Looker riduce il carico sul tuo database e migliora le prestazioni utilizzando i risultati memorizzati nella cache delle query precedenti, se disponibili e se consentito dal criterio di memorizzazione nella cache. Inoltre, puoi creare query complesse come tabelle derivate persistenti (PDT, Persistent Derived Table), che archiviano i risultati per semplificare le query successive.
I gruppi di dati sono molto utili per coordinare la pianificazione ETL (estrazione, trasformazione e caricamento) del database con i criteri di memorizzazione nella cache di Looker e la pianificazione di ricostruzione delle PDT. Puoi utilizzare un gruppo di dati per specificare il trigger di ricostruzione delle PDT in base a quando vengono aggiunti nuovi dati al database. Nello stesso gruppo di dati, puoi specificare un'età massima della cache per le query di Explore che fungono da cassaforte per l'errore nel caso in cui la ricostruzione della PDT non venga attivata per qualche motivo. In questo modo, la modalità di errore per un gruppo di dati consisterà nell'eseguire una query sul database anziché fornire dati non aggiornati dalla cache di Looker.
In alternativa, puoi utilizzare un gruppo di dati per disaccoppiare il trigger di ricostruzione delle PDT dall'età massima della cache. Ciò può essere utile se hai un Explore (esplorazione) basato su dati che si aggiornano molto spesso e che Explore è collegato a una PDT ricreata meno frequentemente. In questo caso, potresti voler reimpostare la cache delle query con una frequenza maggiore rispetto a quella della PDT ricreata.
Per maggiori dettagli sulla memorizzazione nella cache delle query, vedi la sezione relativa all'utilizzo delle query memorizzate nella cache da parte di Looker in questa pagina della documentazione.
Definizione di un gruppo di dati
Un gruppo di dati viene definito con il parametro datagroup, in un file modello o nel proprio file LookML. Puoi definire più gruppi di dati se vuoi criteri di memorizzazione nella cache e ricreazione delle PDT diversi per esplorazioni e/o PDT diverse nel tuo progetto.
Il parametro datagroup può avere i seguenti sottoparametri:
label: specifica un'etichetta facoltativa per il gruppo di dati.description: specifica una descrizione facoltativa del gruppo di dati che può essere utilizzata per spiegare lo scopo e il meccanismo del gruppo di dati.max_cache_age: specifica una stringa che definisce un periodo di tempo. Quando l'età della cache di una query supera il periodo di tempo, Looker invalida la cache. La volta successiva che la query viene eseguita, Looker la invia al database per ottenere nuovi risultati.interval_trigger: specifica una pianificazione temporale per l'attivazione del gruppo di dati, ad esempio"24 hours".
Per ulteriori informazioni su questi parametri, consulta la pagina della documentazione relativa al datagroup.
Come minimo, un gruppo di dati deve contenere almeno il parametro max_cache_age, il parametro sql_trigger o il parametro interval_trigger.
Un gruppo di dati non può avere entrambi i parametri
sql_triggereinterval_trigger. Se definisci un gruppo di dati con entrambi i parametri, il gruppo utilizzerà il valoreinterval_triggere ignorerà il valoresql_trigger, poiché il parametrosql_triggerrichiede che Looker utilizzi le risorse del database durante l'esecuzione della query sul database.
Di seguito è riportato un esempio di un gruppo di dati in cui è configurato un sql_trigger per ricostruire la PDT ogni giorno. Inoltre, il valore max_cache_age è impostato per svuotare la cache delle query ogni due ore, nel caso in cui eventuali esplorazioni uniscano le PDT ad altri dati che si aggiornano più di una volta al giorno.
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
Dopo aver definito il gruppo di dati, puoi assegnarlo a Explore e PDT:
- Per assegnare il gruppo di dati a una PDT, utilizza il parametro
datagroup_triggernel parametroderived_table. Per un esempio, consulta la sezione Utilizzo di un gruppo di dati per specificare un trigger di ricostruzione delle PDT in questa pagina. - Per assegnare il gruppo di dati a un'esplorazione, utilizza il parametro
persist_witha livello di modello o livello di esplorazione. Per un esempio, consulta la sezione Utilizzo di un gruppo di dati per specificare la reimpostazione della cache delle query per le esplorazioni in questa pagina.
Utilizzo di un gruppo di dati per specificare un trigger di ricostruzione delle PDT
Per definire un trigger di ricostruzione delle PDT utilizzando i gruppi di dati, crea un parametro datagroup con il sottoparametro sql_trigger o interval_trigger. Quindi, assegna il gruppo di dati alle singole PDT utilizzando il sottoparametro datagroup_trigger nella definizione derived_table di PDT. Se utilizzi datagroup_trigger per la PDT, non devi specificare un'altra strategia di persistenza per la tabella derivata. Se specifichi più strategie di persistenza per una PDT, riceverai un avviso nell'IDE di Looker e verrà utilizzato solo datagroup_trigger.
Ecco un esempio di definizione di PDT che utilizza il gruppo di dati customers_datagroup. Questa definizione aggiunge anche diversi indici, sia su customer_id che su first_order_date. Per ulteriori informazioni sulla definizione delle PDT, consulta la pagina della documentazione Tabelle derivate in Looker.
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
Se sono presenti PDT a cascata, che dipendono da altre PDT, presta attenzione a non specificare criteri di memorizzazione nella cache del gruppo di dati incompatibili.
Per le connessioni con attributi utente per specificare i parametri di connessione, devi creare una connessione separata utilizzando i campi di override PDT se vuoi eseguire una delle seguenti operazioni:
• Utilizza le PDT nel tuo modello
• Utilizza un gruppo di dati per definire un trigger di ricreazione PDT
Senza le sostituzioni PDT, puoi comunque utilizzare un gruppo di dati conmax_cache_ageper definire il criterio di memorizzazione nella cache delle esplorazioni.
Per ulteriori informazioni sull'utilizzo dei gruppi di dati con le PDT, consulta la pagina della documentazione sulle tabelle derivate in Looker.
Utilizzo di un gruppo di dati per specificare la reimpostazione della cache delle query per le esplorazioni
Quando viene attivato un gruppo di dati, il rigeneratore Looker ricostruisce le PDT che utilizzano tale gruppo come strategia di persistenza. Una volta riprogettate le PDT del gruppo di dati, Looker svuota la cache per le esplorazioni che utilizzano le PDT ricostruite del gruppo di dati. Puoi aggiungere il parametro max_cache_age alla definizione del gruppo di dati se vuoi personalizzare una pianificazione di reimpostazione della cache per il gruppo di dati. Il parametro max_cache_age consente di svuotare la cache delle query in base a una pianificazione specificata, oltre alla reimpostazione automatica della cache delle query eseguita da Looker quando vengono ricostruite le PDT del gruppo di dati.
Per definire un criterio di memorizzazione nella cache delle query con i gruppi di dati, crea un parametro datagroup con il sottoparametro max_cache_age.
Per specificare un gruppo di dati da utilizzare per le reimpostazioni della cache delle query nelle esplorazioni, utilizza il parametro persist_with:
- Per assegnare il gruppo di dati come predefinito per tutte le esplorazioni di un modello, utilizza il parametro
persist_witha livello di modello (in un file di modello). - Per assegnare il gruppo di dati a singole esplorazioni, utilizza il parametro
persist_withsotto un parametroexplore.
Gli esempi riportati di seguito mostrano un gruppo di dati denominato orders_datagroup, definito in un file modello. Il gruppo di dati ha un parametro sql_trigger che specifica che la query select max(id) from my_tablename verrà utilizzata per rilevare quando si è verificato un ETL. Anche se l'ETL non si verifica per un po' di tempo, il max_cache_age del gruppo di dati specifica che i dati memorizzati nella cache verranno utilizzati solo per un massimo di 24 ore.
Il parametro persist_with del modello punta al criterio di memorizzazione nella cache di orders_datagroup, il che significa che questo sarà il criterio di memorizzazione nella cache predefinito per tutte le esplorazioni nel modello. Tuttavia, non vogliamo utilizzare il criterio di memorizzazione nella cache predefinito del modello per le esplorazioni customer_facts e customer_background, quindi possiamo aggiungere il parametro persist_with per specificare un criterio di memorizzazione nella cache diverso per queste due esplorazioni. Le esplorazioni orders ed orders_facts non hanno un parametro persist_with, quindi utilizzeranno il criterio di memorizzazione nella cache predefinito del modello: orders_datagroup.
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
Se sono specificati sia persist_with che persist_for, riceverai un avviso di convalida e verrà utilizzato persist_with.
Utilizzo di un gruppo di dati per attivare le pubblicazioni programmate
I gruppi di dati possono essere utilizzati anche per attivare la pubblicazione di una dashboard, una dashboard precedente o un look. Con questa opzione, Looker invierà i dati al termine del gruppo di dati, in modo che i contenuti pianificati siano aggiornati.
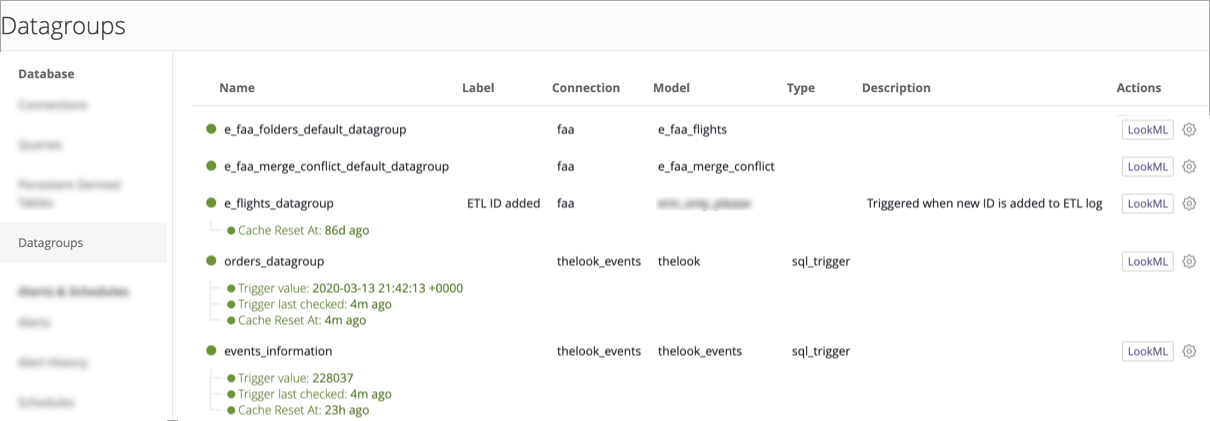
Utilizzare il riquadro Amministratore per i gruppi di dati
Se hai il ruolo Amministratore Looker, puoi utilizzare la pagina Gruppi di dati del riquadro Amministratore per visualizzare i gruppi di dati esistenti. Puoi vedere la connessione, il modello e lo stato corrente di ciascun gruppo di dati e, se specificata in LookML, un'etichetta e una descrizione per ciascun gruppo di dati. Puoi anche reimpostare la cache per un gruppo di dati, attivarlo o accedere al LookML del gruppo di dati.
In che modo Looker utilizza le query memorizzate nella cache
Per le query, il meccanismo di memorizzazione nella cache di Looker funziona come segue:
- Dopo che un utente ha eseguito una query specifica, il risultato della query viene memorizzato nella cache. I risultati nella cache vengono archiviati in un file criptato sull'istanza di Looker.
Quando viene scritta una nuova query, la cache viene controllata per verificare se la query esatta è stata eseguita in precedenza. Tutti i campi, i filtri e i parametri devono essere gli stessi, incluse le impostazioni come i limiti di righe. Se la query non viene trovata, Looker esegue la stessa query sul database per ottenere nuovi risultati, che verranno quindi memorizzati nella cache.
I commenti relativi al contesto non influiscono sulla memorizzazione nella cache. Looker aggiunge un commento univoco all'inizio di ogni query SQL. Tuttavia, finché la query SQL è identica a una query precedente (esclusi i commenti contestuali), Looker utilizzerà i risultati memorizzati nella cache.
Se la query viene trovata nella cache, Looker controlla il criterio di memorizzazione nella cache definito nel modello per verificare se la cache è ancora valida. Per impostazione predefinita, Looker invalida i risultati memorizzati nella cache dopo un'ora. Puoi utilizzare un parametro
persist_for(a livello di modello o Livello di esplorazione) o il parametro più potentedatagroupper specificare il criterio di memorizzazione nella cache che determina le circostanze in cui i risultati memorizzati nella cache diventano non validi e devono essere ignorati. Un amministratore può anche invalidare i risultati memorizzati nella cache per un gruppo di dati.- Se la cache è ancora valida, vengono utilizzati quei risultati.
- Se la cache non è più valida, Looker esegue la query sul database per ottenere nuovi risultati. (che verranno memorizzati nella cache).
Controllare se una query è stata restituita dalla cache
In una finestra di esplorazione, puoi stabilire se una query è stata restituita dalla cache, esaminando l'angolo in alto a destra dopo averla eseguita.
Quando una query viene restituita dalla cache, viene visualizzata la dicitura "da cache". In caso contrario, viene mostrato il tempo necessario per restituire la query.

Forzare la generazione di nuovi risultati dal database
In una finestra di esplorazione, puoi forzare il recupero di nuovi risultati dal database. Seleziona l'opzione Svuota cache e amp; aggiorna dal menu a forma di ingranaggio, disponibile nella parte superiore destra della schermata dopo aver eseguito una query (incluse le query sui risultati uniti):
![]()
Una tabella derivata permanente viene normalmente rigenerata in base alla strategia di persistenza della PDT. Puoi forzare la ricostruzione della tabella derivata in anticipo se l'amministratore ti ha concesso l'autorizzazione develop e stai visualizzando un'esplorazione che include campi della PDT. Seleziona l'opzione Rebuild Derived Tables & Run (Ricostruisci tabelle derivate e esegui) dal menu a discesa a forma di ingranaggio che troverai in alto a destra nella schermata dopo aver eseguito una query:
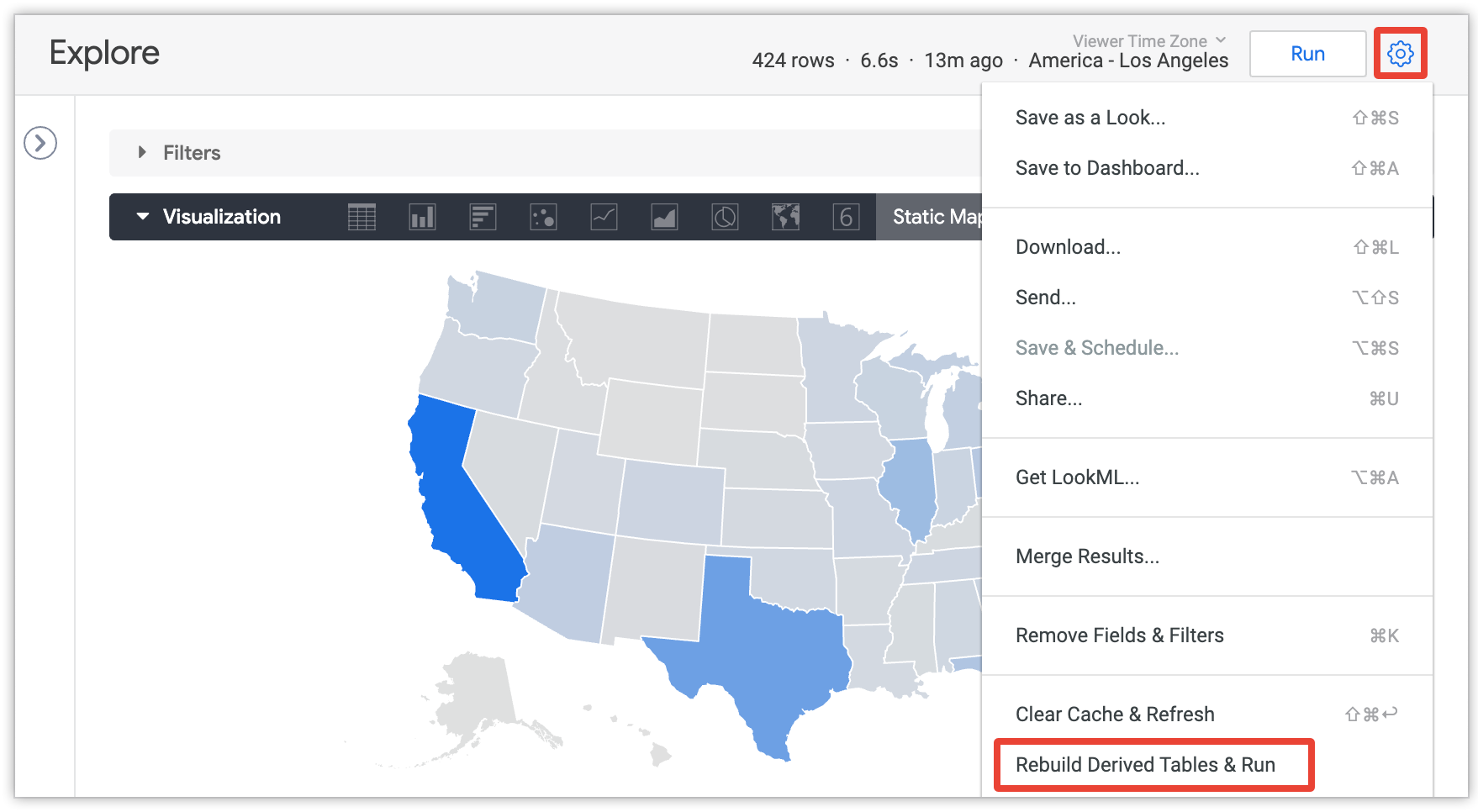
Consulta la pagina della documentazione sulle tabelle derivate in Looker per ulteriori dettagli sull'opzione Rebuild Derived Tables & Run (Ricrea tabelle derivate e esegui).
Per quanto tempo i dati vengono memorizzati nella cache?
Per specificare l'intervallo di tempo prima che i risultati memorizzati nella cache diventino non validi, utilizza il parametro persist_for (per un modello o per un'esplorazione) o il parametro max_cache_age (per un gruppo di dati). Di seguito sono riportati i diversi comportamenti nella sequenza temporale, a seconda che sia scaduta la data persist_for o max_cache_age:
- Prima della scadenza del periodo di tempo di
persist_foromax_cache_age: se la query viene eseguita di nuovo, Looker estrarrà i dati dalla cache. - Alla scadenza di
persist_foro dimax_cache_age: Looker elimina i dati dalla cache, a meno che tu non abbia abilitato la funzionalità Istantane dashboard Looker Labs. - Dopo la scadenza di
persist_foro dimax_cache_age: se la query viene ripetuta, Looker estrae i dati direttamente dal database e reimposta il timer dipersist_foro dimax_cache_age.
Un punto chiave in questo caso è che i dati vengono eliminati dalla cache allo scadere della durata di persist_for o max_cache_age, purché la funzionalità di Lab Instant Dashboard sia disattivata. La funzionalità Dashboard istantanee richiede la cache per poter caricare immediatamente i risultati memorizzati nella cache in una dashboard. Se attivi Dashboard istantanee, i dati rimangono nella cache per 30 giorni o fino a quando i limiti di archiviazione della cache non vengono raggiunti. Se la cache raggiunge il limite di spazio di archiviazione, i dati vengono espulsi in base a un algoritmo L meno utilizzati di recente (LRU), senza alcuna garanzia che i dati con timer persist_for o max_cache_age scaduti vengano eliminati contemporaneamente.
Riduci al minimo il tempo che i dati trascorrono nella cache.
Looker richiede la cache su disco per i processi interni, quindi i dati vengono sempre scritti nella cache, anche se i parametri persist_for e max_cache_age vengono impostati su 0. Una volta scritti nella cache, i dati vengono contrassegnati per l'eliminazione, ma possono durare fino a 10 minuti su disco.
Tuttavia, tutti i dati dei clienti che sono memorizzati nella cache del disco sono criptati tramite Advanced Encryption Standard (AES) e puoi ridurre al minimo la quantità di tempo in cui i dati vengono memorizzati nella cache apportando le seguenti modifiche:
- Disattiva la funzionalità Looker Labs di Looker Labs, che richiede che Looker memorizzi i dati.
- Per qualsiasi parametro
persist_for(per un modello o un'esplorazione) o il parametromax_cache_age(per un gruppo di dati), imposta il valore su 0. Per le istanze Looker con dashboard istantanee disattivate, Looker elimina la cache alla scadenza dipersist_foro al momento in cui i dati raggiungono il valoremax_cache_agespecificato nel relativo datagroup. Questo non è necessario per il parametropersist_fordelle tabelle derivate permanenti, perché le tabelle derivate permanenti vengono scritte nel database stesso e non nella cache. - Imposta il parametro
suggest_persist_forsu un breve periodo di tempo. Il valoresuggest_persist_forspecifica per quanto tempo Looker deve conservare i suggerimenti filtro nella cache. I suggerimenti per i filtri si basano su una query dei valori del campo filtrato. I risultati di queste query vengono conservati nella cache, consentendo a Looker di fornire rapidamente suggerimenti man mano che l'utente digita nel campo di testo del filtro. L'impostazione predefinita è memorizzare nella cache i suggerimenti per i filtri per sei ore. Per ridurre al minimo il tempo in cui i tuoi dati si trovano nella cache, imposta il valoresuggest_persist_forsu un valore inferiore, ad esempio 5 minuti.