Richten Sie eine Umgebung ein, bevor Sie einen Vertex AI Neural Architecture Search-Test starten.
Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
Aktualisieren Sie die gcloud CLI nach der Initialisierung und installieren Sie die erforderlichen Komponenten:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Führen Sie folgenden Befehl aus, um die gcloud CLI zu initialisieren:
gcloud init -
Aktualisieren Sie die gcloud CLI nach der Initialisierung und installieren Sie die erforderlichen Komponenten:
gcloud components update gcloud components install beta
- Wenn Sie allen Nutzern von Neural Architecture Search die Rolle Vertex AI-Nutzer (
roles/aiplatform.user) zuweisen möchten, wenden Sie sich an Ihren Projektadministrator. - Installieren Sie Docker.
Wenn Sie ein Linux-basiertes Betriebssystem wie Ubuntu oder Debian verwenden, fügen Sie der Gruppe
dockerIhren Nutzernamen hinzu, damit Sie Docker ohnesudoausführen können:sudo usermod -a -G docker ${USER}Möglicherweise müssen Sie Ihr System neu starten, wenn Sie sich zur Gruppe
dockerhinzugefügt haben. - Öffnen Sie Docker. Prüfen Sie, ob Docker ausgeführt wird, indem Sie den folgenden Docker-Befehl ausführen, der die aktuelle Zeit und das aktuelle Datum zurückgibt:
docker run busybox date
- Verwenden Sie
gcloudals Credential Helper für Docker:gcloud auth configure-docker
- (Optional) Wenn Sie den Container mit GPU lokal ausführen möchten, installieren Sie
nvidia-docker. -
Geben Sie einen Namen für den neuen Bucket an. Der Name muss sich von allen anderen Bucket-Namen in Cloud Storage unterscheiden:
BUCKET_NAME="YOUR_BUCKET_NAME"
Beispielsweise verwenden Sie den Projektnamen mit angehängtem
-vertexai-nas:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
Prüfen Sie den erstellten Bucketnamen.
echo $BUCKET_NAME
-
Wählen Sie eine Region für den Bucket aus und legen Sie eine Umgebungsvariable
REGIONfest.Verwenden Sie dieselbe Region, in der Sie auch Neural Architecture Search-Jobs ausführen möchten.
Mit dem folgenden Code wird beispielsweise
REGIONerstellt und dafürus-central1festgelegt:REGION=us-central1
-
Erstellen Sie den neuen Bucket:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- Wählen Sie für Dienst die Option Vertex AI API aus.
- Wählen Sie bei Region die Region aus, nach der Sie filtern möchten.
- Wählen Sie für Kontingent einen Beschleunigernamen aus, dessen Präfix Training von benutzerdefiniertem Modell lautet.
- Bei V100-GPUs lautet der Wert Training von benutzerdefiniertem Modell Nvidia V100-GPUs pro Region.
- Für CPUs kann der Wert Training von benutzerdefiniertem Modell CPUs für N1/E2-Maschinentypen pro Region sein. Die Zahl für CPU stellt die CPU-Einheit dar. Wenn Sie 8
highmem-16-CPUs wünschen, stellen Sie Ihre Kontingentanfrage für 8 * 16 = 128 CPU-Einheiten. Geben Sie außerdem den gewünschten Wert für die Region ein.
Richten Sie grundlegende Umgebungsvariablen ein:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginRichten Sie die Docker-Authentifizierung für Ihre Artefakt-Registry ein:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(Optional) Konfigurieren Sie eine virtuelle Python 3-Umgebung. Python 3 wird empfohlen, ist aber nicht erforderlich:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateInstallieren Sie weitere Bibliotheken:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0Erstellen Sie ein Dienstkonto:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEWeisen Sie dem Dienstkonto die Rollen
aiplatform.userundstorage.objectAdminzu:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdminÖffnen Sie ein neues Shell-Terminal.
Führen Sie den Git-Klonbefehl aus:
git clone https://github.com/google/vertex-ai-nas.git
Cloud Storage-Bucket einrichten
In diesem Abschnitt wird gezeigt, wie Sie einen neuen Bucket erstellen. Sie können auch einen vorhandenen Bucket verwenden. Dieser muss sich aber in der Region befinden, in der Sie AI Platform-Jobs ausführen. Wenn er nicht Teil des Projekts ist, das Sie zum Ausführen der neuronalen Architektursuche verwenden, müssen Sie den Dienstkonten für die neuronale Architektur explizit Zugriff gewähren.
Zusätzliche Gerätekontingente für das Projekt anfordern
Die Anleitungen verwenden etwa fünf CPU-Maschinen, für die keine zusätzlichen Kontingente erforderlich sind. Führen Sie nach der Ausführung der Anleitungen Ihren Neural Architecture Search-Job aus.
Der Neural Architecture Search-Job trainiert einen Batch von Modellen parallel. Jedes trainierte Modell entspricht einem Test.
Lesen Sie den Abschnitt zum Bestimmen von number-of-parallel-trials, um die Anzahl der CPUs und GPUs zu schätzen, die für einen Suchjob erforderlich sind.
Beispiel: Wenn für jeden Test zwei T4-GPUs verwendet werden und Sie number-of-parallel-trials auf 20 setzen, benötigen Sie insgesamt ein Kontingent von 40 T4-GPUs für einen Suchjob. Wenn jeder Test eine highmem-16-CPU verwendet, benötigen Sie außerdem 16 CPU-Einheiten pro Test, also 320 CPU-Einheiten für 20 parallele Tests.
Wir verlangen allerdings ein Minimumkontingent von 10 parallelen Tests (oder ein GPU-Kontingent von 20).
Das Standardkontingent für GPUs variiert je nach Region und GPU-Typ und beträgt normalerweise 0, 6 oder 12 für ein Tesla_T4 und 0 oder 6 für ein Tesla_V100. Das Standardkontingent für CPUs variiert je nach Region und liegt normalerweise bei 20, 450 oder 2.200.
Optional: Wenn Sie mehrere Suchjobs parallel ausführen möchten, skalieren Sie die Kontingentanforderung. Wenn Sie ein Kontingent anfordern, wird Ihnen dieses nicht sofort in Rechnung gestellt. Die Kosten werden nach dem Ausführen eines Jobs berechnet.
Wenn Sie kein ausreichendes Kontingent haben und einen Job starten möchten, der mehr Ressourcen als das Kontingent benötigt, gibt der Job keinen Fehler aus, der folgenden Elementen ähnelt:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
Wenn mehrere Jobs für dasselbe Projekt gleichzeitig gestartet wurden und das Kontingent nicht für alle ausreicht, wird in einigen Fällen ein Job in der Warteschlange gehalten und nicht trainiert. Brechen Sie in diesem Fall den Job in der Warteschlange ab und fordern Sie entweder ein höheres Kontingent an oder warten Sie, bis der vorherige Job abgeschlossen ist.
Anschließend können Sie auf der Seite Kontingente das zusätzliche Gerätekontingent anfordern.
Sie können Filter anwenden, um das zu bearbeitende Kontingent zu finden: 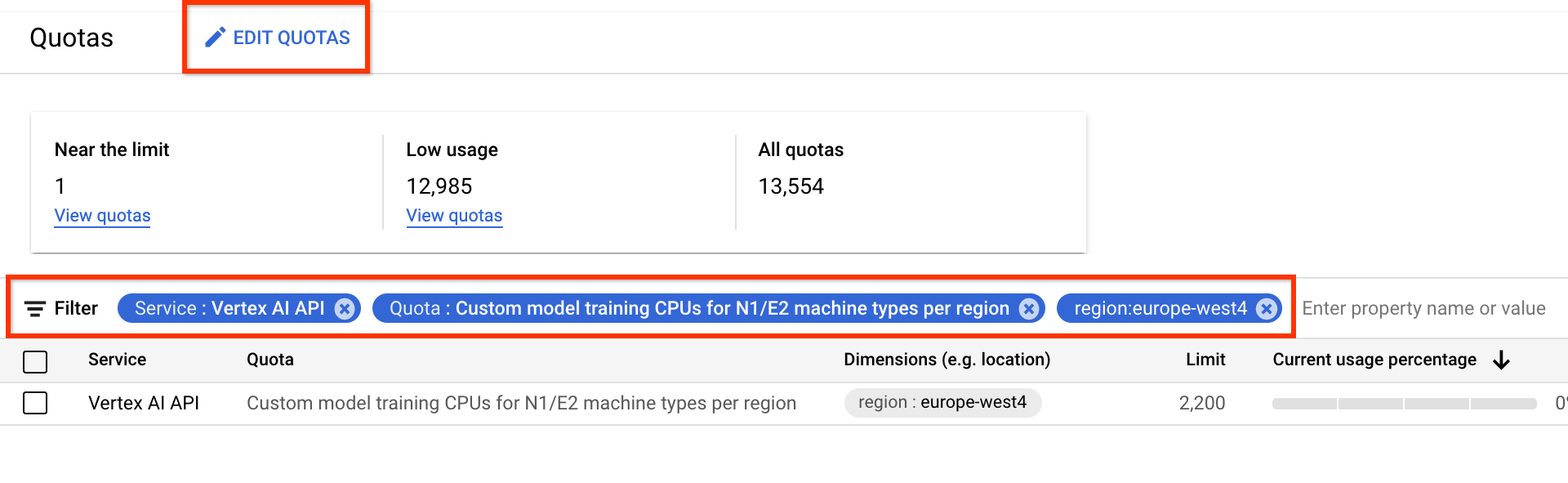
Nachdem Sie eine Kontingentanfrage erstellt haben, erhalten Sie eine Case number und darauf aufbauende E-Mails zum Status der Anfrage. Die Genehmigung eines GPU-Kontingents kann etwa zwei bis fünf Werktage dauern. Im Allgemeinen sollte ein Kontingent von etwa 20–30 GPUs in etwa zwei bis drei Tagen genehmigt werden. Die Genehmigung von ca. 100 GPUs kann fünf Werktage dauern. Die Genehmigung eines CPU-Kontingents kann bis zu zwei Werktage dauern.
Wenn jedoch in einer Region ein großer Mangel an GPU-Typ auftritt, gibt es auch bei einer kleinen Kontingentanfrage keine Garantie.
In diesem Fall werden Sie möglicherweise aufgefordert, eine andere Region oder einen anderen GPU-Typ zu verwenden. Im Allgemeinen sind T4-GPUs leichter zu erhalten als V100-GPUs. T4-GPUs benötigen mehr Zeit, sind jedoch kostengünstiger.
Weitere Informationen finden Sie unter Kontingentanpassung anfordern.
Artifact Registry für Ihr Projekt einrichten
Sie müssen eine Artefakt-Registry für Ihr Projekt und Ihre Region einrichten, in die Sie Ihre Docker-Images übertragen.
Rufen Sie die Seite Artifact Registry für Ihr Projekt auf. Aktivieren Sie die Artifact Registry API für Ihr Projekt, falls noch nicht geschehen:
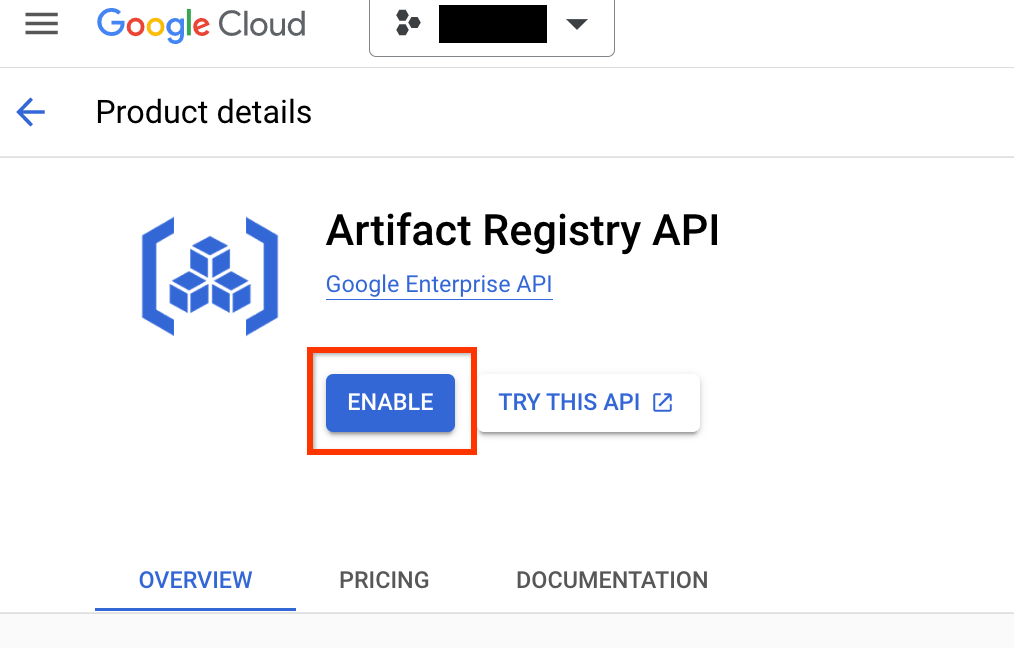
Nach der Aktivierung beginnen Sie mit der Erstellung eines neuen Repositorys durch Klicken auf REPOSITORY ERSTELLEN:
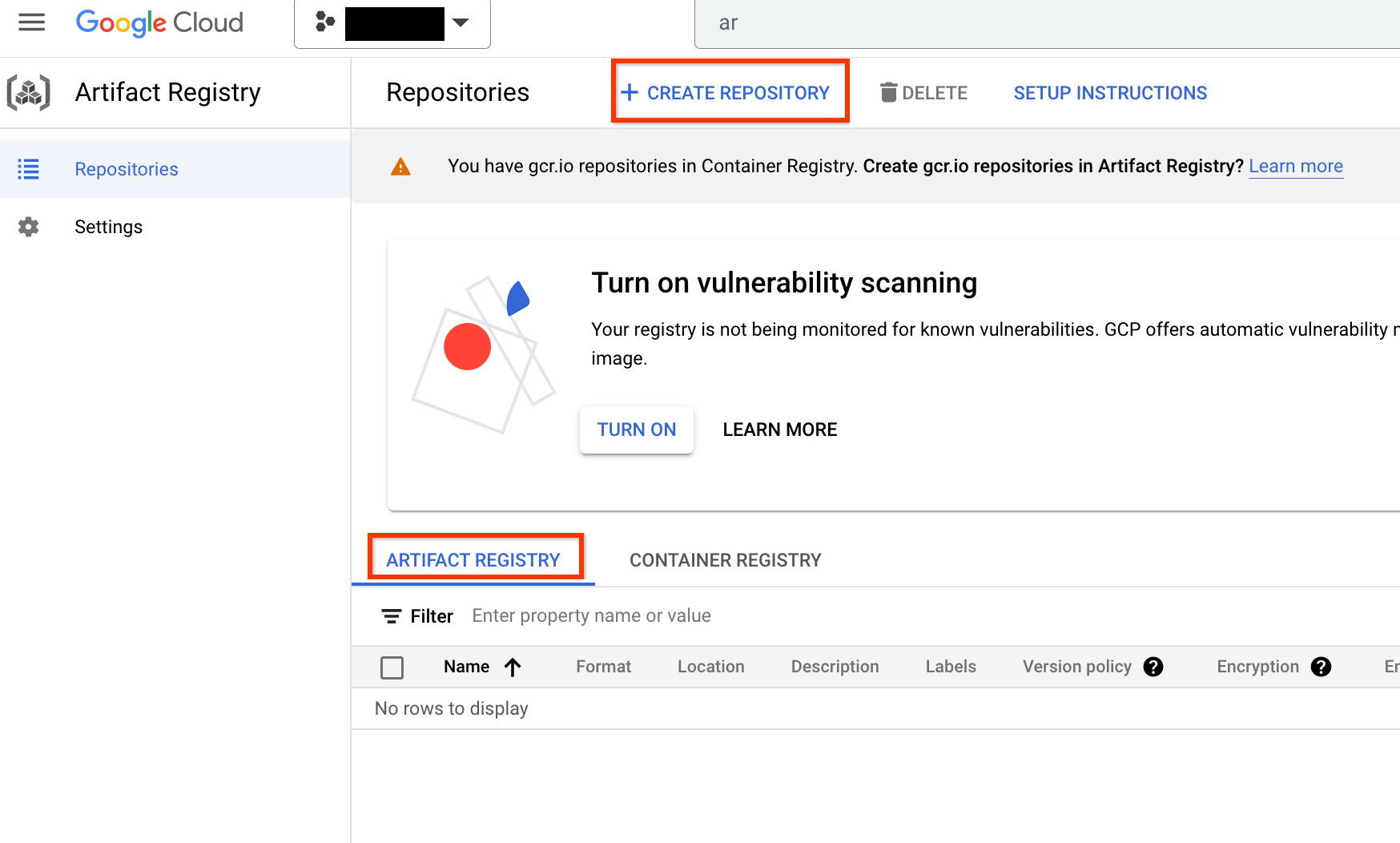
Wählen Sie Name als nas, Format als Docker und Standorttyp als Region. Wählen Sie unter Region den Speicherort aus, an dem Sie Ihre Jobs ausführen möchten, und klicken Sie dann auf ERSTELLEN.
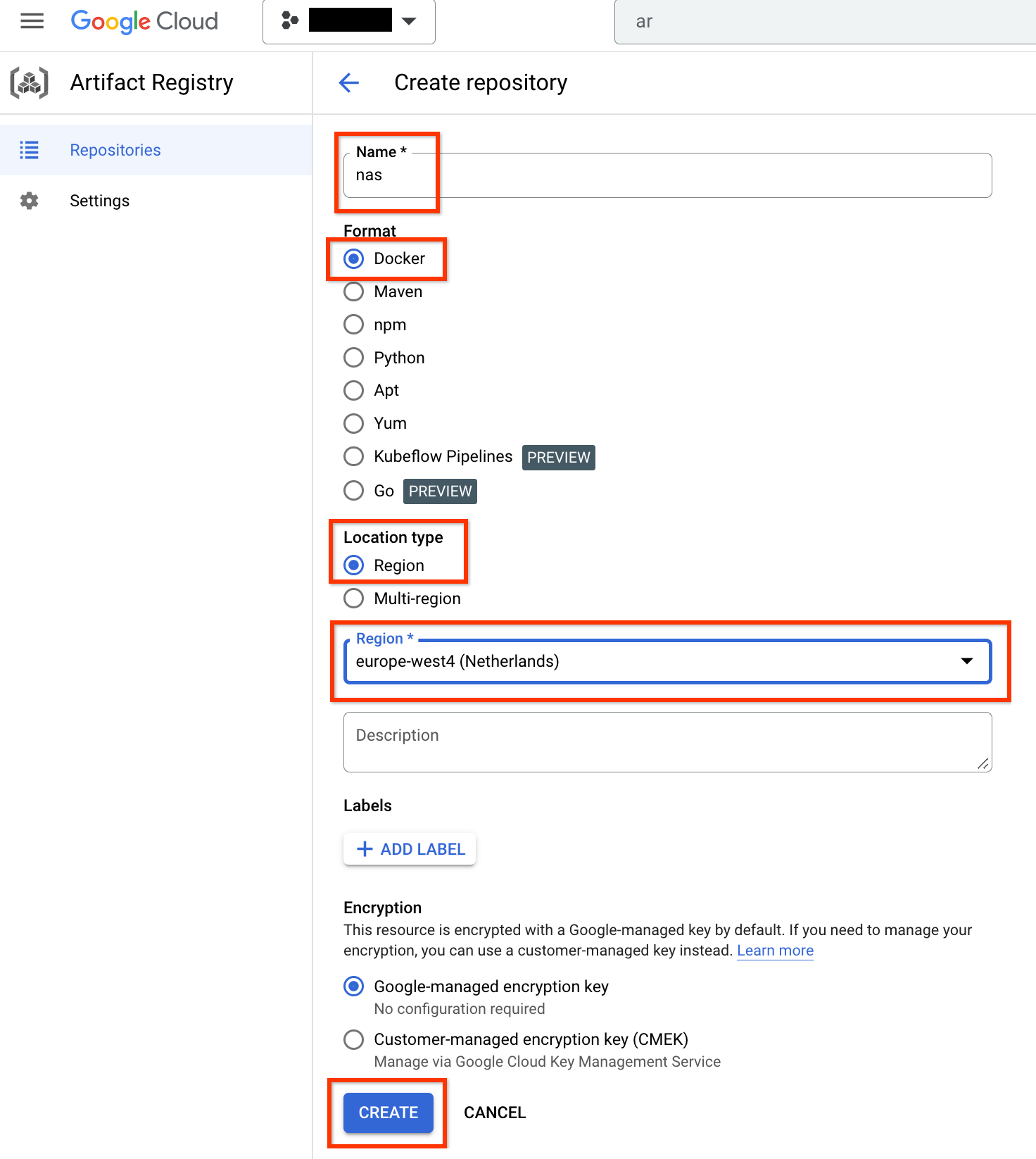
So sollte das gewünschte Docker-Repository wie unten dargestellt erstellt werden:
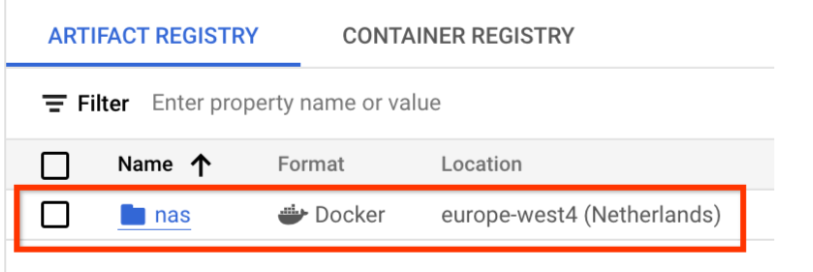
Sie müssen auch die Authentifizierung einrichten, um Docker in dieses Repository zu übertragen. Der folgende Abschnitt, Einrichtung der lokalen Umgebung, enthält diesen Schritt.
Lokale Umgebung einrichten
Sie können diese Schritte mit der Bash-Shell in Ihrer lokalen Umgebung ausführen oder in einem Notebook in einer Vertex AI Workbench-Instanz.
Dienstkonto einrichten
Sie müssen ein Dienstkonto einrichten, bevor Sie NAS-Jobs ausführen können. Sie können diese Schritte mit der Bash-Shell in Ihrer lokalen Umgebung ausführen oder in einem Notebook in einer Vertex AI Workbench-Instanz.
Beispiel: Mit folgenden Befehlen wird ein Dienstkonto mit dem Namen my-nas-sa unter dem Projekt my-nas-project mit den Rollen aiplatform.user und storage.objectAdmin erstellt:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
Code herunterladen
Zum Starten eines Neural Architecture Search-Tests müssen Sie den Python-Beispielcode herunterladen. Dieser enthält vordefinierte Trainer, Suchbereichsdefinitionen und die zugehörigen Clientbibliotheken.
Führen Sie folgende Schritte aus, um den Quellcode herunterzuladen.