Dieses Dokument enthält allgemeine Informationen zum differenziellen Datenschutz für BigQuery. Die Syntax finden Sie in der differenziellen Datenschutzklausel. Eine Liste der Funktionen, die Sie mit dieser Syntax verwenden können, finden Sie unter Differenzielle private Aggregatfunktionen.
Was ist differenzieller Datenschutz?
Differenzieller Datenschutz ist ein Standard für Berechnungen von Daten, der die personenbezogenen Daten begrenzt, die in einer Ausgabe angezeigt werden. Differenzieller Datenschutz wird häufig verwendet, um Daten gemeinsam zu nutzen und Inferenzen über Personengruppen zu ermöglichen, während gleichzeitig verhindert wird, dass jemand Informationen über eine Person erlernt.
Differenzieller Datenschutz ist nützlich:
- Wo die Gefahr einer Re-Identifikation besteht.
- Um den Kompromiss zwischen Risiko und analytischem Nutzen zu quantifizieren.
Betrachten wir ein einfaches Beispiel, um den differenziellen Datenschutz besser zu verstehen.
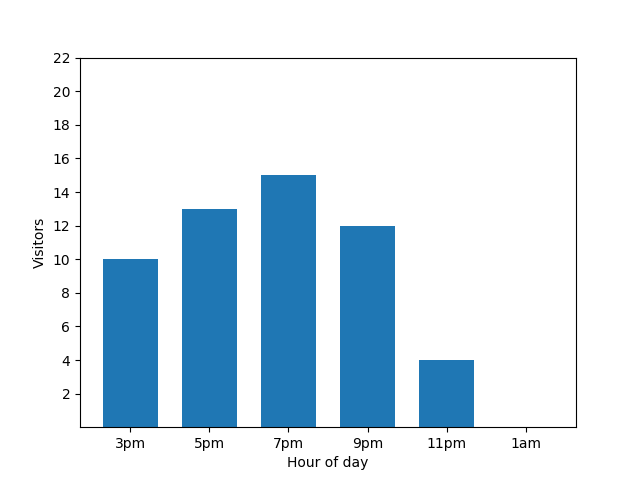
Dieses Balkendiagramm zeigt die Auslastung eines kleinen Restaurants an einem bestimmten Abend. Viele Gäste kommen um 19:00 Uhr und das Restaurant ist um 01:00 Uhr komplett leer:
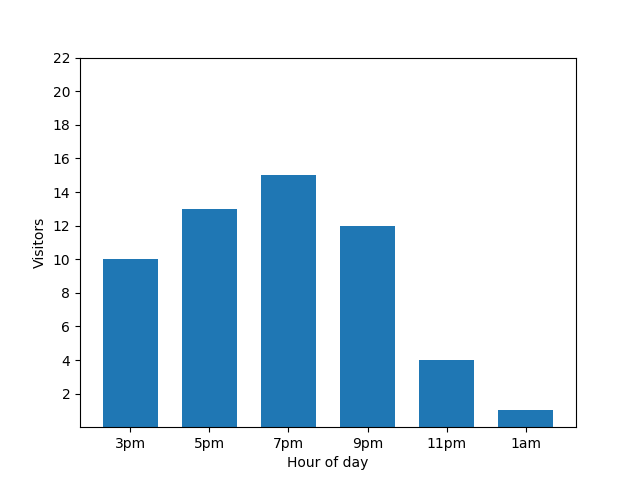
Dieses Diagramm sieht nützlich aus, hat aber einen Haken. Wenn ein neuer Gast ankommt, wird dies sofort durch das Balkendiagramm sichtbar. Im folgenden Diagramm ist klar erkennbar, dass ein neuer Gast vorhanden ist und dieser Gast etwa um 1:00 Uhr eingegangen ist:
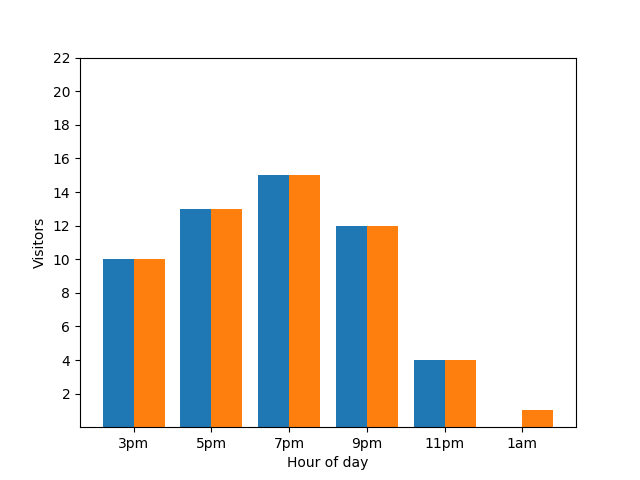
Die Angabe dieses Details ist aus Sicht des Datenschutzes nicht optimal, da anonymisierte Statistiken keinen Aufschluss über individuelle Abgaben geben sollten. Wenn Sie diese beiden Diagramme nebeneinander stellen, ist das noch besser erkennbar: Das orangefarbene Balkendiagramm hat einen zusätzlichen Gast, der um 01:00 Uhr angekommen ist:
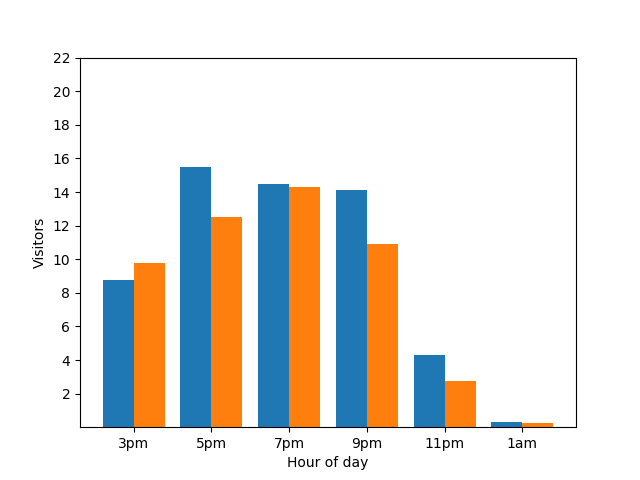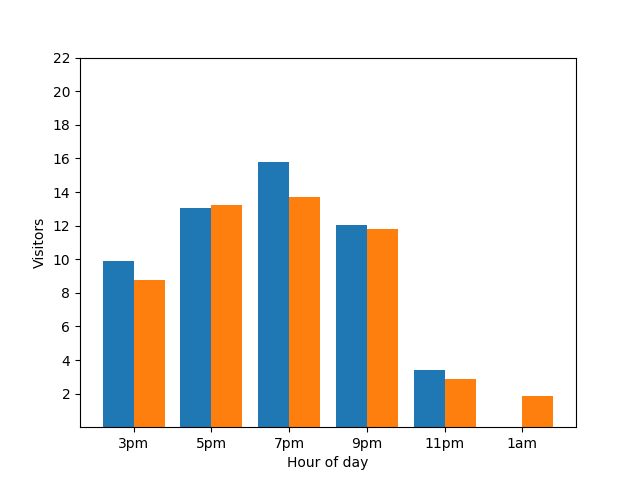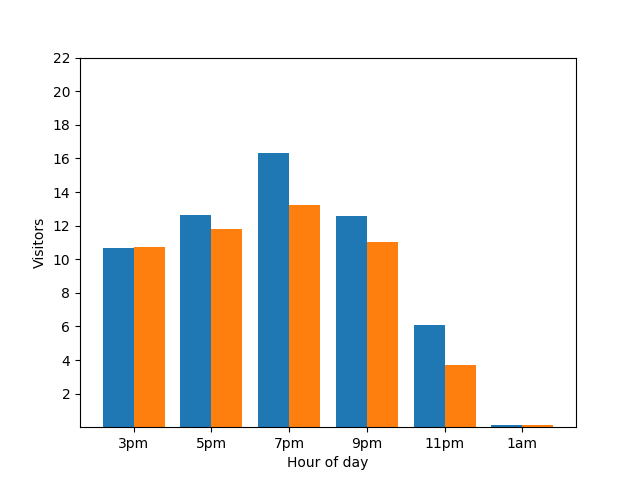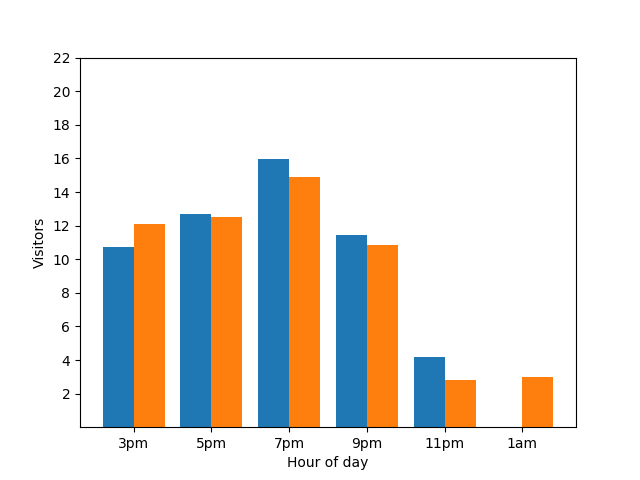
Auch das ist nicht gut. Um diesem Datenschutzproblem vorzubeugen, können Sie den Balkendiagrammen mithilfe des differenziellen Datenschutzes zufälliges Rauschen hinzufügen. Im folgenden Vergleichsdiagramm werden die Ergebnisse anonymisiert und es werden keine einzelnen Beiträge mehr angezeigt.
Funktionsweise des differenziellen Datenschutzes bei Abfragen
Das Ziel des differenziellen Datenschutzes ist es, das Offenlegungsrisiko zu minimieren: das Risiko, dass jemand Informationen über eine Entität in einem Datensatz in Erfahrung bringen kann. Der differenzielle Datenschutz schafft einen Ausgleich zwischen der Notwendigkeit, die Privatsphäre zu schützen, und dem Nutzen von statistischen Analysen. Je mehr Datenschutz, desto geringer der statistische analytische Nutzen und umgekehrt.
Mit GoogleSQL for BigQuery können Sie die Ergebnisse einer Abfrage mit differenziell privaten Aggregationen transformieren. Bei der Ausführung der Abfrage passiert Folgendes:
- Berechnung die Aggregationen pro Entität für jede Gruppe, wenn Gruppen mit einer
GROUP BY-Klausel angegeben sind. Beschränkung de Anzahl der Gruppen, zu denen jede Entität beitragen kann, basierend auf dem differenziellen Datenschutzparametermax_groups_contributed. - Clamping für alle aggregierten Beiträge pro Einheit, damit sie innerhalb der Clamping-Grenzen liegen. Wenn die Clamping-Grenzen nicht angegeben sind, werden sie implizit auf eine differenzielle private Weise berechnet.
- Zusammenfassung der eingeschränkten aggregierten Beiträge pro Entität für jede Gruppe.
- Fügt Rauschen zum endgültigen Aggregatwert für jede Gruppe hinzu. Das Ausmaß des zufälligen Rauschens ist eine Funktion aller Clamping-Grenzen und Datenschutzparameter.
- Berechnung einer ungenauen Entitätsanzahl für jede Gruppe und Entfernung von Gruppen mit wenigen Entitäten. Eine ungenaue Entitätsanzahl trägt dazu bei, einen nicht deterministischen Satz von Gruppen zu vermeiden.
Das Ergebnis ist ein Datensatz, in dem jede Gruppe verrauschte Gesamtergebnisse hat und kleine Gruppen eliminiert wurden.
Weitere Informationen zu differenziellem Datenschutz und den entsprechenden Anwendungsfällen finden Sie in den folgenden Artikeln:
- Eine nutzerfreundliche, nicht technische Einführung in den differenziellen Datenschutz
- Differenzielles privates SQL mit begrenztem Nutzerbeitrag
- Differenzieller Datenschutz auf Wikipedia
Gültige differenzielle private Abfrage erstellen
Die folgenden Regeln müssen erfüllt sein, damit die differenzielle private Abfrage gültig ist:
- Eine Spalte für Datenschutzeinheiten ist definiert.
- Die Liste
SELECTenthält eine differenzielle private Klausel. - Nur differenzielle private Aggregatfunktionen befinden sich in der Liste
SELECTmit der differenziellen privaten Klausel.
Spalte für Datenschutzeinheit definieren
Eine Datenschutzeinheit ist die Entität in einem Dataset, das mit differenziellem Datenschutz geschützt wird. Eine Entität kann eine Einzelperson, ein Unternehmen, ein Standort oder eine beliebige Spalte sein.
Eine differenziell private Abfrage darf nur eine Spalte für die Datenschutzeinheit enthalten. Eine Spalte der Datenschutzeinheit ist eine eindeutige Kennung für eine Datenschutzeinheit und kann in mehreren Gruppen vorhanden sein. Da mehrere Gruppen unterstützt werden, muss der Datentyp für die Datenschutzeinheitspalte gruppierbar sein.
Sie können eine Spalte für die Datenschutzeinheit in der OPTIONS-Klausel einer differenziellen Datenschutzklausel mit der eindeutigen Kennzeichnung privacy_unit_column definieren.
In den folgenden Beispielen wird eine Spalte für die Datenschutzeinheit zu einer differenziellen Datenschutzklausel hinzugefügt. id steht für eine Spalte, die aus einer Tabelle namens students stammt.
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM students;
SELECT WITH DIFFERENTIAL_PRIVACY
OPTIONS (epsilon=10, delta=.01, privacy_unit_column=members.id)
item,
COUNT(*, contribution_bounds_per_group=>(0, 100))
FROM (SELECT * FROM students) AS members;
Rauschen aus einer differenziellen privaten Abfrage entfernen
Weitere Informationen finden Sie in der Referenz zur Abfragesyntax unter Rauschen entfernen.
Rauschen in einer differenziellen privaten Abfrage einfügen
Weitere Informationen finden Sie in der Referenz zur Abfragesyntax unter Rauschen hinzufügen.
Gruppen beschränken, in denen eine Datenschutzeinheit-ID vorhanden sein kann
Weitere Informationen finden Sie in der Referenz zur Abfragesyntax unter Gruppen einschränken, in denen eine Datenschutzeinheit-ID vorhanden sein kann.
Beschränkungen
In diesem Abschnitt werden die Einschränkungen des differenziellen Datenschutzes beschrieben.
Auswirkungen der differenziellen Privatsphäre auf die Leistung
Differenzielle private Abfragen werden langsamer ausgeführt als Standardabfragen, da die Aggregation pro Entität durchgeführt wird und die Einschränkung max_groups_contributed angewendet wird. Wenn Sie die Beitragsgrenzen beschränken, können Sie die Leistung Ihrer differenziellen privaten Abfragen verbessern.
Die Leistungsprofile der folgenden Abfragen sind nicht ähnlich:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
Der Grund für den Leistungsunterschied besteht darin, dass für differenziell private Abfragen eine zusätzliche Granularitätsstufe für die Gruppierung verwendet wird, da ebenfalls eine Aggregation pro Entität durchgeführt werden muss.
Die Leistungsprofile der folgenden Abfragen sollten ähnlich sein, wobei die differenzielle private Abfrage etwas langsamer ist:
SELECT
WITH DIFFERENTIAL_PRIVACY OPTIONS(epsilon=1, delta=1e-10, privacy_unit_column=id)
column_a, COUNT(column_b)
FROM table_a
GROUP BY column_a;
SELECT column_a, id, COUNT(column_b)
FROM table_a
GROUP BY column_a, id;
Die differenzielle private Abfrage ist langsamer, da sie eine hohe Anzahl unterschiedlicher Werte für die Datenschutzeinheit-Spalte hat.
Implizite Begrenzungsbeschränkungen für kleine Datasets
Die implizite Begrenzung funktioniert am besten bei Berechnung mit großen Datasets. Die implizite Begrenzung kann mit Datasets fehlschlagen, die eine geringe Anzahl von Datenschutzeinheiten enthalten, wobei keine Ergebnisse zurückgegeben werden. Darüber hinaus kann die implizite Begrenzung eines Datasets mit einer geringen Anzahl von Datenschutzeinheiten dazu führen, dass ein großer Teil von Nicht-Ausreißern eingegrenzt wird, was zu unzureichend erfassten Aggregationen und Ergebnissen führt, die mehr durch die Begrenzung als durch zusätzliches Rauschen verändert werden. Datasets, die eine geringe Anzahl von Datenschutzeinheiten haben oder dünn partitioniert sind, sollten eher explizit als implizit eingegrenzt werden.
Sicherheitslücken und Datenschutz
Jeder differenzielle Datenschutzalgorithmus – einschließlich dieses Algorithmus – birgt das Risiko eines Lecks persönlicher Daten, wenn ein Analyst in böser Absicht handelt, insbesondere bei der Berechnung grundlegender Statistiken wie Summen, aufgrund arithmetischer Einschränkungen.
Einschränkungen bei Datenschutzgarantien
Während BigQuery Differential Privacy den Algorithmus für differenziellen Datenschutz anwendet, gibt es keine Garantie für die Datenschutzattribute des resultierenden Datasets.
Laufzeitfehler
Ein Analyst, der in böser Absicht handelt und die Möglichkeit hat, Abfragen zu schreiben oder Eingabedaten zu kontrollieren, könnte einen Laufzeitfehler bei persönlichen Daten auslösen.
Gleitkommarauschen
Sicherheitslücken im Zusammenhang mit Rundung, wiederholten Rundungen und Neuanordnungsangriffen sollten vor der Verwendung von differenziellem Datenschutz berücksichtigt werden. Diese Sicherheitslücken sind besonders bedenklich, wenn ein Angreifer einen Teil der Inhalte eines Datasets oder die Reihenfolge der Inhalte in einem Dataset manipulieren kann.
Differenziell private Hinzufügungen von Rauschen auf Gleitkommadatentypen unterliegen den unter Weitverbreitete Unterschätzung der Empfindlichkeit von differenziell privaten Bibliotheken und wie man sie behebt beschriebenen Schwachstellen. Das Hinzufügen von Rauschen bei Ganzzahldatentypen ist nicht von den in diesem Artikel beschriebenen Sicherheitslücken betroffen.
Risiken von Timing-Angriffen
Ein Analyst, der in böser Absicht handelt, könnte eine ausreichend komplexe Abfrage ausführen, um anhand der Ausführungsdauer einer Abfrage Rückschlüsse auf die Eingabedaten zu ziehen.
Fehlklassifizierung
Bei der Erstellung einer differenziellen Datenschutzabfrage wird davon ausgegangen, dass Ihre Daten in einer bekannten und verständlichen Struktur vorliegen. Wenn Sie differenziellen Datenschutz auf die falschen Kennzeichnungen anwenden, z. B. auf eine Transaktions-ID anstelle der ID einer einzelnen Entität, werden vertrauliche Daten möglicherweise preisgegeben.
Wenn Sie Hilfe bei der Analyse Ihrer Daten benötigen, sollten Sie Dienste und Tools wie die folgenden nutzen:
Preise
Für die Verwendung des differenziellen Datenschutzes fallen keine zusätzlichen Kosten an, aber für die Analyse gelten die standardmäßigen BigQuery-Preise.