Wenn Sie die Anleitungen bereits ausgeführt haben, werden auf dieser Seite die Best Practices für die Suche in der Neural Architecture Search beschrieben. Der erste Abschnitt fasst einen vollständigen Workflow zusammen, den Sie für Ihren Job in der Neural Architecture Search ausführen können. Die anderen Abschnitte enthalten detaillierte Beschreibungen der einzelnen Schritte. Wir empfehlen dringend, die gesamte Seite zu lesen, bevor Sie den ersten Neural Architecture Search-Job ausführen.
Vorgeschlagener Workflow
Hier finden Sie einen vorgeschlagenen Workflow für die Neural Architecture Search und Links zu den entsprechenden Abschnitten für weitere Informationen:
- Aufteilen des Trainings-Datasets für die Stage-1-Suche.
- Achten Sie darauf, dass Ihr Suchbereich unseren Richtlinien entspricht.
- Führen Sie ein vollständiges Training mit Ihrem Basismodell aus und rufen Sie eine Validierungskurve ab.
- Führen Sie die Proxy-Task-Design-Tools aus, um die beste Proxyaufgabe zu finden.
- Führen Sie finale Prüfungen für Ihre Proxyaufgabe durch.
- Legen Sie eine geeignete Anzahl von Gesamttests und parallelen Tests fest und starten Sie die Suche.
- Überwachen Sie das Suchdiagramm und beenden Sie es, wenn es konvergiert oder eine große Anzahl von Fehlern oder kein Vorhandensein von Konvergenzen angezeigt wird.
- Führen Sie ein vollständiges Training mit den Top-10-Tests aus, die Sie bei der Suche für das Endergebnis ausgewählt haben. Für das vollständige Training können Sie mehr Erweiterung oder vortrainierte Gewichtungen verwenden, um die bestmögliche Leistung zu erzielen.
- Analysieren Sie die gespeicherten Messwerte/Daten aus der Suche und ziehen Sie Schlussfolgerungen für zukünftige Iterationen des Suchbereichs.
Typische Neural Architecture Search

Die obige Abbildung zeigt eine typische Kurve der Neural Architecture Search.
Y-axis zeigt hier die Testversionen und X-axis zeigt die Anzahl der bisher gestarteten Tests.
Die ersten ca. 100 bis 200 Tests sind hauptsächlich zufällige Untersuchungen des Suchbereichs durch den Controller.
Während der ersten Erkundungen zeigen sich in den Prämien große Unterschiede, da viele Arten von Modellen im Suchbereich getestet werden.
Wenn die Anzahl der Tests zunimmt, beginnt der Controller mit der Suche nach besseren Modellen. Daher erhöht sich die Prämie zuerst und später nimmt die Varianz der Prämie und das Prämienwachstum ab, sodass Konvergenz angezeigt wird. Die Anzahl der Tests, bei denen die Konvergenz auftritt, kann je nach Größe des Suchbereichs variieren. In der Regel beträgt die Anzahl der Tests jedoch in der Größenordnung von 2.000 Tests.
Zwei Phasen der Neural Architecture Search: Proxyaufgabe und vollständiges Training
Die Neural Architecture Search funktioniert in zwei Phasen:
Stage1-Search verwendet eine viel kleinere Darstellung des vollständigen Trainings, die normalerweise innerhalb von etwa 1 bis 2 Stunden abgeschlossen ist. Diese Darstellung wird als Proxyaufgabe bezeichnet und hilft, die Suchkosten niedrig zu halten.
Stage2-full-training umfasst ein vollständiges Training für die Top-10-Bewertungsmodelle von stage1-search. Aufgrund des stochastischen Charakters der Suche kann es sein, dass das beste Modell aus stage1-search nicht das beste Modell während des stage2-full-training ist. Daher ist es wichtig, einen Pool von Modellen für das vollständige Training auszuwählen.
Da der Controller das Prämiensignal von der kleineren Proxyaufgabe und nicht vom vollständigen Training erhält, ist es wichtig, eine optimale Proxyaufgabe für Ihre Aufgabe zu finden.
Kosten für die Neural Architecture Search
Die Kosten für die Neural Architecture Search ergeben sich aus search-cost = num-trials-to-converge * avg-proxy-task-cost.
Angenommen, die Rechenzeit der Proxyaufgabe beträgt etwa 1/30 der vollständigen Trainingszeit und die Anzahl der benötigten Konvergenzen beträgt ca. 2.000. Die Suchkosten belaufen sich dann auf ~ 67 * full-training-cost.
Da die Kosten für die Neural Architecture Search hoch sind, ist es empfehlenswert, sich auf die Feinabstimmung Ihrer Proxyaufgabe zu konzentrieren und für Ihre erste Suche einen kleineren Suchbereich zu verwenden.
Dataset-Aufteilung zwischen zwei Phasen der Neural Architecture Search
Angenommen, Sie verfügen bereits über die Trainingsdaten und die Validierungsdaten für Ihr Baseline-Training, dann wird die folgende Aufteilung des Datasets für die beiden Phasen der NAS Neural Architecture Search empfohlen:
- Stage1-search-Training: ca. 90 % der Trainingsdaten
Stage1-search-Validierung: ca. 10 % der Trainingsdaten
Stage2-full-training-Training: 100 % der Trainingsdaten
Stage2-full-training-Training: 100 % der Validierungsdaten
Die Aufteilung der Daten für das stage2-full-Training ist dieselbe wie für das reguläre Training. In stage1-search wird jedoch eine Aufteilung der Trainingsdaten für die Validierung verwendet. Die Verwendung verschiedener Validierungsdaten in stage1 und stage2 hilft bei der Erkennung von Verzerrungen der Modellsuche aufgrund der Dataset-Aufteilung. Achten Sie darauf, dass die Trainingsdaten gut gemixt werden, bevor sie weiter aufgeteilt werden, und dass die endgültige 10%ige Aufteilung der Trainingsdaten eine ähnliche Verteilung wie die ursprünglichen Validierungsdaten aufweist.
Kleine oder unausgeglichene Daten
Die Architektursuche wird für begrenzte Trainingsdaten oder für sehr unausgewogene Datasets nicht empfohlen, bei denen einige Klassen sehr selten sind. Wenn Sie aufgrund fehlender Daten bereits starke Erweiterungen für Ihr Basistraining verwenden, wird die Modellsuche nicht empfohlen.
In diesem Fall können Sie nur die Erweiterungssuche nutzen, um nach der besten Erweiterungsrichtlinie anstatt nach einer optimalen Architektur zu suchen.
Design des Suchbereichs
Die Architektursuche sollte nicht mit der Erweiterungssuche oder der Hyperparametersuche (z. B. Einstellungen für Lernrate oder Optimierungstool) kombiniert werden. Das Ziel der Architektursuche ist es, die Leistung von Modell A mit Modell B zu vergleichen, wenn nur architekturbasierte Unterschiede vorhanden sind. Daher sollten die Erweiterungseinstellungen und die Hyperparameter-Einstellungen gleich bleiben.
Die Erweiterungssuche kann als weitere Phase ausgeführt werden, nachdem die Architektursuche abgeschlossen wurde.
Die Neural Architecture Search kann in Sachen Suchbereichgröße bis zu 10^20 erreichen. Ist Ihr Suchbereich jedoch größer, können Sie ihn in sich gegenseitig ausschließende Teile aufteilen. Sie können z. B. zuerst nach dem Encoder getrennt vom Decoder oder nach dem Kopf suchen. Wenn Sie immer noch eine gemeinsame Suche ausführen möchten, können Sie einen kleineren Suchraum um die zuvor gefundenen besten Einzeloptionen erstellen.
Optional: Sie können die Modellskalierung vom Blockdesign trennen, wenn Sie einen Suchbereich entwerfen. Die Blockdesign-Suche sollte zuerst mit einem herunterskalierten Modell erfolgen. Dies kann die Kosten für die Proxy-Aufgabenlaufzeit erheblich senken. Sie können dann eine separate Suche auszuführen, um das Modell zu skalieren. Weitere Informationen finden Sie unter
Examples of scaled down models.
Training und Suchzeit optimieren
Bevor Sie die Suche in der Neural Architecture Search ausführen, ist es wichtig, die Trainingszeit für Ihr Basismodell zu optimieren. Dies spart Ihnen langfristig Kosten. Hier finden Sie einige Optionen zur Optimierung des Trainings:
- Maximale Ladegeschwindigkeit für Daten:
- Achten Sie darauf, dass sich der Bucket, in dem sich Ihre Daten befinden, in derselben Region wie Ihr Job befindet.
- Informationen zur Verwendung von TensorFlow finden Sie unter
Best practice summary. Sie können auch das TFRecord-Format für Ihre Daten verwenden. - Wenn Sie PyTorch verwenden, beachten Sie die Richtlinien für ein effizientes PyTorch-Training.
- Mit verteiltem Training können Sie mehrere Beschleuniger oder mehrere Maschinen nutzen.
- Verwenden Sie Training mit gemischter Genauigkeit, um eine erhebliche Trainingsgeschwindigkeit und -reduzierung zu erhalten.
Informationen zum Training mit gemischter Genauigkeit mit TensorFlow finden Sie unter
Mixed Precision. - Einige Beschleuniger (wie A100) sind in der Regel kostengünstiger.
- Passen Sie die Batchgröße an, um die GPU-Auslastung zu maximieren.
Das folgende Diagramm zeigt eine Unterauslastung von GPUs (bei 50 %).
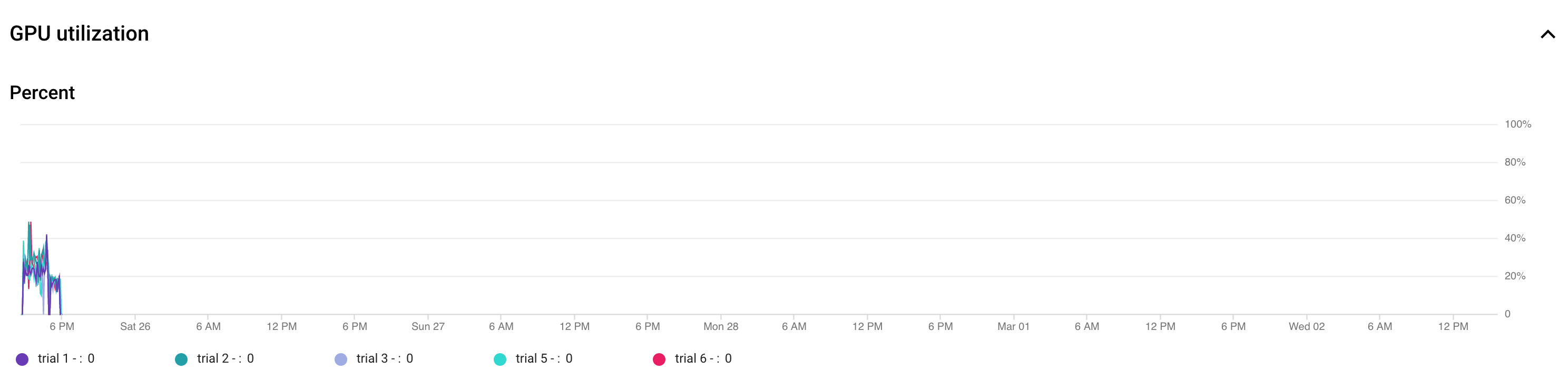 Durch Erhöhung der Batchgröße können GPUs stärker genutzt werden. Sie sollten die Batchgröße jedoch sorgsam erhöhen, da dies die Fehler aufgrund fehlenden Speichers während der Suche erhöhen kann.
Durch Erhöhung der Batchgröße können GPUs stärker genutzt werden. Sie sollten die Batchgröße jedoch sorgsam erhöhen, da dies die Fehler aufgrund fehlenden Speichers während der Suche erhöhen kann. - Wenn bestimmte Architekturblöcke unabhängig vom Suchbereich sind, können Sie versuchen, für diese Bereitstellungen vortrainierte Checkpoints zu laden. Die vortrainierten Prüfpunkte sollten im Suchbereich gleich sein und keine Verzerrung verursachen. Wenn Ihr Suchbereich beispielsweise nur für den Decoder bestimmt ist, kann der Encoder vortrainierte Checkpoints verwenden.
Anzahl der GPUs für jeden Suchtest
Verwenden Sie eine geringere Anzahl von GPUs pro Test, um die Startzeit zu verkürzen. So starten zum Beispiel 2 GPUs 5 Minuten lang, 8 GPUs 20 Minuten. Es ist effizienter, zwei GPUs pro Test zu verwenden, um eine Neural Architecture Search-Jobproxyaufgabe auszuführen.
Gesamtzahl der Tests und parallelen Tests für die Suche
Gesamte Testeinstellungen
Nachdem Sie die beste Proxyaufgabe gesucht und ausgewählt haben, können Sie eine vollständige Suche starten. Es lässt sich nicht im Voraus wissen, wie viele Tests es dauern wird, um zu konvergieren. Die Zahl der Tests, bei denen die Konvergenz auftritt, kann je nach Größe des Suchbereichs variieren. In der Regel liegt diese Zahl jedoch bei etwa 2.000 Tests.
Wir empfehlen eine sehr hohe Einstellung für --max_nas_trial – ca. 5.000 bis 10.000. Brechen Sie den Suchjob vorzeitig ab, wenn das Suchdiagramm Konvergenz zeigt.
Sie haben auch die Möglichkeit, einen vorherigen Suchjob mit dem Befehl search_resume fortzusetzen.
Sie können jedoch die Suche aus einem anderen Job zur Fortsetzung der Suche nicht fortsetzen.
Daher können Sie einen ursprünglichen Suchauftrag nur einmal fortsetzen.
Einstellung für parallele Tests
Der stage1-Suchjob führt die Batchverarbeitung aus. Dazu werden --max_parallel_nas_trial Tests gleichzeitig ausgeführt. Dies ist entscheidend, um die Gesamtlaufzeit des Suchjobs zu reduzieren. Sie können die erwartete Anzahl an Tagen für die Suche berechnen:days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Hinweis: Sie können zuerst 3000 als grobe Schätzung für trials-to-converge verwenden. Dies ist eine gute anfängliche Obergrenze. Sie können zuerst 2 Stunden als grobe Schätzung für den avg-trial-duration-in-hours verwenden. Dies ist eine gute Obergrenze für die Zeit, die einzelne Proxyaufgaben benötigen.
Es empfiehlt sich, eine --max_parallel_nas_trial-Einstellung von 20 bis 50 zu verwenden, basierend auf dem Accelerator-Kontingent Ihres Projekts und auf days-required-for-search.
Beispiel: Wenn Sie --max_parallel_nas_trial auf 20 festlegen und jede Proxyaufgabe zwei NVIDIA T4-GPUs verwendet, sollten Sie ein Kontingent von mindestens 40 NVIDIA T4-GPUs reserviert haben. Die Einstellung für --max_parallel_nas_trial wirkt sich nicht auf das Gesamtergebnis der Suche aus, aber auf die days-required-for-search.
Eine kleinere Einstellung für max_parallel_nas_trial, z. B. ca. 10, ist ebenfalls möglich (20 GPUs). Dann sollten Sie aber die days-required-for-search ungefähr abschätzen und darauf achten, dass sie innerhalb des Job-Zeitlimits liegt.
Der stage2-full-Trainingsjob trainiert in der Regel standardmäßig alle Tests parallel. In der Regel sind das die zehn besten Tests, die parallel ausgeführt werden. Wenn jedoch jeder stage2-full-Training-Test zu viele GPUs (z. B. acht GPUs) für Ihren Anwendungsfall verwendet und Sie kein ausreichendes Kontingent haben, können Sie stage2-Jobs manuell in Batches ausführen. Sie können z. B. zuerst ein stage2-full-Training für nur fünf Tests und dann ein weiteres stage2-full-Training für die nächsten fünf Tests ausführen.
Standardjob-Zeitlimit
Das standardmäßige NAS-Job-Zeitlimit ist auf 14 Tage festgelegt. Danach wird der Job abgebrochen. Wenn Sie davon ausgehen, dass der Job länger ausgeführt werden muss, können Sie den Suchjob beispielsweise einmal für 14 Tage fortsetzen. Insgesamt können Sie einen Suchjob 28 Tage lang ausführen, einschließlich der Fortsetzung.
Einstellung für maximale Anzahl fehlgeschlagener Tests
Die maximale Anzahl fehlgeschlagener Tests sollte auf etwa ein Drittel der max_nas_trial-Einstellung festgelegt werden. Der Job wird abgebrochen, wenn die Anzahl der fehlgeschlagenen Tests dieses Limit erreicht.
Wann sollte die Suche beendet werden?
Sie sollten die Suche in folgenden Fällen beenden:
Die Suchkurve beginnt zu konvergieren (die Varianz nimmt ab):
Hinweis: Wenn keine Latenzbeschränkung verwendet wird oder die harte Latenzbeschränkung mit einem losen Latenzlimit verwendet wird, zeigt die Kurve möglicherweise keinen Anstieg der Prämie, sollte aber dennoch eine Konvergenz haben. Dies liegt daran, dass der Controller möglicherweise schon frühzeitig eine hohe Genauigkeit gesehen hat.Mehr als 20 % der Tests enthalten ungültige Prämien (Fehler):
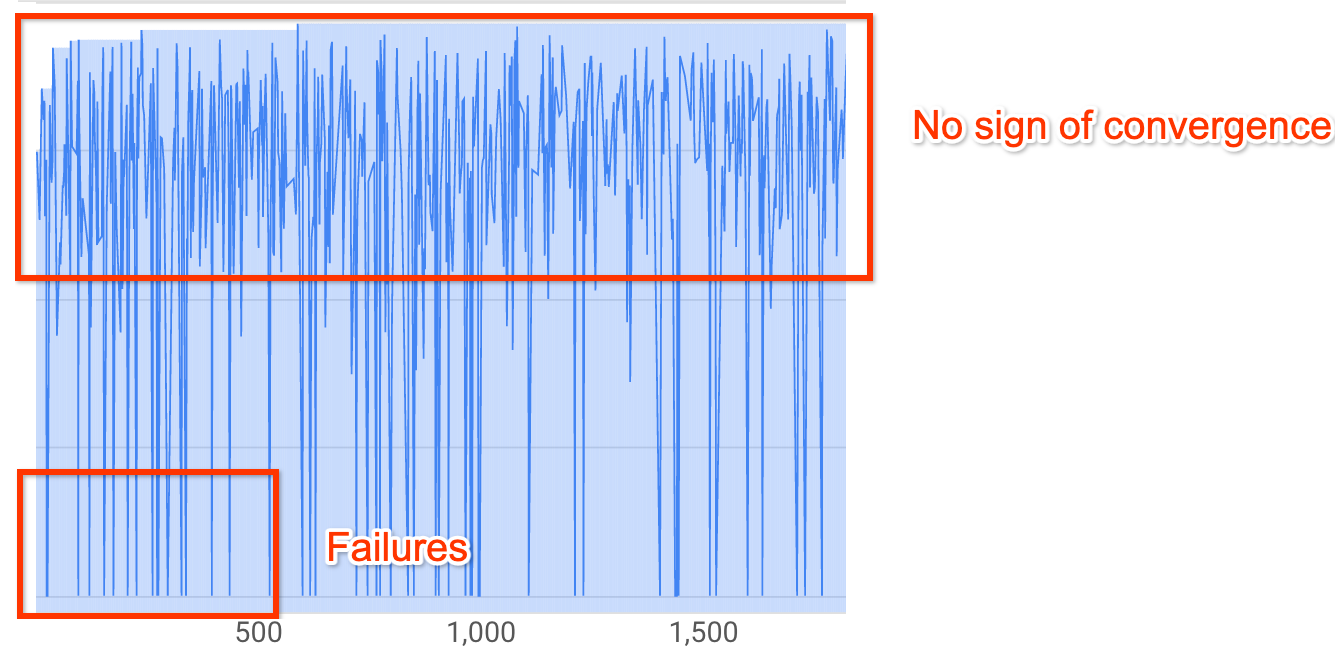
Die Suchkurve steigt auch nach ~500 Tests weder an noch konvergiert sie (wie oben gezeigt). Wenn sie eine Erhöhung der Prämie oder eine Verringerung der Varianz anzeigt, können Sie fortfahren.