Looker (Google Cloud Core) muss mit einer Datenbank verbunden sein, damit Daten analysiert werden können. Mit der BigQuery QuickStart Connection kann eine Standardverbindung zu einer BigQuery Standard SQL-Datenbank erstellt werden.
Hinweise
Zum Konfigurieren einer BigQuery QuickStart-Verbindung sind die folgenden Berechtigungen erforderlich.
Looker-Berechtigungen
Wenn Sie eine der folgenden Looker-Berechtigungen haben, können Sie die Seite BigQuery QuickStart Connection auf der Startseite Ihrer Looker (Google Cloud Core)-Instanz aufrufen und bearbeiten:
- Die Looker-Administratorrolle
- Die Looker-Berechtigung
manage_project_connections
IAM-Berechtigungen
Looker (Google Cloud Core)-Instanzen können Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) zur Authentifizierung verwenden, wenn Sie eine Verbindung zu BigQuery einrichten. Wenn Sie ADC verwenden, wird die Verbindung mit den Anmeldedaten des Looker (Google Cloud Core)-Dienstkontos bei der Datenbank authentifiziert. Das Dienstkonto muss die folgenden IAM-Berechtigungen haben, um auf das BigQuery-Dataset zuzugreifen:
Für das Projekt, das das BigQuery-Dataset enthält, muss das Looker-Dienstkonto die folgenden IAM-Rollen haben:
- Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer) - BigQuery-Jobnutzer (
roles/bigquery.jobUser) BigQuery-Datenbearbeiter (
roles/bigquery.dataEditor) oder die folgenden IAM-Berechtigungen:bigquery.config.getbigquery.datasets.createbigquery.datasets.getbigquery.tables.createbigquery.tables.get
- Service Usage Consumer (
Für das Abrechnungsprojekt muss das Looker-Dienstkonto die folgenden IAM-Rollen haben:
- Service Usage Consumer (
roles/serviceusage.serviceUsageConsumer) - BigQuery-Jobnutzer (
roles/bigquery.jobUser)
- Service Usage Consumer (
Wenn das Looker (Google Cloud Core)-Dienstkonto noch nicht die erforderlichen IAM-Rollen hat, verwenden Sie die E-Mail-Adresse des Dienstkontos, wenn Sie Rollen in diesem Projekt zuweisen. Die E-Mail-Adresse des Dienstkontos finden Sie auf der Seite IAM in der Google Cloud Console. Klicken Sie dazu das Kästchen Von Google bereitgestellte Rollenzuweisungen einschließen an. Die E-Mail hat das Format service-<project number>@gcp-sa-looker.iam.gserviceaccount.com. Verwenden Sie diese E-Mail-Adresse, um dem Dienstkonto die richtigen Rollen zuzuweisen.
BigQuery-Verbindung für die Kurzanleitung konfigurieren
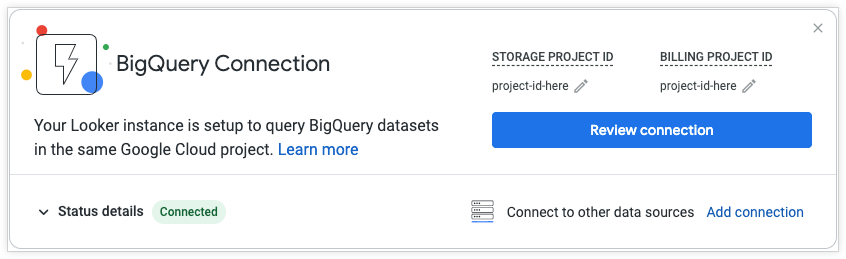
Die BigQuery-Schnellstartverbindung kann von Nutzern mit den entsprechenden Berechtigungen entweder auf der Seite Startseite oder auf der Seite Verbindungen im Bereich Verwaltung aufgerufen und bearbeitet werden. Auf der Seite Verbindungen wird die BigQuery-Schnellstartverbindung unter dem Namen Standard-BigQuery-Verbindung angezeigt. Bei einer neuen Instanz sind die Felder Storage project ID (Speicherprojekt-ID) und Billing project ID (Abrechnungsprojekt-ID) standardmäßig auf None (Keine) festgelegt.
Klicken Sie auf der Seite Startseite auf die Schaltfläche Verbindung überprüfen, um die Verbindung zu verwalten. Sie können die Kachel Startseite schließen, indem Sie auf das x klicken oder die Option BigQuery-Schnellstart in der Seitenleiste Entdecken deaktivieren.
Die Verbindung zur BigQuery-Kurzanleitung enthält die folgenden Abschnitte:
ID des Abrechnungsprojekts
Die Projekt-ID dient als eindeutige Kennung für das Google Cloud Abrechnungsprojekt. Das Abrechnungsprojekt ist das Google Cloud Projekt, das für die BigQuery-Nutzung in Rechnung gestellt wird. Sie können jedoch weiterhin Datasets in einem anderen Google Cloud -Projekt abfragen, wenn Ihre LookML-Entwickler voll qualifizierte Tabellennamen im Parameter sql_table_name Ihrer LookML-Ansichten, Explores oder Joins angeben. Dies ist ein erforderliches Feld.
Authentifizierung bei einer BigQuery-Datenbank mit OAuth: Bei BigQuery-Verbindungen kann Looker (Google Cloud Core) automatisch die Anmeldedaten für OAuth-Anwendungen verwenden, die Ihr Looker (Google Cloud Core)-Administrator beim Erstellen der Instanz verwendet hat. Weitere Informationen finden Sie auf der Seite OAuth-Anmeldedaten für die Autorisierung für eine Looker (Google Cloud Core)-Instanz erstellen.
Maximieren Sie den Abschnitt Statusdetails, um die Einstellungen für Ihre Verbindung zu testen.
Primäres Dataset
Die Seite Primäres Dataset enthält die folgenden Einstellungen.
Speicherprojekt-ID
Geben Sie im Feld Storage Project ID (Speicherprojekt-ID) die Projekt-ID für das Projekt ein, das das BigQuery-Dataset enthält, mit dem Sie eine Verbindung herstellen möchten. Das gilt auch, wenn es sich um dasselbe Projekt handelt, das die Looker (Google Cloud Core)-Instanz enthält. Dies ist ein erforderliches Feld.
Primäres Dataset
Das primäre Dataset ist das Dataset, in dem BigQuery nach Tabellen sucht, wenn ihr Speicherort im SQL-Abfragetext nicht angegeben ist. Beachten Sie, dass Looker (Google Cloud Core)-Abfragen auf Tabellen in beliebigen Projekten oder Datasets verweisen können, sofern die Abfragen Tabellennamen mit vollständigem Umfang im Format project_id.dataset_name.table_name verwenden. Das Looker (Google Cloud Core)-Dienstkonto benötigt außerdem die entsprechenden IAM-Berechtigungen, um auf die Tabellen an diesem Speicherort zuzugreifen. Dies ist ein erforderliches Feld.
Weitere Informationen zu Datasets finden Sie auf der Dokumentationsseite Looker mit BigQuery verbinden.
Maximieren Sie den Abschnitt Statusdetails, um die Einstellungen für Ihre Verbindung zu testen.
Optionale Einstellungen
Der Abschnitt Optionale Einstellungen enthält die folgenden Optionen:
Maximale Anzahl von Verbindungen pro Knoten: Die maximale Anzahl von Verbindungen zur Datenbank, die gleichzeitig zulässig sind. Hinweis: Diese Einstellung gilt für jeden Knoten in der Looker (Google Cloud Core)-Bereitstellung. Der Wert muss zwischen 5 und 100 liegen und kann zunächst unverändert bleiben. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt Maximale Anzahl von Verbindungen pro Knoten auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
Zeitlimit für Verbindungspool: Die Anzahl der Sekunden, die eine Abfrage wartet, bevor es bei einem vollen Verbindungspool zu einer Zeitüberschreitung kommt. Der Standardwert kann zunächst unverändert bleiben. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt Zeitüberschreitung für Verbindungspool auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
Zusätzliche JDBC-Parameter: Fügen Sie alle zusätzlichen JDBC-Parameter wie BigQuery-Labels hinzu (weitere Informationen dazu finden Sie auf dieser Seite im Abschnitt Jobbezeichnungen und Kontextkommentare für BigQuery-Verbindungen).
Wartungszeitplan: Cron-Ausdruck, der die maximale Häufigkeit von Datengruppen-Triggerprüfungen und PAT-Wartungen angibt. Weitere Informationen zu dieser Einstellung finden Sie in der Dokumentation zum Wartungszeitplan.
SSL: Wählen Sie aus, ob Ihre Daten bei der Übergabe zwischen Looker (Google Cloud Core) und Ihrer Datenbank mit SSL-Verschlüsselung geschützt werden sollen. SSL ist nur eine Option zum Schutz Ihrer Daten. Andere sichere Optionen werden auf der Dokumentationsseite Sicheren Datenbankzugriff aktivieren beschrieben.
SSL-Zertifikat überprüfen: Geben Sie an, ob die Überprüfung des von der Verbindung verwendeten SSL-Zertifikats angefordert werden soll. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt SSL-Zertifikat bestätigen auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
Tabellen und Spalten vorab im Cache speichern: In SQL Runner werden alle Tabelleninformationen unmittelbar nach der Auswahl einer Verbindung und eines Schemas vorab geladen. Somit kann SQL Runner Tabellenspalten schnell anzeigen, nachdem Sie auf einen Tabellennamen geklickt haben. Für Verbindungen und Schemata mit vielen Tabellen oder sehr großen Tabellen soll SQL-Runner jedoch möglicherweise nicht alle Informationen vorab laden.
Schema abrufen und im Cache speichern: Für einige Funktionen zum Schreiben von SQL, z. B. die Aggregat-Awareness, verwendet Looker (Google Cloud Core) das Informationsschema Ihrer Datenbank, um das Schreiben von SQL zu optimieren. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt Informationsschema für SQL-Schreibvorgänge abrufen auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
PDTs aktivieren: Aktivieren Sie den Schalter PDTs aktivieren, um nichtflüchtige abgeleitete Tabellen zu aktivieren. Wenn PATs aktiviert sind, werden im Fenster Optionale Einstellungen zusätzliche PAT-Felder und der Bereich PAT-Überschreibungen angezeigt.
Temp database (Temporäre Datenbank): Geben Sie das Dataset in BigQuery ein, in dem in Looker (Google Cloud Core) persistente abgeleitete Tabellen erstellt werden. Sie sollten dieses Dataset im Voraus mit den entsprechenden Schreibberechtigungen konfigurieren. Dieses Feld ist erforderlich, um PDTs zu verwenden.
Maximale Anzahl von PAT-Builder-Verbindungen: Die Einstellung Maximale Anzahl von PAT-Builder-Verbindungen ist standardmäßig auf 1 festgelegt, kann aber auf bis zu 10 erhöht werden. Der Wert darf jedoch nicht höher sein als der Wert, der in Max. Verbindungen pro Knoten festgelegt ist. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt Maximale Anzahl von Verbindungen für PDT-Generator auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden. Wählen Sie diesen Wert mit Bedacht. Ist der Wert zu hoch, überlastet dies möglicherweise Ihre Datenbank. Wenn der Wert niedrig ist, können PDTs oder aggregierte Tabellen mit langer Ausführungszeit die Erstellung anderer persistenter Tabellen verzögern oder andere Abfragen für die Verbindung verlangsamen.
Fehlgeschlagene PDT-Builds wiederholen: Mit der Ein/Aus-Schaltfläche Fehlgeschlagene PDT-Builds wiederholen wird konfiguriert, wie der Looker (Google Cloud Core)-Regenerator versucht, Trigger-persistierte Tabellen neu zu erstellen, die im vorherigen Regenerator-Zyklus fehlgeschlagen sind. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt Fehlgeschlagene PAT-Builds wiederholen auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
API-Steuerung für PAT: Mit dem Ein/Aus-Schalter API-Steuerung für PAT wird festgelegt, ob die API-Aufrufe
start_pdt_build,check_pdt_buildundstop_pdt_buildfür diese Verbindung verwendet werden können. Wenn die Ein/Aus-Schaltfläche PDT API Control deaktiviert ist, schlagen diese API-Aufrufe fehl, wenn sie auf PDTs für diese Verbindung verweisen.PDT-Überschreibungen: Wenn Ihre Datenbank nichtflüchtige abgeleitete Tabellen unterstützt und Sie in den Verbindungseinstellungen die Ein/Aus-Schaltfläche PDTs aktivieren aktiviert haben, wird in Looker (Google Cloud Core) der Bereich PDT-Überschreibungen angezeigt. Im Bereich PDT Overrides können Sie separate JDBC-Parameter (Host, Port, Database, Username, Password, Schema, zusätzliche Parameter und After-Connect-Anweisungen) eingeben, die für PDT-Prozesse spezifisch sind. Weitere Informationen zu dieser Einstellung finden Sie im Abschnitt PDT-Überschreibungen auf der Dokumentationsseite Looker mit Ihrer Datenbank verbinden.
Zeitzone der Datenbank: Die Zeitzone, in der Ihre Datenbank zeitbasierte Informationen speichert. Looker (Google Cloud Core) muss diese kennen, damit Zeitwerte für Nutzer konvertiert werden können. Dies erleichtert das Verständnis und die Nutzung zeitbasierter Daten. Weitere Informationen finden Sie auf der Dokumentationsseite Zeitzoneneinstellungen verwenden.
Zeitzone der Abfrage: Die Option Zeitzone der Abfrage ist nur sichtbar, wenn Sie Nutzerspezifische Zeitzonen deaktiviert haben. Weitere Informationen finden Sie auf der Dokumentationsseite Zeitzoneneinstellungen verwenden.
Maximieren Sie den Abschnitt Statusdetails, um die Einstellungen für Ihre Verbindung zu testen.
Überprüfen
Prüfen und ändern Sie die Verbindungsdetails, die Sie in den vorherigen Abschnitten eingegeben haben, im Abschnitt Überprüfen.
Maximieren Sie den Abschnitt Statusdetails, um die Einstellungen für Ihre Verbindung zu testen. Klicken Sie neben dem jeweiligen Abschnitt auf das Bearbeitungssymbol, um zu diesem Abschnitt zurückzukehren und die Einstellungen zu ändern.
Verbindung speichern und testen
Wenn Sie Änderungen an der BigQuery-Kurzanleitung speichern möchten, klicken Sie auf Speichern.
Sie können Ihre Verbindungseinstellungen an verschiedenen Stellen in der Looker (Google Cloud Core)‑Benutzeroberfläche testen:
- Maximieren Sie unten auf einer der QuickStart-Verbindungsseiten den Abschnitt Statusdetails und klicken Sie auf Verbindung testen.
- Erweitern Sie auf der Seite Startseite unten auf der Kachel „QuickStart-Verbindung“ den Bereich Statusdetails und klicken Sie auf Verbindung testen.
- Wählen Sie auf der Seite Verbindungen (Admin) neben dem Eintrag der Verbindung die Schaltfläche Testen aus, wie auf der Dokumentationsseite Verbindungen beschrieben.
Nachdem Sie die Verbindungseinstellungen eingegeben haben, klicken Sie auf Test, um die Richtigkeit der Informationen zu überprüfen und sicherzustellen, dass die Datenbank eine Verbindung herstellen kann.
Sollte Ihre Verbindung einen oder mehrere Tests nicht bestehen, können Sie Folgendes versuchen:
- Führen Sie einige der auf der Dokumentationsseite Datenbankkonnektivität testen aufgeführten Schritte zur Fehlerbehebung durch.
- Greifen Sie auf die Logs Ihrer Looker (Google Cloud Core)-Instanz zu, um detailliertere Fehlermeldungen zu erhalten.
- Wenden Sie sich an den Support, um weitere Unterstützung bei der Fehlerbehebung zu erhalten.
Nächste Schritte
- Nutzer in Looker (Google Cloud Core) verwalten
- Looker (Google Cloud Core)-Instanz über die Google Cloud Console verwalten
- Looker (Google Cloud Core)-Administratoreinstellungen
- LookML-Beispielprojekt auf einer Looker (Google Cloud Core)-Instanz verwenden