系统活动中的查询性能指标探索可提供从 Looker 实例运行的每个查询的详细细分数据。
例如,您可以使用此探索来调查查询的哪些组成部分加载时间最长。您还可以使用此探索来识别查询性能趋势和异常情况。
如需详细了解系统活动中提供的探索,请参阅使用系统活动探索监控 Looker 使用情况文档页面。
查看查询性能指标
您可以在“系统活动”查询性能指标探索中查看查询性能指标。您必须是 Looker 管理员或拥有 see_system_activity 权限,才能查看查询性能指标探索。
了解 Looker 查询生命周期
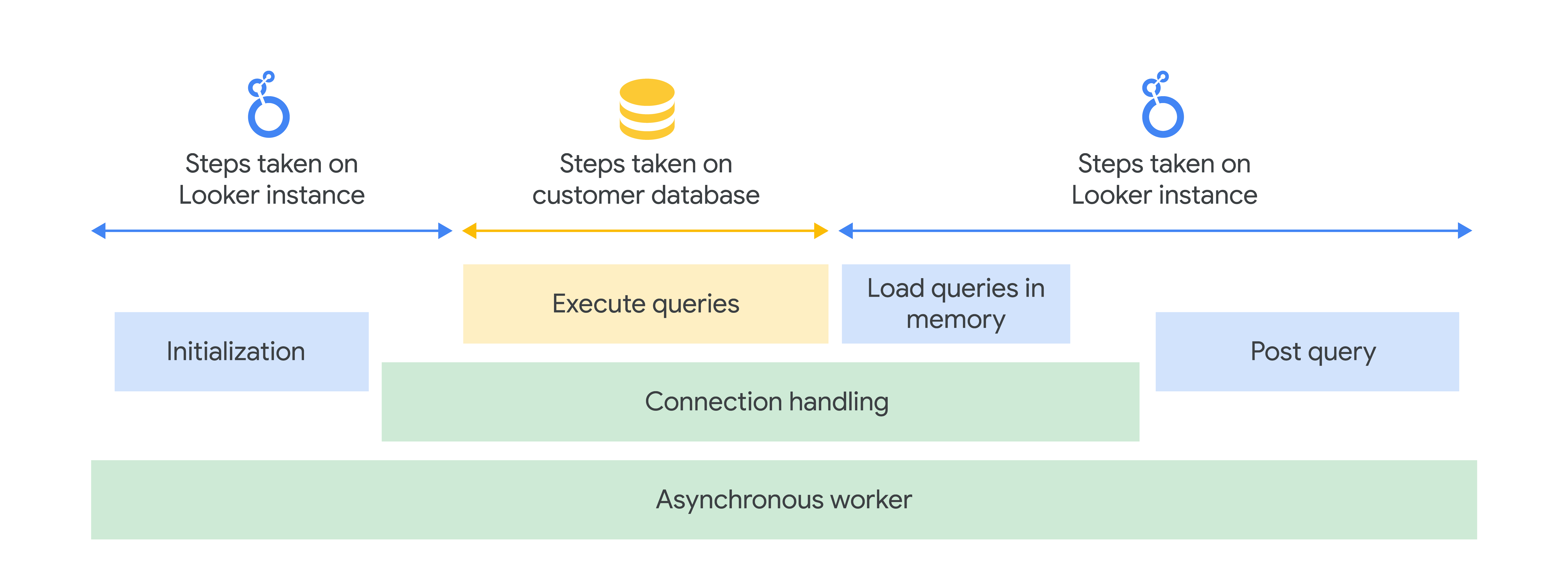
Looker 发送到数据库的每个查询都会经历多个阶段,每个阶段又包含多个步骤。这些步骤中的每一步都以维度形式显示在查询性能指标探索中。
从宏观层面来看,这些阶段可以概念化为以下内容:
- 异步工作器阶段:首先,必须将查询任务分配给可用的异步工作器。如果没有可用的工作器,则可能会有排队时间。
- 初始化阶段:分配异步工作线程后,Looker 实例会运行多个初始化步骤来准备查询。
- 连接处理阶段:初始化完成后,Looker 实例会与客户数据库建立连接。
- 主查询阶段:Looker 实例与客户数据库建立连接后,系统会在客户数据库上执行主查询。系统还可能会根据为查询选择的选项运行其他查询来计算结果,例如总计。如果查询不是流式传输的,则查询会加载到 Looker 实例的内存中。之后,Looker 实例与客户数据库之间的连接会关闭。
- 查询后阶段:最后,Looker 实例会运行多个查询后步骤,以准备将查询发送到下一个目的地。此时,异步工作器会被释放。
查询效果指标
以下各部分按时间顺序列出了每个查询阶段和查询步骤。
异步工作器阶段指标
| 查询步骤 | 指标说明 |
|---|---|
Queued |
查询等待异步工作器可用于运行查询的时间(以秒为单位)。 |
Async processing |
异步工作器在查询上花费的时间(以秒为单位)。工作器会继续处理查询,直到后查询阶段完成,因此此指标会与此页面上的大多数其他指标重叠。 |
初始化阶段指标
| 查询步骤 | 指标说明 |
|---|---|
Model Init: From Cache |
从缓存中提取模型定义所需的时间(以秒为单位)。如果此方法返回 null 值,则表示模型已加载并解析,而不是从缓存中提取。(请参阅 Model Init: Computed 步骤。) |
Model Init: Computed |
加载和解析运行查询所需的模型所花费的时间(以秒为单位)。如果此方法返回 null 值,则表示模型是从缓存中检索的,而不是从头开始加载和解析的。(请参阅 Model Init: From Cache 步骤。) |
Explore Init: From Cache |
从缓存中提取“探索”初始化信息所需的时间(以秒为单位)。如果此函数返回 null 值,则表示探索是从缓存中提取的,而不是加载和解析的。(请参阅 Explore Init: Computed 步骤。) |
Explore Init: Computed |
在开始探索之前,初始化探索所需的时间(以秒为单位)。prepare如果此方法返回 null 值,则表示探索是从缓存中检索的,而不是从头加载和解析的。(请参阅 Explore Init: From Cache 步骤。) |
Prepare |
根据探索定义准备查询所需的时间(以秒为单位)。 |
连接处理阶段指标
| 查询步骤 | 指标说明 |
|---|---|
Per User Throttler |
查询等待连接可供用户运行查询的时间(以秒为单位)。 |
Acquire Connection |
Looker 实例获取与客户数据库的连接所需的时间(以秒为单位)。此步骤包括查找用户凭据、创建连接池(如果尚不存在)以及初始化连接以供使用所需的时间。 |
Connection Held |
Looker 实例与客户数据库保持连接的时间(以秒为单位)。此步骤包括客户数据库运行 SQL 查询所需的时间。 |
主要查询阶段指标
| 查询步骤 | 指标说明 |
|---|---|
Cache Load |
从结果集缓存中提取原始结果所花费的时间(以秒为单位)。 |
PDTs |
构建查询所需的持久派生表所用的时间(以秒为单位)。 |
Execute Main Query |
在客户数据库中运行 primary 查询所需的时间(以秒为单位)。这不包括在客户数据库上获取连接所需的时间。对于需要使用允许返回大型结果功能的查询,系统不会跟踪此指标。 |
Execute Totals Query |
运行查询以生成客户数据库中的总数所需的时间(以秒为单位)。仅适用于启用了总计的查询。 |
Execute Row Totals Query |
在客户数据库中运行查询以生成行总数所需的时间(以秒为单位)。仅适用于启用了行总计的查询。 |
Execute Grand Totals Query |
在客户数据库中运行查询以生成总计所需的时间(以秒为单位)。仅适用于同时启用了总计和行总计的查询。 |
Load Process and Stream Main Query |
加载主要查询(来自客户数据库)、处理主要查询(在 Looker 实例上)并将其流式传输(到客户端)所用的时间(以秒为单位)。仅适用于流式查询。 |
Load Main Query In Memory |
从客户数据库将主查询结果加载到内存中所需的时间(以秒为单位)。仅适用于非流式查询。 |
Load Totals Query In Memory |
将生成总数的查询加载到内存中所用的时间(以秒为单位)。仅适用于启用了总计的非流式查询。 |
Load Row Totals Query In Memory |
将用于生成行总计的查询加载到内存中所用的时间(以秒为单位)。仅适用于启用了行总计的非流式查询。 |
Load Grand Totals Query In Memory |
将查询加载到内存中以生成总计所需的时间(以秒为单位)。仅适用于同时启用了总计和行总计的非流式查询。 |
查询后阶段指标
| 查询步骤 | 指标说明 |
|---|---|
Postprocessing |
后处理查询所需的时间(以秒为单位)。在连接关闭后发生。 |
Stream to Cache |
处理结果并将其流式传输到渲染缓存所需的时间(以秒为单位)。 |
BigQuery BI Engine 指标
如果您将 BigQuery BI Engine 与 Looker 搭配使用,则可以使用查询性能指标探索来查看有关查询的数据库特定信息。不使用 BI Engine 的查询以及对 BigQuery 数据库以外的数据库进行的查询会针对这些指标返回 null 值。
| 指标 | 指标说明 |
|---|---|
BigQuery Job ID |
相应查询的 BigQuery 作业 ID(或 NULL)。 为了缩短 BigQuery 中的查询响应时间,Looker 会使用 如果 BigQuery 确定无法立即返回结果,则会创建一个作业,并且相应查询将具有 BigQuery 作业 ID(而 BigQuery 查询 ID 将为 NULL)。 |
BigQuery Query ID |
相应查询的 BigQuery 查询 ID(或 NULL)。 为了缩短 BigQuery 中的查询响应时间,Looker 会使用 如果 BigQuery 确定无法立即返回结果,则会创建一个作业,并且相应查询将具有 BigQuery 作业 ID(而 BigQuery 查询 ID 将为 NULL)。如果此字段为空,则表示 BigQuery 无法立即执行查询,而是创建了一个作业来运行查询。请改用 |
BI Engine Mode |
查询是否能够部分或完全加速运行。如需详细了解此字段的可能值,请参阅 BI Engine 加速统计信息。 |
BI Engine Reason |
如果查询无法以完全加速模式运行,此字段会显示相应原因。此消息直接来自 Google BigQuery。 |
使用查询性能指标进行问题排查
分析查询指标有助于提升 Looker 实例的性能。首先,从系统活动信息中心列表中选择性能建议信息中心。