Looker では、利用可能でキャッシュ ポリシーにより許可されている場合、以前のクエリのキャッシュに保存された結果を使用して、データベースの負荷を減らしてパフォーマンスを向上させます。また、複雑なクエリを永続的な派生テーブル(PDT)として作成し、結果を保存して後のクエリを簡素化することもできます。
データグループは、データベースの ETL(抽出、変換、読み込み)のスケジュールを Looker のキャッシュ ポリシーと PDT の再ビルド スケジュールに合わせて調整するのに非常に便利です。データグループを使用すると、データベースに新しいデータが追加されたタイミングに基づいて、PDT の再構築トリガーを指定できます。同じデータグループで、なんらかの理由で PDT の再ビルドがトリガーされない場合に、Explore クエリがフェイルセーフとして機能するように最大キャッシュ期間を指定できます。このようにして、データグループの故障モードで、Lookerキャッシュから失効したデータが供給されるのではなく、データベースをクエリすることができます。
あるいは、データグループを使用して、PDT の再構築トリガーをキャッシュの最大存続期間から分離することもできます。これは、頻繁に更新されるデータに基づく Explore があり、再ビルドの頻度が低い PDT にその Explore が結合されている場合に便利です。このようなケースでは、PDTが再構築される頻度よりも頻繁にクエリキャッシュをリセットしたいと思うでしょう。
クエリのキャッシュの詳細については、このドキュメント ページの Looker のキャッシュされたクエリの使用方法をご覧ください。
データグループの定義
データグループは、モデルファイルまたは独自の LookML ファイルで、datagroup パラメータを使用して定義されます。プロジェクトの異なるExploreやPDTに対して、それぞれ異なるキャッシングポリシーやPDT再構築ポリシーを設定したい場合は、複数のデータグループを定義できます。
datagroup パラメータには次のサブパラメータを指定できます。
label- データグループのオプションのラベルを指定します。description- データグループの目的とメカニズムの説明に使用できる、データグループの任意の説明を指定します。max_cache_age- 期間を定義する文字列を指定します。クエリのキャッシュの経過時間が所定の時間を超えると、Looker はキャッシュを無効にします。次回このクエリが発行されると、クエリはデータベースに送られ、最新の結果が取得されます。interval_trigger- データグループをトリガーする期間("24 hours"など)のスケジュールを指定します。
これらのパラメータについて詳しくは、データグループのドキュメント ページをご覧ください。
データグループには、少なくとも max_cache_age パラメータ、sql_trigger パラメータ、または interval_trigger パラメータが必要です。
データグループに
sql_triggerパラメータとinterval_triggerパラメータの両方を設定することはできません。両方のパラメータでデータグループを定義する場合、データグループはinterval_trigger値を使用し、sql_trigger値を無視します。これは、sql_triggerパラメータは、データベースをクエリするときにデータベース リソースを使用することが要求されるためです。
PDT を毎日再構築するよう sql_trigger が設定されているデータグループの例を次に示します。また、max_cache_age は、いずれかの Explore が 1 日 1 回以上の頻度で更新される他のデータに PDT を結合する場合に備えて、クエリ キャッシュを 2 時間ごとにクリアするように設定されています。
datagroup: customers_datagroup {
sql_trigger: SELECT DATE(NOW());;
max_cache_age: "2 hours"
}
データグループを定義したら、それをExploreとPDTに割り当てることができます。
- データグループを PDT に割り当てるには、
derived_tableパラメータの下のdatagroup_triggerパラメータを使用します。例については、このページのデータグループを使用して PDT の再ビルドトリガーを指定するをご覧ください。 - データグループを Explore に割り当てるには、モデルレベルまたはExplore レベルで
persist_withパラメータを使用します。例については、このページのデータグループを使用して Explore のクエリ キャッシュのリセットを指定するをご覧ください。
データグループを使用してPDTの再構築トリガーを指定する
データグループを使用して PDT 再構築トリガーを定義するには、sql_trigger または interval_trigger サブパラメータを指定して datagroup パラメータを作成します。次に、PDT' の derived_table 定義内の datagroup_trigger サブパラメータを使用して、データグループを個々の PDT に割り当てます。PDT に datagroup_trigger を使用する場合、派生テーブルに対して他の永続性戦略を指定する必要はありません。PDT に複数の永続化戦略を指定すると、Looker IDE に警告が表示され、datagroup_trigger のみが使用されます。
customers_datagroup データグループを使用する PDT 定義の例を次に示します。この定義では、customer_id と first_order_date の両方に複数のインデックスも追加されます。PDT の定義について詳しくは、Looker の派生テーブルに関するドキュメント ページをご覧ください。
view: customer_order_facts {
derived_table: {
sql: ... ;;
datagroup_trigger: customers_datagroup
indexes: ["customer_id", "first_order_date"]
}
}
カスケード PDT、他の PDT に依存する PDT がある場合は、互換性のないデータグループ キャッシュ ポリシーを指定しないように注意してください。
接続パラメータを指定するユーザー属性がある接続では、次のいずれかを行うには、PDT オーバーライド フィールドを使用して別の接続を作成する必要があります。
• モデルで PDT を使用する
• データグループを使用して PDT 再ビルドトリガーを定義します
PDT のオーバーライドがなくても、データグループでmax_cache_ageを使用してキャッシュを定義できます。
データグループと PDT の連携の詳細については、Looker の派生テーブルをご覧ください。
データグループを使用してExploreのクエリキャッシュリセットを指定する
データグループがトリガーされると、Looker リジェネレータは、そのデータグループを永続化戦略として使用する PDT を再構築します。データグループの PDT が再ビルドされると、Looker はデータグループの再構築 PDT を使用する Explore のキャッシュを削除します。データグループのクエリ キャッシュ リセット スケジュールをカスタマイズするには、max_cache_age パラメータをデータグループ定義に追加します。max_cache_age パラメータを使用すると、データグループの PDT の再構築時に Looker が実行する自動クエリ キャッシュのリセットに加えて、指定したスケジュールでクエリ キャッシュを削除できます。
データグループでクエリ キャッシュ ポリシーを定義するには、max_cache_age サブパラメータを使用して datagroup パラメータを作成します。
Explore でのクエリのキャッシュのリセットに使用するデータグループを指定するには、persist_with パラメータを使用します。
- モデル内のすべての Explore でデータグループをデフォルトとして割り当てるには、モデルレベル(モデルファイル)の
persist_withパラメータを使用します。 - データグループを個々の Explore に割り当てるには、
exploreパラメータの下にあるpersist_withパラメータを使用します。
次の例は、モデルファイルで定義されている orders_datagroup という名前のデータグループを示しています。データグループには、sql_trigger パラメータがあります。このパラメータにより、クエリ select max(id) from my_tablename が、ETL の発生を検出するために使用されます。その ETL がしばらくの間発生しなくても、データグループの max_cache_age は、キャッシュされたデータを最大 24 時間だけ使用するように指定します。
モデルの persist_with パラメータは、orders_datagroup キャッシュ ポリシーを参照します。つまり、これはモデル内のすべての Explore のデフォルトのキャッシュ ポリシーになります。ただし、customer_facts と customer_background の Explore にはモデルのデフォルトのキャッシュ ポリシーを使用しません。したがって、persist_with パラメータを追加して、この 2 つの Explore に別のキャッシュ ポリシーを指定できます。orders と orders_facts の Explore には persist_with パラメータがないため、モデルのデフォルトのキャッシュ ポリシー(orders_datagroup)を使用します。
datagroup: orders_datagroup {
sql_trigger: SELECT max(id) FROM my_tablename ;;
max_cache_age: "24 hours"
}
datagroup: customers_datagroup {
sql_trigger: SELECT max(id) FROM my_other_tablename ;;
}
persist_with: orders_datagroup
explore: orders { ... }
explore: order_facts { ... }
explore: customer_facts {
persist_with: customers_datagroup
...
}
explore: customer_background {
persist_with: customers_datagroup
...
}
persist_with と persist_for の両方を指定すると、検証の警告が表示され、persist_with が使用されます。
データグループを使ってスケジュールされた配信をトリガーする
データグループは、ダッシュボード、以前のダッシュボード、または Look の配信をトリガーするためにも使用できます。このオプションを使うと、データグループが完了するとLookerはデータを送信し、スケジュール設定されたコンテンツが最新の状態となります。
データグループの管理パネルの使用
Looker 管理者のロールをお持ちの場合は、[管理] パネルの [データグループ] ページを使用して既存のデータグループを表示できます。各データグループの接続、モデル、現在のステータスを確認できます。LookML で指定されている場合は、各データグループのラベルと説明も表示されます。データグループのキャッシュをリセットしたり、データグループをトリガーしたり、データグループの LookML に移動したりすることもできます。

Lookerにおけるキャッシュされたクエリの用途
Lookerにおけるクエリのキャッシングの仕組みは次のとおりです。
- ユーザーが特定のクエリを実行すると、そのクエリの結果はキャッシュに保存されます。キャッシュされた結果はLookerインスタンス上の暗号化ファイルに保存されます。
新しいクエリが書き込まれると、キャッシュがチェックされ、正確なクエリが以前に実行されたかどうかを確認します。行の上限などの設定を含め、すべてのフィールド、フィルタ、パラメータは同一である必要があります。まったく同じクエリが見つからなければ、テータベースに対してクエリが実行され、新たに結果を取得します(そして、その結果がキャッシュされます)。
コンテキスト コメントはキャッシュには影響しません。Looker では、各 SQL クエリの先頭に一意のコメントが追加されます。ただし、SQLクエリそのものが(コンテキストコメントを除き)以前のクエリと同じである限り、キャッシュされた結果を使用します。
クエリがキャッシュで見つかると、Looker はモデルで定義されているキャッシング ポリシーをチェックし、キャッシュが有効かどうかを確認します。デフォルトでは、Looker は 1 時間後にキャッシュされた結果を無効にします。
persist_forパラメータ(モデルレベルまたは Explore レベル)またはより強力なdatagroupパラメータを使用して、キャッシュに保存された結果が無効になり無視される状況を決定するキャッシュ ポリシーを指定できます。管理者がデータグループのキャッシュされた結果を無効にすることもできます。- キャッシュがまだ有効な場合には、その結果を使用します。
- キャッシュが無効になっている場合、Looker はデータベースに対してクエリを実行して、新しいクエリ結果を取得します。(そして、その新しい結果がキャッシュされます。)
クエリの結果がキャッシュから返されたものかどうかを確認する
[Explore] ウィンドウでクエリを実行すると、右上隅を見ることでキャッシュからクエリが返されているかどうかを確認できます。
クエリがキャッシュから返された場合は、「キャッシュから」と表示されます。それ以外の場合、クエリを返すためにかかった合計時間が表示されます。

データベースから強制的に新しい結果が生成されるようにする
[Explore] ウィンドウで、データベースから新しい結果を強制的に取得できます。クエリを実行した後、画面右上に表示される歯車メニューから [キャッシュを消去して更新] オプションを選択します(Merged Results を含む)。
![]()
通常、永続的な派生テーブルは PDT の永続化戦略に基づいて再生成されます。管理者が develop 権限を付与していて、PDT のフィールドを含む Explore を表示している場合は、派生テーブルを早期に再ビルドできます。クエリの実行後に画面右上に表示される歯車のプルダウン メニューから、[派生テーブルを再ビルド] オプションを選択します。
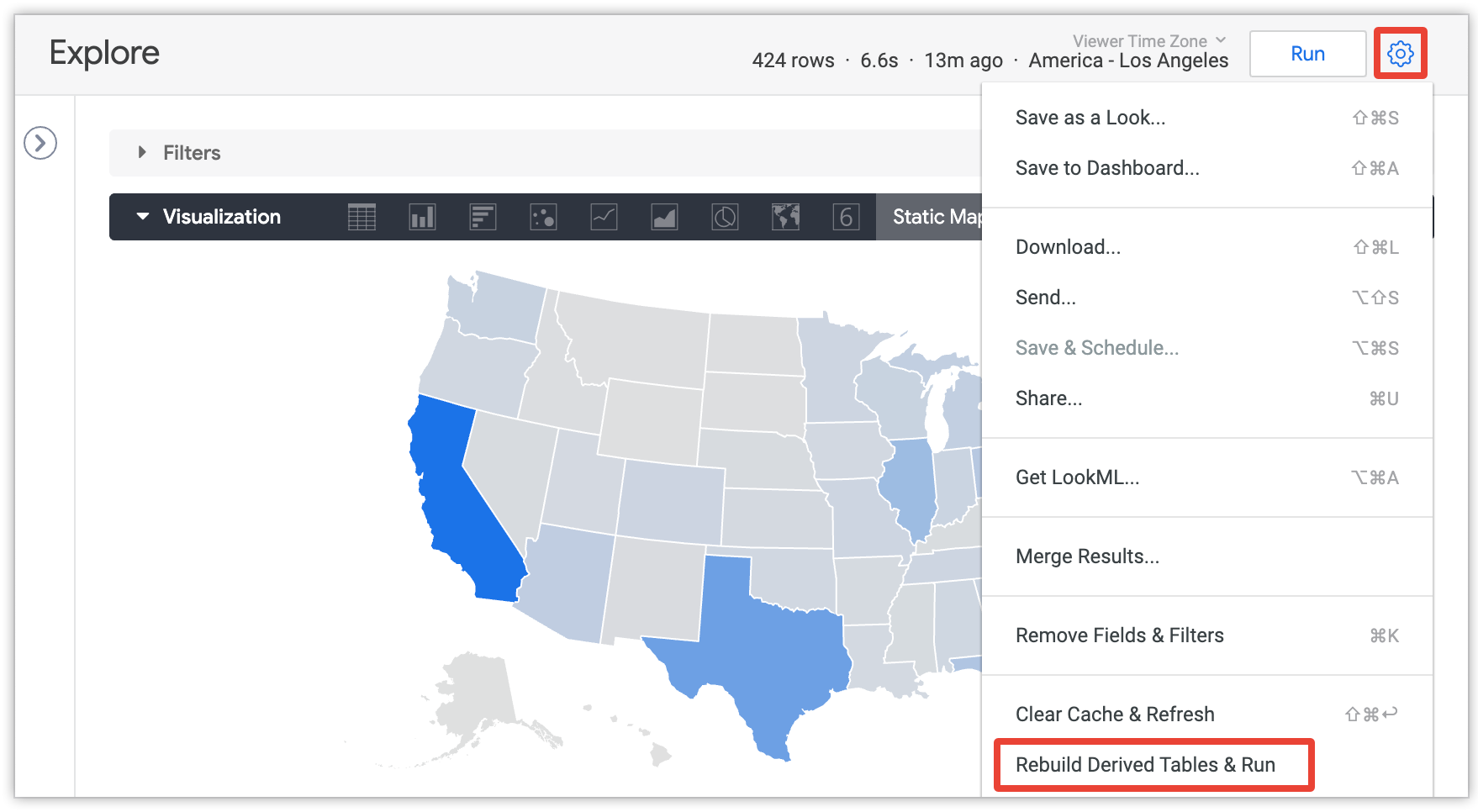
[派生テーブルの再構築と実行] オプションについて詳しくは、Looker での派生テーブルに関するドキュメント ページをご覧ください。
データがキャッシュに保存される期間
キャッシュに保存された結果が無効になるまでの時間を指定するには、persist_for パラメータ(モデルの場合、Explore の場合)または max_cache_age パラメータ(データグループの場合)を使用します。persist_for と max_cache_age の時間の経過に応じて、タイムラインに沿った動作が異なります。
persist_forまたはmax_cache_ageの時間が経過する前: クエリが再実行されると、Looker はキャッシュからデータを pull します。persist_forまたはmax_cache_ageの期限が切れた場合: Instant Dashboard Looker Labs 機能を有効にしていない限り、Looker はキャッシュからデータを削除します。persist_forまたはmax_cache_ageの時間が経過した後: クエリが再実行されると、Looker はデータベースからデータを直接 pull し、persist_forまたはmax_cache_ageタイマーをリセットします。
ここでの重要なポイントは、Looker のインスタント ダッシュボード機能が無効になっている間は、persist_for または max_cache_age の時間が経過すると、データがキャッシュから削除されることです。(インスタント ダッシュボード機能では、キャッシュに保存された結果をダッシュボードにすぐに読み込むためにキャッシュが必要です)。インスタント ダッシュボードを有効にすると、データはキャッシュに 30 日間またはキャッシュ ストレージの上限に達するまでキャッシュに残ります。キャッシュがストレージの上限に達すると、データは LRU(Least Recent Use)アルゴリズムに基づいて排出され、persist_for または max_cache_age のタイマーが期限切れとなったデータが一度に削除されます。
データがキャッシュに保存される期間を最小限に抑える
Looker では内部プロセスにディスク キャッシュが必要なため、persist_for パラメータと max_cache_age パラメータを 0 に設定しても、データは常にキャッシュに書き込まれます。データがキャッシュに書き込まれると、削除フラグが設定されますが、最大10分間はディスク上に存在することがあります。
ただし、ディスクキャッシュに入る顧客データはすべてAES(Advanced Encryption Standard)により暗号化されており、さらに、次の変更を実施することで、顧客データがキャッシュに保存される期間を最小限に抑えることができます。
- インスタント ダッシュボード Looker ラボ機能を無効にします。この機能を利用するには、Looker でデータをキャッシュに保存する必要があります。
persist_forパラメータ(モデルまたは Explore の場合)またはmax_cache_ageパラメータ(データグループの場合)の場合は、値を 0 に設定します。インスタント ダッシュボードがオフになっている Looker インスタンスでは、persist_forの期限が切れるか、データがデータグループで指定されたmax_cache_ageに到達すると、キャッシュが削除されます。(永続的な派生テーブルのpersist_forパラメータでは必要ありません)。永続的な派生テーブルは、キャッシュではなくデータベース自体に書き込まれるからです。suggest_persist_forパラメータを短い時間に設定します。suggest_persist_for値は、Looker がフィルタの候補をキャッシュに保存する期間を指定します。フィルタの候補は、フィルタ対象のフィールドの値に対するクエリに基づいています。これらのクエリ結果はキャッシュに保存されるため、ユーザーがフィルタ テキスト フィールドに入力すると Looker がすばやく候補を提示できます。デフォルトでは、フィルタ候補は 6 時間キャッシュされます。データがキャッシュに保存される時間を最小限に抑えるには、suggest_persist_for値を 5 分などより低い値に設定します。