Tabular Workflows is a set of integrated, fully managed, and scalable pipelines for end-to-end ML with tabular data. It leverages Google's technology for model development and provides you with customization options to fit your needs.
Benefits
- Fully managed: you don't need to worry about updates, dependencies and conflicts.
- Easy to scale: you don't need to re-engineer infrastructure as workloads or datasets grow.
- Optimized for performance: the right hardware is automatically configured for the workflow's requirements.
- Deeply integrated: compatibility with products in the Vertex AI MLOps suite, like Vertex AI Pipelines and Vertex AI Experiments, lets you run many experiments in a short amount of time.
Technical Overview
Each workflow is a managed instance of Vertex AI Pipelines.
Vertex AI Pipelines is a serverless service that runs Kubeflow pipelines. You can use pipelines to automate and monitor your machine learning and data preparation tasks. Each step in a pipeline performs part of the pipeline's workflow. For example, a pipeline can include steps to split data, transform data types, and train a model. Since steps are instances of pipeline components, steps have inputs, outputs, and a container image. Step inputs can be set from the pipeline's inputs or they can depend on the output of other steps within this pipeline. These dependencies define the pipeline's workflow as a directed acyclic graph.
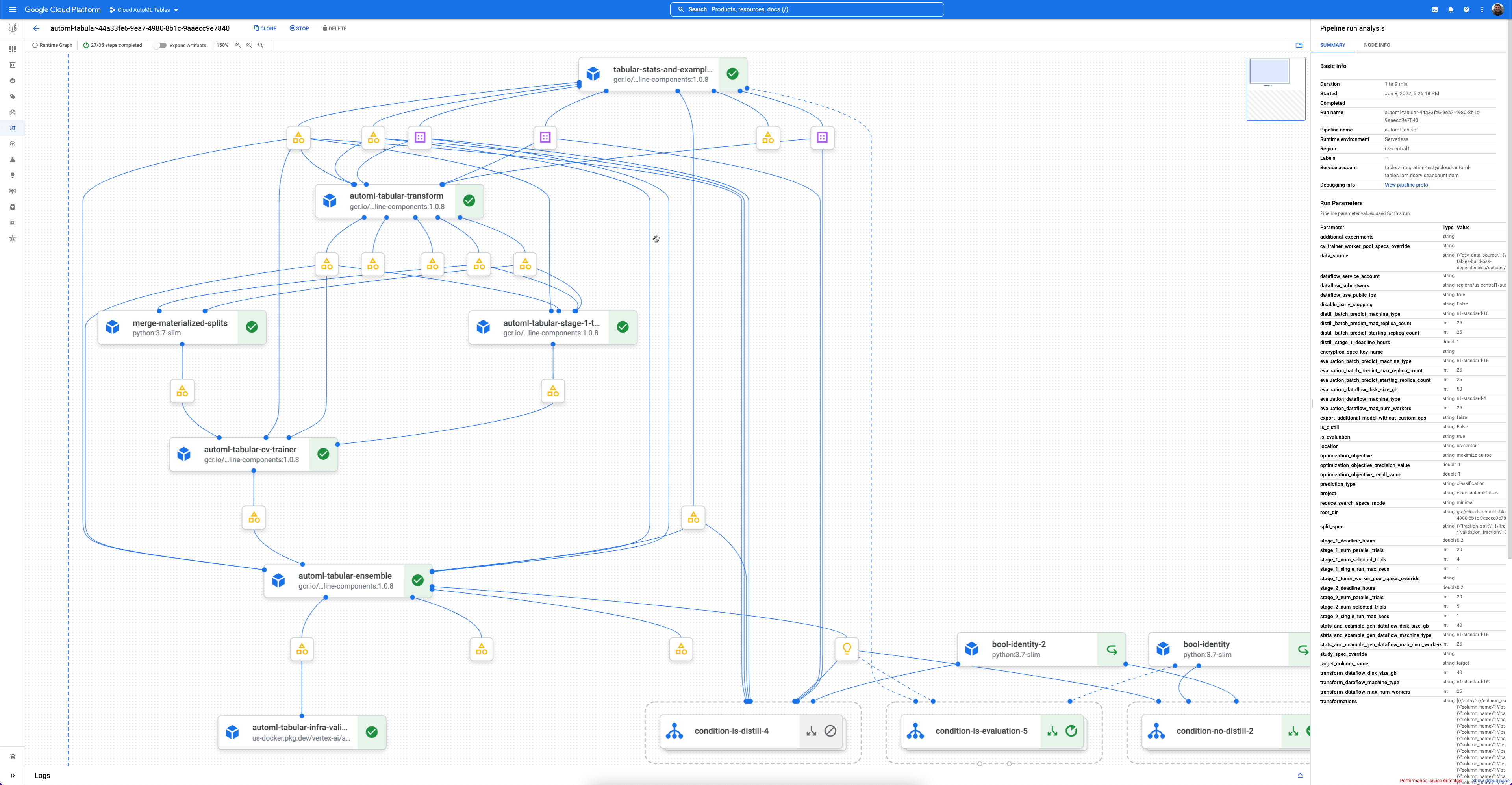
Get started
In most cases, define and run the pipeline using the Google Cloud Pipeline Components SDK. The following sample code illustrates this process. Note that the actual implementation of the code might differ.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
For sample colabs and notebooks, contact your sales representative or fill out a request form.
Versioning and maintenance
Tabular Workflows have an effective versioning system that allows for continuous updates and improvements without breaking changes to your applications.
Each workflow is releases and updated as part of the Google Cloud Pipeline Components SDK. Updates and modifications to any workflow are released as new versions of that workflow. Previous versions of every workflow are always available through the older versions of the SDK. If the SDK version is pinned, the workflow version is also pinned.
Available workflows
Vertex AI provides the following Tabular Workflows:
| Name | Type | Availability |
|---|---|---|
| Feature Transform Engine | Feature Engineering | Public Preview |
| End-to-End AutoML | Classification & Regression | Generally Available |
| TabNet | Classification & Regression | Public Preview |
| Wide & Deep | Classification & Regression | Public Preview |
| Forecasting | Forecasting | Public Preview |
For additional information and sample notebooks, contact your sales representative or fill out a request form.
Feature Transform Engine
Feature Transform Engine performs feature selection and feature transformations. If feature selection is enabled, Feature Transform Engine creates a ranked set of important features. If feature transformations are enabled, Feature Transform Engine processes the features to ensure that the input for model training and model serving is consistent. Feature Transform Engine can be used on its own or together with any of the tabular training workflows. It supports both TensorFlow and non-TensorFlow frameworks.
For more information, see Feature engineering.
Tabular Workflows for classification and regression
Tabular Workflow for End-to-End AutoML
Tabular Workflow for End-to-End AutoML is a complete AutoML pipeline for classification and regression tasks. It is similar to the AutoML API, but allows you to choose what to control and what to automate. Instead of having controls for the whole pipeline, you have controls for every step in the pipeline. These pipeline controls include:
- Data splitting
- Feature engineering
- Architecture search
- Model training
- Model ensembling
- Model distillation
Benefits
- Supports large datasets that are multiple TB in size and have up to 1000 columns.
- Allows you to improve stability and lower training time by limiting the search space of architecture types or skipping architecture search.
- Allows you to improve training speed by manually selecting the hardware used for training and architecture search.
- Allows you to reduce model size and improve latency with distillation or by changing the ensemble size.
- Each AutoML component can be inspected in a powerful pipelines graph interface that lets you see the transformed data tables, evaluated model architectures, and many more details.
- Each AutoML component gets extended flexibility and transparency, such as being able to customize parameters, hardware, view process status, logs, and more.
Input-Output
- Takes a BigQuery table or a CSV file from Cloud Storage as input.
- Produces a Vertex AI model as output.
- Intermediate outputs include dataset statistics and dataset splits.
For more information, see Tabular Workflow for End-to-End AutoML.
Tabular Workflow for TabNet
Tabular Workflow for TabNet is a pipeline that you can use to train classification or regression models. TabNet uses sequential attention to choose which features to reason from at each decision step. This promotes interpretability and more efficient learning because the learning capacity is used for the most salient features.
Benefits
- Automatically selects the appropriate hyperparameter search space based on the dataset size, inference type, and training budget.
- Integrated with Vertex AI. The trained model is a Vertex AI model. You can run batch inferences or deploy the model for online inferences right away.
- Provides inherent model interpretability. You can get insight into which features TabNet used to make its decision.
- Supports GPU training.
Input-Output
Takes a BigQuery table or a CSV file from Cloud Storage as input and provides a Vertex AI model as output.
For more information, see Tabular Workflow for TabNet.
Tabular Workflow for Wide & Deep
Tabular Workflow for Wide & Deep is a pipeline that you can use to train classification or regression models. Wide & Deep jointly trains wide linear models and deep neural networks. It combines the benefits of memorization and generalization. In some online experiments, the results showed that Wide & Deep significantly increased Google store application acquisitions compared with wide-only and deep-only models.
Benefits
- Integrated with Vertex AI. The trained model is a Vertex AI model. You can run batch inferences or deploy the model for online inferences right away.
Input-Output
Takes a BigQuery table or a CSV file from Cloud Storage as input and provides a Vertex AI model as output.
For more information, see Tabular Workflow for Wide & Deep.
Tabular Workflows for forecasting
Tabular Workflow for Forecasting
Tabular Workflow for Forecasting is the complete pipeline for forecasting tasks. It is similar to the AutoML API, but lets you to choose what to control and what to automate. Instead of having controls for the whole pipeline, you have controls for every step in the pipeline. These pipeline controls include:
- Data splitting
- Feature engineering
- Architecture search
- Model training
- Model ensembling
Benefits
- Supports large datasets that are up to 1TB in size and have up to 200 columns.
- Lets you improve stability and lower training time by limiting the search space of architecture types or skipping architecture search.
- Lets you improve training speed by manually selecting the hardware used for training and architecture search.
- Lets you reduce model size and improve latency by changing the ensemble size.
- Each component can be inspected in a powerful pipelines graph interface that lets you see the transformed data tables, evaluated model architectures and many more details.
- Each component gets extended flexibility and transparency, such as being able to customize parameters, hardware, view process status, logs and more.
Input-Output
- Takes a BigQuery table or a CSV file from Cloud Storage as input.
- Produces a Vertex AI model as output.
- Intermediate outputs include dataset statistics and dataset splits.
For more information, see Tabular Workflow for Forecasting.
What's next
- Learn about Tabular Workflow for End-to-End AutoML.
- Learn about Tabular Workflow for TabNet.
- Learn about Tabular Workflow for Wide & Deep.
- Learn about Tabular Workflow for Forecasting.
- Learn about Feature engineering.
- Learn about Pricing for Tabular Workflows.