本文档是系列文章中的一篇,该系列提供了有关规划和执行 Oracle® 11g/12c 数据库到 Cloud SQL for PostgreSQL 版本 12 的迁移的关键信息和指导。除了设置简介部分之外,本系列文章还包括以下部分:
- 将 Oracle 用户迁移到 Cloud SQL for PostgreSQL:术语和功能(本文档)
- 将 Oracle 用户迁移到 Cloud SQL for PostgreSQL:数据类型、用户和表
- 将 Oracle 用户迁移到 Cloud SQL for PostgreSQL:查询、存储过程、函数和触发器
- 将 Oracle 用户迁移到 Cloud SQL for PostgreSQL:安全、操作、监控和日志记录
- 将 Oracle 数据库用户和架构迁移到 Cloud SQL for PostgreSQL
术语
本部分详细介绍了 Oracle 与 Cloud SQL for PostgreSQL 在数据库术语方面的异同。它回顾和比较了每个数据库平台的核心方面。由于架构上的差异(例如 Oracle 12c 引入了多租户功能),比较针对 Oracle 11g 和 12c 版本进行了区分。此处参考的 Cloud SQL for PostgreSQL 版本为 12。
本部分重点介绍 Oracle 与 Cloud SQL for PostgreSQL 在术语上的主要差异。本文档后面会进行详细介绍。
| Oracle 11g | 说明 | Cloud SQL for PostgreSQL | 主要区别 |
|---|---|---|---|
| instance | 一个 Oracle 11g 实例只能保存一个数据库。 | instance | 一个 Cloud SQL for PostgreSQL 实例只托管一个数据库集群。数据库集群是存储在共同数据区域中的数据库的集合。 |
| 数据库 | 数据库可用作单个实例(数据库的名称与实例名称相同)。 | 数据库 | 多个或单个数据库服务于多个应用。 |
| schema | 架构和用户是相同的,因为它们都被视为数据库对象的所有者(可在不指定架构或分配给架构的情况下创建用户)。 | schema | 一个数据库包含一个或多个架构。架构中包含对象(例如表)。可以在同一数据库的不同架构中使用相同的对象名称,而不会产生冲突。 |
| 用户 | 与架构相同,因为这两者都是数据库对象的所有者(例如实例 → 数据库 → 架构/用户 → 数据库对象)。 | role | 角色可以是一个数据库用户或一组数据库用户,具体取决于其设置方式。角色可以拥有数据库对象(例如表)。 角色的范围为整个数据库集群,并且可以将角色的成员资格授予其他角色。 |
| role | 定义的一组数据库权限,可链接为一个组并分配给数据库用户 | ||
| 管理员/ 系统用户 |
具有最高级别的访问权限的 Oracle 管理员用户:SYS |
cloudsqlsuperuser | Cloud SQL for PostgreSQL 提供默认 postgres 用户。此用户是 cloudsqlsuperuser 角色的一部分,拥有以下属性(权限):CREATEROLE、CREATEDB、LOGIN。由于 Cloud SQL for PostgreSQL 是一项代管式服务,因此它会限制对需要高级权限的特定系统过程和表的访问。因此, postgres 用户没有 SUPERUSER 或 REPLICATION 属性。您无法创建或访问具有 superuser 属性的用户。 |
| 字典/ 元数据 |
Oracle 使用以下元数据表:USER_TableName |
字典/ 元数据 |
Cloud SQL for PostgreSQL 使用 ANSI 标准 INFORMATION_SCHEMA 来提供字典和元数据信息。 |
| 系统动态视图 | Oracle 动态视图:V$ViewName |
系统 动态视图 |
Cloud SQL for PostgreSQL 具有以下动态统计信息视图:pg_stat_ViewNamepg_statio_ViewName |
| tablespace | Oracle 数据库的主要逻辑存储结构;每个表空间可以保存一个或多个数据文件。 | tablespace | 在 Cloud SQL for PostgreSQL 中,使用预定义的目录结构将数据文件一起存储在数据库集群的数据目录 PGDATA 中。Cloud SQL for PostgreSQL 中的表空间提供了一种机制,可在存储数据文件的文件系统中定义自定义位置。由于 Cloud SQL for PostgreSQL 是一项代管式服务,因此 Google Cloud 会为您管理主机的底层文件系统。您无法在 Cloud SQL for PostgreSQL 上创建新的表空间。 |
| 数据文件 | Oracle 数据库的物理元素, 它们用于保存数据且在特定表空间下进行定义。 单个数据文件按初始大小和最大大小来定义,可保存多个表的数据。 Oracle 数据文件使用 .dbf 后缀(可选)。 |
数据文件 | Cloud SQL for PostgreSQL 将数据库集群中的每个数据库存储在其各自的子目录中。数据库中的每个表和索引都存储在该子目录中的单独文件中。 |
| 系统表空间 | 包含整个 Oracle 数据库的数据字典表和视图对象。 | 不存在 | 使用预定义的目录结构将数据字典表和视图对象存储在数据库集群的数据目录 PGDATA 的 INFORMATION_SCHEMA 中。 |
| 临时表空间 | 包含在会话期间有效的架构对象;此外, 它还支持运行不适合服务器内存的操作。 |
临时文件 | 临时文件用于存储不适合服务器内存的运行中的操作。这些文件存储在名为 pgsql_tmp 的目录中,并且仅在 SQL 语句执行时创建。 |
| 撤消表空间 | 一种特殊类型的系统永久表空间, 在自动撤消管理模式(默认设置)下运行数据库时,Oracle 用它来管理回滚操作。 |
不存在 | 为了允许回滚操作,Cloud SQL for PostgreSQL 会保留在表的数据文件中更新或删除的行。清空是恢复或重用已更新或已删除的行占用的磁盘空间的过程。 |
| ASM | Oracle 存储空间自动管理是一个集成的高性能数据库文件系统和磁盘管理器,均由使用 ASM 配置的 Oracle 数据库自动运行。 | 不支持 | Cloud SQL for PostgreSQL 依赖操作系统文件系统来存储数据文件,没有等效于 Oracle ASM 的功能。但是,Cloud SQL for PostgreSQL 支持许多可实现存储自动化(例如存储空间自动扩容)、性能和可伸缩性的功能。 |
| 表/视图 | 用户创建的基本数据库对象。 | 表/视图 | 与 Oracle 相同。 |
| 具体化视图 | 使用特定 SQL 语句定义, 可以根据特定配置手动或自动刷新。 |
具体化视图 | 具体化视图的工作方式与 Oracle 类似。使用 REFRESH
MATERIALIZED VIEW 语句手动进行刷新。 |
| 序列 | Oracle 唯一值生成器。 | 序列 | 与 Oracle 类似。 |
| 同义词 | 充当其他数据库对象的备用标识符的 Oracle 数据库对象。 | 不支持 | Cloud SQL for PostgreSQL 不提供同义词;解决方法是在设置适当的权限时使用视图 |
| 分区 | Oracle 提供了许多分区解决方案,用于将大型表拆分为较小的托管部分。 | 分区 | Cloud SQL for PostgreSQL 支持 Oracle 样式的声明式分区和使用继承进行分区,从而提供更大的分区灵活性。 |
| 闪回数据库 | Oracle 专有功能,可用于将 Oracle 数据库初始化到先前定义的时间,从而查询或恢复被意外修改或损坏的数据。 | 不支持 | 替代解决方案是,您可以使用 Cloud SQL 备份和时间点恢复将数据库恢复到先前的状态(例如在删除表之前恢复)。 |
| sqlplus | Oracle 命令行界面,可用于查询和管理数据库实例。 | psql | 用于查询和管理的 Cloud SQL for PostgreSQL 等效命令行界面。可以从任何具有相应权限的客户端连接到 Cloud SQL。 |
| PL/SQL | Oracle 扩展了过程语言,使其涵盖 ANSI SQL。 | PL/pgSQL | Cloud SQL for PostgreSQL 有自己的过程语言,称为 PL/pgSQL,在很多方面与 Oracle 的 PL/SQL 类似。有关这两种语言的主要区别的总结,请参阅从 Oracle SQL/SQL 移植。 |
| 包头和包体 | Oracle 专属功能,可将存储过程和函数分组到同一逻辑引用下。 | 不支持 | Cloud SQL for PostgreSQL 使用架构来组织函数。 |
| 存储过程和函数 | 使用 PL/SQL 实现代码功能。 | 存储过程和函数 | Cloud SQL for PostgreSQL 支持使用各种编程语言(例如 PL/pgSQL 和 C)实现存储过程和函数。 |
| 触发器 | 用于控制表的 DML 实现的 Oracle 对象。 | 触发器 | 与 Oracle 类似。 |
| PFILE/SPFILE | Oracle 实例和数据库级参数保存在被称为 SPFILE 的二进制文件中(在之前的版本中,该文件被称为 PFILE),该文件可作为用于手动设置参数的文本文件。 |
Cloud SQL for PostgreSQL 数据库标志 | 您可以通过数据库标志实用程序设置或修改 Cloud SQL for PostgreSQL 参数。 |
| SGA/PGA/ AMM |
Oracle 内存参数,用于控制对数据库实例的内存分配。 | 各种内存相关参数 | Cloud SQL for PostgreSQL 有自己的内存参数。类似的参数包括 shared_buffers、temp_buffers 和 work_mem。在 Cloud SQL for PostgreSQL 中,这些参数由所选实例类型预定义,并且值会相应地更改。您可以使用数据库标志实用程序调整某些参数。 |
| 缓冲区缓存 | 通过从缓冲区缓存中检索缓存的数据来减少 SQL I/O 操作。可以通过查询提示在数据库级别和会话级别管理内存参数。 | 类似功能 | Cloud SQL for PostgreSQL 的缓冲区缓存大小由 shared_buffer 参数控制,该参数不在 Cloud SQL 中公开。Cloud SQL 提供内存用量指标,用于合理调整实例大小。 |
| 数据库提示 | Oracle 控制对 SQL 语句的影响的功能,这些语句会影响优化器的行为来提升性能。Oracle 具有 50 多个不同的数据库提示。 | 不支持 | Cloud SQL for PostgreSQL 不支持数据库提示。您可以使用显式 JOIN 语法有限地控制 Cloud SQL for PostgreSQL 的查询规划器。 |
| RMAN | Oracle 恢复管理器实用程序。用于通过扩展功能实现数据库备份,进而支持多个灾难恢复场景等(例如克隆)。 | Cloud SQL for PostgreSQL 备份 | Cloud SQL for PostgreSQL 提供了两种应用完整备份的方法:按需备份和自动备份。 |
| 数据转储 (EXPDP/ IMPDP) |
Oracle 转储生成实用程序,可用于导出/导入、数据库备份(在架构或对象级别)、架构元数据、生成架构 SQL 文件等诸多功能。 | Cloud SQL for PostgreSQL 导出/导入 | Cloud SQL for PostgreSQL 提供两种与 Cloud Storage 存储桶之间的导出/导入格式:SQL 和 CSV。 或者,您也可以使用 pg_dump 等导出/导入实用程序连接到数据库实例。 |
| SQL*Loader | 此工具可让您上传外部文件(例如文本文件、CSV 文件等)中的数据。 | psql \copy |
借助 psql 客户端中的 \copy 命令,您可以将文本、CSV 或二进制文件(Oracle 支持其他文件格式)加载到具有相应结构的数据库表中。 |
| Data Guard | 使用备用实例的 Oracle 灾难恢复解决方案,用户可用它从备用实例执行 READ 操作。 |
Cloud SQL for PostgreSQL 高可用性和复制功能 | 为了实现灾难恢复或高可用性,Cloud SQL for PostgreSQL 提供故障切换副本架构,对于只读操作(READ/WRITE 分离)使用读取副本。 |
| Active Data Guard/ GoldenGate |
Oracle 的主要复制解决方案,支持备用 (DR)、只读实例、双向复制(多主实例)和数据仓储等多种用途。 | Cloud SQL for PostgreSQL 读取副本 | Cloud SQL for PostgreSQL 读取副本,用于实现读取/写入分离的聚类。目前,不支持 GoldenGate 双向复制或异构复制等多主实例配置。 |
| RAC | Oracle 真正应用集群。Oracle 专有聚类解决方案,通过部署具有单个存储单元的多个数据库实例来提供高可用性。 | 不支持 | Cloud SQL for PostgreSQL 不支持多主实例架构。Cloud SQL for PostgreSQL 通过备用实例提供高可用性,并通过读取副本提高读取可伸缩性。 |
| Grid/Cloud Control (OEM) | Oracle 软件,用于管理和监控 Web 应用格式的数据库和其他相关服务。此工具可用于实时分析数据库来了解使用频繁的工作负载。 | Google Cloud 控制台, Cloud Monitoring |
使用 Cloud SQL for PostgreSQL 进行监控,包括基于时间和基于资源的详细图表。此外,还可使用 Cloud Monitoring 保存特定的 Cloud SQL for PostgreSQL 监控指标和日志分析来实现高级监控功能。 |
| 重做日志 | Oracle 事务日志,包含两个(或更多)预分配且已定义的文件,这些文件用于在发生数据修改时存储所有数据修改。重做日志旨在实例失败时保护数据库。 | WAL 日志 | Cloud SQL for PostgreSQL 使用预写式日志记录 (WAL),以便将数据文件的更改刷入永久存储空间中,用于崩溃恢复。 |
| 归档日志 | 归档日志提供了对备份和复制等操作的支持。Oracle 在每次重做日志切换操作后写入归档日志(若已启用)。 | WAL 归档 | WAL 日志保留的 Cloud SQL for PostgreSQL 实现。WAL 归档随时间点恢复启用和使用。 |
| 控制文件 | Oracle 控制文件保存数据库的相关信息,例如数据文件、重做日志名称、位置、当前日志序列号,以及实例检查点信息。 | PGDATA and pg_control
|
Cloud SQL for PostgreSQL 架构没有等效于 Oracle 控制文件的概念。数据库相关的文件保存在通常成为 PGDATA 的目录中。与记录和检查点相关的 WAL 信息存储在 pg_control 中。 |
| 系统更改编号 (SCN) | SCN 标记 Oracle 数据库中的特定时间点。 | 日志序列号 (LSN) | Cloud SQL for PostgreSQL 中的等效功能是 LSN。像 SCN 一样,LSN 随时间单调递增。 |
| AWR | Oracle AWR(自动工作负载代码库)是一份详细报告,提供有关 Oracle 数据库实例性能的详细信息,被视为用于性能诊断的 DBA 工具。 | 统计信息收集器 | Cloud SQL for PostgreSQL 没有等效于 Oracle AWR 的报告,但 PostgreSQL 会收集统计信息收集器收集的性能数据。收集的统计信息通过 pg_stat_* 和 pg_statio_* 视图公开。 |
DBMS_SCHEDULER
|
Oracle 实用程序用于设置预定义操作并为其设置时间。 | 不支持 | Cloud SQL for PostgreSQL 不提供内置的计划实用程序。 Google Cloud 提供 Cloud Scheduler,让您能够安排数据库任务(例如导出)。 |
| 透明数据加密 | 加密存储在磁盘上的数据,作为静态数据保护。 | Cloud SQL 高级加密标准 | Cloud SQL for PostgreSQL 使用 256 位高级加密标准 (AES-256) 来保护静态数据和传输中的数据。 |
| 高级压缩 | 为了减少占用的数据库存储空间、降低存储费用和提升数据库性能,Oracle 提供了数据(表/索引)高级压缩功能。 | TOAST | Cloud SQL for PostgreSQL 使用名为 TOAST 的基础架构来自动和透明地压缩单个数据页无法容纳的可变长度数据,但此基础架构并不直接相当于 Oracle 高级压缩。 |
| SQL Developer | Oracle 的免费 SQL GUI,用于管理和运行 SQL 和 PL/SQL 语句。 | pgAdmin | Cloud SQL for PostgreSQL 的免费 SQL GUI,用于管理和运行 SQL 和 PostgreSQL 代码语句。 |
| 提醒日志 | Oracle 的主日志,用于记录一般数据库操作和错误。 | PostgreSQL 错误报告和日志记录 | 使用 Cloud Logging 的日志查看器检查 PostgreSQL 错误日志。 |
| DUAL 表 | Oracle 特殊表,用于检索伪列值,例如 SYSDATE 或 USER |
不存在 | Cloud SQL for PostgreSQL 允许在 SQL 语句中省略 FROM 子句。例如:SELECT NOW();
是 PostgreSQL 中的有效语句。 |
| 外部表 | Oracle 允许用户创建其源数据位于数据库外部文件中的外部表。 | 不支持 | 作为托管式服务,Cloud SQL for PostgreSQL 不公开运行数据库实例的主机的底层文件系统。 要解决此问题,您可以将源数据导入 PostgreSQL 表以查询数据。 |
| Listener | Oracle 网络进程,负责侦听传入的数据库连接。 | Cloud SQL 授权网络 | 在 Cloud SQL 授权网络配置页面中允许来自远程来源的连接后,Cloud SQL for PostgreSQL 可接受来自远程来源的连接。 |
| TNSNAMES | 用于定义数据库地址的 Oracle 网络配置文件,便于使用连接别名建立连接。 | 不存在 | Cloud SQL for PostgreSQL 接受使用 Cloud SQL 实例连接名称或专用/公共 IP 地址的外部连接。Cloud SQL 代理是一种额外的安全访问方法,您无需允许特定的 IP 地址或配置 SSL 即可使用该代理连接到 Cloud SQL for PostgreSQL。 |
| 实例默认端口 | 1521 | 实例默认端口 | 5432 |
| 数据库链接 | Oracle 架构对象,可用于与本地/远程数据库对象进行交互。 | 外部数据封装容器 (FDW) | Cloud SQL for PostgreSQL 中的 postgres_fdw 扩展程序允许其他(“外部”)PostgreSQL 数据库中的表在当前数据库中公开为“外部”表。然后,这些表就可以使用了,就好像它们是本地表一样。 |
Oracle 12c 与 Cloud SQL for PostgreSQL 之间的术语差异
| Oracle 12c | 说明 | Cloud SQL for PostgreSQL | 主要区别 |
|---|---|---|---|
| 实例 | 在 Oracle 12c 中引入的多租户功能,允许一个实例将多个数据库作为可插入数据库 (PDB) 托管,而在 Oracle 11g 中,一个 Oracle 实例只能托管一个数据库。 | 实例 | 一个 Cloud SQL for PostgreSQL 实例只托管一个数据库集群。数据库集群是存储在共同数据区域中的数据库的集合。 |
| CDB | 多租户容器数据库 (CDB) 可支持一个或多个 PDB,还可创建角色等 CDB 全局对象(可影响所有 PDB)。 | PostgreSQL 实例 | Cloud SQL for PostgreSQL 实例类似于 Oracle CDB。两者都为托管数据库提供系统层。 |
| PDB | PDB(可插入数据库)可用于将服务和应用彼此隔离,并可用作可移植的架构集合。 | PostgreSQL 数据库/ 架构 |
一个 Cloud SQL for PostgreSQL 数据库可同时为多个服务和应用以及多个数据库用户提供服务。 |
| 会话序列 | 从 Oracle 12c 开始,您可以在会话级别(仅在会话中返回唯一值)或全局级别(例如使用临时表时)创建序列。 | 临时序列 | 系统会为当前数据库会话创建临时序列,并在会话退出时自动丢弃此序列。 |
| 身份列 | Oracle 12c IDENTITY 类型会生成序列并将它与表列相关联,无需您手动创建单独的序列对象。 |
SERIAL 列 | 通过将列的数据类型定义为 SERIAL,Cloud SQL for PostgreSQL 会自动创建序列,并在新行插入表中时使用该序列填充列值。 |
| 分片 | Oracle 分片是一种解决方案;在该方案中,一个 Oracle 数据库被分区到多个较小的数据库中(分片),以支持 OLTP 环境的可伸缩性、可用性和地理位置分布。 | 不受支持(作为一项功能) | Cloud SQL for PostgreSQL 没有等效的分片功能。可以使用具有支持应用层的 Cloud SQL for PostgreSQL(作为数据平台)来实现分片。 |
| 内存中数据库 | Oracle 提供了一系列功能,可提高 OLTP 以及混合工作负载的数据库性能。 | 不支持 | Cloud SQL for PostgreSQL 没有内置的等效功能。但是,您可以将我们的代管式 Redis 服务 Memorystore 用作替代方案。 |
| 隐去 | “隐去”属于 Oracle 高级安全功能,它可执行列遮盖操作,防止用户和应用检索敏感数据。 | 不支持 | Cloud SQL for PostgreSQL 没有内置的等效功能。不过,您可以使用 Sensitive Data Protection 对敏感数据进行去标识化处理。 |
功能
虽然 Oracle 11g/12c 和 Cloud SQL for PostgreSQL 数据库使用不同的架构(基础架构和扩展过程语言)构建,但它们在关系型数据库系统的基本方面是相同的。它们都支持数据库对象、多用户并发工作负载和具有 ACID 属性的事务。它们还管理支持多个隔离级别(根据应用的需求)的锁定争用,并满足应用对联机事务处理 (OLTP) 操作和联机分析处理 (OLAP) 的持续要求。
以下部分简要介绍 Oracle 与 Cloud SQL for PostgreSQL 之间的一些主要功能差异。在某些情况下,如果需要强调差异,本部分会包含详细的技术比较。
创建和查看现有数据库
| Oracle 11g/12c | Cloud SQL for PostgreSQL 12 |
|---|---|
您通常可以使用 Oracle 数据库创建助理 (DBCA) 实用程序创建数据库和查看现有数据库。手动创建的数据库或实例需要您指定其他参数:SQL> CREATE DATABASE ORADB |
使用 CREATE DATABASE Name; 形式的语句,如下例所示:postgres=> CREATE DATABASE PGSQLDB; |
| Oracle 12c | Cloud SQL for PostgreSQL 12 |
在 Oracle 12c 中,您可以通过种子创建 PDB,这通过容器数据库 (CDB) 模板或通过从现有 PDB 克隆 PDB 来实现。您可以使用多个参数:SQL> CREATE PLUGGABLE DATABASE PDB |
使用 CREATE DATABASE Name; 形式的语句,如下例所示:postgres=> CREATE DATABASE PGSQLDB; |
列出所有 PDB:SQL> SHOW is PDBS; |
列出所有现有数据库:postgres=> \list |
连接到其他 PDB:SQL> ALTER SESSION SET CONTAINER=pdb; |
连接到其他数据库:postgres=> \connect databaseName;
或: postgres=> \c databaseName |
打开或关闭特定 PDB(打开/只读):SQL> ALTER PLUGGABLE DATABASE pdb CLOSE; |
不支持单个数据库。 所有数据库都位于同一 Cloud SQL for PostgreSQL 实例下;因此,所有数据库均全部启动或全部关闭。 |
通过 Google Cloud 控制台管理数据库
在 Google Cloud 控制台中,转到数据库 > SQL > 实例 >(选择您的 PostgreSQL 实例)> 数据库。
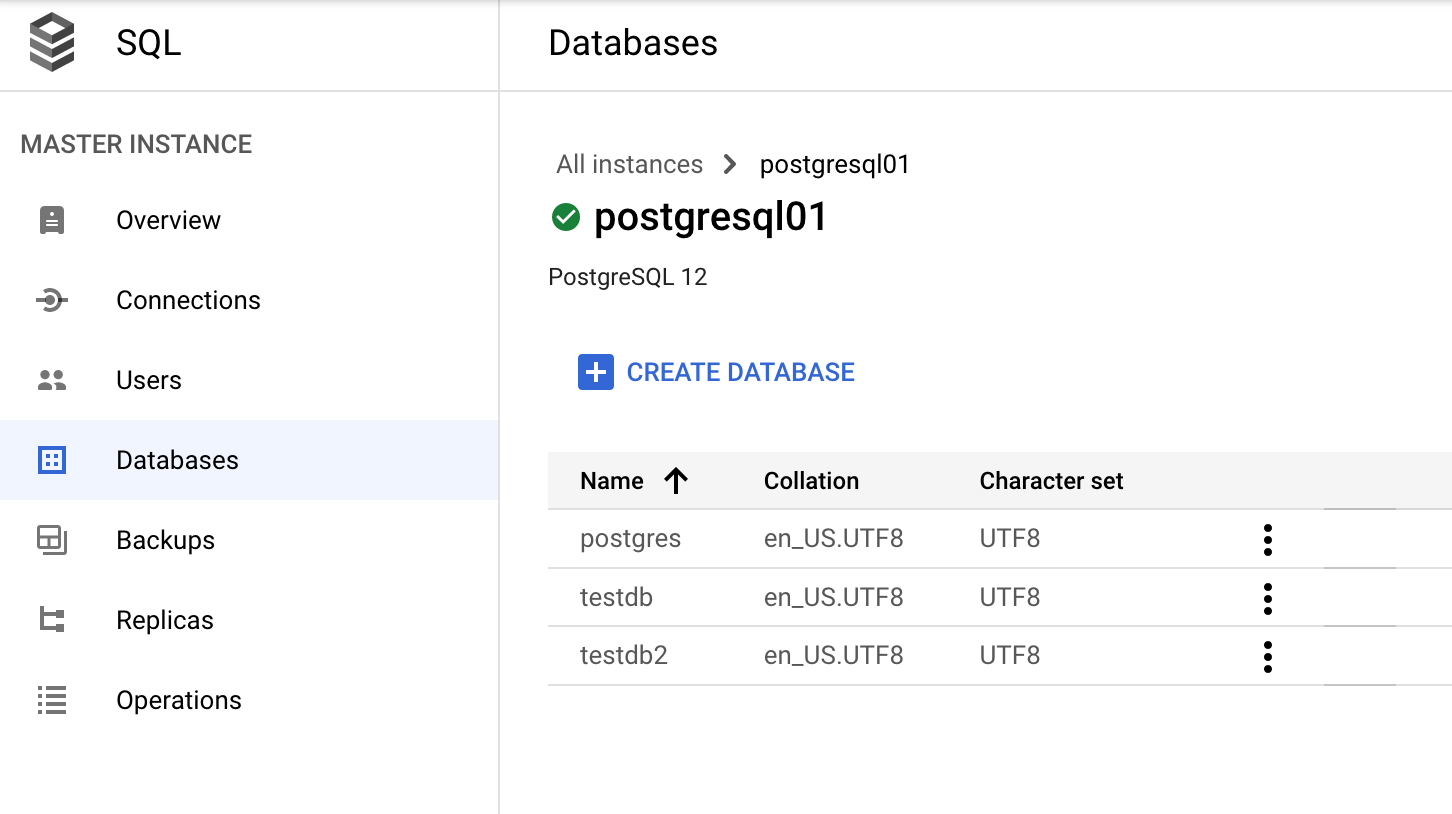
数据字典和动态视图
Oracle 数据库提供数据字典以及动态性能视图(V$ 视图),以协助各种数据库维护和监控任务。数据字典存储用于管理数据库中对象的所有信息,而动态性能视图包含与数据库性能相关的许多信息。这些视图会在数据库运行时持续更新。
相比之下,PostgreSQL 提供了多个元数据目录,其用途与 Oracle 的数据字典和动态性能视图类似:
- 系统目录:关于所有数据库对象的元数据。
- 统计信息收集视图:针对 PostgreSQL 的活动进行报告。
- 信息架构视图:关于根据 ANSI SQL 标准报告的所有数据库对象的元数据。
查看元数据和系统动态视图
本部分简要介绍 Oracle 中使用的一些最常见的元数据表和系统动态视图,以及它们在 Cloud SQL for PostgreSQL 12 中的对应数据库对象。
Oracle 提供数百个系统元数据表和视图(在某些系统架构中,例如 SYS 或 SYSTEM),而 PostgreSQL 只有数十个。在每种情况中,可以有多个数据库对象用于特定用途。
Oracle 提供多个级别的元数据对象,每个级别都需要不同的特权:
USER_TableName:该用户可以查看。ALL_TableName:所有用户都可以查看。DBA_TableName:拥有 DBA 权限(例如SYS和SYSTEM)的用户才可以查看。
对于动态性能视图,Oracle 使用 V$/GV$ 前缀。相比之下,Cloud SQL for PostgreSQL 元数据和视图位于 information_schema 和 pg_catalog 架构中。
| 元数据类型 | Oracle 表/视图 | Cloud SQL for PostgreSQL 表/视图/查询 |
|---|---|---|
| 开放会话 | V$SESSION |
pg_catalog.pg_stat_activity |
| 正在运行的事务 | V$TRANSACTION |
不受支持。解决方法是 pg_locks 提供包含一个或多个锁的未完成事务列表。 |
| 数据库对象 | DBA_OBJECTS |
pg_catalog.pg_class |
| 表 | DBA_TABLES |
pg_catalog.pg_tables |
| 表列 | DBA_TAB_COLUMNS |
pg_catalog.pg_attribute |
| 表和列特权 | TABLE_PRIVILEGES |
information_schema.table_privileges
information_schema.column_privileges |
| 分区 | DBA_TAB_PARTITIONS
DBA_TAB_SUBPARTITIONS |
pg_catalog.pg_partitioned_table |
| 视图 | DBA_VIEWS |
pg_catalog.pg_views |
| 限制条件 | DBA_CONSTRAINTS |
pg_catalog.pg_constraint |
| 索引 | DBA_INDEXES |
pg_catalog.pg_index |
| 具体化视图 | DBA_MVIEWS |
pg_catalog.pg_matviews |
| 存储过程 | DBA_PROCEDURES |
pg_catalog.pg_proc |
| 存储函数 | DBA_PROCEDURES |
pg_catalog.pg_proc |
| 触发器 | DBA_TRIGGERS |
pg_catalog.pg_trigger |
| 用户 | DBA_USERS |
pg_catalog.pg_user |
| 用户特权 | DBA_SYS_PRIVS |
pg_catalog.pg_roles |
| 作业/ 调度器 |
DBA_JOBS |
不受支持。 |
| 表空间 | DBA_TABLESPACES |
pg_catalog.pg_tablespace |
| 数据文件 | DBA_DATA_FILES |
不受支持。 |
| 同义词 | DBA_SYNONYMS |
不受支持。 |
| 序列 | DBA_SEQUENCES |
pg_catalog.pg_sequence |
| 数据库链接 | DBA_DB_LINKS |
pg_catalog.pg_foreign_server |
| 统计信息 | DBA_TAB_STATISTICS
DBA_TAB_COL_STATISTICS
DBA_SQLTUNE_STATISTICS
DBA_CPU_USAGE_STATISTICS |
pg_catalog.pg_stats |
| 锁定 | DBA_LOCK |
pg_catalog.pg_locks |
| 数据库参数 | V$PARAMETER |
pg_catalog.pg_settings
show |
| 细分 | DBA_SEGMENTS |
不受支持。 |
| 角色 | DBA_ROLES |
pg_catalog.pg_roles |
| 会话历史记录 | V$ACTIVE_SESSION_HISTORY |
不受支持。 |
| 版本 | V$VERSION |
select version(); |
| 等待事件 | V$WAITCLASSMETRIC |
不受支持。 |
| SQL 调整和 分析 |
V$SQL |
不受支持。 |
| 实例 内存调整 |
V$SGA
V$SGASTAT
V$SGAINFO
V$SGA_CURRENT_RESIZE_OPS
V$SGA_RESIZE_OPS
V$SGA_DYNAMIC_COMPONENTS
V$SGA_DYNAMIC_FREE_MEMORY
V$PGASTAT |
未内置到 Cloud SQL for PostgreSQL 中。使用 pg_buffercache 扩展程序来实时检查共享的缓冲区缓存。 |
系统参数
可专门配置 Oracle 和 Cloud SQL for PostgreSQL 数据库,使它们实现除默认配置之外的一些功能。如需更改 Oracle 中的配置参数,您需要具备某些管理权限(主要是 SYS/SYSTEM 用户权限)。
以下是使用 ALTER SYSTEM 语句更改 Oracle 配置的示例。在此示例中,用户仅在 spfile 配置级别更改“失败登录后最高尝试次数”参数(修改仅在重新启动后有效):
SQL> ALTER SYSTEM SET SEC_MAX_FAILED_LOGIN_ATTEMPTS=2 SCOPE=spfile;
在下一个示例中,用户请求查看 Oracle 参数值:
SQL> SHOW PARAMETER SEC_MAX_FAILED_LOGIN_ATTEMPTS;
输出内容类似如下:
NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ sec_max_failed_login_attempts integer 2
Oracle 参数修改在下面 3 个范围内起作用:
- SPFILE:参数修改将写入 Oracle
spfile,需要重新启动实例才能使参数生效。 - MEMORY:仅在不允许静态参数更改时才在内存层应用参数修改。
- BOTH:在服务器参数文件和实例内存中均应用参数修改,不允许更改静态参数。
Cloud SQL for PostgreSQL 配置标志
您可以使用 Google Cloud 控制台中的配置标志、gcloud CLI 或 CURL 来修改 Cloud SQL for PostgreSQL 系统参数。请参阅 Cloud SQL for PostgreSQL 支持的可更改的所有参数的完整列表。
PostgreSQL 参数可划分到下面几个范围:
- 动态参数:可在运行时更改。
- 数据库参数:仅应用于某个 PostgreSQL 实例中的特定数据库。
- 角色参数:仅应用于特定数据库角色。
- 静态参数:需要重新启动实例才能生效。
- 会话参数:只能针对当前会话生命周期在会话级别更改,与其他会话隔离。
- 全局参数:将对所有当前和未来会话产生全局影响。
有关更改 Cloud SQL for PostgreSQL 参数的示例
控制台
使用 Google Cloud 控制台启用 log_connections 参数。
转到 Cloud Storage 的修改实例页面。
在标志下,点击添加项目,然后搜索
log_connections,如以下屏幕截图所示。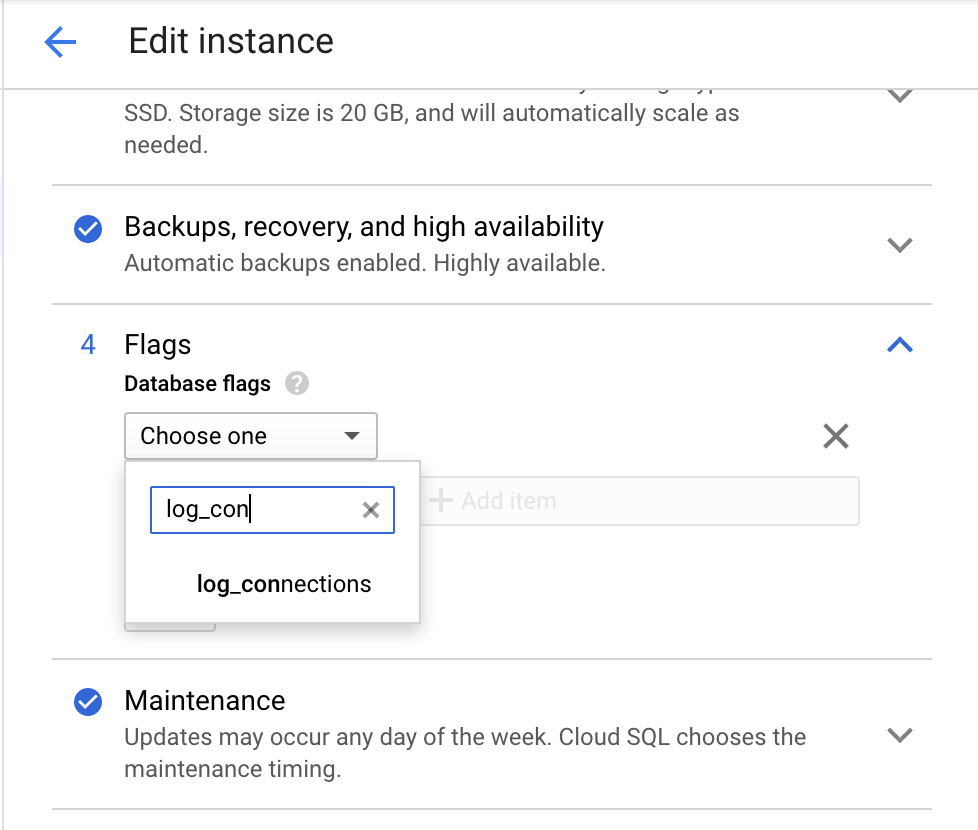
gcloud
- 使用 gcloud CLI 启用
log_connections参数:
gcloud sql instances patch INSTANCE_NAME \
--database-flags log_connections=on
输出如下所示:
WARNING: This patch modifies database flag values, which may require your instance to be restarted. Check the list of supported flags - /sql/docs/postgres/flags - to see if your instance will be restarted when this patch is submitted. Do you want to continue (Y/n)?
Cloud SQL for PostgreSQL
在会话级别设置 timezone。此更改对当前会话有效,有效期仅持续到该会话生命周期结束为止。
显示
timezone配置参数:postgres=> SHOW timezone;您将看到以下输出,其中
timezone为set to UTC:TimeZone ---------- UTC (1 row)
将
timezone设置为 UTC-9:postgres=> SET timezone='UTC-9';显示
timezone配置参数:postgres> SHOW timezone;您将看到以下输出,其中
timezone设置为UTC-9:TimeZone ---------- UTC-9 (1 row)
事务和隔离级别
本部分介绍 Oracle 和 Cloud SQL for PostgreSQL 在事务执行和隔离级别方面的主要差异。
提交模式
默认情况下,Oracle 在非自动提交模式下运行,其中每个 DML 事务都必须通过 COMMIT/ROLLBACK 语句确定。Oracle 和 PostgreSQL 的一个基本区别是,PostgreSQL 会在每个不遵循 START TRANSACTION(或 BEGIN)的命令之后隐式发出 COMMIT。这在某些其他数据库引擎中称为自动提交。自动提交是默认启用的,但您可以使用 SET AUTOCOMMIT OFF 在会话级别停用它。
隔离级别
ANSI/ISO SQL 标准 (SQL:92) 定义了 4 个隔离级别。每个级别都提供了一种不同的方法来处理数据库事务的并发执行:
- 读取未提交:当前处理的事务可以查看其他事务创建的未提交的数据。如果执行回滚,则所有数据都将恢复到其之前的状态。
- 读取已提交:事务仅可查看已提交的数据更改,无法查看未提交的更改(“脏读取”)。
- 可重复读取:仅在两个事务均发出
COMMIT或均回滚后,一个事务才能查看另一事务所作的更改。 - 可序列化:最严格/最强的隔离级别。此级别会锁定所有被访问的记录,还会锁定资源,避免记录被附加到表中。
事务隔离级别管理已更改的数据对其他正在运行的事务的可见性。此外,如果多个并发事务访问相同的数据,则所选的事务隔离级别会影响不同事务的交互方式。
Oracle 支持以下隔离级别:
- 读取已提交(默认)
- Serializable
- 只读(不属于 ANSI/ISO SQL 标准 (SQL:92))
Oracle MVCC(多版本并发控制):
- Oracle 使用 MVCC 机制在整个数据库和所有会话中提供自动读取一致性。
- Oracle 依靠当前事务的系统更改编号 (SCN) 获取一致的数据库视图;因此,所有数据库查询仅返回在查询执行时提交的与 SCN 相关的数据。
- 隔离级别可在事务和会话级别进行更改。
下面是设置隔离级别的示例:
-- Transaction Level
SQL> SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
SQL> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SQL> SET TRANSACTION READ ONLY;
-- Session Level
SQL> ALTER SESSION SET ISOLATION_LEVEL = SERIALIZABLE;
SQL> ALTER SESSION SET ISOLATION_LEVEL = READ COMMITTED;
Cloud SQL for PostgreSQL 支持在 ANSI SQL:92 标准中指定的以下四个事务隔离级别:
- 读取未提交(等效于读取已提交)
- 读取已提交(默认)
- 可重复读取
- Serializable
Cloud SQL for PostgreSQL 的默认隔离级别为 READ COMMITTED。这些隔离级别可以在 SESSION 级别、TRANSACTION 级别和 INSTANCE 级别进行更改。
如需在 TRANSACTION 和 SESSION 级别验证当前隔离级别,请使用以下语句:
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
输出如下所示:
current_setting ----------------- read committed (1 row)
您可以按如下所示修改隔离级别语法:
SET [SESSION CHARACTERISTICS AS] TRANSACTION ISOLATION LEVEL [ REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED | SERIALIZABLE]
您还可以在 SESSION 级别修改隔离级别:
postgres=> SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- Verify
postgres=> SELECT CURRENT_SETTING('TRANSACTION_ISOLATION');
输出如下所示:
current_setting ----------------- repeatable read (1 row)
INSTANCE 级别的隔离级别使用数据库标志 default_transaction_isolation 进行控制。您可以使用以下语句来进行验证:
postgres=> SHOW DEFAULT_TRANSACTION_ISOLATION;
输出如下所示:
default_transaction_isolation ------------------------------- repeatable read (1 row)
后续步骤
- 详细了解 Cloud SQL for PostgreSQL 用户账号。
- 探索有关 Google Cloud 的参考架构、图表和最佳做法。查看我们的 Cloud 架构中心。