空間分析のベスト プラクティス
このドキュメントでは、BigQuery で地理空間クエリのパフォーマンスを最適化するためのベスト プラクティスについて説明します。これらのベスト プラクティスを使用すると、パフォーマンスを向上させ、費用とレイテンシを削減できます。
データセットには、道路、土地区画、洪水地域などの複雑な特徴を表すポリゴン、マルチポリゴン シェイプ、LineString の大規模なコレクションを含めることができます。各シェイプには数千個のポイントを含めることができます。BigQuery のほとんどの空間演算(交差や距離の計算など)では、基盤となるアルゴリズムが通常、各シェイプのほとんどのポイントを参照して結果を生成します。オペレーションによっては、アルゴリズムがすべてのポイントを参照します。複雑なシェイプの場合、各ポイントを参照すると、空間オペレーションのコストと所要時間が増加する可能性があります。このガイドで紹介する戦略と方法を使用することで、こうした一般的な空間オペレーションを最適化し、パフォーマンスを向上させて費用を削減できます。
このドキュメントでは、BigQuery 地理空間テーブルが地理列でクラスタ化されていることを前提としています。
シェイプを簡略化する
ベスト プラクティス: simplify 関数と snap-to-grid 関数を使用して、元のデータセットの簡素化バージョンをマテリアライズド ビューとして保存します。
多くの点を持つ複雑なシェイプは、精度をあまり損なうことなく簡略化できます。BigQuery の ST_SIMPLIFY 関数と ST_SNAPTOGRID 関数は、別々に使用するか、組み合わせて使用して複雑なシェイプの点数を減らします。これらの関数は、BigQuery のマテリアライズド ビューと組み合わせて、元のデータセットの簡素化されたバージョンをマテリアライズド ビューとして保存します。このマテリアライズド ビューは、ベーステーブルに対して自動的に最新の状態に保たれます。
シェイプの簡素化は、次のユースケースでデータセットのコストとパフォーマンスの改善に非常に有効です。
- 実際のシェイプとの類似性を維持する必要がある場合。
- 高精度なオペレーションを実行する必要がある場合。
- シェイプの詳細が目立って損なわれることなく、可視化を高速化したい場合。
次のコードサンプルでは、geom という名前の GEOGRAPHY 列を持つベーステーブルで ST_SIMPLIFY 関数を使用する方法を示します。このコードは、指定された許容値 1.0 メートルを超えてシェイプのエッジを乱すことなく、シェイプを簡素化してポイントを削除します。
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SIMPLIFY(geom, 1.0) AS geom
FROM base_table
)
次のコードサンプルでは、ST_SNAPTOGRID 関数を使用して、0.00001 度の解像度でポイントをグリッドにスナップする方法を示します。
CREATE MATERIALIZED VIEW project.dataset.base_mv
CLUSTER BY geom
AS (
SELECT
* EXCEPT (geom),
ST_SNAPTOGRID(geom, -5) AS geom
FROM base_table
)
この関数の grid_size 引数は指数として機能します。つまり、10e-5 = 0.00001 です。この解像度は、赤道で発生する最悪のケースでは約 1 メートルに相当します。
これらのビューを作成したら、ベーステーブルのクエリに使用するクエリ セマンティクスを使用して base_mv ビューにクエリを実行します。この手法を使用すると、より詳細に分析する必要があるシェイプのコレクションをすばやく特定し、ベーステーブルで 2 回目の詳細な分析を実行できます。クエリをテストして、データに最適なしきい値を確認します。
測定のユースケースでは、ユースケースに必要な精度を決定します。ST_SIMPLIFY 関数を使用する場合は、threshold_meters パラメータを必要な精度に設定します。都市以上のスケールで距離を測定する場合は、しきい値を 10 メートルに設定します。より小さいスケール(建物と最寄りの水域間の距離を測定する場合など)では、1 メートル以下の小さいしきい値の使用を検討してください。しきい値の値を小さくすると、指定したシェイプから削除されるポイントが少なくなります。
ウェブサービスからマップレイヤを提供する場合は、bigquery-geotools プロジェクトを使用して、さまざまなズームレベルのマテリアライズド ビューを事前計算できます。これは、BigQuery から空間レイヤを提供できる Geoserver のドライバです。このドライバは、異なる ST_SIMPLIFY しきい値パラメータを持つ複数のマテリアライズド ビューを作成するため、ズームレベルが高いほど詳細度が低くなります。
ポイントと長方形を使用する
ベスト プラクティス: シェイプをポイントまたは長方形に縮小して、その位置を表します。
シェイプを 1 つのポイントまたは長方形に縮小すると、クエリのパフォーマンスを向上させることができます。このセクションのメソッドは、シェイプの詳細と比率を正確に表現するものではなく、シェイプの位置を表現するように最適化されています。
シェイプの地理的な中心点(重心)を使用して、シェイプ全体の位置を表すことができます。シェイプを含む長方形を使用してシェイプの範囲を作成します。この範囲は、シェイプの位置を表すことや、相対サイズに関する情報を保持することのために使用できます。
2 つの都市間の距離など、2 点間の距離を測定する必要が生じた場合、ポイントと長方形を使用すると、データセットのコストとパフォーマンスを改善できます。
たとえば、米国の土地区画のデータベースを BigQuery テーブルに読み込み、最も近い水域を特定することを考えてみます。この場合、ST_CENTROID 関数と、このドキュメントのシェイプを単純化するセクションで説明する方法と組み合わせて、区画の重心を事前計算すると、ST_DISTANCE 関数または ST_DWITHIN 関数を使用するときに実行される比較回数を減らすことができます。ST_CENTROID 関数を使用する場合は、計算に区画の重心を考慮する必要があります。このように、区画の重心を事前計算することで、パフォーマンスの変動を抑えることもできます。これは、区画のシェイプによってポイント数が異なる可能性があるためです。
このメソッドのバリエーションとして、ST_CENTROID 関数ではなく ST_BOUNDINGBOX 関数を使用して、入力シェイプの周囲の長方形のエンベロープを計算する方法があります。単一ポイントを使用するほど効率的ではありませんが、特定のエッジケースの発生を減らすことができます。ST_BOUNDINGBOX 関数の出力には考慮すべきポイントが常に 4 つしか含まれないため、このバリアントは依然として一貫して優れたパフォーマンスを提供します。境界ボックスの結果は STRUCT 型になります。つまり、距離を手動で計算するか、このドキュメントの後半で説明するベクトル インデックス メソッドを使用する必要があります。
ハルを使用する
ベスト プラクティス: ハルを使用して、シェイプの位置を表現するように最適化します。
シェイプをシュリンク ラップし、そのシュリンク ラップの境界を計算すると、その境界はハルと呼ばれます。凸包では、結果として得られるシェイプのすべての角度が凸になります。シェイプの範囲と同様に、凸包は基になるシェイプの相対サイズと比率に関する情報を保持します。ただし、ハルを使用すると、後続の分析でより多くのポイントを保存して考慮する必要があるというデメリットがあります。
ST_CONVEXHULL 関数を使用すると、シェイプの位置を表現するために最適化できます。この関数を使用すると精度が向上しますが、パフォーマンスは低下します。ST_CONVEXHULL 関数は ST_EXTENT 関数と似ていますが、出力シェイプにはより多くのポイントが含まれ、入力シェイプの複雑さに基づいてポイント数が異なります。複雑でないシェイプの小規模なデータセットではパフォーマンスのメリットはほとんどありませんが、サイズが大きく複雑なシェイプの非常に大規模なデータセットでは、ST_CONVEXHULL 関数は費用、パフォーマンス、精度のバランスが取れています。
グリッド システムを使用する
ベスト プラクティス: 地理空間グリッド システムを使用して領域を比較します。
ユースケースで局所的な領域内でデータの集計を行い、領域の統計の集計値を他の領域と比較する場合は、標準化されたグリッド システムを使用してさまざまな領域を比較することをおすすめします。
たとえば、小売業者は、店舗がある領域や、新店舗の建設を検討している領域における、人口統計の変化を時系列で分析できます。また、保険会社は、特定の領域で発生している自然災害のリスクを分析することで、不動産リスクについてよく理解できます。
S2 や H3 などの標準グリッド システムを使用すると、このような統計集計と空間分析を高速化できます。また、これらのグリッド システムを使用すると、分析の開発を簡素化し、開発効率を高めることもできます。
たとえば、米国の国勢調査区を使用した比較ではサイズの不整合が発生します。つまり、国勢調査区間で同等の比較を行うには、修正因子を適用する必要があります。また、国勢調査区やその他の行政境界は時間の経過とともに変化するため、これらの変化に対応するための労力が必要になります。空間分析にグリッド システムを使用すると、このような課題に対処できます。
ベクトル検索とベクトル インデックスを使用する
ベスト プラクティス: 最近傍ジオ空間クエリには、ベクトル検索とベクトル インデックスを使用します。
ベクトル検索機能は BigQuery で導入され、セマンティック検索、類似性検出、取得による拡張生成などの ML のユースケースを実現します。これらのユースケースを実現するための鍵となるのが、近似最近傍探索と呼ばれるインデックス作成方法です。ベクトル検索を使用すると、空間内の点を表すベクトルを比較することで、最近傍の地理空間クエリを高速化および簡素化できます。
ベクトル検索を使用することで、半径で特徴を検索できます。まず、検索範囲を設定します。最適な半径は、最近傍検索の結果セットで確認できます。半径を設定したら、ST_DWITHIN 関数を使用して、近くの特徴を特定します。
たとえば、すでに位置情報を把握している特定のアンカービルに最も近い 10 件の建物を見つけるとします。各建物の重心をベクトルとして新しいテーブルに保存し、テーブルをインデックスに登録して、ベクトル検索を使用して検索できます。
この例では、BigQuery の Overture Maps データを使用して、対象エリアに対応する建物シェイプと geom_vector というベクトルの個別のテーブルを作成することもできます。この例では、米国バージニア州ノーフォーク市を対象としています。次のコードサンプルに示すように、FIPS コードは 51710 です。
CREATE TABLE vector_search.norfolk_buildings
AS (
SELECT
*,
[
ST_X(ST_CENTROID(building.geometry)),
ST_Y(ST_CENTROID(building.geometry))] AS geom_vector
FROM `bigquery-public-data.overture_maps.building` AS building
INNER JOIN `bigquery-public-data.geo_us_boundaries.counties` AS county
ON (st_intersects(county.county_geom, building.geometry))
WHERE county.county_fips_code = '51710'
)
次のコードサンプルでは、テーブルにベクトル インデックスを作成する方法を示します。
CREATE
vector index building_vector_index
ON
vector_search.norfolk_buildings(geom_vector)
OPTIONS (index_type = 'IVF')
このクエリは、特定のアンカー ビルディングに最も近い 10 件の建物を特定します。
SELECT base.*
FROM
VECTOR_SEARCH(
TABLE vector_search.norfolk_buildings,
'geom_vector',
(
SELECT
geom_vector
FROM
vector_search.norfolk_buildings
WHERE id = '56873794-9873-4fe1-871a-5987bb3a0efb'
),
top_k => 10,
distance_type => 'EUCLIDEAN',
options => '{"fraction_lists_to_search":0.1}')
[クエリ結果] ペインで、[可視化] タブをクリックします。アンカー ビルディングに最も近い一群の建物のシェイプが地図に表示されます。
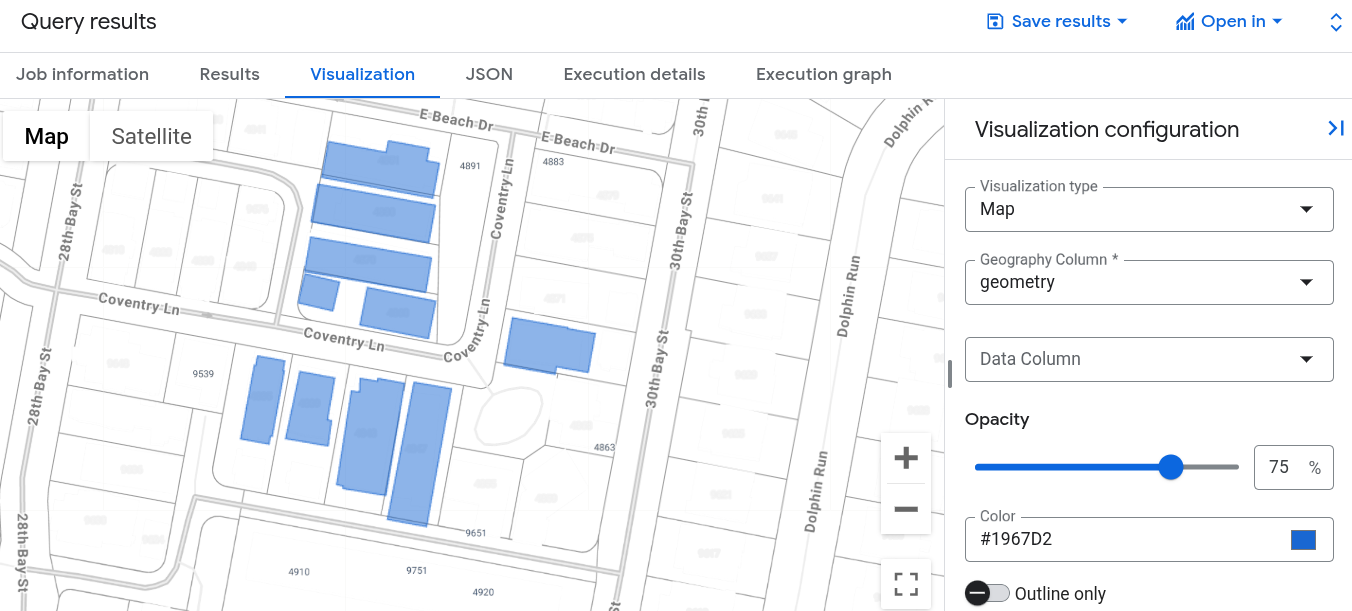
Google Cloud コンソールでこのクエリを実行する場合は、[ジョブ情報] をクリックして、[ベクトル インデックス使用モード] が FULLY_USED に設定されていることを確認します。これは、クエリが、先ほど作成した building_vector_index ベクトル インデックスを利用していることを示しています。
大規模なシェイプを分割する
ベスト プラクティス: 大規模なシェイプを ST_SUBDIVIDE 関数で分割します。
ST_SUBDIVIDE 関数を使用して、大規模なシェイプや長い行文字列を小さなシェイプに分割します。
次のステップ
- 空間分析用のグリッド システムの使用方法を確認する。
- 詳細については、BigQuery の地理関数をご覧ください。
- ベクトル インデックスを管理する方法を確認する。
- 詳細については、BigQuery での空間インデックス作成とクラスタリングに関するベスト プラクティスをご覧ください。
- BigQuery で地理空間データを分析して可視化する方法については、地理空間分析のスタートガイドをご覧ください。