Introduzione a Cloud TPU
Le TPU (Tensor Processing Unit) sono circuiti integrati per applicazioni specifiche (ASIC) sviluppati da Google e utilizzati per accelerare i carichi di lavoro di machine learning. Per informazioni più dettagliate sull'hardware TPU, consulta Architettura di sistema. Cloud TPU è un servizio web che rende disponibili le TPU come risorse di calcolo scalabili su Google Cloud.
Le TPU addestrano i modelli in modo più efficiente utilizzando hardware progettato per eseguire operazioni su matrici di grandi dimensioni, spesso presenti negli algoritmi di machine learning. Le TPU dispongono di memoria on-chip ad alta larghezza di banda (HBM) che ti consente di utilizzare modelli e dimensioni di batch più grandi. Le TPU possono essere collegate in gruppi chiamati pod che scalano i carichi di lavoro con poche o nessuna modifica al codice.
Come funziona?
Per capire come funzionano le TPU, è utile capire in che modo altri acceleratori risolvono le sfide computazionali dell'addestramento dei modelli di ML.
Come funziona una CPU
Una CPU è un processore generico basato sull'architettura di Von Neumann. Ciò significa che una CPU lavora con software e memoria in questo modo:
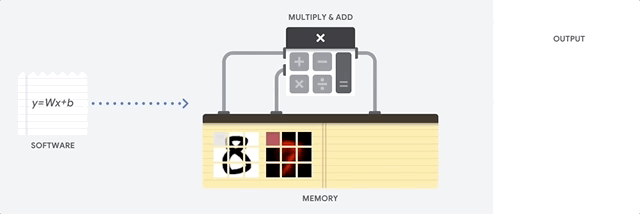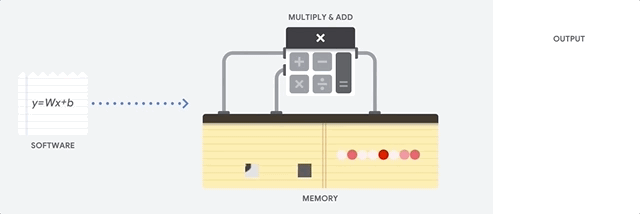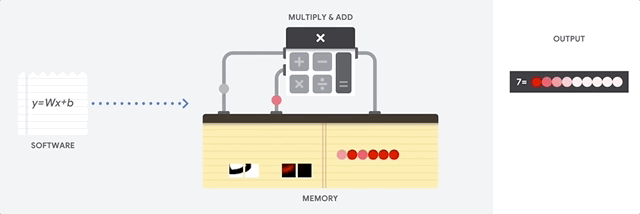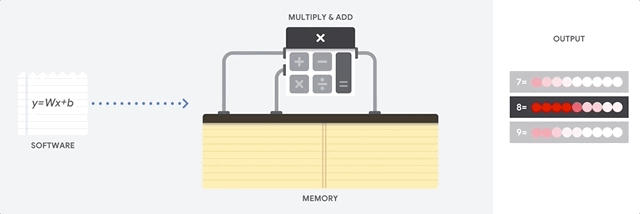
Il vantaggio principale delle CPU è la loro flessibilità. Puoi caricare qualsiasi tipo di software su una CPU per molti tipi diversi di applicazioni. Ad esempio, puoi utilizzare una CPU per l'elaborazione di testi su un PC, per controllare i motori dei razzi, eseguire transazioni bancarie o classificare le immagini con una rete neurale.
Una CPU carica i valori dalla memoria, esegue un calcolo sui valori e memorizza nuovamente il risultato nella memoria per ogni calcolo. L'accesso alla memoria è lento rispetto alla velocità di calcolo e può limitare il throughput totale delle CPU. Questo è spesso indicato come collo di bottiglia di von Neumann.
Come funziona una GPU
Per ottenere una maggiore velocità in termini di throughput, le GPU contengono migliaia di unità aritmetiche logiche (ALU) in un singolo processore. Una GPU moderna di solito contiene tra 2500 e 5000 ALU. Il grande numero di processori ti consente di eseguire contemporaneamente migliaia di moltiplicazioni e addizioni.

Questa architettura GPU funziona bene in applicazioni con parallelismo massiccio, come le operazioni sulle matrici in una rete neurale. Infatti, in un tipico carico di lavoro di addestramento per il deep learning, una GPU può fornire un throughput di un ordine di grandezza superiore rispetto a una CPU.
Tuttavia, la GPU è ancora un processore generico che deve supportare molti diversi software e applicazioni. Pertanto, le GPU hanno lo stesso problema delle CPU. Per ogni calcolo nelle migliaia di ALU, una GPU deve accedere ai registri o alla memoria condivisa per leggere gli operandi e memorizzare i risultati intermedi del calcolo.
Come funziona una TPU
Google ha progettato le Cloud TPU come processori a matrice specializzati per i carichi di lavoro delle reti neurali. Le TPU non possono eseguire elaboratori di testi, controllare motori di razzi o eseguire transazioni bancarie, ma possono gestire a velocità elevate operazioni di matrice di grandi dimensioni utilizzate nelle reti neurali.
Il compito principale delle TPU è l'elaborazione delle matrici, ovvero una combinazione di operazioni di moltiplicazione e accumulo. Le TPU contengono migliaia di accumulatori di moltiplicazione collegati direttamente tra loro per formare una grande matrice fisica. Questa è un'architettura di array systolico. Cloud TPU v3, contengono due array systolici di ALU 128 x 128 su un singolo processore.
L'host TPU esegue lo streaming dei dati in una coda infeed. La TPU carica i dati dalla coda infeed e li archivia nella memoria HBM. Al termine del calcolo, la TPU carica i risultati nella coda di outfeed. L'host TPU legge quindi i risultati della coda di outfeed e li memorizza nella memoria dell'host.
Per eseguire le operazioni delle matrici, la TPU carica i parametri dalla memoria HBM nell'unità di moltiplicazione a matrice (MXU).

Successivamente, la TPU carica i dati dalla memoria HBM. Quando viene eseguita ogni moltiplicazione, il risultato viene passato all'accumulatore di moltiplicazioni successivo. L'output è la somma di tutti i risultati della moltiplicazione tra i dati e i parametri. Non è richiesto alcun accesso alla memoria durante il processo di moltiplicazione delle matrici.
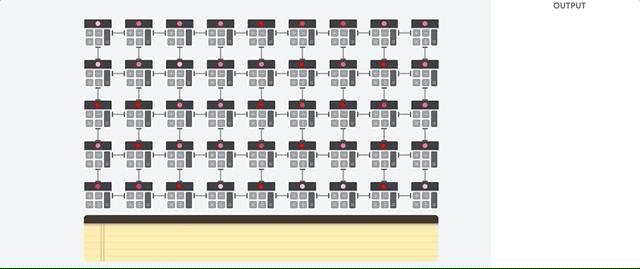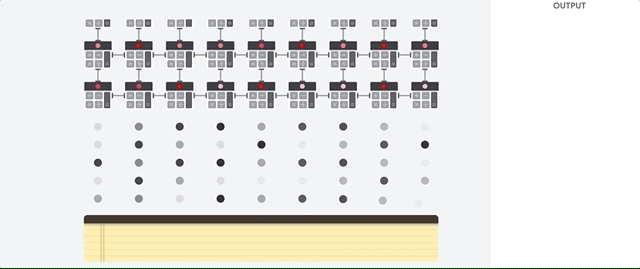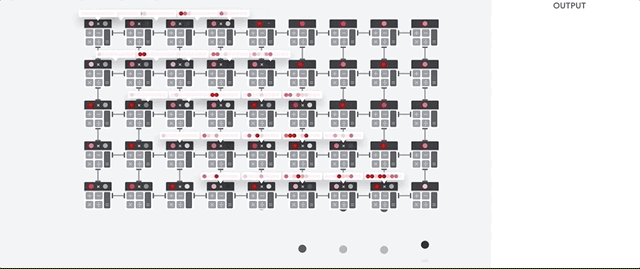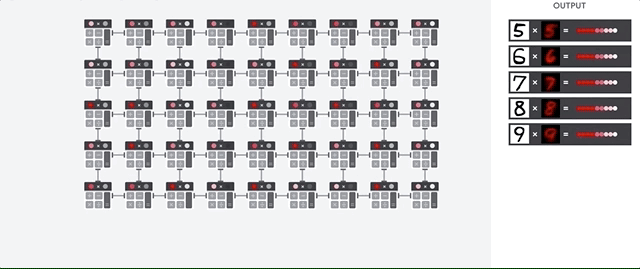
Di conseguenza, le TPU possono raggiungere una velocità di calcolo elevata per i calcoli delle reti neurali.
Compilatore XLA
Il codice eseguito sulle TPU deve essere compilato dal compilatore XLA (algebra lineare dell'acceleratore). XLA è un compilatore just-in-time che prende il grafo emesso da un'applicazione del framework ML e compila i componenti di algebra lineare, perdita e gradiente del grafo in codice macchina TPU. Il resto del programma viene eseguito sulla macchina host TPU. Il compilatore XLA fa parte dell'immagine VM TPU che viene eseguita su una macchina host TPU.
Quando utilizzare le TPU
Le Cloud TPU sono ottimizzate per carichi di lavoro specifici. In alcuni casi, potresti voler utilizzare GPU o CPU su istanze Compute Engine per eseguire i carichi di lavoro di machine learning. In generale, puoi decidere quale hardware è il migliore per il tuo carico di lavoro in base alle seguenti linee guida:
CPU
- Prototipazione rapida che richiede la massima flessibilità
- Modelli semplici che non richiedono molto tempo per l'addestramento
- Modelli di piccole dimensioni con dimensioni dei batch efficaci ridotte
- Modelli che contengono molte operazioni TensorFlow personalizzate scritte in C++
- Modelli limitati dall'I/O disponibile o dalla larghezza di banda di rete del sistema di destinazione
GPU
- Modelli con un numero significativo di operazioni TensorFlow/PyTorch/JAX personalizzate che devono essere eseguite almeno parzialmente su CPU
- Modelli con operazioni TensorFlow non disponibili su Cloud TPU (vedi l'elenco delle operazioni TensorFlow disponibili)
- Modelli di medie e grandi dimensioni con dimensioni di batch effettive più grandi
TPU
- Modelli in cui predominano i calcoli matriciali
- Modelli senza operazioni TensorFlow/PyTorch/JAX personalizzate all'interno del loop di addestramento principale
- Modelli che vengono addestrati per settimane o mesi
- Modelli di grandi dimensioni con grandi dimensioni di batch effettive
- Modelli con embedding di grandi dimensioni comuni nei workload di ranking e consigli avanzati
Le Cloud TPU non sono adatte ai seguenti carichi di lavoro:
- Programmi di algebra lineare che richiedono frequenti ramificazioni o contengono molte operazioni algebriche elementari
- Carichi di lavoro che richiedono operazioni aritmetiche ad alta precisione
- Carichi di lavoro di reti neurali che contengono operazioni personalizzate nel loop di addestramento principale
Best practice per lo sviluppo del modello
Un programma il cui calcolo è dominato da operazioni non matriciali come addizione, trasformazione o concatenazione probabilmente non raggiungerà un elevato utilizzo di MXU. Di seguito sono riportate alcune linee guida per aiutarti a scegliere e creare modelli adatti per Cloud TPU.
Layout
Il compilatore XLA esegue trasformazioni del codice, inclusa la suddivisione di una moltiplicazione di matrici in blocchi più piccoli, per eseguire in modo efficiente i calcoli sull'unità di matrice (MXU). La struttura dell'hardware MXU, un array sistolica 128 x 128, e il design del sottosistema di memoria delle TPU, che preferisce dimensioni che sono multipli di 8, vengono utilizzati dal compilatore XLA per l'efficienza del tiling. Di conseguenza, alcuni layout sono più adatti alla suddivisione in riquadri, mentre altri richiedono l'applicazione di modifiche alla forma prima di poter essere suddivisi in riquadri. Le operazioni di ricreazione della forma sono spesso vincolate dalla memoria su Cloud TPU.
Forme
Il compilatore XLA compila un grafo ML just in time per il primo batch. Se eventuali gruppi successivi hanno forme diverse, il modello non funziona. (La ricomposiz ione del grafico ogni volta che la forma cambia è troppo lenta.) Pertanto, qualsiasi modello con tensori con forme dinamiche non è adatto alle TPU.
Spaziatura interna
Un programma Cloud TPU ad alte prestazioni è un programma in cui il calcolo intensivo può essere suddiviso in blocchi di 128 x 128. Quando un calcolo della matrice non può occupare un'intera MXU, il compilatore completa i tensori con zeri. Esistono due svantaggi per la spaziatura interna:
- I tensori riempiti con zeri sottoutilizzano il core TPU.
- Il padding aumenta la quantità di spazio di archiviazione della memoria on-chip richiesta per un tensore e può portare a un errore di memoria insufficiente nei casi estremi.
Sebbene il padding venga eseguito automaticamente dal compilatore XLA, se necessario, è possibile determinare la quantità di padding eseguita tramite lo strumento op_profile. Puoi evitare il padding scegliendo dimensioni dei tensori ben adatte alle TPU.
Dimensioni
La scelta di dimensioni dei tensori adeguate è fondamentale per ottenere il massimo delle prestazioni dall'hardware TPU, in particolare dall'unità MXU. Il compilatore XLA tenta di utilizzare la dimensione del batch o una dimensione della funzionalità per utilizzare al meglio l'unità MXU. Pertanto, uno di questi deve essere un multiplo di 128. In caso contrario, il compilatore aggiungerà un a capo a uno di questi fino a 128. Idealmente, le dimensioni del batch e le dimensioni delle funzionalità devono essere multipli di 8, il che consente di estrarre prestazioni elevate dal sottosistema di memoria.
Integrazione di Controlli di servizio VPC
I Controlli di servizio VPC di Cloud TPU ti consentono di definire perimetri di sicurezza attorno alle tue risorse Cloud TPU e di controllare il movimento dei dati oltre il confine del perimetro. Per scoprire di più sui Controlli di servizio VPC, consulta Panoramica dei Controlli di servizio VPC. Per scoprire le limitazioni nell'utilizzo di Cloud TPU con i Controlli di servizio VPC, consulta Prodotti supportati e limitazioni.
Edge TPU
I modelli di machine learning addestrati nel cloud devono sempre più eseguire l'inferenza "a livello perimetrale", ovvero su dispositivi che operano a livello perimetrale dell'Internet of Things (IoT). Questi dispositivi includono sensori e altri smart device che raccolgono dati in tempo reale, prendono decisioni intelligenti e poi intervengono o comunicano le loro informazioni ad altri dispositivi o al cloud.
Poiché questi dispositivi devono funzionare con un'alimentazione limitata (inclusa l'alimentazione a batteria), Google ha progettato il coprocessore Edge TPU per accelerare l'inferenza ML su dispositivi a basso consumo energetico. Un singolo Edge TPU può eseguire 4 trilioni di operazioni al secondo (4 TOPS) utilizzando solo 2 watt di potenza, in altre parole, hai 2 TOPS per watt. Ad esempio, Edge TPU può eseguire modelli di visione artificiale mobile all'avanguardia come MobileNet V2 a quasi 400 frame al secondo e in modo efficiente dal punto di vista energetico.
Questo acceleratore ML a basso consumo energetico migliora Cloud TPU e Cloud IoT per fornire un'infrastruttura end-to-end (cloud-to-edge, hardware e software) che semplifica le soluzioni basate sull'AI.
Edge TPU è disponibile per i tuoi dispositivi di prototipazione e produzione in diversi fattori di forma, tra cui un computer a scheda singola, un system-on-module, una scheda PCIe/M.2 e un modulo montato sulla superficie. Per ulteriori informazioni su Edge TPU e su tutti i prodotti disponibili, visita il sito coral.ai.
Inizia a utilizzare Cloud TPU
- Configurare un account Google Cloud
- Attiva l'API Cloud TPU
- Concedere a Cloud TPU l'accesso ai bucket Cloud Storage
- Eseguire un calcolo di base su una TPU
- Addestra un modello di riferimento su una TPU
- Analizzare il modello
Richiesta di assistenza
Contatta l'assistenza Cloud TPU. Se hai un progetto Google Cloud attivo, preparati a fornire le seguenti informazioni:
- L'ID del tuo progetto Google Cloud
- Il nome della TPU, se esistente
- Altre informazioni che vuoi fornire
Passaggi successivi
Vuoi saperne di più su Cloud TPU? Le seguenti risorse potrebbero esserti utili: