Looker 使用先前查询的缓存结果(如果可用),并在缓存政策允许的情况下降低数据库的负载并提高性能。此外,您还可以将复杂查询创建为永久性派生表 (PDT),其中存储结果以简化后续查询。
Datagroup 非常实用,可用于协调数据库的 ETL(提取、转换和加载)时间表与 Looker 的缓存政策和 PDT 重建时间表。您可以使用数据组,根据何时将新数据添加到数据库来指定 PDT 的重建触发器。在同一数据组中,您可以为“探索”查询指定一个缓存时长上限,以便在 PDT 重建因某种原因未触发时起到防故障保护作用。这样,数据组的失败模式将是查询数据库,而不是从 Looker 缓存传送过时的数据。
或者,您也可以使用数据组将 PDT 重新构建触发器与缓存最长期限分离。如果您有一个基于数据更新频率很高的“探索”功能,并且“探索”已加入某个重建频率较低的 PDT,此方法会非常有用。在这种情况下,您需要重新设置查询缓存,而不是重新构建您的 PDT。
如需详细了解查询缓存,请参阅此文档页面上的 Looker 如何使用缓存的查询部分。
定义数据组
可以使用 datagroup 参数在模型文件或自己的 LookML 文件中定义数据组。如果您想为项目中的不同探索和/或 PDT 使用不同的缓存和 PDT 重建政策,可以定义多个数据组。
datagroup 参数可以具有以下子参数:
label- 为数据组指定可选标签。description- 为数据组指定可选说明,用于解释数据组的用途和机制。max_cache_age- 指定定义时间段的字符串。当查询的缓存存在时间超出时间段时,Looker 就会将该缓存失效。下次发出查询时,Looker 会将查询发送到数据库以获取最新结果。interval_trigger- 指定触发数据组的时间表,例如"24 hours"。
如需详细了解这些参数,请参阅 datagroup 文档页面。
数据组必须至少包含 max_cache_age 参数、sql_trigger 参数或 interval_trigger 参数。
数据组不能同时包含
sql_trigger和interval_trigger参数。如果使用这两个参数定义一个数据组,该数据组将使用interval_trigger值并忽略sql_trigger值,因为sql_trigger参数要求 Looker 在查询数据库时使用数据库资源。
下面是一个数据组示例,其sql_trigger设置为每天重新构建 PDT。此外,max_cache_age 设置为每两小时清除一次查询缓存,以防任何“探索”将 PDT 与刷新频率高于每天一次的其他数据联接起来。
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
定义数据组后,您可以将其分配给“探索”和“首选交易”:
- 要将数据组分配给 PDT,请使用
derived_table参数下的datagroup_trigger参数。如需查看示例,请参阅本页面上的使用数据组指定 PDT 的重建触发器部分。 - 要将数据组分配给“探索”功能,请使用模型级别或探索级别的
persist_with参数。有关示例,请参阅本页面上的使用数据组指定“探索”的查询缓存重置部分。
使用数据组为 PDT 指定重建触发器
如需使用数据组定义 PDT 重建触发器,请使用 sql_trigger 或 interval_trigger 子参数创建一个 datagroup 参数。然后,使用 PDT 的 derived_table 定义中的 datagroup_trigger 子参数将数据组分配给各个 PDT。如果您针对 PDT 使用 datagroup_trigger,则无需为派生的表格指定任何其他持久性策略。如果您为 PDT 指定了多个持久性策略,您将在 Looker IDE 中收到一条警告,并且仅使用 datagroup_trigger。
下面是一个使用 customers_datagroup 数据组的 PDT 定义示例。此定义还在 customer_id 和 first_order_date 上添加了多个索引。如需详细了解如何定义 PDT,请参阅 Looker 中的派生表文档页面。
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
如果您有级联 PDT,依赖于其他 PDT 的 PDT,请注意不要指定不兼容的数据组缓存政策。
对于具有用于指定连接参数的用户属性的连接,如果您想执行以下任一操作,就必须使用 PDT 替换字段创建单独的连接:
• 在模型中使用 PDT
• 使用数据组定义 PDT 重建触发器
如果不使用 PDT 替换,您仍然可以使用包含max_cache_age的数据组为“探索”功能定义缓存政策。
如需详细了解数据组如何与 PDT 搭配使用,请参阅 Looker 中的派生表文档页面。
使用数据组为“探索”指定查询缓存重置
当数据组被触发时,Looker 重新生成程序将重建使用该数据组作为持久性策略的 PDT。当数据组的 PDT 重建后,Looker 将为使用数据组重建的 PDT 的探索清除缓存。如果要为数据组自定义查询缓存重置时间表,您可以在数据组定义中添加 max_cache_age 参数。借助 max_cache_age 参数,除了在重建数据组的 PDT 时 Looker 执行的自动查询缓存重置之外,您还可以按指定时间表清除查询缓存。
如需使用 datagroup 定义查询缓存政策,请使用 max_cache_age 子参数创建一个 datagroup 参数。
如需指定用于“探索”上查询缓存重置的数据组,请使用 persist_with 参数:
- 要将数据组指定为模型中所有“探索”的默认项,请在模型级(在模型文件中)使用
persist_with参数。 - 若要将数据组分配给各个“探索”,请使用
explore参数下的persist_with参数。
以下示例显示了在模型文件中定义的名为 orders_datagroup 的数据组。该数据组有一个 sql_trigger 参数,用于指定查询 select max(id) from my_tablename 将用于检测何时发生了 ETL。即使一段时间内 ETL 并未执行,数据组的 max_cache_age 也会指定缓存的数据最多只使用 24 小时。
此模型的 persist_with 参数指向 orders_datagroup 缓存政策,这意味着这将是模型中所有探索的默认缓存政策。不过,我们不希望为 customer_facts 和 customer_background 探索使用模型的默认缓存政策,因此可以添加 persist_with 参数为这两种探索指定不同的缓存政策。orders 和 orders_facts 探索没有 persist_with 参数,因此将使用模型的默认缓存政策:orders_datagroup。
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
如果同时指定了 persist_with 和 persist_for,您将收到验证警告,并且会使用 persist_with。
使用数据组触发按计划传送
数据组还可用于触发信息中心、旧版信息中心或外观的投放。选择此选项后,Looker 会在数据组完成后发送您的数据,以便所安排的内容处于最新状态。
对数据组使用管理面板
如果您拥有 Looker 管理员角色,则可以使用管理面板的数据组页面查看现有数据组。您可以看到每个数据组的连接、模型和当前状态,以及每个数据组的标签和说明(如果在 LookML 中进行了指定)。您还可以重置数据组的缓存、触发数据组或导航到数据组的 LookML。

Looker 如何使用缓存的查询
对于查询,Looker 中的缓存机制的工作原理如下:
- 用户运行特定查询后,系统会缓存该查询的结果。缓存结果存储在 Looker 实例的加密文件中。
编写新查询时,系统会检查缓存,看看之前是否运行过确切的查询。所有字段、过滤条件和参数(包括行数上限等设置)都必须相同。如果未找到该查询,Looker 将对数据库运行查询以获取最新的数据库结果(并缓存这些结果)。
上下文注释不会影响缓存。Looker 在每个 SQL 查询的开头添加唯一注释。不过,只要 SQL 查询本身与之前的查询相同(不包括上下文注释),Looker 就会使用缓存的结果。
如果在缓存中找到查询,则 Looker 会检查模型中定义的缓存政策,以确定缓存是否仍然有效。默认情况下,Looker 会在一小时后使缓存结果失效。您可以使用
persist_for参数(在模型级别或探索级别)或使用更强大的datagroup参数来指定缓存政策,以确定缓存结果在哪些情况下失效且应被忽略。管理员也可以使数据组的缓存结果失效。- 如果缓存仍然有效,则系统会使用这些结果。
- 如果缓存不再有效,则 Looker 对数据库运行查询以获取最新查询结果。(这些新结果也会缓存。)
查看是否从缓存返回了查询
在探索窗口中,您可以在运行查询后查看右上角来确定是否从缓存中返回了查询。
从缓存返回查询时,系统会显示“来自缓存”。否则,系统会显示返回查询的时间量。

强制从数据库生成新结果
在探索窗口中,您可以强制从数据库检索新结果。运行查询后,您可以在屏幕右上角找到清除缓存和刷新选项(包括合并结果查询):
![]()
永久性派生表通常会根据 PDT 的持久性策略重新生成。如果管理员已授予您 develop 权限,并且您查看的“探索”包含 PDT 中的字段,您可以强制重建派生表。运行查询后的屏幕右上角会显示 Rebuild Derived Tables & Run 选项(位于屏幕的右上方):
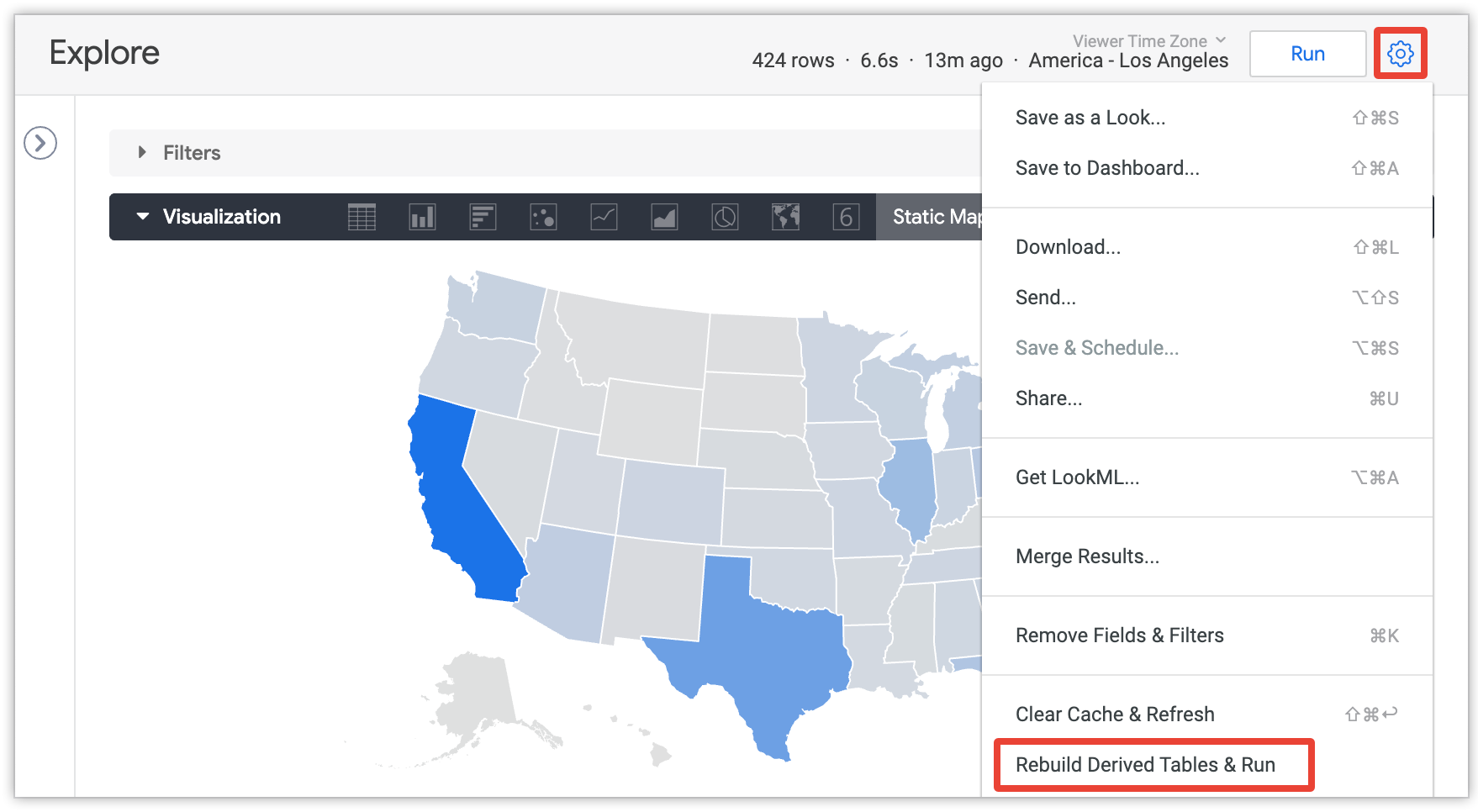
如需详细了解重建派生表和运行选项,请参阅 Looker 中的派生表文档页面。
数据在缓存中保留多长时间?
如需指定缓存结果的无效时长,请使用 persist_for 参数(针对模型或探索)或 max_cache_age 参数(针对数据组)。以下是时间轴上的不同行为,具体取决于 persist_for 或 max_cache_age 时间是否已到期:
- 在
persist_for或max_cache_age时间期限之前:如果重新运行查询,Looker 会从缓存中拉取数据。 persist_for或max_cache_age时间到期后:除非您启用了即时信息中心 Looker Labs 功能,否则 Looker 会从缓存中删除数据。persist_for或max_cache_age时间过后:如果重新运行查询,Looker 会直接从数据库中提取数据,并重置persist_for或max_cache_age计时器。
这里的一点是,只要 persist_for 或 max_cache_age 时间过期,只要 Instant Dashboard Looker Labs 功能被停用,数据就会从缓存中删除。(即时信息中心功能需要缓存才能立即将缓存结果加载到信息中心。)如果您启用即时信息中心,数据会在缓存中保留 30 天,或达到缓存存储限制。如果缓存达到存储空间上限,系统会根据“最近最少使用”(LRU) 算法弹出数据,但 persist_for 或 max_cache_age 计时器已到期的数据将一次性全部删除。
最大限度地缩短数据在缓存中的时间
Looker 要求为内部进程使用磁盘缓存,因此数据始终会写入缓存,即使您将 persist_for 和 max_cache_age 参数设为 0 也是如此。写入缓存后,数据将被标记为删除,但最长可能会在磁盘上存在 10 分钟。
但是,磁盘缓存中的所有客户数据都已采用高级加密标准 (AES) 加密,您可以通过做出以下更改来最大限度地缩短数据在缓存中的存储时长:
- 停用即时信息中心 Looker Labs 功能,该功能需要 Looker 在缓存中存储数据。
- 对于任何
persist_for参数(对于模型或探索)或max_cache_age参数(对于数据组),请将值设置为 0。对于关闭即时信息中心的 Looker 实例,当persist_for时间到期或数据达到其数据组中指定的max_cache_age时,Looker 会删除缓存。(对于永久性派生表的persist_for参数,则无需执行此操作,因为永久性派生表会被写入数据库本身,而不是写入缓存。) - 将
suggest_persist_for参数设置为较小的时间。suggest_persist_for值用于指定 Looker 在缓存中保留过滤器建议的时间。系统会根据被过滤字段的值查询来显示过滤建议。这些查询结果会保留在缓存中,以便 Looker 在用户在过滤条件文本字段输入内容时快速提供建议。默认将过滤条件建议缓存 6 小时。为了最大限度地缩短数据在缓存中花费的时间,请将suggest_persist_for值设置为较小的值(例如 5 分钟)。