CustomTrainingJob.
When you create a CustomTrainingJob, you define a training pipeline in the
background. Vertex AI uses the training pipeline and the code in your
Python training script to train and create your model. For more information, see
Create training pipelines.
Define your training pipeline
To create a training pipeline, you create a CustomTrainingJob object. In the
next step, you use the CustomTrainingJob's run command to create and train
your model. To create a CustomTrainingJob, you pass the following parameters
to its constructor:
display_name- TheJOB_NAMEvariable you created when you defined the command arguments for the Python training script.script_path- The path to the Python training script you created earlier in this tutorial.container_url- The URI of a Docker container image that's used to train your model.requirements- The list of the script's Python package dependencies.model_serving_container_image_uri- The URI of a Docker container image that serves predictions for your model. This container can be prebuilt or your own custom image. This tutorial uses a prebuilt container.
Run the following code to create your training pipeline. The
CustomTrainingJob
method uses the Python training script in the task.py file to construct a CustomTrainingJob.
job = aiplatform.CustomTrainingJob(
display_name=JOB_NAME,
script_path="task.py",
container_uri="us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8:latest",
requirements=["google-cloud-bigquery>=2.20.0", "db-dtypes", "protobuf<3.20.0"],
model_serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
Create and train your model
In the previous step you created a
CustomTrainingJob
named job. To create and train your model, call the run method on your
CustomTrainingJob object and pass it the following parameters:
dataset- The tabular dataset you created earlier in this tutorial. This parameter can be a tabular, image, video, or text dataset.model_display_name- A name for your model.bigquery_destination- A string that specifies the location of your BigQuery dataset.args- The command-line arguments that are passed to the Python training script.
To start training your data and create your model, run the following code in your notebook:
MODEL_DISPLAY_NAME = "penguins_model_unique"
# Start the training and create your model
model = job.run(
dataset=dataset,
model_display_name=MODEL_DISPLAY_NAME,
bigquery_destination=f"bq://{project_id}",
args=CMDARGS,
)
Before continuing with the next step, make sure the following appears in the
job.run command's output to verify it's done:
CustomTrainingJob run completed.
After the training job completes, you can deploy your model.
Deploy your model
When you deploy your model, you also create an Endpoint resource that's used
to make predictions. To deploy your model and create an endpoint, run the
following code in your notebook:
DEPLOYED_NAME = "penguins_deployed_unique"
endpoint = model.deploy(deployed_model_display_name=DEPLOYED_NAME)
Wait until your model deploys before you continue to the next step. After your
model deploys, the output includes the text, Endpoint model deployed.
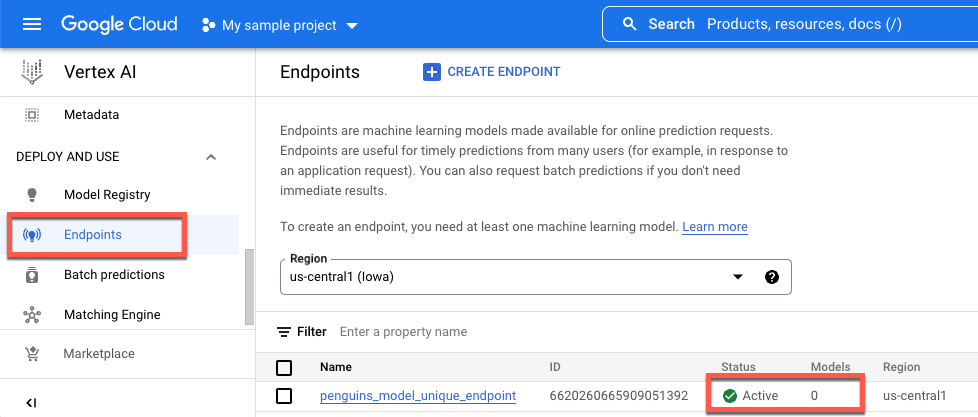
To view the status of your deployment in the Google Cloud console, do the following:
In the Google Cloud console, go to the Endpoints page.
Monitor the value under Models. The value is
0after the endpoint is created and before the model is deployed. After the model deploys, the value updates to1.The following shows an endpoint after it's created and before a model is deployed to it.
The following shows an endpoint after it's created and after a model is deployed to it.
