると、表示オプションは適用されず、Look または Explore の [Data] セクションにデータテーブルが表示されます。
データ値
[データ値] セクションで、ダウンロードした結果の表示方法を選択します。
- [Formatted] を選択すると、データは Looker の [Explore] エクスペリエンスに類似して表示されますが、一部の機能(リンクなど)はすべてのファイル形式でサポートされません。
- [Unformated] を選択した場合、Looker では、Looker デベロッパーが配置した長すぎる番号の丸めや特殊文字の追加など、特別な形式のクエリ結果を適用しません。これは多くの場合、処理のためにデータを他のツールに送信するときに推奨されます。
含める行と列の数
このセクションでは、ダウンロードに含めるデータの量を指定できます。ほとんどのタイルで、ダウンロード ポップアップのこのセクションには [含める行数] という名前が付いています。タイルクエリにピボットされた項目が含まれている場合、このセクションには [含める行と列の数] と表示されます。オプションには、
- 現在の結果テーブル: タイルの基礎となるデータテーブルの行数制限(タイルクエリに少なくとも 1 つのピボット ディメンションが含まれている場合は列制限も)によって指定された行数。
- すべての結果: タイルのデータテーブルが、より制限の厳しい行の制限または列の制限を指定していても、タイルクエリから返されるすべての結果。このオプションを選択する前に、このページのすべての結果またはカスタム オプションを使用する場合の考慮事項セクションをご覧ください。このオプションは、
download_without_limit権限がないユーザーには表示されません。 - カスタム: ダウンロードする行のカスタム数。
download_with_limit権限を持つユーザーは 5,000 行までに制限されます。Looker 管理者が上限を増やさない限り、他のユーザーの上限は通常、100,000 です。レガシー機能: 無制限のダウンロードの許可(Looker 4.14 以降)のコミュニティ投稿をご覧ください。
すべての結果またはカスタム オプションを使用する場合の考慮事項
Looker が権限をチェックし、クエリの複雑さとデータベース言語によってクエリ全体をダウンロードできるかどうかが判定されます。設定した制限を超える結果をダウンロードする権限があり、クエリ全体をダウンロードできると Looker が判断した場合、[ダウンロード] ウィンドウで [すべての結果] オプションを利用できます。
通常、[すべての結果] オプションは、次のようなクエリでは無効になります。
- 行の合計を含める
- [合計に対する割合]、[前の行に対する割合]、または累積の種類の measure を使用します。
- 結果をストリーミングできないデータベース言語からデータを取得する
- ピボットを計算できないデータベース言語からデータが取得されるため、Looker で計算されるピボット列を含める
[すべての結果] オプションが使用可能な場合でも、すべての結果をダウンロードする際は注意が必要です。クエリによっては、数千行または数百万行が含まれる非常に大きなクエリがあり、ほとんどのスプレッドシート プログラムや Looker インスタンスで処理しきれない場合があります。
[すべての結果] オプションを使用できない場合は、[カスタム] オプションを使用して、権限で許可されている行の最大数を指定できます。[カスタム] を選択すると、ダウンロードする結果の行数を指定できます。クエリにピボットされたディメンションが含まれている場合は、ダウンロードする列の数を指定することもできます。
管理者向け: Looker インスタンスのデータのダウンロードを有効にする
特定のダウンロード オプションを使用するには、セルフホスト型の Looker デプロイの管理者が適切なバージョンの Chromium レンダラをインストールしている必要があります。インスタンスがLookerでホストされている場合は、Chromiumがすでにインストールされています。
ビジネス ユーザー機能の管理のドキュメント ページには、ダウンロード プロセスに関する重要な管理者用情報が記載されています。
- ユーザー権限とダッシュボードのダウンロード
- ダウンロード用に画像ベースの形式をレンダリングする
- レンダリングされた形式とダウンロード権限
- JSON のダウンロード形式
- サイズの大きい Excel ファイルのダウンロードに関するトラブルシューティング
ユーザーがダウンロードするために割り当てる必要がある権限、特に download_with_limit 権限と download_without_limit 権限について詳しくは、ロールのドキュメント ページをご覧ください。