用法
|
层次结构
aggregate_table |
默认值
无接受
聚合表的名称、用于定义表的 query 子参数,以及用于定义表的持久性策略的 materialization 子参数特殊规则
|
定义
aggregate_table 参数用于创建汇总表,可最大程度地减少数据库中大型表所需的查询次数。
Looker 使用汇总认知度逻辑查找数据库中可用且最小且最有效的汇总表格,同时保持查询的正确性。(请参阅认知度感知文档页面,了解创建汇总表格的概览和策略。)
对于数据库中非常大的表,您可以创建较小的数据汇总表,并按不同的属性组合分组。汇总表格将充当总览表或摘要表,Looker 会尽可能将其用于查询,而不是原始的大型表。
如需访问以进行汇总感知,必须在数据库中保留汇总表。持久化策略在汇总表的
materialization参数中指定。此外,由于汇总表是一种永久性派生表 (PDT),因此汇总表的数据库连接和方言要求与 PDT 相同。如需了解详情,请参阅 Looker 中的派生表文档页面。
创建汇总表后,您可以在“探索”中运行查询,查看 Looker 使用的汇总表。如需了解详情,请参阅汇总认知度文档页面中的确定用于查询的汇总表格部分。
如需了解未使用汇总表格的常见原因,请参阅汇总认知度文档页面上的问题排查部分。
在 LookML 中定义汇总表
您可以使用“探索”功能或信息中心来创建一个 LookML 汇总表格,而无需从头开始创建 LookML。如需了解详情,请参阅本页的从探索中获取汇总表 LookML 和从信息中心获取汇总表 LookML 部分。
每个 aggregate_table 参数的名称都必须在给定的 explore 中具有唯一性。
aggregate_table 参数具有 query 和 materialization 子参数。
query
query 形参定义了对汇总表的查询,包括要使用的维度和衡量指标。query 参数包含以下子参数:
本部分引用了
aggregate_table中的query参数。
| 参数名称 | 说明 | 示例 |
|---|---|---|
dimensions |
要添加到汇总表格中的“探索”维度(以英文逗号分隔)。dimensions 字段使用以下格式:dimensions: [dimension1, dimension2, ...]
此列表中的每个维度都必须在查询的“探索”视图视图中定义为 dimension。如果您希望在“探索”查询中添加定义为 filter 字段的字段,可以将其添加到汇总表查询中的 filters 列表。
|
dimensions: |
measures |
“探索”中要添加到汇总表格中的措施的逗号分隔列表。measures 字段使用以下格式:measures: [measure1, measure2, ...]如需了解汇总认知度支持的衡量类型,请参阅总体认知度文档页面上的衡量类型因素部分。 |
measures: |
filters |
(可选)向 query 添加过滤条件。过滤条件添加到生成聚合表的 SQL 的 WHERE 子句中。filters 字段使用以下格式:filters: [field1: "value1", field2: "value2", ...]
如需了解过滤器如何防止系统使用您的汇总表格,请参阅汇总认知度文档页面上的过滤器因素部分。 |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
(可选)为 query 指定排序字段和排序方向(升序或降序)。sorts 字段使用以下格式:sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
设置 query 的时区。如果未指定时区,汇总表格将不会执行任何时区转换,而会使用数据库时区。
如需了解如何设置时区以使汇总表用作查询来源,请参阅汇总认知度文档页面上的时区因素部分。 在 IDE 中输入 timezone 参数时,IDE 会自动建议时区值。IDE 还会在快捷帮助面板中显示受支持的时区值列表。 |
timezone: America/Los_Angeles |
materialization
materialization 参数指定汇总表的持久性策略,以及 SQL 方言可能支持的其他分布、分区、索引和聚类选项。
要访问汇总认知度报告,您的汇总表格必须持久保留在数据库中。汇总表必须具有以下一种持久性策略:
汇总表可能支持其他 materialization 选项,具体取决于您的 SQL 方言:
最后,要创建一个增量汇总表,请使用以下 materialization 子参数:
datagroup_trigger
使用 datagroup_trigger 参数,根据模型文件中定义的现有数据组触发重新生成汇总表:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
使用 sql_trigger_value 参数,可以根据您提供的 SQL 语句触发重新生成汇总表。如果 SQL 语句的结果与之前的值不同,系统会重新生成表。当日期发生变化时,此 sql_trigger_value 语句将触发重新生成:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
汇总表也支持 persist_for 参数。不过,就整体认知度而言,persist_for 策略可能无法让您取得最佳效果。这是因为当用户运行依赖于 persist_for 表的查询时,Looker 会根据 persist_for 设置检查表的存在时间。如果该表的存在时间早于 persist_for 设置,系统会在运行查询之前重新生成该表。如果存在时间低于 persist_for 设置,则使用现有表。因此,除非用户在 persist_for 小时内运行查询,否则必须重建汇总表,才能用于汇总感知。
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
除非您了解相关限制并且有具体的 persist_for 实现用例,否则最好使用 datagroup_trigger 或 sql_trigger_value 作为聚合表的持久性策略。
cluster_keys
借助 cluster_keys 参数,您可以向 BigQuery 或 Snowflake 上的分区表添加聚类列。聚类根据聚类列中的值对分区中的数据进行排序,并将聚类列按大小最佳的存储块进行归类。
对于 BigQuery,同样使用
partition_keys参数进行分区的汇总表也支持聚类。
如需了解详情,请参阅 cluster_keys 参数文档页面。
distribution
借助 distribution 参数,您可以从聚合表中指定要应用分布键的列。distribution 仅适用于 Redshift 和 Aster 数据库。对于其他 SQL 方言(例如 MySQL 和 Postgres),请改用 indexes。
如需了解详情,请参阅 distribution 参数文档页面。
distribution_style
借助 distribution_style 参数,您可以指定对汇总表格的查询如何在 Redshift 数据库中的各个节点之间分布:
distribution_style: all表示所有行均已完全复制到每个节点。distribution_style: even指定均匀分布,以便以轮询方式将行分发到不同的节点。
如需根据特定列中的唯一值(分布键)分发查询,您可以使用
distribution参数。
如需了解详情,请参阅 distribution_style 参数文档页面。
indexes
借助 indexes 参数,您可以将索引应用于聚合表的列。
如需了解详情,请参阅 indexes 参数文档页面。
partition_keys
partition_keys 参数定义了将对汇总表进行分区的一系列列。partition_keys 支持能够对列进行分区的数据库方言。如果运行查询时对分区列进行过滤,数据库将仅扫描包含已过滤数据的分区,而不是扫描整个表。只有 Presto 和 BigQuery 方言支持 partition_keys。
如需了解详情,请参阅 partition_keys 参数文档页面。
sortkeys
借助 sortkeys 参数,您可以指定聚合表的一个或多个列,对其应用常规排序键。
如需了解详情,请参阅 sortkeys 参数文档页面。
increment_key
如果您的方言支持,您可以在项目中创建增量 PDT。增量 PDT 是一种永久性派生表 (PDT),Looker 通过将新数据附加到表来构建构建,而不是完全重建表。如需了解详情,请参阅增量 PDT 文档页面。
汇总表格是一种 PDT,可以通过添加 increment_key 参数以增量方式构建此类表格。increment_key 参数用于指定应查询新数据并附加到汇总表的时间增量。
如需了解详情,请参阅 increment_key 参数文档页面。
increment_offset
increment_offset 参数指定了要将数据附加到汇总表时要重建的旧时间段的数量(以递增键的粒度表示)。对于增量永久性磁盘和汇总表,increment_offset 参数是可选的。
如需了解详情,请参阅 increment_offset 参数文档页面。
从“探索”中获取汇总表 LookML
作为一种快捷方式,Looker 开发者可以使用“探索”查询来创建汇总表,然后将 LookML 复制到 LookML 项目中:
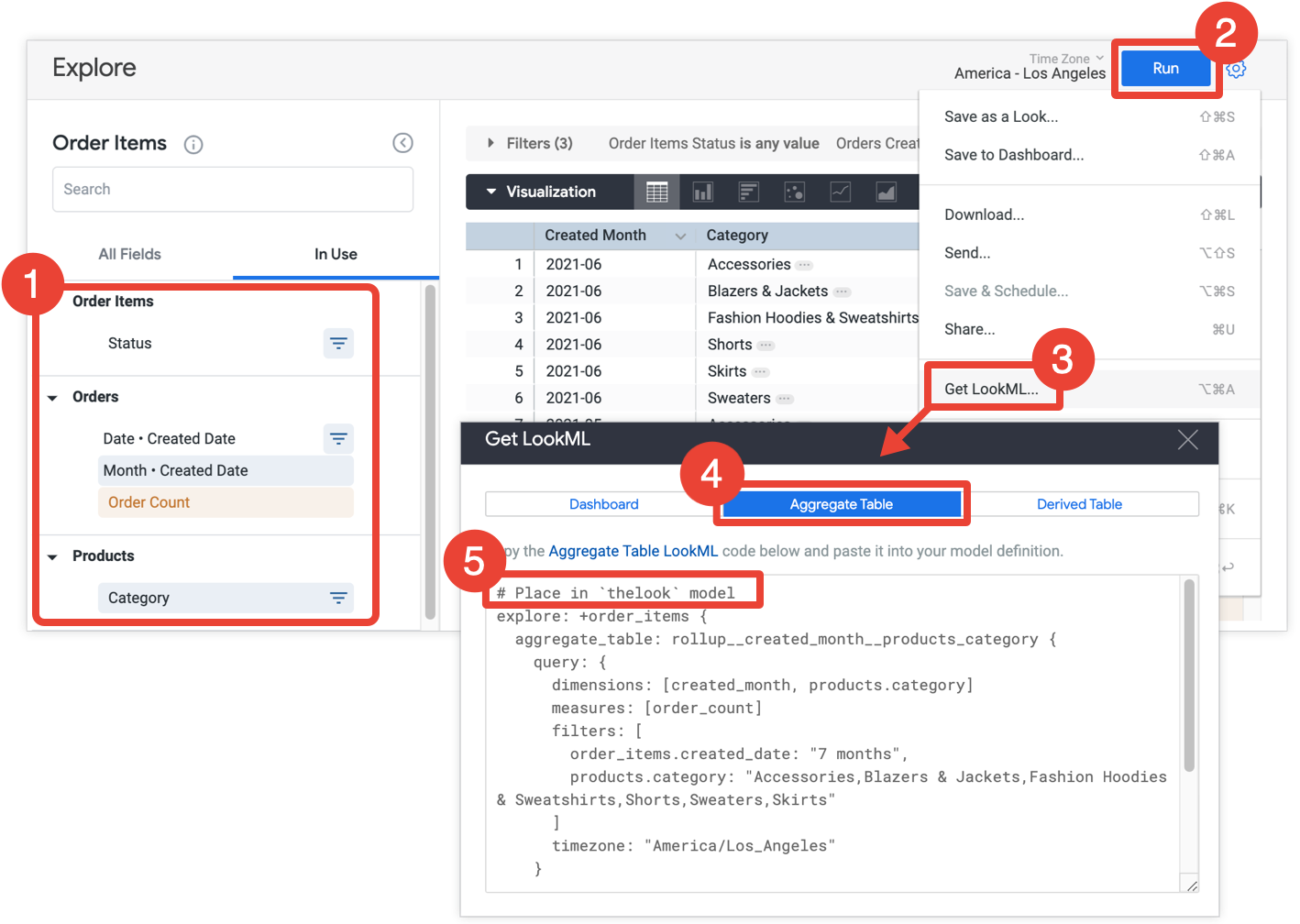
- 在“探索”中,选择汇总表格中包含的所有字段和过滤条件。
- 点击运行以获取结果。
- 从“探索”的齿轮菜单中选择获取 LookML。此选项仅适用于 Looker 开发者。
- 点击汇总表格标签页。
- Looker 为探索优化提供 LookML,以将汇总表添加到“探索”中。复制 LookML 并将其粘贴到关联的模型文件中,该文件位于“探索”优化上方的注释中。如果“探索”是在单独的探索文件(而非模型文件)中定义的,您可以向“探索”的文件而非模型文件添加优化。这两个位置都可以。
Looker 根据“探索”中的维度为汇总表格命名。每次为汇总表格提供汇总表格 LookML 时,Looker 都会使用相同的名称。请注意对之前可能已添加的同一探索的其他优化。如果您或其他开发者已经从探索中获得汇总表 LookML,Looker 将为汇总表提供相同的名称。如果探索包含多项优化,且每项优化包含同名的汇总表格,则一项优化将覆盖其他优化,如 LookML 优化文档页面的按顺序应用优化部分所述。
如果您需要修改汇总表 LookML,可以使用本页在 LookML 中定义聚合表部分中所述的参数。您可以重命名汇总表格,而无需更改其对原始“探索”查询的适用范围。不过,对汇总表格所做的任何其他更改都可能影响 Looker 能否对“探索”查询使用汇总表格。请参阅汇总认知度文档页面的设计汇总表格部分,获取有关如何优化汇总表格以确保将其用于汇总认知度的提示。
从信息中心获取汇总表 LookML
Looker 开发者的另一种方法是,获取信息中心中所有卡片的汇总表 LookML,然后将 LookML 复制到 LookML 项目中。
创建汇总表可以显著提高信息中心的性能,尤其是查询大量数据集的卡片。
如果您拥有 develop 权限,就可以让 LookML 为信息中心创建汇总表格,方法是打开信息中心,从信息中心的三点状菜单中选择 Get LookML,然后选择汇总表格标签页:
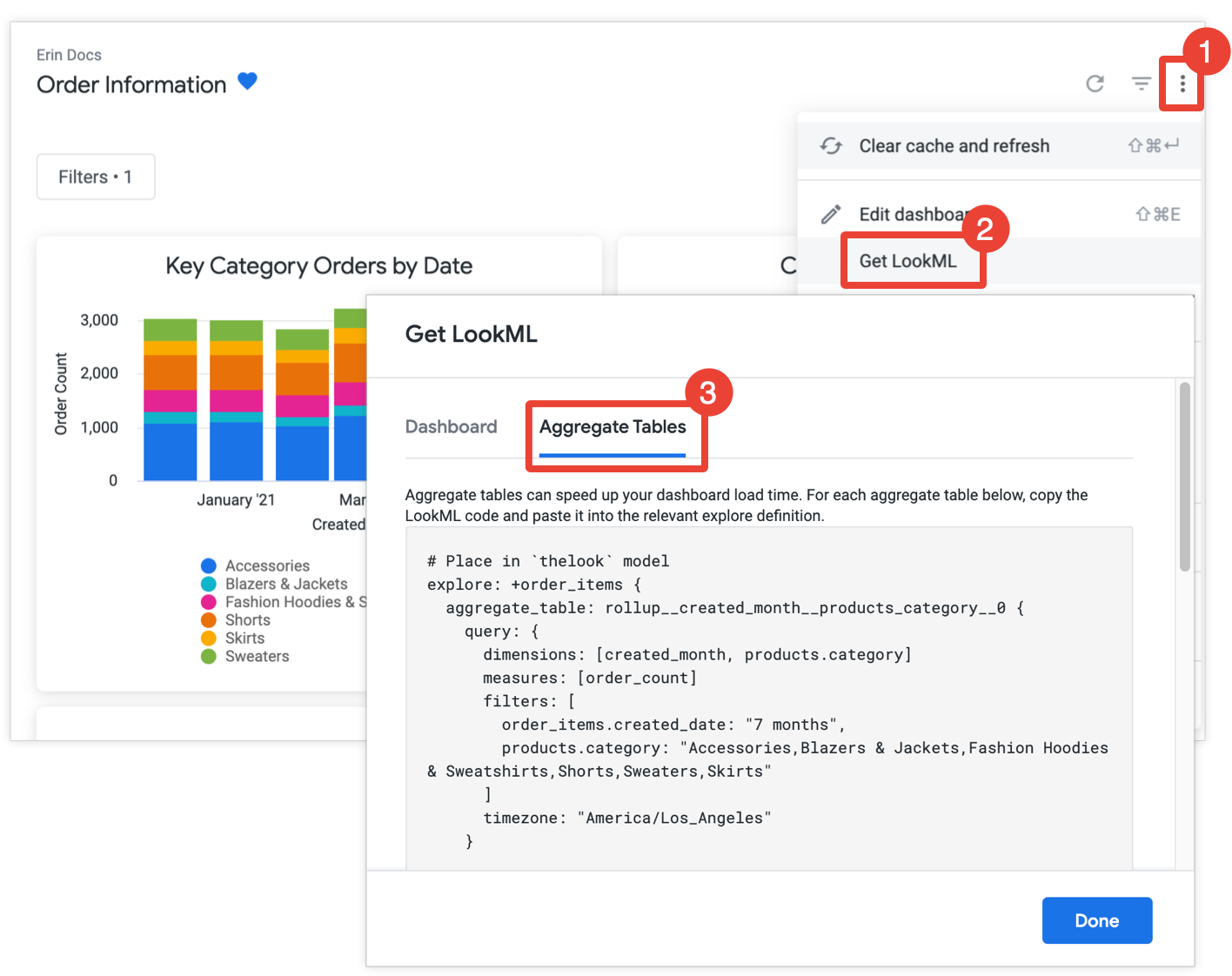
对于尚未利用汇总感知功能进行优化的每个图块,Looker 会提供探索优化的 LookML,会将汇总表格添加到“探索”中。如果信息中心包含来自同一探索的多个卡片,Looker 会将所有汇总表格放在单个探索优化中。为了减少生成的汇总表格数,Looker 会确定生成的汇总表格是否可以用于多个卡片。如果有,则会删除任何可用于较少卡片的冗余汇总表格。
将每个“探索”优化项目复制并粘贴到关联的模型文件中(如“探索优化”上方的注释中所示)。如果“探索”是在单独的探索文件(而非模型文件)中定义的,您可以向“探索”文件(而非模型文件)添加优化标签。这两个位置都可以。
请注意,Looker 会根据卡片查询中的维度为每个汇总表格命名。每次为卡片查询提供汇总表 LookML 时,Looker 都会对汇总表使用相同的名称。因此,您应注意该卡片中“探索”部分以前可能添加的其他优化条件。如果您或其他开发者已经从信息中心图块的查询中获取了汇总表 LookML,Looker 将为它的汇总表提供相同的名称。如果探索包含多项优化,且每项优化包含同名的汇总表格,则一项优化将覆盖其他优化,如 LookML 优化文档页面的按顺序应用优化部分所述。
如果有应用于卡片的信息中心过滤条件,Looker 会将该维度添加到卡片的汇总表格中,以便汇总表格可用于该卡片。这是因为只有当查询的过滤条件引用可用作汇总表中的维度的字段时,汇总表才能用于查询。如需了解相关信息,请参阅汇总认知度文档页面。
如果您需要修改汇总表 LookML,可以使用本页在 LookML 中定义聚合表部分中所述的参数。您可以重命名汇总表,而无需更改其对原始信息中心图块的适用性,但对汇总表的任何其他更改都可能影响 Looker 对信息中心使用汇总表的能力。请参阅汇总认知度文档页面的设计汇总表格部分,获取有关如何优化汇总表格以确保将其用于汇总认知度的提示。
示例
以下示例为 event 探索创建了一个 monthly_orders 汇总表。汇总表格会创建按月订单。Looker 会使用汇总表格查看可利用每月粒度的订单计数查询,例如按年、每季度和每月订单计数的查询。
使用数据组 orders_datagroup 为汇总表设置持久性。
汇总表定义如下所示:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
注意事项
有关有策略地创建汇总表格的提示,请参阅汇总认知度文档页面的设计汇总表格部分:
为总体认知度提供方方面面的支持
能否使用汇总感知功能取决于您的 Looker 连接的数据库方言。在最新版 Looker 中,以下方言支持汇总认知度: