Vertex AI Pipelines ist ein verwalteter Dienst, mit dem Sie End-to-End-Workflows für maschinelles Lernen (ML) auf der Google Cloud-Plattform erstellen, bereitstellen und verwalten können. Sie bietet eine serverlose Umgebung zum Ausführen Ihrer Pipelines, sodass Sie sich keine Gedanken über die Verwaltung der Infrastruktur machen müssen.
In dieser Anleitung verwenden Sie Vertex AI Pipelines, um einen benutzerdefinierten Trainingsjob auszuführen und das trainierte Modell in Vertex AI in einer hybriden Netzwerkumgebung bereitzustellen.
Der gesamte Vorgang dauert zwei bis drei Stunden, einschließlich etwa 50 Minuten für die Pipelineausführung.
Diese Anleitung richtet sich an Unternehmensnetzwerkadministratoren, Data Scientists und Forscher, die mit Vertex AI, Virtual Private Cloud (VPC), der Google Cloud Console und Cloud Shell vertraut sind. Kenntnisse über Vertex AI Workbench sind hilfreich, aber nicht erforderlich.
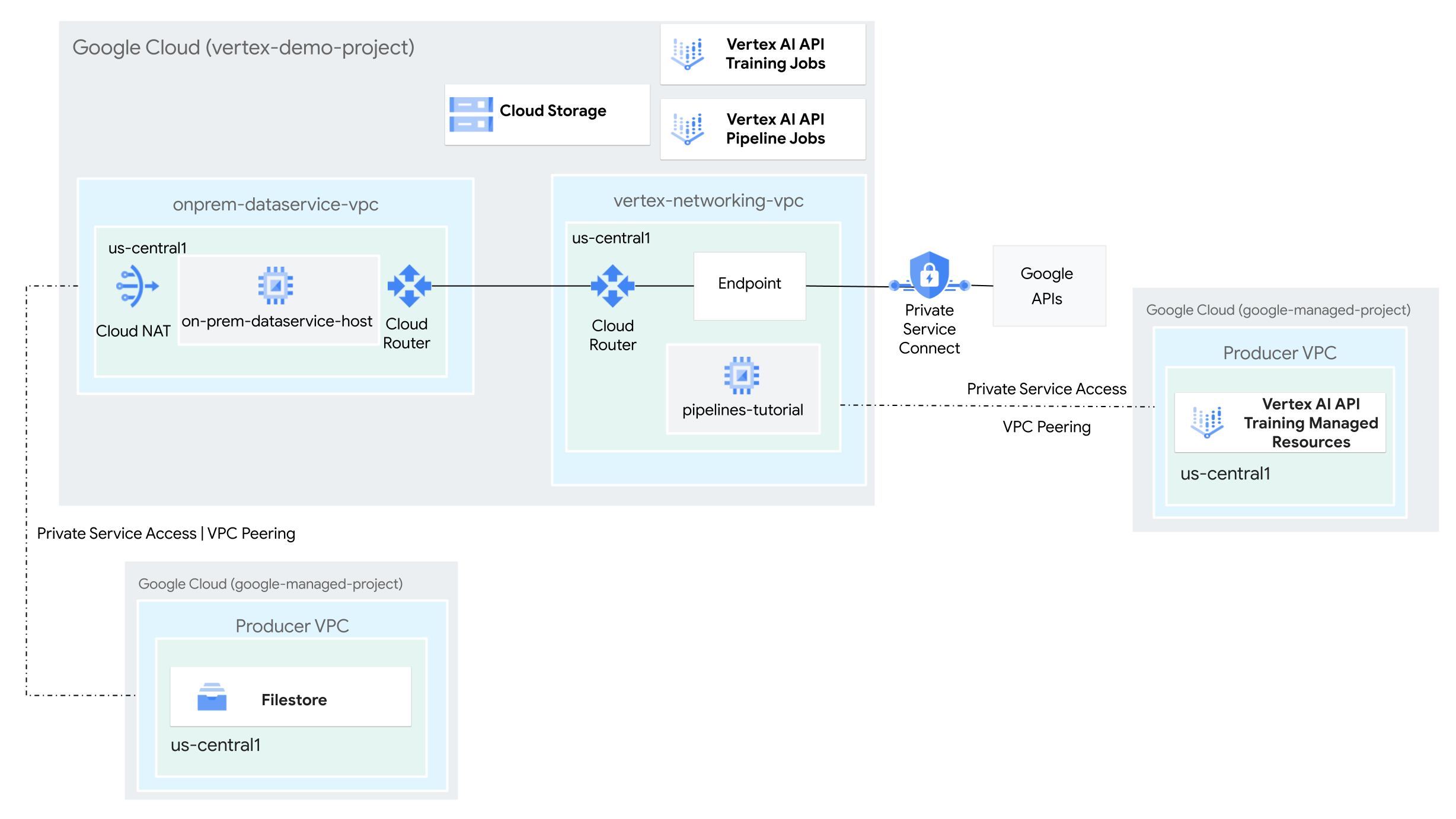
Ziele
- Erstellen Sie zwei VPC-Netzwerke (Virtual Private Cloud):
- Mit der ersten (
vertex-networking-vpc) können Sie mit der Vertex AI Pipelines API eine Pipeline-Vorlage zum Trainieren eines Machine-Learning-Modells erstellen und hosten und es dann an einem Endpunkt bereitstellen. - Das andere (
onprem-dataservice-vpc) steht für ein lokales Netzwerk.
- Mit der ersten (
- Verbinden Sie die beiden VPC-Netzwerke so:
- Stellen Sie HA VPN-Gateways, Cloud VPN-Tunnel und Cloud Router bereit, um
vertex-networking-vpcundonprem-dataservice-vpczu verbinden. - Erstellen Sie einen PSC-Endpunkt (Private Service Connect), um private Anfragen an die Vertex AI Pipelines REST API weiterzuleiten.
- Konfigurieren Sie ein benutzerdefiniertes Cloud Router Route Advertisement in
vertex-networking-vpc, um Routen für den Private Service Connect-Endpunkt gegenüberonprem-dataservice-vpcanzukündigen.
- Stellen Sie HA VPN-Gateways, Cloud VPN-Tunnel und Cloud Router bereit, um
- Erstellen Sie eine Filestore-Instanz im
onprem-dataservice-vpc-VPC-Netzwerk und fügen Sie ihr Trainingsdaten in einer NFS-Freigabe hinzu. - Erstellen Sie eine Python-Paketanwendung für den Trainingsjob.
- Erstellen Sie eine Vertex AI Pipelines-Jobvorlage, um Folgendes zu tun:
- Erstellen und führen Sie den Trainingsjob mit den Daten aus der NFS-Freigabe aus.
- Importieren Sie das trainierte Modell und laden Sie es in die Vertex AI Model Registry hoch.
- Erstellen Sie einen Vertex AI-Endpunkt für Onlinevorhersagen.
- Stellen Sie das Modell für den Endpunkt bereit.
- Laden Sie die Pipelinevorlage in ein Artifact Registry-Repository hoch.
- Verwenden Sie die Vertex AI Pipelines REST API, um einen Pipelineausführung von einem lokalen Datendiensthost (
on-prem-dataservice-host) auszulösen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Vorbereitung
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Öffnen Sie Cloud Shell, um die in dieser Anleitung aufgeführten Befehle auszuführen. Cloud Shell ist eine interaktive Shell-Umgebung für Google Cloud, mit der Sie Projekte und Ressourcen über Ihren Webbrowser verwalten können.
- Legen Sie in Cloud Shell das aktuelle Projekt auf Ihre Google Cloud-Projekt-ID fest und speichern Sie dann dieselbe Projekt-ID in der Shell-Variablen
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} - Wenn Sie nicht der Projektinhaber sind, bitten Sie den Projektinhaber, Ihnen die Rolle Projekt-IAM-Administrator (
roles/resourcemanager.projectIamAdmin) zuzuweisen. Sie benötigen diese Rolle, um im nächsten Schritt IAM-Rollen zuzuweisen. -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/artifactregistry.admin, roles/artifactregistry.repoAdmin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/file.editor, roles/logging.viewer, roles/logging.admin, roles/notebooks.admin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/servicemanagement.quotaAdmin, roles/serviceusage.serviceUsageAdmin, roles/storage.admin, roles/storage.objectAdmin, roles/aiplatform.admin, roles/aiplatform.user, roles/aiplatform.viewer, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/resourcemanager.projectIamAdmingcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
- Replace
PROJECT_IDwith your project ID. -
Replace
USER_IDENTIFIERwith the identifier for your user account. For example,user:myemail@example.com. - Replace
ROLEwith each individual role.
- Replace
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Cloud Logging, Network Connectivity, Notebooks, Cloud Filestore, Service Networking, Service Usage, and Vertex AI APIs:
gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com logging.googleapis.com networkconnectivity.googleapis.com notebooks.googleapis.com file.googleapis.com servicenetworking.googleapis.com serviceusage.googleapis.com aiplatform.googleapis.com
VPC-Netzwerke erstellen
In diesem Abschnitt erstellen Sie zwei VPC-Netzwerke: Ein VPC-Netzwerk für den Zugriff auf Google APIs für Vertex AI Pipelines und das andere zur Simulation eines lokalen Netzwerks. In jedem der beiden VPC-Netzwerke erstellen Sie einen Cloud Router und ein Cloud NAT-Gateway. Ein Cloud NAT-Gateway bietet ausgehende Verbindungen für Compute Engine-VM-Instanzen ohne externe IP-Adressen.
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}vertex-networking-vpc-VPC-Netzwerk erstellengcloud compute networks create vertex-networking-vpc \ --subnet-mode customErstellen Sie im Netzwerk
vertex-networking-vpcein Subnetz mit dem Namenpipeline-networking-subnet1und dem primären IPv4-Bereich von10.0.0.0/24:gcloud compute networks subnets create pipeline-networking-subnet1 \ --range=10.0.0.0/24 \ --network=vertex-networking-vpc \ --region=us-central1 \ --enable-private-ip-google-accessErstellen Sie das VPC-Netzwerk, um das lokale Netzwerk (
onprem-dataservice-vpc) zu simulieren:gcloud compute networks create onprem-dataservice-vpc \ --subnet-mode customErstellen Sie im Netzwerk
onprem-dataservice-vpcein Subnetz mit dem Namenonprem-dataservice-vpc-subnet1und dem primären IPv4-Bereich von172.16.10.0/24:gcloud compute networks subnets create onprem-dataservice-vpc-subnet1 \ --network onprem-dataservice-vpc \ --range 172.16.10.0/24 \ --region us-central1 \ --enable-private-ip-google-access
Prüfen, ob die VPC-Netzwerke richtig konfiguriert sind
Rufen Sie in der Google Cloud Console den Tab Netzwerke im aktuellen Projekt auf der Seite VPC-Netzwerke auf.
Prüfen Sie in der Liste der VPC-Netzwerke, ob die beiden Netzwerke erstellt wurden:
vertex-networking-vpcundonprem-dataservice-vpc.Klicken Sie auf den Tab Subnetze im aktuellen Projekt.
Prüfen Sie in der Liste der VPC-Subnetze, ob die Subnetze
pipeline-networking-subnet1undonprem-dataservice-vpc-subnet1erstellt wurden.
Hybridkonnektivität konfigurieren
In diesem Abschnitt erstellen Sie zwei (HA VPN)-Gateways, die miteinander verbunden sind. Eines befindet sich im VPC-Netzwerk vertex-networking-vpc. Das andere befindet sich im VPC-Netzwerk onprem-dataservice-vpc. Jedes Gateway enthält einen Cloud Router und ein VPN-Tunnelpaar.
HA VPN-Gateways erstellen
Erstellen Sie in Cloud Shell das HA VPN-Gateway für das VPC-Netzwerk
vertex-networking-vpc:gcloud compute vpn-gateways create vertex-networking-vpn-gw1 \ --network vertex-networking-vpc \ --region us-central1Erstellen Sie das HA VPN-Gateway für das VPC-Netzwerk
onprem-dataservice-vpc:gcloud compute vpn-gateways create onprem-vpn-gw1 \ --network onprem-dataservice-vpc \ --region us-central1Wechseln Sie in der Google Cloud Console auf der Seite VPN zum Tab Cloud VPN-Gateways.
Prüfen Sie, ob die beiden Gateways (
vertex-networking-vpn-gw1undonprem-vpn-gw1) erstellt wurden und ob jedes Gateway zwei Schnittstellen-IP-Adressen hat.
Cloud Router und Cloud NAT-Gateways erstellen
In jedem der beiden VPC-Netzwerke erstellen Sie zwei Cloud Router: einen für die Verwendung mit Cloud NAT und einen für die Verwaltung von BGP-Sitzungen für das HA VPN.
Erstellen Sie in Cloud Shell einen Cloud Router für das VPC-Netzwerk
vertex-networking-vpc, das für das VPN verwendet wird:gcloud compute routers create vertex-networking-vpc-router1 \ --region us-central1 \ --network vertex-networking-vpc \ --asn 65001Erstellen Sie einen Cloud Router für das VPC-Netzwerk
onprem-dataservice-vpc, das für das VPN verwendet werden soll:gcloud compute routers create onprem-dataservice-vpc-router1 \ --region us-central1 \ --network onprem-dataservice-vpc \ --asn 65002Erstellen Sie einen Cloud Router für das VPC-Netzwerk
vertex-networking-vpc, das für Cloud NAT verwendet wird:gcloud compute routers create cloud-router-us-central1-vertex-nat \ --network vertex-networking-vpc \ --region us-central1Konfigurieren Sie ein Cloud NAT-Gateway auf dem regionalen Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-vertex-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Erstellen Sie einen Cloud Router für das VPC-Netzwerk
onprem-dataservice-vpc, das für Cloud NAT verwendet wird:gcloud compute routers create cloud-router-us-central1-onprem-nat \ --network onprem-dataservice-vpc \ --region us-central1Konfigurieren Sie ein Cloud NAT-Gateway auf dem regionalen Cloud Router:
gcloud compute routers nats create cloud-nat-us-central1-on-prem \ --router=cloud-router-us-central1-onprem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1Wechseln Sie in der Google Cloud Console zur Seite Cloud Routers.
Prüfen Sie in der Liste Cloud Router, ob die folgenden Router erstellt wurden:
cloud-router-us-central1-onprem-natcloud-router-us-central1-vertex-natonprem-dataservice-vpc-router1vertex-networking-vpc-router1
Möglicherweise müssen Sie den Browsertab der Google Cloud Console aktualisieren, um die neuen Werte zu sehen.
Klicken Sie in der Liste der Cloud Router auf
cloud-router-us-central1-vertex-nat.Prüfen Sie auf der Seite Routerdetails, ob das Cloud NAT-Gateway
cloud-nat-us-central1erstellt wurde.Klicken Sie auf den Zurückpfeil, um zur Seite Cloud Router zurückzukehren.
Klicken Sie in der Liste der Cloud Router auf
cloud-router-us-central1-onprem-nat.Prüfen Sie auf der Seite Routerdetails, ob das Cloud NAT-Gateway
cloud-nat-us-central1-on-premerstellt wurde.
VPN-Tunnel erstellen
Erstellen Sie in der Cloud Shell im Netzwerk
vertex-networking-vpceinen VPN-Tunnel mit dem Namenvertex-networking-vpc-tunnel0:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel0 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 0Erstellen Sie im Netzwerk
vertex-networking-vpceinen VPN-Tunnel mit dem Namenvertex-networking-vpc-tunnel1:gcloud compute vpn-tunnels create vertex-networking-vpc-tunnel1 \ --peer-gcp-gateway onprem-vpn-gw1 \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router vertex-networking-vpc-router1 \ --vpn-gateway vertex-networking-vpn-gw1 \ --interface 1Erstellen Sie im Netzwerk
onprem-dataservice-vpceinen VPN-Tunnel mit dem Namenonprem-dataservice-vpc-tunnel0:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel0 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 0Erstellen Sie im Netzwerk
onprem-dataservice-vpceinen VPN-Tunnel mit dem Namenonprem-dataservice-vpc-tunnel1:gcloud compute vpn-tunnels create onprem-dataservice-vpc-tunnel1 \ --peer-gcp-gateway vertex-networking-vpn-gw1 \ --region us-central1\ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router onprem-dataservice-vpc-router1 \ --vpn-gateway onprem-vpn-gw1 \ --interface 1Rufen Sie in der Google Cloud Console die Seite VPN auf.
Prüfen Sie in der Liste der VPN-Tunnel, ob die vier VPN-Tunnel erstellt wurden.
BGP-Sitzungen erstellen
Cloud Router verwendet das Border Gateway Protocol (BGP), um Routen zwischen Ihrem VPC-Netzwerk (in diesem Fall vertex-networking-vpc) und Ihrem lokalen Netzwerk (dargestellt durch onprem-dataservice-vpc) auszutauschen. Auf dem Cloud Router konfigurieren Sie eine Schnittstelle und einen BGP-Peer für Ihren lokalen Router.
Die Konfigurationen für Schnittstelle und BGP-Peer bilden zusammen eine BGP-Sitzung.
In diesem Abschnitt erstellen Sie zwei BGP-Sitzungen für vertex-networking-vpc und zwei für onprem-dataservice-vpc.
Nachdem Sie die Schnittstellen und BGP-Peers zwischen Ihren Routern konfiguriert haben, beginnen sie automatisch mit dem Austausch von Routen.
BGP-Sitzungen für vertex-networking-vpc erstellen
Erstellen Sie in Cloud Shell im Netzwerk
vertex-networking-vpceine BGP-Schnittstelle fürvertex-networking-vpc-tunnel0:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.0.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel0 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceinen BGP-Peer fürbgp-onprem-tunnel0:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel0 \ --interface if-tunnel0-to-onprem \ --peer-ip-address 169.254.0.2 \ --peer-asn 65002 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceine BGP-Schnittstelle fürvertex-networking-vpc-tunnel1:gcloud compute routers add-interface vertex-networking-vpc-router1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel vertex-networking-vpc-tunnel1 \ --region us-central1Erstellen Sie im Netzwerk
vertex-networking-vpceinen BGP-Peer fürbgp-onprem-tunnel1:gcloud compute routers add-bgp-peer vertex-networking-vpc-router1 \ --peer-name bgp-onprem-tunnel1 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1
BGP-Sitzungen für onprem-dataservice-vpc erstellen
Erstellen Sie im Netzwerk
onprem-dataservice-vpceine BGP-Schnittstelle füronprem-dataservice-vpc-tunnel0:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel0-to-vertex-networking-vpc \ --ip-address 169.254.0.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel0 \ --region us-central1Erstellen Sie im Netzwerk
onprem-dataservice-vpceinen BGP-Peer fürbgp-vertex-networking-vpc-tunnel0:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel0 \ --interface if-tunnel0-to-vertex-networking-vpc \ --peer-ip-address 169.254.0.1 \ --peer-asn 65001 \ --region us-central1Erstellen Sie im Netzwerk
onprem-dataservice-vpceine BGP-Schnittstelle füronprem-dataservice-vpc-tunnel1:gcloud compute routers add-interface onprem-dataservice-vpc-router1 \ --interface-name if-tunnel1-to-vertex-networking-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel onprem-dataservice-vpc-tunnel1 \ --region us-central1Erstellen Sie im Netzwerk
onprem-dataservice-vpceinen BGP-Peer fürbgp-vertex-networking-vpc-tunnel1:gcloud compute routers add-bgp-peer onprem-dataservice-vpc-router1 \ --peer-name bgp-vertex-networking-vpc-tunnel1 \ --interface if-tunnel1-to-vertex-networking-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1
BGP-Sitzungserstellung prüfen
Rufen Sie in der Google Cloud Console die Seite VPN auf.
Prüfen Sie in der Liste der VPN-Tunnel, ob sich der Wert in der Spalte BGP-Sitzungsstatus für jeden Tunnel von BGP-Sitzung konfigurieren in BGP eingerichtet gändert. Möglicherweise müssen Sie den Browsertab der Google Cloud Console aktualisieren, um die neuen Werte zu sehen.
Erkannte Routen onprem-dataservice-vpc validieren
Rufen Sie in der Google Cloud Console die Seite VPC-Netzwerke auf.
Klicken Sie in der Liste der VPC-Netzwerke auf
onprem-dataservice-vpc.Klicken Sie auf den Tab Routen.
Wählen Sie in der Liste Region die Option us-central1 (Iowa) aus und klicken Sie auf Ansehen.
Prüfen Sie in der Spalte Ziel-IP-Adressbereich, ob der Subnetz-IP-Bereich
pipeline-networking-subnet1(10.0.0.0/24) zweimal angezeigt wird.Möglicherweise müssen Sie den Browsertab der Google Cloud Console aktualisieren, um beide Einträge zu sehen.
Erkannte Routen vertex-networking-vpc validieren
Klicken Sie auf den Zurückpfeil, um zur Seite VPC-Netzwerke zurückzukehren.
Klicken Sie in der Liste der VPC-Netzwerke auf
vertex-networking-vpc.Klicken Sie auf den Tab Routen.
Wählen Sie in der Liste Region die Option us-central1 (Iowa) aus und klicken Sie auf Ansehen.
Prüfen Sie in der Spalte Ziel-IP-Adressbereich, ob der IP-Bereich des Subnetzes
onprem-dataservice-vpc-subnet1(172.16.10.0/24) zweimal angezeigt wird.
Private Service Connect-Endpunkt für Google APIs erstellen
In diesem Abschnitt erstellen Sie einen Private Service Connect-Endpunkt für Google APIs, mit dem Sie von Ihrem lokalen Netzwerk aus auf die Vertex AI Pipelines REST API zugreifen.
Reservieren Sie in Cloud Shell eine Nutzerendpunkt-IP-Adresse, die für den Zugriff auf Google APIs verwendet wird:
gcloud compute addresses create psc-googleapi-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=192.168.0.1 \ --network=vertex-networking-vpcErstellen Sie eine Weiterleitungsregel, um den Endpunkt mit Google APIs und Google-Diensten zu verbinden.
gcloud compute forwarding-rules create pscvertex \ --global \ --network=vertex-networking-vpc \ --address=psc-googleapi-ip \ --target-google-apis-bundle=all-apis
Benutzerdefinierte Route Advertisements für vertex-networking-vpc erstellen
In diesem Abschnitt erstellen Sie Folgendes:Benutzerdefiniertes Route Advertisement
fürvertex-networking-vpc-router1 (Der Cloud Router für
vertex-networking-vpc ), um die IP-Adresse des PSC-Endpunkts gegenüber deronprem-dataservice-vpc VPC-Netzwerk zu bewerben
Wechseln Sie in der Google Cloud Console zur Seite Cloud Routers.
Klicken Sie in der Liste der Cloud Router auf
vertex-networking-vpc-router1.Klicken Sie auf der Seite Routerdetails auf Bearbeiten.
Wählen Sie im Abschnitt Beworbene Routen für Routen die Option Benutzerdefinierte Routen erstellen.
Wählen Sie das Kästchen Alle für den Cloud Router sichtbaren Subnetze bewerben aus. Damit können Sie weiterhin die Subnetze bewerben, die für den Cloud Router zur Verfügung stehen. Wenn Sie diese Option aktivieren, entspricht dies dem Verhalten von Cloud Router im standardmäßigen Advertisement-Modus.
Klicken Sie auf Benutzerdefinierte Route hinzufügen.
Wählen Sie für Quelle die Option Benutzerdefinierter IP-Bereich aus.
Geben Sie als IP-Adressbereich die folgende IP-Adresse ein:
192.168.0.1Geben Sie unter Beschreibung den folgenden Text ein:
Custom route to advertise Private Service Connect endpoint IP addressKlicken Sie auf Fertig und anschließend auf Speichern.
Prüfen, ob onprem-dataservice-vpc die beworbenen Routen erlernt hat
Rufen Sie in der Google Cloud Console die Seite Routen auf.
Führen Sie auf dem Tab Aktive Routen folgende Schritte aus:
- Wählen Sie für Netzwerk die Option
onprem-dataservice-vpcaus. - Wählen Sie bei Region die Option
us-central1 (Iowa)aus. - Klicken Sie auf Ansehen.
Prüfen Sie in der Liste der Routen, ob zwei Einträge vorhanden sind, deren Namen mit
onprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel0und zwei, deren Namen mitonprem-dataservice-vpc-router1-bgp-vertex-networking-vpc-tunnel1beginnen.Wenn diese Einträge nicht sofort angezeigt werden, warten Sie einige Minuten und aktualisieren Sie dann den Browsertab der Google Cloud Console.
Prüfen Sie, ob zwei der Einträge einen Ziel-IP-Bereich von
192.168.0.1/32und zwei einen Ziel-IP-Bereich von10.0.0.0/24haben.
- Wählen Sie für Netzwerk die Option
VM-Instanz in onprem-dataservice-vpc erstellen
In diesem Abschnitt erstellen Sie eine VM-Instanz, die einen lokalen Datendiensthost simuliert. Gemäß den Best Practices für Compute Engine und IAM verwendet diese VM ein nutzerverwaltetes Dienstkonto anstelle des Compute Engine-Standarddienstkontos.
Vom Nutzer verwaltetes Dienstkonto für die VM-Instanz erstellen
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Erstellen Sie ein Dienstkonto mit dem Namen
onprem-user-managed-sa:gcloud iam service-accounts create onprem-user-managed-sa \ --display-name="onprem-user-managed-sa"Weisen Sie dem Dienstkonto die IAM-Rolle Vertex AI User (
roles/aiplatform.user) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Weisen Sie die Rolle Vertex AI-Betrachter (
roles/aiplatform.viewer) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.viewer"Weisen Sie die Rolle Filestore-Bearbeiter (
roles/file.editor) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/file.editor"Weisen Sie die Rolle Dienstkonto Administrator (
roles/iam.serviceAccountAdmin) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountAdmin"Weisen Sie die Rolle Dienstkontonutzer (
roles/iam.serviceAccountUser) zu.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/iam.serviceAccountUser"Weisen Sie die Rolle Artifact Registry-Leser (
roles/artifactregistry.reader) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.reader"Weisen Sie die Rolle Storage-Objekt-Administrator (
roles/storage.objectAdmin) zu.gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.objectAdmin"Weisen Sie die Rolle Logging-Administrator (
roles/logging.admin) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:onprem-user-managed-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/logging.admin"
on-prem-dataservice-host
VM-Instanz erstellen
Die von Ihnen erstellte VM-Instanz hat keine externe IP-Adresse und lässt keinen direkten Zugriff über das Internet zu. Zum Aktivieren des Administratorzugriffs auf die VM verwenden Sie die TCP-Weiterleitung von Identity-Aware Proxy (IAP).
Erstellen Sie in Cloud Shell die VM-Instanz
on-prem-dataservice-host:gcloud compute instances create on-prem-dataservice-host \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=onprem-dataservice-vpc-subnet1 \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --shielded-secure-boot \ --service-account=onprem-user-managed-sa@$projectid.iam.gserviceaccount.com \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Erstellen Sie eine Firewallregel, damit IAP eine Verbindung zu Ihrer VM-Instanz herstellen kann:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network onprem-dataservice-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
zu Aktualisieren die Datei /etc/hosts, sodass sie auf den PSC-Endpunkt verweist.
In diesem Schritt fügen Sie der Datei /etc/hosts eine Zeile hinzu, die bewirkt, dass an den öffentlichen Dienstendpunkt (us-central1-aiplatform.googleapis.com) gesendete Anfragen an den PSC-Endpunkt (192.168.0.1) weitergeleitet werden.
Melden Sie sich in Cloud Shell mit IAP bei der VM-Instanz
on-prem-dataservice-hostan:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapVerwenden Sie auf der VM-Instanz
on-prem-dataservice-hosteinen Texteditor wievimodernano, um die Datei/etc/hostszu öffnen, z. B.:sudo vim /etc/hostsFügen Sie der Datei die folgende Zeile hinzu:
192.168.0.1 us-central1-aiplatform.googleapis.comDiese Zeile weist dem vollständig qualifizierten Domainnamen für die Vertex AI Google API (
us-central1-aiplatform.googleapis.com) die IP-Adresse des PSC-Endpunkts (192.168.0.1) zu.Die bearbeitete Datei sollte folgendermaßen aussehen:
127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 192.168.0.1 us-central1-aiplatform.googleapis.com # Added by you 172.16.10.6 on-prem-dataservice-host.us-central1-a.c.PROJECT_ID.internal on-prem-dataservice-host # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleSpeichern Sie die Datei so:
- Wenn Sie
vimverwenden, drücken Sie die TasteEscund geben Sie dann:wqein, um die Datei zu speichern und zu beenden. - Wenn Sie
nanoverwenden, geben SieControl+Oein und drücken SieEnter, um die Datei zu speichern. Geben Sie dann zum BeendenControl+Xein.
- Wenn Sie
Pingen Sie den Vertex AI API-Endpunkt so an:
ping us-central1-aiplatform.googleapis.comDer Befehl
pingsollte Folgendes zurückgeben:192.168.0.1ist die IP-Adresse des PSC-Endpunkts:PING us-central1-aiplatform.googleapis.com (192.168.0.1) 56(84) bytes of data.Geben Sie
Control+Cein, umpingzu beenden.Geben Sie
exitein, um dieon-prem-dataservice-host-VM-Instanz zu beenden und zum Cloud Shell-Prompt zurückzukehren.
Netzwerk für eine Filestore-Instanz konfigurieren
In diesem Abschnitt aktivieren Sie den Zugriff auf private Dienste für Ihr VPC-Netzwerk, um eine Filestore-Instanz zu erstellen und als NFS-Freigabe (Network File System) bereitzustellen. Informationen zu den Schritten in diesem und im nächsten Abschnitt finden Sie unter NFS-Freigabe für benutzerdefiniertes Training bereitstellen und VPC-Netzwerk-Peering einrichten.
Zugriff auf private Dienste in einem VPC-Netzwerk aktivieren
In diesem Abschnitt erstellen Sie eine Dienstnetzwerkverbindung und ermöglichen damit privaten Dienstzugriff auf das onprem-dataservice-vpc-VPC-Netzwerk über das VPC-Netzwerk-Peering.
Legen Sie in Cloud Shell mit
gcloud compute addresses createeinen reservierten IP-Adressbereich fest:gcloud compute addresses create filestore-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=10.243.208.0 \ --prefix-length=24 \ --description="filestore subnet" \ --network=onprem-dataservice-vpcStellen Sie mithilfe von
gcloud services vpc-peerings connecteine Peering-Verbindung zwischen demonprem-dataservice-vpc-VPC-Netzwerk und dem Google-Dienstnetzwerk her:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=filestore-subnet \ --network=onprem-dataservice-vpcAktualisieren Sie das VPC-Netzwerk-Peering, um den Import und Export benutzerdefinierter gelernter Routen zu aktivieren:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=onprem-dataservice-vpc \ --import-custom-routes \ --export-custom-routesRufen Sie in der Google Cloud Console die Seite VPC-Netzwerk-Peering auf.
Prüfen Sie in der Liste der VPC-Peerings, ob es einen Eintrag für das Peering zwischen
servicenetworking.googleapis.comund dem VPC-Netzwerkonprem-dataservice-vpcgibt.
Benutzerdefinierte Route Advertisements für filestore-subnet erstellen
Wechseln Sie in der Google Cloud Console zur Seite Cloud Routers.
Klicken Sie in der Liste der Cloud Router auf
onprem-dataservice-vpc-router1.Klicken Sie auf der Seite Routerdetails auf Bearbeiten.
Wählen Sie im Abschnitt Beworbene Routen für Routen die Option Benutzerdefinierte Routen erstellen.
Wählen Sie das Kästchen Alle für den Cloud Router sichtbaren Subnetze bewerben aus. Damit können Sie weiterhin die Subnetze bewerben, die für den Cloud Router zur Verfügung stehen. Wenn Sie diese Option aktivieren, entspricht dies dem Verhalten von Cloud Router im standardmäßigen Advertisement-Modus.
Klicken Sie auf Benutzerdefinierte Route hinzufügen.
Wählen Sie für Quelle die Option Benutzerdefinierter IP-Bereich aus.
Geben Sie als IP-Adressbereich die folgende IP-Adressbereich ein:
10.243.208.0/24Geben Sie unter Beschreibung den folgenden Text ein:
Filestore reserved IP address rangeKlicken Sie auf Fertig und anschließend auf Speichern.
Filestore-Instanz im onprem-dataservice-vpc-Netzwerk erstellen
Nachdem Sie den Zugriff auf private Dienste für Ihr VPC-Netzwerk aktiviert haben, erstellen Sie eine Filestore-Instanz und stellen Sie die Instanz als NFS-Freigabe für Ihren benutzerdefinierten Trainingsjob bereit. Dadurch können Ihre Trainings-Jobs auf Remotedateien zugreifen, als ob sie lokal wären, was einen hohen Durchsatz und eine niedrige Latenz ermöglicht.
Erstellen Sie die Filestore-Instanz.
Rufen Sie in der Google Cloud Console die Seite Filestore-Instanzen auf.
Klicken Sie auf Instanz erstellen und konfigurieren Sie die Instanz wie folgt.
Legen Sie für Instanz-ID Folgendes fest:
image-data-instanceWählen Sie als Instanztyp die Option Basis aus.
Legen Sie Speichertyp auf HDD fest.
Setzen Sie Kapazität zuweisen auf 1
TiB.Legen Sie für Region den Wert us-central1 und für Zone den Wert us-central1-a fest.
Legen Sie VPC-Netzwerk auf
onprem-dataservice-vpcfest.Legen Sie für Zugewiesener IP-Bereich die Option Vorhandenen zugewiesenen IP-Bereich verwenden fest und wählen Sie
filestore-subnetaus.Legen Sie für Dateifreigabe-Name Folgendes fest:
vol1Legen Sie unter Zugriffssteuerungen die Option Allen Clients im VPC-Netzwerk Zugriff gewähren fest.
Klicken Sie auf Erstellen.
Notieren Sie sich die IP-Adresse Ihrer neuen Filestore-Instanz. Möglicherweise müssen Sie den Browsertab der Google Cloud Console aktualisieren, um die neue Instanz zu sehen.
Filestore-Dateifreigabe bereitstellen
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Melden Sie sich bei der VM-Instanz
on-prem-dataservice-hostan:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapInstallieren Sie das NFS-Paket auf der VM-Instanz:
sudo apt-get update -y sudo apt-get -y install nfs-commonErstellen Sie ein Bereitstellungsverzeichnis für die Filestore-Dateifreigabe:
sudo mkdir -p /mnt/nfsStellen Sie die Dateifreigabe bereit. Ersetzen Sie dazu FILESTORE_INSTANCE_IP durch die IP-Adresse Ihrer Filestore-Instanz:
sudo mount FILESTORE_INSTANCE_IP:/vol1 /mnt/nfsWenn die Verbindung überschreitet, müssen Sie die richtige IP-Adresse der Filestore-Instanz angeben.
Prüfen Sie mit dem folgenden Befehl, ob die NFS-Bereitstellung erfolgreich war:
df -hPrüfen Sie, ob die Dateifreigabe
/mnt/nfsim Ergebnis angezeigt wird:Filesystem Size Used Avail Use% Mounted on udev 1.8G 0 1.8G 0% /dev tmpfs 368M 396K 368M 1% /run /dev/sda1 9.7G 1.9G 7.3G 21% / tmpfs 1.8G 0 1.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/sda15 124M 11M 114M 9% /boot/efi tmpfs 368M 0 368M 0% /run/user 10.243.208.2:/vol1 1007G 0 956G 0% /mnt/nfsÄndern Sie die Berechtigungen, um den Zugriff auf die Dateifreigabe zu ermöglichen:
sudo chmod go+rw /mnt/nfs
Dataset in die Dateifreigabe herunterladen
Laden Sie den Datset in der VM-Instanz
on-prem-dataservice-hostin die Dateifreigabe herunter:gcloud storage cp gs://cloud-samples-data/vertex-ai/dataset-management/datasets/fungi_dataset /mnt/nfs/ --recursiveDer Download dauert einige Minuten.
Prüfen Sie mit dem folgenden Befehl, ob das Dataset erfolgreich kopiert wurde:
sudo du -sh /mnt/nfsFolgende Ausgabe wird erwartet:
104M /mnt/nfsGeben Sie
exitein, um dieon-prem-dataservice-host-VM-Instanz zu beenden und zum Cloud Shell-Prompt zurückzukehren.
Staging-Bucket für Ihre Pipeline erstellen
Vertex AI Pipelines speichert die Artefakte Ihrer Pipeline, die Cloud Storage verwenden. Bevor Sie die Pipeline ausführen, müssen Sie einen Cloud Storage-Bucket für die Ausführung von Staging-Pipelines erstellen.
Erstellen Sie in Cloud Shell einen Cloud Storage-Bucket.
gcloud storage buckets create gs://pipelines-staging-bucket-$projectid --location=us-central1
Nutzerverwaltetes Dienstkonto für Vertex AI Workbench erstellen
Erstellen Sie in Cloud Shell ein Dienstkonto:
gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Weisen Sie dem Dienstkonto die IAM-Rolle Vertex AI User (
roles/aiplatform.user) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Weisen Sie die Rolle Artifact Registry-Administrator (
artifactregistry.admin) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"Weisen Sie die Rolle Storage Admin (
storage.admin) zu:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"
Python-Trainingsanwendung erstellen
In diesem Abschnitt erstellen Sie eine Vertex AI Workbench-Instanz und verwenden diese, um ein benutzerdefiniertes Python-Trainingsanwendungspaket zu erstellen.
Vertex AI Workbench-Instanz erstellen
Rufen Sie in der Google Cloud Console auf der Seite Vertex AI Workbench den Tab Instanzen auf.
Klicken Sie auf Neu erstellen und wählen Sie Erweiterte Optionen aus.
Die Seite Neue Instanz wird geöffnet.
Geben Sie auf der Seite Neue Instanz im Abschnitt Details die folgenden Informationen für Ihre neue Instanz ein und klicken Sie dann auf Weiter:
Name: Geben Sie Folgendes ein und ersetzen Sie dabei PROJECT_ID durch die Projekt-ID:
pipeline-tutorial-PROJECT_IDRegion: Wählen Sie us-central1 aus.
Zone: Wählen Sie us-central1-a aus.
Entfernen Sie das Häkchen aus dem Kästchen Serverlose interaktive Dataproc-Sitzungen aktivieren.
Klicken Sie im Bereich Umgebung auf Weiter.
Geben Sie im Abschnitt Maschinentyp Folgendes ein und klicken Sie dann auf Weiter:
- Maschinentyp: Wählen Sie N1 und dann
n1-standard-4aus dem Menü Maschinentyp aus. Shielded VM: Klicken Sie die folgenden Kästchen an:
- Secure Boot
- Virtual Trusted Platform Module (vTPM)
- Integritätsmonitoring
- Maschinentyp: Wählen Sie N1 und dann
Achten Sie darauf, dass im Abschnitt Laufwerke die Option Von Google verwalteter Verschlüsselungsschlüssel ausgewählt ist. Klicken Sie dann auf Weiter:
Geben Sie im Abschnitt Netzwerk Folgendes ein und klicken Sie dann auf Weiter:
Netzwerk: Wählen Sie Netzwerk in diesem Projekt aus und führen Sie die folgenden Schritte aus:
Wählen Sie im Feld Netzwerk die Option vertex-networking-vpc aus.
Wählen Sie im Feld Subnetzwerk die Option pipeline-networking-subnet1 aus.
Entfernen Sie das Häkchen aus dem Kästchen Externe IP-Adresse zuweisen. Wenn Sie keine externe IP-Adresse zuweisen, kann die Instanz keine unerwünschten Nachrichten über das Internet oder andere VPC-Netzwerke mehr empfangen.
Klicken Sie auf das Kästchen Proxyzugriff zulassen.
Geben Sie im Abschnitt IAM und Sicherheit Folgendes ein und klicken Sie dann auf Weiter:
IAM und Sicherheit: Führen Sie die folgenden Schritte aus, um einem einzelnen Nutzer Zugriff auf die JupyterLab-Oberfläche der Instanz zu gewähren:
- Wählen Sie Dienstkonto aus.
- Entfernen Sie das Häkchen aus dem Kästchen Compute Engine-Standarddienstkonto verwenden.
Dieser Schritt ist wichtig, da dem Compute Engine-Standarddienstkonto (und damit dem soeben angegebenen einzelnen Nutzer) die Rolle "Editor" (
roles/editor) für Ihr Projekt haben könnte. Geben Sie im Feld E-Mail-Adresse des Dienstkontos Folgendes ein und ersetzen Sie PROJECT_ID durch die Projekt-ID:
workbench-sa@PROJECT_ID.iam.gserviceaccount.com(Dies ist die E-Mail-Adresse des benutzerdefinierten Dienstkontos, die Sie zuvor erstellt haben.) Dieses Dienstkonto hat eingeschränkte Berechtigungen.
Weitere Informationen zum Gewähren des Zugriffs finden Sie unter Zugriff auf die JupyterLab-Oberfläche einer Vertex AI Workbench-Instanz verwalten.
Sicherheitsoptionen: Entfernen Sie das Häkchen aus dem folgenden Kästchen:
- Root-Zugriff auf die Instanz
Klicken Sie das folgende Kästchen an:
- nbconvert: Mit
nbconvertkönnen Nutzer eine Notebookdatei als anderen Dateityp exportieren und herunterladen, z. B. HTML, PDF oder LaTeX. Diese Einstellung ist für einige Notebooks im GitHub-Repository Google Cloud Generative AI erforderlich.
Entfernen Sie das Häkchen aus dem folgenden Kästchen:
- Download von Dateien
Klicken Sie auf das folgende Kästchen, sofern Sie sich nicht in einer Produktionsumgebung befinden:
- Terminalzugriff: Dies ermöglicht den Terminalzugriff auf Ihre Instanz über die JupyterLab-Benutzeroberfläche.
Heben Sie im Bereich Systemzustand die Auswahl der Option Automatisches Umgebungsupgrade auf und geben Sie Folgendes an:
Klicken Sie unter Berichterstellung die folgenden Kästchen an:
- Bericht zum Systemzustand aktivieren
- Benutzerdefinierte Messwerte an Cloud Monitoring melden
- Cloud Monitoring installieren
- DNS-Status für erforderliche Google-Domains melden
Klicken Sie auf Erstellen und warten Sie einige Minuten, bis die Vertex AI Workbench-Instanz erstellt ist.
Trainingsanwendung in der Vertex AI Workbench-Instanz ausführen
Rufen Sie in der Google Cloud Console auf der Seite Vertex AI Workbench den Tab Instanzen auf.
Klicken Sie neben dem Namen der Vertex AI Workbench-Instanz (
pipeline-tutorial-PROJECT_ID, wobei PROJECT_ID die Projekt-ID ist) auf JupyterLab öffnen.Ihre Vertex AI Workbench-Instanz öffnet JupyterLab.
Wählen Sie Datei > Neu > Terminal aus.
Definieren Sie im JupyterLab-Terminal (nicht in Cloud Shell) eine Umgebungsvariable für Ihr Projekt. Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_IDErstellen Sie die übergeordneten Verzeichnisse für die Trainingsanwendung (noch im JupyterLab-Terminal):
mkdir fungi_training_package mkdir fungi_training_package/trainerDoppelklicken Sie im Dateibrowser auf den Ordner
fungi_training_packageund dann auf den Ordnertrainer.Klicken Sie im Dateibrowser mit der rechten Maustaste auf die leere Dateiliste unter der Überschrift Name und wählen Sie Neue Datei aus.
Klicken Sie mit der rechten Maustaste auf die neue Datei und wählen Sie Datei umbenennen aus.
Benennen Sie die Datei von
untitled.txtintask.pyum.Doppelklicken Sie auf die Datei
task.py, um sie zu öffnen.Kopieren Sie den folgenden Code in
task.py:# Import the libraries import tensorflow as tf from tensorflow.python.client import device_lib import argparse import os import sys # add parser arguments parser = argparse.ArgumentParser() parser.add_argument('--data-dir', dest='dataset_dir', type=str, help='Dir to access dataset.') parser.add_argument('--model-dir', dest='model_dir', default=os.getenv("AIP_MODEL_DIR"), type=str, help='Dir to save the model.') parser.add_argument('--epochs', dest='epochs', default=10, type=int, help='Number of epochs.') parser.add_argument('--batch-size', dest='batch_size', default=32, type=int, help='Number of images per batch.') parser.add_argument('--distribute', dest='distribute', default='single', type=str, help='distributed training strategy.') args = parser.parse_args() # print the tf version and config print('Python Version = {}'.format(sys.version)) print('TensorFlow Version = {}'.format(tf.__version__)) print('TF_CONFIG = {}'.format(os.environ.get('TF_CONFIG', 'Not found'))) print('DEVICES', device_lib.list_local_devices()) # Single Machine, single compute device if args.distribute == 'single': if tf.test.is_gpu_available(): strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0") else: strategy = tf.distribute.OneDeviceStrategy(device="/cpu:0") # Single Machine, multiple compute device elif args.distribute == 'mirror': strategy = tf.distribute.MirroredStrategy() # Multiple Machine, multiple compute device elif args.distribute == 'multi': strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy() # Multi-worker configuration print('num_replicas_in_sync = {}'.format(strategy.num_replicas_in_sync)) # Preparing dataset BUFFER_SIZE = 1000 IMG_HEIGHT = 224 IMG_WIDTH = 224 def make_datasets_batched(dataset_path, global_batch_size): # Configure the training data generator train_data_dir = os.path.join(dataset_path,"train/") train_ds = tf.keras.utils.image_dataset_from_directory( train_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # Configure the validation data generator val_data_dir = os.path.join(dataset_path,"valid/") val_ds = tf.keras.utils.image_dataset_from_directory( val_data_dir, seed=36, image_size=(IMG_HEIGHT, IMG_WIDTH), batch_size=global_batch_size ) # get the number of classes in the data num_classes = len(train_ds.class_names) # Configure the dataset for performance AUTOTUNE = tf.data.AUTOTUNE train_ds = train_ds.cache().shuffle(BUFFER_SIZE).prefetch(buffer_size=AUTOTUNE) val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) return train_ds, val_ds, num_classes # Build the Keras model def build_and_compile_cnn_model(num_classes): # build a CNN model model = tf.keras.models.Sequential([ tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)), tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'), tf.keras.layers.MaxPooling2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(num_classes) ]) # compile the CNN model model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) return model # Get the strategy data NUM_WORKERS = strategy.num_replicas_in_sync # Here the batch size scales up by number of workers GLOBAL_BATCH_SIZE = args.batch_size * NUM_WORKERS # Create dataset generator objects train_ds, val_ds, num_classes = make_datasets_batched(args.dataset_dir, GLOBAL_BATCH_SIZE) # Compile the model with strategy.scope(): # Creation of dataset, and model building/compiling need to be within # `strategy.scope()`. model = build_and_compile_cnn_model(num_classes) # fit the model on the data history = model.fit(train_ds, validation_data=val_ds, epochs=args.epochs) # save the model to the output dir model.save(args.model_dir)Wählen Sie Datei > Python-Datei speichern aus.
Erstellen Sie im JupyterLab-Terminal in jedem Unterverzeichnis eine Datei
__init__.py, um sie zu einem Paket hinzuzufügen:touch fungi_training_package/__init__.py touch fungi_training_package/trainer/__init__.pyDoppelklicken Sie im Dateibrowser auf den neuen Ordner
fungi_training_package.Wählen Sie Datei > Neu > Python-Datei aus.
Klicken Sie mit der rechten Maustaste auf die neue Datei und wählen Sie Datei umbenennen aus.
Benennen Sie die Datei von
untitled.pyinsetup.pyum.Doppelklicken Sie auf die Datei
setup.py, um sie zu öffnen.Kopieren Sie den folgenden Code in
setup.py:from setuptools import find_packages from setuptools import setup setup( name='trainer', version='0.1', packages=find_packages(), include_package_data=True, description='Training application package for fungi-classification.' )Wählen Sie Datei > Python-Datei speichern aus.
Öffnen Sie in Ihrem Terminal das Verzeichnis
fungi_training_package:cd fungi_training_packageVerwenden Sie den Befehl
sdist, um die Quellverteilung der Trainingsanwendung zu erstellen.python setup.py sdist --formats=gztarWechseln Sie zum übergeordneten Verzeichnis:
cd ..Prüfen Sie, ob Sie sich im richtigen Verzeichnis befinden:
pwdSie erhalten folgende Ausgabe:
/home/jupyterKopieren Sie das Python-Paket in den Staging-Bucket:
gcloud storage cp fungi_training_package/dist/trainer-0.1.tar.gz gs://pipelines-staging-bucket-$projectid/training_package/Prüfen Sie, ob der Staging-Bucket das Paket enthält:
gcloud storage ls gs://pipelines-staging-bucket-$projectid/training_packageDie Ausgabe sieht so aus:
gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz
Dienstnetzwerkverbindung für Vertex AI Pipelines erstellen
In diesem Abschnitt erstellen Sie eine Dienstnetzwerkverbindung, mit der Erstellerdienste etabliert werden, die über VPC-Netzwerk-Peering mit dem VPC-Netzwerk vertex-networking-vpc verbunden sind. Weitere Informationen finden Sie unter VPC-Netzwerk-Peering.
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Legen Sie mit
gcloud compute addresses createeinen reservierten IP-Adressbereich fest:gcloud compute addresses create vertex-pipeline-subnet \ --global \ --purpose=VPC_PEERING \ --addresses=192.168.10.0 \ --prefix-length=24 \ --description="pipeline subnet" \ --network=vertex-networking-vpcStellen Sie mithilfe von
gcloud services vpc-peerings connecteine Peering-Verbindung zwischen demvertex-networking-vpc-VPC-Netzwerk und dem Google-Dienstnetzwerk her:gcloud services vpc-peerings connect \ --service=servicenetworking.googleapis.com \ --ranges=vertex-pipeline-subnet \ --network=vertex-networking-vpcAktualisieren Sie die VPC-Peering-Verbindung, um den Import und Export benutzerdefinierter gelernter Routen zu aktivieren:
gcloud compute networks peerings update servicenetworking-googleapis-com \ --network=vertex-networking-vpc \ --import-custom-routes \ --export-custom-routes
Pipeline-Subnetz über den pipeline-networking-Cloud Router bewerben
Wechseln Sie in der Google Cloud Console zur Seite Cloud Router.
Klicken Sie in der Liste der Cloud Router auf
vertex-networking-vpc-router1.Klicken Sie auf der Seite Routerdetails auf Bearbeiten.
Klicken Sie auf Benutzerdefinierte Route hinzufügen.
Wählen Sie für Quelle die Option Benutzerdefinierter IP-Bereich aus.
Geben Sie als IP-Adressbereich die folgende IP-Adressbereich ein:
192.168.10.0/24Geben Sie unter Beschreibung den folgenden Text ein:
Vertex AI Pipelines reserved subnetKlicken Sie auf Fertig und anschließend auf Speichern.
Pipelinevorlage erstellen und in Artifact Registry hochladen
In diesem Abschnitt erstellen und laden Sie eine Pipelinevorlage für Kubeflow Pipelines (KFP) hoch. Diese Vorlage enthält eine Workflowdefinition, die mehrmals von einem einzelnen Nutzer oder von mehreren Nutzern wiederverwendet werden kann.
Pipeline definieren und kompilieren
Doppelklicken Sie in JupyterLab im Dateibrowser auf den obersten Ordner.
Wählen Sie File > New > Notebook aus.
Wählen Sie im Menü Kernel auswählen die Option
Python 3 (ipykernel)aus und klicken Sie auf Auswählen.Führen Sie in einer neuen Notebookzelle den folgenden Befehl aus, um sicherzustellen, dass Sie die neueste Version von
pipverwenden:!python -m pip install --upgrade pipFühren Sie den folgenden Befehl aus, um das Google Cloud Pipeline Components SDK aus dem Python Package Index (PyPI) zu installieren:
!pip install --upgrade google-cloud-pipeline-componentsWenn die Installation abgeschlossen ist, wählen Sie Kernel > Restart kernel, um den Kernel neu zu starten und dafür zu sorgen, dass die Bibliothek für den Import verfügbar ist.
Führen Sie den folgenden Code in einer neuen Notebook-Zelle aus, um die Pipeline zu definieren:
from kfp import dsl # define the train-deploy pipeline @dsl.pipeline(name="custom-image-classification-pipeline") def custom_image_classification_pipeline( project: str, training_job_display_name: str, worker_pool_specs: list, base_output_dir: str, model_artifact_uri: str, prediction_container_uri: str, model_display_name: str, endpoint_display_name: str, network: str = '', location: str="us-central1", serving_machine_type: str="n1-standard-4", serving_min_replica_count: int=1, serving_max_replica_count: int=1 ): from google_cloud_pipeline_components.types import artifact_types from google_cloud_pipeline_components.v1.custom_job import CustomTrainingJobOp from google_cloud_pipeline_components.v1.model import ModelUploadOp from google_cloud_pipeline_components.v1.endpoint import (EndpointCreateOp, ModelDeployOp) from kfp.dsl import importer # Train the model task custom_job_task = CustomTrainingJobOp( project=project, display_name=training_job_display_name, worker_pool_specs=worker_pool_specs, base_output_directory=base_output_dir, location=location, network=network ) # Import the model task import_unmanaged_model_task = importer( artifact_uri=model_artifact_uri, artifact_class=artifact_types.UnmanagedContainerModel, metadata={ "containerSpec": { "imageUri": prediction_container_uri, }, }, ).after(custom_job_task) # Model upload task model_upload_op = ModelUploadOp( project=project, display_name=model_display_name, unmanaged_container_model=import_unmanaged_model_task.outputs["artifact"], ) model_upload_op.after(import_unmanaged_model_task) # Create Endpoint task endpoint_create_op = EndpointCreateOp( project=project, display_name=endpoint_display_name, ) # Deploy the model to the endpoint ModelDeployOp( endpoint=endpoint_create_op.outputs["endpoint"], model=model_upload_op.outputs["model"], dedicated_resources_machine_type=serving_machine_type, dedicated_resources_min_replica_count=serving_min_replica_count, dedicated_resources_max_replica_count=serving_max_replica_count, )Führen Sie den folgenden Code in einer neuen Notebookzelle aus, um die Pipelinedefinition zu kompilieren:
from kfp import compiler PIPELINE_FILE = "pipeline_config.yaml" compiler.Compiler().compile( pipeline_func=custom_image_classification_pipeline, package_path=PIPELINE_FILE, )Im Dateibrowser wird in der Dateiliste eine Datei namens
pipeline_config.yamlangezeigt.
Artifact Registry-Repository erstellen
Führen Sie den folgenden Code in einer neuen Notebookzelle aus, um ein Artefakt-Repository vom Typ KFP zu erstellen:
REPO_NAME="fungi-repo" REGION="us-central1" !gcloud artifacts repositories create $REPO_NAME --location=$REGION --repository-format=KFP
Pipelinevorlage in Artifact Registry hochladen
In diesem Abschnitt konfigurieren Sie einen Registry-Client des Kubeflow Pipelines SDK und laden Ihre kompilierte Pipelinevorlage aus Ihrem JupyterLab-Notebook in Artifact Registry hoch.
Führen Sie in Ihrem JupyterLab-Notebook den folgenden Code aus, um die Pipeline-Vorlage hochzuladen. Ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
PROJECT_ID = "PROJECT_ID" from kfp.registry import RegistryClient host = f"https://{REGION}-kfp.pkg.dev/{PROJECT_ID}/{REPO_NAME}" client = RegistryClient(host=host) TEMPLATE_NAME, VERSION_NAME = client.upload_pipeline( file_name=PIPELINE_FILE, tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})Rufen Sie in der Google Cloud Console die Seite Vertex AI Pipelines-Vorlagen auf, um zu prüfen, ob Ihre Vorlage hochgeladen wurde.
Klicken Sie zum Öffnen des Bereichs Repository auswählen auf Repository auswählen.
Klicken Sie in der Repository-Liste auf das von Ihnen erstellte Repository (
fungi-repo) und dann auf Auswählen.Prüfen Sie, ob Ihre Pipeline (
custom-image-classification-pipeline) in der Liste aufgeführt ist.
Pipelineausführung lokal auslösen
In diesem Abschnitt verwenden Sie cURL, um einen Pipelineausführung über Ihre lokale Anwendung auszulösen, nachdem Sie die Pipeline-Vorlage und das Trainingspaket erstellt haben.
Pipelineparameter angeben
Führen Sie in Ihrem JupyterLab-Notebook den folgenden Befehl aus, um den Namen der Pipeline-Vorlage zu prüfen:
print (TEMPLATE_NAME)Der zurückgegebene Name der Vorlage lautet:
custom-image-classification-pipelineFühren Sie den folgenden Befehl aus, um die Version der Pipeline-Vorlage abzurufen:
print (VERSION_NAME)Der zurückgegebene Name der Pipeline-Vorlageversion sieht so aus:
sha256:41eea21e0d890460b6e6333c8070d7d23d314afd9c7314c165efd41cddff86c7Notieren Sie sich den gesamten String mit dem Versionsnamen.
Führen Sie in der Cloud Shell die folgenden Befehle aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:
projectid=PROJECT_ID gcloud config set project ${projectid}Melden Sie sich bei der VM-Instanz
on-prem-dataservice-hostan:gcloud compute ssh on-prem-dataservice-host \ --zone=us-central1-a \ --tunnel-through-iapVerwenden Sie auf der VM-Instanz
on-prem-dataservice-hosteinen Texteditor wievimodernano, um die Dateirequest_body.jsonzu erstellen, z. B.:sudo vim request_body.jsonFügen Sie der Datei
request_body.jsonden folgenden Text hinzu:{ "displayName": "fungi-image-pipeline-job", "serviceAccount": "onprem-user-managed-sa@PROJECT_ID.iam.gserviceaccount.com", "runtimeConfig":{ "gcsOutputDirectory":"gs://pipelines-staging-bucket-PROJECT_ID/pipeline_root/", "parameterValues": { "project": "PROJECT_ID", "training_job_display_name": "fungi-image-training-job", "worker_pool_specs": [{ "machine_spec": { "machine_type": "n1-standard-4" }, "replica_count": 1, "python_package_spec":{ "executor_image_uri":"us-docker.pkg.dev/vertex-ai/training/tf-cpu.2-8.py310:latest", "package_uris": ["gs://pipelines-staging-bucket-PROJECT_ID/training_package/trainer-0.1.tar.gz"], "python_module": "trainer.task", "args": ["--data-dir","/mnt/nfs/fungi_dataset/", "--epochs", "10"], "env": [{"name": "AIP_MODEL_DIR", "value": "gs://pipelines-staging-bucket-PROJECT_ID/model/"}] }, "nfs_mounts": [{ "server": "FILESTORE_INSTANCE_IP", "path": "/vol1", "mount_point": "/mnt/nfs/" }] }], "base_output_dir":"gs://pipelines-staging-bucket-PROJECT_ID", "model_artifact_uri":"gs://pipelines-staging-bucket-PROJECT_ID/model/", "prediction_container_uri":"us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest", "model_display_name":"fungi-image-model", "endpoint_display_name":"fungi-image-endpoint", "location": "us-central1", "serving_machine_type":"n1-standard-4", "network":"projects/PROJECT_NUMBER/global/networks/vertex-networking-vpc" } }, "templateUri": "https://us-central1-kfp.pkg.dev/PROJECT_ID/fungi-repo/custom-image-classification-pipeline/latest", "templateMetadata": { "version":"VERSION_NAME" } }Ersetzen Sie die folgenden Werte:
- PROJECT_ID: Ihre Projekt-ID.
- PROJECT_NUMBER: die Projektnummer Diese unterscheidet sich von der Projekt-ID. Sie finden die Projektnummer in der Google Cloud Console auf der Seite Projekteinstellungen des Projekts.
- FILESTORE_INSTANCE_IP: die IP-Adresse der Filestore-Instanz, z. B.
10.243.208.2. Sie finden diese auf der Seite „Filestore-Instanzen“ für Ihre Instanz. - VERSION_NAME: Der Name der Pipeline-Vorlagenversion (
sha256:...), den Sie sich in Schritt 2 notiert haben.
Speichern Sie die Datei so:
- Wenn Sie
vimverwenden, drücken Sie die TasteEscund geben Sie dann:wqein, um die Datei zu speichern und zu beenden. - Wenn Sie
nanoverwenden, geben SieControl+Oein und drücken SieEnter, um die Datei zu speichern. Geben Sie dann zum BeendenControl+Xein.
- Wenn Sie
Pipelineausführung aus Ihrer Vorlage senden
Führen Sie in der VM-Instanz
on-prem-dataservice-hostden folgenden Befehl aus und ersetzen Sie dabei PROJECT_ID durch Ihre Projekt-ID:curl -v -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json; charset=utf-8" \ -d @request_body.json \ https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/pipelineJobsDie Ausgabe ist lang, aber Sie sollten vor allem auf die folgende Zeile achten, die angibt, dass der Dienst sich vorbereitet, die Pipeline auszuführen:
"state": "PIPELINE_STATE_PENDING"Die gesamte Pipelineausführung dauert etwa 45 bis 50 Minuten.
Rufen Sie in der Google Cloud Console im Abschnitt Vertex AI auf der Seite Pipelines den Tab Ausführungen auf.
Klicken Sie auf den Namen der Pipeline-Ausführung (
custom-image-classification-pipeline).Die Seite zum Ausführen der Pipeline wird angezeigt und zeigt die Laufzeitgrafik der Pipeline an. Die Zusammenfassung der Pipeline wird im Bereich Pipelineausführungsanalyse angezeigt.
Weitere Informationen zu den im Laufzeitdiagramm angezeigten Informationen, und der Möglichkeit, Logs aufzurufen und Vertex ML Metadata zu verwenden, um mehr über die Artefakte Ihrer Pipeline zu erfahren, finden Sie unter Pipelineergebnisse visualisieren und analysieren.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Sie können die einzelnen Ressourcen im Projekt so löschen:
So löschen Sie alle Pipelineausführungen:
Rufen Sie in der Google Cloud Console im Abschnitt Vertex AI auf der Seite Pipelines den Tab Ausführungen auf.
Wählen Sie die zu löschenden Pipelineausführungen aus und klicken Sie auf Löschen.
So löschen Sie die Pipelinevorlage:
Rufen Sie auf der Seite Pipelines im Abschnitt Vertex AI den Tab Meine Vorlagen auf.
Klicken Sie neben der Pipeline-Vorlage
custom-image-classification-pipelineauf Aktionen und wählen Sie Löschen aus.
So löschen Sie das Repository aus Artifact Registry:
Rufen Sie auf der Seite Artifact Registry den Tab Repositories auf.
Wählen Sie das Repository
fungi-repoaus und klicken Sie auf Löschen.
Heben Sie die Bereitstellung des Modells am Endpunkt so auf:
Rufen Sie im Abschnitt Vertex AI den Tab Endpunkte auf der Seite Onlinevorhersagen auf.
Klicken Sie auf
fungi-image-endpoint, um die Seite „Endpunktdetails“ aufzurufen.Klicken Sie in der Zeile für das Modell auf
fungi-image-model, dann auf Aktionen und wählen Sie Bereitstellung des Modells am Endpunkt aufheben aus.Klicken Sie im Dialogfeld Bereitstellung des Endpunkts aufheben auf Bereitstellung aufheben.
So löschen Sie den Endpunkt:
Rufen Sie im Abschnitt Vertex AI den Tab Endpunkte auf der Seite Onlinevorhersagen auf.
Wählen Sie
fungi-image-endpointaus und klicken Sie auf Löschen.
Löschen Sie das Modell so:
Zur Seite Model Registry
Klicken Sie in der Zeile für Ihr Modell
fungi-image-modelauf Aktionen und wählen Sie Modell löschen aus.
Löschen Sie den Staging-Bucket so:
Gehen Sie zur Seite Cloud Storage
Wählen Sie
pipelines-staging-bucket-PROJECT_IDaus, wobei PROJECT_ID die Projekt-ID ist, und klicken Sie auf Löschen.
Löschen Sie die Vertex AI Workbench-Instanz so:
Rufen Sie auf der Seite Workbench im Abschnitt Vertex AI den Tab Instanzen auf.
Wählen Sie die Vertex AI Workbench-Instanz
pipeline-tutorial-PROJECT_IDaus, wobei PROJECT_ID die Projekt-ID ist, und klicken Sie auf Löschen.
Löschen Sie die Compute Engine-VM-Instanz so:
Zur Seite "Compute Engine"
Wählen Sie die VM-Instanz
on-prem-dataservice-hostaus und klicken Sie auf Löschen.
Löschen Sie die VPN-Tunnel so:
Zur VPN-Seite
Klicken Sie auf der Seite VPN auf den Tab Cloud VPN-Tunnel.
Wählen Sie in der Liste der VPN-Tunnel die vier VPN-Tunnel aus, die Sie in dieser Anleitung erstellt haben, und klicken Sie auf Löschen.
Löschen Sie die HA VPN-Gateways so:
Klicken Sie auf der Seite VPN auf den Tab Cloud VPN-Gateways.
Klicken Sie in der Liste der VPN-Gateways auf
onprem-vpn-gw1.Klicken Sie auf der Seite Details zum Cloud VPN-Gateway auf VPN-Gateway löschen.
Klicken Sie bei Bedarf auf den Zurückpfeil, um zur Liste der VPN-Gateways zurückzukehren, und klicken Sie dann auf
vertex-networking-vpn-gw1.Klicken Sie auf der Seite Details zum Cloud VPN-Gateway auf VPN-Gateway löschen.
Löschen Sie die Cloud Router so:
Wechseln Sie zur Seite Cloud Router.
Wählen Sie in der Liste der Cloud Router die vier Router aus, die Sie in dieser Anleitung erstellt haben.
Klicken Sie zum Löschen der Router auf Löschen.
Dadurch werden auch die beiden Cloud NAT-Gateways gelöscht, die mit den Cloud Routern verbunden sind.
Löschen Sie die Dienstnetzwerkverbindungen zu den VPC-Netzwerken
vertex-networking-vpcundonprem-dataservice-vpcso:Zur Seite "VPC-Netzwerk-Peering"
Wählen Sie
servicenetworking-googleapis-comaus.Klicken Sie auf Löschen, um die Verbindungen zu löschen.
Löschen Sie so die Weiterleitungsregel
pscvertexfür das VPC-Netzwerkvertex-networking-vpc:Wechseln Sie auf der Seite Load Balancing zum Tab Front-Ends.
Klicken Sie in der Liste der Weiterleitungsregeln auf
pscvertex.Klicken Sie auf der Seite Details zu Globale Weiterleitungsregel auf Löschen.
So löschen Sie die Filestore-Instanz:
Filestore-Seite aufrufen
Wählen Sie die Instanz
image-data-instanceaus.Klicken Sie zum Löschen der Instanz auf Aktionen und dann auf Instanz löschen.
Löschen Sie die VPC-Netzwerke so:
Rufen Sie die Seite VPC-Netzwerke auf.
Klicken Sie in der Liste der VPC-Netzwerke auf
onprem-dataservice-vpc.Klicken Sie auf der Seite VPC-Netzwerkdetails auf VPC-Netzwerk löschen.
Durch das Löschen des jeweiligen Netzwerks werden auch die zugehörigen Subnetzwerke, Routen und Firewallregeln gelöscht.
Klicken Sie in der Liste der VPC-Netzwerke auf
vertex-networking-vpc.Klicken Sie auf der Seite VPC-Netzwerkdetails auf VPC-Netzwerk löschen.
Löschen Sie die Dienstkonten
workbench-saundonprem-user-managed-saso:Rufen Sie die Seite Dienstkonten auf.
Wählen Sie die Dienstkonten
onprem-user-managed-saundworkbench-saaus und klicken Sie auf Löschen.
Nächste Schritte
Informationen zum Orchestrating des Prozesses zum Erstellen und Bereitstellen von Modellen für maschinelles Lernen mit Vertex AI Pipelines