クエリのパフォーマンス分析情報を取得する
クエリの実行グラフは、BigQuery がクエリの実行に使用するステップを視覚的に表したものです。このドキュメントでは、クエリ実行グラフを使用してクエリ パフォーマンスの問題を診断し、クエリのパフォーマンス分析情報を確認する方法について説明します。
BigQuery は優れたクエリ パフォーマンスを発揮しますが、多数の内部要因と外部要因を持つ複雑な分散システムでもあります。これらの要因は、クエリ速度に影響を及ぼす可能性があります。SQL は宣言型であるため、クエリ実行の複雑さが覆い隠されることもあります。つまり、クエリの実行速度が予想よりも遅い場合や、以前よりも遅い場合、何が起こっているのかを理解することが困難になる可能性があるということです。
クエリ実行グラフは、クエリプランとクエリ パフォーマンスの詳細を調べるための動的グラフィカル インターフェースです。実行中または完了したクエリのクエリ実行グラフを確認できます。
また、クエリ実行グラフを使用して、クエリのパフォーマンス分析情報を取得することもできます。パフォーマンス分析情報には、クエリ パフォーマンスを改善する際に役立つベスト エフォート型の推奨事項が出力されます。クエリ パフォーマンスは多面的なものであるため、パフォーマンス分析情報ではクエリ パフォーマンス全体の一部の情報しか得られない場合があります。
必要な権限
クエリ実行グラフを使用するには、次の権限が必要です。
bigquery.jobs.getbigquery.jobs.listAll
これらの権限は、BigQuery の次の Identity and Access Management(IAM)事前定義ロールで利用可能です。
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
実行グラフの構造
クエリ実行グラフは、コンソールにあるクエリプランのグラフィカル ビューです。各ボックスは、次のようにクエリプランのステージを表します。
- 入力: テーブルからのデータ読み取り、または特定の列の選択
- 結合:
JOIN条件に基づく 2 つのテーブルのデータの結合 - 集計:
SUMなどの計算の実行 - 並べ替え: 結果の並べ替え
ステージは、ステージ内の各ワーカーが実行する個々のオペレーションを記述するステップで構成されます。ステージをクリックして開くと、そのステップを表示できます。ステージには、相対的なタイミング情報と絶対的なタイミング情報も含まれます。ステージ名は、実行するステップを要約したものです。たとえば、名前に「join」が付いているステージは、ステージのプリンシパル ステップが JOIN オペレーションであることを意味します。ステージ名の末尾に + が付いている場合、追加で重要なステップを実行することを意味します。たとえば、名前に JOIN+ が付いているステージは、そのステージで結合オペレーションやその他の重要なステップが実行されることを意味します。
ステージを接続する線は、ステージ間の中間データの交換を表します。BigQuery は、ステージの実行中に中間データをシャッフル メモリに保存します。末端の数字は、ステージ間で交換される行数の推定値を示します。シャッフル メモリの割り当ては、アカウントに割り当てられたスロット数と相関しています。シャッフルの割り当て分を超過すると、シャッフル メモリの一部がディスクに移動し、クエリのパフォーマンスが大幅に低下する可能性があります。
クエリのパフォーマンス分析情報を表示する
コンソール
次の手順に沿って、クエリのパフォーマンス分析情報を表示します。
Google Cloud コンソールで [BigQuery] ページを開きます。
エディタで、[個人履歴] または [プロジェクト履歴] をクリックします。
ジョブのリストで、目的のクエリジョブを見つけます。[ アクション] をクリックし、[クエリをエディタで開く] を選択します。
[実行グラフ] タブを選択して、クエリの各ステージをグラフィカルに表示します。
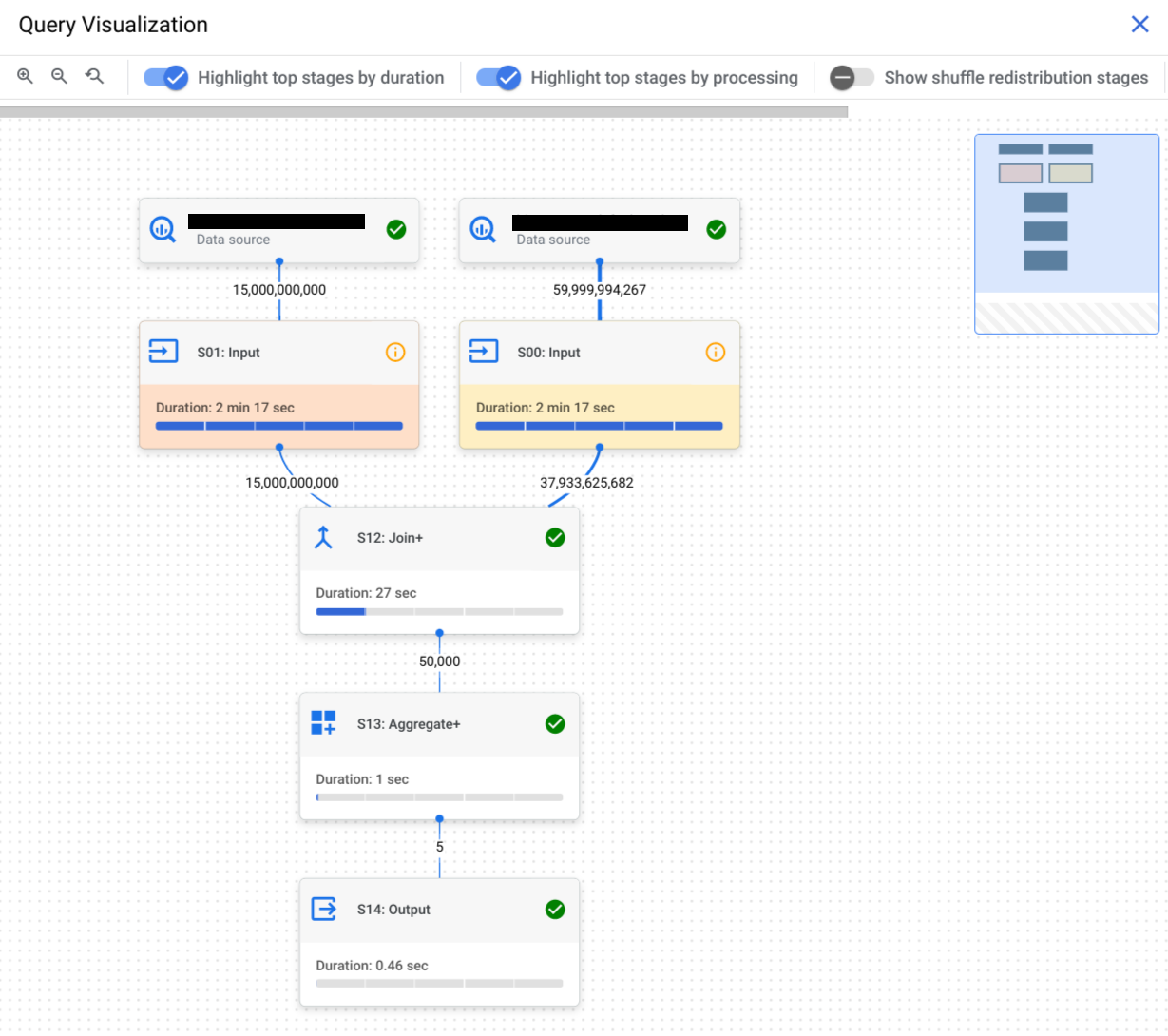
クエリステージにパフォーマンス分析情報があるかどうかは、表示されるアイコンで確認できます。情報アイコン のあるステージには、パフォーマンス分析情報があります。チェック アイコン があるステージには、パフォーマンス分析情報がありません。
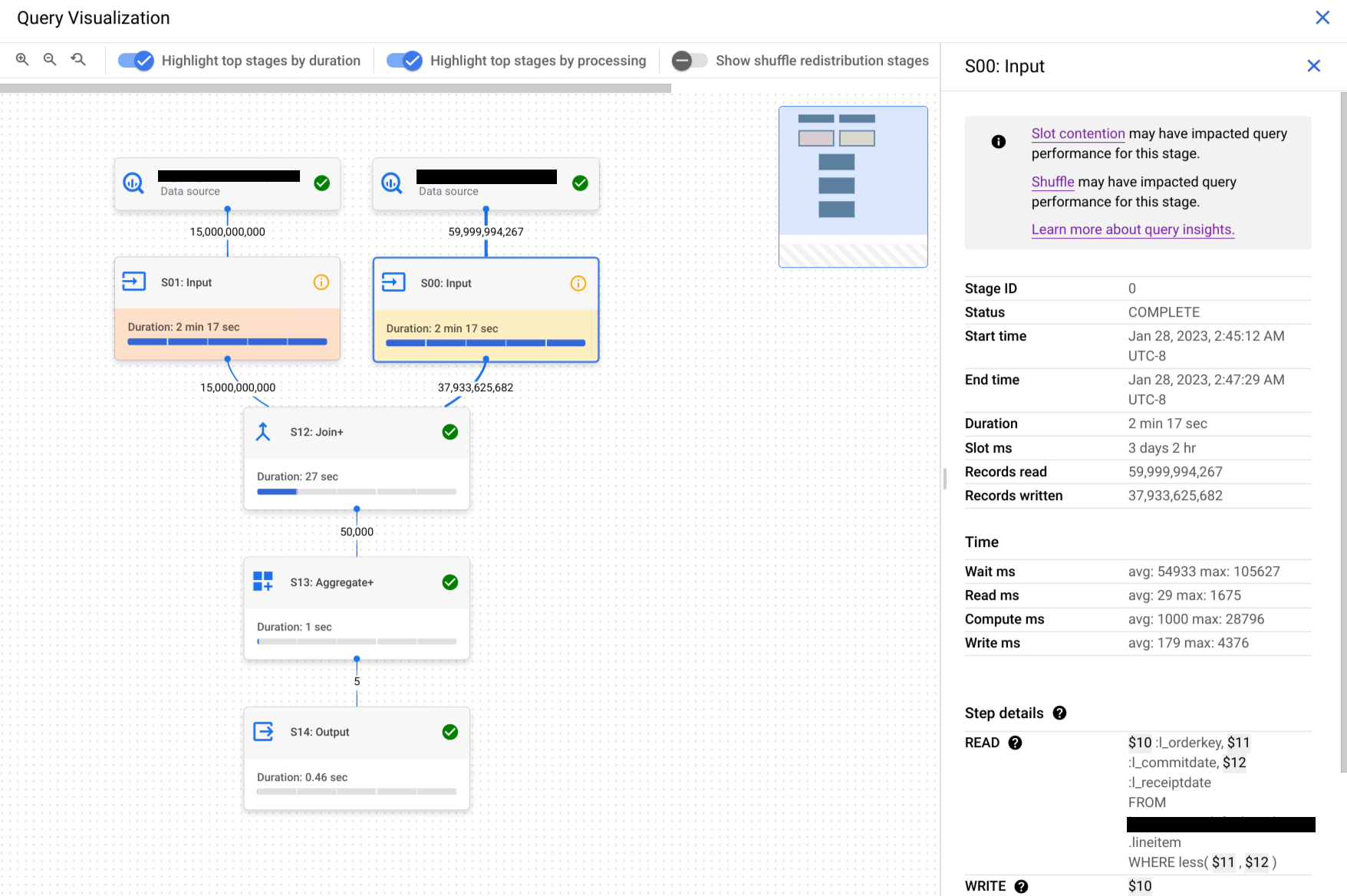
ステージをクリックしてステージの詳細ペインを開きます。ここでは、次の情報を確認できます。
省略可: 実行中のクエリを調べる場合は、同期アイコン をクリックして実行グラフを更新し、クエリの現在のステータスを反映させます。

省略可: ステージ期間別に上位のステージをグラフでハイライト表示するには、[期間別の上位のステージをハイライト表示する] をクリックします。

省略可: 使用されたスロット時間別の上位のステージをグラフでハイライト表示するには、[処理別の上位のステージをハイライト表示する] をクリックします。

省略可: グラフにシャッフルの再分配ステージを含めるには、[シャッフルの再分配の段階を表示する] をクリックします。

このオプションを使用すると、デフォルトの実行グラフでは表示されていない再パーティション化ステージと結合ステージが表示されます。
再パーティション化ステージと結合ステージはクエリの実行中に追加され、クエリを処理するワーカー間でのデータ分散を改善するために使用されます。これらのステージはクエリテキストとは無関係であるため、表示されるクエリプランを簡略化するために非表示になっています。
パフォーマンス低下の問題が発生しているクエリについては、そのクエリの [ジョブ情報] タブにパフォーマンス分析情報も表示されます。
![[ジョブ情報] タブ。](https://cloud.google.com/static/bigquery/images/job-perf-insights.png?hl=ja)
SQL
Google Cloud コンソールで、[BigQuery] ページに移動します。
クエリエディタで次のステートメントを入力します。
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
[実行] をクリックします。
クエリの実行方法については、インタラクティブ クエリを実行するをご覧ください。
API
クエリのパフォーマンス分析情報をグラフィカル以外の形式で取得するには、jobs.list API メソッドを呼び出し、返される JobStatistics2 情報を検査します。
クエリのパフォーマンス分析情報を解釈する
このセクションでは、パフォーマンス分析情報が示す内容と、その内容に対処する方法について説明します。
パフォーマンス分析情報は、次の 2 種類の対象者が使用することを前提としています。
アナリスト: プロジェクトでクエリを実行します。以前実行したクエリの実行速度が予想外に遅くなっている理由を探り、クエリのパフォーマンスを向上させるためのヒントを得たいと考えています。必要な権限に記載されている権限があります。
データレイクまたはデータ ウェアハウスの管理者: 組織の BigQuery リソースと予約を管理しています。BigQuery 管理者ロールに関連付けられた権限があります。
以下の各セクションでは、これらのどのロールが付与されているかに基づいて、表示されたパフォーマンス分析情報に対処するためのガイダンスを提供します。
スロット競合
クエリを実行すると、BigQuery はクエリに必要な作業をタスクに分割しようとします。タスクは、ステージから入出力されるデータの単一のスライスです。1 つのスロットがタスクを受け取り、ステージのそのデータスライスを実行します。BigQuery スロットがこれらのタスクを並列実行して、高いパフォーマンスを実現できると理想的です。実行開始を待機しているタスクがクエリに多数あるにもかかわらず、BigQuery がそれらを実行するのに十分なスロットを確保できない場合、スロット競合が発生します。
アナリストの場合の対処方法
クエリで処理されるデータを削減するのガイダンスに沿って、クエリで処理するデータを削減します。
管理者の場合の対処方法
次の操作を行って、スロットの可用性を高めるかスロットの使用量を減らします。
- BigQuery をオンデマンド料金で使用している場合、クエリではスロットの共有プールが使用されます。代わりに予約を購入して、容量ベースの分析料金に切り替えることを検討してください。予約を使用すると、組織のクエリ専用のスロットを予約できます。
BigQuery の予約を使用している場合は、クエリを実行したプロジェクトに割り当てられている予約に十分なスロットがあることを確認します。次のシナリオでは、予約に十分なスロットがない可能性があります。
- 予約スロットを使用しているジョブが他にもある。管理リソースグラフを使用すると、組織による予約の使用状況を確認できます。
- クエリを高速実行するのに十分なスロットが予約に割り当てられていない。スロット見積もりツールを使用すると、クエリのタスクを効率的に処理するために必要な予約の規模を見積もることができます。
この問題に対処するには、次のいずれかの方法を試します。
- その予約にスロット(ベースライン スロットまたは予約スロットの最大数のいずれか)を追加する。
- 追加の予約を作成し、クエリを実行するプロジェクトに割り当てる。
- リソースを大量に消費するクエリを、1 つの予約内でさまざまな時間に分散させるか、複数の予約に分散させる。
クエリ対象のテーブルがクラスタ化されていることを確認します。クラスタリングを使用すると、相関データを含む列を BigQuery がすばやく読み取ることができます。
クエリ対象のテーブルがパーティション分割されていることを確認します。パーティション分割されていないテーブルの場合、BigQuery はテーブル全体を読み取ります。テーブルをパーティション分割することで、テーブルの目的のサブセットのみをクエリできます。
シャッフルの割り当て不足
BigQuery は、クエリを実行する前にクエリのロジックをステージに分割します。BigQuery スロットが各ステージのタスクを実行します。スロットは、ステージのタスクの実行を完了すると、中間結果をシャッフルに格納します。クエリのその後のステージでは、シャッフルからデータを読み取ってクエリの実行を続行します。シャッフルに書き込む必要があるデータの量がシャッフルの容量を超えた場合、シャッフルの割り当て不足が発生します。
アナリストの場合の対処方法
スロット競合の場合と同様に、クエリで処理されるデータ量を減らすと、シャッフルの使用量が低下する可能性があります。これを行うには、クエリで処理されるデータを削減するのガイダンスに沿って操作してください。
SQL の特定のオペレーション、特に JOIN 操作と GROUP BY 句では、シャッフルを多用します。可能であれば、これらのオペレーションのデータ量を減らすと、シャッフルの使用量が低下する可能性があります。
管理者の場合の対処方法
次の操作を行って、シャッフルの割り当ての競合を減らします。
- スロット競合と同様に、BigQuery をオンデマンド料金で使用する場合、クエリではスロットの共有プールが使用されます。代わりに予約を購入して、容量ベースの分析料金に切り替えることを検討してください。予約を使用すると、プロジェクトのクエリ専用のスロットとシャッフル容量が提供されます。
BigQuery の予約を使用している場合、スロットには専用のシャッフル容量があります。シャッフルを大量に使用するクエリが予約で実行されている場合、並列実行される他のクエリで十分なシャッフル容量を確保できなくなることがあります。多くのシャッフル容量を使用しているジョブを特定するには、
INFORMATION_SCHEMA.JOBS_TIMELINEビューでperiod_shuffle_ram_usage_ratio列をクエリします。この問題に対処するには、次の方法をいくつか試します。
- その予約にスロットを追加する。
- 追加の予約を作成し、クエリを実行するプロジェクトに割り当てる。
- シャッフルを大量に消費するクエリを、1 つの予約内でさまざまな時間に分散させるか、複数の予約に分散させる。
データ入力スケールの変更
このパフォーマンス分析情報が表示されるということは、クエリが最後にクエリを実行したときよりも、特定の入力テーブルに対して少なくとも 50% 多くのデータを読み取っています。テーブル変更履歴を使用すると、クエリで使用されているテーブルのサイズが最近増加したかどうかを確認できます。
アナリストの場合の対処方法
クエリで処理されるデータを削減するのガイダンスに沿って、クエリで処理するデータを削減します。
カーディナリティの高い結合
結合の両側で一意でないキーを使用する結合がクエリに含まれている場合、出力テーブルのサイズがいずれかの入力テーブルのサイズよりもはるかに大きくなることがあります。この分析情報は、入力行に対する出力行の割合が高いことを示し、これらの行数に関する情報を提供します。
アナリストの場合の対処方法
結合条件をチェックして、出力テーブルのサイズの増加が想定内であることを確認します。クロス結合は使用しないでください。クロス結合を使用する必要がある場合は、GROUP BY 句を使用して結果を事前に集計するか、ウィンドウ関数を使用します。詳細については、JOIN を使用する前にデータを削減するをご覧ください。
パーティション スキュー
この機能に関するフィードバックを提供するか、サポートをリクエストする場合は、bq-query-inspector-feedback@google.com までメールをお送りください。
データの分布が偏っていると、クエリの実行が遅くなる可能性があります。クエリが実行されると、BigQuery はデータを小さなパーティションに分割します。パーティションをスロット間で共有することはできません。そのため、データが均等に分散されていないと、一部のパーティションが非常に大きくなり、その大きいパーティションを処理するスロットがクラッシュします。
スキューは JOIN ステージで発生します。JOIN 操作を実行すると、BigQuery は JOIN 操作の右側と左側のデータをパーティションに分割します。パーティションが大きすぎると、再パーティション分割ステージによってデータが再調整されます。過度のデータスキューが生じていて、BigQuery がこれ以上再調整できない場合、パーティション スキューの分析情報が「JOIN」ステージに追加されます。このプロセスは、「再パーティション分割ステージ」と呼ばれます。BigQuery がこれ以上分割できない大きなパーティションを検出すると、パーティション スキューの分析情報が JOIN ステージに追加されます。
アナリストの場合の対処方法
パーティション スキューを回避するには、できるだけ早い段階でデータをフィルタリングします。
クエリステージ情報を解釈する
クエリのパフォーマンス分析情報だけでなく、クエリステージの詳細を確認する際に次のガイドラインを使用すると、クエリに問題があるかどうかを判断できます。
- 以前に実行したクエリと比較して、1 つ以上のステージの [待機(ミリ秒)] 値が高い場合:
- ワークロードに対応するのに十分なスロットがあるかどうかを確認します。十分でない場合は、リソースを大量に消費するクエリを実行する際に負荷が分散されるようにロードバランシングを行います。
- 1 つのステージの [待機(ミリ秒)] 値が以前よりも高い場合は、前のステージを確認して、ボトルネックが生じているかどうかを確認します。クエリに関連するテーブルのデータやスキーマの大幅な変更などが、クエリのパフォーマンスに影響することがあります。
- ステージの [シャッフルの出力バイト数] 値が前のクエリ実行や前のステージと比較して高い場合は、そのステージで処理されたステップを評価して、予想外に多くのデータが作成されているかどうかを確認します。一般的な原因の一つは、結合の両側に重複するキーがある
INNER JOINがステップで処理されたことです。この場合、予想外に多くのデータが返される場合があります。 - 実行グラフを使用して、所要時間別、処理別の上位ステージを確認します。クエリによって生成されるデータの量を確認し、クエリで参照されるテーブルのサイズに比例するかどうかを検討してください。データ量とテーブルのサイズが比例しない場合は、そのステージのステップを確認し、いずれかのステップで想定外の量の中間データが生成されているかどうかを確認します。
次のステップ
- クエリの最適化に関するガイドラインで、クエリのパフォーマンスを向上させるためのヒントをご覧ください。