Per una guida sull'implementazione dell'awareness aggregata, consulta anche l'articolo del Centro assistenza Tutorial sull'awareness aggregata.
Panoramica
Looker utilizza la logica di awareness aggregata per trovare la tabella più piccola ed efficiente disponibile nel tuo database per eseguire una query pur mantenendo la precisione.
Per le tabelle molto grandi nel database, gli sviluppatori di Looker possono creare tabelle di dati aggregati di dimensioni più piccole, raggruppate in base a varie combinazioni di attributi. Le tabelle aggregate funzionano come roll-up o tabelle di riepilogo che Looker può utilizzare per eseguire query quando possibile, anziché la tabella grande originale. Se implementato strategicamente, l'awareness aggregata può accelerare la query media in base agli ordini di grandezza.
Ad esempio, potresti avere una tabella di dati con scala nell'ordine dei petabyte con una riga per ogni ordine che si è verificato sul tuo sito web. Da questo database, puoi creare una tabella aggregata con i tuoi totali giornalieri delle vendite. Se il tuo sito web riceve 1000 ordini ogni giorno, la tabella aggregata giornaliera rappresenti ogni giorno con 999 righe in meno rispetto alla tabella originale. Puoi creare un'altra tabella aggregata con i totali delle vendite mensili che risulterà ancora più efficiente. Quindi, se un utente esegue una query per le vendite giornaliere o settimanali, Looker utilizzerà la tabella delle vendite totali giornaliere. Se un utente esegue una query sulle vendite annuali e non hai una tabella aggregata annuale, Looker utilizzerà la cosa migliore successiva, che è la tabella aggregata delle vendite mensili in questo esempio.
Questa immagine mostra in che modo Looker risponde alle tue domande degli utenti con le tabelle aggregate, quando possibile:
- Per una query sulle vendite mensili totali, Looker utilizza la tabella aggregata sulla base delle vendite mensili (
sales_monthly_aggregate_table). - Per una query sul totale di ogni vendita in un giorno, non esiste una tabella aggregata con quella granularità, quindi Looker riceve i risultati delle query dalla tabella del database originale (
orders_database). Tuttavia, se gli utenti eseguono questo tipo di query spesso, puoi facilmente creare una tabella aggregata per questo. - Per una query sulle vendite settimanali, non esiste una tabella aggregata settimanale, quindi Looker utilizza la cosa migliore successiva, che è la tabella aggregata basata sulle vendite giornaliere (
sales_daily_aggregate_table).
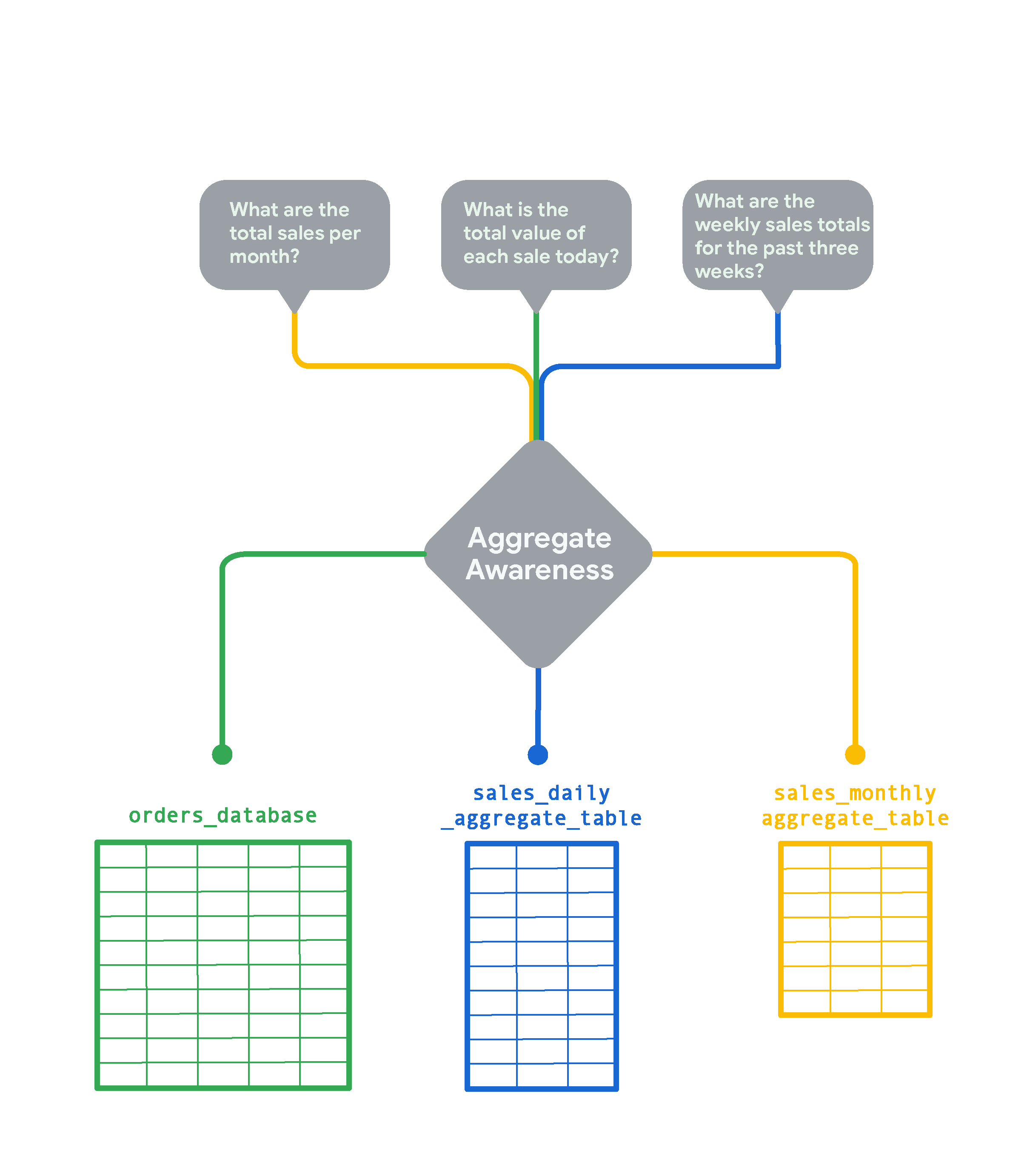
Utilizzando la logica di awareness aggregata, Looker esegue query sulla tabella aggregata più piccola possibile per rispondere alle domande degli utenti. La tabella originale viene utilizzata solo per le query che richiedono una granularità maggiore rispetto a quelle fornite dalle tabelle aggregate.
Non è necessario unire le tabelle aggregate o aggiungerle a un'esplorazione separata. Invece, Looker modifica in modo dinamico la clausola FROM della query Explore per accedere alla migliore tabella aggregata per la query. Ciò significa che le dettaglio vengono mantenute e le esplorazioni possono essere consolidate. Con il riconoscimento degli aggregati, un'esplorazione può sfruttare automaticamente le tabelle aggregate ma può comunque analizzare nei dettagli i dati granulari, se necessario.
Puoi anche sfruttare le tabelle aggregate per migliorare drasticamente le prestazioni delle dashboard, in particolare per i riquadri che eseguono query su enormi set di dati. Per maggiori dettagli, consulta la sezione Ottenere il codice LookML della tabella aggregata da una dashboard nella pagina della documentazione del parametro aggregate_table.
Aggiunta di tabelle aggregate al progetto
Per essere accessibili per l'awareness aggregata, le tabelle aggregate devono essere persistenti nel tuo database. Poiché le tabelle aggregate sono un tipo di tabella derivata permanente (PDT), le tabelle aggregate hanno gli stessi requisiti delle PDT. Per maggiori dettagli, consulta la pagina Tabelle derivate in Looker.
Gli sviluppatori di Looker possono creare tabelle aggregate strategiche che riducono al minimo il numero di query richieste nelle tabelle di grandi dimensioni in un database. Le tabelle aggregate devono essere continuative nel tuo database affinché siano accessibili per l'awareness aggregata. Le tabelle aggregate sono quindi un tipo di tabella derivata permanente (PDT).
Una tabella aggregata viene definita utilizzando il parametro aggregate_table in un parametro explore nel progetto LookML.
Ecco un esempio di explore con una tabella aggregata in LookML:
explore: orders {
label: "Sales Totals"
join: order_items {
sql_on: ${orders.id} = ${order_items.id} ;;
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [created_month]
measures: [order_items.total_sales]
}
}
# other explore parameters
}
Per creare una tabella aggregata, puoi scrivere il codice LookML da zero oppure recuperare il LookML della tabella aggregata da un'esplorazione o da una dashboard. Consulta la pagina di documentazione del parametro aggregate_table per le specifiche del parametro aggregate_table e dei relativi sottoparametri.
Progettazione di tabelle aggregate
Affinché una query di esplorazione utilizzi una tabella aggregata, deve essere in grado di fornire dati precisi per la query di esplorazione. Looker può utilizzare una tabella aggregata per una query di Explore se tutte le condizioni seguenti sono vere:
- I campi della query Esplora sono un sottoinsieme dei campi della tabella aggregata (vedi la sezione Fattori del campo in questa pagina). Per gli intervalli di tempo, i periodi di tempo della query Esplora possono essere ricavati dai periodi di tempo nella tabella aggregata (consulta la sezione Fattori relativi al periodo di tempo in questa pagina).
- La query di esplorazione contiene i tipi di misurazione supportati dall'awareness aggregata (consulta la sezione Fattori per il tipo di misurazione in questa pagina) oppure la tabella Esplora ha una tabella aggregata che corrisponde esattamente (vedi la sezione Creazione di tabelle aggregate che corrispondono esattamente alle query di Esplora in questa pagina).
- Il fuso orario della query Esplora corrisponde al fuso orario utilizzato dalla tabella aggregata (consulta la sezione Fattori di fuso orario in questa pagina).
- I filtri delle query di Esplora che sono disponibili come dimensioni nella tabella aggregata o ciascuno dei filtri della query Esplora corrisponde a un filtro nella tabella aggregata (consulta la sezione Fattori di filtro in questa pagina).
Un modo per garantire che una tabella aggregata possa fornire dati accurati per una query di Explore è semplicemente creare una tabella aggregata che corrisponde esattamente a una query di Explore. Per maggiori dettagli, consulta la sezione Creazione di tabelle aggregate che corrispondono esattamente alle query di Esplora in questa pagina.
Fattori sul campo
Per essere utilizzata per una query di Explore, una tabella aggregata deve avere tutte le dimensioni e le misure necessarie per la query di Explore, inclusi i campi utilizzati per i filtri nella query di Explore. Se una query di Explore contiene una dimensione o una misura che non è in una tabella aggregata, Looker non può utilizzare la tabella aggregata e utilizzerà invece la tabella di base.
Ad esempio, se una query raggruppa le dimensioni A e B, le aggrega per misura C e filtra la dimensione D, la tabella aggregata deve avere almeno A, B e D come dimensioni e C come misura.
La tabella aggregata può contenere anche altri campi, ma, per essere idonea all'ottimizzazione, deve contenere almeno i campi Query di esplorazione. L'unica eccezione sono le dimensioni del periodo di tempo, perché i periodi di granularità più evidenti possono essere ricavati da quelli più granulari.
A causa di queste considerazioni sul campo, una tabella aggregata è specifica dell'Explore in cui è definita. Una tabella aggregata definita in un'esplorazione non può essere utilizzata per le query in un'altra esplorazione.
Fattori relativi a tempistiche
La logica di awareness aggregata di Looker è in grado di ricavare un periodo di tempo dall'altro. È possibile utilizzare una tabella aggregata per una query purché il periodo di tempo della tabella aggregata abbia una granularità maggiore (o uguale) della query Esplora. Ad esempio, una tabella aggregata basata sui dati giornalieri può essere utilizzata per una query Esplora che richiede altri periodi di tempo, come query per dati giornalieri, mensili e annuali o persino per giorni del mese, giorni dell'anno e settimane dell'anno. Tuttavia, non è possibile utilizzare una tabella aggregata annuale per una query Esplora che richiede dati orari, poiché i dati della tabella aggregata non hanno una granularità sufficiente per la query Esplora.
Lo stesso vale per i sottoinsiemi di intervalli di tempo. Ad esempio, se hai una tabella aggregata che viene filtrata per gli ultimi tre mesi e un utente esegue una query sui dati con un filtro per gli ultimi due mesi, Looker potrà utilizzare la tabella aggregata per quella query.
Inoltre, la stessa logica si applica alle query con filtri di periodo di tempo: una tabella aggregata può essere utilizzata per una query con un filtro di periodo di tempo, purché il periodo di tempo della tabella aggregata abbia una granularità (o uguale) maggiore del filtro di periodo di tempo utilizzato nella query di Explore. Ad esempio, una tabella aggregata con una dimensione temporale giornaliera può essere utilizzata per una query Esplora che filtra per giorno, settimana o mese.
Misurare i fattori di tipo
Affinché una query di esplorazione utilizzi una tabella aggregata, le misure nella tabella aggregata devono essere in grado di fornire dati accurati per la query di esplorazione.
Per questo motivo sono supportati solo determinati tipi di misure, come descritto nelle sezioni seguenti:
- Misure con i tipi di misurazione supportati
- Misure definite da espressioni SQL
- Misure non definite con
${TABLE} - Misure approssimative sui conteggi distinti
Se una query di Explore utilizza qualsiasi altro tipo di misura, Looker utilizzerà la tabella originale, non la tabella aggregata, per restituire i risultati. L'unica eccezione è se la query Esplora è una corrispondenza esatta di una query tabella aggregata, come descritto nella sezione Creare tabelle aggregate che corrispondono esattamente alle query Esplora.
In caso contrario, per restituire i risultati verrà utilizzata la tabella originale, non la tabella aggregata.
Misure con i tipi di misurazione supportati
L'awareness aggregata può essere utilizzata per le query Esplora che utilizzano misure con i seguenti tipi di misurazione:
Se un'esplorazione unisce più tabelle di database, Looker può eseguire il rendering delle misure di tipo
SUM,COUNTeAVERAGErispettivamente comeSUM DISTINCT,COUNT DISTINCTeAVERAGE DISTINCT. Looker lo fa per evitare errori di calcolo dei fanout, come descritto nella sezione Simmetrici aggregati per esplorazioni con join in questa pagina.
Per utilizzare una tabella aggregata per una query di Explore, deve essere in grado di operare sulle misure della tabella aggregata per fornire dati precisi nella query di Explore. Ad esempio, una misura con type: sum può essere utilizzata per l'awareness aggregata perché puoi sommare diverse somme: puoi sommare una tabella aggregata delle somme settimanali per ottenere una somma mensile precisa. Analogamente, è possibile utilizzare una misura con type: max perché è possibile utilizzare una tabella aggregata di valori massimi giornalieri per trovare il massimo settimanale preciso.
Nel caso di misure con type: average, l'awareness aggregata è supportata perché Looker utilizza dati di somma e conteggio per estrarre con precisione i valori medi dalle tabelle aggregate.
Misure definite con espressioni SQL
L'awareness aggregata può essere utilizzata anche con misure definite con espressioni nel parametro sql. Quando vengono definite con espressioni SQL, sono supportati anche i seguenti tipi di misurazione:
Il riconoscimento degli aggregati è supportato per le misure definite come combinazioni di altre misure, come in questo esempio:
measure: total_revenue_in_dollars {
type: number
sql: ${total_revenue_in_dollars} - ${inventory_item.total_cost_in_dollars} ;;
}
Il riconoscimento aggregato è supportato anche per le misurazioni in cui i parametri sono definiti nel parametro sql, ad esempio:
measure: wholesale_value {
type: number
sql: (${order_items.total_sale_price} * 0.60) ;;
}
Inoltre, il riconoscimento aggregato è supportato per le misure in cui le operazioni MIN, MAX e COUNT sono definite nel parametro sql, come questa misura:
measure: most_recent_order_date {
type: date
sql: MAX(${users.created_at_raw})
}
Il riconoscimento degli aggregati è supportato solo per le operazioni
MIN(),MAX()eCOUNT(). Se vuoi utilizzare una media o una somma nella tua tabella aggregata, puoi creare una misura ditype: averageotype: sum, entrambe supportate per l'awareness aggregata.
Misure che fanno riferimento ai campi LookML
Quando si utilizzano le espressioni sql nelle misure, il riconoscimento aggregato supporta i seguenti tipi di riferimenti ai campi:
- Riferimenti che utilizzano il formato
${view_name.field_name}, che indica i campi in altre viste - Riferimenti che utilizzano il formato
${field_name}, che indica i campi nella stessa vista
Il riconoscimento aggregato non è supportato per le misure definite utilizzando il formato ${TABLE}.column_name, che indica una colonna in una tabella. Per una panoramica sull'utilizzo dei riferimenti in LookML, consulta la pagina della documentazione dedicata a incorporare SQL e fare riferimento agli oggetti LookML.
Ad esempio, una misura definita con questo parametro sql non sarebbe supportata in una tabella aggregata, poiché utilizza il formato ${TABLE}.column_name:
measure: wholesale_value {
type: number
sql: (${TABLE}.total_sale_price * 0.60) ;;
}
Se vuoi includere questa misura in una tabella aggregata, puoi creare una dimensione definita con il formato ${TABLE}.column_name, poi creare una misura che faccia riferimento alla dimensione in questo modo:
dimension: total_sale_price {
sql: (${TABLE}.total_sale_price) ;;
}
measure: wholesale_value {
type: number
sql: (${total_sale_price} * 0.60) ;;
}
Ora puoi utilizzare la misura wholesale_value nella tabella aggregata.
Misure approssimative sui conteggi distinti
In generale, i conteggi distinti non sono supportati per l'awareness aggregata perché non puoi ottenere dati precisi se provi ad aggregare conteggi distinti. Ad esempio, se stai conteggiando gli utenti distinti su un sito web, potrebbe esserci un utente che ha visitato il sito due volte, dopo tre settimane. Se tenti di applicare una tabella settimanale aggregata per ottenere un conteggio mensile di utenti distinti sul tuo sito web, tale utente verrà conteggiato due volte nella tua query conteggio mensile e i dati non saranno corretti.
A questo scopo, puoi creare una tabella aggregata che corrisponda esattamente a una query Esplora, come descritto nella sezione Creare tabelle aggregate che corrispondono esattamente alle query Esplora in questa pagina. Quando la query di esplorazione e la query di una tabella aggregata sono uguali, le misurazioni di conteggio distinte forniscono dati precisi, pertanto possono essere utilizzate per l'awareness aggregata.
Un'altra opzione è utilizzare approssimazioni per conteggi distinti. Per i dialetti che supportano gli schizzi HyperLogLog, Looker può utilizzare l'algoritmo HyperLogLog per approssimare i conteggi distinti per le tabelle aggregate.
È noto che l'algoritmo HyperLogLog presenta un errore di circa il 2%. Il parametro allow_approximate_optimization: yes richiede agli sviluppatori di Looker di riconoscere l'autorizzazione a utilizzare dati approssimativi per la misura in modo che la misura possa essere calcolata approssimativamente dalle tabelle aggregate.
Per ulteriori informazioni e per l'elenco dei dialetti che supportano il conteggio distinto tramite HyperLogLog, consulta la pagina della documentazione relativa al parametro allow_approximate_optimization.
Fattori relativi al fuso orario
In molti casi, gli amministratori di database utilizzano il fuso orario UTC come fuso orario per i database. Tuttavia, molti utenti potrebbero non essere nel fuso orario UTC. Looker offre diverse opzioni per convertire i fusi orari in modo che gli utenti ricevano i risultati delle query nel proprio fuso orario:
- Fuso orario delle query, un'impostazione che si applica a tutte le query sulla connessione al database. Se tutti gli utenti si trovano nello stesso fuso orario, puoi impostare un unico fuso orario della query in modo che tutte le query vengano convertite dal fuso orario del database nel fuso orario della query.
- Fusi orari specifici degli utenti, in cui agli utenti possono essere assegnati e selezionati singolarmente i fusi orari. In questo caso, le query vengono convertite dal fuso orario del database nel fuso orario del singolo utente.
Per ulteriori informazioni su queste opzioni, consulta la pagina Utilizzo delle impostazioni relative al fuso orario.
Questi concetti sono importanti per comprendere l'awareness aggregata, poiché, affinché una tabella aggregata venga utilizzata per una query con dimensioni o filtri di data, il fuso orario nella tabella aggregata deve corrispondere all'impostazione del fuso orario utilizzato per la query originale.
Le tabelle aggregate utilizzano il fuso orario del database se non è specificato alcun valore timezone. Nella connessione al database verrà utilizzato anche il fuso orario del database se una delle seguenti condizioni è vera:
- Il database non supporta i fusi orari.
- La connessione al fuso orario della query relativa alla connessione al tuo database è impostata sullo stesso fuso orario del database e il fuso orario.
- La connessione al tuo database non ha un fuso orario della query né fusi orari specifici per l'utente. In questo caso, la connessione al tuo database utilizza il fuso orario del database.
Se una di queste condizioni è vera, puoi omettere il parametro timezone per le tabelle aggregate.
In caso contrario, il fuso orario della tabella aggregata deve essere definito in modo che corrisponda a eventuali query in modo che venga utilizzata con maggiore probabilità:
- Se la connessione al database utilizza un unico fuso orario della query, devi abbinare il valore
timezonedella tabella aggregata al valore del fuso orario della query. - Se la connessione al tuo database utilizza fusi orari specifici per utente, devi creare tabelle aggregate identiche, ciascuna con un valore
timezonediverso in base ai fusi orari possibili degli utenti.
Looker non può utilizzare una tabella aggregata per una query di Explore se il fuso orario nella tabella aggregata non corrisponde al fuso orario della query di Explore. Se la connessione al tuo database ha fusi orari specifici per l'utente, significa che devi avere una tabella aggregata separata per ciascuno dei fusi orari degli utenti.
Fattori di filtro
Fai attenzione quando includi filtri nella tabella aggregata. I filtri di una tabella aggregata possono limitare i risultati al punto in cui la tabella aggregata è inutilizzabile. Ad esempio, supponiamo che crei una tabella aggregata per i conteggi giornalieri degli ordini e che i filtri della tabella aggregata vengano applicati solo agli ordini di occhiali da sole provenienti dall'Australia. Se un utente esegue una query Explore per il numero giornaliero di ordini di occhiali da sole in tutto il mondo, Looker non può utilizzare la tabella aggregata per tale query di Explore, poiché la tabella contiene solo i dati relativi all'Australia. La tabella aggregata filtra i dati in modo troppo limitato per essere utilizzati dalla query di esplorazione.
Inoltre, tieni presente i filtri che i tuoi sviluppatori di Looker potrebbero avere integrato in Explore, ad esempio:
access_filters: consente di applicare limitazioni ai dati specifici degli utenti.always_filter: richiede agli utenti di includere un determinato insieme di filtri per una query Esplora. Gli utenti possono modificare il valore del filtro predefinito per la query, ma non possono rimuovere completamente il filtro.conditionally_filter: definisce un insieme di filtri predefiniti che gli utenti possono ignorare se applicano almeno un filtro di un secondo elenco definito anche nella sezione Esplora.
Questi tipi di filtri si basano su campi specifici. Se Esplora ha questi filtri, devi includere i relativi campi nel parametro dimensions di aggregate_table.
Ad esempio, ecco un'esplorazione con un filtro di accesso basato sul campo orders.region:
explore: orders {
access_filter: {
field: orders.region
user_attribute: region
}
}
Per creare una tabella aggregata da utilizzare per questa esplorazione, la tabella deve includere il campo su cui si basa il filtro di accesso. Nel prossimo esempio, il filtro di accesso si basa sul campo orders.region e lo stesso campo viene incluso come dimensione nella tabella aggregata:
explore: orders {
access_filter: {
field: orders.region # <-- orders.region field
user_attribute: region
}
aggregate_table: sales_monthly {
materialization: {
datagroup_trigger: orders_datagroup
}
query: {
dimensions: [orders.created_day, orders.region] # <-- orders.region field
measures: [orders.total_sales]
timezone: America/Los_Angeles
}
}
}
Poiché la query della tabella aggregata include la dimensione orders.region, Looker può filtrare dinamicamente i dati nella tabella aggregata in modo che corrispondano al filtro della query di Explore. Pertanto, Looker può comunque utilizzare la tabella aggregata per le query di Explore, anche se il filtro Explore ha un filtro di accesso.
Questo vale anche per le query di Explore che utilizzano una tabella nativa derivata configurata con bind_filters. Il parametro bind_filters trasmette i filtri specificati da una query di esplorazione alla sottoquery di tabella nativa derivata. In caso di conoscenza aggregata, se la tua query Esplora richiede una tabella derivata nativa che utilizza bind_filters, la query Esplora può utilizzare una tabella aggregata solo se tutti i campi utilizzati nella parametro nativo della tabella derivata bind_filters hanno gli stessi valori del filtro nella query Esplora come nella tabella aggregata.
Creazione di tabelle aggregate che corrispondono esattamente alle query di Esplora
Un modo per assicurarti che una tabella aggregata possa essere utilizzata per una query di Explore è creare semplicemente una tabella aggregata che corrisponda esattamente alla query di Explore. Se la query di esplorazione e la tabella aggregata utilizzano entrambi le stesse misure, dimensioni, filtri, fusi orari e altri parametri, per definizione i risultati della tabella aggregata verranno applicati alla query di esplorazione. Se una tabella aggregata è una corrispondenza esatta di una query Explore (Esplora), Looker è in grado di utilizzare tabelle aggregate che includono qualsiasi tipo di misura.
Puoi creare una tabella aggregata da un'esplorazione utilizzando l'opzione Get LookML dal menu a forma di ingranaggio di un Esplora. Puoi anche creare corrispondenze esatte per tutti i riquadri di una dashboard utilizzando l'opzione Ottieni LookML dal menu a forma di ingranaggio di una dashboard.
Stabilire quale tabella aggregata viene utilizzata per una query
Gli utenti con autorizzazioni di see_sql possono utilizzare i commenti nella scheda SQL di un'esplorazione per vedere quale tabella aggregata verrà utilizzata per una query. I commenti della scheda SQL vengono mostrati anche in modalità di sviluppo, quindi gli sviluppatori possono testare nuove tabelle aggregate per vedere come Looker le utilizza prima di eseguire il push di nuove tabelle in produzione.
Ad esempio, in base alla tabella mensile aggregata di esempio mostrata in precedenza, possiamo accedere a Esplora ed eseguire una query per i totali delle vendite annuali. Possiamo quindi fare clic sulla scheda SQL per visualizzare i dettagli della query creata da Looker. Se sei in modalità Development (Sviluppo), Looker visualizza i commenti per indicare la tabella aggregata utilizzata per la query:

Dai commenti della scheda SQL si evince che Looker utilizza la tabella aggregata sales_monthly per questa query e fornisce informazioni sul motivo per cui non sono state utilizzate altre tabelle aggregate per la query:
-- use existing orders::sales_monthly in sandbox_scratch.LR$LB4151619827209021_orders$sales_monthly
-- Did not use orders::sales_weekly; it does not include the following fields in the query: orders.created_month
-- Did not use orders::sales_daily; orders::sales_monthly was a better fit for optimization.
-- Did not use orders::sales_last_3_days; contained filters not in the query: orders.created_date
Per informazioni sui possibili commenti visualizzati nella scheda SQL e suggerimenti su come risolverli, consulta la sezione Risoluzione dei problemi di questa pagina.
Stime di risparmio sul calcolo per l'awareness aggregata
Se la connessione al tuo database supporta le stime dei costi e se è possibile utilizzare una tabella aggregata per una query, la finestra Esplora mostrerà i risparmi di calcolo derivanti dall'utilizzo della tabella aggregata anziché l'esecuzione di query direttamente sul database. Il risparmio di awareness aggregato viene visualizzato a sinistra del pulsante Esegui in un'esplorazione prima dell'esecuzione della query:

Prima di eseguire la query, se vuoi vedere quale tabella aggregata verrà utilizzata per la query, puoi fare clic sulla scheda SQL, come descritto nella sezione Stabilire quale tabella aggregata viene utilizzata per una query di questa pagina della documentazione.
Una volta eseguita la query, la finestra Esplora mostra la tabella aggregata utilizzata per rispondere alla query:

Il risparmio aggregato per l'awareness viene mostrato per le connessioni al database abilitate per le stime dei costi. Per ulteriori informazioni, consulta la pagina Esplorazione dei dati in Looker.
Nuovo unione di Looker con le tue tabelle aggregate
Per le tabelle aggregate con filtri di tempo, Looker può unire dati aggiornati nella tabella aggregata. La tua tabella aggregata potrebbe contenere dati relativi agli ultimi tre giorni, ma potrebbe essere stata creata ieri. Nella tabella aggregata non saranno presenti le informazioni di oggi, quindi non ti aspetteresti di utilizzarla per una query Esplora sulle informazioni giornaliere più recenti.
Tuttavia, Looker può comunque utilizzare i dati della tabella aggregata per la query, perché Looker eseguirà una query sui dati più recenti, poi unirà i risultati ai risultati della tabella aggregata.
Looker può unire i dati aggiornati con i dati della tabella aggregata nelle seguenti circostanze:
- La tabella aggregata è provvista di un filtro temporale.
- La tabella aggregata include una dimensione basata sullo stesso campo temporale del filtro temporale.
Ad esempio, la seguente tabella aggregata ha una dimensione basata sul campo orders.created_date e un filtro temporale ("3 days") basato sullo stesso campo:
aggregate_table: sales_last_3_days {
query: {
dimensions: [orders.created_date]
measures: [order_items.total_sales]
filters: [orders.created_date: "3 days"] # <-- time filter
timezone: America/Los_Angeles
}
...
}
Se questa tabella aggregata è stata creata ieri, Looker recupererà i dati più recenti che non sono ancora inclusi nella tabella aggregata, quindi unirà i risultati aggiornati con i risultati della tabella aggregata. Ciò significa che gli utenti riceveranno i dati più recenti ottimizzando al contempo il rendimento utilizzando il riconoscimento degli aggregati.
Se sei in modalità Development (Sviluppo), puoi fare clic sulla scheda SQL di un'esplorazione per visualizzare la tabella aggregata che Looker ha utilizzato per la query e l'istruzione UNION che Looker utilizza per importare dati più recenti non inclusi nella tabella aggregata.
Attualmente, se Looker non è in grado di unificare i dati aggiornati con la tabella aggregata, Looker utilizzerà i dati esistenti della tabella aggregata.
Le tabelle aggregate devono essere persistenti
Per essere accessibile per l'awareness aggregata, la tabella aggregata deve essere continua nel tuo database. La strategia di persistenza è specificata nel parametro materialization della tabella aggregata. Poiché le tabelle aggregate sono un tipo di tabella derivata permanente (PDT), le tabelle aggregate hanno gli stessi requisiti delle PDT. Per maggiori dettagli, consulta la pagina Tabelle derivate in Looker.
Puoi creare PDT incrementali nel tuo progetto se il dialetto le supporta. Looker crea PDT incrementali aggiungendo dati aggiornati alla tabella, anziché ricreare la tabella nella sua interezza. Poiché le tabelle aggregate sono a loro volta un tipo di PDT, puoi anche creare tabelle aggregate incrementali. Per ulteriori informazioni sulle PDT incrementali, consulta la pagina relativa alla documentazione relativa alle PDT incrementali. Consulta la pagina della documentazione relativa al parametro increment_key per visualizzare un esempio di tabella aggregata incrementale.
Un utente con autorizzazione di develop può sostituire le impostazioni di persistenza e ricreare tutte le tabelle aggregate per una query per ottenere i dati più aggiornati. Per ricreare le tabelle per una query, utilizza l'opzione Rebuild Derived Tables & Run (Ricostruisci tabelle derivate e esegui) dal menu Explore's:
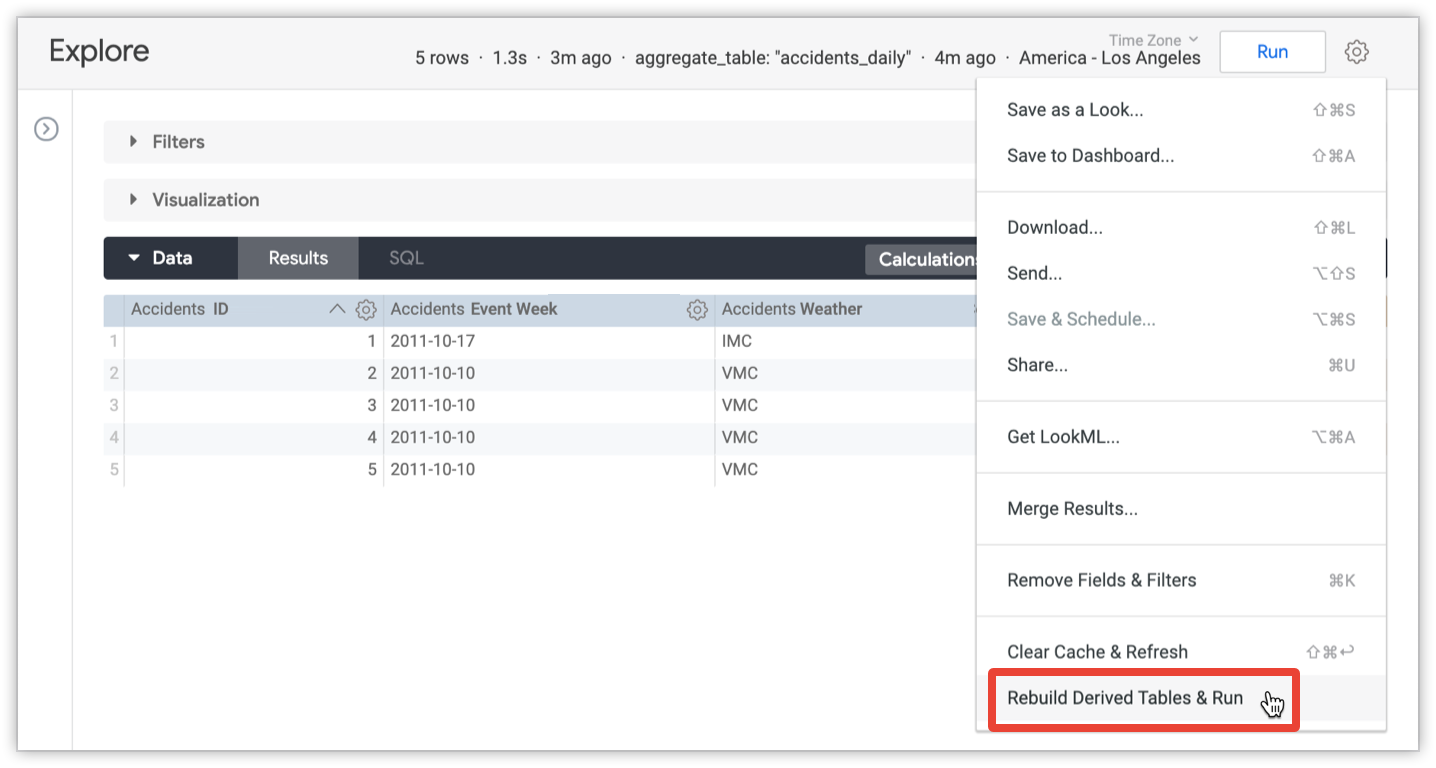
Devi attendere il caricamento della query Esplora prima che questa opzione sia disponibile.
L'opzione Ricostruisci tabelle derivate ed esegui ricostruisce tutte le tabelle derivate a cui viene fatto riferimento nella query, oltre a eventuali tabelle derivate che dipendono dalle tabelle nella query. Sono incluse le tabelle aggregate, che a loro volta sono un tipo di tabella derivata permanente.
Per l'utente che avvia l'opzione Ricostruisci tabelle derivate ed esegui, la query attende che le tabelle vengano ricostruite prima di caricare i risultati. Le query di altri utenti continueranno a utilizzare le tabelle esistenti. Una volta che le tabelle permanenti vengono ricostruite, tutti gli utenti utilizzeranno quelle ricostruite.
Consulta la pagina della documentazione sulle tabelle derivate in Looker per ulteriori dettagli sull'opzione Rebuild Derived Tables & Run (Ricrea tabelle derivate e esegui).
Risolvere i problemi
Come descritto nella sezione Stabilire quale tabella aggregata viene utilizzata per una query, se sei in modalità di sviluppo, puoi eseguire query nella scheda Esplora e fare clic sulla scheda SQL per visualizzare i commenti sulla tabella aggregata utilizzata per l'eventuale query.
La scheda SQL include anche commenti sul motivo per cui le tabelle aggregate non sono state utilizzate per una query, in questo caso. Per le tabelle aggregate che non vengono utilizzate, il commento inizierà con:
Did not use [explore name]::[aggregate table name];
Ad esempio, ecco un commento sul perché la tabella aggregata sales_daily definita nell'area di lavoro order_items Esplora non è stata usata per una query:
-- Did not use order_items::sales_daily; query contained the following filters
that were neither included as fields nor exactly matched by filters in the aggregate table:
order_items.created_year.
In questo caso, i filtri della query hanno impedito l'utilizzo della tabella aggregata.
La tabella seguente mostra altri possibili motivi per cui non è possibile utilizzare una tabella aggregata, unitamente ai passaggi per migliorarne l'usabilità.
| Motivo per cui non si utilizza la tabella aggregata |
Spiegazione e possibili passaggi |
|---|---|
| Questo campo non è presente in Esplora. | Si è verificato un errore con il tipo di convalida LookML. Molto probabilmente il motivo è che la tabella aggregata non è stata definita correttamente oppure perché nel codice LookML è presente un errore ortografico per la tabella aggregata. Una probabile causa è un nome di campo errato o simile. Per risolvere il problema, verifica che le dimensioni e le misure nella tabella aggregata corrispondano ai nomi dei campi in Explore. Per ulteriori informazioni su come definire una tabella aggregata, consulta la pagina della documentazione relativa al parametro aggregate_table. |
| La tabella aggregata non include i seguenti campi nella query. | Per essere utilizzata per una query di Explore, una tabella aggregata deve avere tutte le dimensioni e le misure necessarie per la query di Explore, inclusi i campi utilizzati per i filtri nella query di Explore. Se una query di Explore contiene una dimensione o una misura che non è in una tabella aggregata, Looker non può utilizzare la tabella aggregata e utilizzerà invece la tabella di base. Per informazioni dettagliate, consulta la sezione Fattori relativi al campo di questa pagina. L'unica eccezione sono le dimensioni del periodo di tempo, perché i periodi di granularità più evidenti possono essere ricavati da quelli più granulari. Per risolvere il problema, verifica che i campi Query di esplorazione siano inclusi nella definizione della tabella aggregata. |
| La query contiene i seguenti filtri che non sono stati inclusi come campi né corrispondevano esattamente ai filtri della tabella aggregata. | I filtri della query Explore impediscono a Looker di utilizzare la tabella aggregata. Per risolvere il problema, puoi procedere in uno dei seguenti modi:
|
| La query contiene le seguenti misure che non possono essere aggregate. | La query contiene uno o più tipi di misurazione non supportati per l'awareness aggregata, come Conteggio distinto, Mediana o Percentile. Per risolvere questo problema, controlla il tipo di ciascuna misura nella query e assicurati che sia uno dei tipi di misurazione supportati. Inoltre, se la tua esplorazione ha unito, verifica che le tue misure non vengano convertite in misure distinte (aggregati simmetrici) tramite un ventaglio di join. Per una spiegazione, consulta la sezione Aggregazioni simmetriche per esplorazioni con join in questa pagina. |
| Una tabella aggregata diversa è più adatta per l'ottimizzazione. | Erano presenti più tabelle aggregate utilizzabili per la query e Looker ha trovato una tabella aggregata più ottimale da utilizzare. In questo caso non è necessario fare nulla. |
Looker non ha eseguito alcun raggruppamento (a causa di un parametro primary_key o cancel_grouping_fields), pertanto la query non può essere aggregata. |
La query fa riferimento a una dimensione che ne impedisce la presenza di una clausola GROUP BY, pertanto Looker non può utilizzare alcuna tabella aggregata per la query.
Per risolvere il problema, verifica che il parametro primary_key della vista e il parametro cancel_grouping_fields di Explore siano configurati correttamente. |
| La tabella aggregata conteneva filtri non presenti nella query. | La tabella aggregata contiene un filtro non temporale che non è presente nella query. Per risolvere il problema, puoi rimuovere il filtro dalla tabella aggregata. Per informazioni dettagliate, consulta la sezione Fattori di filtro in questa pagina. |
Un campo è definito come solo filtro nella query Esplora, ma è elencato nel parametro dimensions della tabella aggregata. |
Il parametro dimensions della tabella aggregata elenca un campo definito solo come campo filter nella query di esplorazione.Per risolvere il problema, rimuovi il campo dall'elenco dimensions della tabella aggregata. Se questo campo è necessario per la tabella aggregata, aggiungilo all'elenco filters nella query della tabella aggregata. |
| Lo strumento di ottimizzazione non può determinare il motivo per cui la tabella aggregata non è stata utilizzata. | Questo commento è riservato ai casi d'angolo. Se lo vedi per una query Esplora utilizzata di frequente, puoi creare una tabella aggregata che corrisponda esattamente alla query di Explore. Puoi recuperare facilmente LookML da tabella aggregata da un'esplorazione, come descritto nella pagina del parametro aggregate_table. |
Aspetti da considerare
Aggregati simmetrici per le esplorazioni con join
Un aspetto importante da considerare è che in un Explore che unirà più tabelle di database, Looker può eseguire misurazioni di tipo SUM, COUNT e AVERAGE rispettivamente come SUM DISTINCT, COUNT DISTINCT e AVERAGE DISTINCT. Looker lo fa per evitare errori di calcolo dei fanout. Ad esempio, una misura count viene visualizzata come tipo di misurazione count_distinct. Questo serve a evitare errori di calcolo dei fanout per i join e fa parte della funzionalità simmetrica degli aggregati di Looker. Per una spiegazione di questa funzionalità di Looker, consulta l'articolo del Centro assistenza sugli aggregati simmetrici.
La funzionalità simmetrica aggregata impedisce gli errori di calcolo, ma può anche impedire che le tabelle aggregate vengano utilizzate in determinati casi, quindi è importante da capire.
Per i tipi di misurazione supportati dall'awareness aggregata, questo vale per sum, count e average. Looker visualizzerà i tipi di misure come DISTINCT se:
- La misura proviene dalla "visualizzazione" di un'unione molta a uno o da uno a molti.
- La misura proviene dalla visualizzazione di un join many-to-many.
Consulta la pagina della documentazione relativa al parametro relationship per una spiegazione di questi tipi di join.
Se ritieni che la tua tabella aggregata non venga utilizzata per questo motivo, puoi crearne una che corrisponda esattamente a una query di Explore al fine di utilizzare questi tipi di misurazione per un'esplorazione con join. Per ulteriori informazioni, consulta la sezione Creazione di tabelle aggregate che corrispondono esattamente alle query di Esplora in questa pagina.
Inoltre, se hai un dialetto SQL che supporta gli schizzi HyperLogLog, puoi aggiungere il parametro allow_approximate_optimization: yes alla misura. Quando una misura di conteggio è definita con allow_approximate_optimization: yes, Looker può utilizzarla per l'awareness aggregata, anche se viene visualizzata come un conteggio distinto.
Per i dettagli, consulta la pagina della documentazione relativa al parametro allow_approximate_optimization e un elenco dei dialetti SQL che supportano gli schizzi HyperLogLog.
Supporto del dialetto per la consapevolezza aggregata
La possibilità di utilizzare la consapevolezza aggregata dipende dal dialetto del database utilizzato dalla connessione di Looker. Nell'ultima release di Looker, i seguenti dialetti supportano l'awareness aggregata:
Il codice SQL precedente di Google BigQuery supporta l'awareness aggregata, ma non supporta l'unione di dati aggiornati con i dati della tabella aggregata.
Supporto del dialetto per la creazione incrementale di tabelle aggregate
Affinché Looker supporti le tabelle aggregate incrementali nel tuo progetto Looker, devono essere supportate anche il tuo dialetto del database. La tabella seguente mostra quali dialetti supportano sia le tabelle aggregate sia la creazione incrementale delle PDT nell'ultima release di Looker: