本页定义了以下核心术语和概念,您在 LookML 开发过程中可能会经常遇到这些术语和概念:
本页未介绍 Look 和用户定义的信息中心,因为用户无需使用任何 LookML 即可创建它们。不过,这些查询依赖于本页讨论的底层 LookML 元素。
如需查看 Looker 中使用的术语和定义的完整列表,请参阅 Looker 术语库。如需全面了解可在 LookML 项目中使用的 LookML 参数,请参阅 LookML 快速参考页面。
如需了解 Looker 和 Looker Studio 中类似术语和概念之间的细微差别,请参阅 Looker 和 Looker Studio 共享的术语和概念文档页面。
LookML 项目
在 Looker 中,项目是一个文件集合,其中的文件负责说明用于执行 SQL 查询的对象、数据库连接和界面元素。从最基本的层面上讲,这些文件描述了数据库表之间的关系以及 Looker 应如何解读这些关系。这些文件还可能包含 LookML 参数,用于定义或更改 Looker 界面中显示的选项。每个 LookML 项目都位于自己的 Git 代码库中,以便进行版本控制。
将 Looker 连接到数据库后,您可以指定要用于 Looker 项目的数据库连接。

您可以通过 Looker 中的 Develop 菜单访问项目(如需了解详情和其他选项,请参阅访问项目文件)。

如需了解如何创建新项目,请参阅生成模型文档页面;如需了解如何访问和更改现有 LookML 项目,请参阅访问和修改项目信息文档页面。
项目的组成部分
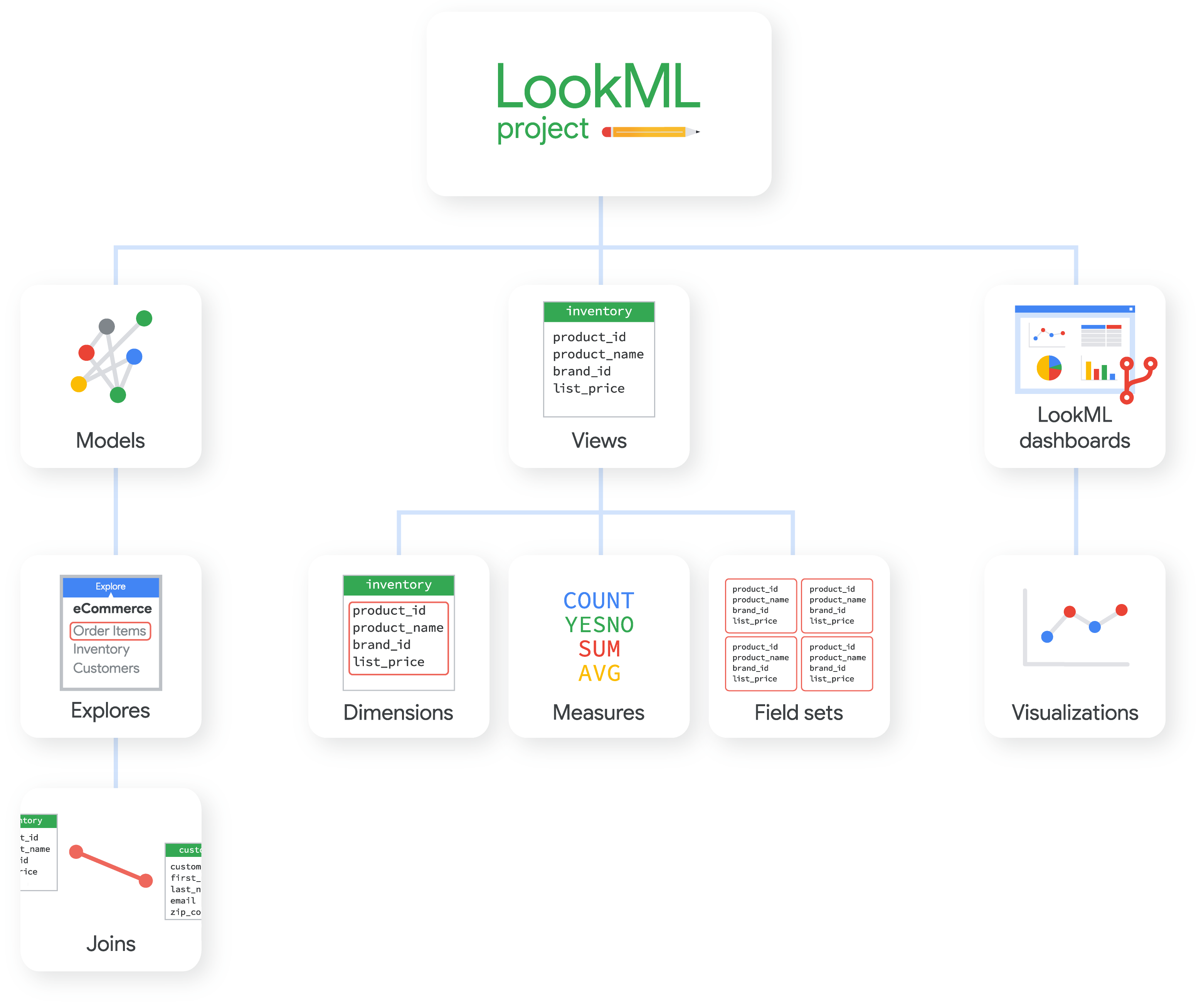
如图所示,以下是 LookML 项目中一些更常见的文件类型:
- 模型包含有关要使用哪些表以及如何将它们联接在一起的信息。您通常会在其中定义模型、Explore 和联接。
- 视图包含有关如何访问或计算每个表(或多个联接表)中的信息的信息。您通常会在该文件中定义视图、视图的维度和度量,以及视图的字段集。
- 探索通常在模型文件中定义,但有时您需要单独的探索文件用于派生表,或者用于扩展或优化模型中的探索。
- 清单文件可以包含有关使用从其他项目导入的文件的说明,也可以包含项目本地化设置。
除了模型文件、视图文件、探索文件和清单文件之外,项目还可以包含与内置信息中心、文档、本地化等相关的其他类型的文件。如需详细了解这些类型的文件以及 LookML 项目中可能包含的其他类型的文件,请参阅 LookML 项目文件文档页面。
这些文件共同构成一个项目。如果您使用 Git 进行版本控制,那么每个项目通常都有自己的 Git 代码库作为备份。
LookML 项目和文件来自哪里?
创建 LookML 文件最常见的方法是从数据库生成 LookML 项目。您还可以创建空白项目,然后手动创建其 LookML 文件。
当您从数据库生成新项目时,Looker 会创建一组基准文件,您可以将这些文件用作构建项目的模板:
您可以在此处移除不需要的视图和探索,并添加自定义维度和衡量指标,从而自定义项目。
主要 LookML 结构
如项目组成部分示意图所示,一个项目通常包含一个或多个模型文件,其中包含用于定义模型及其 Explore 和联接的参数。此外,项目通常包含一个或多个视图文件,每个文件都包含用于定义相应视图及其字段(包括维度和度量)以及字段集的参数。项目还可以包含项目清单文件,用于配置项目级设置。本部分将介绍这些主要结构。
型号
模型是数据库的自定义门户,旨在为特定业务用户提供直观的数据探索体验。在单个 LookML 项目中,同一数据库连接可以对应多个模型。每个模型都可以向不同的用户公开不同的数据。例如,销售代理需要的数据与公司高管不同,因此您可能需要开发两个模型,以便为每类用户提供合适的数据库视图。
模型用于指定与单个数据库的连接。开发者还可以在模型文件中定义模型的 Explore。默认情况下,探索会整理到定义它们的模型名称下。您的用户会在探索菜单中看到列出的模型。

如需详细了解模型文件(包括模型文件的结构和一般语法),请参阅LookML 项目中的文件类型文档页面。
如需详细了解可在模型文件中使用的 LookML 参数,请参阅模型参数文档页面。
查看
视图声明定义了字段(维度或度量)列表及其与底层表或派生表的关联。在 LookML 中,视图通常引用底层数据库表,但也可以表示派生表。
一个视图可以与其他视图联接。视图之间的关系通常在模型文件的 Explore 声明中定义。
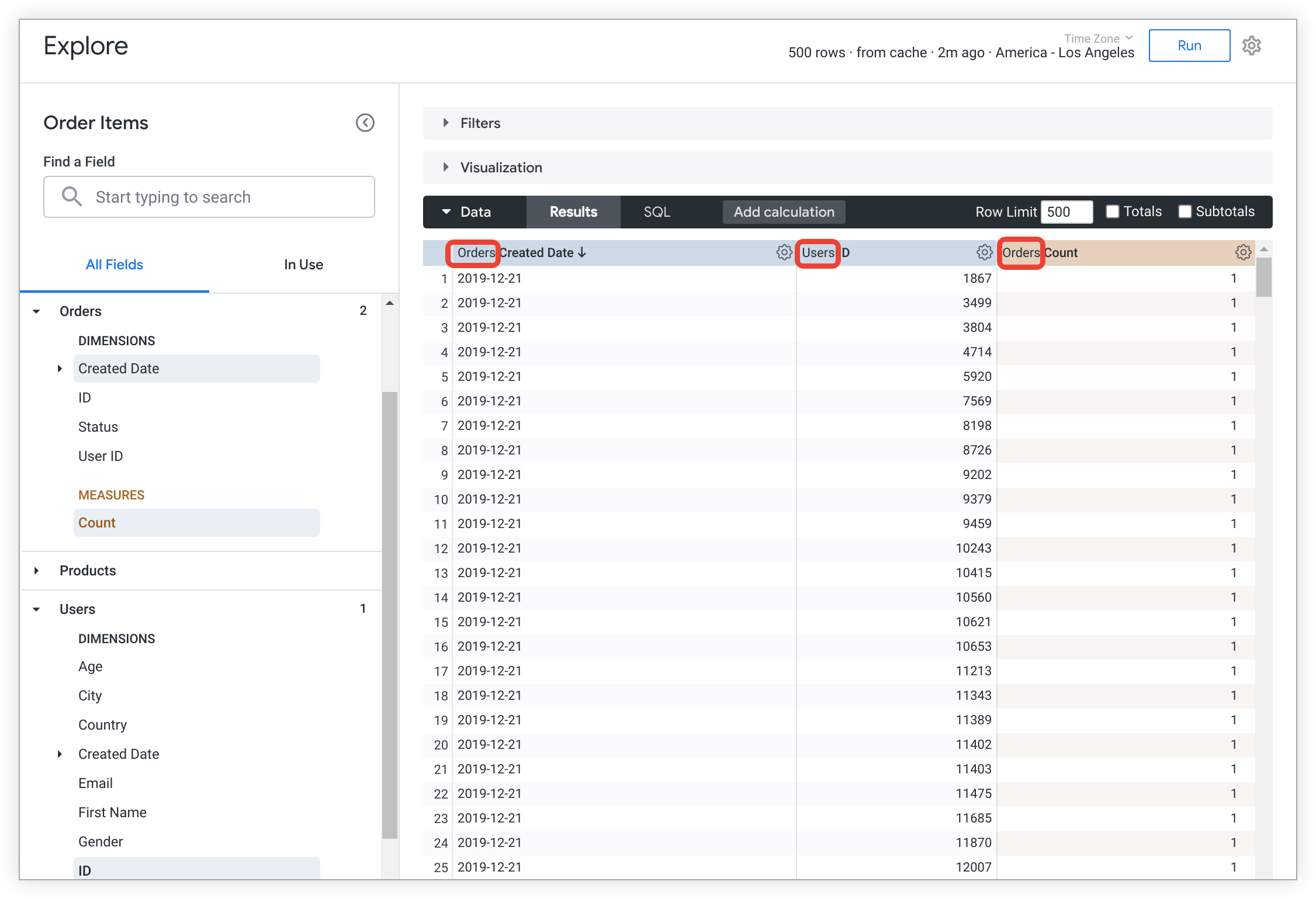
默认情况下,视图名称会显示在探索数据表中维度和度量名称的开头。此命名惯例可清晰指明相应字段所属的视图。在以下示例中,视图名称“Orders”和“Users”列在数据表中的字段名称之前:
如需详细了解视图文件,包括视图文件的结构和常规语法,请参阅LookML 项目中的文件类型文档。
如需详细了解可在视图文件中使用的 LookML 参数,请参阅视图参数文档页面。
探索
探索是用户可以查询的视图。您可以将探索视为查询的起点,或者用 SQL 术语来说,视为 SQL 语句中的 FROM。并非所有视图都是探索,因为并非所有视图都描述了感兴趣的实体。例如,与州名称的查找表对应的州视图不需要探索,因为业务用户永远不需要直接查询它。另一方面,企业用户可能希望能够查询订单视图,因此为订单定义探索很有意义。如需了解用户如何与探索互动来查询数据,请参阅在 Looker 中查看探索并与之互动文档页面。
在 Looker 中,用户可以在探索菜单中看到列出的探索。探索会列在所属模型的名称下方。

按照惯例,Explore 会在模型文件中使用 explore 参数进行声明。在以下模型文件示例中,电子商务数据库的 orders 探索是在模型文件中定义的。explore 声明中引用的视图 orders 和 customers 在各自的视图文件中定义。
connection: order_database
include: "filename_pattern"
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
在此示例中,connection 参数用于指定模型的数据库连接,而 include 参数用于指定可供模型引用的文件。
此示例中的 explore 声明还指定了视图之间的联接关系。如需详细了解 join 声明,请参阅本页的联接部分。如需详细了解可与 join 参数搭配使用的 LookML 参数,请访问联接参数文档页面。
维度和度量字段
视图包含字段(主要是维度和度量),这些字段是 Looker 查询的基本构建块。
在 Looker 中,维度是可分组的字段,可用于过滤查询结果。可以是下列任意一种:
- 一种与底层表中的列直接关联的属性
- 事实或数值
- 根据单行中其他字段的值计算得出的派生值
在 Looker 中,维度始终显示在 Looker 生成的 SQL 的 GROUP BY 子句中。
例如,产品视图的维度可能包括产品名称、产品型号、产品颜色、产品价格、产品创建日期和产品生命周期结束日期。
指标是使用 SQL 聚合函数(例如 COUNT、SUM、AVG、MIN 或 MAX)的字段。根据其他指标值计算出的任何字段也是指标。衡量指标可用于过滤分组值。例如,销售视图的指标可能包括售出商品总数(一种计数)、总销售价格(一种总和)和平均销售价格(一种平均值)。
字段的行为和预期值取决于其声明的类型,例如 string、number 或 time。对于度量,类型包括聚合函数,例如 sum 和 percent_of_previous。如需了解详情,请参阅维度类型和衡量类型。
在 Looker 中,字段会列在探索页面左侧的字段选择器中。您可以展开字段选择器中的视图,以显示可从该视图中查询的字段列表。

按照惯例,字段会声明为所属视图的一部分,并存储在视图文件中。以下示例展示了多个维度和度量声明。请注意,我们使用替换运算符 ($) 来引用字段,而无需使用完全限定的 SQL 列名称。
以下是一些维度和指标声明示例:
view: orders {
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: customer_id {
sql: ${TABLE}.customer_id ;;
}
dimension: amount {
type: number
value_format: "0.00"
sql: ${TABLE}.amount ;;
}
dimension_group: created {
type: time
timeframes: [date, week]
sql: ${TABLE}.created_at ;;
}
measure: count {
type: count # creates sql COUNT(orders.id)
sql: ${id} ;;
}
measure: total_amount {
type: sum # creates sql SUM(orders.amount)
sql: ${amount} ;;
}
}
您还可以定义 dimension_group,以便一次性创建多个与时间相关的维度;以及 filter 字段,这些字段具有各种高级应用场景,例如模板化过滤条件。
如需详细了解如何声明字段以及可应用于字段的各种设置,请参阅字段参数文档页面。
联接
作为 explore 声明的一部分,每个 join 声明都指定了一个可以加入到探索中的视图。当用户创建包含多个视图中的字段的查询时,Looker 会自动生成 SQL 联接逻辑,以正确引入所有字段。
以下是 explore 声明中的联接示例:
# file: ecommercestore.model.lookml
connection: order_database
include: "filename_pattern" # include all the views
explore: orders {
join: customers {
sql_on: ${orders.customer_id} = ${customers.id} ;;
}
}
如需了解详情,请访问 在 LookML 中使用联接 文档页面。
项目清单文件
您的项目可能包含一个项目清单文件,该文件用于设置项目级设置,例如指定要导入到当前项目中的其他项目、定义 LookML 常量、指定模型本地化设置,以及向项目添加扩展程序和自定义可视化图表。
每个项目只能有一个清单文件。该文件必须命名为 manifest.lkml,并位于 Git 代码库的根级。如果您在 IDE 中使用文件夹,请确保 manifest.lkml 文件位于项目目录结构中的根级别。
如需从其他项目导入 LookML 文件,请使用项目清单文件为当前项目指定名称,并指定任何外部项目的位置(可以存储在本地或远程)。例如:
# This project
project_name: "my_project"
# The project to import
local_dependency: {
project: "my_other_project"
}
remote_dependency: ga_360_block {
url: "https://github.com/llooker/google_ga360"
ref: "4be130a28f3776c2bf67a9acc637e65c11231bcc"
}
在项目清单文件中定义外部项目后,您可以使用模型文件中的 include 参数将这些外部项目中的文件添加到当前项目中。例如:
include: "//my_other_project/imported_view.view"
include: "//ga_360_block/*.view"
如需了解详情,请参阅从其他项目导入文件文档页面。
如需向模型添加本地化,请使用项目清单文件指定默认本地化设置。例如:
localization_settings: {
default_locale: en
localization_level: permissive
}
指定默认本地化设置是本地化模型的一个步骤。如需了解详情,请参阅本地化 LookML 模型文档页面。
集合
在 Looker 中,集是一个列表,用于定义一组一起使用的字段。通常,集合用于指定在用户深入分析数据后要显示的字段。下钻集是按字段指定的,因此您可以完全控制用户点击表格或信息中心中的值时显示的数据。集合还可以用作安全功能,用于定义对特定用户可见的字段组。
以下示例展示了视图 order_items 中的集合声明,该声明定义了列出有关已购商品的相关详细信息的字段。请注意,该组通过指定范围来引用其他视图中的字段。
set: order_items_stats_set {
fields: [
id, # scope defaults to order_items view
orders.created_date, # scope is "orders" view
orders.id,
users.name,
users.history, # show all products this user has purchased
products.item_name,
products.brand,
products.category,
total_sale_price
]
}
如需了解有关集合的完整使用详情,请参阅 set 参数文档页面。
展开细目
在 Looker 中,您可以配置某个字段,以便用户可以进一步下钻到数据中。下钻功能适用于查询结果表和信息中心。下钻会启动一个新查询,该查询会受到您点击的值的限制。
维度和度量的下钻行为有所不同:
- 当您对某个维度进行下钻时,新查询会根据下钻的值进行过滤。例如,如果您在按日期查询客户订单时点击某个特定日期,新查询将仅显示该特定日期的订单。
- 在对某个指标进行下钻时,新查询将显示促成该指标的数据集。例如,在细分某个数量时,新查询会显示用于计算该数量的行。在对最大值、最小值和平均值指标进行下钻时,下钻仍会显示促成该指标的所有行。这意味着,如果对最大值指标进行下钻,系统会显示用于计算最大值的所有行,而不仅仅是最大值对应的单行。
新下钻查询要显示的字段可以通过集来定义,也可以通过 drill_fields 参数(针对字段)或 drill_fields 参数(针对视图)来定义。
派生表
派生表是一种查询,其结果可像数据库中的实际表一样使用。派生表是通过在 view 声明中使用 derived_table 参数创建的。Looker 会将派生表视为具有自己的一组列的物理表。派生表会作为自己的视图公开,并以与常规视图相同的方式定义维度和度量。派生表的视图可以像任何其他视图一样进行查询并联接到其他视图中。
派生表还可以定义为永久性派生表 (PDT),即写入数据库中的临时架构并根据您通过持久性策略指定的计划自动重新生成的派生表。
如需了解详情,请参阅 Looker 中的派生表文档页面。
数据库连接
LookML 项目的另一个重要元素是 Looker 用于在数据库中运行查询的数据库连接。Looker 管理员使用“连接”页面配置数据库连接,LookML 开发者使用模型文件中的 connection 参数指定要用于模型的连接。如果您从数据库生成 LookML 项目,Looker 会自动在模型文件中填充 connection 参数。
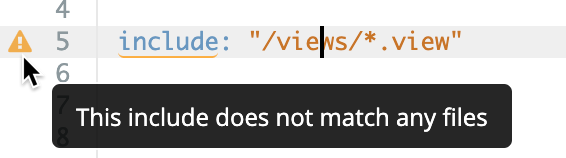
区分大小写
LookML 区分大小写,因此在引用 LookML 元素时,请务必注意大小写。如果您引用的元素不存在,Looker 会提醒您。
例如,假设您有一个名为 e_flights_pdt 的探索,而 LookML 开发者使用不正确的大小写形式 (e_FLIGHTS_pdt) 来引用该探索。在此示例中,Looker IDE 显示一条警告,指出 Explore e_FLIGHTS_pdt 不存在。此外,IDE 还会建议现有探索的名称,即 e_flights_pdt:

不过,如果您的项目中同时包含 e_FLIGHTS_pdt 和 e_flights_pdt,Looker IDE 将无法纠正您,因此您必须确定自己想要的是哪个版本。一般来说,在命名 LookML 对象时,最好坚持使用小写字母。
IDE 文件夹名称也区分大小写。指定文件路径时,必须保持文件夹名称的大小写一致。例如,如果您有一个名为 Views 的文件夹,则必须在 include 参数中使用相同的首字母大写形式。同样,如果您的首字母大写形式与项目中的现有文件夹不匹配,Looker IDE 会指示错误: