In dieser Anleitung wird beschrieben, wie Sie die asynchrone Replikation von Hyperdisk Balanced über zwei Google Cloud Regionen hinweg als Notfallwiederherstellungslösung (Disaster Recovery, DR) aktivieren und wie Sie die DR-Instanzen im Notfall hochfahren.
Microsoft SQL Server Failover Cluster Instances (FCI) ist eine einzelne hochverfügbare SQL Server-Instanz, die auf mehreren Windows Server Failover Cluster-Knoten (WSFC) bereitgestellt wird. Die SQL-Instanz wird immer auf nur einem der Clusterknoten aktiv gehostet. Bei einem zonenweiten Ausfall oder einem VM-Problem überträgt WSFC die Inhaberschaft der Instanzressourcen automatisch auf einen anderen Knoten im Cluster, sodass Clients die Verbindung wiederherstellen können. Für SQL Server-FCI müssen sich die Daten auf freigegebenen Laufwerken befinden, damit der Zugriff über alle WSFC-Knoten möglich ist.
Damit die SQL Server-Bereitstellung einem regionalen Ausfall standhalten kann, replizieren Sie die Festplattendaten der primären Region in eine sekundäre Region, indem Sie die asynchrone Replikation aktivieren. In dieser Anleitung werden Hyperdisk Balanced-Multi-Writer-Laufwerke mit hoher Verfügbarkeit verwendet, um die asynchrone Replikation über zwei Google Cloud Regionen hinweg als DR-Lösung (Disaster Recovery, Notfallwiederherstellung) für SQL Server FCI zu ermöglichen. Außerdem wird beschrieben, wie Sie die DR-Instanzen im Notfall hochfahren. In diesem Dokument ist ein Notfall ein Ereignis, bei dem ein primärer Datenbankcluster ausfällt oder nicht mehr verfügbar ist, weil die Region des Clusters nicht mehr verfügbar ist, z. B. aufgrund einer Naturkatastrophe.
Diese Anleitung richtet sich an Datenbankarchitekten, Administratoren und Entwickler.
Notfallwiederherstellung in Google Cloud
Bei der Notfallwiederherstellung in Google Cloud geht es darum, den kontinuierlichen Zugriff auf Daten aufrechtzuerhalten, wenn eine Region ausfällt oder nicht mehr zugänglich ist. Es gibt mehrere Bereitstellungsoptionen für die DR-Site, die durch die Anforderungen an das Recovery Point Objective (RPO) und das Recovery Time Objective (RTO) bestimmt werden. In dieser Anleitung wird eine der Optionen behandelt, bei denen die an die VM angehängten Laufwerke von der primären Region in die DR-Region repliziert werden.
Notfallwiederherstellung mit asynchroner Hyperdisk-Replikation
Die asynchrone Hyperdisk-Replikation ist eine Speicheroption, die eine asynchrone Speicherkopie für die Replikation von Laufwerken zwischen zwei Regionen bietet. Im unwahrscheinlichen Fall eines regionalen Ausfalls können Sie mit der asynchronen Replikation von Hyperdisk für Ihre Daten ein Failover in einer sekundären Region durchführen und Ihre Arbeitslasten in dieser Region neu starten.
Bei der asynchronen Replikation von Hyperdisk werden Daten von einem Laufwerk, das an eine laufende Arbeitslast angehängt ist (das primäre Laufwerk), auf ein separates Laufwerk in einer anderen Region repliziert. Das Laufwerk, auf dem die replizierten Daten empfangen werden, wird als sekundäres Laufwerk bezeichnet. Die Region, in der das primäre Laufwerk ausgeführt wird, wird als primäre Region bezeichnet. Die Region, in der das sekundäre Laufwerk ausgeführt wird, ist die sekundäre Region. Damit die Replikate aller an jeden SQL Server-Knoten angeschlossenen Laufwerke Daten vom selben Zeitpunkt enthalten, werden die Laufwerke einer Konsistenzgruppe hinzugefügt. Mit Konsistenzgruppen können Sie DR- und DR-Tests auf mehreren Laufwerken durchführen.
Notfallwiederherstellungsarchitektur
Das folgende Diagramm zeigt für die asynchrone Replikation von Hyperdisk eine minimale Architektur, die die Datenbank-Hochverfügbarkeit in einer primären Region, R1, und die Laufwerkreplikation von der primären Region in die sekundäre Region, R2, unterstützt.
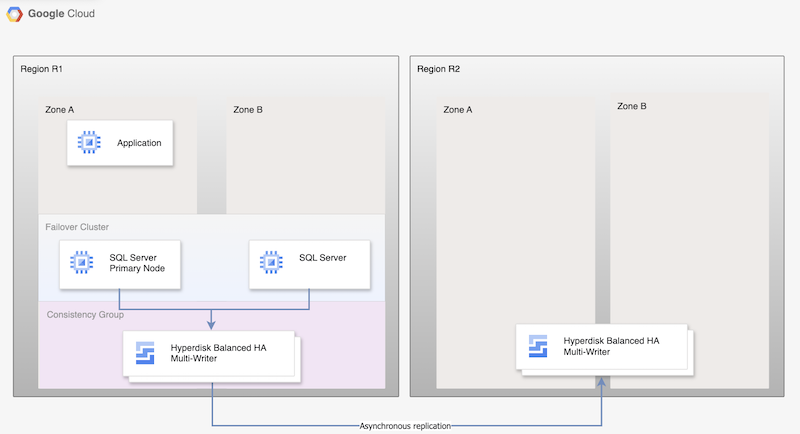
Abbildung 1. Architektur für die Notfallwiederherstellung mit Microsoft SQL Server und asynchroner Hyperdisk-Replikation
Diese Architektur funktioniert so:
- Zwei Instanzen von Microsoft SQL Server, eine primäre Instanz und eine Standby-Instanz, sind Teil eines FCI-Clusters und befinden sich in der primären Region (R1), aber in verschiedenen Zonen (Zonen A und B). Beide Instanzen verwenden ein Hyperdisk-Laufwerk mit ausgeglichener Hochverfügbarkeit, sodass von beiden VMs auf die Daten zugegriffen werden kann. Eine Anleitung finden Sie unter SQL Server-FCI-Cluster mit Hyperdisk Balanced-Hochverfügbarkeitsmodus für mehrere Autoren konfigurieren.
- Laufwerke von beiden SQL-Knoten werden Konsistenzgruppen hinzugefügt und in die DR-Region R2 repliziert. Compute Engine repliziert die Daten asynchron von R1 nach R2.
- Bei der asynchronen Replikation werden nur die Daten auf den Laufwerken in R2 repliziert, nicht die VM-Metadaten. Während der Notfallwiederherstellung werden neue VMs erstellt und die vorhandenen replizierten Laufwerke werden an die VMs angehängt, um die Knoten online zu schalten.
Notfallwiederherstellungsprozess
Der DR-Prozess schreibt die Betriebsschritte vor, die Sie ausführen müssen, nachdem eine Region nicht mehr verfügbar ist, um die Arbeitslast in einer anderen Region fortzusetzen.
Ein grundlegender DR-Prozess für die Datenbank besteht aus den folgenden Schritten:
- Die erste Region (R1), die die primäre Datenbankinstanz ausführt, fällt aus.
- Das operative Team erkennt und bestätigt offiziell den Notfall und entscheidet, ob ein Failover erforderlich ist.
- Wenn ein Failover erforderlich ist, müssen Sie die Replikation zwischen den primären und sekundären Laufwerken beenden. Aus den Laufwerkreplikaten wird eine neue VM erstellt und online gestellt.
- Die Datenbank in der DR-Region R2 wird validiert und online geschaltet. Die Datenbank in R2 wird zur neuen primären Datenbank, wodurch die Verbindung wieder möglich ist.
- Nutzer setzen die Verarbeitung in der neuen primären Datenbank fort und greifen auf die primäre Instanz in R2 zu.
Dieser grundlegende Prozess richtet zwar eine funktionierende primäre Datenbank neu ein, doch wird keine vollständige HA-Architektur aufgebaut, da die neue primäre Datenbank nicht repliziert wird.
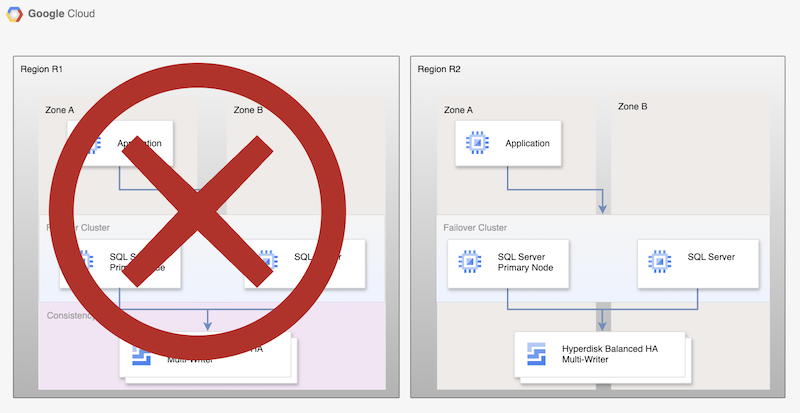
Abbildung 2. SQL Server-Bereitstellung nach der Notfallwiederherstellung mit asynchroner Replikation nichtflüchtiger Speicher
Fallback zu einer wiederhergestellten Region
Sobald die primäre Region (R1) wieder online ist, können Sie den Failback-Prozess planen und ausführen. Der Failback-Prozess besteht aus allen Schritten, die in dieser Anleitung beschrieben werden. In diesem Fall ist R2 jedoch die Quelle und R1 die Wiederherstellungsregion.
SQL Server-Version auswählen
In dieser Anleitung werden die folgenden Versionen von Microsoft SQL Server unterstützt:
- SQL Server 2016 Enterprise und Standard Edition
- SQL Server 2017 Enterprise und Standard Edition
- SQL Server 2019 Enterprise und Standard Edition
- SQL Server 2022 Enterprise und Standard Edition
In dieser Anleitung wird die SQL Server-Failover-Clusterinstanz mit Hyperdisk Balanced High Availability-Laufwerk verwendet.
Wenn Sie keine Funktionen von SQL Server Enterprise benötigen, können Sie die Standard Edition von SQL Server verwenden:
Bei den Versionen 2016, 2017 und 2019 und 2022 von SQL Server ist Microsoft SQL Server Management Studio im Image installiert. Sie müssen das Programm nicht separat installieren. In einer Produktionsumgebung empfehlen wir jedoch, in jeder Region eine Instanz von Microsoft SQL Server Management Studio auf einer separaten VM zu installieren. Wenn Sie eine HA-Umgebung einrichten, sollten Sie Microsoft SQL Server Management Studio für jede Zone einmal installieren. So ist sichergestellt, dass die Instanz auch dann verfügbar bleibt, wenn eine andere Zone ausfällt.
Notfallwiederherstellung für Microsoft SQL Server einrichten
In dieser Anleitung wird das Image sql-ent-2022-win-2022 für Microsoft SQL Server Enterprise verwendet.
Eine vollständige Liste der Images finden Sie unter Betriebssystem-Images.
Hochverfügbarkeits-Cluster mit zwei Instanzen einrichten
Erstellen Sie zuerst einen Hochverfügbarkeits-Cluster mit zwei Instanzen in einer Region, um die Laufwerksreplikation für SQL Server zwischen zwei Regionen einzurichten.
Eine Instanz dient als primäre und die andere als Standby-Instanz. Folgen Sie der Anleitung unter SQL Server-FCI-Cluster mit Hyperdisk Balanced High Availability-Modus für mehrere Autoren konfigurieren, um diesen Schritt auszuführen.
In dieser Anleitung wird us-central1 für die primäre Region R1 verwendet.
Wenn Sie die Schritte unter SQL Server-FCI-Cluster mit Hyperdisk Balanced-Multiwriter-Modus für Hochverfügbarkeit konfigurieren ausgeführt haben, haben Sie zwei SQL Server-Instanzen in derselben Region (us-central1) erstellt. Sie haben eine primäre SQL Server-Instanz (node-1) in us-central1-a und eine Standby-Instanz (node-2) in us-central1-b bereitgestellt.
Asynchrone Replikation von Laufwerken aktivieren
Nachdem Sie alle VMs erstellt und konfiguriert haben, aktivieren Sie die Laufwerksreplizierung zwischen den beiden Regionen. Führen Sie dazu die folgenden Schritte aus:
Erstellen Sie eine Konsistenzgruppe für beide SQL Server-Knoten und den Knoten, auf dem die Rollen für Zeugen und Domaincontroller gehostet werden. Eine der Einschränkungen für Konsistenzgruppen besteht darin, dass sie nicht zonenübergreifend sein können. Daher müssen Sie jeden Knoten einer separaten Konsistenzgruppe hinzufügen.
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
Fügen Sie die Laufwerke der primären und Standby-VMs den entsprechenden Konsistenzgruppen hinzu.
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
Erstellen Sie leere sekundäre Laufwerke in der sekundären Region.
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
Starten Sie die Laufwerksreplikation. Daten werden vom primären Laufwerk auf das neu erstellte leere Laufwerk in der Notfallwiederherstellungs-Region repliziert.
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
Die Daten sollten jetzt zwischen den Regionen repliziert werden.
Der Replikationsstatus für jedes Laufwerk sollte Active lauten.
Notfallwiederherstellung simulieren
In diesem Abschnitt testen Sie die in dieser Anleitung eingerichtete Architektur zur Notfallwiederherstellung.
Ausfall simulieren und ein Notfallwiederherstellungs-Failover ausführen
Bei einem Failover erstellen Sie neue VMs in der DR-Region und hängen die replizierten Laufwerke an diese an. Zur Vereinfachung des Failovers können Sie eine andere Virtual Private Cloud (VPC) in der Notfallwiederherstellungsregion für die Wiederherstellung verwenden, um dieselbe IP-Adresse zu verwenden.
Bevor Sie mit dem Failover beginnen, muss node-1 der primäre Knoten für die von Ihnen erstellte AlwaysOn-Verfügbarkeitsgruppe sein. Rufen Sie den Domaincontroller und den primären SQL Server-Knoten auf, um Probleme bei der Datensynchronisierung zu vermeiden, da die beiden Knoten durch zwei separate Konsistenzgruppen geschützt werden.
So simulieren Sie einen Ausfall:
Erstellen Sie eine VPC für die Wiederherstellung.
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
Beenden Sie die Datenreplikation.
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
Beenden Sie die Quell-VMs in der primären Region.
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
Benennen Sie die vorhandenen VMs um, um doppelte Namen im Projekt zu vermeiden.
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
Erstellen Sie VMs in der DR-Region mit den sekundären Laufwerken. Diese VMs haben die IP-Adresse der Quell-VM.
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
Sie haben einen Ausfall simuliert und eine Failover auf die DR-Region ausgeführt. Sie können jetzt testen, ob die sekundäre Instanz ordnungsgemäß funktioniert.
SQL Server-Verbindung prüfen
Nachdem Sie die VMs erstellt haben, prüfen Sie, ob die Datenbanken erfolgreich wiederhergestellt wurden und der Server wie erwartet funktioniert. Führen Sie eine Abfrage aus der wiederhergestellten Datenbank aus, um die Datenbank zu testen.
- Stellen Sie über Remote Desktop eine Verbindung zur SQL Server-VM her.
- Öffnen Sie SQL Server Management Studio.
- Prüfen Sie im Dialogfeld Mit Server verbinden, ob der Servername auf
node-1festgelegt ist, und wählen Sie Verbinden aus. Wählen Sie im Dateimenü Datei > Neu > Abfrage mit der aktuellen Verbindung aus.
USE [bookshelf]; SELECT * FROM Books;