Vista geral
O Looker usa a lógica de reconhecimento de agregação para encontrar a tabela mais pequena e eficiente disponível na sua base de dados para executar uma consulta, mantendo a precisão.
Para tabelas muito grandes na sua base de dados, os programadores do Looker podem criar tabelas agregadas de dados mais pequenas, agrupadas por várias combinações de atributos. As tabelas agregadas funcionam como tabelas de resumo ou de agregação que o Looker pode usar para consultas sempre que possível, em vez da tabela grande original. Quando implementada estrategicamente, a notoriedade agregada pode acelerar a consulta média por ordens de magnitude.
Por exemplo, pode ter uma tabela de dados à escala de petabytes com uma linha para cada encomenda que ocorreu no seu Website. A partir desta base de dados, pode criar uma tabela agregada com os totais de vendas diários. Se o seu Website receber 1000 encomendas todos os dias, a tabela agregada diária representaria cada dia com menos 999 linhas do que a tabela original. Pode criar outra tabela agregada com os totais de vendas mensais que será ainda mais eficiente. Assim, agora, se um utilizador executar uma consulta para vendas diárias ou semanais, o Looker usa a tabela do total de vendas diárias. Se um utilizador executar uma consulta sobre as vendas anuais e não tiver uma tabela agregada anual, o Looker usa a melhor alternativa seguinte, que é a tabela agregada de vendas mensais neste exemplo.
O Looker responde às perguntas dos utilizadores com as tabelas agregadas mais pequenas sempre que possível. Por exemplo:
- Para uma consulta sobre o total de vendas mensais, o Looker usa a tabela agregada com base nas vendas mensais (
sales_monthly_aggregate_table). - Para uma consulta sobre o total de cada venda num dia, não existe uma tabela agregada com esse nível de detalhe. Por isso, o Looker recebe os resultados da consulta da tabela da base de dados original (
orders_database). (No entanto, se os seus utilizadores executarem este tipo de consulta com frequência, pode criar uma tabela agregada para a mesma.) - Para uma consulta sobre as vendas semanais, não existe uma tabela agregada semanal. Por isso, o Looker usa a melhor alternativa, que é a tabela agregada com base nas vendas diárias (
sales_daily_aggregate_table).
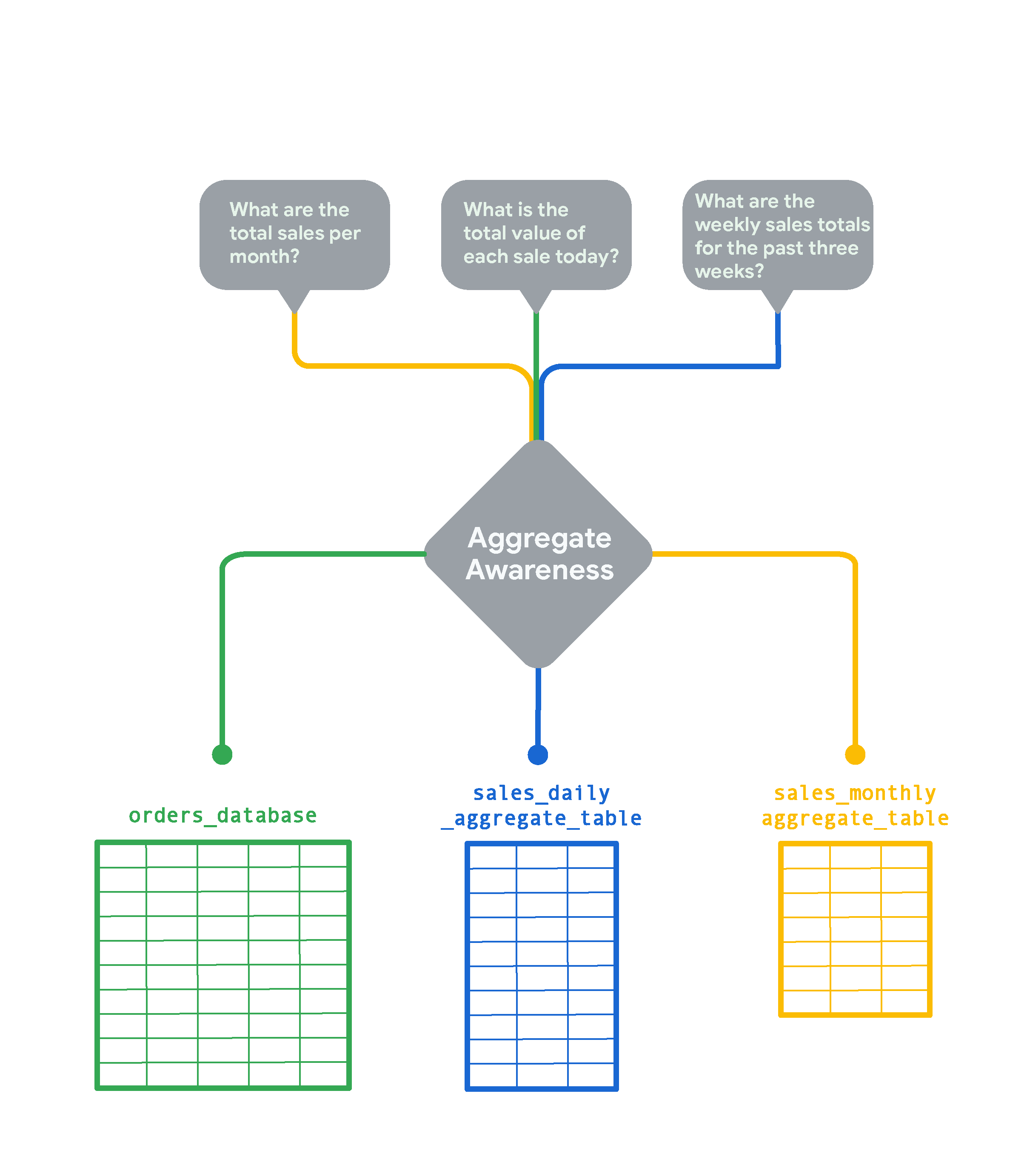
Usando a lógica de reconhecimento de agregação, o Looker consulta a menor tabela de agregação possível para responder às perguntas dos seus utilizadores. A tabela original seria usada apenas para consultas que exigissem um nível de detalhe mais preciso do que o que as tabelas agregadas podem oferecer.
Não é necessário juntar tabelas agregadas nem adicioná-las a uma exploração separada. Em alternativa, o Looker ajusta dinamicamente a cláusula FROM da consulta de exploração para aceder à melhor tabela de agregação para a consulta. Isto significa que as suas análises detalhadas são mantidas e as explorações podem ser consolidadas. Com o conhecimento agregado, uma exploração pode tirar partido automaticamente das tabelas agregadas, mas ainda analisar detalhadamente os dados detalhados, se necessário.
Também pode tirar partido das tabelas agregadas para melhorar drasticamente o desempenho dos painéis de controlo, especialmente para mosaicos que consultam conjuntos de dados enormes. Para mais detalhes, consulte a secção Obter LookML da tabela agregada a partir de um painel de controlo na página de documentação do parâmetro aggregate_table.
Adicionar tabelas agregadas ao seu projeto
Os programadores do Looker podem criar tabelas agregadas estratégicas que minimizam o número de consultas necessárias nas tabelas grandes numa base de dados. As tabelas agregadas têm de ser mantidas na sua base de dados para que possam ser acessíveis para a análise detalhada de dados agregados. Por conseguinte, as tabelas agregadas são um tipo de tabela derivada persistente (PDT).
Uma tabela agregada é definida através do parâmetro aggregate_table num parâmetro explore no seu projeto LookML.
Segue-se um exemplo de um explore com uma tabela agregada no LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
Para criar uma tabela agregada, pode escrever o LookML de raiz ou pode obter o LookML da tabela agregada a partir de uma análise detalhada ou a partir de um painel de controlo. Consulte a página de documentação do parâmetro aggregate_table para ver os detalhes do parâmetro aggregate_table e os respetivos subparâmetros.
Conceber tabelas agregadas
Para que uma consulta de exploração use uma tabela de agregação, esta tem de conseguir fornecer dados precisos para a consulta de exploração. O Looker pode usar uma tabela agregada para uma consulta de exploração se todas as seguintes condições forem verdadeiras:
- Os campos da consulta Explorar são um subconjunto dos campos da tabela de dados agregados (consulte a secção Fatores de campo nesta página). Em alternativa, para os períodos, os períodos da consulta de exploração podem ser derivados dos períodos na tabela de agregação (consulte a secção Fatores de período nesta página).
- A consulta Explorar contém tipos de métricas suportados pela notoriedade agregada (consulte a secção Fatores do tipo de métrica nesta página) ou a consulta Explorar tem uma tabela agregada que é uma correspondência exata (consulte a secção Criar tabelas agregadas que correspondam exatamente às consultas Explorar nesta página).
- O fuso horário da consulta Explorar corresponde ao fuso horário usado pela tabela agregada (consulte a secção Fatores de fuso horário nesta página).
- Os filtros da consulta de exploração fazem referência a campos que estão disponíveis como dimensões na tabela agregada, ou cada um dos filtros da consulta de exploração corresponde a um filtro na tabela agregada (consulte a secção Fatores de filtragem nesta página).
Uma forma de garantir que uma tabela de dados agregados pode fornecer dados precisos para uma consulta de exploração é criar uma tabela de dados agregados que corresponda exatamente a uma consulta de exploração. Consulte a secção Criar tabelas agregadas que correspondem exatamente às consultas de exploração nesta página para ver detalhes.
Fatores de campo
Para ser usada numa consulta de exploração, uma tabela agregada tem de ter todas as dimensões e medidas necessárias para essa consulta de exploração, incluindo os campos usados para filtros na consulta de exploração. Se uma consulta de exploração contiver uma dimensão ou uma medida que não esteja numa tabela agregada, o Looker não pode usar a tabela agregada e usa a tabela base.
Por exemplo, se uma consulta agrupa por dimensões A e B, agrega pela métrica C e filtra pela dimensão D, a tabela de agregação tem de ter, no mínimo, A, B e D como dimensões e C como métrica.
A tabela agregada também pode ter outros campos, mas tem de ter, pelo menos, os campos de consulta de exploração para ser viável para otimização. A única exceção são as dimensões de intervalo de tempo, uma vez que os intervalos de tempo com um nível de detalhe mais baixo podem ser derivados dos intervalos de tempo com um nível de detalhe mais elevado.
Devido a estas considerações de campo, uma tabela agregada é específica da exploração na qual está definida. Uma tabela agregada definida numa exploração não é usada para consultas noutra exploração.
Fatores de prazo
A lógica de notoriedade agregada do Looker consegue derivar um período de outro. Pode usar uma tabela agregada para uma consulta, desde que o período da tabela agregada tenha uma granularidade mais detalhada (ou igual) à da consulta de exploração. Por exemplo, pode usar uma tabela agregada baseada em dados diários para uma consulta de exploração que peça outros intervalos de tempo, como consultas de dados diários, mensais e anuais, ou até mesmo dados de dia do mês, dia do ano e semana do ano. No entanto, não é possível usar uma tabela agregada anual para uma consulta de exploração que exija dados por hora, uma vez que os dados da tabela agregada não têm uma granularidade suficientemente detalhada para a consulta de exploração.
O mesmo se aplica aos subconjuntos de intervalos de tempo. Por exemplo, se tiver uma tabela agregada filtrada para os últimos três meses e um utilizador consultar os dados com um filtro para os últimos dois meses, o Looker vai poder usar a tabela agregada para essa consulta.
Além disso, a mesma lógica aplica-se a consultas com filtros de período: é possível usar uma tabela agregada para uma consulta com um filtro de período, desde que o período da tabela agregada tenha uma granularidade mais precisa (ou igual) à do filtro de período usado na consulta de exploração. Por exemplo, uma tabela agregada que tenha uma dimensão de período diário pode ser usada para uma consulta de exploração que filtre por dia, semana ou mês.
Fatores do tipo de medida
Para que uma consulta de exploração use uma tabela agregada, as métricas na tabela agregada têm de poder fornecer dados precisos para a consulta de exploração.
Por este motivo, apenas são suportados determinados tipos de medidas, conforme descrito nas secções seguintes:
- Medições com tipos de medição suportados
- Medidas definidas por expressões SQL
- Medidas que não estão definidas com
${TABLE} - Medidas que se aproximam das contagens distintas
Se uma consulta de exploração usar qualquer outro tipo de medida, o Looker usa a tabela original, e não a tabela agregada, para devolver resultados. A única exceção é se a consulta Explorar for uma correspondência exata de uma consulta de tabela agregada, conforme descrito na secção Criar tabelas agregadas que correspondam exatamente a consultas Explorar.
Caso contrário, o Looker usa a tabela original, e não a tabela agregada, para devolver resultados.
Medidas com tipos de medidas suportados
A notoriedade agregada pode ser usada para consultas de exploração que usam medidas com estes tipos de medidas:
Para usar uma tabela agregada para uma consulta de exploração, o Looker tem de poder operar nas medidas da tabela agregada para fornecer dados precisos na consulta de exploração. Por exemplo, uma métrica com type: sum pode ser usada para a notoriedade agregada, porque pode somar várias somas: é possível somar uma tabela agregada de somas semanais para obter uma soma mensal precisa. Da mesma forma, pode usar uma medida com type: max porque é possível usar uma tabela agregada de máximos diários para encontrar o máximo semanal preciso.
No caso das medidas com type: average, a notoriedade agregada é suportada porque o Looker usa dados de soma e contagem para derivar com precisão os valores médios das tabelas agregadas.
Medidas definidas com expressões SQL
A agregação de notoriedade também pode ser usada com medidas definidas com expressões no parâmetro sql. Quando definidos com expressões SQL, os seguintes tipos de métricas também são suportados:
A notoriedade agregada é suportada para medidas definidas como combinações de outras medidas, como neste exemplo:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
A agregação de notoriedade também é suportada para medidas em que os cálculos são definidos no parâmetro sql, como esta medida:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
A agregação de reconhecimento é suportada para medidas em que as operações MIN, MAX e COUNT são definidas no parâmetro sql, como esta medida:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
Medidas que fazem referência a campos do LookML
Quando as expressões sql são usadas em medidas, a agregação de notoriedade suporta os seguintes tipos de referências de campos:
- Referências que usam o formato
${view_name.field_name}, que indica campos noutras vistas - Referências que usam o formato
${field_name}, que indica campos na mesma vista
A agregação de notoriedade não é suportada para medidas definidas com o formato ${TABLE}.column_name, que indica uma coluna numa tabela. (Consulte a página de documentação Incorporar SQL e referir-se a objetos LookML para ver uma vista geral da utilização de referências no LookML.)
Por exemplo, uma medida definida com este parâmetro sql não seria suportada numa tabela agregada, uma vez que usa o formato ${TABLE}.column_name:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
Se quiser incluir esta medida numa tabela agregada, pode, em alternativa, criar uma dimensão definida com o formato ${TABLE}.column_name e, em seguida, criar uma medida que faça referência à dimensão, da seguinte forma:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Agora, pode usar a medida wholesale_value na tabela agregada.
Medidas que se aproximam das contagens distintas
Em geral, as contagens distintas não são suportadas com a notoriedade agregada, porque não pode obter dados precisos se tentar agregar contagens distintas. Por exemplo, se estiver a contabilizar os utilizadores distintos num Website, pode haver um utilizador que acedeu ao Website duas vezes, com um intervalo de três semanas. Se tentou aplicar uma tabela agregada semanal para obter uma contagem mensal de utilizadores distintos no seu Website, esse utilizador seria contabilizado duas vezes na sua consulta de contagem distinta mensal, e os dados estariam incorretos.
Uma solução alternativa para este problema é criar uma tabela agregada que corresponda exatamente a uma consulta de exploração, conforme descrito na secção Criar tabelas agregadas que correspondam exatamente a consultas de exploração nesta página. Quando a consulta de exploração e uma consulta de tabela agregada são iguais, as medidas de contagem distinta fornecem dados precisos, pelo que podem ser usadas para a notoriedade agregada.
Outra opção é usar aproximações para contagens distintas. Para dialetos que suportam esboços HyperLogLog, o Looker pode tirar partido do algoritmo HyperLogLog para aproximar contagens distintas para tabelas agregadas.
Sabe-se que o algoritmo HyperLogLog tem um erro de cerca de 2%. O parâmetro allow_approximate_optimization: yes requer que os programadores do Looker confirmem que não há problema em usar dados aproximados para a medida, para que a medida possa ser calculada aproximadamente a partir de tabelas agregadas.
Consulte a página de documentação do parâmetro allow_approximate_optimization para obter mais informações e a lista de dialetos que suportam a contagem distinta através do HyperLogLog.
Fatores do fuso horário
Em muitos casos, os administradores de bases de dados usam o UTC como o fuso horário para bases de dados. No entanto, muitos utilizadores podem não estar no fuso horário UTC. O Looker tem várias opções para converter fusos horários, para que os seus utilizadores recebam resultados de consultas no respetivo fuso horário:
- Fuso horário da consulta, uma definição que se aplica a todas as consultas na ligação à base de dados. Se todos os seus utilizadores estiverem no mesmo fuso horário, pode definir um único fuso horário de consulta para que todas as consultas sejam convertidas do fuso horário da base de dados para o fuso horário de consulta.
- Fusos horários específicos do utilizador, em que os utilizadores podem ser atribuídos e selecionar fusos horários individualmente. Neste caso, as consultas são convertidas do fuso horário da base de dados para o fuso horário do utilizador individual.
Consulte a página de documentação Usar definições de fuso horário para mais informações sobre estas opções.
Estes conceitos são importantes para compreender a consciência agregada porque, para que uma tabela agregada seja usada para uma consulta com dimensões de data ou filtros de data, o fuso horário na tabela agregada tem de corresponder à definição de fuso horário usada para a consulta original.
As tabelas agregadas usam o fuso horário da base de dados se não for especificado nenhum valor timezone. A ligação à base de dados também usa o fuso horário da base de dados se alguma das seguintes afirmações for verdadeira:
- A sua base de dados não suporta fusos horários.
- O fuso horário de consulta da ligação à base de dados está definido para o mesmo fuso horário que o fuso horário da base de dados.
- A ligação à base de dados não tem um fuso horário de consulta especificado nem fusos horários específicos do utilizador. Se for este o caso, a ligação à base de dados usa o fuso horário da base de dados.
Se alguma destas situações for verdadeira, pode omitir o parâmetro timezone para as tabelas agregadas.
Caso contrário, o fuso horário da tabela de agregação deve ser definido de modo a corresponder a possíveis consultas para que a tabela de agregação seja mais provável de ser usada:
- Se a ligação à base de dados usar um único fuso horário de consulta, deve fazer corresponder o valor
timezoneda tabela agregada ao valor do fuso horário de consulta. - Se a ligação à base de dados usar fusos horários específicos do utilizador, deve criar tabelas agregadas idênticas, cada uma com um valor
timezonediferente para corresponder aos possíveis fusos horários dos seus utilizadores.
Fatores de filtro
Tenha cuidado ao incluir filtros na tabela agregada. Os filtros numa tabela agregada podem restringir os resultados ao ponto de a tabela agregada ficar inutilizável. Por exemplo, suponhamos que cria uma tabela agregada para as contagens de encomendas diárias e que a tabela agregada filtra apenas as encomendas de óculos de sol provenientes da Austrália. Se um utilizador executar uma consulta de exploração para as quantidades de encomendas diárias de óculos de sol em todo o mundo, o Looker não pode usar a tabela agregada para essa consulta de exploração, uma vez que a tabela agregada só tem os dados da Austrália. A tabela agregada filtra os dados de forma demasiado restrita para serem usados pela consulta Explorar.
Além disso, tenha em atenção os filtros que os seus programadores do Looker podem ter incorporado na sua funcionalidade Explorar, como:
access_filters: aplica restrições de dados específicas do utilizador.always_filter: obrigar os utilizadores a incluir um determinado conjunto de filtros para uma consulta de exploração. Os utilizadores podem alterar o valor do filtro predefinido para a respetiva consulta, mas não podem remover o filtro por completo.conditionally_filter: define um conjunto de filtros predefinidos que os utilizadores podem substituir se aplicarem, pelo menos, um filtro de uma segunda lista que também está definida na funcionalidade Explorar.
Estes tipos de filtros baseiam-se em campos específicos. Se a sua exploração tiver estes filtros, tem de incluir os respetivos campos no parâmetro dimensions do aggregate_table.
Por exemplo, aqui está uma exploração com um filtro de acesso baseado no campo orders.region:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
Para criar uma tabela agregada que seria usada para esta análise detalhada, a tabela agregada tem de incluir o campo no qual o filtro de acesso se baseia. No exemplo seguinte, o filtro de acesso baseia-se no campo orders.region, e este mesmo campo é incluído como uma dimensão na tabela agregada:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Uma vez que a consulta da tabela agregada inclui a dimensão orders.region, o Looker pode filtrar dinamicamente os dados na tabela agregada para corresponder ao filtro da consulta de exploração. Por conseguinte, o Looker pode continuar a usar a tabela de agregação para as consultas da análise detalhada, mesmo que a análise detalhada tenha um filtro de acesso.
Isto também se aplica a consultas de exploração que usam uma tabela derivada nativa configurada com bind_filters. O parâmetro bind_filters transmite filtros especificados de uma consulta de exploração para a subconsulta da tabela derivada nativa. No caso da notoriedade agregada, se a sua consulta de exploração exigir uma tabela derivada nativa que use bind_filters, a consulta de exploração só pode usar uma tabela agregada se todos os campos usados no parâmetro bind_filters da tabela derivada nativa tiverem exatamente os mesmos valores de filtro na consulta de exploração que na tabela agregada.
Criar tabelas agregadas que correspondam exatamente às consultas da funcionalidade Explorar
Uma forma de garantir que uma tabela de dados agregados pode ser usada para uma consulta de exploração é criar uma tabela de dados agregados que corresponda exatamente à consulta de exploração. Se a consulta Explorar e a tabela agregada usarem as mesmas medidas, dimensões, filtros, fusos horários e outros parâmetros, por definição, os resultados da tabela agregada aplicam-se à consulta Explorar. Se uma tabela agregada for uma correspondência exata de uma consulta de exploração, o Looker pode usar tabelas agregadas que incluam qualquer tipo de medida.
Pode criar uma tabela agregada a partir de uma exploração através da opção Obter LookML no menu de roda dentada de uma exploração. Também pode criar correspondências exatas para todos os mosaicos num painel de controlo através da opção Obter LookML no menu de engrenagem de um painel de controlo.
Determinar que tabela agregada é usada para uma consulta
Os utilizadores com autorizações see_sql podem usar os comentários no separador SQL de uma exploração para ver que tabela agregada vai ser usada para uma consulta. Os comentários do separador SQL também são apresentados no modo de programação, para que os programadores possam testar novas tabelas agregadas para ver como o Looker as usa antes de enviar novas tabelas para produção.
Por exemplo, com base na tabela agregada mensal de exemplo apresentada anteriormente, pode aceder à funcionalidade Explorar e executar uma consulta para os totais de vendas anuais. Em seguida, pode clicar no separador SQL para ver os detalhes da consulta que o Looker criou. Se estiver no modo de programação, o Looker mostra comentários para indicar a tabela agregada que usou para a consulta.
A partir dos seguintes comentários no separador SQL, podemos ver que o Looker está a usar a tabela agregada sales_monthly para esta consulta e informações sobre o motivo pelo qual outras tabelas agregadas não foram usadas para a consulta:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
Consulte a secção Resolução de problemas nesta página para ver possíveis comentários que pode ver no separador SQL e sugestões sobre como os resolver.
Estimativas de poupanças de computação para a notoriedade agregada
Se a ligação da base de dados suportar estimativas de custos e se for possível usar uma tabela agregada para uma consulta, a janela de exploração mostra as poupanças de computação da utilização da tabela agregada em vez de consultar diretamente a base de dados. A poupança de notoriedade agregada é apresentada junto ao botão Executar numa análise detalhada antes de a consulta ser executada.
Antes de executar a consulta, se quiser ver que tabela agregada vai ser usada para a consulta, pode clicar no separador SQL, conforme descrito na secção Determinar que tabela agregada é usada para uma consulta desta página de documentação.
Depois de executar a consulta, a janela Explorar mostra a tabela de agregação que foi usada para responder à consulta junto ao botão Executar.
A poupança de notoriedade agregada é apresentada para associações de bases de dados ativadas para estimativas de custos. Consulte a página de documentação Explorar dados no Looker para mais informações.
O Looker une os novos dados às suas tabelas agregadas
Para tabelas agregadas com filtros de tempo, o Looker pode unir dados atualizados na sua tabela agregada. Pode ter uma tabela agregada que inclua dados dos últimos três dias, mas essa tabela agregada pode ter sido criada ontem. A tabela agregada não teria as informações de hoje, pelo que não seria expectável usá-la para uma consulta de exploração sobre as informações diárias mais recentes.
No entanto, o Looker continua a poder usar os dados nessa tabela agregada para a consulta, porque o Looker executa uma consulta nos dados mais recentes e, em seguida, une esses resultados aos resultados na tabela agregada.
O Looker pode unir dados atualizados com os dados da tabela agregada nas seguintes circunstâncias:
- A tabela agregada tem um filtro de tempo.
- A tabela agregada inclui uma dimensão baseada no mesmo campo de tempo que o filtro de tempo.
Por exemplo, a seguinte tabela agregada tem uma dimensão baseada no campo orders.created_date e tem um filtro de tempo ("3 days") baseado no mesmo campo:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
Se esta tabela agregada foi criada ontem, o Looker vai obter os dados mais recentes que ainda não estão incluídos na tabela agregada e, em seguida, unir os resultados atualizados aos resultados da tabela agregada. Isto significa que os seus utilizadores vão receber os dados mais recentes, enquanto continua a otimizar o desempenho através da notoriedade agregada.
Se estiver no modo de programação, pode clicar no separador SQL de uma exploração para ver a tabela agregada que o Looker usou para a consulta e a declaração UNION que o Looker usou para incluir dados mais recentes que não estavam incluídos na tabela agregada.
As tabelas agregadas têm de ser persistentes
Para ser acessível para a notoriedade agregada, a sua tabela agregada tem de ser mantida na sua base de dados. A estratégia de persistência é especificada no parâmetro materialization da tabela agregada. Uma vez que as tabelas agregadas são um tipo de tabela derivada persistente (PDT), têm os mesmos requisitos que as PDTs. Consulte a página de documentação Tabelas derivadas no Looker para ver detalhes.
Pode criar PDTs incrementais no seu projeto se o seu dialeto os suportar. O Looker cria PDTs incrementais anexando dados atualizados à tabela, em vez de reconstruir a tabela na íntegra. Uma vez que as tabelas agregadas são, em si mesmas, um tipo de PDT, também pode criar tabelas agregadas incrementais. Consulte a página de documentação PDTs incrementais para mais informações sobre os PDTs incrementais. Consulte a página de documentação do parâmetro increment_key para ver um exemplo de uma tabela agregada incremental.
Um utilizador com autorização develop pode substituir as definições de persistência e reconstruir todas as tabelas agregadas para uma consulta de modo a obter os dados mais atualizados. Para recompilar as tabelas de uma consulta, selecione a opção Recompilar tabelas derivadas e executar no menu de engrenagem Ações do Explorar.
Tem de aguardar que a consulta Explorar seja carregada antes de esta opção estar disponível.
A opção Recompilar tabelas derivadas e executar recompila todas as tabelas derivadas referenciadas na consulta, bem como todas as tabelas derivadas das quais as tabelas na consulta dependem. Isto inclui tabelas de agregação, que são, em si mesmas, um tipo de tabela derivada persistente.
Para o utilizador que inicia a opção Recompilar tabelas derivadas e executar, a consulta aguarda a recompilação das tabelas antes de carregar os resultados. As consultas de outros utilizadores continuam a usar as tabelas existentes. Assim que as tabelas persistentes forem reconstruídas, todos os utilizadores vão usar as tabelas reconstruídas.
Consulte a página de documentação Tabelas derivadas no Looker para ver mais detalhes acerca da opção Recompilar tabelas derivadas e executar.
Resolução de problemas
Conforme descrito na secção Determinar que tabela agregada é usada para uma consulta, se estiver no modo de programação, pode executar consultas na ferramenta Explorar e clicar no separador SQL para ver comentários sobre a tabela agregada usada para a consulta, se existir.
O separador SQL também inclui comentários sobre o motivo pelo qual as tabelas agregadas não foram usadas para uma consulta, se for o caso. Para tabelas agregadas que não são usadas, o comentário começa com:
Did not use [explore name]::[aggregate table name];
Por exemplo, segue-se um comentário sobre o motivo pelo qual a sales_daily tabela agregada definida na order_items análise detalhada não foi usada para uma consulta:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
Neste caso, os filtros na consulta impediram a utilização da tabela agregada.
A tabela seguinte mostra outros motivos possíveis pelos quais não é possível usar uma tabela agregada, juntamente com os passos que pode seguir para aumentar a usabilidade da tabela agregada.
| Motivo para não usar a tabela agregada | Explicação e possíveis passos |
|---|---|
| Não existe nenhum campo deste tipo na opção Explorar. | Existe um erro de tipo de validação do LookML. Provavelmente, isto deve-se ao facto de a tabela agregada não ter sido definida corretamente ou de ter havido um erro ortográfico no LookML da tabela agregada. Um provável culpado é um nome de campo incorreto ou semelhante.Para resolver este problema, verifique se as dimensões e as métricas na tabela agregada correspondem aos nomes dos campos na análise detalhada. Consulte a página de documentação do parâmetro aggregate_table para mais informações sobre como definir uma tabela agregada. |
| A tabela agregada não inclui os seguintes campos na consulta. | Para ser usada numa consulta de exploração, uma tabela agregada tem de ter todas as dimensões e medidas necessárias para essa consulta de exploração, incluindo os campos usados para filtros na consulta de exploração. Se uma consulta de exploração contiver uma dimensão ou uma medida que não esteja numa tabela agregada, o Looker não pode usar a tabela agregada e usa a tabela base. Consulte a secção Fatores de campo nesta página para ver detalhes. A única exceção são as dimensões de intervalo de tempo, uma vez que os intervalos de tempo com um nível de detalhe mais baixo podem ser derivados dos intervalos de tempo com um nível de detalhe mais elevado. Para resolver este problema, verifique se os campos da consulta Explorar estão incluídos na definição da tabela agregada. |
| A consulta continha os seguintes filtros que não foram incluídos como campos nem corresponderam exatamente aos filtros na tabela de dados agregados. | Os filtros na consulta de exploração impedem o Looker de usar a tabela de agregação. Para resolver este problema, pode fazer uma das seguintes ações:
|
| A consulta contém as seguintes medidas que não podem ser agregadas. | A consulta contém um ou mais tipos de medidas que não são suportados para a notoriedade agregada, como contagem distinta, mediana ou percentil.Para resolver este problema, verifique o tipo de cada medida na consulta e certifique-se de que é um dos tipos de medidas suportados. Além disso, se o seu Explore tiver junções, verifique se as medidas não são convertidas em medidas distintas (agregados simétricos) através de junções expandidas. Consulte a secção Agregações simétricas para explorações com junções nesta página para ver uma explicação. |
| Uma tabela agregada diferente era mais adequada para a otimização. | Existiam várias tabelas agregadas viáveis para a consulta e o Looker encontrou uma tabela agregada mais otimizada para usar em alternativa. Neste caso, não tem de fazer nada. |
O Looker não fez qualquer agrupamento (devido a um parâmetro primary_key ou cancel_grouping_fields) e, por isso, não é possível resumir a consulta. |
A consulta faz referência a uma dimensão que impede que tenha uma cláusula GROUP BY e, por isso, o Looker não pode usar nenhuma tabela de agregação para a consulta.
Para resolver este problema, verifique se o parâmetro primary_key da vista e o parâmetro cancel_grouping_fields da análise detalhada estão configurados corretamente. |
| A tabela agregada continha filtros que não estavam na consulta. | A tabela agregada tem um filtro que não é de tempo e que não está na consulta.Para resolver este problema, pode remover o filtro da tabela agregada. Consulte a secção Fatores de filtro nesta página para ver detalhes. |
Um campo é definido como um campo apenas de filtragem na consulta de exploração, mas é apresentado no parâmetro dimensions da tabela agregada. |
O parâmetro dimensions da tabela agregada lista um campo que está definido apenas como um campo filter na consulta de exploração.Para resolver este problema, remova o campo da lista dimensions da tabela agregada. Se este campo for necessário para a tabela de agregação, adicione-o à lista filters na consulta da tabela de agregação. |
| O otimizador não consegue determinar o motivo pelo qual a tabela agregada não foi usada. | Este comentário está reservado para casos extremos. Se vir esta mensagem para uma consulta da funcionalidade Explorar que é usada com frequência, pode criar uma tabela agregada que corresponda exatamente à consulta da funcionalidade Explorar. Pode obter o LookML da tabela agregada a partir de uma exploração, conforme descrito na página do parâmetro aggregate_table. |
Aspetos a considerar
Acumulações simétricas para explorações com junções
Uma coisa importante a ter em atenção é que, numa análise detalhada que junta várias tabelas de base de dados, o Looker pode renderizar medidas do tipo SUM, COUNT e AVERAGE como SUM DISTINCT, COUNT DISTINCT e AVERAGE DISTINCT, respetivamente. O Looker faz isto para evitar erros de cálculo de fanout. Por exemplo, uma medida count é renderizada como um tipo de medida count_distinct. Isto destina-se a evitar erros de cálculo de fanout para junções e faz parte da funcionalidade de agregados simétricos do Looker. Consulte a página de práticas recomendadas sobre agregados simétricos para uma explicação desta funcionalidade do Looker.
A funcionalidade de dados agregados simétricos impede cálculos incorretos, mas também pode impedir que as tabelas de dados agregados sejam usadas em determinados casos. Por isso, é importante compreendê-la.
Para os tipos de métricas suportados pela notoriedade agregada, isto aplica-se a sum, count e average. O Looker renderiza estes tipos de medidas como DISTINCT se:
- A medida é da vista "um" de uma junção muitos-para-um ou um-para-muitos.
- A medida é proveniente de qualquer uma das vistas de uma junção muitos para muitos.
Consulte a página de documentação dos parâmetros relationship para ver uma explicação destes tipos de junções.
Se verificar que a sua tabela agregada não está a ser usada por este motivo, pode criar uma tabela agregada que corresponda exatamente a uma consulta de exploração para usar estes tipos de métricas numa exploração com junções. Consulte a secção Criar tabelas agregadas que correspondam exatamente às consultas de exploração nesta página para mais informações.
Além disso, se tiver um dialeto de SQL que suporte esboços HyperLogLog, pode adicionar o parâmetro allow_approximate_optimization: yes à medida. Quando uma medida de contagem é definida com allow_approximate_optimization: yes, o Looker pode usar a medida para a notoriedade agregada, mesmo que seja renderizada como uma contagem distinta.
Consulte a página de documentação do parâmetro allow_approximate_optimization para ver detalhes e uma lista dos dialetos de SQL que suportam esboços HyperLogLog.
Suporte de dialetos para a notoriedade agregada
A capacidade de usar a agregação depende do dialeto da base de dados que a sua ligação do Looker está a usar. No lançamento mais recente do Looker, os seguintes dialetos suportam a notoriedade agregada:
| Dialeto | Suportado? |
|---|---|
| Actian Avalanche | Sim |
| Amazon Athena | Sim |
| Amazon Aurora MySQL | Sim |
| Amazon Redshift | Sim |
| Amazon Redshift 2.1+ | Sim |
| Amazon Redshift Serverless 2.1+ | Sim |
| Apache Druid | Não |
| Apache Druid 0.13+ | Não |
| Apache Druid 0.18+ | Não |
| Apache Hive 2.3+ | Sim |
| Apache Hive 3.1.2+ | Sim |
| Apache Spark 3+ | Sim |
| ClickHouse | Não |
| Cloudera Impala 3.1+ | Sim |
| Cloudera Impala 3.1+ with Native Driver | Sim |
| Cloudera Impala with Native Driver | Sim |
| DataVirtuality | Não |
| Databricks | Sim |
| Denodo 7 | Não |
| Denodo 8 & 9 | Não |
| Dremio | Não |
| Dremio 11+ | Não |
| Exasol | Sim |
| Google BigQuery Legacy SQL | Sim |
| Google BigQuery Standard SQL | Sim |
| Google Cloud PostgreSQL | Sim |
| Google Cloud SQL | Não |
| Google Spanner | Não |
| Greenplum | Sim |
| HyperSQL | Não |
| IBM Netezza | Sim |
| MariaDB | Sim |
| Microsoft Azure PostgreSQL | Sim |
| Microsoft Azure SQL Database | Sim |
| Microsoft Azure Synapse Analytics | Sim |
| Microsoft SQL Server 2008+ | Sim |
| Microsoft SQL Server 2012+ | Sim |
| Microsoft SQL Server 2016 | Sim |
| Microsoft SQL Server 2017+ | Sim |
| MongoBI | Não |
| MySQL | Sim |
| MySQL 8.0.12+ | Sim |
| Oracle | Sim |
| Oracle ADWC | Sim |
| PostgreSQL 9.5+ | Sim |
| PostgreSQL pre-9.5 | Sim |
| PrestoDB | Sim |
| PrestoSQL | Sim |
| SAP HANA | Sim |
| SAP HANA 2+ | Sim |
| SingleStore | Sim |
| SingleStore 7+ | Sim |
| Snowflake | Sim |
| Teradata | Sim |
| Trino | Sim |
| Vector | Sim |
| Vertica | Sim |
Suporte de dialeto para a criação incremental de tabelas agregadas
Para que o Looker suporte tabelas agregadas incrementais no seu projeto do Looker, o dialeto da base de dados também tem de as suportar. A tabela seguinte mostra os dialetos que suportam a criação incremental de PDTs na versão mais recente do Looker:
| Dialeto | Suportado? |
|---|---|
| Actian Avalanche | Não |
| Amazon Athena | Não |
| Amazon Aurora MySQL | Não |
| Amazon Redshift | Sim |
| Amazon Redshift 2.1+ | Sim |
| Amazon Redshift Serverless 2.1+ | Sim |
| Apache Druid | Não |
| Apache Druid 0.13+ | Não |
| Apache Druid 0.18+ | Não |
| Apache Hive 2.3+ | Não |
| Apache Hive 3.1.2+ | Não |
| Apache Spark 3+ | Não |
| ClickHouse | Não |
| Cloudera Impala 3.1+ | Não |
| Cloudera Impala 3.1+ with Native Driver | Não |
| Cloudera Impala with Native Driver | Não |
| DataVirtuality | Não |
| Databricks | Sim |
| Denodo 7 | Não |
| Denodo 8 & 9 | Não |
| Dremio | Não |
| Dremio 11+ | Não |
| Exasol | Não |
| Google BigQuery Legacy SQL | Não |
| Google BigQuery Standard SQL | Sim |
| Google Cloud PostgreSQL | Sim |
| Google Cloud SQL | Não |
| Google Spanner | Não |
| Greenplum | Sim |
| HyperSQL | Não |
| IBM Netezza | Não |
| MariaDB | Não |
| Microsoft Azure PostgreSQL | Sim |
| Microsoft Azure SQL Database | Não |
| Microsoft Azure Synapse Analytics | Sim |
| Microsoft SQL Server 2008+ | Não |
| Microsoft SQL Server 2012+ | Não |
| Microsoft SQL Server 2016 | Não |
| Microsoft SQL Server 2017+ | Não |
| MongoBI | Não |
| MySQL | Sim |
| MySQL 8.0.12+ | Sim |
| Oracle | Não |
| Oracle ADWC | Não |
| PostgreSQL 9.5+ | Sim |
| PostgreSQL pre-9.5 | Sim |
| PrestoDB | Não |
| PrestoSQL | Não |
| SAP HANA | Não |
| SAP HANA 2+ | Não |
| SingleStore | Não |
| SingleStore 7+ | Não |
| Snowflake | Sim |
| Teradata | Não |
| Trino | Não |
| Vector | Não |
| Vertica | Sim |